


|
收稿日期: 2016-04-19
基金项目: 国家自然科学基金(编号:61501009,61371134和61071137)
第一作者简介: 吴俊峰(1986— ),男,博士研究生,研究方向为高光谱遥感图像的分类、目标检测的理论和应用。E-mail:patrickwu0609@ hotmail.com
通讯作者简介: 张浩鹏(1986— ),男,讲师,研究方向为目标三维姿态测量的理论和应用。E-mail:hangpengzhang@buaa.edu.cn
中图分类号: TP391.4
文献标识码: A
|
摘要
善于捕捉空间信息的条件随机场模型虽然已被应用于高光谱遥感图像分类,但条件随机场的性能受到了标注训练样本数量的制约。为解决上述问题,本文提出了一种半监督条件随机场模型用于高光谱遥感图像分类。在该模型中,首先,利用空间-光谱拉普拉斯支持向量机定义关联势函数,以利用未标注样本中包含的信息获取样本类别概率;然后,在交互势函数中嵌入未标注的空间邻域样本,以充分利用空间信息实现对样本类别概率的修正;最后,采用分布式学习策略和平均场完成半监督条件随机场的训练和推断。本文在两个公开的高光谱数据集(Indian Pines数据集,Pavia University数据集)上进行了实验。实验结果表明Kappa系数提升3.94%。
关键词
高光谱, 遥感, 分类, 半监督, 条件随机场
Abstract
Hyperspectral remote sensing image classification is one of the enormous challenges in the field of applied remote sensing. Traditionally, supervised methods, such as Support Vector Machine (SVM), dominate this area. Especially, Conditional Random Field (CRF) excels in solving this kind of problem in most cases, due to its prominent ability in formulating the spatial relationship. However, CRF suffers from the availability of large amount of labeled samples, which is labor- and time-consuming to obtain in practice. The accuracy tends to decrease dramatically once labeled samples are not adequate or informative enough. To solve the above problem, a semi-supervised CRF model is proposed in this paper. In the semi-supervised CRF model, the association potential is defined as the spatio-spectral Laplacian Support Vector Machine (ssLapSVM), to exploit the information contained in the unlabeled samples. And the multi-class probability for each sample is obtained by the ssLapSVM with the one-versus-one scheme. In addition, the interaction potential is newly designed by introducing a weight into the Potts model. Note that, in the classification of hyperspectral remote sensing with limited labeled samples, unlabeled neighbors of one labeled samples may often exist. Thus, the labels of these unlabeled neighbors are assigned based on maximum probability acquired by the ssLapSVM, and use the maximum probability as a weight. In the training phrase, the optimal parameters in the association potential, i.e. ssLapSVM, is firstly trained, and then the whole semi-supervised CRF model is trained to get the optimal parameters in the interaction potential. In the inference phrase, mean-field is adopted to find the optimal label configuration over the testing set. The performance of the proposed semi-supervised CRF model is evaluated on two well-known benchmarks, i.e. Indian Pines scene and Pavia University scene. The objective comparison experiments are carried out among some state-of-the-art methods in terms of kappa statistic. On both Indian Pines (IP) scene and Pavia University (PU) scene, the proposed method can exhibits completely better performance, improve by 4.94%@IP and 3.28%@PU, respectively. In addition, the kappa of the proposed method rises with the increase of the number of labeled training samples. And in most cases, the proposed method shows better performance than other contrast methods under the case of the same training labeled samples. With the increase of trade-off coefficient, kappa statistic rise first and tend to steady, and then degrades dramatically. The proposed method also shows better performance when the larger scope of samples participating in the construction of the interaction potential. In this paper, we have developed a semi-supervised CRF to address the problem of hyperspectral image classification. Our method can effectively improve the kappa statistic under limited labeled-training set by newly designed association and interaction potential. Experiments conducted on two well-known hyperspectral datasets demonstrate the effectiveness of the proposed method. And when compared to related semi-supervised algorithms, the proposed method shows its superiority.
