

|
收稿日期: 2016-06-07; 修改日期: 2016-10-03; 优先数字出版日期: 2016-10-10
基金项目: 国土资源部公益性行业科研专项(编号:201511009-01)
第一作者简介: 闫利(1966— ),男,教授,研究方向为摄影测量与遥感,地面三维激光扫描。E-mail:
lyan@whu.edu.cn
通讯作者简介: 刘异(1983— ),女,副教授,研究方向为遥感图像分类、城市形态分析。E-mail:
yliu@sgg.whu.edu.cn
中图分类号: TP751
文献标识码: A
|
摘要
传统词包模型的视觉词典忽略了场景本身包含的类别信息,难以区分不同类别但外观相似的场景,针对这个问题,本文提出一种顾及场景类别信息的视觉单词优化方法,分别使用Boiman的分配策略和主成分分析对不同场景类别视觉单词的模糊性和单词冗余进行优化,增强视觉词典的辨识能力。本文算法通过计算不同视觉单词的影像频率,剔除视觉词典中影像频率较小的视觉单词,得到每种场景的类别视觉词典,计算类别直方图,将类别直方图和原始视觉直方图融合,得到不同类别场景的融合直方图,将其作为SVM分类器的输入向量进行训练和分类。选取遥感场景标准数据集,验证算法,实验结果表明:本算法能适应不同大小的视觉词典,在模型中增加场景类别信息,增强了词包模型的辨识能力,有效降低场景错分概率,总体分类精度高达89.5%,优于传统的基于金字塔匹配词包模型的遥感影像场景分类算法。
关键词
场景类别, 类别直方图, 视觉单词优化, 主成分分析, 影像频率, 自适应加权融合
Abstract
The traditional Bag Of Words (BOW) model disregards the scene label information of remote sensing images and ambiguity or redundancy of visual vocabularies. Hence, utilizing BOW to classify categories with similar backgrounds is unsuitable. Therefore, we propose an image scene classification algorithm based on the optimization of visual words with respect to scene label information to handle the said problem.This paper reports on an image scene classification algorithm based on the optimization of visual words with respect to scene label information. The algorithm procedure is as follows: first, images are divided into patches utilizing Spatial Pyramid Matching, and then Scale Invariant Features Transform (SIFT) features are extracted for each local image patch. These features are then clustered with K-means to form a histogram of each patch at different levels utilizing the Boiman strategy. We adopt Image Frequency as the feature selection method on visual words in each category to eliminate visual vocabulary irrelevant to a specific category and obtain a class-specific codebook. Principal Component Analysis (PCA) is then utilized to eliminate redundant visual vocabulary. Finally, we produce a mixture of class-specific histograms in each image patch at different pyramid levels and a traditional histogram with an adaptive weight. A fusion of histograms will be placed in a Support Vector Machine (SVM).We conducted experiments in this study on standard datasets of scene classification. Five experiments were conducted to demonstrate the performance of proposed algorithm. The first experiment shows that our algorithm performs better than methods that do not consider the scene label information with an increased accuracy of approximately 6 percent. The second experiment shows that the proposed method suitably performs in classifying categories with similar backgrounds and classifying error decreases in most categories. The third experiment demonstrates that the accuracy of the proposed method is higher at each pyramid level, and combined pyramids can offer even higher accuracy. The fourth experiment shows