

|
收稿日期: 2016-05-30; 优先数字出版日期: 2016-11-17
基金项目: 国家自然科学基金(编号:61673184,41571349,40901232);高分辨率对地观测系统重大专项
第一作者简介: 张锐豪(1991— ),男,硕士研究生,研究方向为高光谱遥感图像处理等。E-mail:
posey41@126.com
通讯作者简介: 罗文斐(1979— ),男,副教授,研究方向为高光谱遥感及其应用、高分辨遥感、遥感图像处理、高性能计算。E-mail:
luowenfei@m.scnu.edu.cn
中图分类号: TP751.1
文献标识码: A
|
摘要
双线性混合模型是近年来非线性光谱解混的研究重点之一,其克服了线性混合模型无法描述地物多重散射作用的缺陷,能够更精确地还原真实的地物光谱混合过程。然而,限于模型的复杂性,目前在缺乏准确的端元先验知识的条件下进行双线性光谱解混仍是一项具有挑战性的任务。差分进化算法(DE)是一种具有良好全局搜索能力的群智能优化算法,其优化求解过程无需进行复杂的数学推导,为双线性光谱解混问题提供了一种有效的解决途径。为此,本文以FAN双线性混合模型为例,提出了一种双种群机制的差分进化算法(记为DE-FAN),实现非监督双线性光谱解混。DE-FAN算法通过建立端元与丰度两个种群的交替进化机制寻找最优解,同时在迭代中引入自适应重构策略增强种群多样性,降低算法陷入局部最优解的风险,最终实现端元与丰度的同时估计。通过模拟图像及真实图像的解混实验进行算法检验,证明DE-FAN算法较之传统非线性解混算法具有更高的解混精度及解混效率。
关键词
高光谱遥感, 光谱解混, 双线性混合模型, 差分进化算法, 双种群机制
Abstract
Hyperspectral unmixing plays an important role in remote sensing applications by extracting the pure constituent spectra and correspondent fractions in mixing pixels. Bilinear mixing models have recently become a hot topic in nonlinear spectral unmixing research. Nevertheless, most of the existing bilinear unmixing algorithms require prior knowledge about the endmembers, which can be regarded as supervised algorithms. This paper reports on a new unsupervised unmixing algorithm based on the FAN bilinear mixing model by employing the differential evolution (DE) algorithm (i.e., DE-FAN), which can solve the bilinear unmixing problems more efficiently and accurately compare with existing unsupervised bilinear unmixing algorithms.Considering the bilinear unmixing problem with hyperspectral imagery, the proposed algorithm makes the following improvements on the standard DE algorithm. First, the mutation factor is tuned dynamically rather than fixed during the iterative process, which can significantly enhance the neighborhood search capability. Second, considering the acceleration of the convergence rate, DE-FAN constructs a double-population (i.e., endmember population and abundance population) framework such that an alternative evolution procedure is presented. Third, the population re-initialization tactic is introduced to enhance the capability of large-scale optimization. It can decrease the number of required population individuals, thus improving the computational efficiency. It can also significantly lower the trapping risk in local optimums. Finally, a cooperative co-evolution tactic is considered. The hyperspectral image is divided into several sub-images and then processed by the DE-FAN algorithm separately. The final solution of the endmember estimation can be obtained by averaging the best solutions from the sub-images. The remaining iterations can continue by fixing the endmember variables with the final endmember solution. The final solution of abundance estimation is achieved when the stopping criteria is met.We validate the DE-FAN algorithm by adopting synthetic datasets and real airborne visible/infrared imaging spectrometer images. Different endmember numbers, signal-to-noise ratios, and maximum abundances are also considered. Several state-of-the-art algorithms (i.e., MVC-NMF, SISAL+FCLS, MU-LQM, N-FINDR+CNLS, geodesic simplex volume maximization, and PG-FAN) are compared. Experimental results conducted utilizing both synthetic and real datasets indicate that the proposed DE-FAN algorithm outperforms other algorithms by obtaining more accurate endmembers and abundance.The DE-FAN algorithm overcomes the LMM shortcomings and solves the bilinear unmixing problem. The unmixing experiments demonstrate that DE-FAN can obtain more accurate results than other classical unmixing algorithms. We will consider the influence of the penalty coefficient and attempt an adaptive method in future work. We will also extend our proposed DE-FAN to more bilinear models such as the polynomial post-nonlinear model and generalized bilinear model.
Key words
hyperspectral remote sensing, spectral unmixing, bilinear mixing model, differential evolution, double-population algorithm
1 引 言
光谱解混是高光谱遥感图像分析的一项关键技术,旨在从混合像元中分离出其所包含的地物光谱信息(称为“端元提取”)及求解出这些地物在该混合像元内所占的比例(称为“丰度反演”)。
根据地物光谱混合机理的差异,光谱混合模型可分为线性混合模型及非线性混合模型。线性混合模型简单易用,在近几十年内诞生了许多经典的线性解混算法:经典的端元提取算法包括了内部最大体积法(N-FINDR)(Winter,1999)、顶点成分分析(VCA)(Nascimento和Dias,2005)等;经典的丰度反演算法包括了非负最小二乘法(NNLS)(Bro和De Jong,1997)、全约束最小二乘法(FCLS)(Heinz和Chang,2001)等。此外,经典的线性解混算法还包括了最小端元体积约束的非负矩阵分解算法(MVC-NMF)(Miao和Qi,2007)、最小端元距离约束的非负矩阵分解算法(MDC-NMF)(Yu 等,2007)等,这类算法可实现端元与丰度的同时估计,且解混时无需预知准确的端元信息,因此被称为非监督解混算法。
