

|
收稿日期: 2017-11-11; 预印本: 2018-04-10
基金项目: 国家自然科学基金(编号:41571422)
第一作者简介: 樊东东,1992年生,男,硕士研究生,研究方向为农业遥感分类、空间数据挖掘。E-mail:fandd@radi.ac.cn
通信作者简介: 李强子,1970年生,男,研究员,研究方向为农业遥感与生态遥感。E-mail:liqz@radi.ac.cn
|
摘要
训练样本质量是决定农作物遥感识别精度的关键因素,虽然高空间分辨率卫星的发展有效地解决了农作物遥感识别过程中的混合像元问题,但是当区域内不同作物种植面积差异较大时,训练集中不同类别样本数量往往相差较大,这样的不均衡数据集影响分类器的训练,导致少数类别的识别精度不理想。为研究作物遥感识别过程中的不均衡样本问题,本文基于GF-2号卫星数据,首先挖掘了地物的光谱信息、纹理信息,用特征递归消除RFE (Recursive Feature Elimination)方法进行特征优选,然后从数据处理的角度采用了5种采样算法对不均衡训练集进行处理,最后使用采样后的均衡数据集训练分类器,对比数据采样前后决策树与Adaboost(Adaptive Boosting)两种分类器的识别结果,发现:(1)经过采样处理后两种分类算法明显提升了小宗作物的分类精度;(2)经过ADASYS (Adaptive synthetic sampling)采样处理后,分类器性能提升最多,决策树的Kappa系数提高了14.32%,Adaboost的Kappa系数提高了10.23%,达到最高值0.9336;(3)过采样的处理效果优于欠采样,过采样对分类器的性能提升更多。综上所述,选择合适的采样方法和分类方法是提高不均衡数据集遥感分类精度的有效途径。
关键词
作物识别, 不均衡数据集, 采样, 遥感, 小宗作物, (GF-2)高分二号
Abstract
The rapid development of high-spatial-resolution satellites has effectively alleviated the problem of mixed pixels in satellite images, thereby enabling extraction of the meticulous distribution of crops from them. The classification of remote sensing images is a quick way to obtain accurate agricultural information. However, the accuracy of supervised classification using remote sensing images is affected by several factors, such as classifier algorithm and input datasets. The imbalanced training samples, which indicates the number of training samples of some categories is considerably smaller or larger than the others, often results in poor classification accuracy for the minority classes. To improve this situation and generalization performance of classifier, this research focused on proper utilization of resampling techniques and classification methodologies for achieving perfect performance of remote sensing image classification. We investigated the aforementioned images by data mining approaches including spectrum and texture features and selection of optimized features based on recursive feature elimination. Then, five resample methods, namely, three over-resampling methods and two under-sampling methods, were separately used to balance the initial training datasets. Finally, we tested the resampled datasets by utilizing two classifiers (decision tree and AdaBoost) and evaluated the performance of each one in terms of kappa coefficient, overall accuracy, producer’s accuracy, and user’s accuracy. The overall classification accuracy and kappa coefficient improved considerably on decision tree (14.32%) and AdaBoost classifier (10.23%) after resampling. The AdaBoost obtained the highest value of kappa coefficient (0.9336) by using the training dataset resampled with ADASYN. The accuracy of classification on minority crops was also increased by resampling training datasets. Meanwhile, feature selection results showed that vegetation and texture indexes were more efficient than features of original reflection ratio to classification. Over-resampling methods had advantages in relieving the influence of imbalanced training samples to classifiers. Resampling