Key words
hyperspectral, remote sensing, classification, semi-supervised, conditional random field
1 引 言
高光谱遥感是现代遥感技术迅猛发展的典型成果之一,是一种新兴且可靠的遥感观测技术(童庆禧 等,2006;Ablin和Sulochana,2013)。高光谱图像分类是遥感图像处理技术中的基本问题之一,也是遥感图像分析和解译的基础和关键(Sun 等,2015;杜培军 等,2016)。
高光谱图像分类是将高光谱图像中所有像素按某种属性分为若干类别的过程,结果受诸多因素影响,其中设计合适的分类算法尤为重要(Sun 等,2015)。通常情况下,监督算法在解决高光谱图像分类问题时表现优异,例如支持向量机(SVM)(Fauvel 等,2008;Melgani和Bruzzone,2004;杨国鹏 等,2008)、条件随机场(CRF) (Lafferty 等,2001)等。近几年来,CRF在遥感图像分类领域中备受关注。在数学描述上,CRF由关联势函数和交互势函数构成。关联势函数描述了样本观察量和其类别标签之间的关系。交互势函数则对空间相邻的标注样本点对应的观察量和类别标签的交互关系进行建模,它不仅能够描述相邻位置样本点对应的观察量之间的相似性,同时也能反映它们的类别兼容性。由于易于通过交互势函数引入空间信息(Zhong 等,2014),CRF能够较好地解决遥感图像分类问题。Zhong和Wang(2008)将CRF应用到高光谱遥感图像分类领域中,并取得了良好的效果。随后,很多学者对CRF进行了改进(Zhong和Wang,2010;Zhong和Wang,2014;Zhong 等,2014),使其在高光谱图像分类中得到充分的应用。但作为监督模型,CRF的性能受到标注样本数量的制约,主要表现为两个方面:(1)对关联势函数的影响。关联势函数通常由某监督类分类器获得的样本后验概率表示。当仅有少量标注样本存在时,该分类器的泛化能力不强,进而影响CRF的性能。(2)对交互势函数的影响。交互势函数在对空间信息进行建模时需要事先已知样本标签。当标注训练样本较少时,某标注样本的空间邻域样本中存在大量或全部为未标注样本,无法提供类别标签,此时交互势函数则无法充分挖掘空间信息,从而影响CRF的性能。
半监督学习是一种解决少量标注样本条件下分类问题的重要方法,它同时利用少量标注样本和大量未标注样本进行训练,以获得性能更强的分类器(Xia 等,2014;王立国 等,2016)。作为典型的半监督模型,拉普拉斯支持向量机(LapSVM)在高光谱分类中得到广泛应用(Gomez-Chova 等,2008;Gu和Feng,2013)。尽管LapSVM能够利用未标注样本,但它并不具备融合遥感图像中普遍存在的空间信息的能力(Yang 等,2014)。Yang等人(2014)在LapSVM基础上利用空间信息构造了一种新的模型,即空间-光谱拉普拉斯支持向量机(ssLapSVM),该算法通过空间信息定义了空间权重矩阵,并同LapSVM自身的流型权重矩阵相结合,试图在标注样本和未标注样本之间建立更加紧密的联系,进而利用未标注样本隐含的信息获得样本观察量与标签之间的关系。但是ssLapSVM算法融合空间信息时仅考虑了空间相邻样本观察量之间的相似性,并未考虑它们之间的类别兼容性。
为了解决上述问题,本文在CRF框架下,通过重新设计关联势函数和改进交互势函数,提出了一种半监督CRF模型,即ssLapSVM-CRF*。在该模型中,针对CRF中关联势函数在标注样本不足时泛化能力不强的问题,通过定义半监督算法ssLapSVM为关联势函数,充分发挥ssLapSVM挖掘未标注样本信息的能力,提升少量标注样本情况下的高光谱遥感图像分类精度。同时,借助于CRF的交互势函数,克服了ssLapSVM在融合空间信息时不能考虑空间相邻样本之间类别兼容性的不足。另外,针对交互势函数在少量标注样本情况下挖掘空间信息能力下降的问题,本文将标注样本空间邻域的未标注样本也嵌入到交互势函数中,获得改进型交互势函数。在改进型交互势函数中,未标注样本的类别标签由关联势函数决定,并引入其类别概率(也由关联势函数ssLapSVM确定)作为权重因子。
为验证算法的有效性,本文在真实拍摄的高光谱数据集(Indian Pines和Pavia University)上进行实验,并与6种相关算法(4种监督算法,即SVM (Fauvel 等,2008)、SVM-CRF (李祖传 等,2011)、MLR (Zhong 等,2014)和MLR-CRF (简写为CRF) (Kae 等,2013),和两种半监督算法,即LapSVM (Gu和Feng,2013)和ssLapSVM (Yang 等,2014))进行比较。另外,为了进一步评估算法性能,本文也将LapSVM定义为关联势函数,并同传统/改进型交互势函数结合,构造半监督CRF,并同上述以ssLapSVM为关联势函数的半监督CRF算法形成内部对比(相关算法命名见表1)。
表 1 算法命名对照表
Table 1 Algorithm naming table
| 关联势函数 | 交互势函数 | 算法名称 |
| ssLapSVM | 改进型交互势函数 | ssLapSVM-CRF* |
| 传统交互势函数 | ssLapSVM-CRF | |
| LapSVM | 改进型交互势函数 | LapSVM-CRF* |
| 传统交互势函数 | LapSVM-CRF |
2 CRF、LapSVM和ssLapSVM原理
2.1 CRF
CRF是Lafferty等人(2001)提出的一种判别式的概率无向图模型,具有强大的上下文信息融合能力。
假设
| $\begin{array}{l}{{{p}}_{{\pi }}}({{{Y}}_l}|{{{X}}_l}) = \displaystyle\frac{1}{{Z({{{X}}_l})}} \times \\\;\exp \left( {\sum\limits_{{{{x}}_i} \in {{{X}}_l}} {({\varphi _i}({y_i},{{{x}}_i};{{\alpha }}) + \lambda \sum\limits_{{{{x}}_j} \in {{E}}({{{x}}_i})} {{\theta _{ij}}({y_i},{y_j},{{{x}}_i},{{{x}}_j};\mu )} )} } \right)\end{array}$ | (1) |
式中,
在CRF模型中,关联势函数在分类过程中起主导作用,通常用某监督分类器的后验概率表示,例如多项式逻辑回归(MLR)(Zhong 等,2014)、SVM(Zhong 等,2014)。作为监督分类器,MLR和SVM的性能受到标注样本数量的制约,进而导致CRF在少量标注样本条件下的分类能力受到限制。
交互势函数是对空间相邻的标注样本点对应的观测量和类别标签的交互关系进行建模,通过对关联势函数获得的样本后验概率进行修正,以得到更加平滑、异类噪声点尽可能少的分类结果。在传统CRF中,交互势函数通常表示为
| $\begin{array}{l}{\theta _{ij}}({y_i},{y_j},{{{x}}_i},{{{x}}_j}) = {t_{ij}}\exp ( - \mu ||{{{x}}_i} - {{{x}}_j}|{|^2})\\[7pt]{t_{ij}} = \left\{ \begin{array}{l} + 1\;\;\;\;\;{y_i} = {y_j}\\[5pt] - 1\;\;\;\;\;{y_i} \ne {y_j}\end{array} \right.\;\;\;\;\;\;{{{x}}_j} \in {{{{ N}}}^2}({{{x}}_i})\;\text{且}\;{{{x}}_j} \in {{{X}}_l}\end{array}$ | (2) |
从式(2)可看出,CRF中的交互势函数的修正和两样本的类别兼容性密切相关。但当标注样本较少时,某标注样本
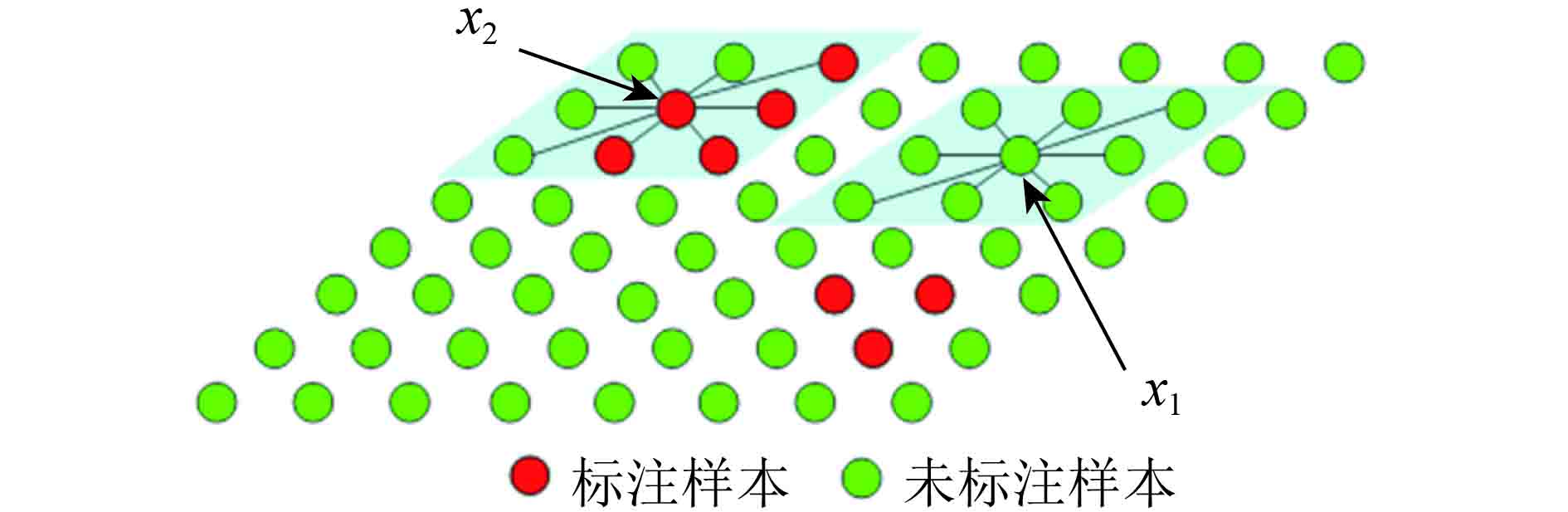

2.2 ssLapSVM