目前经典的非线性混合模型包括了Hapke模型(Hapke,1981)以及双线性混合模型等。双线性混合模型不仅具有与线性混合模型相似的数学形式,又可近似地反映辐射传输过程中的多重散射效应,因此这类模型具有较好的适用性。目前,主要的双线性混合模型包括了Nascimento模型(Nascimento和Bioucas-Dias,2009)、FAN模型(Fan 等,2009)、Generalized Bilinear Model(GBM)模型(Halimi 等,2011)、Polynomial Post Nonlinear Model(PPNM)模型(Altmann 等,2012)及Linear-Quadratic Model(LQM)模型(Meganem 等,2014a)等。其中,FAN模型是最基础且应用较多的双线性混合模型(Chakravortty 等,2014;Eches和Guillaume,2014),GBM模型与PPNM模型均可视为FAN模型的推广。
在双线性解混算法方面,经典的监督双线性解混算法包括了约束非线性最小二乘法(CNLS)(Pu 等,2015)、基于多核学习的Super Kernel-Hype(SK-Hype)算法(Chen 等,2013)等。然而,在现实应用中通常难以预知准确的端元信息,因此非监督解混算法具有重要的研究意义。目前,经典的非监督双线性解混算法主要有FAN模型下的投影梯度算法(PG-FAN)(Eches和Guillaume,2014)以及PPNM模型下的混合蒙特卡洛算法(HMC-PPNM)(Altmann 等,2014)。然而,梯度算法容易陷入局部最优解(张贤达,2004;);而HMC算法则存在计算效率低下的瓶颈问题。
差分进化算法(DE)是一种简单高效的启发式全局搜索算法(Storn和Price,1995),可避免传统数值优化算法复杂的数学推导,能以较高的概率寻得全局最优解(Price 等,2005;Kitayama等,2011)。近年来已有学者将DE算法应用于非监督线性光谱解混,并取得了比传统算法更好的解混效果(Zhong 等, 2014;覃事银 等,2015)。为此,本文将DE算法推广应用于非监督双线性解混问题,以FAN模型为例提出了一种双种群机制下的差分进化光谱解混算法(DE-FAN)。
2 FAN双线性混合模型与解混问题
根据FAN模型的假设,每个混合像元可以表示为
| $\begin{aligned}& {{x = }}\sum\limits_{m = 1}^M {{a_m}{{e}_m} + \sum\limits_{m = 1}^{M - 1} {\sum\limits_{k = m + 1}^M {{a_m}{{e}_k}{{e}_m} \cdot {{e}_k}} } } \\& {\rm{s}}{\rm{.t}}{\rm{.}}\sum\limits_{m = 1}^M {{a_m} = 1,0 \leqslant } {a_m} \leqslant 1\end{aligned}$ | (1) |
式中,M为端元数,
em
为端元向量,am
为相应的丰度值。令端元矩阵记为
E
=[
e
1,
e
2,
| $\begin{aligned}& {{E}_b} = \left[ {{{e}_1} \cdot {{e}_2},{{e}_1} \cdot {{e}_3}, \cdots ,{{e}_{M - 1}} \cdot {{e}_M}} \right]\\ & {{A}_b} = \left[ {{A}_1^r \cdot {A}_2^r;{A}_1^r \cdot {A}_3^r; \cdots ;{A}_{M - 1}^r \cdot {A}_M^r} \right]\end{aligned}$ | (2) |
式中, Air 表示 A 的第i行。令 E *=[ E , Eb ]以及 A *=[ A ; Ab ],则可得到目标函数:
| $f\left( {{E},{A}} \right) = {\left\| {{X} - {{E}^*}{{A}^*}} \right\|_{\rm{F}}}$ | (3) |
式中,|| ·||F表示Frobenius范数。
3 DE光谱解混算法
3.1 DE算法基础
DE算法采用实值编码,主要包含种群变异、种群交叉、种群选择等3个步骤以及缩放因子F、交叉概率CR、种群个体数S等3个参数(Storn和Price,1995)。
种群变异是指通过原始种群个体子集的线性组合生成新的种群个体,由此产生变异种群。其中,DE/rand/1是最为经典的变异策略。
种群交叉用于控制变异种群中包含原始种群信息的量,由此产生候选种群。其中,二项交叉策略是最为常用的交叉策略。
种群选择用于产生进入下一次迭代的新种群,选择的对象为原始种群及种群交叉产生的候选种群。其中,贪婪选择策略是最为常用的选择策略,其保证了种群中适应度更优的个体进入下一次迭代。
为了克服经典DE算法求解高维优化问题时面临的算法收敛缓慢、计算效率低等问题,本文首先在经典DE算法的框架上建立双种群交替进化寻优机制;同时,在双种群机制的基础上引入了种群重构策略以及图像分块策略以进一步提高算法的高维优化能力。
3.2 双种群DE算法框架
为了同时进行端元与丰度的估计,本文引入了双种群交替进化寻优机制,同时沿用经典DE算法的实值向量编码方式,将端元种群和丰度种群的个体分别编码为
| ${E}{{I}_i} = \left[ {{{e}_1};{{e}_2}; \cdots ;{{e}_M}} \right],{A}{{I}_i} = \left[ {{{a}_1};{{a}_2}; \cdots ;{{a}_N}} \right]$ | (4) |
在种群变异步骤中,为了加快算法的收敛速率,本文采取了DE/target-to-best/1变异策略(Vester-strøm和Thomsen,2004);对于原始端元种群与原始丰度种群中的个体 EIi , AIi ,其对应的变异种群个体 EIi* , AIi* 按如下公式产生:
| $\begin{array}{l}{{EI}}_i^* = {{E}}{{I}_i} + F \cdot \left( {{E}}{{I}_{r1}} - {{E}}{{I}_{r2}} \right) + F \cdot \left( {{E}}{{I}_{\rm{best}}} - {{E}}{{I}_i} \right)\\{{AI}}_i^* = {A}{{I}_i} + F \cdot \left( {A}{{I}_{r1}} - {A}{{I}_{r2}} \right) + F \cdot \left( {A}{{I}_{\rm{best}}} - {A}{{I}_i} \right)\end{array}$ | (5) |
式中,F为缩放因子, EI best, AI best为原始种群中的最优个体, EI r1, EI r2, AI r1, AI r2为原始种群中随机抽取的个体。
在种群交叉步骤中,本文沿用了经典DE算法中的二项交叉策略(Storn和Price,1995);对于丰度种群的个体,由于“和为1”约束的存在,同一像元内的丰度分量并非完全独立,因此丰度种群在交叉进化时以像元为单位进行:候选丰度种群的第i个个体第j个像元的丰度分量
| $ \widehat{{AI}_i}\left( {{{a}_j}} \right) = \left\{ \begin{array}{l}{A}{{I}_i}\left( {{{a}_j}} \right),rand > CR\\{{AI}}_i^*\left( {{{a}_j}} \right),rand \leqslant CR\end{array} \right.$ | (6) |
式中,
AIi
(
aj
),
AIi*
(
aj
)分别为原始丰度种群与变异丰度种群中相应的个体及分量。由于本算法在进化中不考虑光谱相关性,因此直接对端元种群个体的各分量采取二项交叉策略:候选端元种群的第i个个体第j个分量
| $ \widehat{{EI}_{ij}} = \left\{ \begin{array}{l}{E}{{I}_{ij}},rand > CR\\{{EI}}_{ij}^*,rand \leqslant CR\end{array} \right.$ | (7) |
式中, EIij , EIij* 分别为原始端元种群与变异端元种群中相应的个体及分量。
在种群选择步骤中,本文采用了双种群交替贪婪选择策略,为了便于描述,此处暂且以种群个体为单位阐释该策略:新端元种群以及新丰度种群的第i个个体 EIi New, AIi New分别按如下公式产生:
| ${{EI}}_i^{{\rm{New}}} = \left\{ \begin{array}{l}{E}{{I}_i},f\left( {{E}{{I}_i},{A}{{I}_i}} \right) < f\left( {{\widehat {{EI}}_i},{A}{{I}_i}} \right)\\{\widehat {{EI}}_i},f\left( {{E}{{I}_i},{A}{{I}_i}} \right) \geqslant f\left( {{\widehat {{EI}}_i},{A}{{I}_i}} \right)\end{array} \right.$ | (8) |
| ${{AI}}_i^{{\rm{New}}} = \left\{ \begin{array}{l}{A}{{I}_i},f\left( {{{EI}}_i^{{\rm{New}}},{A}{{I}_i}} \right) < f\left( {{{EI}}_i^{{\rm{New}}},{\widehat {{AI}}_i}} \right)\\{\widehat {{AI}}_i},f\left( {{{EI}}_i^{{\rm{New}}},{A}{{I}_i}} \right) \geqslant f\left( {{{EI}}_i^{{\rm{New}}},{\widehat {{AI}}_i}} \right)\end{array} \right.$ | (9) |
