



2. 中南大学地理信息系, 湖南 长沙 410083;
3. 西南交通大学高铁运营安全空间信息技术国家地方联合实验室, 四川 成都 611756
2. Department of Geo-Informatics, Central South University, Changsha 410083, China;
3. State-Provincial Joint Engineering Laboratory of Spatial Information Technology for High-speed Railway Safety, Southwest Jiaotong University, Chengdu 611756, China
空间聚类是描述地理现象空间依赖性的重要手段。空间依赖性是地理现象的内蕴特征,其表现为邻近空间数据间通常表现出较强的相似性[1]。空间依赖性的刻画对于研究地理现象的产生机理、分布规律及发展变化趋势具有重要的价值[2]。
空间聚类的核心目的在于依据空间数据间的相似性将空间数据划分为一系列的空间簇,使得相同簇内空间实体相似性尽可能高,而不同簇间空间实体的差异性尽可能大[3-4]。空间聚类在地学领域具有重要的应用价值,已经受到国内外学者的广泛关注,以“空间聚类”为主题的SCI/SSCI论文数目在直线上升(图 1)。

|
| 图 1 以“空间聚类”为主题的SCI/SSCI论文数目(数据源自Web of Science) Fig. 1 The number of SCI/SSCI indexed papers on spatial clustering (from Web of Science) |
空间聚类可以单独作为一种空间依赖性的探索性数据分析工具。例如,在公共卫生领域,空间聚类已经被广泛用于疾病暴发模式识别[5];在犯罪学领域,空间分析已经成为犯罪热点探测的主要工具[6];在气候学领域,空间聚类是气候带识别的有力手段[7];在地质学领域,空间聚类已经被成功应用于地震分布规律的探测[8];在生态学领域,空间聚类也是生态区域划分与景观模式识别的重要工具[9]。
空间聚类对空间依赖性的描述也可以作为其他空间数据分析任务的主要预处理步骤。例如,对于面向对象的高分辨率遥感影像分割分类,空间聚类是对象生成的主要手段[10];稀有事件(如癌症)分析领域,空间聚类是解决小样本问题(small population problem)的有效工具[11];在制图自动综合研究中,空间聚类已经被广泛应用于群组识别[12];在地理可视化等方面,空间聚类可以有效降低空间数据冗余[13];在时空预测建模等方面,空间聚类也是处理空间异质性的一种有效途径[14]。
伴随着大数据时代的到来,空间聚类同样是从大数据中发现价值必须面对的一个普遍性和基础性的问题,有望成为大数据认知的突破口[15]。目前,空间聚类已近成为空间统计、空间数据挖掘、图像模式识别等多个领域研究的核心研究内容,并已经取得了一些代表性的研究成果。然而,由于空间聚类的尺度依赖特征建模能力的不足,导致聚类结果“无中生有”、“无从理解”的困境,已经成为制约当前空间聚类理论研究与实际应用的关键瓶颈问题。为此,本文旨在模拟人类视觉多尺度认知原理及多尺度表达的“自然法则”,建立了一套尺度驱动的空间聚类理论,构建适用不同应用需求的多尺度空间聚类模型。
1 空间聚类的发展:研究进展与方法形成 1.1 空间聚类研究的发展回顾聚类是人类认知自然最基本与最有效的技能之一,长期以来聚类的思想一直以一种经验的形式指导人类实践。1939年,文献[16]首次采用聚类的思想从相关矩阵中提取互相关的组,标志着聚类作为专门研究学科的建立。随后,聚类技术得到了迅速发展,一些沿用至今的经典聚类方法(如k-means)在20世纪50、60年代被相继提出[17]。自20世纪70、80年代以来,伴随着空间数据采集与管理能力的突破性进展,专门针对空间数据的空间聚类研究成为聚类研究的热点。现有空间聚类算法一类是直接移植于聚类早期的研究成果,如空间点事件的聚类问题可以视为一种二维聚类问题;另一类方法是依据空间数据的独特性质(如空间自相关、空间异质性等)而对聚类研究成果的新发展,如自20世纪70年代,地理学与空间统计领域便开始了对空间聚类研究的探索,并发展了一些专门的空间聚类方法,如AZP(automated zoning procedure)[19]与地理分析机[20]等。到20世纪80年代,随着空间数据挖掘技术的兴起,空间聚类研究的关注度持续升温,在理论方法与应用研究方面均取得了重要的进展[21]。下面将对空间聚类方法进行梳理和分析。
1.2 空间聚类方法的形成当前,空间聚类算法的数目繁多,其主要原因有以下两个:
1.2.1 空间簇的定义十分主观[22-23]在实际应用中,3种类型空间簇的定义被广为接受[24]:
(1) 基于中心的簇:即空间簇可以用其中心表示,且簇内空间实体与簇的中心尽可能接近(或相似),而尽可能远离(或异于)其他簇的中心,如图 2(a)所示,基于中心的簇通常是近似球形的。

(2) 基于连接的簇:即空间簇是由邻近(相似)的空间实体通过相互间的连接关系构成的,如图 2(b)所示,基于连接的簇形状可能是不规则的。
(3) 基于密度的簇:即空间簇被定义为被低密度区域分隔的连通高密度区域,如图 2(c)所示,基于密度的簇形状可以是不规则的,且可以对簇和噪声进行区分。
1.2.2 不同类型的空间数据需要不同的聚类方法[25-26]若不考虑空间数据本身的几何形态,空间数据主要可以区分为4种类型[27-28]:
(1) 点事件:主要记录了地理事件或空间设施的空间位置与时间标签,如犯罪事件、疾病病例、兴趣点等,点事件构成的簇一方面需要满足点事件间空间或时空邻近,同时簇的形态通常是不规则的且可能受到空间障碍(如河流、道路)的约束。
(2) 空间格数据:通常记录了研究区域内有限空间单元内的计数值或平均度量值,如遥感影像数据、城市街区人口数据、区域疾病发病率等,空间格数据构成的簇通常需要保证空间连续性。
(3) 地统计数据:主要记录了空间连续变量的点观测值,如气温、降水、土壤重金属含量等,地统计数据构成的簇通常需要同时满足专题属性的相似性与时空邻近性。
(4) 移动轨迹:主要记录了空间对象运动的位置、时间、状态等信息,如人类活动轨迹、动物迁徙轨迹及车辆运行轨迹等,轨迹数据构成的簇需要满足时空连续性的约束。
基于上述3种空间簇类型的定义,空间聚类算法主要可以分为3类:① 基于中心簇定义的划分聚类方法;② 基于连接簇定义的层次聚类方法;③ 基于密度簇定义的密度聚类方法。
1.3 空间聚类算法针对不同空间数据类型,每类聚类方法也衍生出一系列的变种。下面将对上述3类空间聚类算法作简要评述。
1.3.1 划分聚类算法其核心步骤在于通过不断优化基于簇内距离定义的目标函数,将空间数据划分为给定数目的空间簇。k-means是最为典型的划分聚类方法[29],为了提高k-means的稳健性与效率,一些改进的方法被相继提出,如ISODATA[30]、k-mediods[31]、FCM[32]、CLARANS[33]等。上述方法仅能直接应用于空间点的聚类问题,为了同时考虑空间邻近与专题属性相似性,一些划分聚类的方法通过在目标函数中添加空间惩罚算子来保证簇内的空间一致性[34-35];针对空间格数据聚类问题,Openshaw同时考虑空间连通约束与簇内均质性构造目标函数,提出了一种AZP方法[19],后续一些研究对AZP方法容易陷入局部最优[36]、初始簇数设定[37]等问题进行了一系列的改进。
20世纪80年代以来,伴随着人工智能的发展,神经网络方法也被引入空间聚类,其中常用的SOM方法[38-39]实际上可以视为k-means的一种变种,但是其聚类的稳定性和质量得到提高,同时提供了聚类可视化的重要途径。近年来,SOM方法同样被拓展应用于空间格数据与地统计数据,代表性方法有GeoSOM[40]、HSOM[41]等。
1.3.2 层次聚类算法层次聚类算法的核心内容在于定义簇间距离,不断凝聚或分裂获得指定数目的空间簇。常用的簇间距离定义方法包括最近距离(单连接算法)、最远距离(全连接算法)、平均距离(平均连接算法)、最小方差距离(沃德法)等[31]。为了降低噪声点干扰,CURE等方法也通过选取簇内部分代表点的方法计算簇间距离[42]。
另一些方法也借助图的边长来定义簇间的距离,通过合并短边连接的空间实体或删除长边连接的空间实体进行层次聚类[43],常用的图包括最小生成树[44-45]、K最近邻图[46]、Delaunay三角网[47-48]等。为了在层次聚类过程中考虑空间的连续性,可以直接在计算簇间距离时加入空间约束,即只计算空间邻近实体间的距离[49-50]。为了能够在层次聚类过程中动态优化聚类结果,一些方法进一步在空间约束层次聚类结果的基础上构造基于簇内均质性的目标函数,将层次聚类树分割为指定数目空间簇[51-52]。
1.3.3 密度聚类算法密度聚类算法的核心目的在于发现空间实体聚集的高密度区域。早期的一些方法采用扫描窗口在空间或时空域上进行滑动,旨在发现窗口内实体数量或计数显著高于窗口外的高密度窗口,代表性方法有地理分析机[20]与扫描统计量[53]。这类方法难以准确描述空间簇的形态,虽然一些方法能够发现不规则形状的簇,但是计算效率过低[54-55],且多仅能处理空间格数据[56]。