process to training datasets has remarkable advantage in improving the classifier performance if the training datasets are critically imbalanced. The detailed accuracy assessment shows that over-resampling method is more excellent than under-resampling. The reason is that some significant samples are lost during under-resampling, but helpful and useful information is added after over-resampling. AdaBoost classifier performs better than decision tree in terms of solving imbalanced training datasets. Combination of proper resampling approaches and compatible classifier can significantly improve the accuracy of minority classes in the situation of imbalanced dataset classification.
Key words
crops recognition, imbalanced datasets, resampling, remote sensing, minority crops, GF-2
1 引 言
农作物种植面积是作物估产和国家宏观调控的决策信息基础,掌握精准可靠的作物种植面积信息尤为重要(刘克宝 等,2014)。遥感技术可以快速的获取作物种植分布和种植面积等农情信息,对农情监测具有重要意义(Haboudan 等,2002;Harris,2003;Metternicht,2003;Arenas-Toledo和Epiphanio,2011;Rilwani和Ikhuoria,2011)。提高农作物的遥感识别精度不仅有利于得到精细的作物空间分布信息,还可以为精准农业补贴,农业灾害定损服务(吴炳方 等,2004a)。
目前利用遥感识别农作物主要是采用监督分类方法来实现。在监督分类过程中,通过计算训练样本中不同类别在特征空间中的统计信息,建立判别规则对未知像元进行划分。因此监督分类对训练样本的数量和质量具有极强的依赖性,充足且具有代表性的样本能为分类模型提供不同类别的特征差异信息,进而得到更高精度的分类结果。许多研究发现“高质量的样本”对精度的影响超过了分类器本身(Hixson 等,1980;Foody和Mathur,2006)。
小宗作物在中国一般是指在部分地区与广泛种植的农作物相比种植面积较少的农作物。目前国内农作物遥感识别研究多关注水稻、小麦、玉米和大豆等大宗作物,而往往忽视了小宗作物,无法获取全面的农作物种植结构信息(李强子和吴炳方,2004)。提高小宗作物遥感识别精度有利于获取准确的作物空间种植结构信息(胡琼 等,2015)。小宗作物提取精度较低的主要原因之一是中低分辨率影像在作物种植结构复杂区域(如小宗作物种植地块面积小且和大宗作物插花种植)混合像元问题严重,小宗作物的信息往往被大宗作物信息吞噬(刘佳 等,2015),或者在影像上反映不明显,导致小宗作物的提取精度很不理想(吴炳方 等,2004b),高空间分辨率数据不仅有效缓解了混合像元问题,而且能够充分表达地物的邻域空间关系,有利于小宗作物的精细化识别。然而我国地形复杂,地块破碎,多种耕地类型和种植结构并存,导致小宗作物和大宗作物样本数量规模往往相差悬殊,出现不同地物训练样本数量严重不均衡的问题。
研究表明训练样本中不同作物样本数量的不均衡是影响作物识别精度的重要因素之一(吴健平和杨星卫,1996;朱秀芳 等,2007)。丁萧研究了混种区域作物种植面积的大小及分类样本数量对分类精度的影响,结果发现作物种植面积小以及样本数量少都会降低小宗作物的识别精度(丁潇,2014)。虽然神经网络分类(Murthy 等,2003;Sarkar 等,2008),支持向量机(Mathur和Foody,2008;Tan 等,2011;Chen 等,2012),随机森林(Sonobe 等,2014),集成方法(Rätsch 等,2001;Tumer和Oza,2003;Punera和Ghosh,2008)等被广泛用于遥感分类,并且在样本数量均衡时都有良好的分类精度,但是这些算法面对复杂的不均衡数据集时难以发挥优势(Shukla 等,2018)。目前提高不均衡数据集的分类精度主要是通过数据采样处理与改进分类算法。Garcia等利用主成分分析PCA (Principal Component Analysis)和合成少数类过采样方法SMOTE (Synthetic Minority Over-sampling Technique)来改善优势类别和劣势类别的不均衡度从而提高分类精度(García 等,2011)。Waske等(2009)通过集成多个支持向量机分类器提高了小宗作物的识别精度。这些结果表明可以从样本采样和分类算法两个方面来提升样本不均衡时小宗作物的识别精度。
为研究采样处理对提高小宗作物分类精度的潜力,本文分析了5种采样算法对小宗作物识别精度的影响,从而建立兼顾小宗作物识别精度的农作物遥感识别方法。具体目标包括:(1)分析比较采样处理方法对农作物遥感识别精度的影响,并重点关注小宗作物的遥感识别精度。(2)评价不同采样方法对样本不均衡问题的改善效果,得到最佳采样方法。(3)分析不同分类算法对不均衡训练样本采样处理的敏感性。
2 实验区概况
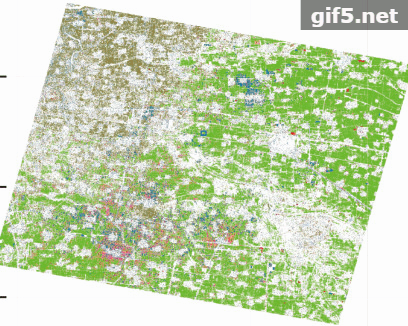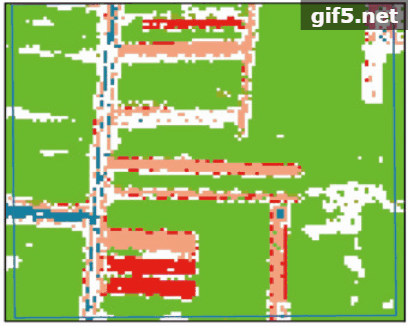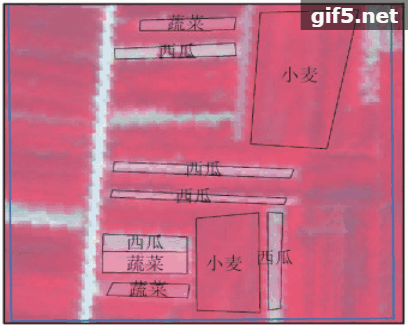
本研究选择安徽省宿州市西北部砀山县与箫县交界地区为实验区(图1)。该区域地处黄淮海平原中南部,属暖温带半湿润季风气候,四季分明,光照充足,年平均气温14.3℃,无霜期约210天,年平均降水量约880 mm。其中粮食作物主要有小麦、玉米,经济作物主要有棉花、花生、蔬菜、西瓜。实验区作物种植结构复杂,西部主要为梨树种植区,并有小量的小麦和西瓜种植,东部主要为冬小麦种植区,并有零星的葡萄、蔬菜等小宗作物种植。实验区5月份主要作物包括小麦、梨树、蔬菜、西瓜等,不同作物种植面积相差较大。当利用遥感识别农作物时,获取充足的小宗作物样本较为困难。
3 数据与预处理
3.1 遥感数据获取及预处理
本研究使用GF-2卫星多光谱数据,数据获取时间为2017-04-30。GF-2卫星于2014-08-19号发射,太阳同步回归轨道,轨道高度631 km,倾角97.9080°,详细波段信息见表1。