式中,
EIi
,
在上述步骤中,端元种群的选择步骤(式(8))可拓展为逐个端元分量选择的方式;具体而言,即固定丰度种群 AI ,先从候选端元种群中抽离出一个端元分量嵌入并替换原始端元种群中相应的端元分量,计算嵌入前后种群个体适应度的变化,根据贪婪选择策略完成该端元分量的更新,然后重复上述嵌入过程直至所有端元分量更新完毕;这种策略可以提高算法进行多端元解混时的精度及稳定性。
在种群进化时,还需要保证种群个体的各个分量都满足相应的约束。对于越界的端元种群个体或丰度种群个体的分量 EIij , AIij ,本文采用的边界控制方法为(Altmann 等,2014):
| $\begin{aligned}{E}{{I}_{ij}} = \left\{ \begin{array}{l} - {E}{{I}_{ij}},{E}{{I}_{ij}} < 0\\2 - {E}{{I}_{ij}},{E}{{I}_{ij}} > 1\end{array} \right.\\{A}{{I}_{ij}} = \left\{ \begin{array}{l} - {A}{{I}_{ij}},{A}{{I}_{ij}} < 0\\2 - {A}{{I}_{ij}},{A}{{I}_{ij}} > 1\end{array} \right.\end{aligned}$ | (10) |
同时,对于丰度种群个体中第j个像元的丰度分量 aj ,本文采用 aj = aj / aj T IM 方式完成丰度“和为1”约束处理。
3.3 种群重构
本文引入了种群重构策略(Mendes和Mohais,2005)以进一步提高算法的全局搜索能力,其原理是种群经过一段时间(重构周期)的迭代后,围绕当前种群中的最优个体按正态分布原理随机生成新的种群个体 EIi , AIi ,并替代旧种群,即:
| $\begin{array}{l}{E}{{I}_{i}} = {E}{{I}_{{\rm{best}}}} + N\left( {{{0}},diag\left( {{{{r}}_E}} \right)} \right)\\{A}{{I}_{i}} = {A}{{I}_{{\rm{best}}}} + N\left( {{{0}},diag\left( {{{{r}}_A}} \right)} \right)\end{array}$ | (11) |
式中, rE , rA 为围绕最优个体各分量重构的方差向量,或称重构半径。为了避免固定取值可能带来的缺陷,本文设置了重构区间[rmin,rmax],根据当前种群最优个体的端元分量和像元丰度分量 ei (t), ai (t)在过去100次迭代中的变化量(Giacobini 等,2007)在重构区间内计算其相应的重构半径:
| $\begin{array}{l}\Delta {{e}_i} = \sqrt {{{\left( {{{e}_i}^{\left( t \right)} - {{e}_i}^{\left( {t - 100} \right)}} \right)}^{\rm{T}}}\left( {{{e}_i}^{\left( t \right)} - {{e}_i}^{\left( {t - 100} \right)}} \right)} \\\Delta {{a}_i} = \sqrt {{{\left( {{{a}_i}^{\left( t \right)} - {{a}_i}^{\left( {t - 100} \right)}} \right)}^{\rm{T}}}\left( {{{a}_i}^{\left( t \right)} - {{a}_i}^{\left( {t - 100} \right)}} \right)} \end{array}$ | (12) |
| $\begin{array}{l}\Delta {{E = }}\left[ {\Delta {{e}_1},\Delta {{e}_2}, \cdots ,\Delta {{e}_M}} \right]\\\Delta {{A = }}\left[ {\Delta {{a}_1},\Delta {{a}_2}, \cdots ,\Delta {{a}_N}} \right]\end{array}$ | (13) |
| $\begin{array}{l}{{{r}}_{{e}_i}} = {r_{\min }} + \displaystyle \frac{{\bf{max}\left( {\Delta {E}} \right) - \Delta {{e}_i}}}{{\bf{max}\left( {\Delta {E}} \right) - \bf{min}\left( {\Delta {E}} \right)}}\left( {{r_{\max }} - {r_{\min }}} \right)\\{{{r}}_{{{a}_i}}} = {r_{\min }} + \displaystyle \frac{{\bf{max}\left( {\Delta {A}} \right) - \Delta {{a}_i}}}{{\bf{max}\left( {\Delta {A}} \right) - \bf{min}\left( {\Delta {A}} \right)}}\left( {{r_{\max }} - {r_{\min }}} \right)\end{array}$ | (14) |
式中, ei (t-100), ai (t-100)为上一重构周期的最优个体中相应的端元分量与像元丰度分量,Δ ei ,Δ ai 为相应的变化量。
3.4 图像分块
为了进一步提高算法优化求解的稳定性,借鉴Differential Evolution Cooperative Coevolution-I(DECC-I)与Differential Evolution Cooperative Coevolution-II(DECC-II)(Yang 等,2008)算法的思想,引入了图像分块策略:将待解混图像按不放回随机抽样方式分割成若干个大小相同或相近且不存在重合的图像子块,各子块独立迭代进化求解。为兼顾图像的全局信息,迭代结束后求取各个子块端元种群最优个体的均值作为最终的全局端元解,并继续对丰度种群进行优化求解,将原先各个子块的丰度解归并到全局端元解下。
综上所述,本文提出了可实现FAN模型非监督光谱解混的双种群差分进化算法,图1为该算法的完整流程。
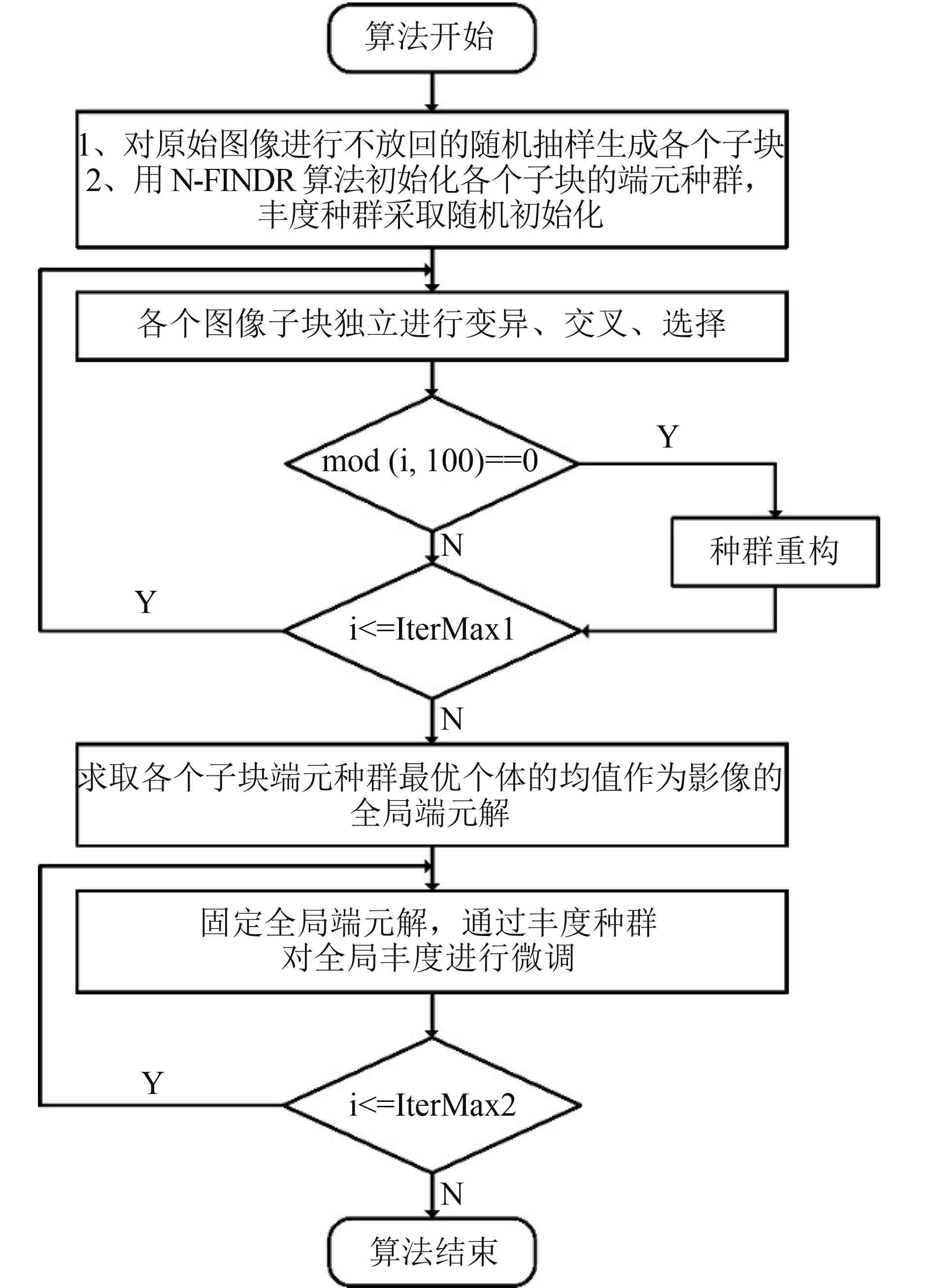

4 实验与结果分析
本文使用DE-FAN算法对包含不同端元数(M)、不同信噪比(SNR)、不同最大丰度(MaxA)的模拟图像以及两幅真实图像进行解混,并与以下6个算法进行对比:(1)MVC-NMF算法(Miao和Qi,2007);(2)Simplex Identification via Split Augmented Lagrangian(SISAL)(Bioucas-Dias,2009)+FCLS(Heinz和Chang,2001)算法;(3)N-FINDR(Winter,1999)+CNLS(Pu 等,2015)算法(4)LQM模型下的乘法更新算法(MU-LQM)(Meganem 等,2014b)算法(5)测地单形体体积最大算法(下文以Heylen指代)(Heylen 等,2011);(6)PG-FAN算法(Eches和Guillaume,2014)。
实验中,MVC-NMF算法、PG-FAN算法、MU-LQM算法以及DE-FAN算法均采用N-FINDR+FCLS算法进行端元解与丰度解的初始化;而Heylen算法、SISAL+FCLS算法与N-FINDR+CNLS算法均包含了独立的端元提取以及丰度反演过程,因此不进行额外的初始化。
为了评价解混结果,本文采用了以下4个精度指标:
(1) 光谱角距离(单位:度):
| ${\rm{SAD = co}}{{\rm{s}}^{ - 1}}\left( {\frac{{{e}_{{\rm{true}}}^{\rm{T}}{{e}_{{\rm{est}}}}}}{{\left\| {{{e}_{{\rm{true}}}}} \right\|\left\| {{{e}_{{\rm{est}}}}} \right\|}}} \right)$ | (15) |
(2) 光谱距离:
| ${\rm{SD = }}{\left\| {{{e}_{{\rm{true}}}} - {{e}_{{\rm{est}}}}} \right\|_2}$ | (16) |
(3) 丰度均方根误差:
| ${\rm{A\_RMSE = }}\sqrt {\frac{{\left\| {{{A}_{{\rm{true}}}} - {{A}_{{\rm{est}}}}} \right\|_{\rm{F}}^2}}{{MN}}} $ | (17) |
(4) 图像重构均方根误差:
| ${\rm{RMSE = }}\sqrt {\frac{{\left\| {{{{X}}_{{\rm{true}}}} - {E}_{{\rm{est}}}^*{A}_{{\rm{est}}}^*} \right\|_{\rm{F}}^2}}{{BN}}} $ | (18) |
式中, X true为原始图像, e true, e est分别为真实的端元与所估计的端元, A true, A est分别为真实的丰度矩阵与所估计的丰度矩阵, E true*, W est*分别为FAN双线性混合后的端元矩阵与丰度矩阵。
4.1 模拟图像实验
以下实验中模拟图像的生成方法为:从United States Geological Survey(USGS)光谱库(Clark 等,2007)中选择若干条光谱,随机生成满足实验条件的丰度向量,进而根据式(1)随机生成模拟图像,模拟图像的大小均为2500个像元,解混时模拟图像的端元数都假设为已知条件。
4.1.1 参数设置