为了克服上述问题,以DBSCAN[57]为代表的一系列方法首先对空间实体局部密度进行估计,进而将空间连续的高密度空间实体连接成簇,可以高效发现不同形状的空间簇。在DBSCAN的基础上后续改进工作主要集中于两方面:一类方法旨在克服DBSCAN难以发现密度差异较大空间簇的不足,代表方法有OPTICS[58]、SNN[59]、ADBSC[60]、DECODE[61]等方法;另一类,将DBSCAN方法拓展应用于不同类型的空间数据,例如针对时空点事件聚类的WNN[62]、STSNN[63],可以聚类空间格数据的GDBSCAN[64]、针对地统计数据的ST-DBSCAN[65]、DBSC[66]以及一系列移动轨迹聚类方法[67-69]。
2 空间聚类的瓶颈问题:尺度依赖 2.1 空间聚类研究的两大困惑虽然国内外学者已经对空间聚类开展了持续的研究,并且已经取得了部分代表性的成果,但是空间聚类在实际应用中依然面临两大困境:
2.1.1 无中生有问题绝大多数方法即使针对不包含聚类结构的数据集,仍然会发现聚类。如图 3所示,针对一个不包含聚类结果随机点事件数据集,当前3类空间聚类方法,即使是能区分噪声的密度聚类方法仍然发现了空间簇,显然这些聚类结果是无效的。

|
| 图 3 随机点事件聚类结果 Fig. 3 Clusters discovered from random spatial points |
2.1.2 无从理解问题
即使同一种聚类方法,采用不同的聚类参数依然会获得千变万化的聚类结果。如图 4所示,针对同一点事件数据集,DBSCAN算法在不同参数下得到的聚类结果差异极大,在实际应用中很难对这些聚类结果进行解释。

|
| 图 4 不同参数下DBSCAN算法针对同一点事件数据集的聚类结果 Fig. 4 The clustering results obtained by DBSCAN using different parameters |
分析上述两个问题的产生根源,是由于空间聚类结构(即空间簇)的尺度依赖特性的直接作用。空间聚类结构作为一种典型的空间模式,其在不同尺度上的表现形式必然存在差异[70-72],这也就可以解释为何一个数据集会得到不同的聚类结果;而空间数据固有的尺度信息决定了从空间数据中发现空间模式(或信息)的种类、数量与可靠性[73-74],因此可以推断空间聚类结果的可靠性或显著性直接受到数据尺度的影响。
2.2 空间聚类的尺度问题在现有研究中,空间聚类的尺度依赖问题已经开始得到部分关注,例如:地理分析机与扫描统计等方法希望通过设置不同大小的扫描窗口发现不同尺度的空间簇;基于密度的方法,旨在通过设置不同大小的局部密度估计带宽(或单元)来探测多尺度的空间簇,代表性方法有尺度空间方法[75-77]、WaveCluster[78]、STING[79]、Meanshift[80]等。然而,实际中这些方法并无法真正发现多尺度的空间聚类结果,如图 5所示,即使针对简单的空间点事件数据,尺度空间方法在不同带宽下的聚类结果并没有准确识别不同形状、密度的空间簇。

依据Goodhild和Quattrochi对建模尺度依赖问题的总结[81],空间聚类的尺度依赖性建模需要系统地考虑以下5个相互关联的主要问题:
(1) 空间聚类尺度的参数化表达:尺度本身的含义就是模糊的、容易混淆的,不同的应用领域、不同的分类准则下,尺度分类和含义通常都存在差异[82]。空间聚类模型中,尺度如何量化为一系列的参数?
(2) 度量尺度的影响:如何度量尺度对空间聚类结果的影响?
(3) 控制尺度的改变:如何控制尺度参数的改变获得多尺度的空间聚类结果?
(4) 构造多尺度的空间聚类模型:如何构建可执行的通用框架进行多尺度空间聚类?
(5) 尺度不变性:空间聚类结果的何种特征不随尺度的改变而产生变化?
本文尝试从人类视觉多尺度认知的生理学原理出发,根据“自然法则”来解决上述问题。
3 尺度驱动的空间聚类理论 3.1 人类认知多尺度聚类结构的生理基础空间聚类是人类基本的认知能力,空间簇的定义从根本上植根于人类的主观认识[18, 83-84]。在二维或三维空间,人类视觉可以轻易地发现一些小样本数据中的聚类结构,模拟人类这种本能的“聚类”(如格式塔准则)一直是空间聚类算法设计的核心指导思想[44, 75]。空间聚类的尺度依赖问题也是建立在人类视觉认知的基础之上:在不同观测距离下发现空间簇的数目和详细程度不同,观测距离越远识别的空间簇数目越少、结构越模糊[77, 85]。为了模拟人类这种多尺度聚类的能力,首先需要对这种认知能力背后的生理学结构进行必要的认识。得益于神经科学与脑认知领域的研究进展[86-88],目前对人类视觉认知的生理结构已经有了初步的了解,如图 6所示。

人类视觉形成的两个核心生理结构是视网膜与视皮层,前者将光信号转换为电信号,并送达大脑,后者负责对这些电信号进行处理最后形成视觉认知。为了分析人类多尺度视觉认知的原理,我们需要解释3个问题:① 人们在一定观测距离上看到的是什么?② 人们在不同观测距离上看到的是什么?③ 视觉认知是否有尺度不变性?