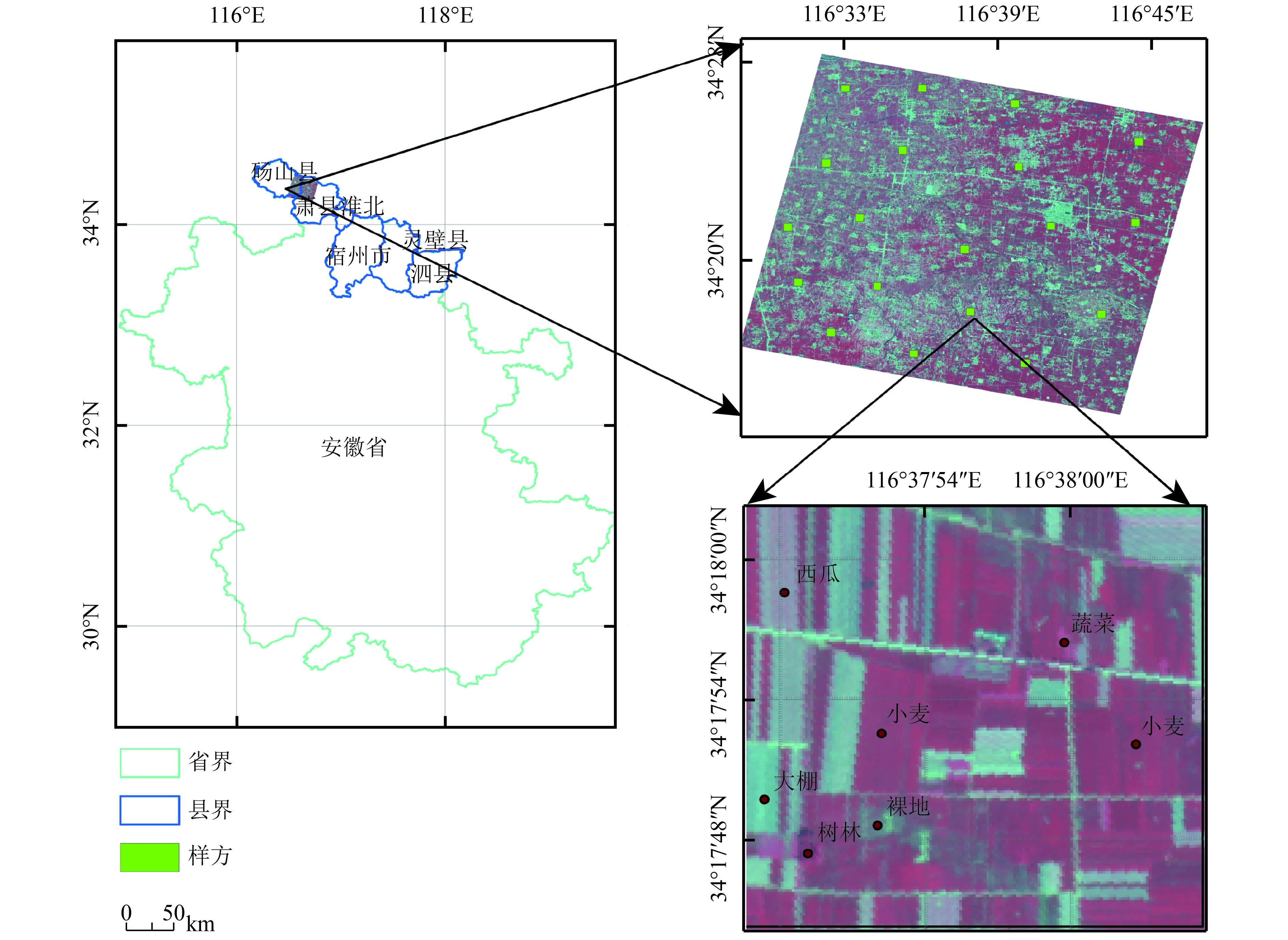

表 1 GF-2卫星参数信息
Table 1 Basic parameters of GF-2 satellite
| 主要载荷 | 波段号 | 波段名称 | 波谱范围/μm | 空间分辨率/m |
| 全色多光谱相机 | 1 | 全色 | 0.45—0.90 | 1 |
| 2 | 蓝波段 | 0.45—0.52 | 4 | |
| 3 | 绿波段 | 0.52—0.59 | 4 | |
| 4 | 红波段 | 0.63—0.69 | 4 | |
| 5 | 近红外 | 0.77—0.89 | 4 |
遥感数据的预处理主要包括辐射校正,几何校正和特征参数计算。辐射校正的目的在于消除电磁波传输过程中大气的影响,获取地面的真实光谱反射率,其中辐射定标就是将卫星各载荷通道观测值转化为等效辐射亮度。公式为
式中,Gain为卫星传感器的增益值,Bias为卫星传感器的补偿值(偏置),DN为遥感影像的灰度值。其中的辐射定标参数来源于中国资源卫星应用中心官网,大气校正采用FLAASH模型。
为了提高农作物的识别能力,本研究在4个原始波段反射率的基础上计算了9种植被特征指数、2种水体指数(表2,其中Rb、Rg、Rr和Rnir分别代表蓝、绿、红和近红外波段的反射率),4个波段的8种纹理指数总共47个特征参数。特征详细信息如下:
光谱特征:蓝、绿、红和近红外波段的反射率B1、B2、B3和B4。
植被指数特征:归一化植被指数NDVI(Normalized Difference Vegetation Index)、三波段梯度差值植被指数TGDVI(Three Gradient Difference Vegetation Index)、土壤调节植被指数SAVI(Soil Adjusted Vegetation Index)、比值植被指数RVI(Ratio Vegetation Index)、红色植被指数RI(Red Vegetation Index)、转换型植被指数TVI(Transformed Vegetation Index)、差值植被指数DVI(Difference Vegetation Index)、归一化差异绿度指数NDGI(Normalized Difference Green Index)、修改性土壤调节植被指数MSAVI(Modified Soil-Adjusted Vegetation Index)。
水体指数特征:水体指数NDWI(Normalize Difference Water Index)、高斯归一化水体指数GNDWI(Gaussian Normalized Difference Water Index)。
纹理特征:基于灰度共生矩阵GLCM(Grey-Level Co-occurrence Matrix)(Haralick 等,1973)计算窗口大小为3×3的均值(Mean)、方差(Variance)、同质性(Homogeneity)、对比度(Contrast)、相异度(Dissimilarity)、信息熵(Entropy)、二阶距(Second Moment)和相关性(Correlation)。
表 2 植被和水体指数计算公式
Table 2 Vegetation and water index
| 指数 | 计算公式 |
| NDVI |
|
| SAVI |
|
| RVI |
|
| RI |
|
| TVI |
|
| DVI |
|
| NDGI |
|
| MSAVI |
|
| NDWI |
|
| GNDWI |
|
为了消除这些特征量级对采样算法和分类算法的影响,同时加快模型参数优化的效率,本研究采用min-max标准化方法对这47个特征进行了处理,将每个特征线性拉伸到0—255的数值范围。
3.2 地面调查数据
为获取遥感作物识别的先验知识并支持实验研究的分类精度验证工作,于2017年5月4日—5月10日对实验区的作物类型进行了地面调查。
实际调查过程中,遵守均匀分布和代表性的原则共设定了19个地面调查样方(图1),样方大小为600 m×600 m。通过野外GPS定位进行对每个样方内作物类型种植范围标记,用以建立解译标志,获得小麦、梨树、西瓜与蔬菜的种植地区共135个。在室内结合地块作物类型及GPS坐标范围勾画训练区与验证区。
本研究根据调查结果分别随机选取训练样本和验证样本,训练集与验证集样本个数比例为3∶1。本文在像元尺度进行作物识别,其中训练样本中各个类别的样本(像元)数量如表3,大宗作物与小宗作物的样本数量差异较大,不均衡问题突出。
表 3 训练集中不同类别的样本个数
Table 3 The number of different categories in training datasets
| 目标类别 | 样本个数 | 样本比重/% |
| 小麦 | 24992 | 47.88 |
| 梨树 | 7491 | 14.35 |
| 裸地 | 3990 | 7.64 |
| 水体 | 2491 | 4.77 |
| 建筑 | 2012 | 3.85 |
| 森林 | 2887 | 5.53 |
| 西瓜 | 3992 | 7.65 |
| 大棚 | 2998 | 5.74 |
| 蔬菜 | 1349 | 2.58 |
| 样本总数 | 52202 | 100.00 |
4 研究方法
本研究基于地面调查资料选取不同地物类别的训练样本,首先利用RFE(Recursive Feature Elimination)进行特征优选得到最佳特征组合,然后对训练集采样处理,最后对分类器精度进行评价。
为改善训练样本中不同类别之间样本数量规模差异大的问题,本研究采用对少数类进行过采样和对多数类进行欠采样两种处理方式,使用采样后的相对均衡的数据集对分类器进行训练。
为了增加实验结果的可靠性,本研究采用决策树和Adaboost(Adaptive Boosting)两种分类算法,基于验证集对分类模型的性能进行评价,分析采样算法对分类精度的影响。本文实验方法流程图如图2所示。
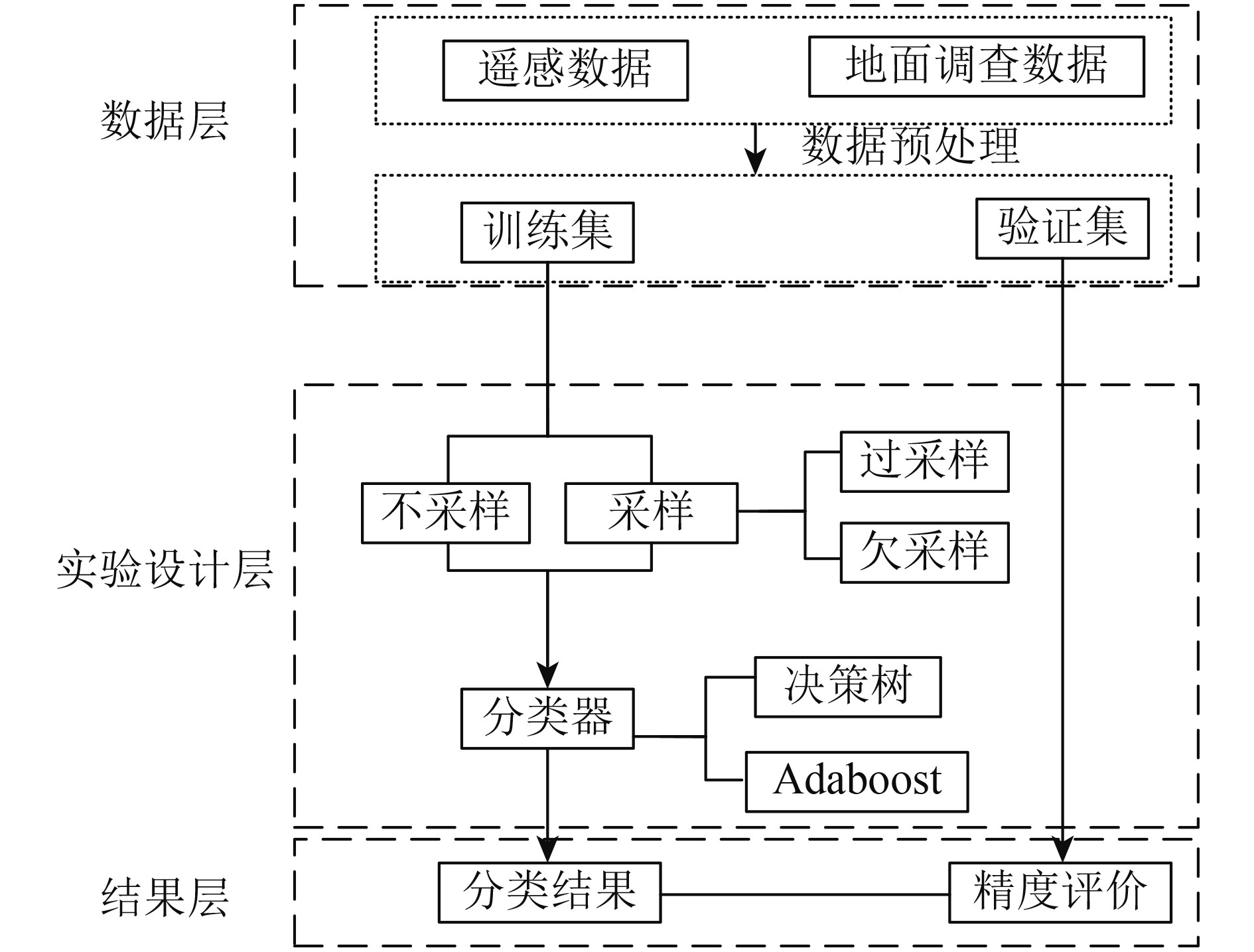
4.1 特征优选方法
选择合适的特征变量是提高作物识别精度的有效途径(贾坤和李强子,2013)。特征筛选可以去除与分类不相关的信息,或者在保证模型精度达到一定要求的前提下,寻找出最优的特征集合(黄东山,2011)。为了去除冗余和对模型贡献不大的无关特征,避免采样处理过程产生不利信息,本研究利用RFE选取最佳的分类特征组合。
RFE是一种寻找最优特征子集的贪心算法,在分类时用于特征选择取得了比较理想的结果(Cutler 等,2007)。RFE主要是通过循环移除特征变量和反复建立模型,利用模型的精度来评价特征的优劣,选出最差的特征,然后在剩余的特征集重复这个过程,直至遍历所有的特征,最后得出最有效的特征组合。本文采用了scikit-learn的RFE模块实现特征消除,并使用RFECV模块来进行交叉验证对特征进行排序。
4.2 不均衡训练数据采样方法
