

|
收稿日期: 2016-10-09; 优先数字出版日期: 2017-09-01
基金项目: 国家重点研发计划项目(编号:2017YFD0300400);河南省高等学校重点科研项目(编号:16A520081);中国科学院战略性先导科技专项(编号:XDA05050000)
第一作者简介: 黄亚博(1982— ),女,讲师,研究方向为遥感地学应用。E-mail:hyb@henu.edu.cn
通讯作者简介: 廖顺宝(1966— ),男,教授,研究方向为遥感与GIS应用及地学信息产品加工与质量评价等。E-mail:liaosb@igsnrr.ac.cn
中图分类号: TP751
文献标识码: A
|
摘要
随着遥感数据获取能力的不断增强,自动化程度已经成为大尺度遥感土地覆被分类面临的关键问题。然而,现有训练样本的人工选取方法成为制约土地覆被分类自动化的瓶颈。本文以河南、贵州两省为研究区,提出一种基于多源数据的土地覆被样本自动提取方法,以构建适用于大尺度的土地覆被自动分类。首先,以2010年1∶10万土地利用数据CHINALC和30 m分辨率全球土地覆被数据GlobleLand30为样本数据源;然后,利用空间一致性分析及异质性分析确定样本初选区域;最后,通过样本提纯去除无效样本。结果表明:(1)应用多源数据的土地覆被样本自动提取方法获得的分类产品总体分类精度高于人工样本提取方法制作的全球土地覆被产品MCD12Q1。(2)与单源样本自动提取方法相比,应用多源数据的土地覆被样本自动提取方法,可获得更好的分类稳定性。综上,多源数据的土地覆被样本自动提取方法可在保证精度的同时,提升土地覆被分类的自动化程度。
关键词
自动化, 样本提取, 土地覆被/土地利用, 分类, MODIS
Abstract
The capability of remotely sensed data acquisition is constantly improved. Thus, enhancing the automation degree for land cover classification at a large scale by remote sensing has become a key problem. However, present manual methods of selecting samples are becoming the bottleneck of automatic land cover classification. Many global and national land cover datasets based on remote sensing have been produced in the past two decades for different international or national initiatives. However, the rich knowledge implied in these products has not been fully exploited. The overall objective of this study is to set up an automatic land cover classification approach at a large scale by remote sensing through an automatic method of collecting land cover samples based on multisource datasets. The practical goals are to improve automation degree of land cover classification and enhance the accuracy of land cover classification. Henan and Guizhou provinces were selected as the study areas based on their types of land covers. First, the national land use database of China at a scale of 1∶100000 (CHINALC) and global land cover data (GlobleLand30) at a resolution of 30 m were selected as the data sources for the sample collection. Second, the initial sample areas were collected based on the spatial consistency analysis and heterogeneity analysis. Third, invalid samples were removed from the initial samples through the technology of sample purification. Finally, the Jeffries–Matusita distance was used to measure the classification feature separability of the samples between the different land cover types to prove the feasibility of the proposed method. The accuracy of the land cover product by the proposed method of