视网膜结构可以类比于一架特殊的照相机,而视网膜上的感受野结构犹如这架照相机的镜头[89]。视觉通路上不同阶段上,视神经连接的感受野尺寸不断增大、结构越来越复杂,因此视网膜上包含了不同尺寸和结构的感受野,犹如一架装配有不同焦距镜头的照相机[90]。感受野的尺寸与观测距离一起决定了视网膜成像的分辨率,在一定观测距离上,感受野尺寸越小分辨率越高,感受野尺寸越大分辨率越低。因此,即使在一定观测距离上,视网膜对现实世界的采样是一系列不同分辨率的图像(即尺度空间),而且对不同分辨率图像的采样没有偏向性[91]。视皮层对这些不同分辨率的图像进行进一步分析,形成最后的视觉认知。进一步,当观测距离不断增大时,由于感受野本身尺寸的限制,视网膜采样图像的最高分辨率将不断降低,因此通过视皮层分析获得的认知图像也将不断模糊[86],这也是多尺度表达的“自然法则”的基本原理[92]。虽然人类的大脑输入的是现实世界多尺度的表达,但是认识系统具有识别尺度不变结构的天然能力,其生理学基础在于每种结构均通过相应尺寸感受野引起视皮层神经元的兴奋,而能够使得较多神经元兴奋的结构将更稳定地被感知,这种尺度不变性的特性已经在心理测试中被验证[93-94]。
通过上述分析,可以发现人类的多尺度聚类认知过程受到两个关键因素的影响:观测距离与感受野尺寸。这二者在人类多尺度视觉认知中的功能是指导空间聚类中尺度定义与尺度参数化表达的重要参考。
3.2 空间聚类中的尺度表达基于对人类多尺度认知生理过程的剖析,发现空间聚类中主要可以定义两类尺度[95]:
数据尺度:一般指用于空间数据采样的尺度。一个数据集可以抽象为一幅特殊的图像[75, 77],数据(或图像)的尺度由采样的最高分辨率决定。在人类视觉多尺度认知中,视网膜可以视为一种空间数据的采样框架,这个采样框架最高分辨率的变化直接受到观测距离的控制。在人类视觉认知中,增大观测距离实际上提供给大脑不同尺度的空间数据进行分析,可以视为一种尺度上推的过程。
分析尺度:通常指给定数据中地理现象或空间模式分析的窗口。现有研究已经发现,视网膜上的一些简单感受野可以从数学上严格表达为一种核结构(如墨西哥帽函数),而感受野的尺寸起到了带宽的作用[89]。不同尺寸感受野获得的尺度空间图像,实际上类似于一种概率密度估计的过程,不同尺寸感受野获得的概率密度图像上发现的空间模式幅度也不相同[80]。
实际上,空间聚类的尺度依赖性主要体现在上述两类尺度的改变,为了进一步对空间聚类尺度依赖性进行量化建模,需要对数据尺度与分析尺度的进行参数化描述。
数据尺度的度量:虽然数据的尺度在不同领域具有不同的度量方式,但是其一般可以定义为研究范围、分辨率和精度[96]。针对不同类型的空间数据,具体的度量指标存在一定差异,例如针对点事件,数据分辨率可以定义为两点间最短距离或比例尺;针对格数据,遥感影像的空间分辨率通常定义为最小可分辨实体尺寸,而对于社会经济等面状数据而言,分辨率通常定义为单元的尺寸或数目。
分析尺度的度量:分析尺度的度量需要同时考虑空间簇的定义与空间数据的类型。对于划分或层次聚类模型而言,分析尺度主要可以定义为空间簇的数目或簇内均质性;对于基于密度的聚类模型,分析尺度主要定义为邻近范围(空间邻近、属性相似)。
3.3 多尺度空间聚类模型的普适性表达基于量化的尺度表达,可以建立一种以尺度为参数的多尺度空间聚类模型[95]
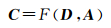 (1)
(1)
式中,C表示聚类结果;F表示空间聚类模型;D表示数据尺度度量参数;A表示分析尺度度量参数。
多尺度聚类模型中,数据尺度对不同分析尺度结果可靠性的影响被建模为一个假设检验问题,如图 7所示。需要注意的是,由于分析尺度不唯一导致多个备择假设同时进行检验,这是一种多重假设检验问题,本文采用控制错误发现率的方法(FDR)进行校正[97]。由式(1) 可见,通过控制数据尺度或分析尺度的参数,可以获得具有明确含义的多尺度空间聚类结果。对于不同尺度的聚类结果,依据视觉认知的尺度不变性原理,在一系列较长尺度范围内保持稳定的聚类结果,可以认为是更为有效的聚类结果,可以采用“尺度生存期”对聚类结果的有效性进行定量的度量[75]。下面将分别给出空间点事件与地统计数据的多尺度空间聚类模型实现方法。

|
| 图 7 数据尺度与分析尺度的关系建模 Fig. 7 Construction of relationship between data and analysis scale |
4 尺度驱动的空间点事件聚类模型 4.1 数据尺度与分析尺度间关系统计建模
针对空间点事件,数据尺度可以用数据分辨率与数据范围来衡量,其中数据分辨率具体可以量化为比例尺,而数据范围可以量化为数据的外包多边形及其面积。由于基于密度的簇定义可以同时描述球形与非球形的空间簇,因此可以被选为空间聚类模型,相应地分析尺度可以量化为估计局部密度的空间邻域尺寸,本文定义为圆形邻域的半径。在给定分析尺度上,局部密度的显著性可以建模为一种多重假设检验问题
H0:空间点事件随机分布;
H1, H2, …, Hi, …, HN:第i个空间点事件的局部密度显著高于随机情况。
一般情况下,零假设下空间点事件的分布可以定义为一种完全空间随机模式
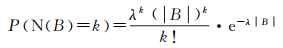 (2)
(2)
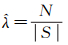 (3)
(3)
式中, N(B)表示空间邻域B内包含空间点事件的个数;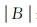
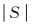
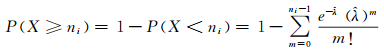 (4)
(4)
式中,ni表示第i个空间点事件邻域内空间点事件的数目。进一步采用FDR方法对多重检验进行校正,将由式(4) 计算获得的N个空间点事件的p-value值升序排列,寻找最大的k值满足
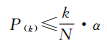 (5)
(5)
式中,α表示显著水平(一般设为0.05或0.01)。所有p-value值小于P(k)的空间点事件,其局部密度可以识别为显著高于随机分布,定义为高密度的核点。
4.2 基于Delaunay三角网的分析尺度自适应选择分析尺度除了估计局部密度,还承担了将高密度核点聚集成簇的任务。若不同空间簇密度高低不同,则需要自适应地估计分析尺度,以确保不同密度的核点都可以聚集成簇。自适应的分析尺度需要同时满足在密度高的区域空间邻域半径相对较小,而在密度低的区域空间邻域半径相对较大。为了满足这一要求,Delaunay三角网是一个合适的建模工具。Delaunay三角网的边长在密度高的区域相对较短,而在密度低的区域边长相对较长。基于这一特点,自适应的分析尺度选择可以通过提取Delaunay三角网边长统计规律实现[98]。针对任一空间实体pi,以pi为中心的空间圆形邻域半径可以定义为
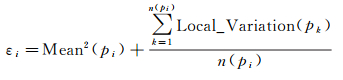 (6)
(6)