传统分类器大多假设训练数据集中各个类别的数量均衡,且各个类别错分代价也相同,但是不均衡数据集中不同类别的样本数目相差较大,然而分类模型常使用经验风险最小作为学习准则,难以学习到如何判别少数类别。因此对不均衡数据集进行采样处理,降低多数类别的样本数量或者增加少数类别的样本数量,可以解决上述问题从而提高算法的分类性能(Elhassan 等,2017)。
常用的采样方法包括过采样和欠采样。过采样是通过算法合成新的少数类别从而增加少数类的数目,欠采样是通过一定算法移除多数类的一些样本,两者最终目的都是使不同类别样本数量达到相对均衡。本研究选取了3种过采样方法、两种欠采样方法来改变训练集的多数类和少数类的样本数量以获得均衡的训练集,用于后续的分类器训练,并用原始不均衡数据集作为对比,采样方法名称如表4。
本研究采用了ADASYN(Adaptive synthetic sampling)、SMOTE(Synthetic Minority Over-sampling Technique)与Borderline-SMOTE 3种方法对少数类别样本进行过采样处理。过采样方法中最简单的方法就是对数据进行复制,但是这些信息会导致分类器学习的规则具体化,导致过拟合现象。人工合成数据的SMOTE是由Chawla等(2002)提出的一种利用训练数据集中少数类别数据的相似性进行局部插值来产生新样本的过采样方法,SMOTE算法假设特征空间中少数类别之间还是少数类别,通过不断合成少数类别样本来使少数类与多数类的样本数量达到平衡,不仅有效解决了数据不均衡的问题,同时避免了分类器的过拟合问题。自适应合成抽样(ADASYN)是由He等(2008)提出的一种自适应采样算法,该算法能根据分类的难易程度自动调整生成样本的个数,提高少数类别在边界的密度。所以ADASYN不仅能够提供平衡的数据集,而且能够聚焦难以学习的少数类类别。Borderline-SMOTE是一种改进的SMOTE算法(Han 等,2005),它只为“边缘处”的少数类别合成样本,不仅能够避免类之间的重叠性,而且生成的少数类能提供更有益的信息。
表 4 采样方法
Table 4 The resampling methods
| 方法名称 | 采样方法编号 | |
| 原始数据集 | NON-resample | 1 |
| 过采样 | ADASYN | 2 |
| SMOTE | 3 | |
| Borderline-SMOTE | 4 | |
| 欠采样 | ENN | 5 |
| NCL | 6 |
本研究采用了最近邻规则ENN(Edited Nearest Neighbor)和邻域清理NCL(Neighborhood Cleaning Rule)两种算法对多数类别进行欠采样处理。欠采样算法中最简单的就是随机删除多数类别的Random Under-sample算法,即随机丢弃一些多数类样本,但是这种算法容易丢失多数类的重要信息。ENN是由Wilson(1972)提出的一种考虑样本分布的欠采样算法(Edited Nearest Neighbor),该算法只删除那些与最近3个临近样本中两个以上都不相同的多数类,以此来减少多数类的样本使数据达到平衡。NCL是由Laurikkala在ENN基础上提出的一种欠采样算法(Laurikkala,2001)。该算法主要思想是针对训练集中的每个样本与3个最近邻样本进行分析,如果这个类别是多数类,但是它3个最近邻域中两个以上是少数类别,则删除这个样本,如果这个样本是少数类,但是它3个最近邻域中两个以上是多数类别,则删除邻域中的多数类别。
4.3 分类实验
本研究选取决策树和Adaboost两种分类器进行实验区农作物识别,并分析这两种分类算法在不同采样处理前后对作物识别的整体效果以及小宗作物的识别精度。
决策树是通过信息增益(ID3算法)、信息增益比(C4.5算法)或Gini指数(CART算法)对每一个节点选择最佳分类属性或属性组合来进行构建分类树的监督学习分类方法,在遥感分类中只要选择合理的地物特征组合就能将地物区分开(刘晓娜 等,2011)。ID3算法对训练集中样本数目敏感,在节点选取时偏好可取数量较多的属性,因此ID3对不均衡数据集比较敏感,本文选用ID3决策树来比较采样处理的效果。
Adaboost是一种迭代算法,其核心思想是通过集成对同一个训练集得到的若干个弱分类器然后得到一个强分类器,通过不断迭代增加错分样本的权重,进行下一次训练,最后融合所有的分类器作为最终的分类器(曹莹 等,2013)。由于其在分类过程中可以更新错分样本的权重,所以可能对不均衡数据集敏感度较低。本研究采用决策树作为Adaboost的弱分类器,弱分类器的个数为500个。
4.4 精度评价
本研究基于验证集中样本的真实类别和分类器对样本的预测类别获取混淆矩阵,在此基础上计算
| ${\rm{User.ACC}}_i = \frac{{{n_i}}}{{{N_i}}}\;\; {\rm{Proc.ACC}}_i = \frac{{{n_i}}}{{{M_i}}}$ |
| $ Kappa = \frac{{N\sum\limits_{i = 1}^m {{M_i} - \sum\limits_{i = 1}^m {({M_i}\times{N_i})} } }}{{{N^2} - \sum\limits_{i = 1}^m {({M_i}\times{N_i})} }} \;\;{P_{\rm{c}}} = \frac{{\sum\limits_{k = 1}^m {{P_{kk}}} }}{N}$ |
式中,User.ACCi表示类别i的用户精度,Ni表示分类器预测为类别i的像元总数,ni表示预测为类别i中实际为类别i的像元个数。Proc.ACCi表示类比i的制图精度,Mi表示验证样本中类别i的像元总数,m表示类别的个数,Pc表示总体精度,N表示样本总个数。
混淆矩阵(Confusion Matrix)是一种表示某一类别的像元个数和地面真实检验为该类别个数的比较矩阵,通过混淆矩阵计算得到的总体精度、Kappa系数、用户精度与制图精度等参数常用来评价像元尺度的分类精度,其中Kappa系数能够描述分类器的整体性能,用户精度和制图精度可以评价某一类别的分类好坏(赵英时,2003)。
5 结果与分析
5.1 最佳特征优选结果
本研究利用RFE方法选择出最佳特征子集,并且利用随机森林分类器得出最佳特征组合中各特征的重要性分数。基于测试数据集绘制了最佳特征组合个数与总体精度、Kappa系数的关系,如图3所示。
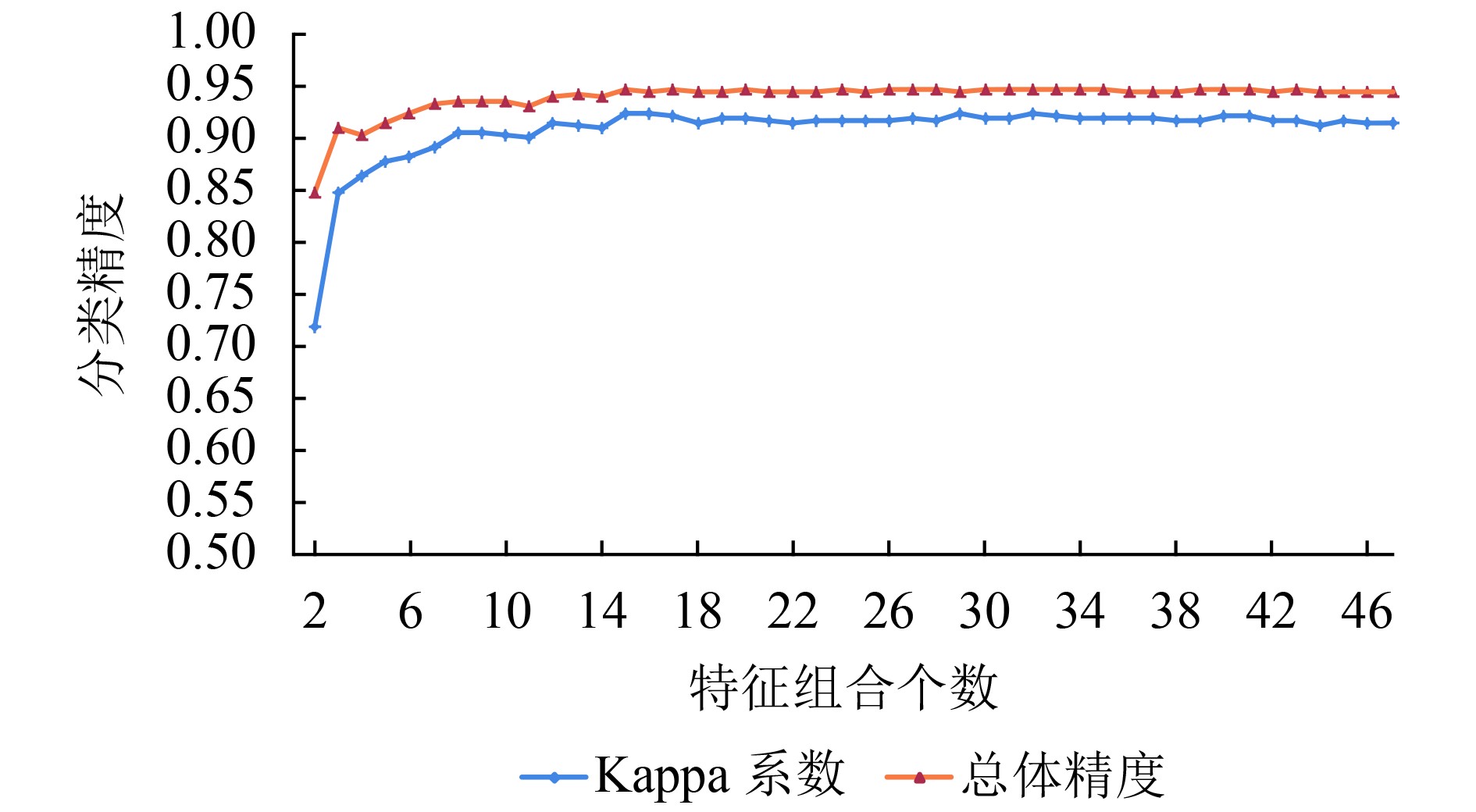
从特征筛选的过程曲线中发现随着特征数量的增加,分类效果并不是持续改善。当特征数量为15时,随机森林分类的总体精度和Kappa系数值就已经达到了最大,之后特征数量的增加并未有效提升分类精度。因此本研究确定最佳特征个数为15。随机森林在训练过程中可以得出特征的重要性分数(图4)。
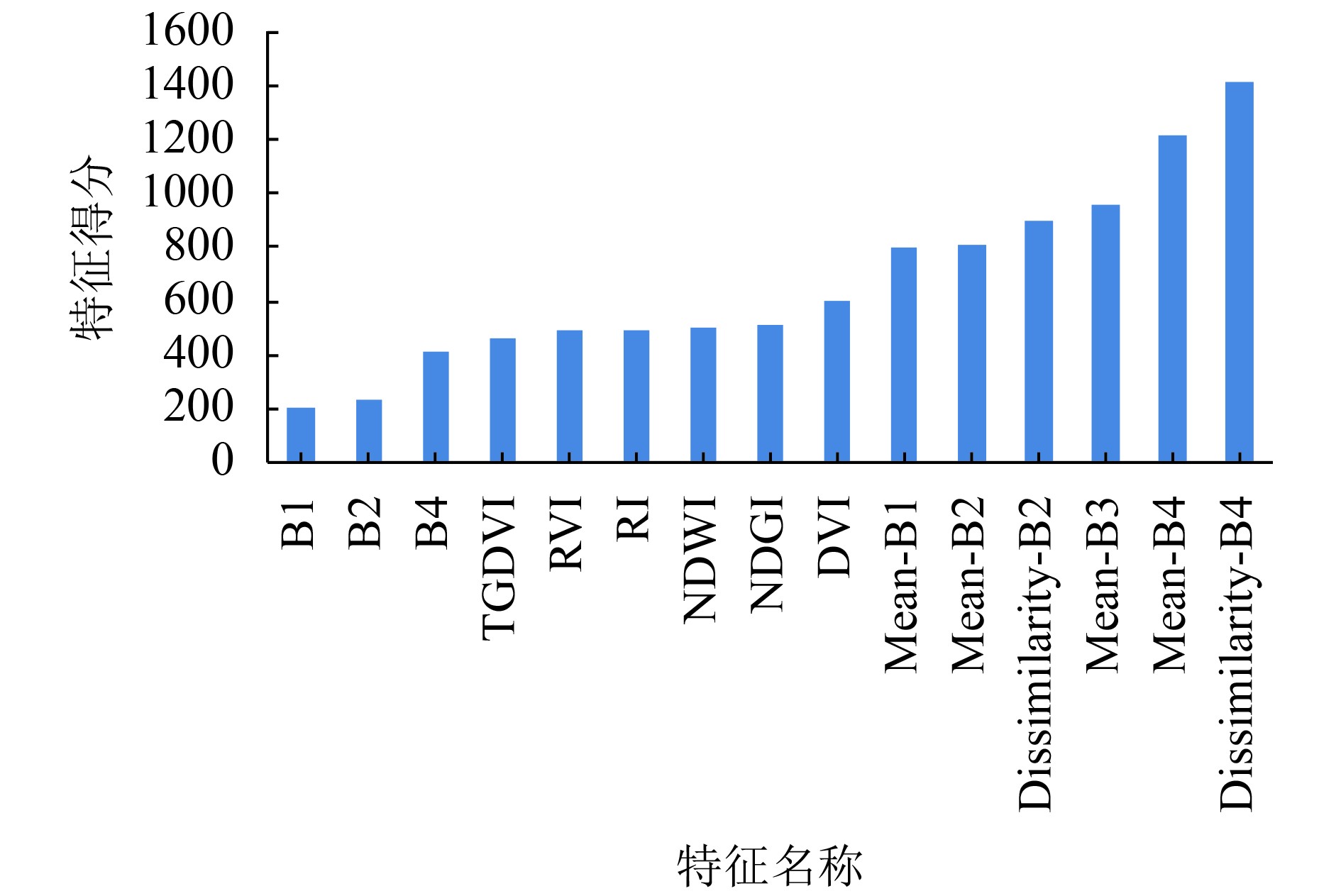