sample collection was assessed and compared with the globe land cover product MCD12Q1. Experimental results show that the following: (a) The overall accuracy of the classification product through the proposed automatic method of sample collection based on multisource datasets was higher than that of the global land cover product MCD12Q1, which was classified based on the manual method of sample selection. The overall accuracy of the land cover classification product based on the proposed method was 78% in Henan province and 57% in Guizhou province, whereas that of MCD12Q1 was 74% and 55%, respectively. The Kappa coefficients of the former were 0.54 and 0.25, respectively, whereas those of the latter were 0.42 and 0.15, respectively. (b) Compared with the method of sample collection based on a single source land cover dataset, the proposed automatic method of sample collection based on multisource datasets had better classification stability and higher classification feature separability. The standard deviation of the Kappa coefficient and accuracy of products by 8-time experiments were less than 0.004. The classified results were also more stable. Unlike the method of sample collection based on a single source land cover dataset, the proposed automatic method of land cover sample collection based on multisource datasets not only improves the automation degree of land cover classification, but also enhances the accuracy of land cover classification.
Key words
automation, samples collection, land-cover/land-use, classification, MODIS
1 引 言
精确的土地覆被/利用产品是气候变化、水文循环、生物多样性保持等模拟的重要基础数据(Wulder和Coops 等,2014;Jun 等,2014;廖顺宝和秦耀辰,2014;Chen 等,2015)。随着对地观测技术的发展,遥感数据获取能力不断增强,导致数据海量化(李德仁 等,2014)。如何自动、快速地制作高精度产品,是大尺度遥感土地覆被分类面临的重要问题(Friedl 等,2010;Zhao 等,2014)。
机器学习算法在土地覆被分类中的应用研究,提升了分类的自动化程度。然而,分类过程中训练样本的提取仍以人工实地考察和高分辨率影像目视解译为主。Szantoi等人(2015)利用GPS设备,对美国福罗里达州8.5 km2的国家湿地公园Everglades NP进行实地调查采样,获得66430个像素点,作为训练样本。IGBP-DIS中379个样本区域由39位遥感专家耗时两周目视解译完成(Scepan 等,1999)。可见,人工样本选取需要耗费极大的人力和物力,无法满足应用的自动化需求。
中国土地利用数据及全球土地覆被数据已有多期,但其蕴藏的丰富地学知识并未充分挖掘应用(Liu 等,2005;候玉婷 等,2011;刘纪远 等,2014;Chen 等,2015)。因此,从现有土地覆被数据中挖掘不变地物特征,指导样本自动提取,对提升土地覆被分类自动化程度及精度具有重要意义。
杨存建和周成虎(2001)采用像元统计法挖掘现有土地覆被数据中的地类光谱知识,辅助样本选择。针对像元样本易受噪声影响的问题,部分学者开展了面向遥感影像的对象级样本提取方法研究(刘锟 等,2012;温奇 等,2013;吴田军 等,2014)。可以看到,这些方法仅采用单源土地覆被数据,未考虑数据源错误引入的无效样本。
基于以上考虑,本文以河南省、贵州省为研究区,利用CHINALC(刘纪远 等,2014)及Globle Land30(Chen 等,2015)多源土地覆被数据,通过数据融合及统计分析技术,挖掘分类正确率较高的不变地物所蕴含的土地覆被类型知识,完成目标影像的训练样本自动提取及土地覆被分类,并进行精度验证分析。
2 研究区与数据
2.1 研究区