式中,Mean2(pi)表示pi二阶邻域的平均边长;n(pi)表示pi二阶邻域内空间点事件的数目;Local_Variation(pk)表示直接与pk连接边长的方差。若两个高密度的核点pi和pj是空间连接的,则要同时满足下面两个条件:① d(pi, pj)≤εi;② d(pi, pj)≤εj。d(pi, pj)表示空间点事件pi和pj间的距离。与DBSCAN算法类似,高密度的空间核点依据空间连接关系聚集成簇。
4.3 基于自然法则的数据尺度控制策略数据尺度的控制旨在模拟不同观测距离下,由于感受野尺寸的限制导致的视网膜采样的模糊效应。这种效应可以采用自然法则[92]进行形式化地描述:“对于一个给定的尺度, 能表现的地理对象之空间变化细节是有局限性的。当超越某种限度时, 所有的细节不能表现出来, 因此可以忽略不计”。
实际上这种限度即表示了人眼感受野尺寸的限制,其在实地距离上的约束(K)可以量化表达为
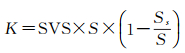 (7)
(7)
式中,SVS表示人眼的最小可分辨距离(或尺寸);S表示空间数据展示的比例尺;Ss表示空间数据的源比例尺。
实践中发现,人眼能区分的最小点符号的尺寸介于0.2 mm到1 mm之间[96],据此可以将SVS经验性地设为1 mm。在自然法则指导下,可以对空间聚类中数据尺度的影响进行定义:
(1) 给定数据尺度上,如果两个空间点事件间的距离小于等于K,则认为二者不可区分;
(2) 给定数据尺度上,若一系列空间点事件可以通过K进行连接(即能够被Eps=K,MinPts=1的DBSCAN算法聚类),则认为这些空间点事件不能区分。
所有不能区分的空间点事件不参与式(2)—(4) 的计算。图 8给出了图 4和5中空间点事件数据集在不同比例尺上的展示结果,并勾画出其中人眼识别的聚集结构。图 9给出了尺度驱动的空间聚类模型通过自然法则控制数据尺度而获得的多尺度聚类结果,直观上可以发现图 8中人眼识别的聚类结果均被很好地发现(为节省空间,数据范围没有依比例尺设置)。采用Jaccard系数评价聚类结果与人眼识别结果的吻合度发现,平均精度超过0.95。

|
| 图 8 不同数据尺度(比例尺)上人眼识别的空间聚类结构 Fig. 8 Spatial clusters identified by human at different data scales (or cartographic ratio) |

|
| 图 9 尺度驱动空间点事件聚类模型的多尺度聚类结果 Fig. 9 Multi-scale clustering results obtained by using the scale-driven model |
5 尺度驱动的地统计数据聚类模型
地统计数据的数据尺度一般从3个方面度量:研究范围、数据分辨率和精度。数据分辨率不仅包括采样单元的大小,同时也包括专题属性的区分能力[74]。精度通常也包括采样单元精度和专题属性值的精度,需要注意的是精度受到数据分辨率的影响。地统计数据中空间簇通常有两种类型,一种是专题属性值相似实体构成的,另一种是专题属性值的热点或冷点。现有的3种空间聚类模型都可以使用,但是其本质上都是优化簇内的均质性或“热度”,因此分析尺度可以被定义为簇内均质性或“热度”的度量。本文以发现专题属性相似且空间邻近实体所构成空间簇为例,选用基于连接性的簇定义,阐述尺度驱动的地统计数据聚类模型构建:
H0:空间数据专题属性随机分布。
H1, H2, …, Hi, …, HN:第i个空间簇的内部均质性显著高于随机情况。
空间实体间的邻近关系可以采用拓扑关系或约束Delaunay三角网的方法进行构建,簇内的均质性需要同时满足两条规则[99]:① 每个空间实体与其邻近空间实体间的专题属性都是相似的;② 每个空间实体与簇内其他非空间邻近实体的专题属性也是相似的。
依据以上两个假设,数据尺度对分析尺度的影响,可以通过一种随机重排检验进行建模[100]。
5.1 针对规则1空间实体间的专题属性相似性(或均质性程度)可以采用方差进行度量,则空间实体pi与其邻近实体的专题属性相似度的显著性可以定义为
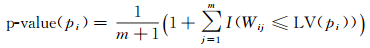 (8)
(8)
式中,m表示专题属性随机重排(即任意空间位置上的专题属性不依赖于空间邻近位置上的专题属性值)的次数;Wij表示第j次随机重排后,以pi为中心的空间邻域内的方差;LV(pi)表示以pi为中心的空间邻域方差观测值;I(·)表示指示函数。给定显著水平α,采用FDR方法对每个空间实体的p-value进行校正后,可以得到空间实体与其邻近空间实体间的专题属性相似性的统计阈值。
5.2 针对规则2在每个空间簇C内进行随机重排,每个空间实体与簇内其他非空间邻近实体相似度的显著水平可以定义为
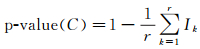 (9)
(9)
式中,r表示簇内专题属性随机重排的次数;第k次随机重排后若每个空间实体与其邻近实体的专题属性相似度代入式(8) 中均可以满足显著性水平α采用FDR方法的校正值,则I记为1,否则记为0。
在重排检验中,空间数据随机重排后构建的统计量经验概率密度分布是判断某一分析尺度上空间簇显著性的根本依据,而这个经验概率密度分布的参数直接受到数据尺度的控制。图 10(a)中包含不同形态、密度的空间簇和噪声,采用尺度驱动的模型可以准确识别其中包含的空间簇(显著水平0.01,重排次数9999,聚类模型为空间约束的Ward法),而采用尺度空间方法(Meanshift)难以准确判断空间簇的显著性,得到的聚类结果包含大量的噪声。

6 总结与展望
本文针对当前空间聚类方法进行研究,发现尚存在两大瓶颈问题:空间簇的显著性难以评价以及聚类结果的多样性难以理解。针对这些问题,从人类多尺度认知的生理原理出发,根据多尺度表达的“自然法则”,提出了一种尺度驱动的空间聚类理论。本文系统阐述了空间聚类中尺度的定义、度量以及参数化建模方法,并建立了针对不同类型空间数据的尺度驱动聚类模型。笔者也作了大量的试验,验证了方法的可行性。
本文虽然为空间聚类的尺度依赖性建模提供了一个新的思路,但仅起到一个抛砖引玉的作用,未来依然需要开展进一步的工作:
(1) 空间聚类的尺度依赖性问题还有一个重要的问题是尺度的自适应选择问题(或尺度不变性),即多尺度的聚类结果哪些是更有效的。“尺度生存期”仅是一种经验性的建模方法。近年来,人类多尺度认知中的“尺度不变性”深层次生理学原理的探究已经引起了广泛的重视,但是如何将其定量化建模,并移植到复杂的地学问题中(非线性、非平稳性等)还需要开展进一步的工作。
(2) 本文针对空间点事件与地统计数据建立的尺度驱动聚类模型需要进一步拓展到其他类型空间数据的聚类问题中,如地统计数据与空间格数据可以同样视为一种空间与专题属性耦合的聚类问题,尺度驱动的地统计数据聚类模型可以较为容易地拓展于空间格数据;空间点事件的聚类模型向时空点事件、轨迹数据扩展时则需要深入研究时空耦合问题。如何针对不同的应用问题,对当前聚类模型的适用性进行系统的归纳与分析对于提高空间聚类的应用效果亦具有重要的价值。
(3) 多模态聚类问题的尺度依赖性,在大数据时代地理对象普遍具有多模态的特点。综合多模态的信息更能够反映地理现象的发展变化特征,而这些多模态特征尺度依赖性建模将更加困难,不仅要考虑每种模态的尺度依赖性,还需考虑不同模态间的关系随尺度的变化。
