{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Active Online Learning in the Binary Perceptron Problem
Cite this Article
Zhou Hai-Jun. Active Online Learning in the Binary Perceptron Problem. Communications in Theoretical Physics, 2019, 71(2): 243 
Permissions
Active Online Learning in the Binary Perceptron Problem
† Corresponding author. E-mail:
Supported by the National Natural Science Foundation of China under Grant Nos. 11421063 and 11747601 and the Chinese Academy of Sciences under Grant No. QYZDJ-SSW-SYS018
Abstract
Abstract
The binary perceptron is the simplest artificial neural network formed by N input units and one output unit, with the neural states and the synaptic weights all restricted to ±1 values. The task in the teacher-student scenario is to infer the hidden weight vector by training on a set of labeled patterns. Previous efforts on the passive learning mode have shown that learning from independent random patterns is quite inefficient. Here we consider the active online learning mode in which the student designs every new Ising training pattern. We demonstrate that it is mathematically possible to achieve perfect (error-free) inference using only N designed training patterns, but this is computationally unfeasible for large systems. We then investigate two Bayesian statistical designing protocols, which require 2.3N and 1.9N training patterns, respectively, to achieve error-free inference. If the training patterns are instead designed through deductive reasoning, perfect inference is achieved using N + log2N samples. The performance gap between Bayesian and deductive designing strategies may be shortened in future work by taking into account the possibility of ergodicity breaking in the version space of the binary perceptron.
1 Introduction
The perceptron invented by Frank Rosenblatt in 1957 is probably the simplest artificial neural network.[1] It has N inputs and one output, with each input neuron i affecting the output neuron through a synapse of weight Ti.[2–3] Given an N-dimensional input vector 
The perceptron can serve as a linear classifier. In this scenario, given P patterns 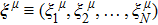
The perceptron can also be studied from the teacher–student perspective, with
The learning performance of the teacher–student perceptron system has been investigated by many authors. In the passive learning mode for which the training patterns are independent and random, it was predicted that perfect (error-free) inference of a binary vector
In this work we address the issue of active learning, which aims at accelerating online inference by carefully designing the training patterns. After the student has encountered P samples and has already gained some knowledge about the truth vector