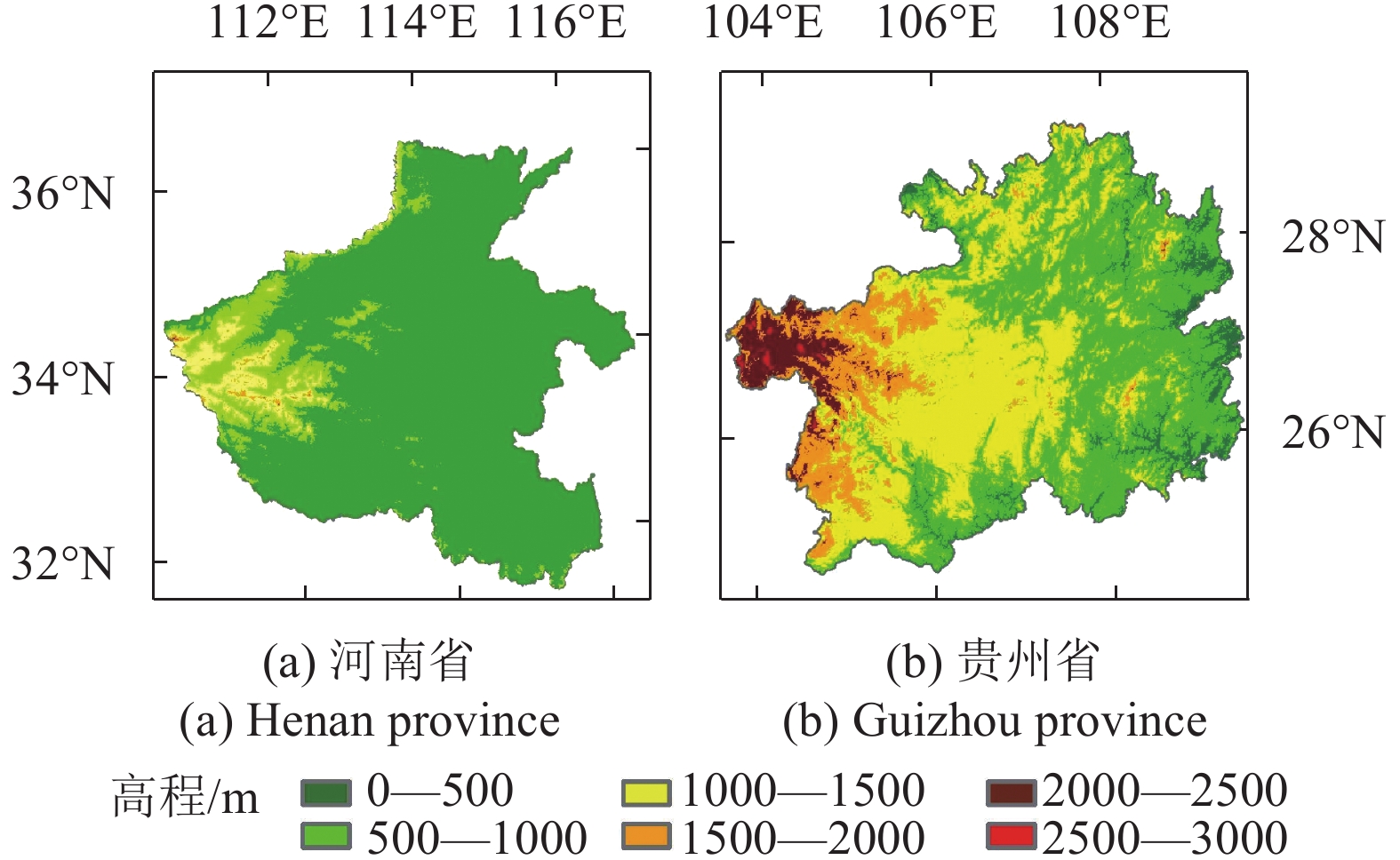
研究区选择地貌类型特点不同的河南、贵州两省。其中,河南省属于典型的温带—亚热带、湿润—半湿润季风气候,地势西高东低,平原、盆地面积占全省总面积的55.7%,土地覆被类型以耕地为主。贵州省为亚热带湿润季风气候,境内山脉众多,92.5%的面积为丘陵和山地,土地覆被复杂度高,土地覆被类型以林地为主。两省组合作为研究区,地貌类型较丰富,土地覆被类型较完备,适用于土地覆被分类研究。研究区高程如图1。

2.2 数据
2.2.1 多源土地覆被/利用数据
以2010年土地覆被数据集为基础进行样本提取,具体包括30 m分辨率全球土地覆被数据集Globle Land30和中国1∶10万土地利用数据CHINALC。GlobleLand30与CHINALC均以LANDSAT TM/ETM+影像为主要数据源。其中,CHINALC以专家目视解译方式制作,GlobleLand30以自动分类为主。经野外实地调查验证与高精度遥感影像样本检验可知,CHINALC和GlobleLand30总体分类精度分别为94.3%(刘纪远 等,2014)和80%(Chen 等,2015)。
2.2.2 其他数据
待分类的目标影像数据为美国国家航空航天局发布的MODIS数据产品。其中,光谱数据为16天合成1—7波段的NBAR产品MCD43A4(MODIS/Terra+AquaNadir BRDF-Adjusted Reflectance 16-Day L3 Global 500 m SIN Grid),物候数据为16天合成植被指数产品MOD13Q1(MODIS/Terra Vegetation Indices 16-Day L3 Global 250 m SIN Grid)中的增强植被指数(EVI)数据。
为验证本文提出的基于多源数据的土地覆被样本自动提取方法(简称多源样本自动提取法)的有效性,利用对比评价法,以高精度目视解译土地覆被产品为参考数据分别对应用多源样本自动提取法所制作的分类产品和全球MODIS土地覆被产品MCD12Q1 V5.1进行精度评价与分析。其中,河南省参考数据为同时相2013年河南省土地利用数据集(HENANLC)、贵州省参考数据为同时相2005年中国土地利用数据CHINALC。HENANLC由国家地球系统科学数据共享平台—黄河下游科学数据中心以LANDSAT TM/ETM+影像为基础,经人工目视解译制作完成,具有较高的精度,可用于分类结果的交叉验证。MCD12Q1是由美国波士顿大学以陆地生态系统参数数据库(STEP)中的站点数据为训练样本制作完成的全球土地覆被数据产品(Muchoney,1999),该产品每年一期,V5.1版本涵盖了2001年—2015年间的土地覆被信息。其研究组发布的精度评价结果显示,MCD12Q1洲际尺度的总体精度在70%—85%(Friedl 等,2010)。
3 研究方法
3.1 技术路线
多源样本自动提取方案核心步骤包含数据预处理、多源数据融合、空间一致性分析、空间异质性分析、样本初选和样本提纯。首先,以2010年土地覆被数据GlobleLand30和CHINALC为数据源,对数据进行预处理。其中,投影方式选择阿尔伯特等积投影,分辨率重采样为500 m,存储方式转换为栅格存储。而后,在统一分类系统的基础上,通过空间一致性分析与异质性分析,将空间一致并具有“同质”特征的像元作为样本首选区域,若“同质”区域样本数量不足,则通过对空间一致区域随机采样进行样本补充。最后,根据样本统计特征剔除无效样本,完成样本提纯,确定最终参与分类的训练样本。样本自动提取核心流程如图2。

3.2 样本提取
土地覆被/利用产品CHINALC、HENANLC、GlobleLand30、MCD12Q1分类系统存在一定差异,其中,CHINALC和HENANLC将土地划分为6个一级类、25个二级类,MCD12Q1分为17个一级类,GlobleLand30分为10个一级类。在进行样本提取前需完成土地覆被分类系统的转换合并。转换后的土地覆被分类系统分为耕地、林地、草地、水体、人工地面(简称人工)、裸地、永久冰雪7类,土地覆被产品分类系统转换合并对应关系如表1。由于河南、贵州两省在2010年CHINALC内无“永久冰雪”,且“裸地”面积仅占总面积的0.01%(河南)、0.02%(贵州),因此不再考虑这两种类别。
表 1 不同土地覆被分类系统间的类别对应关系
Table 1 Corresponding relationships of types in different land cover classification system
| 新类别 | CHINALC/HENANLC | GlobleLand30 | MCD12Q1 |
| 耕地 | 11, 12 | 10 | 12, 14 |
| 林地 | 21, 22, 23, 24 | 20, 40 | 1—9 |
| 草地 | 31, 32, 33 | 30 | 10 |
| 水体 | 41, 42, 43, 45, 46, 64 | 50, 60 | 0, 11 |
| 人工地面 | 51, 52, 53 | 80 | 13 |
| 裸地 | 61, 62, 63, 65, 66, 67 | 70, 90 | 16 |
| 永久雪冰 | 44 | 100 | 15 |
利用空间叠合分析技术,对统一分类系统的GlobleLand30-2010与CHINALC-2010进行空间一致性分析。若两产品分类一致,则认为该像元具有较高的置信度,属于样本初选区域。