| [1] | GETIS A. Spatial Autocorrelation[M]//FISCHER M M, GETIS A. Handbook of Applied Spatial Analysis:Software Tools, Methods and Applications. Berlin:Springer-Verlag, 2010. http://www.springer.com/us/book/9783642036460 |
| [2] | 王劲峰, 葛咏, 李连发, 等. 地理学时空数据分析方法[J]. 地理学报, 2014, 69(9): 1326–1345. WANG Jinfeng, GE Yong, LI Lianfa, et al. Spatiotemporal Data Analysis in Geography[J]. Acta Geographica Sinica, 2014, 69(9): 1326–1345. DOI:10.11821/dlxb201409007 |
| [3] | 李德仁, 王树良, 李德毅. 空间数据挖掘理论与应用[M]. 2版. 北京: 科学出版社, 2013. LI Deren, WANG Shuliang, LI Deyi. Spatial Data Mining Theories and Applications[M]. 2nd ed. Beijing: Science Press, 2013. |
| [4] | SHEKHAR S, JIANG Zhe, ALI R, et al. Spatio-temporal Data Mining:A Computational Perspective[J]. ISPRS International Journal of Geo-Information, 2015, 4(4): 2306–2338. DOI:10.3390/ijgi4042306 |
| [5] | KULLDORFF M, NAGARWALLA N. Spatial Disease Clusters:Detection and Inference[J]. Statistics in Medicine, 1995, 14(8): 799–810. DOI:10.1002/(ISSN)1097-0258 |
| [6] | WANG Xin, ROSTOKER C, HAMILTON H J. A Density-based Spatial Clustering for Physical Constraints[J]. Journal of Intelligent Information Systems, 2012, 38(1): 269–297. DOI:10.1007/s10844-011-0154-7 |
| [7] | FOVELL R G, FOVELL M Y C. Climate Zones of the Conterminous United States Defined Using Cluster Analysis[J]. Journal of Climate, 1993, 6(11): 2103–2135. DOI:10.1175/1520-0442(1993)006<2103:CZOTCU>2.0.CO;2 |
| [8] | ZALIAPIN I, BEN-ZION Y. Earthquake Clusters in Southern California I:Identification and Stability[J]. Journal of Geophysical Research:Solid Earth, 2013, 118(6): 2847–2864. DOI:10.1002/jgrb.50179 |
| [9] | KUPFER J A, GAO Peng, GUO Diansheng. Regionalization of Forest Pattern Metrics for the Continental United States Using Contiguity Constrained Clustering and Partitioning[J]. Ecological Informatics, 2012(9): 11–18. |
| [10] | DRǍGUŢ L, TIEDE D, LEVICK S R. ESP:A Tool to Estimate Scale Parameter for Multiresolution Image Segmentation of Remotely Sensed Data[J]. International Journal of Geographical Information Science, 2010, 24(6): 859–871. DOI:10.1080/13658810903174803 |
| [11] | WANG Fahui, GUO Diansheng, MCLAFFERTY S. Constructing Geographic Areas for Cancer Data Analysis:A Case Study on Late-stage Breast Cancer Risk in Illinois[J]. Applied Geography, 2012, 35(1-2): 1–11. DOI:10.1016/j.apgeog.2012.04.005 |
| [12] | DENG Min, TANG Jianbo, LIU Qiliang, et al. Recognizing Building Groups for Generalization:A Comparative Study[J]. Cartography and Geographic Information Science, 2017: 1–18. DOI:10.1080/15230406.2017.1302821 |
| [13] | GUO Diansheng, GAHEGAN M, MACEACHREN A M, et al. Multivariate Analysis and Geovisualization with an Integrated Geographic Knowledge Discovery Approach[J]. Cartography and Geographic Information Science, 2005, 32(2): 113–132. DOI:10.1559/1523040053722150 |
| [14] | DENG Min, FAN Zide, LIU Qiliang, et al. A Hybrid Method for Interpolating Missing Data in Heterogeneous Spatio-Temporal Datasets[J]. ISPRS International Journal of Geo-Information, 2016, 5(2): 13. DOI:10.3390/ijgi5020013 |