that method utilizing an adaptive weighted fusion method is more accurate than methods without. The final experiment demonstrates that the proposed algorithm performs better than other representative methods under the same conditions.This study proposes a method based on the optimization of visual words with respect to scene label information. This algorithm extracts SIFT features at different levels of pyramids combined with the Boiman strategy to generate universal histograms. DF is adopted as the feature selection method to remove visual words irrelevant to a specific category. PCA is then applied to remove redundancy and obtain class-specific codebook and histograms. Finally, a practical adaptive weighted fusion method that combines the traditional histograms of different levels with the class-specific histogram is proposed and placed in an SVM trainer and classifier. The experiment results show that the proposed algorithm suitably performs in classifying categories with similar backgrounds and displays higher stability. However, the proposed algorithm only considers one SIFT descriptor that corresponds to only one visual word. We can perform experiments on one SIFT descriptor that corresponds to several visual words and other feature selection procedures in future research.
Key words
scene classification, class-specific histogram, optimization of visual words, principal component analysis, image frequency, adaptive weighted mixture
1 引 言
场景分类是遥感影像解译的重要环节,是遥感领域的研究热点之一。目前遥感影像场景分类技术的发展可分为以下4个阶段:(1)基于底层特征的方法, 如Scale Invariant Feature Transform(SIFT)(Lowe, 2004)、Histogram of Oriented Gradient(HOG)(Dalal, 2008)、Census Transform Histogram(CENTRIST)(Wu和Rehg, 2011)和gist(Oliva和Torralba,2001)等;(2)基于中层特征的方法,包括Bag Of Words(BOW)(Csurka 等, 2004)模型、高效匹配核函数Efficient Match Kernel(EMK)(Bo和Sminchisescu, 2009)、Locality-Constrained Linear Coding(LLC) (Juneja 等, 2013);(3)基于高层特征的方法,常见的高层特征方法有:Object Bank(OB)(Li, 2010)、Latent Pyramid Regions(LPR)(Sadeghi和Tappen, 2012)和Patches(Singh 等, 2012)等;(4)基于机器学习的方法, 常用的有Convolutional Neural Networks (CNN)(Karpathy 等, 2014)、Deep Convolutional Neural Networks (DCNN)(Krizhevsky 等, 2012)。其中,中层特征相对底层特征能更好地表示图像的语义信息,相对高层特征计算复杂度较低,机器学习的场景分类方法则主要侧重于选择合适的分类器,因此,中层特征的研究仍然是场景分类的一个重要突破点。
中层特征是对底层特征的聚集与整合,其本质是依托中层特征建立底层特征与场景语义信息之间的联系,在上述中层特征方法中,BOW模型在图像分析和分类领域取得了巨大成功,相对其他方法在复杂场景中表现更好(Zhao 等, 2014)。BOW模型不涉及影像包含的具体目标,而是对底层特征进行聚类,将聚类中心作为视觉单词,通过影像底层特征相对视觉单词的分布表达场景语义信息,该方法计算复杂度较低且准确性较高,但BOW模型的视觉词典通常由K均值聚类得到,聚类中心放在特征出现频繁的位置,但特征出现频繁的位置辨识能力不一定强,因此可对视觉单词进行优化以提高分类精度。
视觉单词可采用更好的聚类算法 (Jurie和Triggs, 2005;Larlus和Jurie, 2006)、合并场景类别 (Moosmann 等, 2008)、抑制视觉单词的模糊性和去除单词冗余等方法进行优化,其中抑制视觉单词的模糊性和单词冗余方法分类结果较好(Van Gemert 等, 2010)。视觉单词的模糊性是指某些图像特征,尤其是视觉单词边界处的特征,可能对应多个视觉单词,选择特征对应的视觉单词时会出现视觉单词模糊的问题。为了抑制该问题,Sivic和Zisserman(2003)剔除了影像中出现频率最高或最低的视觉单词, 该方法在目标识别领域效果较好,但用于场景分类精度较低;Jiang等人(2007)把一幅图像提取的每个特征分配给多个邻近的视觉单词, 但该方法分类精度提升不明显;Perronnin(2008),Agarwal和Triggs(2008)提出一种概率视觉单词投票策略,即给定一个视觉单词,每一个图像特征根据图像的后验概率对多个视觉单词投票,该方法对简单物体分类精度较高,但在复杂场景分类效果不佳;也有研究者使用稀疏编码(Sparse Coding) (Yang 等, 2009)方法将特征分解为多个视觉单词的线性组合, 该方法分类效果较好,但很难进行样本的预测。Boiman等人(2008)把图像的特征直接分配给最邻近的视觉单词,该方法可以明显提升复杂场景的分类性能,本文使用该方法抑制视觉单词的模糊性。