从特征重要性得分可以发现,对于研究区的夏粮作物来说,纹理指数比光谱指数的得分更高,且纹理指数中近红外的相异度得分最高,其次是近红外的均值。最佳特征组合中原始波段的反射率得分最低,植被指数得分介于反射率和纹理特征之间。这充分说明了高分辨率数据挖掘地物的光谱信息和空间纹理信息的必要性。
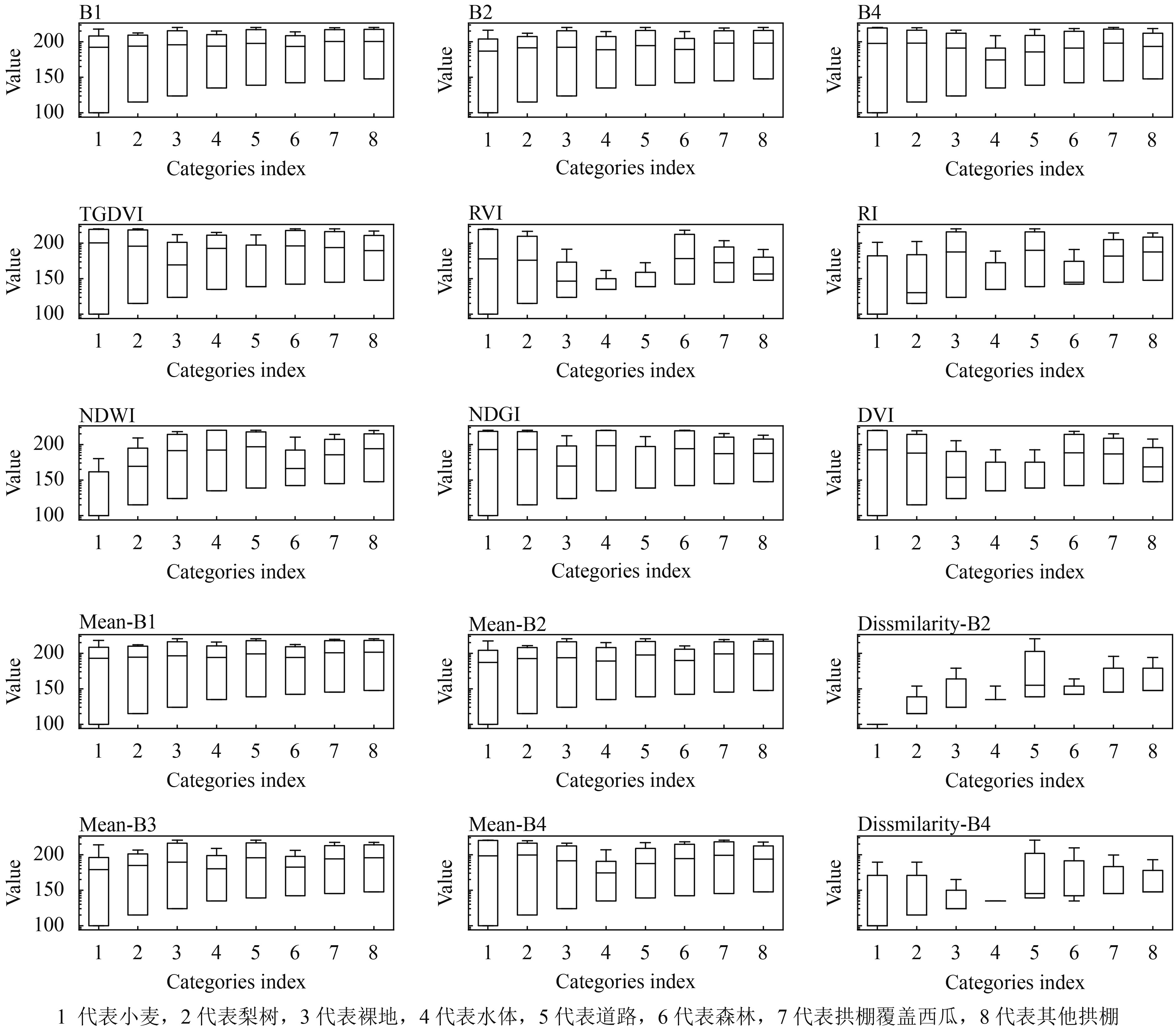
通过分析训练集中8种地物在最优特征空间的数值分布(图5),发现特征对地物的可分离度决定了其自身的重要性。地物在Dissmilarity-B2、Dissmilarity-B4数值分布差异较大,这些特征重要性得分也比较高。小麦在Dissmilarity-B2与Dissmilarity-B4特征数值较小,说明邻近像元上小麦对绿、近红外波段的反射率差异较小,这也与视觉上的感受相同;水体在近红外的相异度几乎相同,数值分布范围比较集中;道路、森林与拱棚覆盖西瓜具有清晰规律的纹理特征,因此在近红外波段的相异度较大;在RVI、DVI等植被指数上,植被与其他地物的数值分布差异较大,比原始反射率特征上更容易区分。从地物在这些特征的数值分布来看,地物的可分离度较好,这也能避免数据过采样中的类特征空间重叠问题。
5.2 过采样方法对少数类特征空间的影响
过采样算法会增加少数类别的样本数量,新增加的数据会改变原数据集少数类别在特征空间的数据分布。本研究计算了小宗作物在采样前后的均值和标准差,其中西瓜在过采样前后在B1、RVI、Dissmilarity-B2和Mean-B4共4个特征上均值和标准差变化情况如图6。
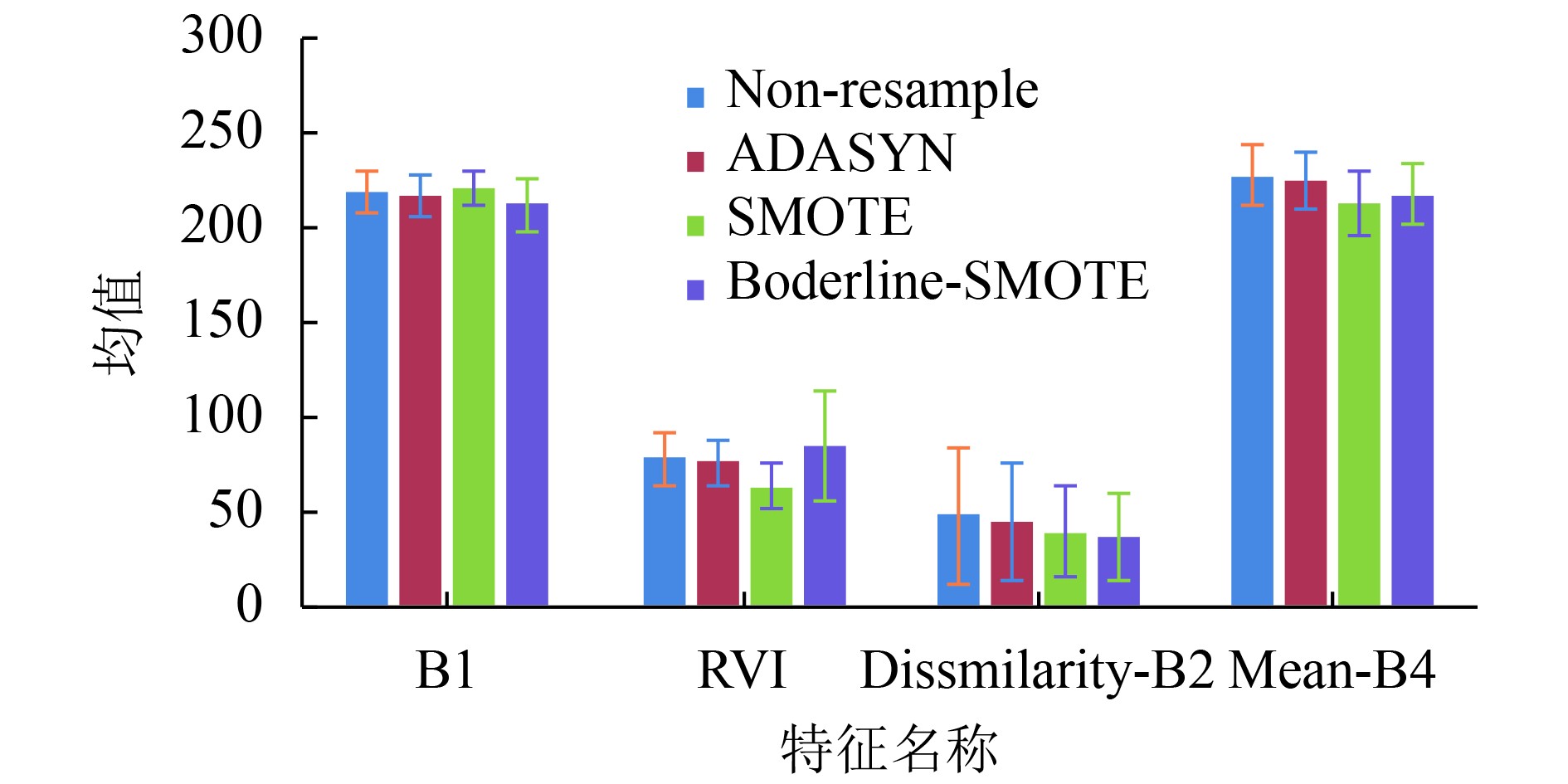
由图6可知,ADASYN采样前后西瓜的特征数值分布变化最小,这说明ADASYN采样算法可以在有效增加少数类别数目的同时保证数据的特征空间稳定。SMOTE采样后的西瓜数据集在RVI、Dissmilarity-B2和Mean-B4上的均值都比之前变小,这表明SMOTE只是在局部少数类之间进行插值,在边界处合成的样本较少。Borderline-SMOTE采样后的西瓜数据集在RVI特征上均值与标准差比原始数据集大,在其他特征上变化比ADASYN与SMOTE大,说明它在边界合成数据较多。由此可知不同的过采样方法合成的新样本对小宗作物的信息增益不同,因此为分类器提供的有效信息也不同。
5.3 欠采样方法对多数类特征空间的影响
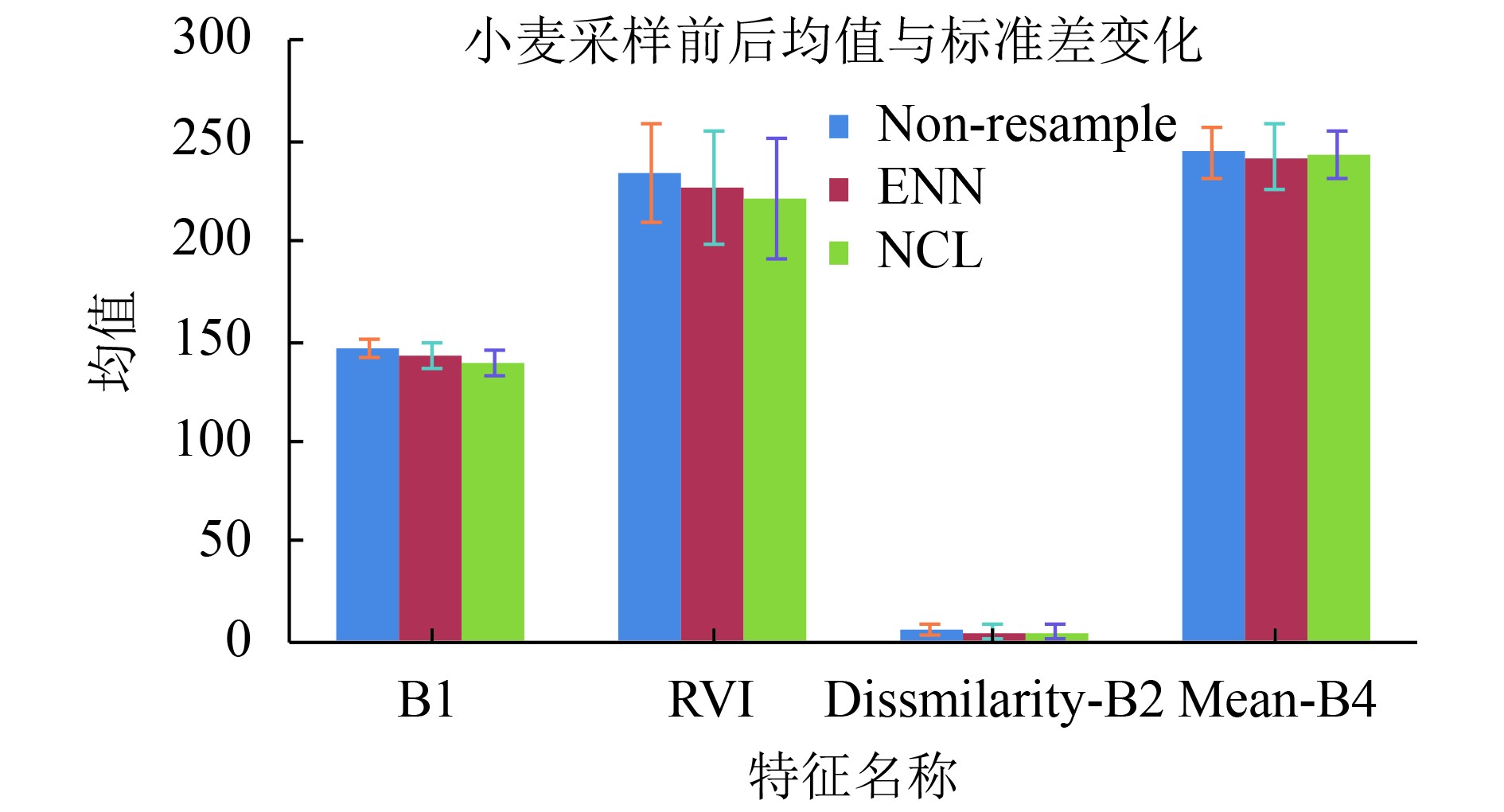
本研究利用ENN、NCL两种欠采样方法对训练集中小麦的样本进行抽样,通过去除一定数量的样本,缩小训练集中小宗作物与小麦样本数量的差异。
由图7知,ENN欠采样后的小麦在4个特征上均值普遍降低,但是数值分布范围与采样前类似。NCL采样后,小麦在RVI上标准差明显增大,说明NCL更容易去掉特征空间相似的多数类别。由此可知欠采样过程能有效去除多数类别相似的点,但是对于多数类别信息的保留程度不同。
5.4 采样方法对作物分类精度的影响
在没有采样处理的情况下,使用不均衡训练样本进行分类模型训练,分类器往往对少数类训练不足或统计特征把握不充分。本研究采用5种采样算法对遥感不均衡训练样本集进行处理,处理后训练集中的样本个数如表5。使用采样后的数据集分别训练决策树和Adaboost两种分类器。利用验证集获取相应的混淆矩阵,在此基础上计算总体精度、Kappa系数、用户精度与制图精度(表6),比较分类器在原始不均衡样本集和采样后的样本集的训练效果。
表 5 采样后训练集中样本个数
Table 5 Number of different categories after sampling
| 种类 | 采样方法编号 | |||||
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 西瓜 | 3992 | 24910 | 24992 | 24992 | 3992 | 3992 |
| 梨树 | 7491 | 25055 | 24992 | 24992 | 7491 | 7491 |
| 小麦 | 24992 | 24992 | 24992 | 24992 | 15221 | 13926 |
| 蔬菜 | 1349 | 24954 | 24992 | 24992 | 1349 | 1349 |
分析表6可知,采样处理后的数据集相较于不均衡数据集,对分类器的整体精度都有了很大的提高。其中过采样方法中ADASYN算法的效果最优,经其采样后的训练集比基于原始不均衡数据集训练出的决策树模型的Kappa系数有明显提高,从原来的0.80提高到0.91,提升幅度为14.32%,总体精度提升幅度为9.52%;其次是Borderline-SMOTE算法,经其采样后的数据集对决策树的Kappa系数提高了12.73%,达到0.90,总体精度提高幅度为8.33%。效果最差的是SMOTE算法,对决策树的Kappa系数只提高了11.8%,总体精度提升幅度为5.95%。ADASYN采样对Adaboost分类器Kappa系数提高了12.17%,达到0.93,总体精度提升幅度为8.04%,达到0.94,分类效果为所有实验组里面最优。欠采样方法中NCL在Adaboost算法上的表现最差,Kappa系数只提高了5.47%,总体精度提高了3.44%。ENN对Adaboost算法的Kappa系数与总体精度分别提高了5.95%与4.59%。NCL对决策树的Kappa系数与总体精度分别提高6.25%与4.76%,对Adaboost的Kappa系数与总体精度分别提高7.50%与5.95%。总体来看,经过对不均衡训练样本进行采样处理,分类器的总体分类精度都有提升,表明采样处理可有效解决因样本不均衡而造成的总体或部分类别识别精度低的问题。
表 6 精度对比
Table 6 Performance of different methods
| 采样方法编号 | ||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | |||
| Decision tree classifier | Kappa系数 | 0.80 | 0.91 | 0.87 | 0.90 | 0.86 | 0.85 | |
| 总体精度 | 0.84 | 0.92 | 0.89 | 0.91 | 0.89 | 0.88 | ||
| 用户精度 | 西瓜 | 0.71 | 0.84 | 0.80 | 0.83 | 0.81 | 0.82 | |
| 梨树 | 0.63 | 0.93 | 0.83 | 0.91 | 0.86 | 0.88 | ||
| 小麦 | 0.92 | 0.90 | 0.91 | 0.89 | 0.88 | 0.75 | ||
| 蔬菜 | 0.55 | 0.71 | 0.69 | 0.70 | 0.69 | 0.67 | ||
| 制图精度 | 西瓜 | 0.84 | 0.90 | 0.88 | 0.89 | 0.88 | 0.87 | |
| 梨树 | 0.68 | 0.95 | 0.84 | 0.93 | 0.91 | 0.88 | ||