| [15] | 李德毅. 大数据认知—"2015大数据价值实现之路高峰论坛"主题报告[J]. 重庆理工大学学报(自然科学), 2015, 29(9): 1–6. LI Deyi. Big Data Cognition:Keynote Lecture of "2015 Forum of Big Data Value Realization Road"[J]. Journal of Chongqing University of Technology (Natural Science), 2015, 29(9): 1–6. |
| [16] | TRYON R C. Cluster Analysis:Correlation Profile and Orthometric (Factor) Analysis for the Isolation of Unities in Mind and Personality[M]. Ann Arbor:Edwards Brothers, Inc., Lithoprinters and Publishers, 1939. |
| [17] | WU Xindong, KUMAR V, QUINLAN J R, et al. Top 10 Algorithms in Data Mining[J]. Knowledge and Information Systems, 2008, 14(1): 1–37. DOI:10.1007/s10115-007-0114-2 |
| [18] | XU R, WUNSCH Ⅱ D C. Clustering[M]. New Jersey: John Wiley & Sons, 2009. |
| [19] | OPENSHAW S. A Geographical Solution to Scale and Aggregation Problems in Region-Building, Partitioning and Spatial Modelling[J]. Transactions of the Institute of British Geographers, 1977, 2(4): 459–472. DOI:10.2307/622300 |
| [20] | OPENSHAW S, CHARLTON M, WYMER C, et al. A Mark 1 Geographical Analysis Machine for the Automated Analysis of Point Data Sets[J]. International Journal of Geographical Information Systems, 1987, 1(4): 335–358. DOI:10.1080/02693798708927821 |
| [21] | 邓敏, 刘启亮, 李光强, 等. 空间聚类分析及应用[M]. 北京: 科学出版社, 2011. DENG Min, LIU Qiliang, LI Guangqiang, et al. Spatial Clustering and Its Applications[M]. Beijing: Science Press, 2011. |
| [22] | ESTIVILL-CASTRO V. Why So Many Clustering Algorithms:A Position Paper[J]. ACM SIGKDD Explorations Newsletter, 2002, 4(1): 65–75. DOI:10.1145/568574 |
| [23] | JAIN A K. Data Clustering:50 Years beyond k-means[J]. Pattern Recognition Letters, 2010, 31(8): 651–666. DOI:10.1016/j.patrec.2009.09.011 |
| [24] | TAN Pangning, STEINBACH M, KUMAR V. Introduction to Data Mining[M]. Boston: Addison Wesley Press, 2006. |
| [25] | AGGARWAL C C, REDDY C K. Data Clustering:Algorithms and Applications[M]. London: CRC Press, 2014. |
| [26] | KISILEVICH S, MANSMANN F, NANNI M, et al. Spatio-temporal Clustering[M]//MAIMON O, ROKACH L. 2nd ed. Data Mining and Knowledge Discovery Handbook. Berlin:Springer, 2010:855-874. |
| [27] | GUO D S. Exploratory Spatial Data Analysis[M]//RICHARDSON D, CASTREE N, GOODCHILD M F, et al. The International Encyclopedia of Geography. London:John Wiley & Sons, 2017:1-25. http://www.wiley.com/WileyCDA/WileyTitle/productCd-0471735450.html |
| [28] | 王劲峰. 空间分析[M]. 北京: 科学出版社, 2006: 185-217. WANG Jinfeng. Spatial Analysis[M]. Beijing: Science Press, 2006: 185-217. |
| [29] | MACQUEEN J B. Some Methods for Classification and Analysis of Multivariate Observations[C]//Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability. Berkeley:University of California Press, 1967:281-297. https://projecteuclid.org/download/pdf_1/euclid.bsmsp/1200512992 |
| [30] | BALL G H, HALL D J. A Clustering Technique for Summarizing Multivariate Data[J]. Behavioral Science, 1967, 12(2): 153–155. DOI:10.1002/(ISSN)1099-1743 |
| [31] | KAUFMAN L, ROUSSEEUW P J. Finding Groups in Data:An Introduction to Cluster Analysis[M]. New York: John Wiley & Sons, 1990. |