Although the deductive-logic algorithm certainly outperforms the data-driven Bayesian algorithms, the observation that the Bayesian statistical approach achieves perfect inference of N bits with less than 2N one-bit measurements is still quite encouraging. We expect that the performance of the Bayesian active inference algorithms will be further improved after taking into account the possibility of ergodicity breaking in the version space of the perceptron. If the version space divides into a large number of well-separated clusters, the assumption of Gaussian distribution of the mean field theory will no longer be valid (Sec.
The concept of active (or adaptive) learning has been widely discussed in the fields of education science[28] and optimal experimental design.[29–30] Science itself may also be considered as an active learning process,[29] for which data-inspired intuitive insights, controlled experiments, and deductive reasoning are all indispensable. Artificial deep neural networks are becoming powerful tools for extracting the most important features from huge amount of data,[31–32] facilitating hypothesis formation and experimental design. Recently there has been great enthusiasm in this direction, and efficient active learning algorithms for deep neural networks are start to be explored.[33–36] A lot of work remains to be done on this important issue. From the theoretical side, the binary perceptron may serve as a simple model system to push for the limit of active Bayesian learning. Another basic inference problem which is closely related to the perceptron model is the so-called one-bit compressed sensing problem.[37–38] At the moment only the passive mode of one-bit compressed sensing has been considered in the literature. Beyond the single-layered perceptron and one-bit compressed sensing, the next and more challenging model is the multi-layered binary perceptron system.
2 Inference by Deductive Reasoning
We first show that if the student employs deductive reasoning, online perceptral learning can be made very efficient. At the start of the learning process, the student can simply choose an arbitrary pattern 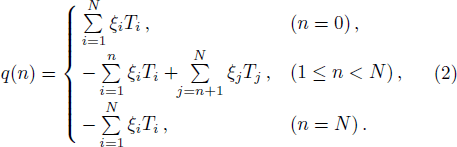
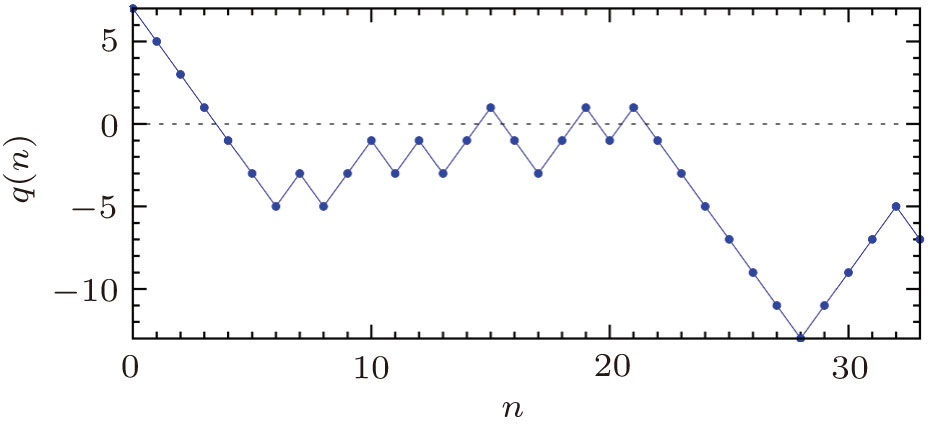
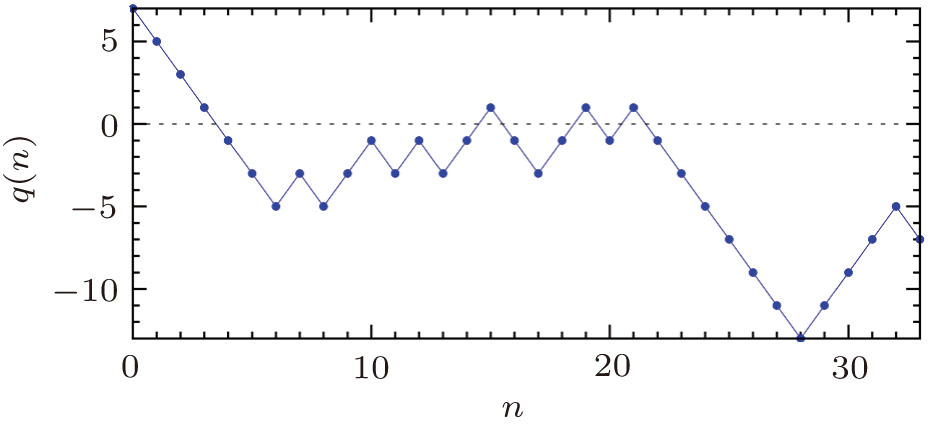 | Fig. 1 An example of the overlap function q(n) for a small perceptron of size N = 33. The random initial binary pattern |
The value of such an integer n* can be determined through at most log2N queries. Starting from nl = 0 and nr = N, the query sequence goes as follows: (i) feed pattern
The value of q(n*), i.e. the overlap between 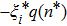
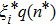
By the above-mentioned deductive reasoning method, the binary weight vector
3 Version Space Minimization
After P training samples 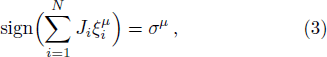
Consider two vectors 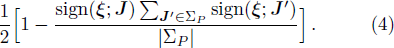
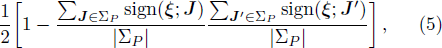
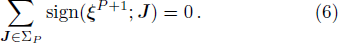
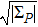
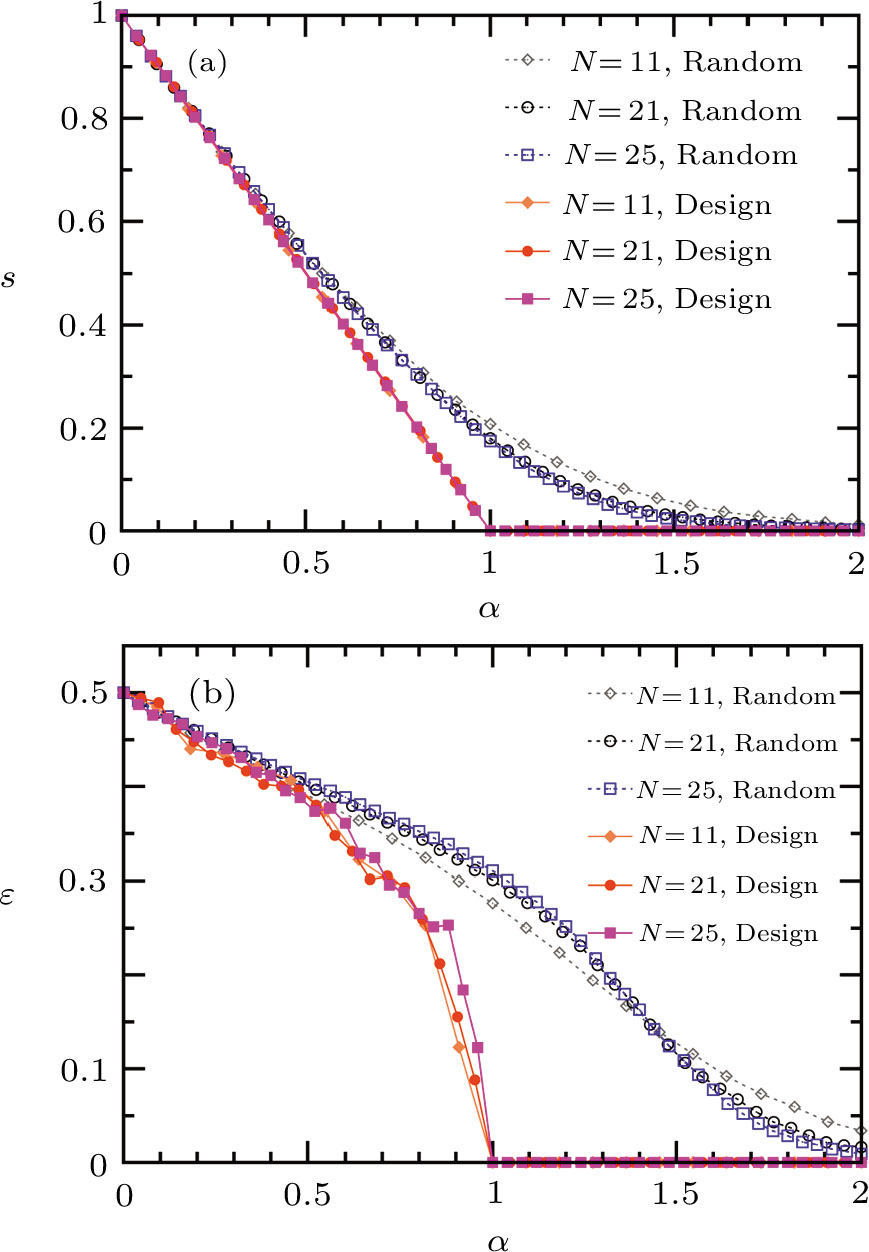
We test the performance of this conceptually simple designing principle on small perceptrons of size N ≤ 25, for which the whole version space can be stored in the memory of a desktop computer. In Fig.