LapSVM成功地将未标注样本隐含的信息加入到SVM的学习过程中,其性能比单纯使用标注样本训练得到的分类器有了显著提高。但在高光谱遥感图像分类的具体应用中,LapSVM忽略了遥感图像中普遍存在的空间信息。
Yang等人(2014)利用空间信息定义了空间权重矩阵
以二分问题为例,给定样本集合
| $\begin{array}{l}\arg \min \displaystyle\frac{1}{{{n_l}}}\sum\limits_{i = 1}^{{n_l}} {V({{{x}}_i},{y_i},f)} + {\gamma _A}\left\| f \right\|_H^2 + {\gamma _M}\left\| f \right\|_M^2\\V({{{x}}_i},{y_i},f) = \max \{ 0,1 - {y_i}f({{{x}}_i})\} \\f({{x}}) = \displaystyle\sum\limits_{i = 1}^{{n_l} + {n_u}} {{\omega _i}K({{{x}}_i},{{x}}) + b} = {{{\omega }}^{\rm{T}}}{{{K}}_i}\left( {{{X}},{{{x}}_i}} \right) + b\\\left\| f \right\|_H^2 = {{{\omega }}^{\rm{T}}}{{K\omega }},\;\;\;\;{{\omega }} = {({\omega _1}, \cdots ,{\omega _{{n_l} + {n_u}}})^{\rm{T}}}\\\left\| f \right\|_M^2 = \displaystyle\sum\limits_{i,j = 1}^{{n_l} + {n_u}} {\left( {u{{W}}_{ij}^m + (1 - u){{W}}_{ij}^s} \right){{\left( {f({{{x}}_i}) - f({{{x}}_j})} \right)}^2}} \\{{W}}_{ij}^s = \left\{ \begin{array}{l}\exp \left( {\displaystyle\frac{{ - {{\left\| {{{{x}}_i} - {{{x}}_j}} \right\|}^2}}}{\sigma }} \right)\;{{{x}}_i} \in {{{N}}^1}({{{x}}_j})\;\text{或}\;{{{x}}_j} \in {{{N}}^1}({{{x}}_i})\\0\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\text{其他}\end{array} \right.\end{array}$ | (3) |
式中,
一旦获得模型的最优参数
| $y_*' = {\mathop{\rm sgn}} (f({{{x}}_*})) = {\mathop{\rm sgn}} ({{{\omega }}^*}^{\rm{T}}{{{K}}_*}({{X}},{{{x}}_*}) + {b^*})$ | (4) |
空间信息的引入,使得ssLapSVM的性能相比于LapSVM有了较大的提升。但从式(3)中
3 本文算法
在CRF框架下,给定标注样本
| $\begin{array}{l}{{{p}}_{{\pi }}}({{{Y}}_l}|{{{X}}_l}) = \displaystyle\frac{1}{{Z({{{X}}_l})}}\; \times \\\exp \left( {\sum\limits_{{{{x}}_i} \in {{{X}}_l}} {(\varphi _i'({y_i},{{{x}}_i},{{{X}}_u};{{\alpha }}) + \lambda \sum\limits_{{{{x}}_j} \in {{{{N}}}^{\;2}}\;({{{x}}_i})} {\theta _{ij}'({y_i},{y_j},{{{x}}_i},{{{x}}_j};\mu )} )} } \right)\end{array}$ | (5) |
式中,
3.1 改进的关联势函数
为充分利用未标注样本隐含的信息,本文分别利用ssLapSVM定义关联势函数,实现半监督分类。此时,关联势函数定义为
| $\varphi _i'({y_i},{{{x}}_i},{{{X}}_u};{{\alpha }}) = \log \left( {\sum\limits_{l = 1}^L {1({y_i} = l){P_*}(l|{{{x}}_i})} } \right)$ | (6) |
式中,
| $\begin{array}{l}\mathop {\min }\limits_{{P_*}} \displaystyle\sum\limits_{l = 1}^L {\sum\limits_{j:j \ne l} {{{({p_{jl}}{P_*}(l|{{{x}}_i}) - {p_{lj}}{P_*}(j|{{{x}}_i}))}^2}} } \;\;\;\;\\{\rm{s}}{\rm{.t}}{\rm{.}}\;\;\sum\limits_{l = 1}^L {{P_*}(l|{{{x}}_i}) = 1} \\{p_{jl}} = {p_*}(j|j - vs - l,{{{x}}_i}) = \displaystyle\frac{1}{{1 + \exp ( - f({{{x}}_i}))}}\\{p_{lj}} = {p_*}(l|j - vs - l,{{{x}}_i}) = \displaystyle\frac{1}{{1 + \exp ( - f({{{x}}_i}))}}\end{array}$ | (7) |
3.2 改进的交互势函数
在标注训练样本数量较少的情况下,传统交互势函数的空间平滑作用会降低,甚至消失。在这种情况下,为保证交互势函数依然能够有效融合空间信息,本文对传统交互势函数进行改进,具体表达式为
| $\begin{array}{l}\theta _{ij}'({y_i},{y_j},{{{x}}_i},{{{x}}_j}) = {t_{ij}}{\eta _j}\exp ( - \mu ||{{{x}}_i} - {{{x}}_j}|{|^2})\\{t_{ij}} = \left\{ \begin{array}{l} + 1\;\;\;\;\;{y_i} = {y_j}\\ - 1\;\;\;\;\;{y_i} \ne {y_j}\end{array} \right.\;\;\;\;\;\;{{{x}}_j} \in {{{{N}}}^2}({{{x}}_i})\\[10pt]{\eta _j} = \left\{ \begin{array}{l}1\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;{{{x}}_j} \in {{{X}}_l}\\{P_*}(l|{{{x}}_j})\;\;\;\;\;\;{{{x}}_j} \notin {{{X}}_l}\end{array} \right.\end{array}$ | (8) |
式中,
3.3 模型训练与推断
在CRF框架下,本文算法整合了新的关联势函数和交互势函数来实现高光谱遥感图像的半监督分类。在训练过程中,采用分步学习的策略来估计模型的最优参数
| $\begin{array}{l}{\mu ^*} \approx \mathop {\arg \max }\limits_\mu \!\! \sum\limits_{{{{x}}_i} \in {{{X}}_l}} \!\! {\log \;p({y_i}|{{{x}}_i},{{{\omega}} ^*},{b^*};\mu )} = \mathop {\arg \max }\limits_\mu \!\! \sum\limits_{{{{x}}_i} \in {{{X}}_l}} \!\! {\log \displaystyle\frac{1}{{{z_i}}}\exp \left( {\varphi _i'({y_i},{{{x}}_i},{{{X}}_u},{{{\omega }}^*},{b^*}) + \lambda \!\!\! \sum\limits_{{{{x}}_j} \in {{{{N}}}^{\;2}}({{{x}}_i})} \!\!\! {\theta _{ij}'({y_i},{y_j},{{{x}}_i},{{{x}}_j};\mu )} } \right)} \\{z_i} = \sum\limits_{{y_i} \in \{ 1, \cdots ,L\} } {\exp \left( {\varphi _i'({y_i},{{{x}}_i},{{{X}}_u},{{{\omega }}^*},{b^*}) + \lambda \!\! \displaystyle\sum\limits_{{{{x}}_j} \in {{{{N}}}^{\;2}}({{{x}}_i})} \!\! {\theta _{ij}'({y_i},{y_j},{{{x}}_i},{{{x}}_j};\mu )} } \right)} \end{array}$ | (9) |