本节所采用的参数设置均为经过了大量光谱解混实验所得的最优设置,但由于篇幅所限,对于部分可找到参考依据的设置,下文将不再列出实验对比结果,而仅给出相应的参考文献,具体设置如下:
对于种群个体数,参考文献(Storn和Price,1995)中的设置,本文将其设置为S=10。
对于缩放因子F,本文采用了随机向量取值策略(Mendes和Mohais,2005):
| $F = rand \left( {length\left( {{{{y}}_i}} \right),1} \right)$ | (19) |
对交叉概率CR,参考文献(Mendes和Mohais,2005;Das和Suganthan,2011)中的设置,本文将其设置为:CR=0.5。
对于图像子块大小P以及种群重构区间[rmin,rmax],本文通过包含了5个端元,最大丰度为0.8并加入了20 db高斯噪声的模拟图像解混实验获取其最优设置。由于参数组合方式较多,本文限于篇幅原因只列出部分参数组合下的解混结果,表1、表2分别为DE-FAN算法在设置不同图像子块大小以及不同重构区间条件下的解混精度比较,可见当P=100、[rmin,rmax]=[10–6,10–3]时解混精度较高;因此,在后续实验中均采用上述设置。
表 1 不同图像子块大小条件下解混精度比较
Table 1 Results comparison in terms of different subimage size
| 子块大小 | |||||
| 50 | 100 | 250 | 500 | 2500 | |
| SAD | 2.6795 | 2.8761 | 3.0233 | 3.6176 | 5.8506 |
| SD | 0.5074 | 0.4932 | 0.4994 | 0.5811 | 0.7663 |
| A_RMSE | 0.0909 | 0.0895 | 0.0906 | 0.1068 | 0.1258 |
| RMSE | 0.0160 | 0.0159 | 0.0163 | 0.0205 | 0.0272 |
| 注:[γmin,γmax]=[10–6,10–3]。 | |||||
表 2 不同重构区间条件下解混精度比较
Table 2 Results comparison in terms of different re-initialization intervals
| 重构区间(10^) | |||||||||||||||
| [–6, –5] | [–6, –4] | [–6, –3] | [–6, –2] | [–6, –1] | [–5, –4] | [–5, –3] | [–5, –2] | [–5, –1] | [–4, –3] | [–4, –2] | [–4, –1] | [–3, –2] | [–3, –1] | [–2, –1] | |
| SAD | 2.9982 | 2.8241 | 2.8761 | 3.5853 | 8.7130 | 3.2207 | 3.2059 | 4.0114 | 7.6742 | 3.8519 | 3.2003 | 6.5170 | 4.2172 | 7.4401 | 7.8714 |
| SD | 0.5409 | 0.5121 | 0.4932 | 0.5663 | 1.1327 | 0.5360 | 0.5291 | 0.6532 | 1.2515 | 0.5799 | 0.5760 | 1.1203 | 0.7280 | 1.2268 | 1.4448 |
| A_RMSE | 0.0930 | 0.0903 | 0.0895 | 0.0941 | 0.1307 | 0.0918 | 0.0905 | 0.1102 | 0.1254 | 0.0965 | 0.0933 | 0.1195 | 0.1045 | 0.1211 | 0.1352 |
| RMSE | 0.0157 | 0.0161 | 0.0159 | 0.0172 | 0.0398 | 0.0157 | 0.0164 | 0.0171 | 0.0349 | 0.0168 | 0.0169 | 0.0289 | 0.0185 | 0.0308 | 0.0338 |
| 注:图像子块大小P=100。 | |||||||||||||||
此外,算法中端元全局求解的最大迭代次数为10000,丰度全局求解的最大迭代次数为5000。
4.1.2 不同端元数目图像解混效果评价
各幅模拟图像的端元数目分别设置为3、5、7、9,最大丰度均设置为0.8并加入20 db的高斯噪声。表3、表4分别为本实验中端元提取与丰度反演的精度统计,可见DE-FAN算法在各项精度指标上均优于其他算法。其中,DE-FAN算法最显著的优势体现在端元的求解精度上,这也说明采用图像分块策略求解得到的全局端元解可以更好地逼近真实端元。
表 3 不同端元数目模拟图像的端元提取结果
Table 3 Endmember results for the synthetic datasets with different endmember numbers
| 端元数 | MVC-NMF | SISAL+FCLS | Heylen | N-FINDR+CNLS | MU-LQM | PG-FAN | DE-FAN | |||||||||||||
| SAD | SD | SAD | SD | SAD | SD | SAD | SD | SAD | SD | SAD | SD | SAD | SD | |||||||
| 3端元 | 2.6184 | 1.2205 | 5.3235 | 1.7572 | 13.6673 | 2.0092 | 7.6598 | 1.5218 | 6.9096 | 1.9864 | 4.6462 | 1.2119 | 1.3474 | 0.3226 | ||||||
| 5端元 | 4.5635 | 1.4563 | 12.2278 | 2.8139 | 14.4073 | 2.1107 | 5.2549 | 1.0450 | 9.5779 | 1.5261 | 5.0229 | 0.8916 | 2.8761 | 0.4932 | ||||||
| 7端元 | 9.3772 | 2.5300 | 23.6321 | 3.8794 | 15.1262 | 2.2352 | 5.5171 | 0.9196 | 7.6671 | 1.6223 | 3.8078 | 0.7882 | 2.5537 | 0.3583 | ||||||
| 9端元 | 14.4184 | 2.4485 | 34.6991 | 4.7789 | 17.4364 | 2.3342 | 5.7865 | 0.9896 | 11.9914 | 1.5772 | 7.6444 | 1.0165 | 4.8396 | 0.5061 | ||||||
| 注:N=2500,SNR=20 db,最大丰度:0.8。 | ||||||||||||||||||||
表 4 不同端元数目模拟图像的丰度反演结果
Table 4 Abundance results for the synthetic datasets with different endmember numbers
| 端元数 | MVC-NMF | SISAL+FCLS | Heylen | N-FINDR+CNLS | MU-LQM | PG-FAN | DE-FAN | |||||||||||||
| A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | |||||||
| 3端元 | 0.0342 | 0.0112 | 0.0456 | 0.0609 | 0.1082 | 0.2071 | 0.0787 | 0.0305 | 0.0686 | 0.0454 | 0.0729 | 0.0121 | 0.0247 | 0.0104 | ||||||
| 5端元 | 0.1324 | 0.1707 | 0.1125 | 0.1647 | 0.2992 | 0.6589 | 0.1427 | 0.0260 | 0.1591 | 0.0467 | 0.1428 | 0.0173 | 0.0895 | 0.0159 | ||||||
| 7端元 | 0.1047 | 0.0213 | 0.0789 | 0.1733 | 0.2205 | 0.4949 | 0.0792 | 0.0241 | 0.0702 | 0.0535 | 0.0704 | 0.0193 | 0.0639 | 0.0179 | ||||||
| 9端元 | 0.1053 | 0.1087 | 0.0921 | 0.2213 | 0.1819 | 0.5743 | 0.0810 | 0.0212 | 0.1110 | 0.0837 | 0.1174 | 0.1573 | 0.0882 | 0.0191 | ||||||
| 注:N=2500,SNR=20 db,最大丰度:0.8。 | ||||||||||||||||||||
DE-FAN算法随着端元数增加解混精度也有一定的下滑,原因是端元数的增加导致了待求解变量增加,同时也意味着目标函数中二阶混合项大幅增加,这也加大了算法的求解难度。
4.1.3 不同信噪比图像解混效果评价
各幅模拟图像均包含5个端元,最大丰度均设置为0.8并分别加入20 db、30 db、50 db、Inf db的高斯噪声。表5、表6分别为本实验中端元提取与丰度反演的精度统计,可见DE-FAN算法对于不同信噪比图像的解混效果整体上优于其他算法;除了对于20 db的模拟图像的解混精度有一定下滑外,算法对于30 db、50 db、Inf db的模拟图像的解混精度相近,说明DE-FAN算法对于噪声具有良好的鲁棒性;综合参考表1中DE-FAN算法在不同图像子块大小条件下的解混精度:当算法不采用图像分块策略(P=2500)时,DE-FAN算法的解混精度在总体上也优于文中其他对比算法,而引入图像分块策略后解混精度有了进一步提升。可知除了DE-FAN算法内在的寻优机制具有较好的鲁棒性外(Vesterstrøm和Thomsen,2004;Luukka和Lampinen,2011),图像分块策略对增强算法的鲁棒性也有一定的作用。值得说明的是,在50 db和Inf db情况下,虽然MVC-NMF算法能够获得最小的RMSE,但是实际提取的端元和丰度精度都不如DE-FAN算法,这说明DE-FAN算法能够获得更匹配的解。
