 2019, Vol. 40
2019, Vol. 40



2. 哈尔滨工程大学 计算机科学与技术学院, 黑龙江 哈尔滨 150001
2. College of Computer Science and Technology, Harbin Engineering University, Harbin 150001, China
本文面向网络信息动态数据流研究中文动态多文档文摘(Chinese dynamic multi-document summarization,CDMDS)的建模方法。从分析中文语言特色入手,在建模的基础上,也对CDMDS评测领域开展了研究,提出了动态的中文评测系统和指标。随着英文领域的动态文摘方法研究的深入,中文文本挖掘领域也逐渐关注了这一研究热点。由于中文文本结构的特殊性,使得中文动态摘要的研究较少。本研究从中文文本的动态语义结构出发,分析具有不同时序特征的文本集合,对内容的理解和动态演化关系进行了建模和分析,加强了主题相关性和内容的低冗余性,为基于理解的文本内容新颖性、流畅性提高保障。
文摘技术的发展与其自动评测技术的发展是相辅相成的。CDMDS模型的处理对象为具有动态演化性的网络信息数据流文档,这不仅使研究遇到了前所未有的难题,还给相应的自动评测技术带来了困难。本文提出了CDMDS建模方法, 其重点为动态性的实现。为了支持CDMDS模型的可靠性,还就中文动态自动评测方法进行了研究。本文结合中文多文档文摘系统和动态性等特点,提出了一种具有多语种语言领域移植性的自动评测方法,主要研究基于动态的中文文摘与其参考文摘的一元词重合率和二元词语重合率等问题。
1 研究现状分析 1.1 中文多文档文摘及动态文摘发展现状文本语料的句子级抽取虽然能够提高理解式摘要的可读性,但是缺乏分词的处理和语义的理解,使得基于句子的摘要生成方法缺乏统一的规范。因此本文提出的基于词级的文摘评价方法具有一定研究意义。
在国内,目前对中文的多文档文摘的研究虽然还处于起步阶段,但已有哈尔滨工业大学、华北电力大学[1]、复旦大学、北京大学等高校取得了较好的进展。
在多文档文摘的研究中,基于文档特征集合的方法主要有郭庆琳等[2]开发的面向“塑料”行业的基于文本聚类和自然语言理解的自动文摘系统TCAAS;张其文等[3]将语义方法融入统计算法,提出了一种基于统计的多文档文摘提取方法;文献[4]提出了基于文档集和内局部主题的判定和抽取生成多文档文摘的方法;吴玲达等提出了一种针对新闻事件的多文档摘要生成方法;还有刘德荣等[5]开发的针对大规模文档集的综合性自动摘要系统。
中文文摘的时序特征研究中,叶娜等[6-7]提出了基于浅层分析技术的文摘分析方法,通过主题划分和语义识别实现文本内容分析;许洪波等[8-9]提出了面向Web话题的多文档文摘技术,力求降低文摘的冗余性;结合中文文本的结构特点,余珊珊等[10]将标题、段落、特殊句子、句子位置和长度等信息引入到网络图中改进了句子相似度计算方法,并将其应用于中文文本的自动摘要提取。
但是国内对于动态多文档文摘的研究基本都是基于英语语料以及国际标准评测的方法,基本没有中文多文档文摘动态性能的研究,这是中文文摘技术发展的一个突破口。一些研究也表明,在计算语言学领域,中文文摘技术一直是比较薄弱的环节,因此CDMDS模型具有一定的研究价值。
1.2 中文多文档文摘系统的自动评测传统的摘要评测需要人工对摘要的各种标准做出判定,因此常带来主观因素影响的评测结果的不一致性,自动评测技术的研究将解决这一问题。在中文领域,如何利用相应算法和语料结构来构建自动评测框架具有重要的意义。自动评测适合于基于原文抽取的文摘,它是内部评测方法的应用。
傅间莲等[11]提出了一种新的评价方法(F-new-measure),并应用于文本自动摘要中。将压缩率指标添加到评价当中,评价值较稳定;魏继增等[12]提出以信息覆盖程度为指标的文摘标准。
BLEU[13]是一种经典评测工具。它以精确率为主要研究目标,对基于原文抽取的自动文摘进行评价,也被大量运用在机器翻译当中。ROUGE(recall-oriented understudy for gisting evaluation)[14-15]是一种重要的评价标准,在国际知名评测中被采用作为主要的评价方法。ROUGE-N计算系统生成文摘与人工文摘之间同现单元的个数,是一个用来评价的态演化性的指标。
2 CDMDS建模方法本文使用基于文摘系统模型及算法同时改进的动态文摘模型对中文文档集信息的动态演化性进行建模。因此为了使CDMDS具有动态性,必须在其模型中对文档集的动态演化性建模。综合起来,如图 1所示动态中文多文档文摘系统框架主要包含特征抽取、信息过滤、句子加权、文摘句选择及排序模块。