| 小麦 | 0.96 | 0.95 | 0.96 | 0.95 | 0.94 | 0.95 | ||
| 蔬菜 | 0.66 | 0.79 | 0.76 | 0.77 | 0.78 | 0.77 | ||
| Adaboost classifier | Kappa系数 | 0.84 | 0.93 | 0.90 | 0.92 | 0.89 | 0.88 | |
| 总体精度 | 0.87 | 0.94 | 0.92 | 0.93 | 0.91 | 0.90 | ||
| 用户精度 | 西瓜 | 0.81 | 0.88 | 0.82 | 0.86 | 0.83 | 0.84 | |
| 梨树 | 0.71 | 0.94 | 0.91 | 0.93 | 0.90 | 0.87 | ||
| 小麦 | 0.92 | 0.91 | 0.92 | 0.92 | 0.91 | 0.90 | ||
| 蔬菜 | 0.65 | 0.79 | 0.70 | 0.71 | 0.69 | 0.67 | ||
| 制图精度 | 西瓜 | 0.87 | 0.94 | 0.90 | 0.93 | 0.87 | 0.89 | |
| 梨树 | 0.76 | 0.95 | 0.92 | 0.94 | 0.93 | 0.89 | ||
| 小麦 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 | ||
| 蔬菜 | 0.73 | 0.81 | 0.77 | 0.78 | 0.76 | 0.75 | ||
经过采样处理,分类器对小宗作物的分类精度明显提高。从表6中可看出,ADASYN过采样处理后的数据集训练得到的决策树分类器对西瓜、梨树、蔬菜的用户精度明显提升,梨树的用户精度提高了了47.61%,蔬菜的用户精度提高了29.09%,西瓜的用户精度提高了18.31%。经ADASYN采样处理的数据集训练得到的Adaboost对梨树、蔬菜与西瓜的用户精度提升幅度分别为32.39%、21.53%与8.64%。从表6可以看出,经过采样处理后的数据集训练出的分类器对小宗作物的制图精度也有所改善,ADASYN算法依然表现最优,这表明经过ADASYN算法合成的少数类别样本能够增加少数类别的有效信息,对提高少数类别的分类精度具有重要意义。ENN与NCL对小宗作物的精度提升较少,尤其NCL表现最差,可能的原因是此方法剔除了多数类样本中与最近的3个少数类类别平均距离最近的样本,只考虑了局部信息而损失了多数类的重要信息,导致采样后的数据集丢失了一些“支撑向量”。另外欠采样只是单纯的减少了大宗作物的样本数量,对数据集中小宗作物信息没有产生影响。因此过采样对不均衡数据集的处理效果要优于欠采样算法。
Adaboost比决策树分类器在原始不均衡数据集上的分类性能更好。从表6可知,使用不进行采样处理的不均衡样本,Adaboost分类器Kappa系数可以达到0.84,而决策树仅有0.80,Adaboost比决策树总体精度高0.03。另外,从表6中可知,Adaboost对小宗作物的分类精度优于决策树,原因在于Adaboost分类器在进行训练过程中,可以增加对错分的少数类别的样本权重,从而提高对少数类别的分类能力。
5.5 分类结果与分析
采用ADASYN算法结合Adaboost分类器提取了研究区的作物类型,图8给出了作物类型的空间分布,基于分类结果统计,研究区种植作物4.21万hm2,其中小麦、梨树、西瓜、大棚覆盖作物、蔬菜分别为2.57、0.62、0.47、0.42和0.13万hm2,分别占总面积的61%、15%、11%、10%和3%。
从分类结果与真实地面作物类型对比中可以发现,通过采样处理,小宗作物西瓜,蔬菜都能够得到更好的识别效果。同时使用GF-2数据在像元尺度进行分类也面临着“异物同谱”以及混合像元的问题,导致零星道路错分为大棚。

6 结 论
本研究通过采样处理改善了训练数据集大宗作物样本数量与小宗作物样本数量不均衡的问题,分析两种分类算法在样本数据采样前后的总体识别精度和小宗作物识别精度,得到结论如下:
(1)采用监督分类方法进行遥感作物识别时,采样处理可有效改善样本质量,提高分类器的训练效果,从而提高小宗作物的识别精度;(2)优选过采样方法能够增加特征空间上少数类边界处的样本从而提高小宗作物的有效信息,更有利于提高小宗作物的分类精度(3)欠采样方法不仅能减少大宗作物的样本数量,而且可以保留其有效信息,还可以在不影响大宗作物精度的前提下提高小宗作物的精度。
本研究所采用的5种采样处理方法均可在一定程度上改善小宗作物的识别精度。其中过采样方法ADASYN算法对不均衡数据集的处理效果最好,它能根据分类的难易程度自适应合成一定数量的少数类别样本,进而提高对决策树和Adaboost分类器的整体性能和小宗作物识别能力,而SMOTE增加的少数类别对提高小宗作物精度贡献较小。欠采样方法中NCL因为容易丢失多数类的边界样本,甚至影响大宗作物的精度,因此效果一般。另外,不同的过采样方法虽然都可以增加小宗作物的样本数量,但是对于小宗作物分类精度提升不同,同时不同欠采样对大宗作物有效信息的损失也不同。所以进行遥感分类的训练样本选择时,选取具有代表性的一定数量的样本是提高分类精度的关键。
Adaboost对不均衡数据集分类效果尤佳。Adaboost在采样处理后对小宗作物的识别精度优于决策树,采样前Adaboost分类器Kappa系数比决策树高0.046。因此选择分类方法时应考虑算法对不均衡数据集的敏感度。
本研究介绍的方法可以在较大程度上改善区域农作物遥感识别精度,尤其是可以改善小宗作物的识别精度。随着国家农业的发展,特色农作物,如茶叶、烟草、中草药等越来越受到关注,本研究可以为这些小宗作物的遥感识别与面积估算调查提供技术参考。本文只分析了采样处理在提高不均衡数据集作物遥感分类精度的潜力,没有探讨样本规模对不均衡分类精度的影响,接下来应对样本规模与分类精度之间的关系进行深入的分析研究。
参考文献(References)
-
Arenas-Toledo J M and Epiphanio J C N. 2011. Harmonic amplitude-terms mask to highlight agriculture in the savanna domain below the Brazilian Amazonian frontier. International Journal of Remote Sensing, 32 (18): 5021–5034. [DOI: 10.1080/01431161.2010.495096]
-
Cao Y, Miao Q G, Liu J C and Gao L. 2013. Advance and prospects of AdaBoost algorithm. Acta Automatica Sinica, 39 (6): 745–758. [DOI: 10.3724/SP.J.1004.2013.00745] ( 曹莹, 苗启广, 刘家辰, 高琳. 2013. AdaBoost算法研究进展与展望. 自动化学报, 39 (6): 745–758. [DOI: 10.3724/SP.J.1004.2013.00745] )