视觉单词不仅存在模糊性问题,还有单词冗余问题。单词冗余是指视觉词典中某些单词具有相关性,冗余的单词会对分类场景进行干扰,影响分类精度。目前去除冗余信息,常用的方法有主成分分析法(PCA) (Okumura, 2011)、Word Activation Forces(WAFs) (Li 等, 2012)、Naïve Bayes(Chen 等, 2009)和Topic Model(Cao和Li, 2007)等,这些方法通过抑制单词冗余提升影像语义描述的能力,其中PCA算法准确度高,计算复杂度较低,本文使用该方法去除单词冗余。
遥感影像场景分类算法通常没有考虑场景的类别信息,相似场景间错分严重。若考虑场景的类别信息,增加类别之间的区分度,则能够提高分类精度。因此,本文提出一种顾及遥感影像场景类别信息的视觉单词优化分类方法,引入文本分类领域表现较好的文档频率(DF)(Yang和Pedersen, 1997)思想对BOW模型得到的视觉词典进行特征选择,使用Boiman的分配策略和主成分分析方法分别抑制视觉单词的模糊性和冗余性,为每一类别生成类别视觉词典,突出场景的类别特征,以空间金字塔模型为基础将类别视觉词典和全局视觉词典联合生成表达类别特征的融合直方图,最终得到较好的场景分类结果。
2 顾及类别的视觉单词优化方法
2.1 顾及类别的视觉单词优化方法整体流程
传统BOW模型场景分类方法,分类仅使用统一的全局视觉词典,没有考虑场景的类别信息,对相似场景的区分能力较弱,针对该缺点,本文使用顾及场景类别信息的方法对视觉单词进行了优化。首先,通过优化全局视觉词典减弱单词的冗余性与模糊性,为各类别建立类别视觉词典,突出场景类别信息;其次,将全局视觉词典与类别视觉词典联合,使融合后的直方图,更好的反映场景特征,达到较好的分类效果。图1给出了本文算法的基本流程,其中训练过程如下:


(1) 引入空间金字塔增加BOW模型的空间分布信息,结合Boiman的分配策略生成训练影像的全局直方图。对每幅训练影像使用空间金字塔模型(SPM),将影像分解为不同级别的图像块,对每块影像提取SIFT特征点,并使用K-means对所有SIFT特征点进行聚类,得到全局视觉词典。把各图像块的SIFT特征分配给最邻近的视觉单词,统计每块影像各视觉单词对应的SIFT特征数目,得到各级特征直方图,将各级直方图加权联合,得到训练影像的全局直方图。
(2) 使用顾及类别信息的视觉单词优化方法生成训练影像的类别直方图。对每一类别所有训练影像,利用文档频率的思想,统计出现各视觉单词的影像数目,即影像频率(IF), 对全局视觉词典进行特征选择,保留影像出现频率大于阈值的视觉单词,然后使用主成分分析法再次去除冗余单词,最终对所有类别的剩余单词进行维度统一,生成各类别的类别视觉词典。将全局直方图映射到类别视觉词典上,即得到训练影像的类别直方图。
(3) 将类别直方图和全局直方图自适应加权联合生成融合直方图,使用支持向量机(SVM)分类器训练。对于训练影像来说,类别已知,每幅影像只对应一个类别直方图。将得到的全局直方图和类别直方图进行自适应加权融合,把各级直方图加权联合,得到最终的融合直方图,投入SVM训练器进行训练。
测试过程如下:
(1) 引入空间金字塔模型,结合Boiman的分配策略生成测试影像的全局直方图。对每幅测试图像使用与训练过程相同的方法进行空间金字塔分解,提取SIFT特征,根据训练得到的全局视觉词典,生成测试影像的全局直方图。
(2) 使用优化后的类别视觉词典生成测试影像的类别直方图。将测试影像的全局直方图分别映射到不同类别的类别视觉词典上,得到一组类别直方图,类别直方图数量与场景数量相同。
(3) 将类别直方图和全局直方图自适应加权联合生成融合直方图,使用SVM分类器分类。把测试影像的一组类别直方图分别与全局直方图自适应加权融合,得到一组融合直方图。分别投入SVM分类器中,通过投票的方式得到最终的分类结果。
2.2 结合空间金字塔的BOW模型与运用
BOW模型对底层特征的聚类过程会损失特征点的位置信息,在BOW模型加入空间金字塔能够增加特征点的空间信息,可以弥补原始BOW的这一缺点。空间金字塔模型通过对场景图像进行多级划分,获取不同尺度下的BOW直方图并对其加权联合,使得直方图能够反映影像的空间信息,增强直方图的区分能力。具体原理及实现过程如下:
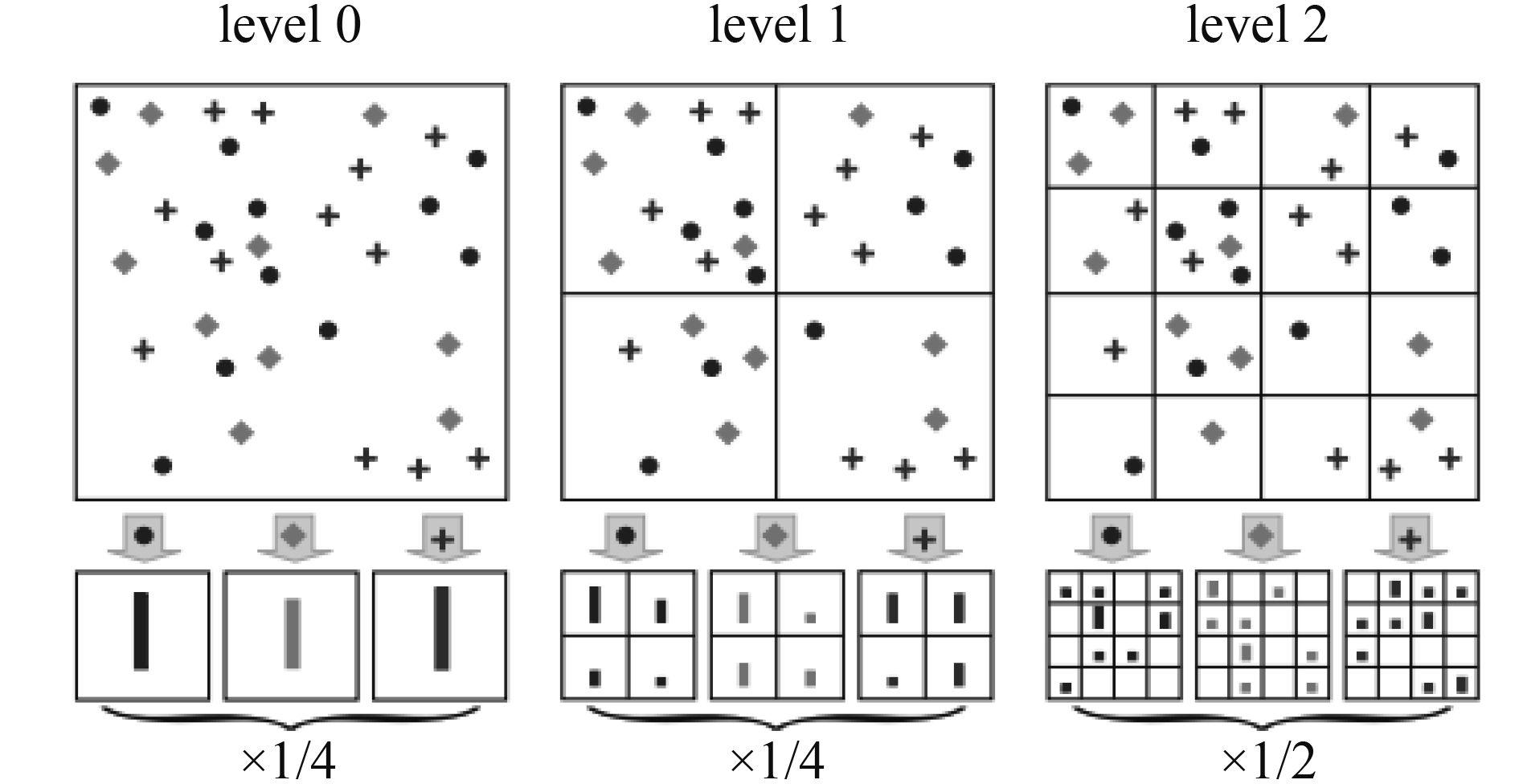
训练过程:将每幅训练图像按照级别进行分块,如图2所示。
| ${H} = \left[ {\frac{{\mathbf{1}}}{{\mathbf{4}}}{{H}_{\mathbf{0}}},\frac{{\mathbf{1}}}{{\mathbf{4}}}{H}_{\mathbf{1}}^{\mathbf{1}}, \ldots ,\frac{{\mathbf{1}}}{{\mathbf{4}}}{H}_{\mathbf{1}}^{\mathbf{4}},\frac{{\mathbf{1}}}{{\mathbf{2}}}{H}_{\mathbf{2}}^{\mathbf{1}}, \ldots ,\frac{{\mathbf{1}}}{{\mathbf{2}}}{H}_{\mathbf{2}}^{{\mathbf{16}}}} \right]$ | (1) |
测试过程:参照训练过程,对测试影像进行分块,特征提取,利用训练过程得到的全局视觉词典,生成测试影像的全局直方图,使用金字塔匹配核投入SVM分类器分类,金字塔匹配核如式(2)所示。
| ${{k}^L}\left( {{X,Y}} \right) \!=\! {{I}^L} \!+\! \sum\limits_{l = 0}^{L - 1} {\frac{{\mathbf{1}}}{{{{\mathbf{2}}^{L - 1}}}}} \left( {{{I}^l} \!-\! {{I}^{l + 1}}} \right) \!=\! \frac{{\mathbf{1}}}{{{{\mathbf{2}}^L}}}{{I}^0} \!+\! \sum\limits_{l = 1}^L {\frac{{\mathbf{1}}}{{{{\mathbf{2}}^{L - l + 1}}}}} {{I}^l}$ | (2) |