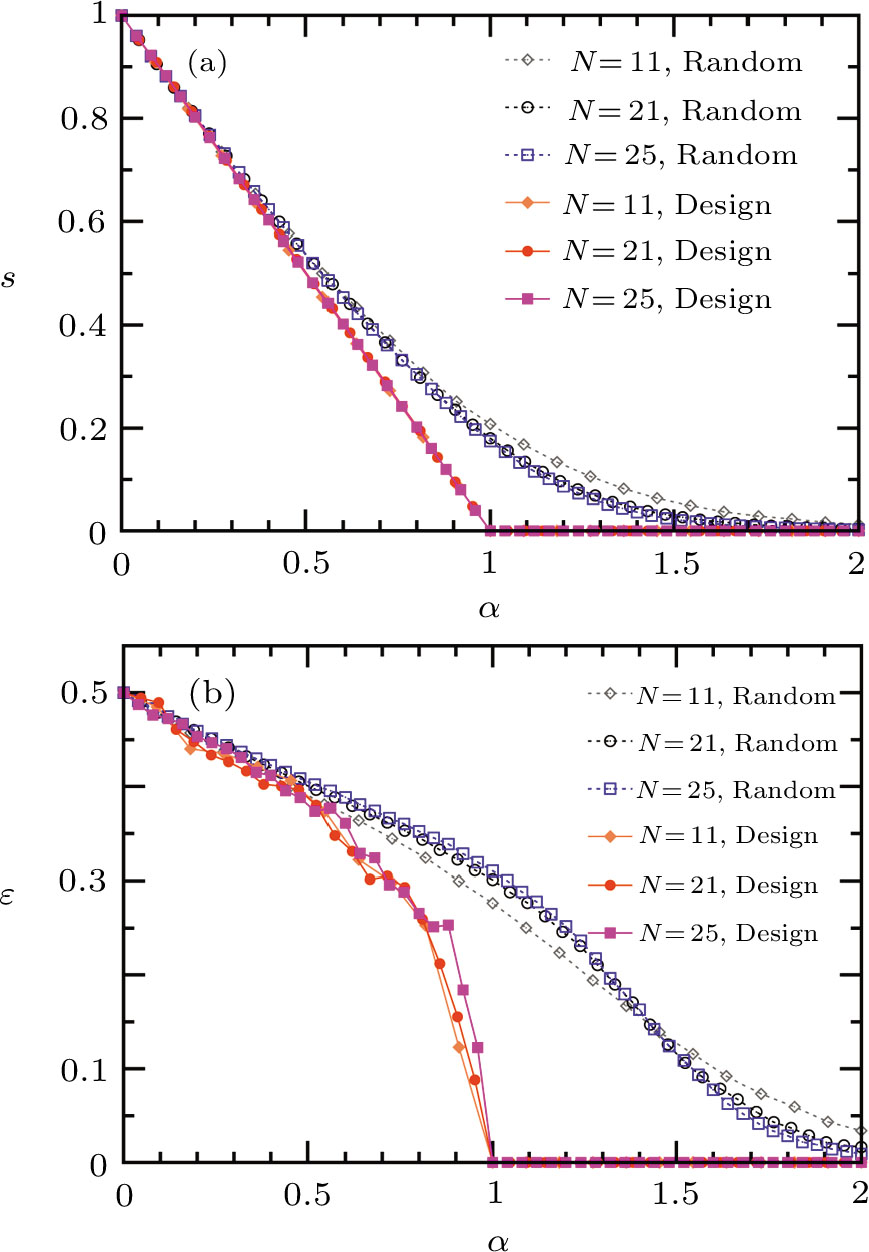 | Fig. 2 The active learning strategy (6) outperforms passive learning on small Ising perceptrons: (a) entropy density s (in units of bit), (b) generalization error ε. Training patterns are added one after another, α = P/N is the instantaneous density of patterns (N is the number of input neurons and P is the number of training patterns). Each data point is obtained by averaging over 1,000 independent runs of the passive (Random) or the active (Design) learning algorithm. |
These simulation results indicate that, in principle, perfect learning using only N training patterns is possible. But directly employing Eq. (
With respect to all the accumulated P training patterns at the end of the P-th learning stage, the volume of the version space ΣP (the partition function) is expressed as
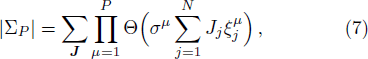
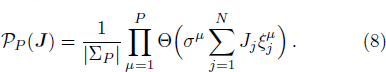
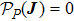
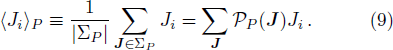
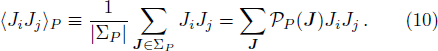
Now consider adding a new training pattern 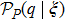
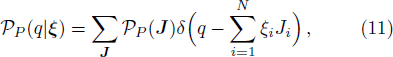
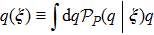
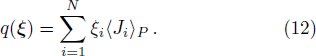
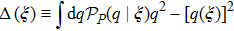
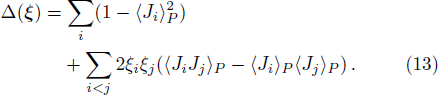
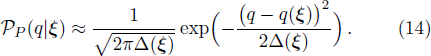
According to the designing principle (6), the (P + 1)-th training pattern should refute half of the weight vectors in ΣP. This means that the overlap between 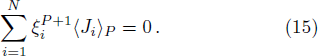
We employ simulated annealing[42] to sample a maximally random pattern 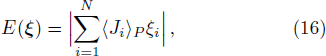
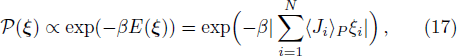
4 Experience Accumulation
To exploit the designing principle (15) we must first compute 〈Ji〉P for all the weight indices i. At P = 0 we know that 〈Ji〉0 = 0 for all the synaptic weights Ji. But the task for P ≥ 1 is quite non-trivial and can not be made exact. In the online learning paradigm we compute 〈Ji〉P approximately by iteration.