-
Chawla N V, Bowyer K W, Hall L O and Kegelmeyer W P. 2002. SMOTE: synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 16 (1): 321–357. [DOI: 10.1613/jair.953]
-
Chen C F, Chen C R and Son N T. 2012. Investigating rice cropping practices and growing areas from MODIS data using empirical mode decomposition and support vector machines. Giscience and Remote Sensing, 49 (1): 117–138. [DOI: 10.2747/1548-1603.49.1.117]
-
Cutler D R, Edwards T C Jr, Beard K H, Cutler A, Hess K T, Gibson J and Lawler J J. 2007. Random forests for classification in ecology. Ecology, 88 (11): 2783–2792. [DOI: 10.1890/07-0539.1]
-
Ding X. 2014. Study on Distribution of Crop’s Structure in Heilongjiang. Harbin: Northeast Agricultural University (丁潇. 2014. 黑龙江省农作物种植结构布局研究. 哈尔滨: 东北农业大学)
-
Elhassan A T, Aljourf M, Al-Mohanna F and Shoukri M. 2017. Classification of imbalance data using tomek link (T-Link) combined with random under-sampling (RUS) as a data reduction method. Global Journal of Technology and Optimization (S1): 111 [DOI: 10.4172/2229-8711.S1111]
-
Foody G M and Mathur A. 2006. The use of small training sets containing mixed pixels for accurate hard image classification: training on mixed spectral responses for classification by a SVM. Remote Sensing of Environment, 103 (2): 179–189. [DOI: 10.1016/j.rse.2006.04.001]
-
García V, Sánchez J S and Mollineda R A. 2011. Classification of high dimensional and imbalanced hyperspectral imagery data//Proceedings of the 5th Iberian Conference on Pattern Recognition and Image Analysis. Las Palmas de Gran Canaria, Spain: Springer [DOI: 10.1007/978-3-642-21257-4_80]
-
Haboudane D, Miller J R, Tremblay N, Zarco-Tejada P J and Dextraze L. 2002. Integrated narrow-band vegetation indices for prediction of crop chlorophyll content for application to precision agriculture. Remote Sensing of Environment, 81 (2/3): 416–426. [DOI: 10.1016/S0034-4257(02)00018-4]
-
Han H, Wang W Y and Mao B H. 2005. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning//Huang D S, Zhang X P and Huang G B, eds. Advances in Intelligent Computing. Berlin Heidelberg: Springer [DOI: 10.1007/11538059_91]
-
Haralick R M, Shanmugam K and Dinstein I. 1973. Textural features for image classification. IEEE Transactions on Systems, Man, and Cybernetics, SMC-3 (6): 610–621. [DOI: 10.1109/TSMC.1973.4309314]
-
Harris R. 2003. Remote sensing of agriculture change in Oman. International Journal of Remote Sensing, 24 (23): 4835–4852. [DOI: 10.1080/0143116031000068178]
-
He H B, Bai Y, Garcia E A and Li S T. 2008. ADASYN: adaptive synthetic sampling approach for imbalanced learning//Proceedings of 2008 IEEE International Joint Conference on Neural Networks. Hong Kong, China: IEEE [DOI: 10.1109/IJCNN.2008.4633969]
-
Hixson M, Scholz D, Fuhs N and Akiyama T. 1980. Evaluation of several schemes for classification of remotely sensed data. Photogrammetric Engineering and Remote Sensing, 46 (12): 1547–1553.