4 实验与分析
为验证算法性能,选择了通用的高光谱数据集进行实验,即Indian Pines和Pavia University数据集,并将本文算法和6种相关算法进行比较,包括SVM (Fauvel 等,2008)、SVM-CRF (李祖传 等,2011)、MLR (Zhong 等,2014)、CRF (Kae 等,2013)、LapSVM (Gu和Feng,2013)和ssLapSVM (Yang 等,2014)。为进一步评价算法能力,将本文算法同ssLapSVM-CRF、LapSVM-CRF和LapSVM-CRF*进行横向对比。客观评价指标采用类别精度(CA)和Kappa系数(Sun 等,2015)。Kappa系数计算方法同文献(Sun 等,2015)。需要强调的是,不同于文献(Yang 等,2014),本文的评价指标结果均在测试集上进行统计,不包括参与训练的未标注训练样本集(由于未标注训练样本参与训练,会使训练所得模型在该样本上的分类精度明显偏高,进而使得最终的分类精度产生“虚高”现象)。同时,为消除随机性影响,所有统计实验结果均为10次结果的平均值。
4.1 数据库
实验所用高光谱数据集从[2014-04-07]http:// www.ehu.eus/ccwintco/index.php?title=Hyperspectral _Remote_Sensing_Scenes)获得,且每个数据集的光谱响应被归一到[0, 1]范围内。两个高光谱数据集的简介如下:
(1) Indian Pines数据集:大小为145×145,拥有200个波段。该数据集被划分为16个类别,其伪彩色图和地表覆盖真值图分别如图2(a)和(b)所示。
(2) Pavia University数据集:拥有103个波段,大小为610×340,全部地表覆盖被标注为9个类别,其伪彩色图和地表覆盖真值图分别如图5(a)和(b)所示。
4.2 参数设置
影响本文算法性能的超参数主要包括:
(1) 关联势函数固有参数(表3)。鉴于径向基核函数(RBF)具有强大的数据表达能力,采用RBF作为核函数。在具体实验中,针对每个数据集,采用五折交叉验证分别训练
(2) 交互势函数固有参数:空间邻域范围
(3)在4.3.1节和4.3.2节中,折衷参数
4.3 实验结果与分析
4.3.1 Indian Pines数据集实验结果与分析
在该数据集下,随机选择50%的真值样本点作为测试集。在其余真值中,从每个类别中随机选择5个真值样本点作为标注训练样本集,再随机选择2000个点构成未标注训练样本集,而剩余样本点作为验证集。测试集、标注和未标注训练样本集包含的真值样本点如图2(c)、(d)和(e)所示。

图2和表2分别列出了不同算法在Indian Pines(16类)数据集上的分类效果和客观评价结果(最优参数见表3),从中可看出:
表 2 Indian Pines(16类)数据集结果对比
Table 2 The results comparison on Indian Pines (16 categories)
| 指标 | 编号 | 算法 | |||||||||
| SVM | SVM-CRF | MLR | CRF | LapSVM | ssLapSVM | LapSVM-CRF | LapSVM-CRF* | ssLapSVM-CRF | ssLapSVM-CRF* | ||
| CA | C 1 | 56.52 | 56.52 | 60.87 | 65.22 | 26.09 | 56.52 | 17.39 | 21.74 | 78.26 | 60.87 |
| C 2 | 00.56 | 00.14 | 28.15 | 29.97 | 26.05 | 24.09 | 24.09 | 25.35 | 27.03 | 25.77 | |
| C 3 | 22.41 | 21.45 | 22.89 | 20.48 | 19.28 | 31.08 | 18.31 | 16.39 | 26.27 | 32.53 | |
| C 4 | 70.59 | 78.99 | 41.18 | 42.86 | 38.66 | 85.71 | 38.66 | 41.18 | 94.12 | 94.96 | |
| C 5 | 54.55 | 53.72 | 46.69 | 45.45 | 80.58 | 96.28 | 83.88 | 88.43 | 95.45 | 96.69 | |
| C 6 | 67.95 | 70.96 | 55.89 | 63.01 | 73.15 | 91.57 | 76.44 | 76.99 | 91.78 | 92.33 | |
| C 7 | 100.00 | 100.00 | 92.86 | 92.86 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| C 8 | 94.14 | 95.82 | 88.70 | 90.79 | 78.66 | 99.16 | 82.43 | 80.33 | 94.98 | 100.00 | |
| C 9 | 90.00 | 90.00 | 100.00 | 100.00 | 90.00 | 90.00 | 90.00 | 90.00 | 90.00 | 90.00 | |
| C 10 | 30.04 | 28.19 | 37.24 | 37.04 | 46.91 | 50.41 | 48.97 | 49.18 | 53.50 | 54.53 | |
| C 11 | 54.64 | 57.33 | 67.18 | 69.22 | 60.18 | 70.36 | 61.81 | 64.25 | 73.78 | 74.35 | |
| C 12 | 45.12 | 51.85 | 25.25 | 24.24 | 23.91 | 46.13 | 21.89 | 23.23 | 52.86 | 49.83 | |
| C 13 | 100.00 | 100.00 | 99.03 | 99.03 | 99.03 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| C 14 | 59.87 | 60.82 | 53.40 | 54.98 | 71.88 | 69.98 | 75.36 | 75.83 | 74.25 | 72.35 | |
| C 15 | 59.59 | 65.28 | 38.86 | 41.45 | 51.81 | 91.19 | 54.40 | 61.66 | 96.89 | 92.23 | |
| C 16 | 97.87 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| Kappa | 40.77 | 42.39 | 42.88 | 44.28 | 47.06 | 58.55 | 48.33 | 49.67 | 61.14 | 61.44 | |
表 3 Indian Pines (16类)数据集下相关算法参数设置
Table 3 Parameters configuration of different methods on Indian Pines (16 categories)
| 序号 | 算法 | 参数 | |||||||||
| 核参数σ | 影响因子C | 正则化权重lrl2reg | 系数γA | 系数γM | k-近邻 | 空间邻域N1×N1 | 权重u | 空间邻域N2×N2 | 折衷系数λ | ||
| 1 | SVM | 5 | 1000 | – | – | – | – | – | – | – | – |
| 2 | SVM-CRF | 5 | 1000 | – | – | – | – | – | – | 3×3 | 0.3 |
| 3 | MLR | – | – | 1E–5 | – | – | – | – | – | – | – |