式中,
X,Y
表示两幅不同影像的全局直方图,
| ${I}\left( {{H}_X^l,{H}_Y^l} \right) = \mathop {\min }\limits_{i = 1}^{c\left( l \right)} \left( {{H}_X^l\left( {i} \right),{H}_Y^l\left( {i} \right)} \right)$ | (3) |
式中, HXl (i), HYl (i)分别为X,Y在l级别下第i个图像块的特征点数,直方图交叉核通过对两幅影像级别l下的特征直方图取对应维度的最小值,得到由最小值组成的级别l直方图。
2.3 顾及类别的视觉单词优化方法
本文提出了一种顾及遥感影像场景类别信息的视觉单词优化算法,其主要思想是假定全局视觉单词集合为
顾及类别的视觉单词优化方法的具体步骤如下:
(1) 利用BOW得到全局视觉词典,遍历特定类别的所有训练影像,计算全局视觉词典中所有视觉单词的IF值。
(2) 经统计为每个类别设置IF阈值,阈值选取原则为使得高于阈值的视觉单词数量约为原有视觉单词数量的一半,保证剩余视觉单词既能够反映场景类别信息而又减少冗余,选取所有类别中最小的IF阈值IFmin作为算法最终阈值,用于对所有类别的视觉单词进行筛选。若IF≥IFmin,则保留,否则删除。把保留的视觉单词重新排列,得到特征选择后的视觉单词集
(3) 全局视觉词典是由SIFT特征聚类得到的,每个视觉单词都是一个128维向量,视觉词典
① 将
② 对 X 矩阵的每一行进行零均值化,即减去这一行的均值。
③ 参照式(4)所示,求出 X 的协方差矩阵 C
| $\begin{array}{l}{C} = E\left[ {\left( {{X} - E\left[ {X} \right]} \right){{\left( {{X} - E\left[ {X} \right]} \right)}^{\rm T}}} \right]\\ = \left[ {\begin{array}{*{20}{l}}{E\left[ {\left( {{{X}_1} - {{\mu }_1}} \right)\left( {{{X}_1} - {{\mu }_1}} \right)} \right]}&{E\left[ {\left( {{{X}_1} - {{\mu }_1}} \right)\left( {{{X}_2} - {{\mu }_2}} \right)} \right]}& \cdots &{E\left[ {\left( {{{X}_1} - {{\mu }_1}} \right)\left( {{{X}_n} - {{\mu }_n}} \right)} \right]}\\{E\left[ {\left( {{{X}_2} - {{\mu }_2}} \right)\left( {{{X}_1} - {{\mu }_1}} \right)} \right]}&{E\left[ {\left( {{{X}_2} - {{\mu }_2}} \right)\left( {{{X}_2} - {{\mu }_2}} \right)} \right]}& \cdots &{E\left[ {\left( {{{X}_2} - {{\mu }_2}} \right)\left( {{{X}_n} - {{\mu }_n}} \right)} \right]}\\ \vdots & \vdots & \ddots & \vdots \\{E\left[ {\left( {{{X}_n} - {{\mu }_n}} \right)\left( {{{X}_1} - {{\mu }_1}} \right)} \right]}&{E\left[ {\left( {{{X}_n} - {{\mu }_n}} \right)\left( {{{X}_2} - {{\mu }_2}} \right)} \right]}& \cdots &{E\left[ {\left( {{{X}_n} - {{\mu }_n}} \right)\left( {{{X}_n} - {{\mu }_n}} \right)} \right]}\end{array}} \right]\end{array}$ | (4) |
式中,μi =E( Xi ), 即Xi 的期望值。
④ 求协方差矩阵 C 的特征值及对应的特征向量。
⑤ 将特征向量按对应特征值大小从上到下按行排列成矩阵 D ,计算特征值之和占总特征值超过0.95的最小值k,即从n′个视觉单词中选择出相互独立又包含视觉单词类别信息的k个视觉单词。
⑥ 取矩阵 D 前k行构成矩阵 P , Y = PX , Y 即为降维到k维的类别视觉词典,不同类别的视觉词典维度k不完全相同。
(4) 由于不同类别视觉词典维度的不统一,将所有的类别视觉词典与维度最大的类别视觉词典对齐,不足补零,得到维度相同的类别视觉词典。
(5) 将全局直方图映射到所有类别视觉词典上,得到类别直方图。
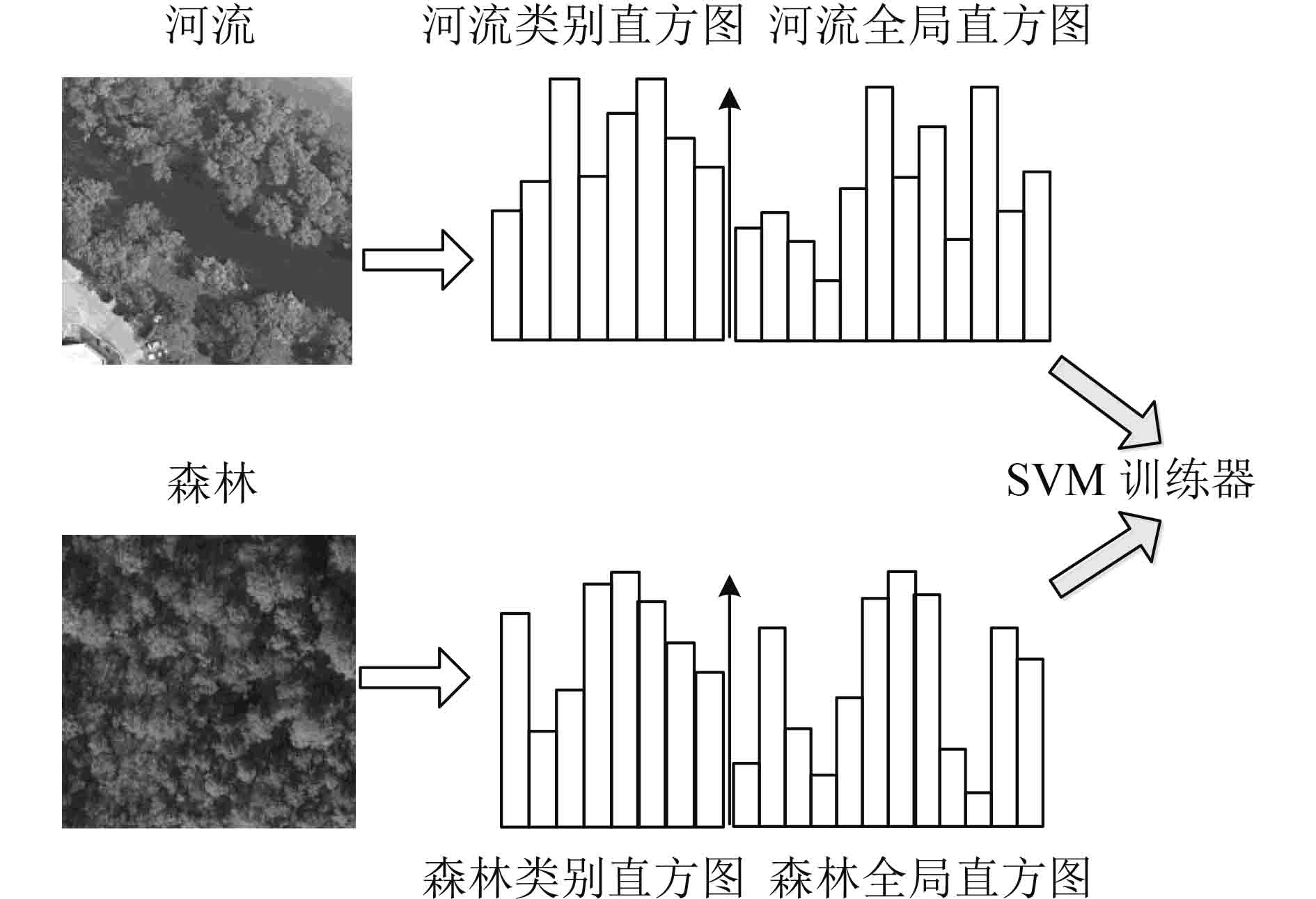
以图3场景为例,河流与森林两个场景背景部分都是森林,场景相似度很高,全局直方图外观也十分相似,难以将其区分。本文方法针对两个场景分别对视觉单词进行特征选择,可以有效的去除场景直方图中较为相似的部分,扩大直方图之间的差异;利用PCA算法剔除具有相关性的视觉单词,得到相互独立的类别视觉词典,使类别直方图的区分力相较于原始的全局直方图有明显提升。

2.4 结合空间金字塔的自适应加权融合
场景分类时,仅使用类别直方图,会导致影像细节信息丢失;仅使用全局直方图,会存在许多与该类别无关的特征信息。因此,采用类别直方图和全局直方图融合的方法以提高分类精度。融合直方图不但保留了影像细节信息,而且能够反映出特定类别与其他类别之间的差异,降低场景错分的可能性,图4为以森林与河流两个相似场景为例的融合直方图生成示意图。
线性融合是目前较为常见融合方法,该方法权重的选择十分重要,须充分考虑类别直方图和全局直方图的维数和每一视觉单词对应的特征数目,将金字塔各图像块中的类别直方图和全局直方图按照式(5)加权联合:
| ${H} = \left[ {\frac{{\mathbf{1}}}{{\mathbf{4}}}{{H}_{\mathbf{0}}},\frac{{\mathbf{1}}}{{\mathbf{4}}}{H}_{\mathbf{1}}^{\mathbf{1}}, \cdots ,\frac{{\mathbf{1}}}{{\mathbf{4}}}{H}_{\mathbf{1}}^{\mathbf{4}},\frac{{\mathbf{1}}}{{\mathbf{2}}}{H}_{\mathbf{2}}^{\mathbf{1}}, \ldots ,\frac{{\mathbf{1}}}{{\mathbf{2}}}{H}_{\mathbf{2}}^{{\mathbf{16}}}} \right]$ | (5) |
式中, Hij 表示第i级第j图像块的融合直方图,每块的融合直方图 HS 如式(6)所示:
| ${{H}_S} = \left[ {{w_1}{{H}_C};{w_2}{{H}_B}} \right]$ | (6) |
式中, HC 为各块的类别直方图, HB 代表每块的全局直方图,w1、w2分别代表 HC 和 HB 的权值,w1、w2定义如式(7)、(8)所示:
| ${w_1} = \frac{{sum\left( {{{H}_C}} \right)}}{{sum\left( {{{H}_B}} \right)}}$ | (7) |
| ${w_2} = 1 - \frac{{sum\left( {{{H}_C}} \right)}}{{sum\left( {{{H}_B}} \right)}}$ | (8) |
式中,sum( HC )代表类别直方图中各数据之和,sum( HB )代表全局直方图中各数据之和。
w1反映类别直方图在全局直方图中的信息量,用于突出了影像类别信息;w2用于弱化影像的全局信息。每幅测试影像分别对所有类别按照式(6)求出每个子区域影像各类别的融合直方图,再按照式(5)结合各级空间金字塔得到最终的融合直方图。
3 实验结果与分析
3.1 实验数据
本文选取UCMerced_LandUse场景图像数据集(Yang和Newsam,2010)验证算法的有效性,该数据集影像为高分辨率遥感影像,每幅图像大小均为256×256,选择8个存在相似场景的语义类别进行实验,分别为农田、飞机场、丛林、居民区、森林、停车场、河流和公路。每一类场景由100幅图像组成,共计800幅影像,图5为数据集的示例影像。本文选取其中30张作为训练影像,剩余70张影像全部作为测试影像。实验中使用SVM分类器一对多的方式进行分类,核函数为金字塔匹配核。

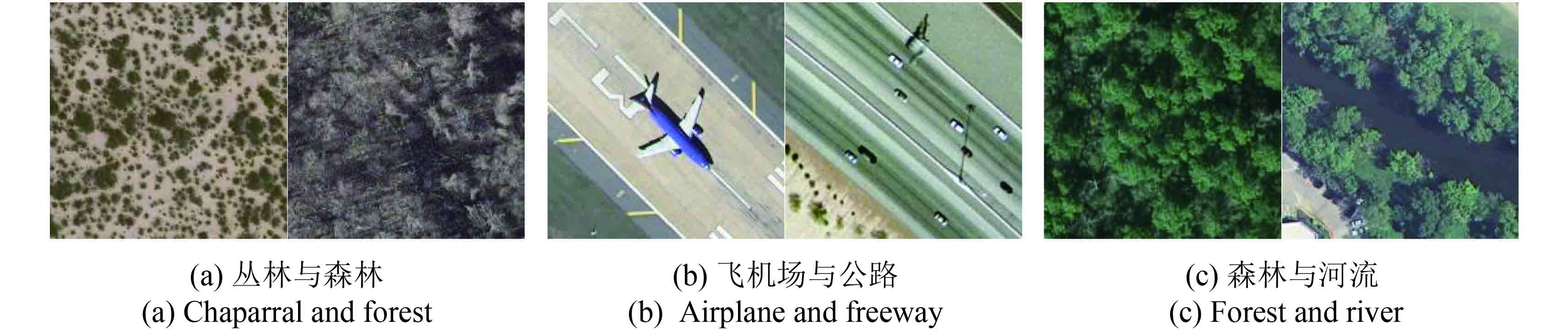
实验影像中存在许多相似场景,如图6(a)-(c)所示,丛林与森林影像组成成分都是树木和土地,区别在于丛林植被种类较多,而森林树木居多;飞机场与公路两者都由交通工具和道路组成,飞机场停落的是飞机,公路则是行驶的车辆;河流两岸的植物与森林相似,但森林场景没有水体。传统方法对以上相似场景的分类没有考虑直方图类别之间差异,用于分类的直方图较为相似,分类结果较差。
3.2 分类性能分析
本文从算法分类精度及稳定性、相似场景分类结果、自适应加权融合效果以及与其他代表方法对比这几个方面验证与分析本文算法性能的优越性。
3.2.1 分类精度及稳定性分析
图7给出原始视觉单词数量分别为100、300、500、700、900和1100时基于金字塔的词包模型方法(下称BOW+SPM)和本文方法的总体分类性能对比。纵轴表示8类地物的平均分类精度,横轴表示全局视觉单词的数目。由图7分析可以得到:本文方法相对BOW+SPM方法,分类精度提高约7%,提升较为明显,通过进行顾及类别的视觉单词优化,使得类别视觉单词突出场景特有的类别信息,拉大相似场景直方图之间的差异性,降低相似场景之间的错分概率;通过剔除与类别关系较弱的冗余视觉单词,保留单词既独立又具有特征代表性,算法稳定性得到增强,相对BOW+SPM方法总体分类精度随视觉单词数目变化减小。
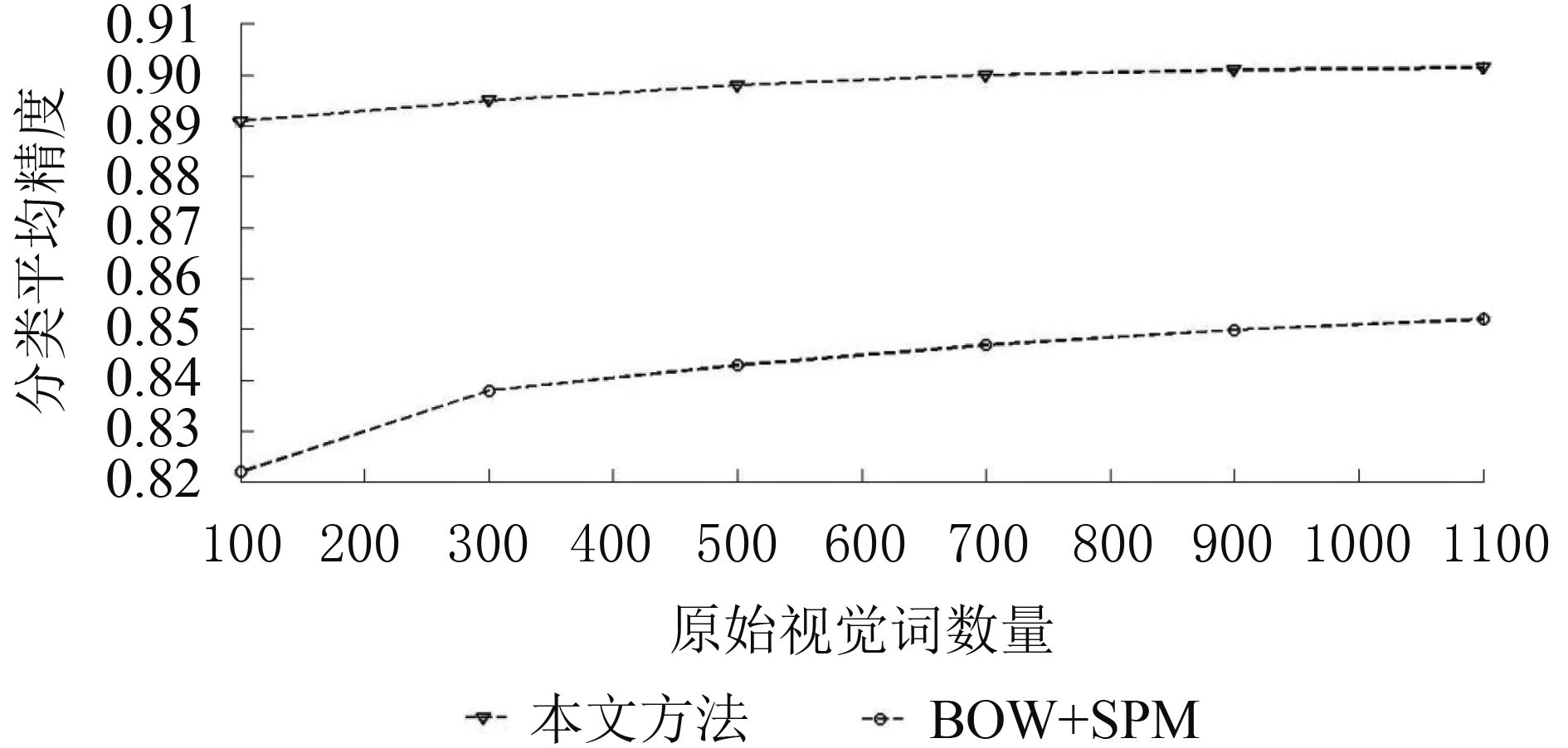
表1给出本文方法和BOW+SPM方法在视觉单词数目为100和500时,不同级别金字塔下8类场景图像的平均分类精度。由表1分析得到:视觉单词长度为100时,本文方法在层级l=0,l=1,l=2时以及联合层级l=0,1,2时分类精度都有明显提高,分别提高了12.9%、9.5%,7.9%,6.9%。视觉单词数目为500时,也有类似提升效果。空间金字塔模型能够增加直方图的空间分布信息,且对各层级存在的错误包容性更强。本文方法在金字塔模型的基础上对视觉单词进行分类别优化,在具有空间分布信息的特征中增强了视觉词典的辨识能力,突出了直方图在空间位置表现的特征差异,使得分类精度有明显提升。
表 1 不同金字塔层级下算法分类性能比较
Table 1 Comparison of performance of different algorithms in different pyramid levels
| /% | |||||
| 视觉单词数量 | 方法 | 单级划分 | 金字塔 | ||
| l=0 | l=1 | l=2 | l=0, 1, 2 | ||
| 100 | BOW+SPM | 72.2 | 77.9 | 79.4 | 82.2 |
| 本文方法 | 86.1 | 87.4 | 87.3 | 89.1 | |
| 500 | BOW+SPM | 74.8 | 78.8 | 79.7 | 84.3 |
| 本文方法 | 87.1 | 88.2 | 88.0 | 89.8 | |
表2给出本文方法和BOW+SPM方法在视觉单词数量为100与500时,计算效率的对比实验,其中,分类总时间分为训练时间和分类时间。加入类别信息后,本文方法训练过程计算效率略有降低,耗时约为BOW+SPM的1.3倍;由于每幅测试影像对应8个融合直方图,测试过程耗时约为BOW+SPM方法的10倍左右。本文算法计算时间有所增加,但增加的时间仍然在可以接受的范围之内,考虑本文算法的分类精度,降低的计算效率对算法性能并未造成很大影响,本文算法依然具有较好的实用性。
表 2 算法时间效率对比
Table 2 Comparison of computational effciency of different algorithms
| /s | ||||
| 视觉单词数量 | 方法 | 训练时间 | 预测时间 | 分类总时间 |
| 100 | BOW+SPM | 1.4 | 3.9 | 5.3 |
| 本文方法 | 1.8 | 45.5 | 47.3 | |
| 500 | BOW+SPM | 2.2 | 6.8 | 9.0 |