-
Hu Q, Wu W B, Song Q, Yu Q Y, Yang P and Tang H J. 2015. Recent progresses in research of crop patterns mapping by using remote sensing. Scientia Agricultura Sinica, 48 (10): 1900–1914. [DOI: 10.3864/j.issn.0578-1752.2015.10.004] ( 胡琼, 吴文斌, 宋茜, 余强毅, 杨鹏, 唐华俊. 2015. 农作物种植结构遥感提取研究进展. 中国农业科学, 48 (10): 1900–1914. [DOI: 10.3864/j.issn.0578-1752.2015.10.004] )
-
Huang D S. 2011. Research on Feature Selection and Semi-Supervised Classification. Wuhan: Huazhong University of Science and Technology (黄东山. 2011. 特征选择及半监督分类方法研究. 武汉: 华中科技大学)
-
Jia K and Li Q Z. 2013. Review of features selection in crop classification using remote sensing data. Resources Science, 35 (12): 2507–2516. ( 贾坤, 李强子. 2013. 农作物遥感分类特征变量选择研究现状与展望. 资源科学, 35 (12): 2507–2516. )
-
Laurikkala J. 2001. Improving identification of difficult small classes by balancing class distribution//Quaglini S, Barahona P and Andreassen S, eds. Artificial Intelligence in Medicine. Berlin Heidelberg: Springer [DOI: 10.1007/3-540-48229-6_9]
-
Li Q Z and Wu B F. 2004. Accuracy assessment of planted area proportion using Landsat TM imagery. Journal of Remote Sensing, 8 (6): 581–587. [DOI: 10.11834/jrs.20040607] ( 李强子, 吴炳方. 2004. 作物种植成数的遥感监测精度评价. 遥感学报, 8 (6): 581–587. [DOI: 10.11834/jrs.20040607] )
-
Liu J, Wang L M, Yang F G, Yang L B and Wang X L. 2015. Remote sensing estimation of crop planting area based on HJ time-series images. Transactions of the Chinese Society of Agricultural Engineering, 31 (3): 199–206. [DOI: 10.3969/j.issn.1002-6819.2015.03.026] ( 刘佳, 王利民, 杨福刚, 杨玲波, 王小龙. 2015. 基于HJ时间序列数据的农作物种植面积估算. 农业工程学报, 31 (3): 199–206. [DOI: 10.3969/j.issn.1002-6819.2015.03.026] )
-
Liu K B, Liu S B, Lu Z J, Song Q, Liu Y X, Zhang D M and Wu W B. 2014. Extraction on cropping structure based on high spatial resolution remote sensing data. Chinese Journal of Agricultural Resources and Regional Planning, 35 (1): 21–26. [DOI: 10.7621/cjarrp.1005-9121.20140104] ( 刘克宝, 刘述彬, 陆忠军, 宋茜, 刘艳霞, 张冬梅, 吴文斌. 2014. 利用高空间分辨率遥感数据的农作物种植结构提取. 中国农业资源与区划, 35 (1): 21–26. [DOI: 10.7621/cjarrp.1005-9121.20140104] )
-
Liu X N, Li X H, Sun D F, Li H, Zhang W W and Zhou L D. 2011. Landscape extraction and corridor site assessment of farmland in urban fringe using SPOT5 remote sensing image. Transactions of the CSAE, 27 (4): 317–323. [DOI: 10.3969/j.issn.1002-6819.2011.04.055] ( 刘晓娜, 李宪海, 孙丹峰, 李红, 张微微, 周连第. 2011. SPOT5遥感影像城郊耕地景观提取与廊道立地分析. 农业工程学报, 27 (4): 317–323. [DOI: 10.3969/j.issn.1002-6819.2011.04.055] )
-
Mathur A and Foody G M. 2008. Crop classification by support vector machine with intelligently selected training data for an operational application. International Journal of Remote Sensing, 29 (8): 2227–2240. [DOI: 10.1080/01431160701395203]
-
Metternicht G. 2003. Vegetation indices derived from high-resolution airborne videography for precision crop management. International Journal of Remote Sensing, 24 (14): 2855–2877. [DOI: 10.1080/01431160210163074]
-
Murthy C S, Raju P V and Badrinath K V S. 2003. Classification of wheat crop with multi-temporal images: performance of maximum likelihood and artificial neural networks. International Journal of Remote Sensing, 24 (23): 4871–4890. [DOI: 10.1080/0143116031000070490]
-
Punera K and Ghosh J. 2008. Consensus-based ensembles of soft clusterings. Applied Artificial Intelligence, 22 (7/8): 780–810. [DOI: 10.1080/08839510802170546]
-
Rätsch G, Onoda T and Müller K R. 2001. Soft margins for AdaBoost. Machine Learning, 42 (3): 287–320. [DOI: 10.1023/A:1007618119488]
-
Rilwani M L and Ikhuoria I A. 2011. Prospects for geoinformatics-based precision farming in the Savanna River basin, Nigeria. International Journal of Remote Sensing, 32 (12): 3539–3549. [DOI: 10.1080/01431161.2010.523022]
-
Sarkar A, Majumdar A, Chatterjee S, Chatterjee D, Ray S S and Kartikeyan B. 2008. Study of the potential of alternative crops by integration of multisource data using a neuro-fuzzy technique. International Journal of Remote Sensing, 29 (19): 5479–5493. [DOI: 10.1080/01431160802007665]
-
Shukla G, Garg R D, Srivastava H S and Garg P K. 2018. Performance analysis of different predictive models for crop classification across an aridic to ustic area of Indian states. Geocarto International, 33 (3): 240–259. [DOI: 10.1080/10106049.2016.1240721]
-
Sonobe R, Tani H, Wang X F, Kobayashi N and Shimamura H. 2014. Parameter tuning in the support vector machine and random forest and their performances in cross- and same-year crop classification using TerraSAR-X. International Journal of Remote Sensing, 32 (23): 7898–7909. [DOI: 10.1080/01431161.2014.978038]
-
Tan C P, Ewe H T and Chuah H T. 2011. Agricultural crop-type classification of multi-polarization SAR images using a hybrid entropy decomposition and support vector machine technique. International Journal of Remote Sensing, 32 (22): 7057–7071. [DOI: 10.1080/01431161.2011.613414]
-
Tumer K and Oza N C. 2003. Input decimated ensembles. Pattern Analysis and Applications, 6 (1): 65–77. [DOI: 10.1007/s10044-002-0181-7]
-
Waske B, Benediktsson J A and Sveinsson J R. 2009. Classifying remote sensing data with support vector machines and imbalanced training data//Proceedings of the 8th International Workshop on Multiple Classifier Systems. Reykjavik, Iceland: Springer [DOI: 10.1007/978-3-642-02326-2_38]
-
Wilson D L. 1972. Asymptotic properties of nearest neighbor rules using edited data. IEEE Transactions on Systems, Man, and Cybernetics, SMC-2 (3): 408–421. [DOI: 10.1109/TSMC.1972.4309137]
-
Wu B F, Fan J L, Tian Y C, Li Q Z, Zhang L, Liu Z L, Zhang G L, He L H, Huang J L, Jiang X B, Yan C Z, Xu A and Zhang W Q. 2004a. A method for crop planting structure inventory and its application. Journal of Remote Sensing, 8 (6): 618–627. [DOI: 10.11834/jrs.20040612] ( 吴炳方, 范锦龙, 田亦陈, 李强子, 张磊, 刘兆礼, 张广录, 何隆华, 黄进良, 江晓波, 颜长珍, 许安, 张维奇. 2004a. 全国作物种植结构快速调查技术与应用. 遥感学报, 8 (6): 618–627. [DOI: 10.11834/jrs.20040612] )
-
Wu B F, Xu W B, Sun M, Li Q Z and Huang H P. 2004b. QuickBird imagery for crop pattern mapping. Journal of Remote Sensing, 8 (6): 688–695. [DOI: 10.11834/jrs.20040620] ( 吴炳方, 许文波, 孙明, 李强子, 黄慧萍. 2004b. 高精度作物分布图制作. 遥感学报, 8 (6): 688–695. [DOI: 10.11834/jrs.20040620] )
-
Wu J P and Yang X W. 1996. Purification of training samples in supervised classification of remote sensing data. Remote Sensing for Land and Resources, 8 (1): 36–41. [DOI: 10.6046/gtzyyg.1996.01.07] ( 吴健平, 杨星卫. 1996. 遥感数据监督分类中训练样本的纯化. 国土资源遥感, 8 (1): 36–41. [DOI: 10.6046/gtzyyg.1996.01.07] )
-
Zhao Y S. 2003. The Principle and Method of Analysis of Remote Sensing Application. Beijing: Science Press (赵英时. 2003. 遥感应用分析原理与方法. 北京: 科学出版社)
-
Zhu X F, Pan Y Z, Zhang J S, Wang S, Gu X H and Xu C. 2007. The effects of training samples on the wheat planting area measure accuracy in TM scale (Ⅰ): the accuracy response of different classifiers to training samples. Journal of Remote Sensing, 11 (6): 826–837. [DOI: 10.11834/jrs.200706112] ( 朱秀芳, 潘耀忠, 张锦水, 王双, 顾晓鹤, 徐超. 2007. 训练样本对TM尺度小麦种植面积测量精度影响研究(Ⅰ)——训练样本与分类方法间分类精度响应关系研究. 遥感学报, 11 (6): 826–837. [DOI: 10.11834/jrs.200706112] )