|
Download:
|
| 图 1 CDMDS框架 Fig. 1 CDMDS framework | |
主题签名的自动获取的思想是,在给定的文档集合中,文档可能会描述一个主题涉及到的内容, 却不清晰地给出这一基本主题,所以为生成高质量的文摘,需要文摘系统自动地去确定主题,采用某种方法找到用来刻画文档集合主题内容的词汇信息。TF-IDF词汇加权算法虽然在信息检索等领域有很好的效果,但是它计算的词汇信息针对的范围相对较大,而对于多文档文摘,需要面对主题进行词汇信息加权。
所以本文提出了基于主题签名的方法进行词汇信息加权,研究了基于同现统计的主题签名自动获取。
1) 主题签名的定义。
句子选择可以通过计算主题描述的相似度得到。主题签名(topic signatures, TS)是指与该概念同现的一组词语。从语言学的角度分析, 即特定语境下的语义相关性。主题签名的形式化定义为:
| $ \begin{array}{l} \;\;\;\;\;\;{T_S} = \left\{ {{\rm{topic}}, {\rm{signature}}} \right\} = \\ \;\left\{ {{\rm{topic}}, \left\langle {\left( {{t_1}, {w_1}} \right), \cdots , \left( {{t_n}, {w_n}} \right)} \right\rangle } \right\} \end{array} $ | (1) |
其中量化过的主题签名包括目标概念topic,相关词语的向量signature。
2) 基于同现统计的主题签名自动获取。
由于人工收集、编写主题签名费时费力,本文将采用自动的方法获取主题签名,即利用分类算法从统计分析的角度,抽取出与目标概念具有强关联的词语集合。
每个待处理的文档集合可看作是特定主题的文档集合R,通过主题签名自动获取可以获得该集合内的词汇统计信息。
2.1.2 句子历史冗余性特征值的计算本文中将对句子所含历史信息的度量称为句子历史冗余性特征,是动态多文档文摘系统区别于其他自动文摘系统的重要核心研究点。本系统通过句子的历史冗余性来刻画句子所含信息的动态演化性。其计算公式为:
| $ {N_{{\rm{Wgt}}}}\left( s \right) = \left\{ {\sum\limits_{i = 1}^m {\left( {\frac{{\sum\limits_{j = 1}^n {{W_{{\rm{gt}}}}\left( {{w_{_{\rm{j}}}}} \right)} }}{{{\rm{length}}\left( {{s_i}} \right)}}} \right)} } \right\}/{\rm{length}}\left( s \right) \cdot {\rm{count}} $ | (2) |
式中:NWgt(s)即为句子s的历史冗余性特征值,通过计算主题词wj的权重Wgt(wj)与句子si与句子s中的主题词词语总数比例,并统计所有句子集合特征值来度量。
2.1.3 句子显著性特征值的计算句子显著性特征即其所含信息对所属文档集全局信息的代表性。根据基于自然语言的数理统计分析原理,越是显著的事物即得到其他事物认可最多的事物,即说明其相对重要性权重越大。本文将某句子与文档集中所有句子相似度的累加值作为衡量句子重要权重的一个指标,称其为句子显著度。
通过计算句子与文档集中所有句子的相似度之累加和来度量句子的显著性特征值,其计算公式为:
| $ {S_{{\rm{Wgt}}}}\left( s \right) = \left\{ {\sum\limits_{i = 1}^m {\left( {\frac{{\sum\limits_{j = 1}^n {{\rm{Weight}}\left( {{w_{_\mathit{j}}}} \right)} }}{{{\rm{length}}\left( {{s_i}} \right)}}} \right)} } \right\}/{\rm{length}}\left( s \right) \cdot {\rm{count}} $ | (3) |
式中:SWgt(s)即为句子s的显著性特征值,m为文档集中句子的总数;n为句子si与句子s中同现的主题词总数。