| 本文方法 | 2.8 | 70.7 | 73.5 | |
3.2.2 相似场景分析
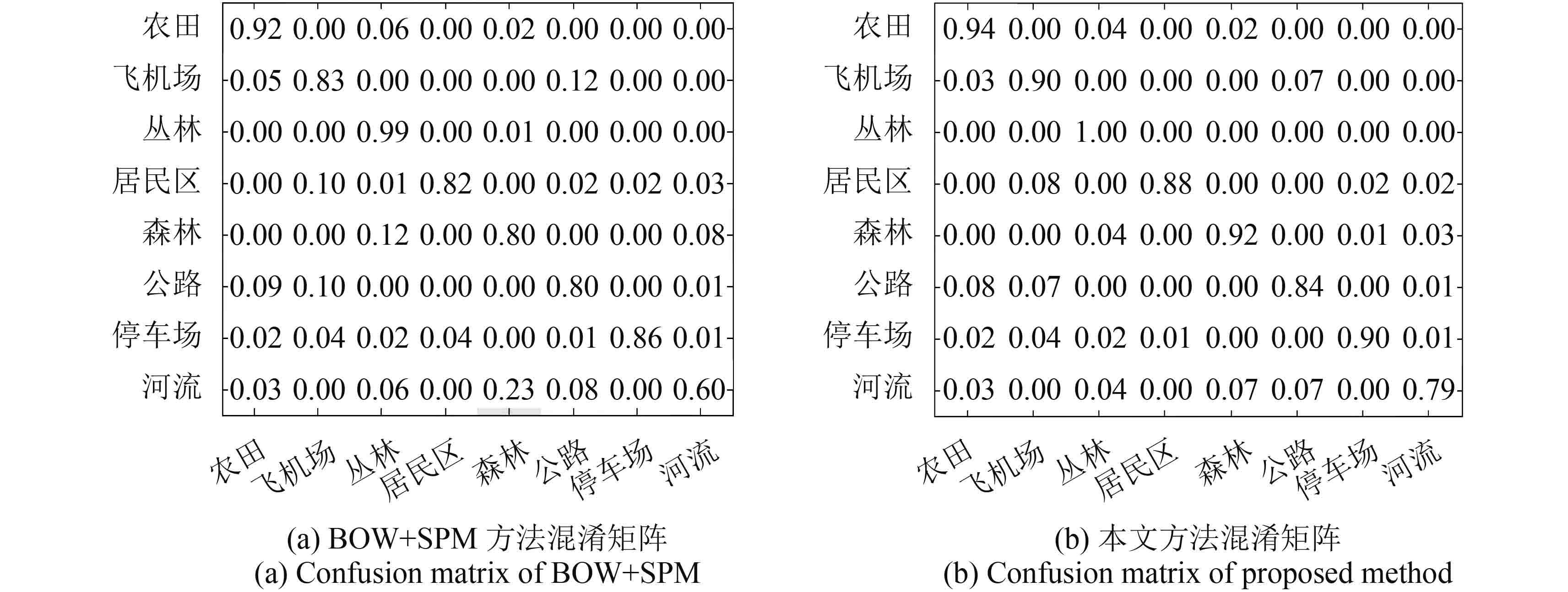
图8显示全局视觉单词数量为500时,本文方法与BOW+SPM方法对8类场景进行分类得到的混淆矩阵图,混淆矩阵的X轴和Y轴均表示场景类别,第i行j列的值表示第i类场景被分为第j类的概率,对角线上元素值代表每类场景的分类精度。计算两种方法的Kappa系数,分别为0.80和0.88,结果表明:本文方法分类精度提升明显。图9给出两种方法区分相似场景的结果对比,图9(a)表示BOW+SPM方法分错而本文方法分对的场景,图9(b)表示两种方法都分错的场景。结合图8和图9可以看出:农田、飞机场、森林和河流等场景,场景外观相互交叉相似,传统方法难以将其区分。本文方法通过对视觉单词进行筛选,保留能够反映场景特征的视觉单词,较好的反映出河流中的水体、飞机场的飞机,森林中的树木等信息,用每一类场景中能够突显场景类别信息的视觉单词进行分类,扩大直方图之间的类别差异,降低错分概率。河流与森林,森林与丛林,飞机场与公路的错分概率分别降低了0.16,0.08和0.05。图9所示的两张红色边框影像,本文方法未能正确区分,这两张影像属于非典型的森林与河流场景,森林中树木干枯,河流中水体接近干涸,影像本身不包含该类别明显的信息特征,因此出现错分。

3.2.3 融合方法对比
表3给出3种不同的加权融合方法,采用三层金字塔联合,全局视觉单词数目为100和500时,对8类地物的总体分类性能对比。由表3可以看出:在不同全局视觉单词数目下,仅使用全局直方图分类性能最差;仅使用类别直方图可以提升分类性能,但类别直方图是由全局直方图降维得到,缺少细节信息,精度提升不明显,仅提升1%左右;使用等比例融合方法可在一定程度上提高分类性能,但融合方法过于简单,没有充分考虑两种直方图的特性,仅提升5%;本文提出的自适应加权融合方法可在原有方法的基础上提升10%的分类性能,提升效果显著。本文将类别直方图和全局直方图进行自适应加权融合,结合两种直方图的优势,有效的保留全局直方图的细节信息,同时突出类别独有特点,使得融合后的直方图很好的反应场景特征,从而显著提高分类精度。实验证明,本文的自适应加权融合方法分类效果最佳。
表 3 各加权融合方式分类性能对比
Table 3 Performance comparison with method with different weights
| /% | ||
| 视觉单词数量 | 方法 | 分类性能 |
| 100 | 仅使用全局直方图 | 78.9 |
| 仅使用类别直方图 | 80.1 | |
| 等比例融合 | 84.2 | |
| 自适应加权融合 | 89.1 | |
| 500 | 仅使用全局直方图 | 79.3 |
| 仅使用类别直方图 | 80.4 | |
| 等比例融合 | 84.8 | |
| 自适应加权融合 | 89.8 | |
3.2.4 与其他代表性方法的对比
本文方法与其他3种有代表性方法进行对比实验,分别为BOW+SPM,PLSA和基于互信息的场景分类方法。BOW+SPM方法如上文所述,使用金字塔匹配核,利用SVM分类器进行分类;Probability Latent Semantic Analysis (PLSA)方法(Jiang 等, 2010)对图像进行标准格网划分,对所有网格进行SIFT特征点提取,视觉单词的数量为500,主题个数为25,该方法对视觉单词进行了二次抽象,然后使用SVM分类器进行分类;基于互信息的场景分类方法(Xie, 2011),在l=0尺度下使用互信息进行视觉单词选择,视觉单词数为500,使用SVM分类器进行分类。
为保证实验条件一致,本文方法视觉单词数量设置为500,所有方法均使用0阶金字塔。分类结果如表4所示,本文方法在实验条件相近的情况下,对金字塔各级全局直方图进行分类别视觉单词优化,提高了视觉词典的辨识能力,突出了场景之间的差异,全局直方图和类别直方图融合后的直方图同时保留两者的特性,相对其他方法分类精度更高,具有较强的优越性。
表 4 与其他代表方法的对比
Table 4 Performance comparison with other representative methods
| /% | ||
| 方法 | 平均分类准确度 | |
| BOW+SPM | 72.20 | |
| PLSA | 82.50 | |
| 基于互信息的场景分类方法 | 83.25 | |
| 本文方法 | 87.10 | |
4 结 论
本文提出一种顾及遥感影像场景类别信息的视觉单词优化分类方法。该方法引入Boiman的分配策略生成全局直方图,通过统计特定类别的影像数据在全局视觉词典出现的频率,对视觉单词进行特征选择并使用PCA方法进行视觉单词优化,消除视觉单词的冗余性,生成类别直方图。将全局直方图和类别直方图自适应加权融合,最终使用结合空间金字塔的融合直方图进行分类。融合直方图不仅突出了影像之间的类别差异,考虑了影像的空间与全局信息,同时弱化了全局直方图中与类别无关的视觉单词信息,能够充分反映影像的类别特点,从而提高了算法的准确度。实验结果表明:该方法具有较好的分类精度和较高的稳定性,受全局视觉词数目影响很小;融合后的直方图区分能力更强,显著降低相似场景间的错分率;相对现有遥感影像场景分类方法精度显著提高,能够为遥感影像分类及变化检测提供良好基础。该方法虽强调出类别之间的差异性,但对类别之间差异极小的场景区分能力较弱;本文没有考虑大类场景下的小类场景区分,这些将是未来工作的研究重点。
参考文献(References)
-
Agarwal A and Triggs B. 2008. Multilevel image coding with hyperfeatures. International Journal of Computer Vision, 78 (1): 15–27. [DOI: 10.1007/s11263-007-0072-x]
-
Bo L F and Sminchisescu C. 2009.Efficient match kernel between sets of features for visual recognition//Advances in Neural Information Processing Systems. Vancouver, British Columbia, Canada: Curran Associates, Inc.:135–143
-