考虑到土地覆被异质度较高区域分类错误率较高(黄亚博和廖顺宝,2016),且单个像元容易受到噪声的影响,设计样本自动提取方案时,以土地覆被类型单一的“同质”区域为优先样本选择区。以河南省为例,在计算“同质”区域时,对空间一致性区域,利用ARCGIS10.2邻域分析中的焦点统计功能,以1500×1500 m为窗口,对每个输入像元计算其指定邻域的变异度。其中,“同质”像元变异度为1,即以该像元为中心点的3×3像元邻域窗口内仅有一种土地覆被类型,而“异质”像元则代表邻域窗口内包含多种土地覆被类型。通过土地覆被类型异质度分析,剔除指定邻域内包含多种土地覆被类型的像元,减少噪声影响。以“同质”区域为样本优选区进行分层随机样本提取,并针对可能出现的“同质”区域样本数目不足问题,利用空间一致区域进行补充。
样本的质量直接影响到土地覆被产品的生产精度。本文所设计的多源样本自动提取方法,可降低现有土地覆被数据分类错误引入无效样本的概率。但分类一致并不等价于分类正确,并且作为样本源的土地覆被数据与目标遥感影像的时相并不相同,地物变化也会引入错误样本,需要对初选样本进行检测。变化检测方法有多种,可借助新旧时相遥感影像的变化确定不变地物的像元位置,如图像代数法、图像数据变换、分类后比较等多种分析方法(Celik,2009;于信芳 等,2014)。但这些方法均需要对新旧两种时相的遥感影像进行分析处理,工作量较大,且阀值需要人工确定。通过对研究区现有土地覆被数据分析可知,在1—5年时间内,土地覆被变化较小。因此,按照统计定律,对目标影像的不同土地覆被类型,统计样本均值,有效样本光谱值主要分布在该地类光谱均值周围。依据拉依达准则,区间
|
$|m_{kl}^i - {\bar m_{kl}}| < 3{{\rm{\sigma }}_{kl}}\;(l \in N,1 \leqslant l \leqslant 7)$
|
(1) |
式中,
3.3 样本可分性分析
为分析多源土地覆被数据样本自动提取步骤的有效性,利用两类地物间J-M距离(Jeffries-Matusita,J-M),对以CHINALC-2010为样本数据源的单源样本自动提取和本文多源样本自动提取两种方法所获得的土地覆被分类样本的特征可分性进行对比分析。并且,为提高客观性,对研究区重复采样8次,且两种提取方法初选样本数量相同。
J-M距离的值在0—2之间,可用于衡量两类地物间的可分性,值越大则可分性越好(Bruzzone 等,1995;Shao,2016)。当J-M距离位于1.0—1.9之间时,不同地类的样本间具有一定的可分性,但容易产生地类混淆。当J-M距离在1.9—2.0之间时,具有较好的可分性(Ghiyamat,2013)。J-M距离计算公式为
|
$J{M_{ij}} = \sqrt {2\left( {1 - {\rm{exp}}\left( { - {B_{ij}}} \right)} \right)} $
|
(2) |
式中,i、j分别代表不同地物类型,Bij为i、j两种地类样本的巴氏距离(Ghiyamat,2013;Padma和Sanjeevi,2014)。
3.4 分类方案与精度评价
以河南、贵州两省为研究区,分别对应用本文多源样本自动提取法所获得的土地覆被分类产品和采用人工样本完成分类的全球土地覆被产品MCD12Q1进行精度评价。首先,在2010年多源土地覆被数据基础上自动提取分类用训练样本。而后,采用C4.5决策树(Quinlan,1996)对目标遥感影像多时相EVI数据、光谱统计值和EVI统计值进行土地覆被分类。最后,利用对比评价法,对本文分类结果和MCD12Q1进行精度对比评价。在数据源方面,本文分类产品与MCD12Q1均以同时相MODIS遥感影像为处理对象。在特征选择方面,MCD12Q1包含12时相32天NBAR光谱数据、EVI、地表温度数据(LST)和全年NBAR、EVI、LST的最小值、最大值、平均值,共135波段(Friedl 等,2010)。而本文分类选用MCD12Q1分类特征子集,仅包含12时相32天EVI数据及NBAR年最大值、年最小值和年平均值共33个波段,特征可分性较MCD12Q1略弱。两产品分类特征对比,如表2。在分类方法方面,MCD12Q1利用Boosting(Quinlan,1996)技术对C4.5决策树算法进行优化,考虑到Boosting技术对噪声样本敏感,本文设计的分类方案仅采用C4.5决策树算法。综上,在分类流程相似,本文分类方案所采用的分类特征及分类算法较MCD12Q1相比处于劣势的情况下,若能取得较好的分类精度,则说明基于多源土地覆被数据的样本自动提取法在土地覆被分类中具有一定的优势。
表 2 土地覆被分类特征
Table 2 Characteristics of land cover classification
| 特征 | 产品源 | 本文分类选用 | MCD12Q1选用 |
| 光谱 | MCD43A4 | – | √ |
| 光谱统计值 | MCD43A4 | √ | √ |
| EVI | MOD13Q1 | √ | √ |
| EVI统计值 | MOD13Q1 | – | √ |
| LST | MOD11A2 | – | √ |
| LST统计值 | MOD11A2 | – | √ |
4 结果分析
4.1 土地覆被分类样本自动提取结果
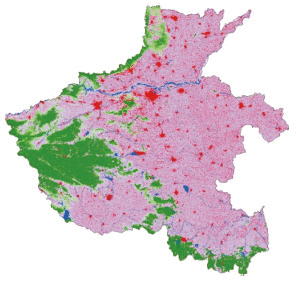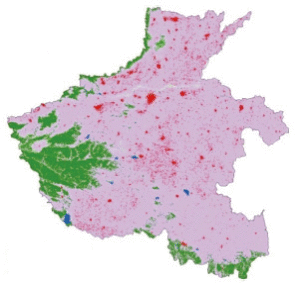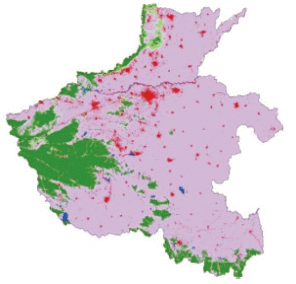
以CHINALC-2010为单一样本数据源,自动重复采样8次,其中一次的分布情况如图3。基于单源自动提取法所获分类样本广泛分布于研究区内,但不能排除由于分类错误造成的无效样本。