After the training pattern 
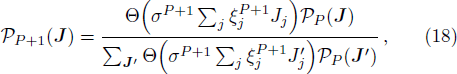
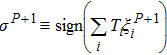
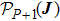
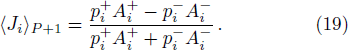
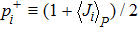
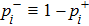
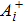
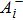
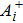
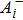
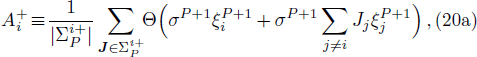
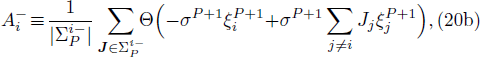
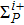
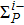
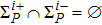
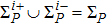
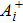
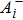
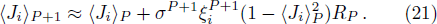
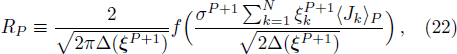
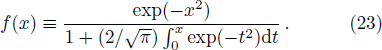
The iterative expression (21) agrees with the belief-propagation equation reported in Ref. [6] (see also Refs. [5,43]). Notice that if 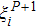
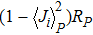
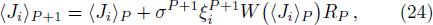
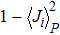
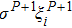
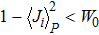
To determine the numerical value of the magnitude factor RP, we need to compute the numerical value of the overlap variance Δ(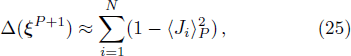
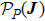
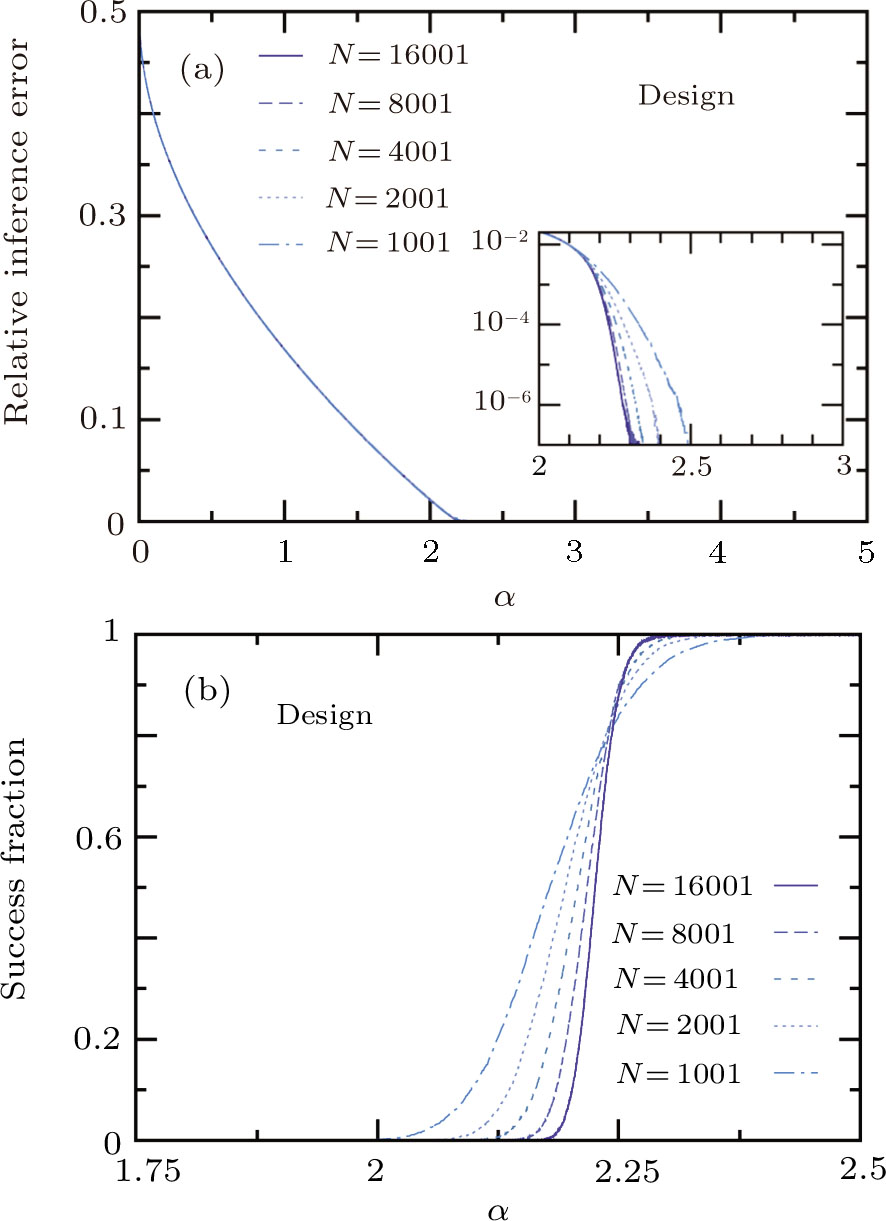
We now test the performance of the simple designing principle (15). The following straightforward inference rule is adopted in the computer simulations: At the end of the P-th learning stage, the inferred truth vector 
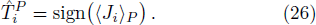
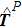
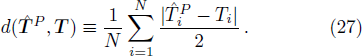
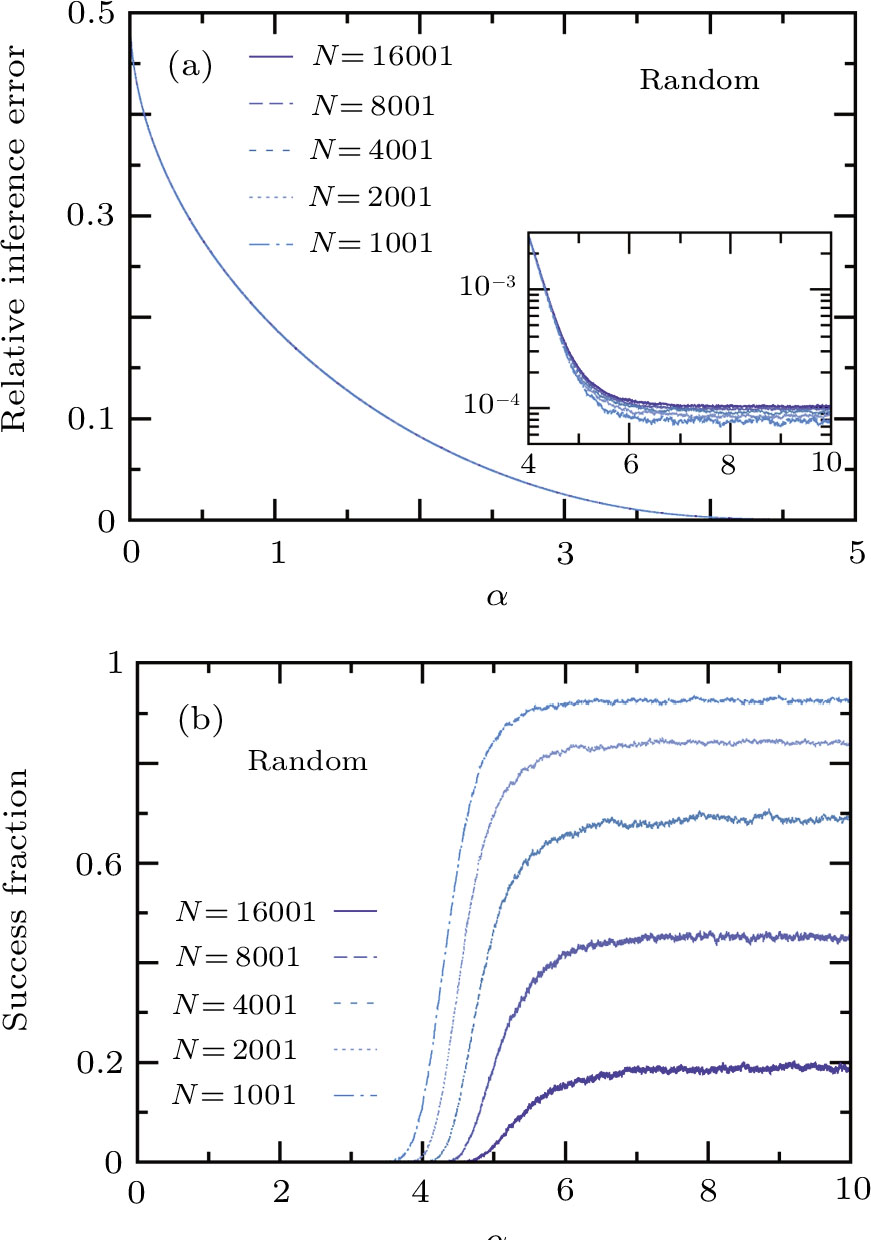
Before testing the active learning mode, we first consider the random passive learning mode, in which every newly introduced training pattern is drawn independently