Boiman O, Shechtman E and Irani M. 2008.In defense of nearest-neighbor based image classification//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, AK: IEEE: 1–8
-
Cao L L and Li F F. 2007. Spatially coherent latent topic model for concurrent segmentation and classification of objects and scenes// Proceedings of the IEEE 11th International Conference on Computer Vision. Rio de Janeiro:IEEE: 1–8
-
Chen J N, Huang H K, Tian S F and Qu Y L. 2009. Feature selection for text classification with Naïve Bayes. Expert Systems with Applications, 36 (3): 5432–5435. [DOI: 10.1016/j.eswa.2008.06.054]
-
Csurka G, Dance C R, Fan L Z, Willamowski J and Bray C. 2004. Visual categorization with bags of keypoints//Workshop on Statistical Learning in Computer Vision.Prague:ECCV: 1–22
-
Dalal N and Triggs B. 2005.Histograms of oriented gradients for human detection//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05). San Diego, CA, USA:IEEE: 886–893
-
Datta R, Joshi D, Li J and Wang J Z. 2008.Image retrieval: ideas, influences, and trends of the new age. ACM Computing Surveys, 40(2):Article No. 5
-
Hao J and Jie X. 2010.Improved bags-of-words algorithm for scene recognition// Proceedings of the 2010 2nd International Conference on Signal Processing Systems (ICSPS). Dalian:IEEE: V2-279-V2-282
-
Jiang Y, Wang R S and Wang C. 2010. Scene classification with context pyramid features. Journal of Computer-Aided Design and Computer Graphics, 22 (8): 1366–1373. ( 江悦, 王润生, 王程. 2010. 采用上下文金字塔特征的场景分类. 计算机辅助设计与图形学学报, 22 (8): 1366–1373. )
-
Jiang Y G, Ngo C W and Yang J. 2007.Towards optimal bag-of-features for object categorization and semantic video retrieval//Proceedings of the 6th ACM International Conference on Image and Video Retrieval. Amsterdam, The Netherlands:ACM: 494–501
-
Juneja M, Vedaldi A, Jawahar C V and Zisserman A. 2013.Blocks that shout: distinctive parts for scene classification//Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition.Portland, OR: IEEE: 923–930
-
Jurie F and Triggs B. 2005.Creating efficient codebooks for visual recognition// Proceedings of the 10th IEEE International Conference on Computer Vision. Beijing, China: IEEE: 604–610
-
Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R and Li F F. 2014. Large-scale video classification with convolutional neural networks//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. Columbus, OH: IEEE: 1725–1732
-
Krizhevsky A, Sutskever I and Hinton G E. 2012.Imagenet classification with deep convolutional neural networks//Advances in Neural Information Processing Systems. Lake Tahoe, Nevada:Curran Associates Inc.: 1097–1105
-
Larlus D and Jurie F. 2006.Latent mixture vocabularies for object categorization// Proceedings of the 17th British Machine Vision Conference.BMVA Press: 959–968
-