表 5 不同信噪比模拟图像的端元提取结果
Table 5 Endmember results for the synthetic datasets with different SNR
| 信噪比 /db | MVC-NMF | SISAL+FCLS | Heylen | N-FINDR+CNLS | MU-LQM | PG-FAN | DE-FAN | |||||||||||||
| SAD | SD | SAD | SD | SAD | SD | SAD | SD | SAD | SD | SAD | SD | SAD | SD | |||||||
| 20 | 4.5635 | 1.4563 | 12.2278 | 2.8139 | 14.4073 | 2.1107 | 5.2549 | 1.0450 | 9.5779 | 1.5261 | 5.0229 | 0.8916 | 2.8761 | 0.4932 | ||||||
| 30 | 4.2203 | 1.3869 | 9.0634 | 2.2854 | 7.1706 | 1.3740 | 4.9263 | 0.8272 | 8.5647 | 1.4606 | 3.5106 | 0.8395 | 1.8847 | 0.3207 | ||||||
| 50 | 3.5555 | 1.3151 | 8.1660 | 2.2455 | 6.8407 | 1.0466 | 5.2858 | 0.9048 | 8.0897 | 1.5104 | 4.5482 | 1.0721 | 1.7956 | 0.3062 | ||||||
| Inf | 3.5047 | 1.3025 | 7.9950 | 2.2104 | 6.6969 | 1.3568 | 6.6338 | 1.3574 | 8.6579 | 1.5372 | 3.6713 | 0.8294 | 1.8368 | 0.3033 | ||||||
| 注:M=5,N=2500,最大丰度:0.8。 | ||||||||||||||||||||
表 6 不同信噪比模拟图像的丰度反演结果
Table 6 Abundance results for the synthetic datasets with different SNR
| 信噪比/db | MVC-NMF | SISAL+FCLS | Heylen | N-FINDR+CNLS | MU-LQM | PG-FAN | DE-FAN | |||||||||||||
| A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | |||||||
| 20 | 0.1324 | 0.1707 | 0.1125 | 0.1647 | 0.2992 | 0.6589 | 0.1427 | 0.0260 | 0.1591 | 0.0467 | 0.1428 | 0.0173 | 0.0895 | 0.0159 | ||||||
| 30 | 0.0818 | 0.0099 | 0.1071 | 0.2101 | 0.1217 | 0.2636 | 0.0907 | 0.0178 | 0.1555 | 0.0330 | 0.0895 | 0.0099 | 0.0612 | 0.0097 | ||||||
| 50 | 0.0653 | 0.0073 | 0.1087 | 0.2149 | 0.3146 | 0.6433 | 0.0824 | 0.0200 | 0.1523 | 0.0297 | 0.1179 | 0.0098 | 0.0641 | 0.0090 | ||||||
| Inf | 0.0645 | 0.0073 | 0.1082 | 0.2142 | 0.2907 | 0.4637 | 0.1052 | 0.0375 | 0.1559 | 0.0304 | 0.1021 | 0.0096 | 0.0578 | 0.0082 | ||||||
| 注:M=5,N=2500,最大丰度:0.8。 | ||||||||||||||||||||
4.1.4 不同最大丰度数据解混效果的评价与分析
各模拟图像均包含5个端元以及加入了20 db的高斯噪声,最大丰度分别设置为0.6、0.7、0.8、0.9。表7、表8分别为端元提取与丰度反演的精度统计,可见DE-FAN算法对于不同最大丰度的模拟图像的解混效果整体上优于其他6个算法;在最大丰度为0.9时,PG-FAN算法对端元和丰度的反演精度也接近于DE-FAN算法,但在其余最大丰度条件下的解混精度则与DE-FAN算法存在较大的差距,这说明DE-FAN算法的解混质量对于初始解质量的依赖性优于PG-FAN算法。
表 7 不同最大丰度模拟图像的端元提取结果
Table 7 Endmember results for the synthetic datasets with different max abundance
| 最大丰度 | MVC-NMF | SISAL+FCLS | Heylen | N-FINDR+CNLS | MU-LQM | PG-FAN | DE-FAN | |||||||||||||
| SAD | SD | SAD | SD | SAD | SD | SAD | SD | SAD | SD | SAD | SD | SAD | SD | |||||||
| 0.6 | 7.4917 | 1.4188 | 11.3345 | 2.3987 | 14.8709 | 2.9279 | 10.6691 | 1.4925 | 9.8126 | 2.3079 | 7.7549 | 1.6069 | 4.3839 | 0.8197 | ||||||
| 0.7 | 5.7147 | 1.6895 | 13.0989 | 2.7596 | 17.2599 | 2.4642 | 7.6568 | 1.4286 | 7.6542 | 1.4554 | 6.0006 | 1.1678 | 2.8991 | 0.5144 | ||||||
| 0.8 | 4.5635 | 1.4563 | 12.2278 | 2.8139 | 14.4073 | 2.1107 | 5.2549 | 1.0450 | 9.5779 | 1.5261 | 5.0229 | 0.8916 | 2.8761 | 0.4932 | ||||||
| 0.9 | 3.7948 | 1.1606 | 12.5644 | 2.8162 | 18.1703 | 3.4028 | 2.6360 | 0.5294 | 7.3686 | 1.4725 | 2.1394 | 0.5466 | 2.0780 | 0.3079 | ||||||
| 注:M=5,N=2500,SNR=20 db。 | ||||||||||||||||||||
表 8 不同最大丰度模拟图像的丰度反演结果
Table 8 Abundance results for the synthetic datasets with different max abundance
| 最大丰度 | MVC-NMF | SISAL+FCLS | Heylen | N-FINDR+CNLS | MU-LQM | PG-FAN | DE-FAN | |||||||||||||
| A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | A-RMSE | RMSE | |||||||
| 0.6 | 0.1341 | 0.1576 | 0.1099 | 0.2213 | 0.3119 | 0.7836 | 0.1323 | 0.0348 | 0.1632 | 0.0387 | 0.1251 | 0.0162 | 0.0921 | 0.0167 | ||||||
| 0.7 | 0.1167 | 0.1370 | 0.1136 | 0.2203 | 0.4100 | 0.8304 | 0.1190 | 0.0297 | 0.1433 | 0.0295 | 0.1099 | 0.0165 | 0.0763 | 0.0162 | ||||||
| 0.8 | 0.1324 | 0.1707 | 0.1125 | 0.1647 | 0.2992 | 0.6589 | 0.1427 | 0.0260 | 0.1591 | 0.0467 | 0.1428 | 0.0173 | 0.0895 | 0.0159 | ||||||
| 0.9 | 0.1048 | 0.0174 | 0.1139 | 0.1655 | 0.4039 | 0.9253 | 0.0844 | 0.0216 | 0.1666 | 0.0305 | 0.0841 | 0.0157 | 0.0656 | 0.0147 | ||||||
| 注:M=5,N=2500,SNR=20 db。 | ||||||||||||||||||||
4.1.5 算法复杂度与效率分析
设待解混图像的波段数为B,总像元数为N,各图像子块所包含的像元数为P,端元数为M,算法中丰度种群与端元种群的个体数都为S,最大迭代次数为I,C为端元混合项的个数。
DE-FAN算法采用了图像分块策略,迭代中存储各图像子块端元种群与丰度种群的最优个体所占用的内存空间分别为NBM/P与NM。各图像子块独立迭代求解时,存储端元种群及丰度种群所占用的内存空间都为SM(B+P),存储原始图像所占用的内存空间为NB。因此,DE-FAN算法的空间复杂度为
| $O\left( {2S \! M\left( {B + P} \right) + NM\left( {1 + B/P} \right) + NB} \right)$ | (20) |
DE-FAN算法中最多嵌套了4层循环,由外向内第1层循环的执行次数为图像的子块数;第2层循环的执行次数为最大迭代次数;第3层循环在种群选择步骤中,循环的执行次数等于端元数;第4层循环用于计算适应度,循环的执行次数为种群个体数乘以端元矩阵与丰度矩阵乘积运算所需的迭代次数。因此DE-FAN算法的时间复杂度为