| 4 | CRF | – | – | 1E–5 | – | – | – | – | – | 3×3 | 0.3 |
| 5 | LapSVM | 0.8 | – | – | 1E–4 | 1E–7 | 10 | – | – | – | – |
| 6 | ssLapSVM | 0.5 | – | – | 5E–3 | 1E–7 | 10 | 3×3 | 0.01 | – | – |
| 7 | LapSVM-CRF | 0.8 | – | – | 1E–4 | 1E–7 | 10 | – | – | 3×3 | 0.3 |
| 8 | LapSVM-CRF* | 0.8 | – | – | 1E–4 | 1E–7 | 10 | – | – | 3×3 | 0.3 |
| 9 | ssLapSVM-CRF | 0.5 | – | – | 5E–3 | 1E–7 | 10 | 3×3 | 0.01 | 3×3 | 0.3 |
| 10 | ssLapSVM-CRF* | 0.5 | – | – | 5E–3 | 1E–7 | 10 | 3×3 | 0.01 | 3×3 | 0.3 |
(1) 与其他半监督方法对比,当ssLapSVM-CRF*和LapSVM、ssLapSVM对比可知,同一地物内“噪声点”(异类地物)相对较少,例如图2(o)中Stone-Steel-Towers类别(C11)中包含的其他地物类别比图2(j)(k)明显减少,在Kappa系数客观评价指标上有明显提升(比ssLapSVM提升4.94%)。对比结果表明(尤其是同ssLapSVM相比较):ssLapSVM-CRF*能够充分发挥CRF对空间信息的描述能力,通过不同的空间信息融合方式,综合考虑样本之间的相似性和类别标签的兼容性,有效地利用空间信息获得空间平滑性更好的分类结果。
(2) 与其他监督类算法对比,当ssLapSVM-CRF*和SVM、SVM-CRF、MLR、CRF4种监督类算法对比时可发现,所提算法的分类效果和Kappa系数都要优于监督类算法,有效地验证了本文通过半监督算法ssLapSVM定义CRF模型中关联势函数的可行性,发挥了ssLapSVM嵌入未标注样本信息的能力,弥补了CRF模型在此方面的不足,使得提出的半监督CRF模型在标注训练样本较少的情况下,依然能够获得较高的分类精度,提升分类能力。
(3) 所提方法之间对比,当进行横向对比时可知,采用改进型交互势函数的算法ssLapSVM-CRF*的分类精度要高于采用传统交互势函数的算法ssLapSVM-CRF,这说明本文提出的交互势函数在标注训练样本较少时具有更强的空间信息融合能力。这一结论也可从LapSVM-CRF*和LapSVM-CRF的对比中得到进一步验证。另外,以ssLapSVM为关联势函数的ssLapSVM-CRF*、ssLapSVM-CRF的性能明显强于以LapSVM为关联势函数的算法LapSVM-CRF*、LapSVM-CRF,这主要是由关联势函数在CRF框架下的主导作用所致。ssLapSVM的性能强于LapSVM,进而产生上述结果。
为充分验证本文算法的性能,对不同算法在标注/未标注训练样本数量变化条件下的分类结果进行比较,结果分别如图3(a)和图4(a)所示。
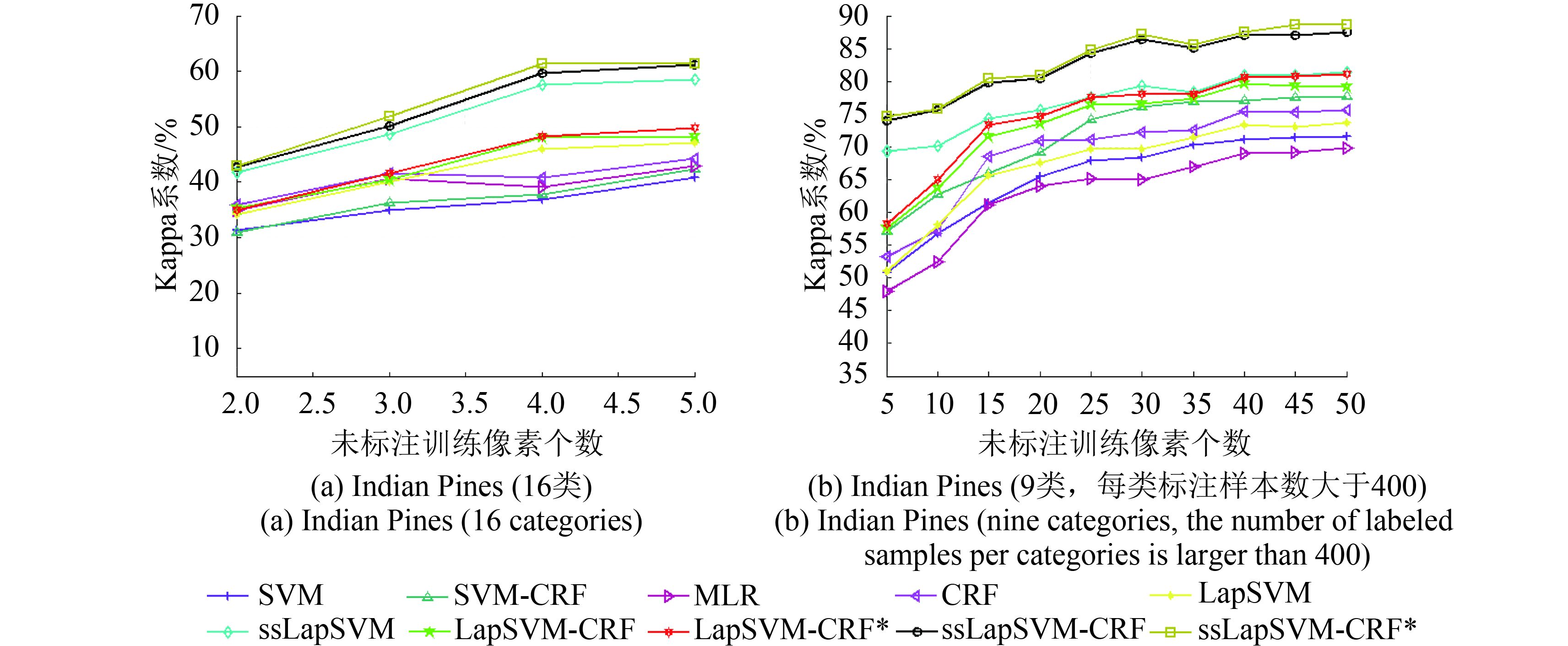
从图3(a)可知,在Indian Pines数据集下,ssLapSVM-CRF*在任意数量的标注样本下的表现都为最佳,分类精度远高于其他算法,这归功于两点:(1)关联势函数ssLapSVM提供了更具判别性的类别概率,这也体现了关联势函数的主导作用,(2)改进型交互势函数对空间信息的有力挖掘。
从图4(a)可知,在标注训练样本数量固定的情况下,ssLapSVM-CRF*受未标注样本数量的影响较大,分类精度随着未标注样本数量的增加而提升。这主要因为当未标注样本点较少时,整个训练集中存在空间相邻的样本点对则更少,此时ssLapSVM中构造的空间权重矩阵
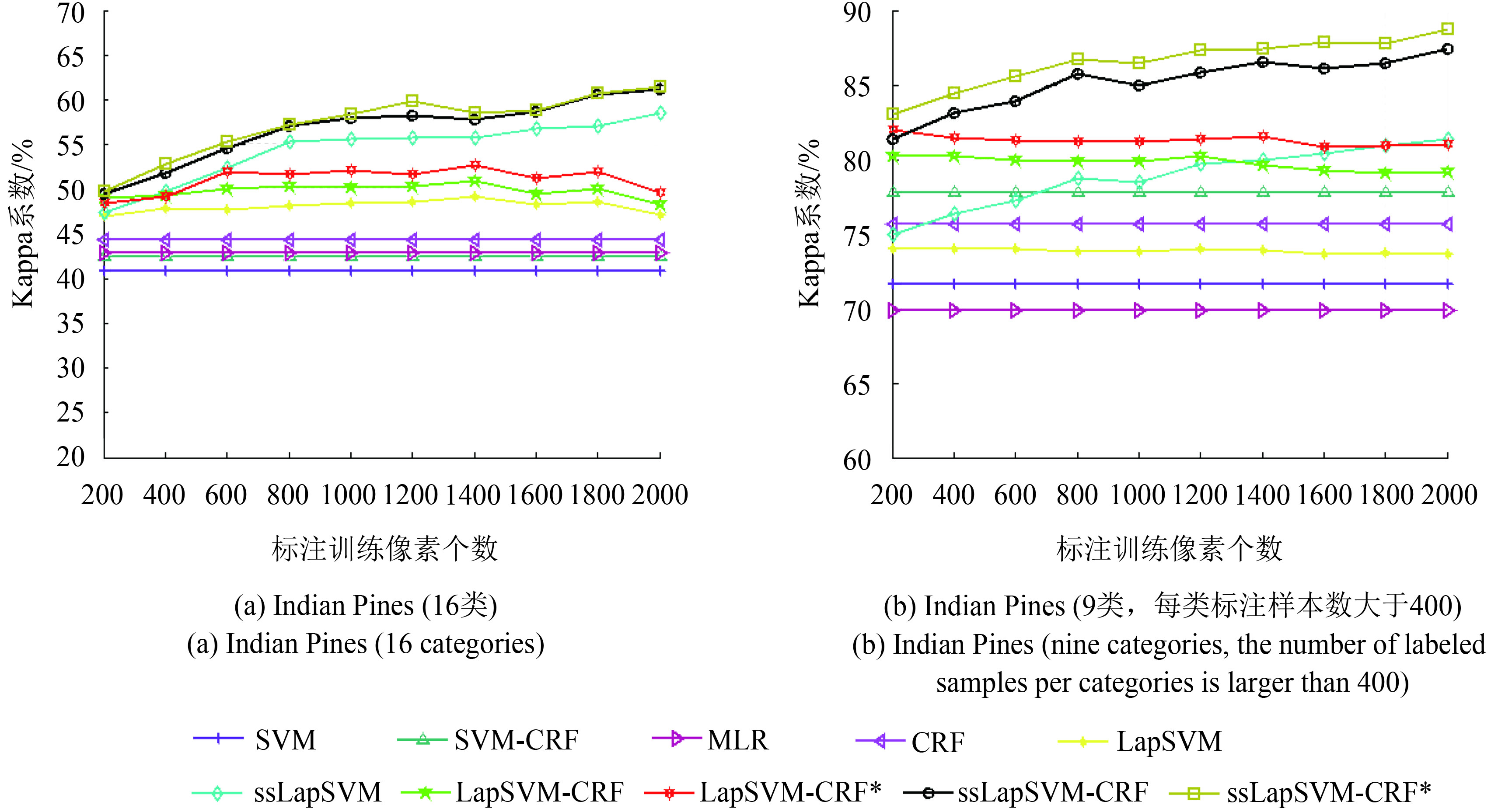
为了进一步验证本文算法的性能,本文将Indian Pines数据集中标注样本数低于400的7个类别去掉,采用余下9个类别进行实验,将不同算法在标注、未标注训练样本变化条件下的分类精度进行了比较,如图3(b)和图4(b)所示,可以看出,本文算法依然展现出较好的分类性能。
4.3.2 Pavia University数据集实验结果与分析
在该数据集下,同样随机选择50%的真值样本点作为测试集。在其余真值点中,从每个类别随机选择50个真值样本点作为标注训练样本集,再随机选择2000个点构成未标注训练样本集,而剩余点作为验证集。测试集、标注和未标注训练样本集包含的真值样本点如图5(c)、(d)和(e)所示。
不同分类算法在Pavia University数据集的分类效果和客观评价结果分别如图5和表4所示(对应的最优参数见表5)。从图5和表4中可以看出:
(1) 与其他半监督方法对比,ssLapSVM-CRF*所得结果比LapSVM、ssLapSVM更加平滑,异类噪声点更少,每个子类别的分类精度都有提高,Kappa系数比对比算法中最优结果(ssLapSVM)提高4.16%。由此可知,所提算法继承了CRF模型的优点,通过引入空间信息,有效地提高高光谱遥感图像的分类精度。而且,在关联势函数ssLapSVM已考虑空间信息的情况下,本文算法通过交互势函数对空间信息的深入挖掘(兼顾样本相似性和标签差异性),仍能进一步提高高光谱图像的分类精度。
(2) 与其他监督类算法对比:当同四种监督类算法对比时可知,本文算法均表现出较强大的分类能力,虽然某些类别精度下降(例如,类别C1、C9),但在Kappa系数评价指标上有明显提高。特别地,当本文算法同两种CRF相关算法对比时,即CRF和SVM-CRF(提升3.28%),可得出结论:本文通过半监督模型定义关联势函数的方法来构建半监督CRF模型的思路行之有效,提出的半监督CRF模型在标注训练样本较少的情况下,依然能够获得较高的分类精度。
(3) 所提方法之间对比,当将本文算法进行相互对比时可发现以ssLapSVM-CRF*的分类精度要明显高于ssLapSVM-CRF。这表明:提出的改进型交互势函数在考虑某标注样本周围全部的空间邻域样本的情况下更能够挖掘遥感图像普遍存在的空间信息,提高算法的性能。而且,上述结论可以进一步由LapSVM-CRF*和LapSVM-CRF之间的对比验证。

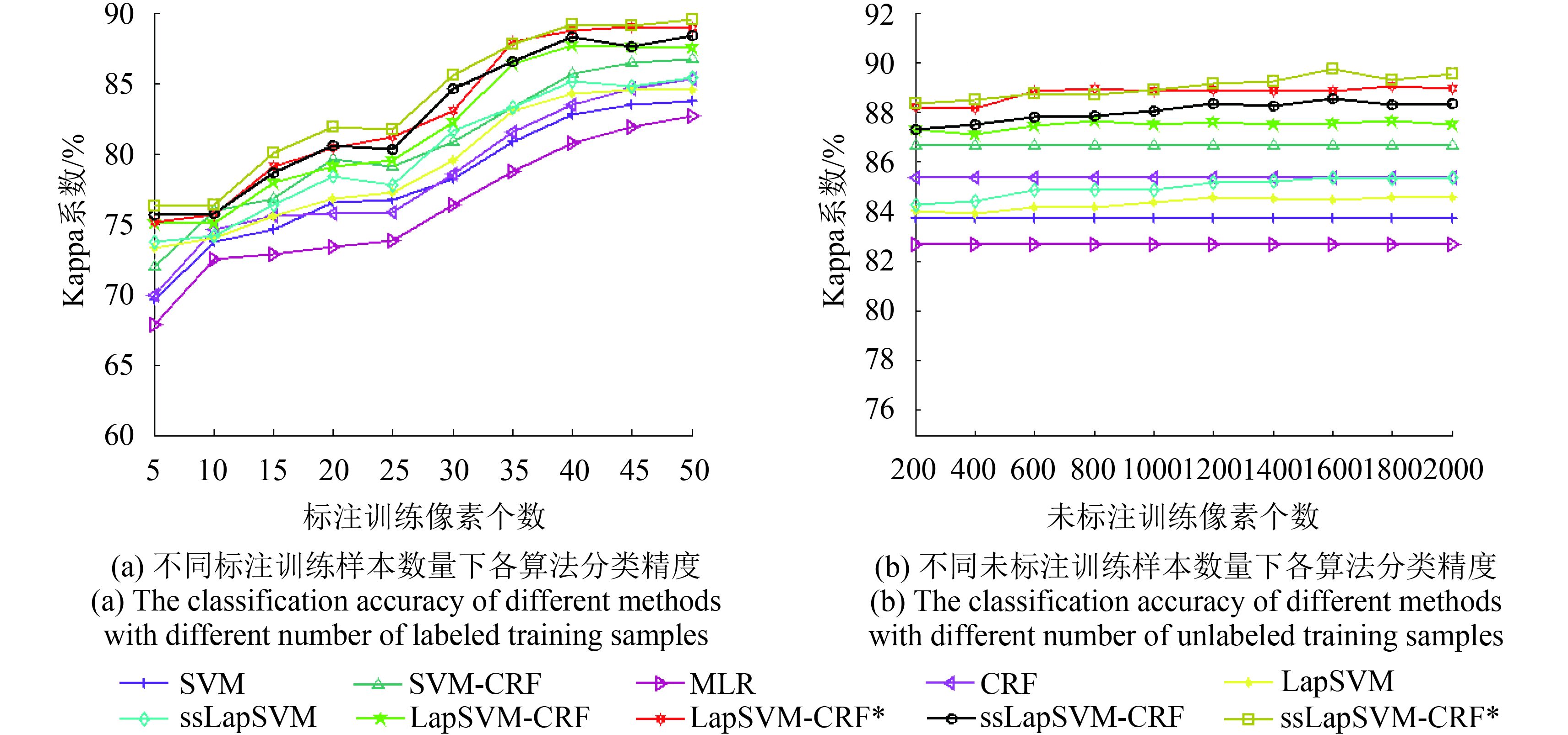
在该数据集中,不同算法在不同数量的标注/未标注样本变化情况下的分类结果如图6所示。
从图6(a)可知,当标注样本数量从5到50变化时,不同算法的分类精度都逐步提升,并且在任意固定数量的标注样本条件下,本文提出的算法均可获得较高的分类精度,获得较好的分类效果。
如图6(b)所示,当未标注样本从200到2000变化时,同Indian Pines数据集下分类结果相类似,ssLapSVM-CRF和ssLapSVM-CRF*对未标注样本数量的变化较为敏感,主要原因依然是未标注样本数量在一定程度影响了ssLapSVM中空间权重矩阵
表 4 Pavia University数据集结果对比
Table 4 The results comparison on Pavia University dataset
| /% | |||||||||||
| 序号 | 算法 | CA | Kappa | ||||||||
| C 1 | C 2 | C 3 | C 4 | C 5 | C 6 | C 7 | C 8 | C 9 | |||
| 1 | SVM | 80.07 | 88.88 | 85.90 | 98.11 | 99.41 | 79.96 | 95.79 | 86.09 | 100.0 | 83.73 |
| 2 | SVM-CRF | 85.01 | 90.67 | 87.52 | 98.43 | 99.41 | 82.47 | 96.69 | 89.79 | 100.0 | 86.68 |
| 3 | MLR | 80.91 | 88.50 | 84.86 | 97.98 | 97.92 | 77.97 | 94.14 | 83.98 | 90.93 | 82.67 |
| 4 | CRF | 84.95 | 89.31 | 86.48 | 98.56 | 98.22 | 80.80 | 95.49 | 88.81 | 98.31 | 85.35 |
| 5 | LapSVM | 79.04 | 91.53 | 84.29 | 98.04 | 99.41 | 79.56 | 96.39 | 84.36 | 97.68 | 84.55 |