2.1.4 句子时间特征值的计算动态摘要的动态性能主要有时间特征体现,传统时序的摘要主要研究句子时间特征的抽取,研究复杂度很高,缺乏度量标准。本系统主要将文档的时序特性,测试语料的文档集句子进行宏观抽取。
根据此思想,句子的时间特征计算公式为:
| $ {T_{{\rm{Wgt}}}}\left( s \right) = 1/n $ | (4) |
式中:n代表按照发表时间排序后的文档集中句子所属文档的排序值。
2.1.5 句子长度特征值的计算本系统在对句子进行抽取时,应对抽取的所有句子设置一定的长度限制,使文摘中含有尽可能多的可用非冗余信息。
任何文摘系统的研究到最后一定会归结为摘要的可阅读性和可理解性研究上,因此在生成摘要的过程中,必然会抽取的信息量做一定的限制。目标是在有限的长度范围内包含尽可能多的内容。
本系统设计惩罚机制,即在抽取过程中,通过量化判断不同长度的句子的重要性。具体惩罚公式如式(5)所示:
| $ \begin{array}{l} \;\;\;\;\;{L_{{\rm{Wgt}}}}\left( s \right) = 1/\left( {{\rm{Length}}\left( s \right) - 0.5 \cdot } \right.\\ \left. {{\rm{MaxLength}}} \right){\rm{Length}}\left( s \right) > 0.5 * {\rm{MaxLength}} \end{array} $ | (5) |
式中:LWgt(s)表示句子s的长度权重;MaxLength表示文档集合中句子的最大长度。
2.1.6 句子位置特征权值的计算句子的分布通常具有一定的规律,由自然语言的书写规律可知,关键句一般位于开头和结尾部分,中间部分的句子多属于解释性的。语言学统计结果也证明了这一点,因此本文也将位置权重作为参数加入到句子计算中。
本系统通过式(6)计算句子的位置权重值:
| $ {P_{{\rm{Wgt}}}}\left( s \right) = 1/n $ | (6) |
式中n代表句子s在其所属文档中的位置值。
2.2 信息过滤模块本文所提模型的处理对象包含历史文档集和当前文档集,其中当前文档集为文摘产生对象,信息过滤模块的实现原理为:1)根据句子的历史冗余性特征值对当前文档集句子集合中的所有句子按从高到低的顺序进行排序;2)根据冗余度计算后的结果,对句子进行取舍;3)按照文摘长度要求,保留冗余度低的句子集合。
经过信息过滤模块处理之后的句子集合为新的备选文档集合。过滤模块的基本要求是控制过滤掉的和处理后留存的句子数量,以保证文档的信息全面性。本系统模块经过一系列的实验并结合先验知识,以自然语言理解的角度将最终候选集合的句子数设定为50左右。
2.3 句子加权模块传统静态文摘系统中,曾尝试使用流形排序的方法进行句子加权。本文研究的动态文摘系统, 需结合动态特征考虑句子权重,因此提出了一种较理想的句子加权算法,即动态流形排序方法。
2.4 候选句生成模块信息过滤后的备选句子集合仍然存在内容上的重复特性,为了充分提高系统性能,再次进行去冗余处理时,提出了将传统的MMR算法进行改进,以主题词权重为主要参考指标再次进行候选句子集合的调整。其计算公式为:
| $ \begin{array}{l} \;\;\;\;\;\;\;\;\;\;\;\;\;\;{A_{{\rm{ZWgt}}}}\left( s \right) = \\ {\rm{ }}\alpha \cdot \left( {{B_{{\rm{ZWgt}}}}\left( s \right) - \beta \cdot \sum\limits_{i = 1}^n {\frac{{\sum\limits_{j = 1}^{{\rm{simcount}}} {{{\rm{W}}_{{\rm{gt}}}}\left( {{w_j}} \right)} }}{{\sum\limits_{k = 1}^{{\rm{count}}\left( {{s_i}} \right)} {{W_{{\rm{gt}}}}\left( {{w_k}} \right)} }}} } \right) \end{array} $ | (7) |
式中:设定新生成的候选句子权重为AZWgt(s),备选句子原始权值(其值的计算祥见句子加权模块)Simcount为候选文摘句s和文摘句si同现的主题词的数量;α和β分别为参数,经过实验和经验测定的α=0.3,β=0.7。