| $O\left( {NBISM\left( {M + {C_{{\rm{FAN}}}}} \right)} \right)$ | (21) |
文中其他对比算法的复杂度分析详见附录A。
综合上述各算法的复杂度分析以及表9中各算法解混运行时间统计,可见DE-FAN算法的解混效率较为一般,优于PG-FAN算法以及Heylen算法,但仍未达到MVC-NMF算法、MU-LQM算法、N-FINDR+CNLS算法以及SISAL+FCLS算法的解混效率,原因是MVC-NMF算法、MU-LQM算法、N-FINDR+CNLS算法以及SISAL+FCLS算法中均采用了数值优化算法,这类算法利用目标函数的局部几何特征进行寻优,通常具有较高的收敛速率;同时,相较于双线性混合模型,基于线性混合模型寻优计算的复杂度通常也更低,因而具有更高的解混效率。此外,SISAL算法以及N-FINDR算法中还对原始数据进行了降维处理,进一步降低了迭代寻优的计算量,因而具有最高的解混效率。
表 9 算法运行时间比较
Table 9 Running time comparison of different algorithms
| /s | ||||||||
| 端元数 | MVC-NMF | SISAL+FCLS | Heylen | N-FINDR+CNLS | MU-LQM | PG-FAN | DE-FAN | |
| 3端元 | 2.794 | 0.887 | 3494.172 | 57.448 | 25.818 | 1549.275 | 832.263 | |
| 5端元 | 4.097 | 0.915 | 18324.671 | 119.553 | 29.015 | 2475.788 | 1479.196 | |
| 7端元 | 5.941 | 0.992 | 41628.846 | 166.156 | 34.038 | 4622.459 | 2294.182 | |
| 9端元 | 7.975 | 1.086 | 97912.622 | 276.920 | 40.366 | 5338.577 | 3331.695 | |
4.2 真实图像实验
本文使用两幅Airborne Visible/Infrared Imaging Spectrometers(AVIRIS)真实图像对DE-FAN算法的现实有效性进行检验。需要说明的是,由于实验区域的像元数据点非均匀分布,因此Heylen算法在两幅真实图像实验中都出现像元点非连通的情况,无法计算出有效的测地距离,因此无法完成真实图像解混实验。
4.2.1 Cuprite矿区图像解混实验
图像2为AVIRIS于1997年所获取的美国内华达州Cuprite矿区图像。本文从这幅图像中截取100×100的子区域作为实验数据(图2),除去水汽吸收波段后共包含189个波段。本文使用VD算法(Chang和Du,2004)在虚警概率为10–3、10–4、10–5条件下分别得到端元数估计值为9、9、8,综合该地区的地质考察资料(Clark 等, 2003),确定该区域内包含了明矾石、高岭石、白云母等9种矿物。将各算法的端元提取结果与光谱库中对应的矿物光谱对比计算得到端元提取精度(Miao和Qi, 2007),表10、表11分别为光谱角距离与光谱距离的精度统计,图3为各算法的丰度反演结果,图4为各算法的RMSE统计。

表 10 Cuprite真实图像端元提取结果的光谱角比较
Table 10 Spectral angles between extracted endmembers from Cuprite image and laboratory spectra
| 算法 | 镁铝石 | 榍石 | 铵长石 | 高岭石 | 白云母 | 玉髓 | 绿脱石 | 明矾石 | 蒙脱石 |
| MVC-NMF | 6.8467 | 8.8229 | 9.6683 | 14.1078 | 2.9087 | 18.837 | 8.3067 | 5.9317 | 8.0423 |
| SISAL+FCLS | 4.3443 | 6.4729 | 11.7500 | 11.3999 | 3.2403 | 35.9313 | 18.2865 | 11.3873 | 9.4736 |
| N-FINDR+CNLS | 6.4952 | 5.5045 | 4.6775 | 8.4205 | 5.2068 | 7.5677 | 5.9256 | 7.0577 | 7.0514 |
| MU-LQM | 4.3283 | 8.4993 | 8.3193 | 6.3856 | 3.8295 | 5.1214 | 6.5448 | 8.1283 | 7.6677 |
| PG-FAN | 6.0212 | 4.0133 | 6.0066 | 6.8906 | 3.8794 | 7.1531 | 7.1886 | 7.6070 | 7.8552 |
| DE-FAN | 5.3461 | 4.2298 | 6.9488 | 6.6805 | 2.2478 | 6.2614 | 5.8441 | 8.8140 | 6.7504 |
表 11 Cuprite真实图像端元提取结果的光谱距离比较
Table 11 Spectral distances between extracted endmembers from Cuprite image and laboratory spectra
| 算法 | 镁铝石 | 榍石 | 铵长石 | 高岭石 | 白云母 | 玉髓 | 绿脱石 | 明矾石 | 蒙脱石 |
| MVC-NMF | 0.6868 | 0.7148 | 1.0025 | 1.3225 | 0.6938 | 1.0003 | 0.6170 | 1.0183 | 0.6793 |
| SISAL+FCLS | 0.8892 | 1.1875 | 1.0216 | 1.2497 | 2.6585 | 2.9426 | 1.3177 | 1.3953 | 1.0331 |
| N-FINDR+CNLS | 0.6772 | 0.5720 | 0.5432 | 0.7468 | 0.6793 | 0.6584 | 0.5587 | 0.7583 | 0.6461 |
| MU-LQM | 0.5135 | 0.5256 | 0.7225 | 0.7668 | 0.7018 | 0.3029 | 0.5494 | 0.6381 | 0.6675 |
| PG-FAN | 0.4403 | 0.3000 | 0.6089 | 0.8699 | 0.7461 | 0.7461 | 0.5190 | 0.7227 | 0.7342 |
| DE-FAN | 0.6960 | 0.3759 | 0.7524 | 0.6292 | 0.4530 | 0.4364 | 0.5183 | 0.7415 | 0.5937 |


可见,DE-FAN算法的端元提取精度整体上优于其他5个算法;实验中SISAL算法提取的端元出现了负值以及数值大于1的情况,导致SISAL算法的端元提取精度与其他算法存在较大差距。在丰度反演方面,DE-FAN算法、PG-FAN算法以及MU-LQM算法的反演结果相似,但与MVC-NMF、SISAL+FCLS等线性解混算法的反演结果呈现较大的差异,而N-FINDR+CNLS算法的反演结果则与其他算法均存在明显差异。在RMSE指标上,SISAL+FCLS算法的结果最好,DE-FAN算法与MVC-NMF算法次之,而MU-LQM以及N-FINDR+CNLS算法最差;但由于SISAL算法提取的端元与真实端元存在较大的偏差,因此这项指标并不能说明该算法具有最好的解混精度。
4.2.2 Moffett区域图像解混实验
图像5为AVIRIS于1997年所获取的美国加州Moffett区域图像。本文从中截取了50×50的子区域作为实验数据(图5),除去水汽吸收波段后共包含189个波段。综合参考该区域相关的解混研究文献,确定该区域内主要包含了植被、水体以及土壤等3大类地物(Altmann 等,2012;Zhuang 等,2015)。由于缺乏该区域准确的端元光谱信息,因此本文参考文献(Zhuang 等,2015)的思路,使用文献(Somers 等,2012)提出的算法提取该区域的端元束,并以各端元束的均值作为参考端元。表12为各算法的端元提取结果精度统计,图5为各算法的RMSE统计,图6为各算法的丰度反演结果。

表 12 Moffett图像端元提取精度
Table 12 Results comparison in terms of different endmembers
| 参数 | MVC-NMF | SISAL+FCLS | N-FINDR+CNLS | MU-LQM | PG-FAN | DE-FAN | |||||||||||||||||
| 植被 | 水体 | 土壤 | 植被 | 水体 | 土壤 | 植被 | 水体 | 土壤 | 植被 | 水体 | 土壤 | 植被 | 水体 | 土壤 | 植被 | 水体 | 土壤 | ||||||
| SAD | 2.8644 | 14.3694 | 3.2450 | 5.6945 | 18.2424 | 2.1165 | 2.8867 | 12.3698 | 2.2450 | 11.1323 | 14.6109 | 3.8058 | 0.8558 | 15.5561 | 0.7264 | 1.0275 | 12.2301 | 0.6866 | |||||
| SD | 0.2553 | 0.1084 | 0.4158 | 0.9723 | 0.6091 | 0.5330 | 0.2453 | 0.0496 | 0.2158 | 0.7569 | 0.1437 | 0.4503 | 0.0470 | 0.0617 | 0.2137 | 0.1097 | 0.0482 | 0.1606 | |||||