| 6 | ssLapSVM | 79.86 | 91.45 | 84.86 | 98.24 | 99.55 | 80.80 | 96.84 | 87.62 | 99.37 | 85.36 |
| 7 | LapSVM-CRF | 83.62 | 93.24 | 86.86 | 98.56 | 99.41 | 82.54 | 96.84 | 87.83 | 98.10 | 87.52 |
| 8 | LapSVM-CRF* | 85.13 | 94.31 | 88.38 | 98.56 | 99.55 | 83.10 | 96.84 | 90.87 | 97.89 | 88.94 |
| 9 | ssLapSVM-CRF | 84.47 | 93.14 | 87.14 | 98.63 | 99.70 | 83.94 | 97.44 | 91.25 | 99.79 | 88.35 |
| 10 | ssLapSVM-CRF* | 86.10 | 93.66 | 88.00 | 98.69 | 100.0 | 85.45 | 97.44 | 93.48 | 99.37 | 89.52 |
表 5 Pavia University数据集下不同算法参数设置
Table 5 Parameters configuration of different methods on Pavia University dataset
| 序号 | 算法 | 参数 | |||||||||
| 核参数σ | 影响因子C | 正则化权重lrl2reg | 系数γA | 系数γM | k-近邻 | 空间邻域N1×N1 | 权重u | 空间邻域N2×N2 | 折衷系数λ | ||
| 1 | SVM | 60 | 1000 | – | – | – | – | – | – | – | – |
| 2 | SVM-CRF | 60 | 1200 | – | – | – | – | – | – | 3×3 | 0.3 |
| 3 | MLR | – | – | 1E–6 | – | – | – | – | – | – | – |
| 4 | CRF | – | – | 1E–6 | – | – | – | – | – | 3×3 | 0.3 |
| 5 | LapSVM | 0.17 | – | – | 5E–4 | 5E–4 | 10 | – | – | – | – |
| 6 | ssLapSVM | 0.12 | – | – | 1E–2 | 5E–3 | 10 | 3×3 | 0.01 | – | – |
| 7 | LapSVM-CRF | 0.17 | – | – | 5E–4 | 5E–4 | 10 | – | – | 3×3 | 0.3 |
| 8 | LapSVM-CRF* | 0.17 | – | – | 5E–4 | 5E–4 | 10 | – | – | 3×3 | 0.3 |
| 9 | ssLapSVM-CRF | 0.12 | – | – | 1E–2 | 5E–3 | 10 | 3×3 | 0.01 | 3×3 | 0.3 |
| 10 | ssLapSVM-CRF* | 0.12 | – | – | 1E–2 | 5E–3 | 10 | 3×3 | 0.01 | 3×3 | 0.3 |
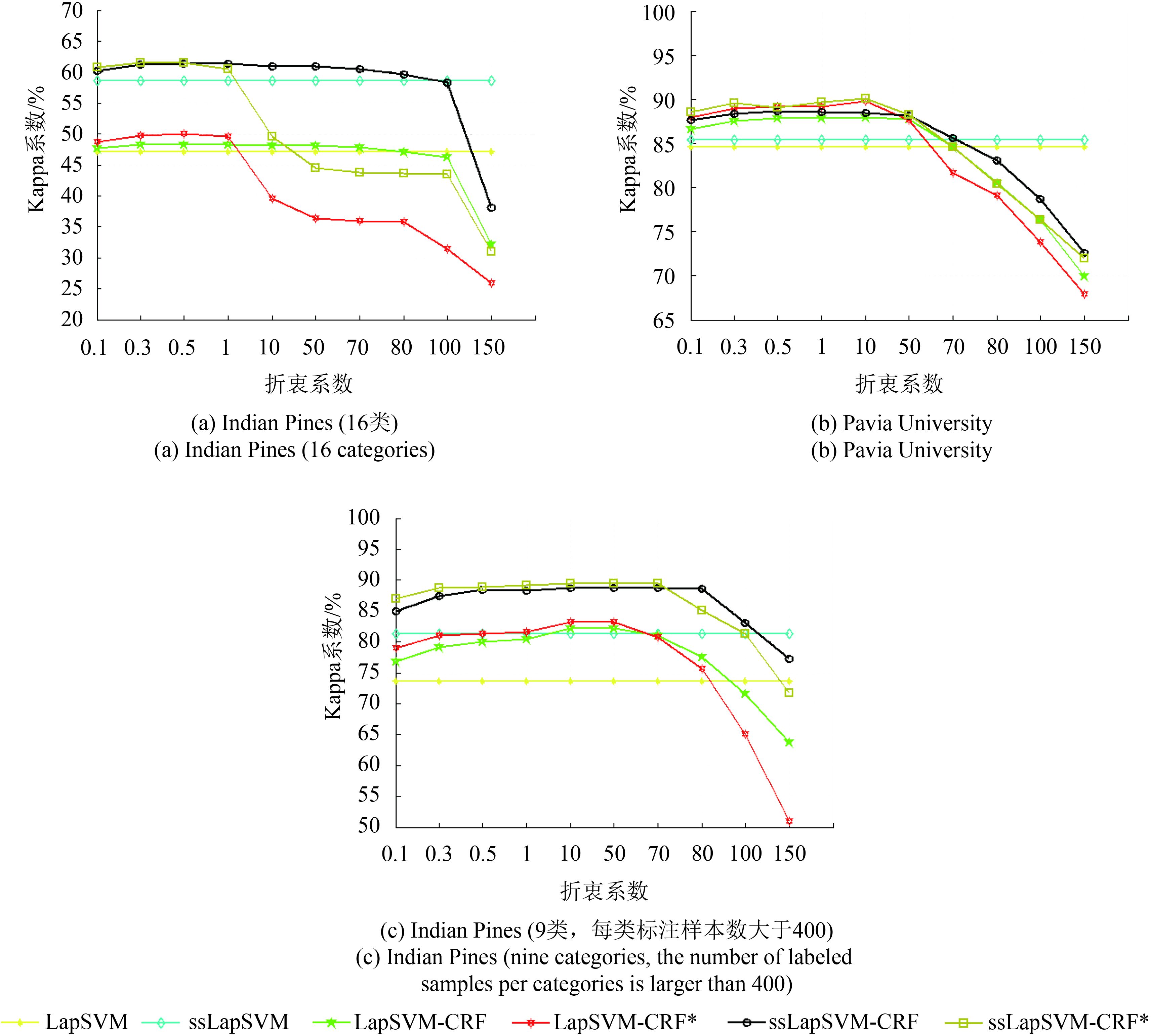
4.3.3 空间邻域范围N1、N2和折衷系数λ对算法性能的影响
在LapSVM-CRF、LapSVM-CRF*、ssLapSVM-CRF和ssLapSVM-CRF*中,空间邻域范围N2可影响交互势函数,进而影响算法性能。而在ssLapSVM-CRF和ssLapSVM-CRF*中,N1可影响关联势函数,从而影响算法最终分类能力。在高光谱图像分类中,常见的空间邻域定义方式有Von Neumann Neighborhood (V)、Moore Neighborhood (M)和Extended Moore Neighborhood (E)(Espínola 等, 2015),如图7所示。

不同的空间邻域定义对本文算法的影响见图8。从中可以看出,在Indian Pines数据集上,随着空间邻域范围的增加(融合的空间信息随之增加),同一算法的性能逐渐提升,但改进型交互势函数对算法性能的提升效果逐渐降低,甚至出现下降。例如,在Indian Pines(9类)数据集中,当空间邻域定义为V时,ssLapSVM-CRF*相比于ssLapSVM-CRF的提升幅度要大于空间邻域定义为M时的幅度,更大于E时的幅度。而在Indian Pines (16类)数据集中,当空间邻域定义为E时,ssLapSVM-CRF*的性能低于ssLapSVM-CRF。这主要是因为当空间邻域范围较大时,训练样本中包含了相对充足且具有空间相邻性的标注样本点对,传统交互势函数融合的空间信息量相对饱和,此时引入未标注样本所包含空间信息的作用则相对性的降低,并表现为改进型交互势函数对算法性能提升的幅度降低。而当空间邻域范围较大时,改进型交互势函数中会引入较大的噪声,因此导致了算法性能的降低。
在Pavia University数据集上,空间邻域范围的增加,使得算法能够融合的信息增加,因此同一算法的性能逐渐提升。但相比V和M,空间邻域定义为E时,改进型交互势函数对空间信息的挖掘效果更为明显,其原因是Pavia University的空间分辨率较高(1.3 m),具有更加丰富的空间细节信息,小范围的空间邻域(V和M)不足以充分挖掘复杂的空间细节信息。
折衷系数λ衡量了关联势函数和交互势函数之间的重要性。从图9可以看出,当λ逐渐增加时,本文算法通过交互势函数融合的空间信息逐渐增加,性能逐步提升。但是当折衷系数继续增加时,交互势函数的作用超越了关联势函数的主导作用,从而使得算法的性能出现下降。
4.3.4 空间与时间复杂度分析
本文算法通过引入未标注训练样本信息和进一步挖掘空间信息来提升高光谱遥感图像的分类精度,然而在一定程度上增加了算法的空间与时间复杂度。

在本文算法中,影响其空间复杂度的因素主要为训练和测试过程中核矩阵的计算,包括标注训练样本及其空间邻域样本、测试样本及其空间邻域样本共4类样本对应的核矩阵。例如,在Indian Pines(16类)数据集上,标注训练样本数为5个/每类,未标注训练样本数为2000个,测试样本数为5128,空间邻域定义为M(8邻域),需要计算的4类核函数?矩阵的维数分别为2010×80,2010×640,2010×5128和2010×41024。从中可以看出,在考虑空间8邻域样本信息时,需要消耗的内存空间直接增加了8倍,具有较高的空间复杂度。
以Indian Pines(16类)数据集中实验为例,不同算法的运行时间(50次结果的平均值)如表6所示。从中可以看出,本文算法需要消耗较多的时间进行训练和测试,其时间主要消耗在二值分类器的训练以及样本多类别概率的计算。
表 6 不同算法运行时间对比
Table 6 The running time comparison of different methods
| 序号 | 算法 | 训练时间/s | 测试时间/s | 总时间/s |
| 1 | SVM | 0.034 | 0.170 | 0.204 |
| 2 | SVM-CRF | 0.840 | 2.434 | 3.274 |
| 3 | MLR | 0.477 | 0.071 | 0.548 |
| 4 | CRF | 3.267 | 3.173 | 6.440 |
| 5 | LapSVM | 36.402 | 11.829 | 48.232 |
| 6 | ssLapSVM | 59.163 | 13.717 | 72.880 |
| 7 | LapSVM-CRF | 42.155 | 15.013 | 57.168 |
| 8 | LapSVM-CRF* | 78.988 | 110.45 | 189.438 |
| 9 | ssLapSVM-CRF | 64.352 | 15.508 | 79.860 |
| 10 | ssLapSVM-CRF* | 102.262 | 110.748 | 213.010 |
| 注:标注训练样本数为5个/每类,未标注训练样本数为2000,测试样本数为5128。 | ||||
4.3.5 差异显著性分析
从表2和表4可知,改进型交互势函数对算法精度的提升均在1%左右,为了充分验证改进型交互势函数的有效性,利用Z-检验进行显著性分析。Z-检验是利用标准正态分布理论来推断差异发生的概率(P值),从而比较两组样本平均数的差异是否显著,P值越大,则差异越显著。在Z-检验算法中,Z值的表达式为