and uniformly at random from the set of 2N Ising patterns. The mean value of the relative inference error of this passive mode, averaged over 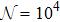
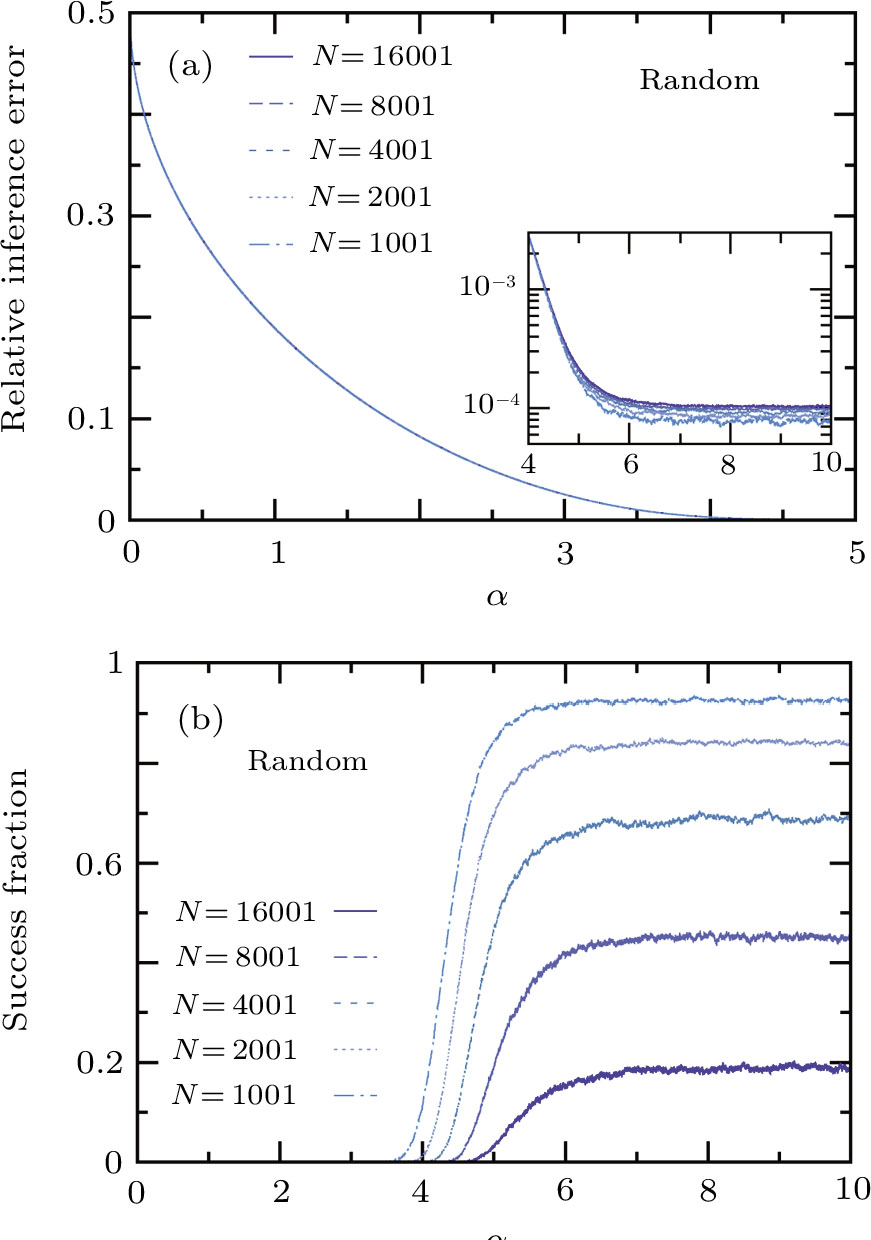 | Fig. 3 The performance of passive online learning. The P training patterns are fed to the student sequentially and they are independent random N-dimensional Ising vectors. The pattern density is α = P/N. The total number of simulated independent online learning trajectories is 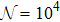 |
As another measure of performance we consider the success fraction, which is defined as the probability that the inferred weight vector 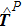
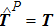
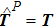
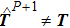
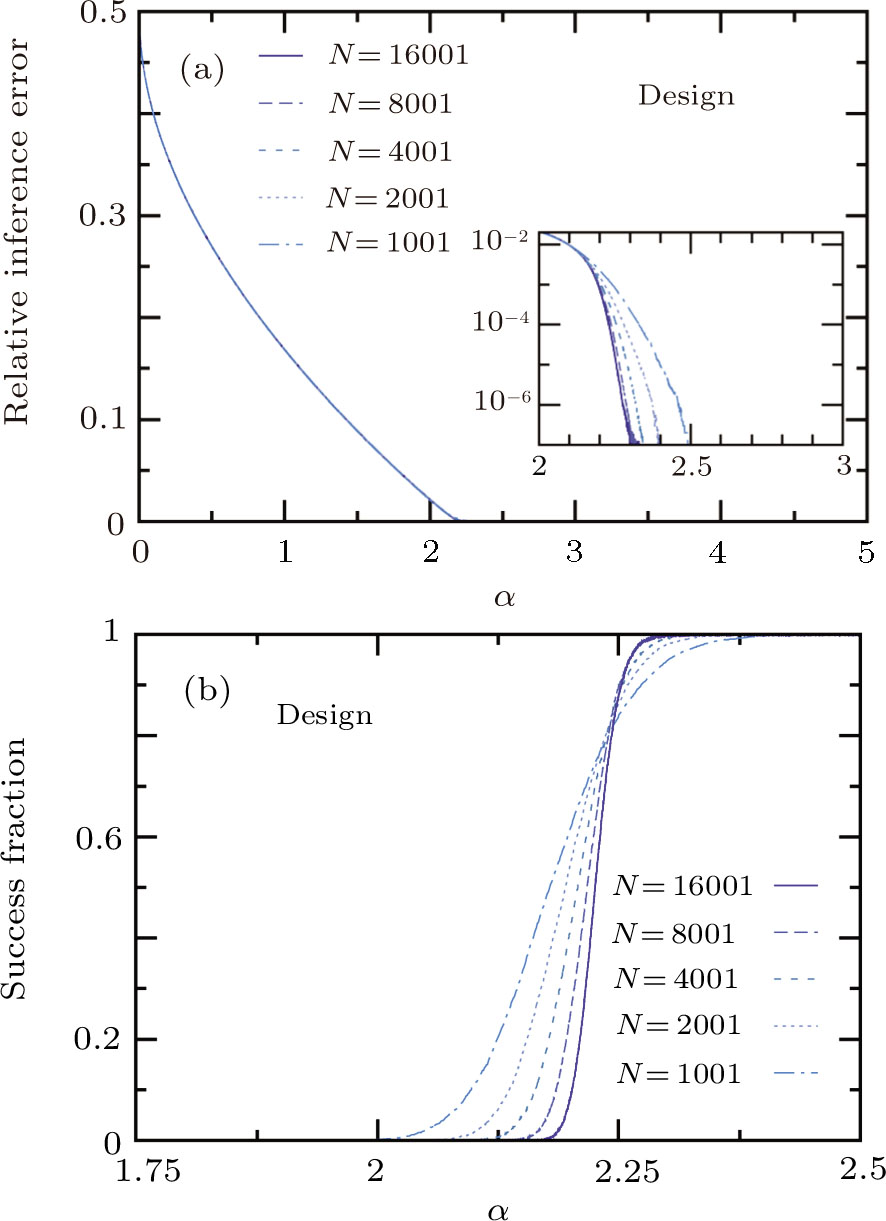
When constraint (15) is imposed in designing each new training pattern, we find that the learning performance is greatly enhanced. As shown in Fig.