3 中文动态多文档文摘评测方法 3.1 ROUGE评测方法在大规模文摘系统评测中人工评测作为专家先验知识的一部分,对评测方向起到指导性作用,经过不断的研究和开发,现在评测方法多是自动评测。
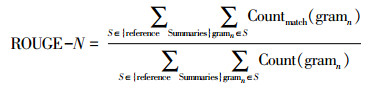
在DUC的历史上,ROUGE评价方法多次被作为主要的评价标准。ROUGE-N的计算更是召回率的精准体现。在中文评测领域虽然缺乏统一标准,但仍可以利用ROUGE-N的思想来计算人工摘要与自动动态文摘系统的共现率:
|
(8) |
2-gram文法结构即依次连续抽取2个单词,以此可得出n-gram的定义。参考句中共有6个词,参考句与之相同的词有1个,因此2-gram匹配度为1/6。
3.2 中文评测指标英文动态多文档文摘任务是TAC2008的update task中引入的一个任务,它的性能主要通过ROUGE评测系统中的ROUGE-2和ROUGE-SU4评测指标进行说明。受此启发,本文的CDMDS的移植性实验, 将使用类似的评测思想进行评测,所不同的是,本章开发的中文评测系统为了更加准确地评测系统性能使用了另外一个评测指标,即ROUGE-1评测指标。此评测指标的定义与ROUGE-1评测指标相似,为了有别于英文动态文摘系统的评测指标,下文分别称此3项评测指标为CROUGE-1,CROUGE-2,CROUGE-3。
1) CROUGE-1评测指标。
在英文文摘系统的评测中,ROUGE-1是一个很重要的评测指标,它计算一元词语在参考文摘与系统文摘中的同现率,能够估计出系统文摘对参考文摘的内容覆盖程度,即达到了有效评测英文文摘系统性能的目的。
由于中文文摘系统与英文文摘系统具有一定的相关性,其系统性能的评测方法也相似,为了更有效地对中文文摘系统的性能进行定位,因此本评测系统引进了英文文摘评测系统中的ROUGE-1评测指标,记为CROUGE-1。CROUGE-1将成为中文动态文摘系统中最基本也是最重要的评测指标,其主要对系统文摘与参考文摘之间的内容相似性进行估计,其计算公式为:
| $ {\rm{CROUGE}} - 1 = \frac{{\sum {{\rm{Coun}}{{\rm{t}}_{{\rm{match}}}}\left( {{\rm{Unigram}}} \right)} }}{{\sum {{\rm{Count}}\left( {{\rm{Unigram}}} \right)} }} $ | (9) |
式中:Unigram代表一元语法,也即一元词语,∑Countmatch(Unigram)为系统文摘与参考文摘中匹配的一元词语数量,∑Count(Unigram)为参考文摘中一元词语的总数量。其具体的实现算法如下:
本模型采用的评测方法与传统的ROUGE-1的不同之处在于传统的ROUGE-1评测方法是一种面向召回率的方法,不论是哪一种系统文摘,都对摘要长度有所要求,因此对系统摘要进行了指定长度的截取。统计人工摘要中词的个数和与人工摘要中相同一元词语的个数和根据式(9)计算当前摘要得分,求得各篇摘要得分的平均值作为系统得分。
2) CROUGE-2评测指标。
CROUGE-1虽然能够估计出系统文摘与参考文摘之间的一元词语匹配率,但是这不足以说明其相互之间的内容匹配率,以及其内容之间的相似度。例如“他打了别人”和“别人打了他”,这两句话的一元词语匹配率达到了百分之百,但是两句话的意思是截然不同的,若用CROUGE-1指标进行评测,其性能为佳。这就足以说明ROUGE-1指标单用时效果不佳,为了克服该指标单用时的缺点,本评测系统又从英文评测系统中引进了ROUGE-2评测指标,即为CROUGE-2。
CROUGE-2对中文动态文摘系统而言是另一重要评测指标,是为了更好地评测中文文摘系统的性能而引进的又一评测指标,其克服了CROUGE-1单独使用时的缺点,CROUGE-2以相连的2个汉字为研究对象,计算系统文摘对参考文摘中相连双汉字的覆盖率,此指标跟CROUGE-1合用时能够准确地估计出系统文摘对参考文摘内容的覆盖度,进而对文摘系统的性能进行高效率的估计,其计算公式为:
| $ {\rm{CROUGE}} - 2 = \frac{{\sum {{\rm{Coun}}{{\rm{t}}_{{\rm{match}}}}\left( {{\rm{Bigram}}} \right)} }}{{\sum {{\rm{Count}}\left( {{\rm{Bigram}}} \right)} }} $ | (10) |
式中:Bigram代表二元语法,也即二元词语,∑Countmatch(Bigram)为系统文摘与参考文摘中匹配的二元词语数量,∑Count(Bigram)为参考文摘中二元词语的总数量。