| $Z = {\bar X_1} - {\bar X_2}/\sqrt {\frac{{{S_1}}}{{{n_1}}} + \frac{{{S_2}}}{{{n_2}}}} $ | (10) |
式中,
表7和表8记录了不同次数独立重复实验下采用改进型交互势函数的相关算法的显著性分析结果。从中可以看出,在不同数据集下,虽然改进型交互势函数对算法分类精度的提升幅值均在1%左右,但差异发生的概率(P值)较大,这表明改进型交互势函数对算法性能的提升效果是十分显著的。而且,随着独立重复实验次数的增加(独立重复实验次数越多,获得的平均精度统计结果以及标准差越能反映总体精度的真实情况),P值呈现出了逐渐增大的趋势(在3个数据集中,P值均>95%@50次),有效地验证了改进型交互势函数的有效性。
表 7 不同数据集下LapSVM-CRF*与LapSVM-CRF的差异显著性分析
Table 7 The significance analysis of the difference between LapSVM-CRF* and LapSVM-CRF on different datasets
| 指标 | Indian Pines (16类)标注:5个/每类,未标注:2000 | Indian Pines (9类)标注:50个/每类,未标注:2000 | Pavia University标注:50个/每类,未标注:2000 | ||||||||||||||
| 10次 | 20次 | 30次 | 40次 | 50次 | 10次 | 20次 | 30次 | 40次 | 50次 | 10次 | 20次 | 30次 | 40次 | 50次 | |||
| 平均值 | 49.67/48.33 | 49.29/48.36 | 49.78/48.54 | 49.98/48.50 | 49.82/48.65 | 81.03/79.16 | 81.59/79.43 | 81.76/79.54 | 81.82/79.57 | 81.75/79.57 | 88.94/87.52 | 88.97/87.56 | 88.85/87.63 | 88.82/87.53 | 88.90/87.66 | ||
| 标准差 | 6.4943/5.0326 | 5.9331/5.2148 | 5.2931/4.8701 | 5.0751/4.5605 | 4.9194/4.4040 | 2.2807/1.4333 | 2.0917/1.4824 | 2.0327/1.3950 | 1.8415/1.3112 | 1.7513/1.2824 | 2.1694/1.6378 | 2.2341/1.7035 | 2.0327/1.3950 | 2.0413/1.4968 | 1.8312/1.3844 | ||
| Z值 | 1.2481 | 1.2457 | 2.1304 | 3.0155 | 2.7095 | 3.0685 | 3.6130 | 3.7854 | 4.0172 | 3.9558 | 2.2301 | 3.1777 | 3.6095 | 4.3375 | 4.8896 | ||
| P值 | 89.4003 | 89.3563 | 98.3431 | 99.8717 | 99.6631 | 99.8924 | 99.9849 | 99.9923 | 99.9971 | 99.9962 | 98.7166 | 99.9258 | 99.9847 | 99.9993 | 99.9999 | ||
| 差异显著性 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| 注:差异显著性:1(十分显著),2(显著),3(不显著)。 | |||||||||||||||||
表 8 不同数据集下ssLapSVM-CRF*与ssLapSVM-CRF的差异显著性分析
Table 8 The significance analysis of the difference between ssLapSVM-CRF* and ssLapSVM-CRF on different datasets
| 指标 | Indian Pines (16类)标注:5个/每类,未标注:2000 | Indian Pines (9类)标注:50个/每类,未标注:2000 | Pavia University标注:50个/每类,未标注:2000 | ||||||||||||||
| 10次 | 20次 | 30次 | 40次 | 50次 | 10次 | 20次 | 30次 | 40次 | 50次 | 10次 | 20次 | 30次 | 40次 | 50次 | |||
| 平均值 | 61.44/61.14 | 62.41/61.40 | 62.85/61.39 | 62.91/61.47 | 62.88/61.42 | 88.68/87.43 | 88.60/87.42 | 88.48/87.40 | 88.58/87.48 | 88.61/87.49 | 89.52/88.35 | 89.21/88.24 | 89.12/88.21 | 89.31/88.24 | 89.72/88.50 | ||
| 标准差 | 4.8554/3.9893 | 4.1590/3.7690 | 4.0192/3.6329 | 4.0015/3.5256 | 3.7934/3.3821 | 1.5428/1.4252 | 1.5333/1.2368 | 1.7252/1.2050 | 1.5750/1.1392 | 1.7490/1.1891 | 2.3881/1.8635 | 2.3353/1.9930 | 2.5493/2.2515 | 2.4509/2.1312 | 2.5363/2.0374 | ||
| Z值 | 0.3190 | 1.6042 | 1.6705 | 1.6616 | 1.7280 | 2.2944 | 3.1707 | 3.4557 | 4.2228 | 4.6203 | 1.7944 | 2.0851 | 2.2748 | 3.1614 | 4.0338 | ||
| P值 | 62.5137 | 94.5665 | 95.2590 | 95.1703 | 95.8006 | 98.9116 | 99.9240 | 99.9726 | 99.9988 | 99.9998 | 96.3625 | 98.1470 | 98.8541 | 99.9215 | 99.9973 | ||
| 差异显著性 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| 注:差异显著性:1(十分显著),2(显著),3(不显著)。 | |||||||||||||||||
5 结 论
为解决少量标注样本条件下的高光谱遥感图像分类问题,基于CRF框架,通过重新设计关联势函数和改进交互势函数,提出了半监督CRF分类算法,即ssLapSVM-CRF*。实验选择了两个通用数据集对模型进行测试,结果表明:
(1) 相比于6种已有算法和3种内部算法,本文算法ssLapSVM-CRF*具有较强的分类能力。
(2) 标注/未标注训练样本数量是影响分类精度的重要因素,而在不同数量的标注/未标注训练样本条件下,本文算法均表现出良好的分类性能。
(3) 空间信息是遥感图像分类中十分重要的信息,可有效提高算法的分类能力。并且,考虑空间信息越充足,算法能力越强。
总的来说,本文针对少量标注样本条件下的高光谱遥感图像的分类问题,提出了行之有效的半监督分类算法。
但是,本文算法在训练过程中采用了分布式的学习策略,效率较低,而且分布式的学习策略忽略了关联/交互势函数在整体训练过程中的相互影响。因此在后续工作中,需要针对性地提出一种更加高效且合理的训练方法,提高模型的学习效率,将其进一步推向工程应用。此外,论文采用的半监督分类模型均为二值模型,在解决多分类问题时需要训练多达
参考文献(References)
-
Ablin R and Sulochana C H. 2013. A survey of hyperspectral image classification in remote sensing. International Journal of Advanced Research in Computer and Communication Engineering, 2 (8): 2986–3000.