对多源自动样本提取法核心阶段结果分析如下。研究区2010年GlobleLand30与CHINALC叠合分析获得土地覆被产品空间一致性分布如图4(a)、4(d)。其中,河南省以耕地为主,林地、草地为辅,两产品空间一致性区域较多,为80%。贵州省以林地为主,耕地、草地为辅,地类破碎度高,空间一致性区域较少,为49%。为减少噪声及定位误差对样本的影响,对空间一致性分布图进行异质度分析,获得“同质”区域,如图4(b)、4(e)。其中,河南土地复杂度较低,“同质”样本区域占总面积的20%,而贵州省受到山地、丘陵地形的影响,同质样本区域较少,占15%。重复采样多次,其中一次多源自动提取样本分布情况如图4(c)、图4(f)。为便于对比分析,多源、单源两种方法初选样本数目相同,初选样本数量如表3。
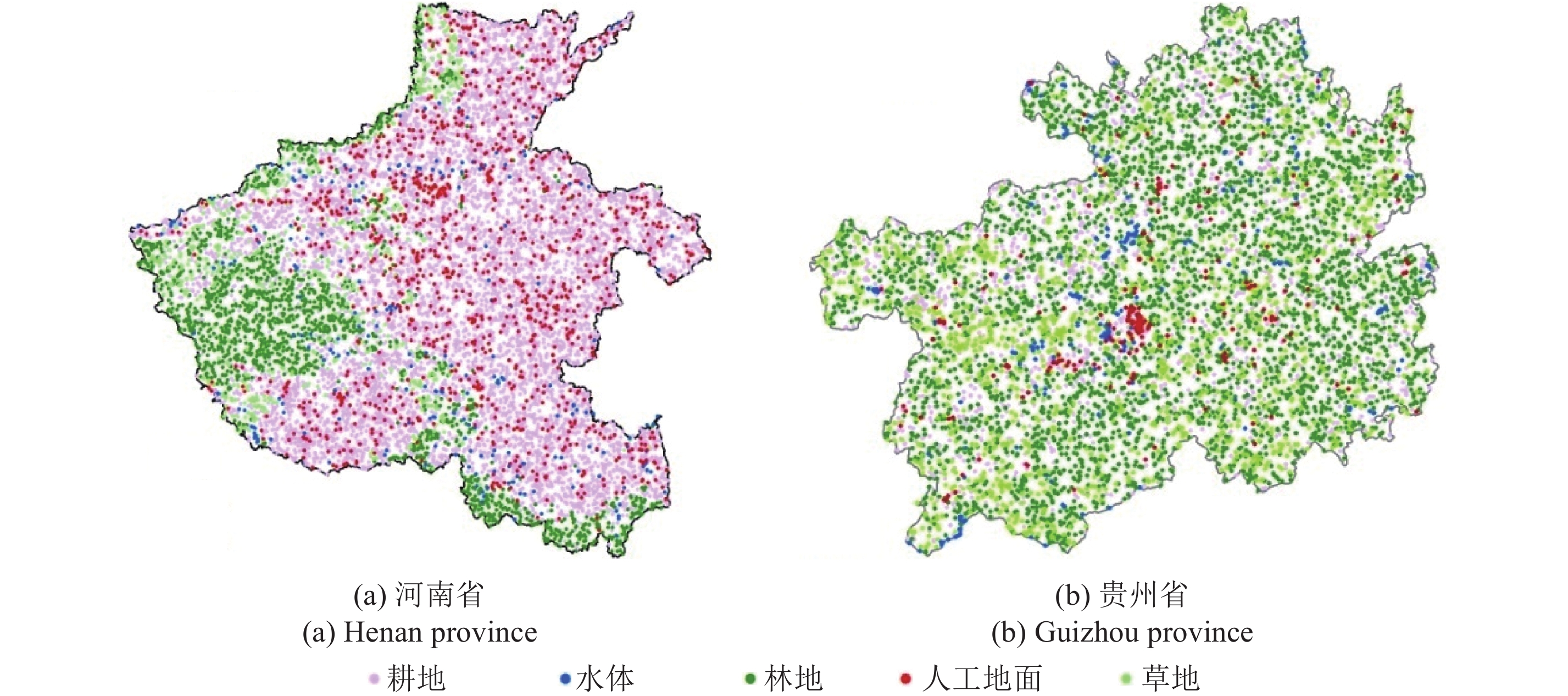
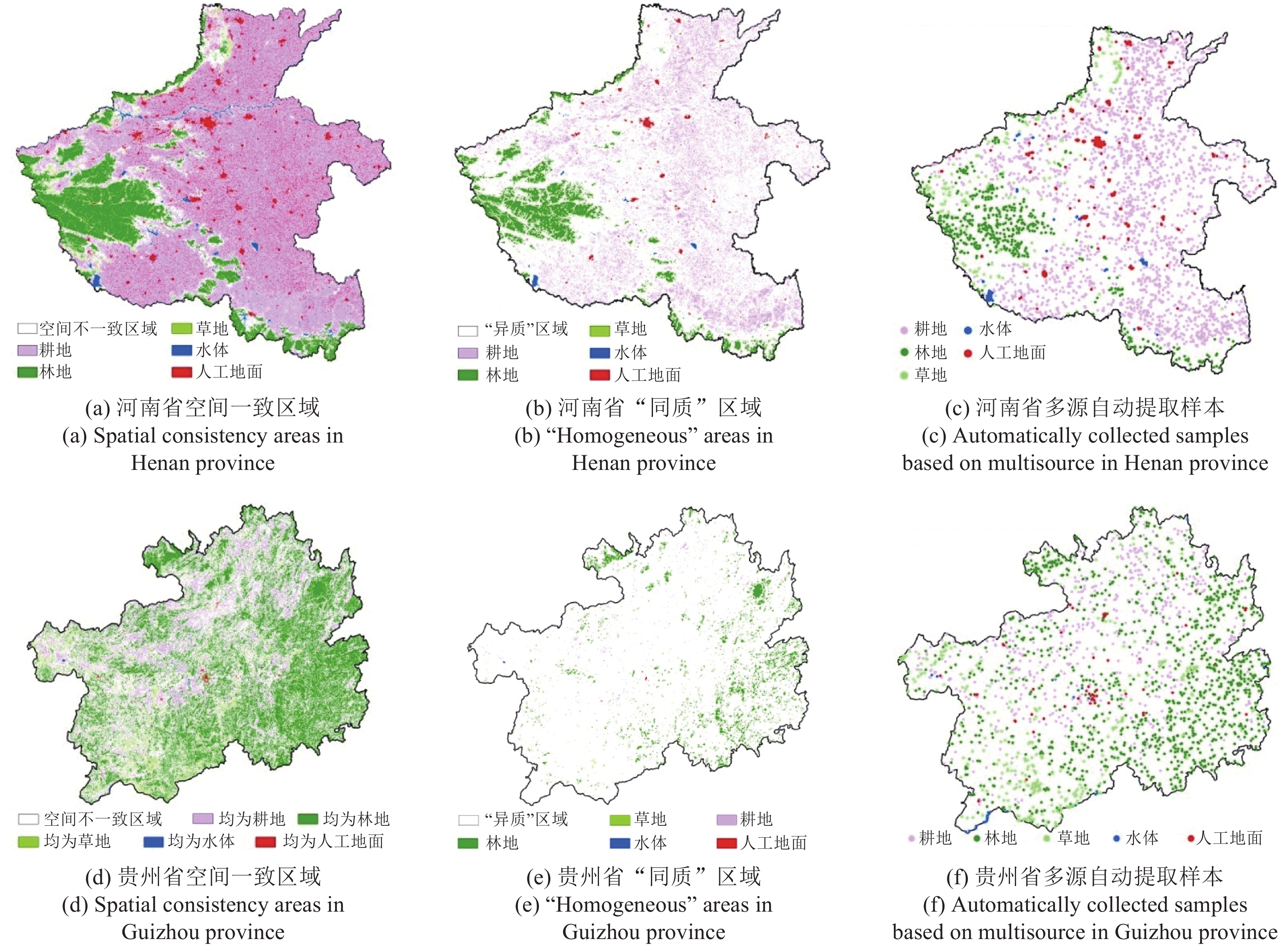
表 3 初选样本数量
Table 3 Number of initial samples
| 地类名称 | 样本像元数/个 | |
| 河南省 | 贵州省 | |
| 耕地 | 2158 | 591 |
| 林地 | 541 | 1135 |
| 草地 | 180 | 361 |
| 水体 | 77 | 118 |
| 人工地面 | 360 | 242 |
4.2 土地覆被分类样本分析
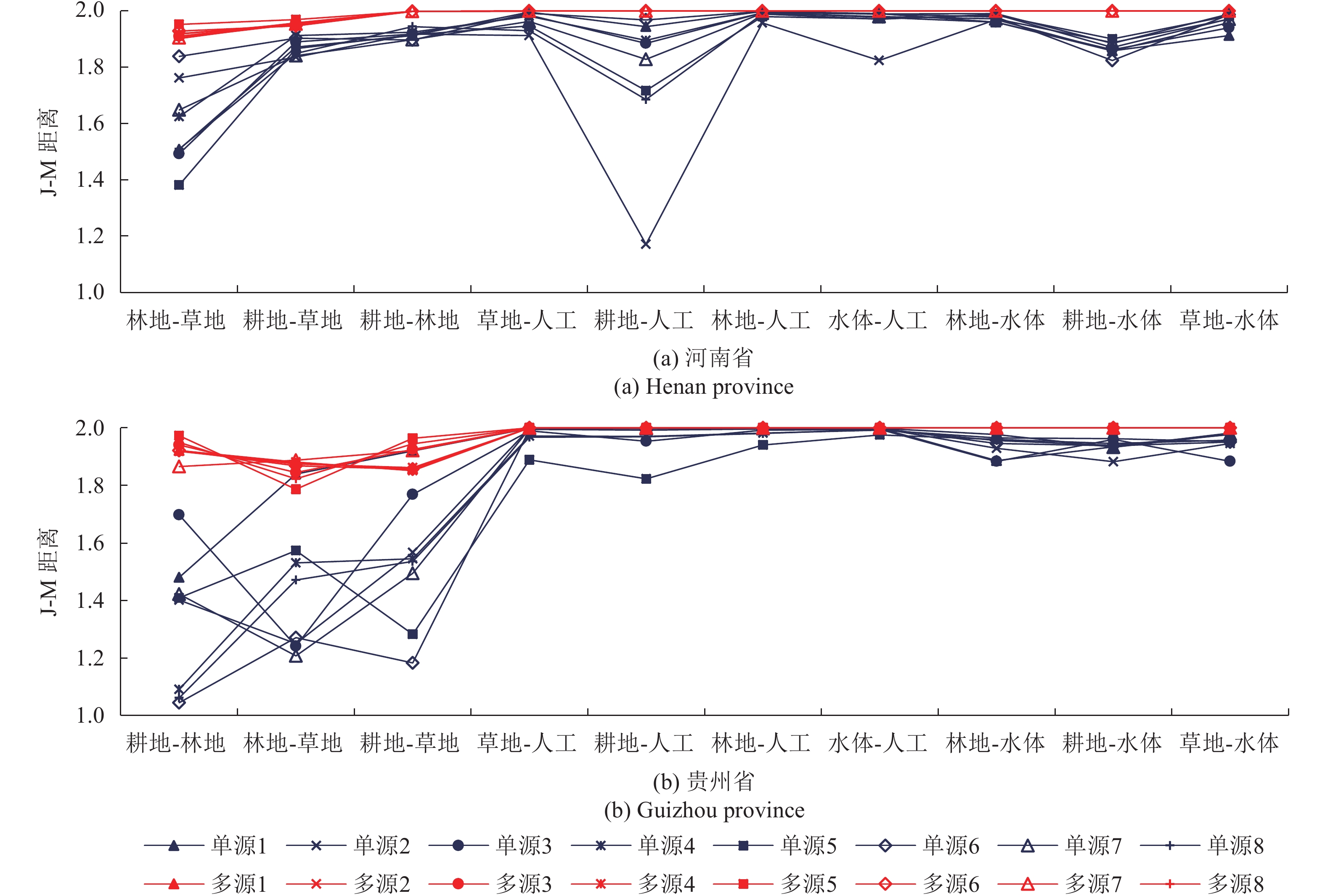
图5描述了研究区8次单源及多源样本自动提取两种方式的土地覆被分类样本特征可分性。其中,基于单源自动提取所获得土地覆被分类样本的特征可分性以蓝色描述,多源自动提取所获得土地覆被分类样本的可分性以红色描述。总体来看,多源样本分类特征可分性大于单源样本可分性,且多源样本自动提取方法所获取样本的J-M距离波动小,稳定性较高。就类别而言,单源和多源两种提取方式所获取的样本在人工–草地、人工–林地、水体–草地的分类特征可分性均较好。但多源样本在草地–林地、草地–耕地、林地–耕地、人工–耕地、水体–耕地等其他地类的分类特征可分性与单源样本相比更高。
综上,从样本分类特征可分性分析结果来看,本文设计的多源自动土地覆被分类样本提取方式样本可分性更优,且在多次采样过程中表现出较高的稳定性。
4.3 分类结果对比分析
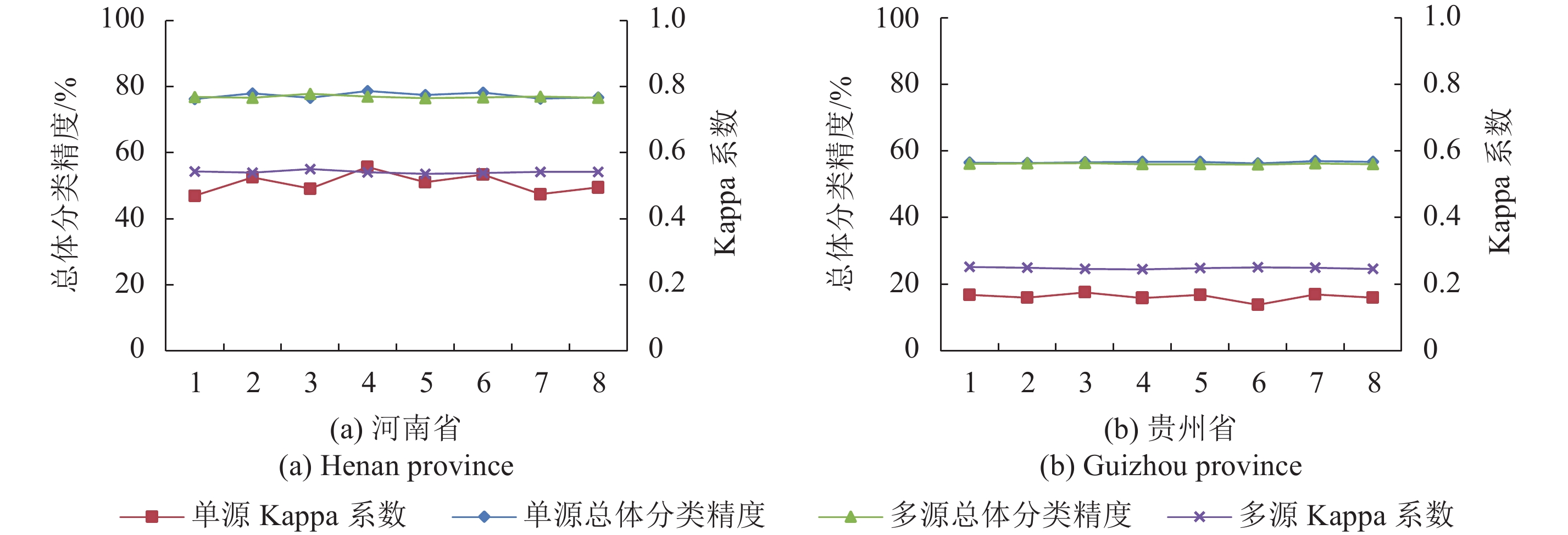
应用单源、多源8次样本提取结果完成土地覆被分类,并以目视解译制作完成的土地利用数据为参考数据,分别对基于单源样本自动提取方案和多源样本自动提取方案制作的两种土地覆被分类产品进行精度评价。两类产品总体分类精度及Kappa系数如图6。利用单源方案,获得产品的平均总体分类精度为77%(河南)、56%(贵州),Kappa系数在0.47—0.53(河南)、0.14—0.18(贵州)之间。利用多源样本自动提取方案获得分类产品的平均总体分类精度与单源方案基本相同,但是多源方案所获产品的Kappa系数在多次实验中较单源产品更高,为0.54—0.55(河南)、0.24—0.25(贵州)。并且,多源方案所获产品的Kappa系数和分类精度在多次实验中数据波动较小,两者的标准差均小于0.004,更为稳定,有利于自动化生产和后期的针对性改进。综上,本文设计的基于多源数据的土地覆被样本自动提取方法较单源提取方法更具优势。
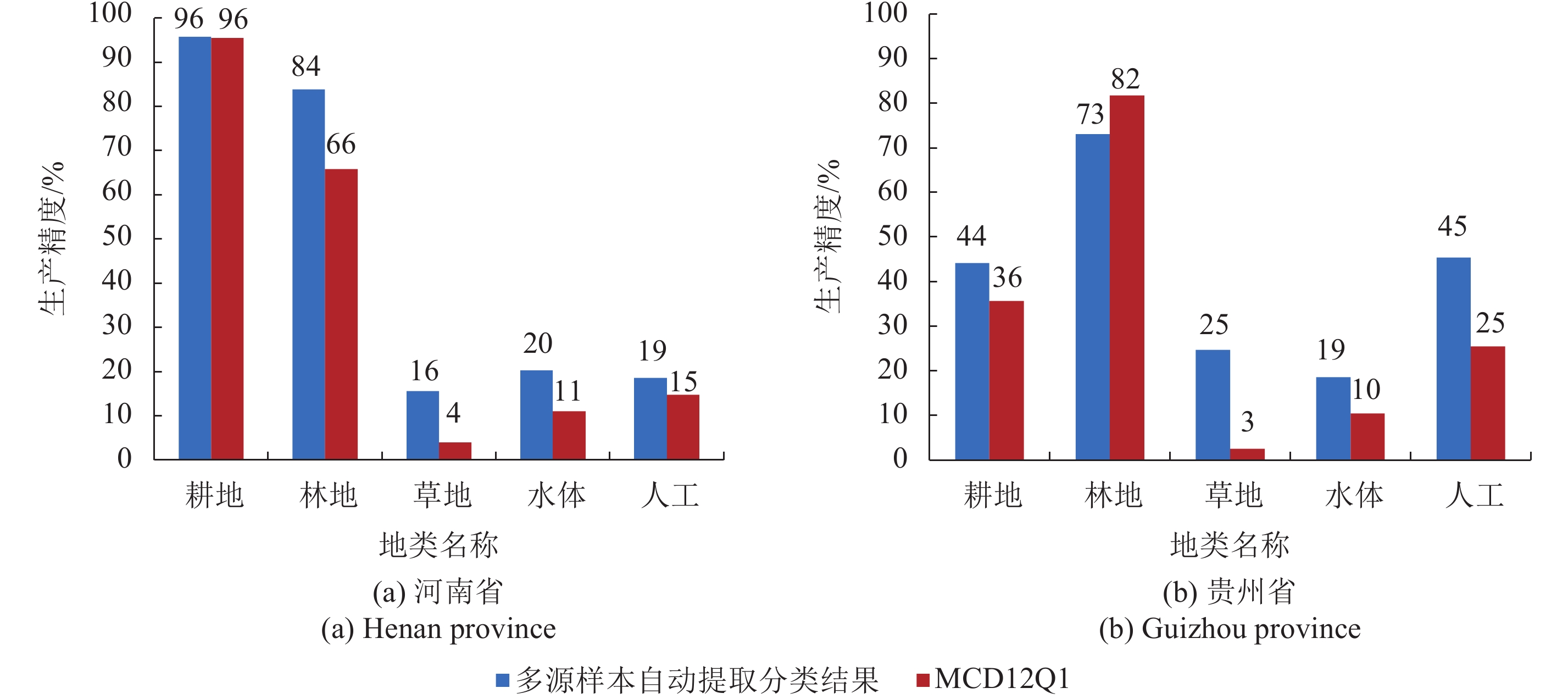
以目视解译制作完成的土地利用数据为参考数据分别对本文多源样本自动提取分类结果与全球土地覆被产品MCD12Q1两种产品进行精度分析。根据多源样本提取方案的稳定性特征,仅选择其中一次分类结果参与对比,两产品土地覆被分布情况如图7所示。
两产品均能描述出耕地、林地、人工地面和主要湖泊水体的分布情况。但在林地–耕地、林地–草地、耕地–草地的识别中存在混淆。进一步对应用本文多源样本自动提取法所获得的土地覆被分类产品和MCD12Q1的总体精度、各地类生产精度、Kappa系数进行分析,各地类生产精度如图8。多源样本自动提取分类产品的总体精度与Kappa系数(河南省为78%、0.54,贵州省为57%、0.25)高于MCD12Q1的总体精度与Kappa系数(河南省为74%、0.42,贵州省为55%、0.15)。就不同地类而言,应用多源样本自动提取法所获得土地覆被产品仅在贵州省林地的生产精度稍低于MCD12Q1,在其他地类均高于MCD12Q1。
综上,使用基于多源数据的土地覆被样本自动提取方法进行分类,具有较高的稳定性,可在保证土地覆被产品精度的同时,提升分类过程的自动化程度。

5 结 论
监督分类中训练样本的数量和质量对于分类精度有重要的影响。目前,野外实地考察及高分辨率影像目视解译是土地覆被样本获取的主要途径,但该方法成本高,耗时久,样本数量不足,存在较大的主观性。针对大尺度土地覆被分类过程中样本提取自动化不足的问题,以现有土地覆被数据为基础,提出一种基于多源历史土地覆被/利用数据的分类样本自动提取方法,并在此基础上构建了自动土地覆被分类架构。与现有土地覆被分类样本的自动提取方法相比,本文方法充分利用了多源土地覆被数据中空间一致区域具有较高分类正确置信度的特点,并通过空间异质度分析与拉依达准则减少了无效样本对分类精度的影响。
综合研究区实验结果表明:(1)应用本文多源样本自动提取方法完成土地覆被产品制作,精度稳定性高,且所获得的产品总体精度高于全球土地覆被产品MCD12Q1。(2)与传统基于单源土地覆被数据的样本提取方法相比,本文在样本提取过程中引入现有多源土地覆被数据,该方法获得的样本具有更高的可分性,有效减少仅采用单一土地覆被数据源引入的错误样本,提升样本质量。综上所述,该方法以现有多源土地覆被产品与待分类遥感影像为输入,在保证分类精度的同时,提升了土地覆被分类流程的自动化程度,能够满足大尺度范围的快速、自动土地覆被分类需求。