 | Fig. 4 Same as Fig. |
5 Additional Orthogonality Considerations
When a new training pattern
To implement these additional orthogonality constraints, we modify the energy function of the simulated annealing process as follows:
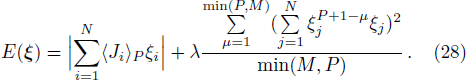
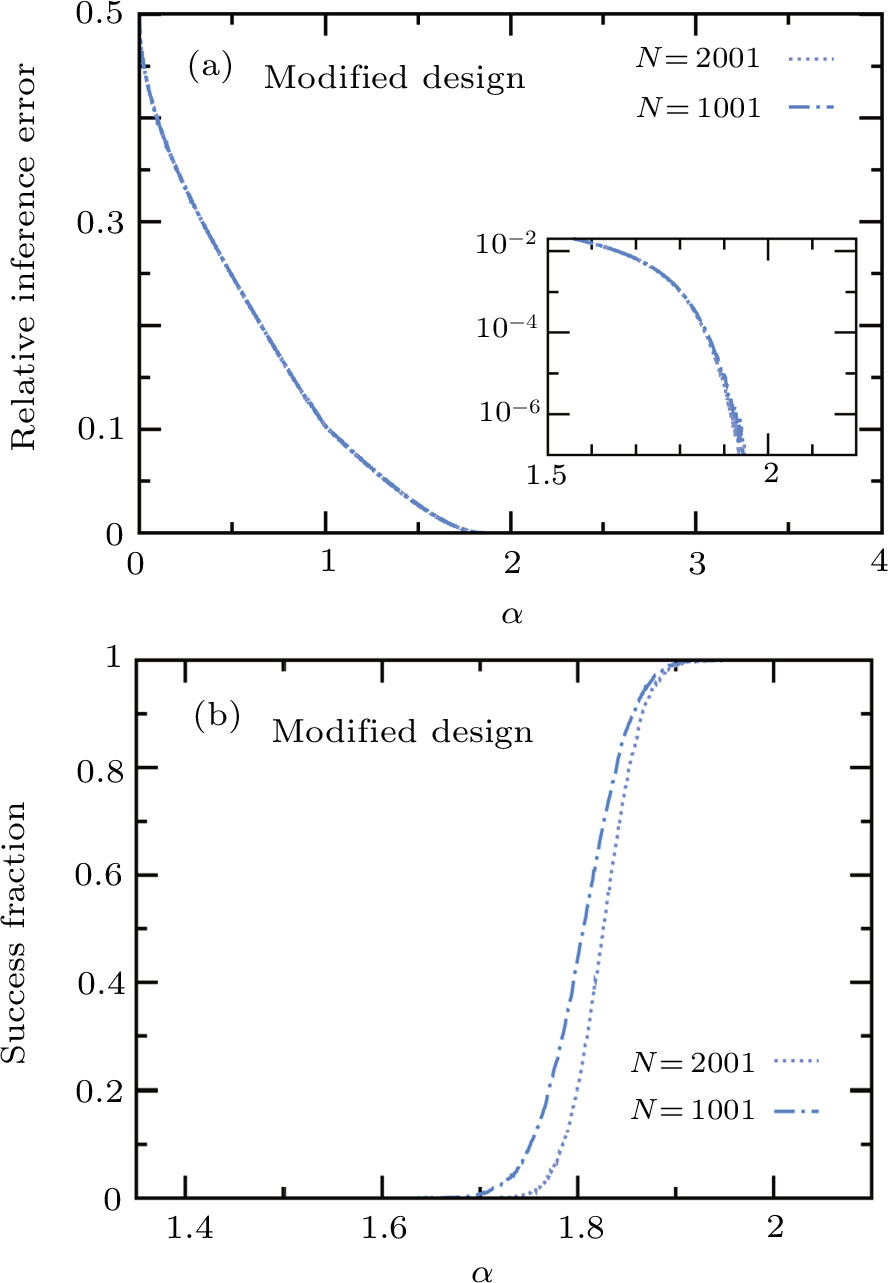
The performance of the modified online learning algorithm is shown in Fig.