Li Q, Zhang H G, Guo J, Bhanu B and An L. 2012. Improving bag-of-words scheme for scene categorization. The Journal of China Universities of Posts and Telecommunications, 19 : 166–171. [DOI: 10.1016/S1005-8885(11)60426-3]
-
Moosmann F, Nowak E and Jurie F. 2008. Randomized clustering forests for image classification. IEEE Transactions on Pattern Analysis and Machine Intelligence, 30 (9): 1632–1646. [DOI: 10.1109/TPAMI.2007.70822]
-
Oliva A and Torralba A. 2001. Modeling the shape of the scene: A holistic representation of the spatial envelope. International Journal of Computer Vision, 42 (3): 145–175. [DOI: 10.1023/A:1011139631724]
-
Perronnin F. 2008. Universal and adapted vocabularies for generic visual categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 30 (7): 1243–1256. [DOI: 10.1109/TPAMI.2007.70755]
-
Sadeghi F and Tappen M F. 2012.Latent pyramidal regions for recognizing scenes//Proceedings of the 12th European Conference on Computer Vision. Berlin Heidelberg:Springer: 228–241
-
Singh S, Gupta A and Efros A A. 2012.Unsupervised discovery of mid-level discriminative patches// Proceedings of the 12th European Conference on Computer Vision.Berlin Heidelberg:Springer: 73–86
-
Sivic J and Zisserman A. 2003.Video Google: atext retrieval approach to object matching in videos// Proceedings of the 9th IEEE International Conference on Computer Vision. Nice, France: IEEE: 1470–1477
-
Van Gemert J C, Veenman C J, Smeulders A W M and Geusebroek JM. 2010. Visual word ambiguity. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32 (7): 1271–1283. [DOI: 10.1109/TPAMI.2009.132]
-
Wu J X and Rehg J M. 2011. CENTRIST: avisual descriptor for scene categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33 (8): 1489–1501. [DOI: 10.1109/TPAMI.2010.224]
-
Xie W J. 2011. Research on Middle Semantic Representation Based Image Scene Classification.Beijing:BeijingJiaotong University (解文杰. 2011.基于中层语义表示的图像场景分类研究. 北京: 北京交通大学)
-
Yang J C, Yu K, Gong Y H and Huang T. 2009.Linear spatial pyramid matching using sparse coding for image classification// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Miami, FL:IEEE: 1794–1801
-
Yang Y and Newsam S. 2010. Bag-of-visual-words and spatial extensions for land-use classification//Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems. San Jose, California:ACM: 270–279
-
Yang Y M and Pedersen J O. 1997.A comparative study on feature selection in text categorization//Proceedings of the Fourteenth International Conference on Machine Learning.San Francisco, CA, USA: Morgan Kaufmann Publishers Inc.: 412–420
-
Zhao LJ, Tang P, Huo L Z and Zheng K. 2014. Review of the bag-of-visual-words models in image scene classification. Journal of Image and Graphics, 19 (3): 333–343. [DOI: 10.11834/jig.20140301] ( 赵理君, 唐娉, 霍连志, 郑柯. 2014. 图像场景分类中视觉词包模型方法综述. 中国图象图形学报, 19 (3): 333–343. [DOI: 10.11834/jig.20140301] )