需要指出的是:(1)为突出核心流程,目前样本提纯采取较为简捷的拉依达准则。在后续的研究工作中,可采用更为精确的无效样本检测方法。(2)尽管本文方法总体精度高于MCD12Q1,但是两者在山地、丘陵的分类精度,都有待进一步提升。分析原因,山地、丘陵以林地、草地、耕地等植被为主,不同植被的EVI存在混淆。并且,山地、丘陵地形造成土地覆被破碎度较高,定位精度较低。以某一固定窗口大小进行异质度分析,可能导致部分有效样本丢失。在下一步研究中,可考虑结合土地覆被破碎度自动确定窗口大小,并利用面向对象技术,提取现有土地覆被产品中不同地类的纹理、形状、植被指数曲线等其他特征,指导样本自动提取,以进一步提升分类精度。(3)现有各种土地覆被/利用数据的分类系统近似但又存在差异,并未在全球甚至全国范围完成标准化,各个系统之间转换存在误差,这势必对土地覆被产品的有效应用造成影响。
参考文献(References)
-
Bruzzone L, Roli F and Serpico S B. 1995. An extension of the Jeffreys-Matusita distance to multiclass cases for feature selection. IEEE Transactions on Geoscience and Remote Sensing, 33 (6): 1318–1321. [DOI: 10.1109/36.477187]
-
Celik T. 2009. Unsupervised change detection in satellite images using principal component analysis and k-means clustering. IEEE Geoscience and Remote Sensing Letters, 6 (4): 772–776. [DOI: 10.1109/LGRS.2009.2025059]
-
Chen J, Chen J, Liao A P, Cao X, Chen L J, Chen X H, He C Y, Han G, Peng S, Lu M, Zhang W W, Tong X H and Mills J. 2015. Global land cover mapping at 30 m resolution: a POK-based operational approach. ISPRS Journal of Photogrammetry and Remote Sensing, 103 : 7–27. [DOI: 10.1016/j.isprsjprs.2014.09.002]
-
Friedl M A, Sulla-Menashe D, Tan B, Schneider A, Ramankutty N, Sibley A and Huang X M. 2010. MODIS Collection 5 global land cover: algorithm refinements and characterization of new datasets. Remote Sensing of Environment, 114 (1): 168–182. [DOI: 10.1016/j.rse.2009.08.016]
-
Ghiyamat A, Shafri H Z M, Mahdiraji G A, Shariff A R M and Mansor S. 2013. Hyperspectral discrimination of tree species with different classifications using single- and multiple-endmember. International Journal of Applied Earth Observation and Geoinformation, 23 : 177–191. [DOI: 10.1016/j.jag.2013.01.004]
-
Hou Y T, Wang S G and Nan Z T. 2011. A rule-based land cover classification method for the Heihe river basin. Acta Geographica Sinica, 66 (4): 549–561. [DOI: 10.11821/xb201104011] ( 候玉婷, 王书功, 南卓铜. 2011. 基于知识规则的土地利用/土地覆被分类方法: 以黑河流域为例. 地理学报, 66 (4): 549–561. [DOI: 10.11821/xb201104011] )
-
Huang Y B and Liao S B. 2016. Regional accuracy assessments of the first global land cover dataset at 30-meter resolution: a case study of Henan province. Geographical Research, 35 (8): 1433–1446. [DOI: 10.11821/dlyj201608003] ( 黄亚博, 廖顺宝. 2016. 首套全球 30 m分辨率土地覆被产品区域尺度精度评价: 以河南省为例. 地理研究, 35 (8): 1433–1446. [DOI: 10.11821/dlyj201608003] )
-
Jun C, Ban Y F and Li S N. 2014. China: open access to earth land-cover map. Nature, 514 (7523): 434 [DOI: 10.1038/514434c]
-