-
Du P J, Xia J S, Xue C H, Tan K, Su H J and Bao R. 2016. Review of hyperspectral remote sensing image classification. Journal of Remote Sensing, 20 (2): 236–256. [DOI: 10.11834/jrs.20155022] ( 杜培军, 夏俊士, 薛朝辉, 谭琨, 苏红军, 鲍蕊. 2016. 高光谱遥感影像分类研究进展. 遥感学报, 20 (2): 236–256. [DOI: 10.11834/jrs.20155022] )
-
Espínola M, Piedra-Fernández J A, Ayala R, Iribarne L and Wang J Z. 2015. Contextual and hierarchical classification of satellite images based on cellular automata. IEEE Transactions on Geoscience and Remote Sensing, 53 (2): 795–809. [DOI: 10.1109/TGRS.2014.2328634]
-
Fauvel M, Benediktsson J A, Chanussot J and Sveinsson J R. 2008. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. IEEE Transactions on Geoscience and Remote Sensing, 46 (11): 3804–3814. [DOI: 10.1109/TGRS.2008.922034]
-
Geng B, Tao D C, Xu C, Yang L J and Hua X S. 2012. Ensemble manifold regularization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34 (6): 1227–1233. [DOI: 10.1109/TPAMI.2012.57]
-
Gomez-Chova L, Camps-Valls G, Munoz-Mari J and Calpe J. 2008. Semisupervised image classification with laplacian support vector machines. IEEE Geoscience and Remote Sensing Letters, 5 (3): 336–340. [DOI: 10.1109/LGRS.2008.916070]
-
Gu Y F and Feng K. 2013. Optimized laplacian SVM with distance metric learning for hyperspectral image classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 6 (3): 1109–1117. [DOI: 10.1109/JSTARS.2013.2243112]
-
Kae A, Sohn K, Lee H and Learned-Miller E. 2013. Augmenting CRFs with boltzmann machine shape priors for image labeling//Proceeding of 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR, USA: IEEE: 2019–2026 [DOI: 10.1109/CVPR.2013.263]
-
Lafferty J D, McCallum A and Pereira F C N. 2001. Conditional random fields: probabilistic models for segmenting and labeling sequence data//Proceedings of 18th International Conference on Machine Learning (ICML). San Francisco, CA, USA: Morgan Kaufmann Publishers Inc.: 282–289
-
Li Z C, Ma J W, Zhang R and Li L W. 2011. Classifying hyperspectral data using support vector machine conditional random field. Geomatics and Information Science of Wuhan University, 36 (3): 306–310. [DOI: 10.13203/j.whugis2011.03.009] ( 李祖传, 马建文, 张睿, 李利伟. 2011. 利用SVM-CRF进行高光谱遥感数据分类. 武汉大学学报(信息科学版), 36 (3): 306–310. [DOI: 10.13203/j.whugis2011.03.009] )
-
Melgani F and Bruzzone L. 2004. Classification of hyperspectral remote sensing images with support vector machines. IEEE Transactions on Geoscience and Remote Sensing, 42 (8): 1778–1790. [DOI: 10.1109/TGRS.2004.831865]
-
Sun L, Wu Z B, Liu J J, Xiao L and Wei Z H. 2015. Supervised spectral-spatial hyperspectral image classification with weighted markov random fields. IEEE Transactions on Geoscience and Remote Sensing, 53 (3): 1490–1503. [DOI: 10.1109/TGRS.2014.2344442]
-
Tong Q X, Zhang B and Zheng L F. 2006. Hyperspectral Remote Sensing: the Principle, Technology and Application. Beijing: Higher Education Press: 1–2 (童庆禧, 张兵, 郑兰芬. 2006. 高光谱遥感: 原理、技术与应用. 北京: 高等教育出版社: 1–2)
-
Wang L G, Yang Y S and Liu D F. 2016. Semi-supervised classification for hyperspectral image based on improved tri-training method. Journal of Harbin Engineering University, 37 (6): 849–854. [DOI: 10.11990/jheu.201505078] ( 王立国, 杨月霜, 刘丹凤. 2016. 基于改进三重训练算法的高光谱图像半监督分类. 哈尔滨工程大学学报, 37 (6): 849–854. [DOI: 10.11990/jheu.201505078] )
-
Xia J S, Chanussot J, Du P J and He X Y. 2014. (Semi-) supervised probabilistic principal component analysis for hyperspectral remote sensing image classification. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 7 (6): 2224–2236. [DOI: 10.1109/JSTARS.2013.2279693]
-
Yang G P, Yu X C, Chen W and Liu W. 2008. Hyperspectral remote sensing image classification based on kernel fisher discriminant analysis. Journal of Remote Sensing, 12 (4): 579–585. [DOI: 10.11834/jrs.20080476] ( 杨国鹏, 余旭初, 陈伟, 刘伟. 2008. 基于核Fisher判别分析的高光谱遥感影像分类. 遥感学报, 12 (4): 579–585. [DOI: 10.11834/jrs.20080476] )
-
Yang L X, Yang S Y, Jin P L and Zhang R. 2014. Semi-supervised hyperspectral image classification using Spatio-spectral Laplacian support vector machine. IEEE Geoscience and Remote Sensing Letters, 11 (3): 651–655. [DOI: 10.1109/LGRS.2013.2273792]
-
Zhong P and Wang R S. 2008. Learning sparse CRFs for feature selection and classification of hyperspectral imagery. IEEE Transactions on Geoscience and Remote Sensing, 46 (12): 4186–4197. [DOI: 10.1109/TGRS.2008.2001921]
-
Zhong P and Wang R S. 2010. Learning conditional random fields for classification of hyperspectral images. IEEE Transactions on Image Processing, 19 (7): 1890–1907. [DOI: 10.1109/TIP.2010.2045034]
-
Zhong P and Wang R S. 2014. Jointly learning the hybrid CRF and MLR model for simultaneous denoising and classification of hyperspectral imagery. IEEE Transactions on Neural Networks and Learning Systems, 25 (7): 1319–1334. [DOI: 10.1109/TNNLS.2013.2293061]
-
Zhong Y F, Lin X M and Zhang L P. 2014. A support vector conditional random fields classifier with a mahalanobis distance boundary constraint for high spatial resolution remote sensing imagery. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 7 (4): 1314–1330. [DOI: 10.1109/JSTARS.2013.2290296]