在总体上,DE-FAN算法与PG-FAN算法在土壤和植被端元提取方面具有相对较高的精度,但在水体端元提取上,N-FINDR+CNLS算法与DE-FAN算法则具有更高的精度。其中,DE-FAN算法对水体端元及土壤端元的提取精度优于PG-FAN算法,但对植被端元的提取效果则稍差于PG-FAN算法。此外,实验中SISAL算法所提取的水体端元也出现了负值的情况,这也导致了SISAL算法的端元提取精度偏低。在丰度反演方面,DE-FAN算法、PG-FAN算法以及N-FINDR+CNLS算法的反演结果更接近于该区域现有的各地物丰度分布研究成果(Altmann 等,2011;Altmann 等,2011;Halimi 等,2011;Altmann 等,2012),与MVC-NMF算法以及SISAL+FCLS算法反演结果的主要差异体现在土壤与水体的丰度分布上。在RMSE指标上,DE-FAN算法、MVC-NMF算法、PG-FAN算法以及SISAL+FCLS算法的结果相近,均显著优于MU-LQM算法以及N-FINDR+CNLS算法。
综上所述,DE-FAN算法对于真实图像的解混精度总体上优于传统的算法。
5 结 论
本文针对FAN双线性混合模型,在经典DE算法的基础上引入了种群自适应重构策略以及图像分块策略,提出了一种新的非监督双线性光谱解混算法(DE-FAN)。DE-FAN算法通过端元种群与丰度种群的交替进化以最小化图像重构误差,最终同时完成端元与丰度的求解。根据模拟图像及真实图像的解混实验结果,表明DE-FAN算法较之文中基于梯度信息或流形学习的双线性光谱解混算法具有更高的多端元解混精度;同时图像分块策略的引入增强了算法对于噪声的鲁棒性,而种群自适应重构策略则使得算法对于初始解质量的依赖性优于文中其他算法。
尽管如此,DE-FAN算法仍有以下问题有待于解决:(1)算法的解混效率有待于进一步优化与提高(2)本文因固定了重构区间的大小而限制了算法的收敛速度,当初始解质量较好时可能会出现冗余的迭代,因此在后续的研究中将寻求建立动态的重构区间机制;(3)本文实现了最基础的FAN模型的非监督光谱解混,在未来的研究中,将利用该算法框架将本文提出的算法拓展于其他非线性混合模型。
附 录A
1 对比算法的空间复杂度分析
对于MVC-NMF算法、PG-FAN算法、MU-LQM算法,参考文献(Miao和Qi,2007;Eches和Guillaume,2014;Meganem 等, 2014b),可知在迭代时存储梯度矩阵、端元解矩阵与丰度解矩阵所占用的内存空间为:M(B+N),因此这3个算法的空间复杂度都为
| $O\left( {MN + MB + NB} \right)(\text{A1})$ |
对于SISAL+FCLS算法,参考文献(Heinz和Chang,2001;Bioucas-Dias,2009),可知其空间复杂度为
| $O\left( {{B^2} + M\left( {N + B} \right) + NB} \right) (\text{A2})$ |
对于N-FINDR+CNLS算法,参考文献(Ganseman和Scheunders,2012;Pu 等,2015),可知其空间复杂度为
| $O\left( {MN + MB + NB} \right) (\text{A3})$ |
对于Heylen算法,参考文献(Heylen 等,2011),设邻域大小为K,算法中存储邻接矩阵以及距离矩阵所占的内存空间为NK。因此Heylen算法的空间复杂度为
| $O\left( {M\left( {N + B} \right) + N\left( {B + 2K} \right)} \right)(\text{A4})$ |
2 对比算法的时间复杂度分析
对于PG-FAN算法,参考文献(Eches和Guillaume,2014),设执行Armijo步长优化的最大迭代次数为:L,非线性混合项的数目为:CFAN,则PG-FAN算法的时间复杂度为
| $O\left( {NBIL\left( {M + {C_{\rm{FAN}}}} \right)} \right)(\text{A5})$ |
对于MU-LQM算法,参考文献(Meganem 等,2014b),设非线性混合项的数目为CLQM,则MU-LQM算法的时间复杂度为
| $O\left( {NBIL\left( {M + {C_{\rm{LQM}}}} \right)} \right)(\text{A6})$ |
对于SISAL+FCLS算法,参考文献(Heinz和Chang,2001;Bioucas-Dias,2009),可知其时间复杂度为
| $O\left( {NB{M^2}} \right)(\text{A7})$ |
对于N-FINDR+CNLS算法,参考文献(Ganseman和Scheunders,2012;Pu 等,2015),可知其时间复杂度为
| $O\left( {{M^2}N\left( {{M^2} + B} \right)} \right)(\text{A8})$ |
对于MVC-NMF算法,参考文献(Miao和Qi,2007),设算法中步长优化的最大迭代次数为:L,则MVC-NMF算法的时间复杂度为
| $O\left( {IL{M^2}\left( {B + N} \right)} \right)(\text{A9})$ |
对于Heylen算法,参考文献(Heylen 等,2011),可知其时间复杂度为
| $O\left( {{N^3}{M^3} + {N^2}{M^2}} \right)(\text{A10})$ |
参考文献(References)
-
Altmann Y, Dobigeon N and Tourneret J Y. 2014. Unsupervised post-nonlinear unmixing of hyperspectral images using a Hamiltonian Monte Carlo algorithm. IEEE Transactions on Image Processing, 23 (6): 2663–2675. [DOI: 10.1109/tip.2014.2314022]
-
Altmann Y, Halimi A, Dobigeon N and Tourneret J Y. 2012. Supervised nonlinear spectral unmixing using a postnonlinear mixing model for hyperspectral imagery. IEEE Transactions on Image Processing, 21 (6): 3017–3025. [DOI: 10.1109/tip.2012.2187668]
-
Bioucas-Dias J M. 2009. A variable splitting augmented Lagrangian approach to linear spectral unmixing // Proceedings of the 1st Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing. Grenoble: IEEE: 1–4
-
Bro R and De Jong S. 1997. A fast non-negativity-constrained least squares algorithm. Journal of Chemometrics, 11 (5): 393–401. [DOI: 10.1002/(SICI)1099-128X(199709/10)11:5<393::AID-CEM483>3.0.CO;2-L]
-
Chakravortty S, Shah E and Chowdhury A S. 2014. Application of spectral unmixing algorithm on hyperspectral data for mangrove species classification // Proceedings of the 1st International Conference on Applied Algorithms. Kolkata, India: Springer: 223–236
-
Chang C I and Du Q. 2004. Estimation of number of spectrally distinct signal sources in hyperspectral imagery. IEEE Transactions on Geoscience and Remote Sensing, 42 (3): 608–619. [DOI: 10.1109/tgrs.2003.819189]
-
Chen J, Richard C and Honeine P. 2013. Nonlinear unmixing of hyperspectral data based on a linear-mixture/nonlinear-fluctuation model. IEEE Transactions on Signal Processing, 61 (2): 480–492. [DOI: 10.1109/tsp.2012.2222390]
-
Clark R N, Swayze G A, Livo K E, Kokaly R F, Sutley S J, Dalton J B, McDougal R R and Gent C A. 2003. Imaging spectroscopy: earth and planetary remote sensing with the USGS Tetracorder and expert systems. Journal of Geophysical Research: Planets, 108 (E12): 5131 [DOI: 10.1029/2002je001847]
-
Clark R N, Swayze G A, Wise R, Livo K E, Hoefen T M, Kokaly R F and Sutley S J. 2007. USGS digital spectral library splib06a. US: Geological Survey.