Li D R, Zhang L P and Xia G S. 2014. Automatic analysis and mining of Remote sensing big data. Acta Geodaetica et Cartographica Sinca, 43 (12): 1211–1216. [DOI: 10.13485/j.cnki.11-2089.2014.0187] ( 李德仁, 张良培, 夏桂松. 2014. 遥感大数据自动分析与数据挖掘. 测绘学报, 43 (12): 1211–1216. [DOI: 10.13485/j.cnki.11-2089.2014.0187] )
-
Liao S B and Qin Y C. 2014. A spatialization method for survey data of theoretical stock-carrying capacity of grassland in China and its application. Geographical Research, 33 (1): 179–190. [DOI: 10.11821/dlyj201401016] ( 廖顺宝, 秦耀辰. 2014. 草地理论载畜量调查数据空间化方法及应用. 地理研究, 33 (1): 179–190. [DOI: 10.11821/dlyj201401016] )
-
Liu J Y, Liu M L, Tian H Q, Zhuang D F, Zhang Z X, Zhang W, Tang X M and Deng X Z. 2005. Spatial and temporal patterns of China’s cropland during 1990-2000: an analysis based on Landsat TM data. Remote Sensing of Environment, 98 (4): 442–456. [DOI: 10.1016/j.rse.2005.08.012]
-
Liu J Y, Kuang W H, Zhang Z X, Xu X L, Qin Y W, Ning J, Zhou W C, Zhang S W, Li R D, Yan C Z, Wu S X, Shi X Z, Jiang N, Yu D S, Pan X Z and Chi W F. 2014. Spatiotemporal characteristics, patterns and causes of land use changes in China since the late 1980s. Acta Geographica Sinca, 24 (2): 3–14. [DOI: 10.11821/dlxb201401001] ( 刘纪远, 匡文慧, 张增祥, 徐新良, 秦元伟, 宁佳, 周万村, 张树文, 李仁东, 颜长珍, 吴世新, 史学正, 江南, 于东升, 潘贤章, 迟文峰. 2014. 20世纪80年代末以来中国土地利用变化的基本特征与空间格局. 地理学报, 24 (2): 3–14. [DOI: 10.11821/dlxb201401001] )
-
Liu K, Yang X M and Zhang T. 2012. Automatic selection of classified samples with the help of previous land cover data. Journal of Geo-information Science, 14 (4): 507–513. [DOI: 10.3724/SP.J.1047.2012.00507] ( 刘锟, 杨晓梅, 张涛. 2012. 前期土地覆被数据辅助下的分类样本自动选取. 地球信息科学学报, 14 (4): 507–513. [DOI: 10.3724/SP.J.1047.2012.00507] )
-
Muchoney D, Strahler A, Hodges J and Locastro J. 1999. The IGBP DISCover confidence sites and the system for terrestrial ecosystem parameterization: tools for validating global land-cover data. Photogrammetric Engineering and Remote Sensing, 65 (9): 1061–1067.
-
Padma S and Sanjeevi S. 2014. Jeffries Matusita based mixed-measure for improved spectral matching in hyperspectral image analysis. International Journal of Applied Earth Observation and Geoinformation, 32 : 138–151. [DOI: 10.1016/j.jag.2014.04.001]
-
Quinlan J R, Scepan J, Menz G, Hansen M C. 1996. Bagging, Boosting, and C4.5//Proceedings of the Thirteenth National Conference on Artificial Intelligence and the Eighth Innovative Applications of Artificial Intelligence Conference. Menlo Park, CA:American Association for Artificial Intelligence: 725–730
-