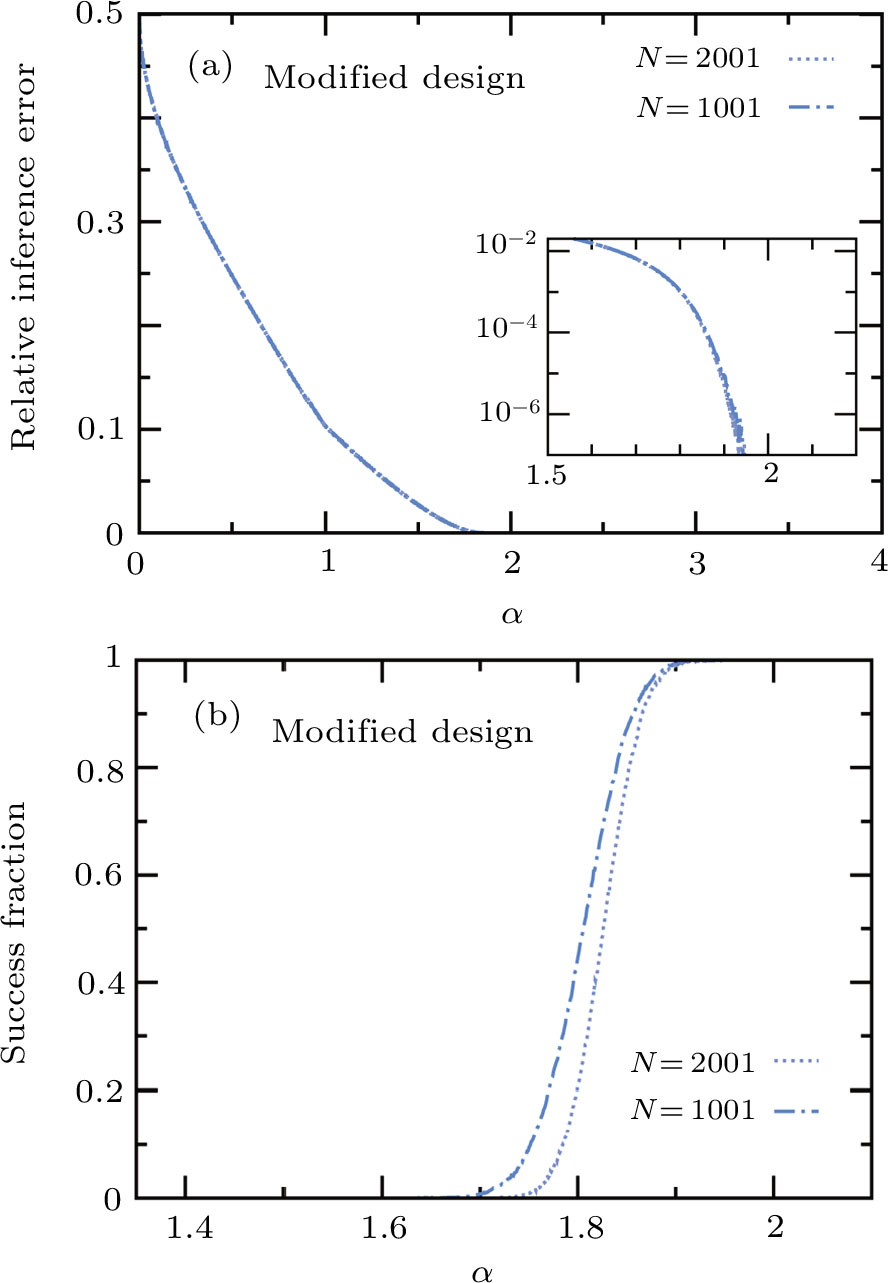 | Fig. 5 Same as Fig. |
It may be possible to further improve the learning performance by optimizing the parameters λ and M of Eq. (
6 Discussion
In this work we considered the Bayesian active learning principle (6) to infer the teacher’s weight vector of an N-dimensional Ising perceptron. Each new Ising training pattern is not randomly drawn as in passive learning but is designed with the aim of splitting the current version space into two equal sub-spaces. This designing principle was exactly implemented for small systems to achieve error-free inference using only N training samples (Fig.
In deriving the constraint Eq. (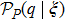
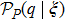
From the academic point of view, active learning in the presence of ergodicity breaking is a very interesting challenge. With an accurate approximation to the overlap probability profile 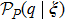
Reference
| [1] | |
| [2] | |
| [3] | |
| [4] | |
| [5] | |
| [6] | |
| [7] | |
| [8] | |
| [9] | |
| [10] | |
| [11] | |
| [12] | |
| [13] | |
| [14] | |
| [15] | |
| [16] | |
| [17] | |
| [18] | |
| [19] | |
| [20] | |
| [21] | |
| [22] | |
| [23] | |
| [24] | |
| [25] | |
| [26] | |
| [27] | |
| [28] | |
| [29] | |
| [30] | |
| [31] | |
| [32] | |
| [33] | |
| [34] | |
| [35] | |
| [36] | |
| [37] | |
| [38] | |
| [39] | |
| [40] | |
| [41] | |
| [42] | |
| [43] | |
| [44] | |
| [45] | |
| [46] |