3) CROUGE-SU4评测指标。
CROUGE-2统计的数据为参考文摘与系统文摘中二元语法同现率,虽然能够在一定程度上评价文摘系统的性能,但是不够全面。因为在中文文章中还存在另一种语言现象,即固定搭配,语言中的固定搭配现象很多,本文研究最具代表性的一种固定搭配现象,即二元固定搭配,此类固定搭配中只有2个中文字,但是此二字之间可以包含任意数量的字。本文对二字之间具有四字的二元固定搭配进行研究,也即英文评测系统ROUGE评测工具中的ROUGE-SU4评测指标,记为CROUGE-SU4,其能很好地克服CROUGE-1和CROUGE-2评测指标的不足,从另外一个角度对文摘系统的性能进行评测。其评测结果也更全面更具说服力。其计算公式为:
| $ {\rm{CROUGE}} - {\rm{SU}}4 = \frac{{\sum {{\rm{Coun}}{{\rm{t}}_{{\rm{match}}}}\left( {{\rm{skip\_four\_gram}}} \right)} }}{{\sum {{\rm{Count}}\left( {{\rm{skip\_four\_gram}}} \right)} }} $ | (11) |
式中:∑Countmatch(skip_four_gram)为参考文摘与系统文摘中二字之间含四字的二元语法词语的同现数目。而∑Count(skip_four_gram)为参考文摘中总的二字之间含四字的二元语法词语的数目。
还有一个重要的与ROUSE密切相关的评测方法—BLEU。BLEU更多时候是被应用在机器翻译中,是一种面向精确率的方法,也可以对原文抽取的自动机械式文摘进行评价。
4 实验结果与分析 4.1 实验语料库介绍中文评测使用的语料来源于本人自整理的网络语料,整个语料库总共有14个主题,整理的大部分同主题的文档集中包含有5个文档,其中第1个文档为历史文摘,其内容为相应主题的历史信息,其余文档为当前文档,其中的内容为相应主题的当前信息,此二者之间的信息具有动态演化性。除此之外,每个主题还具有相应的标准文摘,由人工制定,具有评测参考价值。其基本内容如表 1所示。
| 表 1 中文测试语料库 Table 1 Table of Chinese test corpus |
语料库中一共包含14个主题,本中文动态文摘系统对每一主题的文档集都生成了相应的文摘,总共有14个文摘,由于篇幅的限制,不对所有主题的文摘都进行展示,只列出其中的2个主题的文摘,其中图 2为主题为“戴尔网络报价出错”的文档集的文摘,图 3为主题为“韩国士兵枪杀同伴后携武器出逃”的文档集的文摘。

|
Download:
|
| 图 2 ‘戴尔网络报价出错′主题文档集文摘结果 Fig. 2 "DELL network quotes error" subject document collection summary results | |

|
Download:
|
| 图 3 ‘韩国士兵枪杀同伴后携武器出逃′文摘结果 Fig. 3 "South Korean soldiers shot companions carrying weapons fled" abstract results | |
该评测系统主要使用上文介绍的3个评测指标对提出的中文动态文摘系统的性能进行评测。为了消除系统不稳定及文档集的不同等有关因素对系统性能的影响,保证评测结果的正确性及准确性,该评测系统对语料库中所有主题的文摘都进行了打分。并且将所有主题的文摘打分进行了统计,统计结果打分都列于表 2。
| 表 2 中文系统评测结果 Table 2 evaluation results of Chinese system |
从表 2可以看出,CROUGE-1、CROUGE-2以及CROUGE-SU4的打分均高于ROUSE标准评测的分数,其平均值分别为0.488 6、0.301 2、0.223 1, 说明系统文摘与标准文摘信息重合度比较高、内容相似度很大,即系统所生成的文摘与参考文摘一样能很好的涵盖文摘集的信息。虽然人工文摘的制定尚无统一标准,但是这种评测方法具有一定的参考价值。证明了经过一定改进的评测方法应用在中文文摘领域的可行性。
5 结论1) 通过话题检测与跟踪技术(TDT)与多文档文摘技术的结合,更深刻地理解时序特征对信息处理技术的重要性,得出了相应结论;
2) 对于基于网络动态数据的信息处理领域,动态多文档文摘技术和TDT技术都与动态演化性密切相关。通过对中文特点的分析,将动态多文档文摘模型应用到中文领域进行研究实现了中文的动态多文档文摘系统;