Scepan J, Menz G and Hansen M C. 1999. The DISCover validation image interpretation process. Photogrammetric Engineering and Remote Sensing, 65 (9): 1075–1081.
-
Shao Y, Lunetta R S, Wheeler B, Iiames J S and Campbell J B. 2016. An evaluation of time-series smoothing algorithms for land-cover classifications using MODIS-NDVI multi-temporal data. Remote Sensing of Environment, 174 : 258–265. [DOI: 10.1016/j.rse.2015.12.023]
-
Szantoi Z, Escobedo F J, Abd-Elrahman A, Pearlstine L, Dewitt B and Smith S. 2015. Classifying spatially heterogeneous wetland communities using machine learning algorithms and spectral and textural features. Environmental Monitoring and Assessment, 187 (5): 262 [DOI: 10.1007/s10661-015-4426-5]
-
Wen Q, Xia L G, Li L L and Wu W. 2013. Automatically samples selection in disaster emergency oriented land cover classification. Geomatics and Information Science of Wuhan University, 38 (7): 799–804. ( 温奇, 夏列钢, 李苓苓, 吴玮. 2013. 面向灾害应急土地覆被分类的样本自动选择方法研究. 武汉大学学报(信息科学版), 38 (7): 799–804. )
-
Wu T J, Luo J C, Xia L G, Yang H P, Shen Z F and Hu X D. 2014. An automatic sample collection method for object-oriented classification of remotely sensed imageries based on transfer learning. Acta Geodaetica et Cartographica Sinica, 43 (9): 908–916. [DOI: 10.13485/J.CNKI.11-2089.2014.0163] ( 吴田军, 骆剑承, 夏列钢, 杨海平, 沈占锋, 胡晓东. 2014. 迁移学习支持下的遥感影像对象级分类样本自动选择方法. 测绘学报, 43 (9): 908–916. [DOI: 10.13485/J.CNKI.11-2089.2014.0163] )
-
Wulder M A and Coops N C. 2014. Satellites: make earth observations open access. Nature, 513 (7516): 30–31. [DOI: 10.1038/513030a]
-
Yang C J and Zhou C H. 2001. Investigation on classification of remote sensing image on basis of knowledge. Geography and Territorial Research, 17 (1): 72–77. [DOI: 10.3969/j.issn.1672-0504.2001.01.016] ( 杨存建, 周成虎. 2001. 基于知识的遥感图像分类方法的探讨. 地理学与国土研究, 17 (1): 72–77. [DOI: 10.3969/j.issn.1672-0504.2001.01.016] )
-
Yu X F, Luo Y Y, Zhuang D F, Wang S K and Wang Y. 2014. Comparative analysis of land cover change detection in an Inner Mongolia grassland area. Acta Ecologica Sinica, 34 (24): 7192–7201. [DOI: 10.5846/stxb201310142468] ( 于信芳, 罗一英, 庄大方, 王世宽, 王勇. 2014. 土地覆盖变化检测方法比较: 以内蒙古草原区为例. 生态学报, 34 (24): 7192–7201. [DOI: 10.5846/stxb201310142468] )
-
Zhao Y Y, Gong P, Yu L, Hu L Y, Li X Y, Li C C, Zhang H Y, Zheng Y M, Wang J, Zhao Y C, Cheng Q, Liu C X, Liu S and Wang X Y. 2014. Towards a common validation sample set for global land-cover mapping. International Journal of Remote Sensing, 35 (13): 4795–4814. [DOI: 10.1080/01431161.2014.930202]