-
Das S and Suganthan P N. 2011. Differential evolution: a survey of the state-of-the-art. IEEE Transactions on Evolutionary Computation, 15 (1): 4–31. [DOI: 10.1109/tevc.2010.2059031]
-
Eches O and Guillaume M. 2014. A Bilinear–Bilinear nonnegative matrix factorization method for hyperspectral unmixing. IEEE Geoscience and Remote Sensing Letters, 11 (4): 778–782. [DOI: 10.1109/lgrs.2013.2278993]
-
Fan W Y, Hu B X, Miller J and Li M Z. 2009. Comparative study between a new nonlinear model and common linear model for analysing laboratory simulated-forest hyperspectral data. International Journal of Remote Sensing, 30 (11): 2951–2962. [DOI: 10.1080/01431160802558659]
-
Ganseman J and Scheunders P. 2012. A jump start for NMF with N-FINDR and NNLS.
-
Giacobini M, Brabazon A, Cagoni S, Di Caro G A, Drechsler R, Farooq M, Fink A, Lutton E, Machado P, Minner S, O'Neill M, Romero J, Rothlauf F, Squillero G, Takagi H, Uyar A S and Yang S. 2007. Applications of Evolutionary Computing: EvoWorkshops 2007. Berlin Heidelberg: Springer-Verlag
-
Halimi A, Altmann Y, Dobigeon N and Tourneret J Y. 2011. Nonlinear unmixing of hyperspectral images using a generalized bilinear model. IEEE Transactions on Geoscience and Remote Sensing, 49 (11): 4153–4162. [DOI: 10.1109/TGRS.2010.2098414]
-
Hapke B. 1981. Bidirectional reflectance spectroscopy: 1. Theory. Journal of Geophysical Research: Solid Earth (1978–2012), 86 (B4): 3039–3054. [DOI: 10.1029/JB086iB04p03039]
-
Heinz D C and Chang C I. 2001. Fully constrained least squares linear spectral mixture analysis method for material quantification in hyperspectral imagery. IEEE Transactions on Geoscience and Remote Sensing, 39 (3): 529–545. [DOI: 10.1109/36.911111]
-
Heylen R, Burazerović D and Scheunders P. 2011. Non-linear spectral unmixing by geodesic simplex volume maximization. IEEE Journal of Selected Topics in Signal Processing, 5 (3): 534–542. [DOI: 10.1109/jstsp.2010.2088377]
-
Kitayama S, Arakawa M and Yamazaki K. 2011. Differential evolution as the global optimization technique and its application to structural optimization. Applied Soft Computing, 11 (4): 3792–3803. [DOI: 10.1016/j.asoc.2011.02.012]
-
Luukka P and Lampinen J. 2011. Differential evolution classifier in noisy settings and with interacting variables. Applied Soft Computing, 11 (1): 891–899. [DOI: 10.1016/j.asoc.2010.01.009]
-
Meganem I, Deliot P, Briottet X, Deville Y and Hosseini S. 2014a. Linear–quadratic mixing model for reflectances in urban environments. IEEE Transactions on Geoscience and Remote Sensing, 52 (1): 544–558. [DOI: 10.1109/TGRS.2013.2242475]
-
Meganem I, Deville Y, Hosseini S, Déliot P and Briottet X. 2014b. Linear-quadratic blind source separation using NMF to unmix urban hyperspectral images. IEEE Transactions on Signal Processing, 62 (7): 1822–1833. [DOI: 10.1109/tsp.2014.2306181]
-
Mendes R and Mohais A S. 2005. DynDE: a differential evolution for dynamic optimization problems // Proceedings of the 2005 IEEE Congress on Evolutionary Computation. Edinburgh, Scotland: IEEE: 2808–2815
-
Miao L D and Qi H R. 2007. Endmember extraction from highly mixed data using minimum volume constrained nonnegative matrix factorization. IEEE Transactions on Geoscience and Remote Sensing, 45 (3): 765–777. [DOI: 10.1109/tgrs.2006.888466]
-
Nascimento J M and Bioucas-Dias J M. 2009. Nonlinear mixture model for hyperspectral unmixing // Proc. SPIE 7477, Image and Signal Processing for Remote Sensing XV, 74770I. Berlin, Germany: SPIE
-
Nascimento J M P and Dias J M B. 2005. Vertex component analysis: a fast algorithm to unmix hyperspectral data. IEEE Transactions on Geoscience and Remote Sensing, 43 (4): 898–910. [DOI: 10.1109/tgrs.2005.844293]
-
Price K, Storn R M and Lampinen J A. 2005. Differential Evolution: A Practical Approach to Global Optimization. Berlin Heidelberg: Springer.
-
Pu H Y, Chen Z, Wang B and Xia W. 2015. Constrained least squares algorithms for nonlinear unmixing of hyperspectral imagery. IEEE Transactions on Geoscience and Remote Sensing, 53 (3): 1287–1303. [DOI: 10.1109/tgrs.2014.2336858]
-
Qin S Y, Luo W F, Yang B and Zhang R H. 2015. Simplex volume minimization based differential evolution algorithm for spectral unmixing. Journal of Image and Graphics, 20 (11): 1535–1544. [DOI: 10.11834/jig.20151113] ( 覃事银, 罗文斐, 杨斌, 张锐豪. 2015. 单形体体积最小化的差分进化光谱解混算法. 中国图象图形学报, 20 (11): 1535–1544. [DOI: 10.11834/jig.20151113] )
-
Somers B, Zortea M, Plaza A and Asner G P. 2012. Automated extraction of image-based endmember bundles for improved spectral unmixing. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 5 (2): 396–408. [DOI: 10.1109/jstars.2011.2181340]
-
Storn R and Price K. 1995. Differential evolution-a simple and efficient adaptive scheme for global optimization over continuous spaces. Berkeley: ICSI
-
Vesterstrøm J and Thomsen R. 2004. A comparative study of differential evolution, particle swarm optimization, and evolutionary algorithms on numerical benchmark problems // Proceedings of the Congress on Evolutionary Computation. Portland, OR, USA: IEEE: 1980–1987
-
Winter M E. 1999. N-FINDR: an algorithm for fast autonomous spectral end-member determination in hyperspectral data // Proc. SPIE 3753, Imaging Spectrometry V. Denver, CO, USA: SPIE: 266–275
-
Yang Z Y, Tang K and Yao X. 2008. Large scale evolutionary optimization using cooperative coevolution. Information Sciences, 178 (15): 2985–2999. [DOI: 10.1016/j.ins.2008.02.017]
-
Yu Y, Guo S and Sun W D. 2007. Minimum distance constrained non-negative matrix factorization for the endmember extraction of hyperspectral images // Proc. SPIE 6790, MIPPR 2007: Remote Sensing and GIS Data Processing and Applications; and Innovative Multispectral Technology and Applications. Wuhan, China: SPIE
-
Zhang X D. 2004. Matrix Analysis and Applications. Beijing: Tsinghua University Press: 71–100 (张贤达. 2004.矩阵分析与应用. 北京: 清华大学出版社: 71–100)
-
Zhong Y F, Zhao L and Zhang L P. 2014. An adaptive differential evolution endmember extraction algorithm for hyperspectral remote sensing imagery. IEEE Geoscience and Remote Sensing Letters, 11 (6): 1061–1065. [DOI: 10.1109/lgrs.2013.2285476]
-
Zhuang L, Zhang B, Gao L R, Li J and Plaza A. 2015. Normal endmember spectral unmixing method for hyperspectral imagery. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 8 (6): 2598–2606. [DOI: 10.1109/jstars.2014.2360888]