3) 本文开发了类似于英文评测标准的中文文摘评测系统,目前中文领域缺乏的就是统一的标准的评测机制,很多学者也做了这方面的研究, 但是缺乏权威性,这和中文特殊的语言环境有关。本文的评测系统仿照英文标准的ROUSE评测设置指标,并基于动态数据领域,描述其动态演化性,根据中文特点进行评价。实验表明,此方法有一定的可行性,是一项有价值的研究。
通过动态多文档文摘在中文领域的移植性建模研究,建立了独特的中文动态多文档文摘系统,此类系统的研建有很高的研究和应用价值,在很多中文信息处理领域,将有很好的可应用性。根据中文特点进行评价通过中文领域移植性研究的深入,也可向工程应用领域扩展,以验证评测系统的先进性。
| [1] |
郭庆琳, 樊孝忠, 柳长安. 基于文本聚类的自动文摘系统的研究与实现[J]. 计算机工程, 2006, 32(4): 30-32, 121. GUO Qinglin, FAN Xiaozhong, LIU Changan. Research and implementation about automatic abstract system based on text clustering[J]. Computer engineering, 2006, 32(4): 30-32, 121. (  0) 0)
|
| [2] |
郭庆琳, 樊孝忠, 柳长安. 文本聚类在自动文摘中的应用研究[J]. 计算机应用, 2005, 25(5): 1036-1038. GUO Qinglin, FAN Xiaozhong, LIU Changan. Application in automatic abstracting for text clustering[J]. Computer application, 2005, 25(5): 1036-1038. ( 0)
|
| [3] |
张其文, 李明. 多文档文摘提取方法的研究[J]. 兰州理工大学学报, 2007, 33(1): 96-99. ZHANG Qiwen, LI Ming. Investigation of method for extracting multi-document abstracts[J]. Journal of Lanzhou university of technology, 2007, 33(1): 96-99. DOI:10.3969/j.issn.1673-5196.2007.01.025 ( 0)
|
| [4] |
刘美玲, 任洪娥, 于洋, 等. 基于网络的动态多文档文摘系统框架[J]. 软件学报, 2013, 24(5): 1006-1021. LIU Meiling, REN Honge, YU Yang, et al. Web-based dynamic multi-document summarization system framework[J]. Journal of software, 2013, 24(5): 1006-1021. ( 0)
|
| [5] |
刘德荣, 王永成, 刘传汉. 基于主题概念的多文档自动摘要研究[J]. 情报学报, 2005, 24(1): 69-74. LIU Derong, WANG Yongcheng, LIU Chuanhan. Study of multiple documents summarization based on subject concept cohesion[J]. Journal of the China society for scientific and technical information, 2005, 24(1): 69-74. DOI:10.3969/j.issn.1000-0135.2005.01.010 ( 0)
|
| [6] |
YE Na, ZHU Jingbo, ZHENG Yan, et al. A dynamic programming model for text segmentation based on min-max similarity[C]//Proceedings of the 4th Asia Information Retrieval Conference on Information Retrieval Technology. Harbin, China, 2008: 141-152.
( 0)
|
| [7] |
杨选选, 张蕾. 基于语义角色和概念图的信息抽取模型[J]. 计算机应用, 2010, 30(2): 411-414. YANG Xuanxuan, ZHANG Lei. Information extraction based on semantic role and concept graph[J]. Journal of computer applications, 2010, 30(2): 411-414. ( 0)
|
| [8] |
张瑾, 许洪波, 程学旗. 面向网络演化信息的动态文摘方法研究[J]. 计算机学报, 2008, 31(4): 696-701. ZHANG Jin, XU Hongbo, CHENG Xueqi. Research on dynamic summarization for evolutionary web information[J]. Chinese journal of computers, 2008, 31(4): 696-701. DOI:10.3321/j.issn:0254-4164.2008.04.015 ( 0)
|
| [9] |
ZHANG Jin, CHENG Xueqi, XU Hongbo. Dynamic summarization: Another stride towards summarization[C]//Proceedings of 2007 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology-Workshops. Silicon Valley, CA, USA, 2007: 64-67.
( 0)
|
| [10] |
余珊珊, 苏锦钿, 李鹏飞. 基于改进的TextRank的自动摘要提取方法[J]. 计算机科学, 2016, 43(6): 240-247. YU Shanshan, SU Jindian, LI Pengfei. Improved TextRank-based method for automatic summarization[J]. Computer science, 2016, 43(6): 240-247. ( 0)
|
| [11] |
傅间莲, 陈群秀. 一种新的自动文摘系统评价方法[J]. 计算机工程与应用, 2006, 42(18): 176-177. FU Jianlian, CHEN Qunxiu. A new evaluation method for automatic text summarization[J]. Computer engineering and applications, 2006, 42(18): 176-177. DOI:10.3321/j.issn:1002-8331.2006.18.056 ( 0)
|
| [12] |
魏继增, 孙济洲, 秦兵. 多文档文摘评价标准的研究[J]. 计算机工程与应用, 2007, 43(2): 180-183. WEI Jizeng, SUN Jizhou, QIN Bing. Research on standard of evaluation of multi-document summarization[J]. Computer engineering and applications, 2007, 43(2): 180-183. DOI:10.3321/j.issn:1002-8331.2007.02.053 ( 0)
|
| [13] |
RUSH A M, CHOPRA S, WESTON J. A neural attention model for abstractive sentence summarization[J]. arXiv preprint arXiv: 1509.00685, 2015. https://www.researchgate.net/publication/281487270_A_Neural_Attention_Model_for_Abstractive_Sentence_Summarization
( 0)
|
| [14] |
LIN C Y. Looking for a few good metrics: ROUGE and its evaluation[C]//Proceedings of the NTCIR Workshop. Tokyo, Japan, 2004.
( 0)
|
| [15] |
BOUDIN F, MORENO J M T. NEO-CORTEX: a performant user-oriented multi-document summarization system[M]//GELBUKH A. Computational Linguistics and Intelligent Text Processing. Berlin Heidelberg: Springer, 2007: 551-562.
( 0)
|
| [16] |
刘美玲, 郑德权, 赵铁军, 等. 动态多文档文摘模型[J]. 软件学报, 2012, 23(2): 289-298. LIU Meiling, ZHENG Dequan, ZHAO Tiejun, et al. Dynamic multi-document summarization model[J]. Journal of software, 2012, 23(2): 289-298. ( 0)
|