| [32] | BEZDEK J. Pattern Recognition with Fuzzy Objective Function Algorithms[M]. New York: Plenum Press, 1981. |
| [33] | NG R T, HAN Jiawei. CLARANS:A Method for Clustering Objects for Spatial Data Mining[J]. IEEE Transactions on Knowledge and Data Engineering, 2002, 14(5): 1003–1016. DOI:10.1109/TKDE.2002.1033770 |
| [34] | PHAM D L. Spatial Models for Fuzzy Clustering[J]. Computer Vision and Image Understanding, 2001, 84(2): 285–297. DOI:10.1006/cviu.2001.0951 |
| [35] | IZAKIAN H, PEDRYCZ W, JAMAL I. Clustering Spatiotemporal Data:An Augmented Fuzzy C-Means[J]. IEEE Transactions on Fuzzy Systems, 2013, 21(5): 855–868. DOI:10.1109/TFUZZ.2012.2233479 |
| [36] | OPENSHAW S, RAO L. Algorithms for Reengineering 1991 Census Geography[J]. Environment and Planning A, 1995, 27(3): 425–446. DOI:10.1068/a270425 |
| [37] | DUQUE J C, ANSELIN L, REY S J. The Max-P-Regions Problem[J]. Journal of Regional Science, 2012, 52(3): 397–419. DOI:10.1111/jors.2012.52.issue-3 |
| [38] | KOHONEN T. Self-organizing Maps[M]. Berlin: Springer Press, 1995. |
| [39] | 程博艳, 刘强, 李小文. 一种建筑物群智能聚类法[J]. 测绘学报, 2013, 42(2): 290–294, 303. CHENG Boyan, LIU Qiang, LI Xiaowen. Intelligent Building Grouping Using a Self-organizing Map[J]. Acta Geodaetica et Cartographica Sinica, 2013, 42(2): 290–294, 303. |
| [40] | BAÇÃO F, LOBO V, PAINHO M. The Self-organizing Map, the Geo-SOM, and Relevant Variants for Geosciences[J]. Computers & Geosciences, 2005, 31(2): 155–163. |
| [41] | HAGENAUER J, HELBICH M. Hierarchical Self-organizing Maps for Clustering Spatiotemporal Data[J]. International Journal of Geographical Information Science, 2013, 27(10): 2026–2042. DOI:10.1080/13658816.2013.788249 |
| [42] | GUHA S, RASTOGI R, SHIM K. CURE:An Efficient Clustering Algorithm for Large Databases[C]//Proceedings of 1998 ACM-SIGMOD International Conference on Management of Data. Washington:ACM Press, 1998:73-84. |
| [43] | 郭庆胜, 郑春燕, 胡华科. 基于邻近图的点群层次聚类方法的研究[J]. 测绘学报, 2008, 37(2): 256–261. GUO Qingsheng, ZHENG Chunyan, HU Huake. Hierarchical Clustering Method of Group of Points Based on the Neighborhood Graph[J]. Acta Geodaetica et Cartographica Sinica, 2008, 37(2): 256–261. |
| [44] | ZAHN C T. Graph-theoretical Methods for Detecting and Describing Gestalt Clusters[J]. IEEE Transactions on Computer, 1971, C-20(1): 68–86. DOI:10.1109/T-C.1971.223083 |
| [45] | 艾廷华, 郭仁忠. 基于格式塔识别原则挖掘空间分布模式[J]. 测绘学报, 2007, 36(3): 302–308. AI Tinghua, GUO Renzhong. Polygon Cluster Pattern Mining Based on Gestalt Principles[J]. Acta Geodaetica et Cartographica Sinica, 2007, 36(3): 302–308. |
| [46] | KARYPIS G, HAN E H, KUMAR V. CHAMELEON:A Hierarchical Clustering Algorithm Using Dynamic Modeling[J]. IEEE Computer, 1999, 32(8): 68–75. DOI:10.1109/2.781637 |
| [47] | ESTIVILL-CASTRO V, LEE I. Multi-level Clustering and Its Visualization for Exploratory Spatial Analysis[J]. GeoInformatica, 2002, 6(2): 123–152. DOI:10.1023/A:1015279009755 |
| [48] | DENG Min, LIU Qiliang, CHENG Tao, et al. An Adaptive Spatial Clustering Algorithm Based on Delaunay Triangulation[J]. Computers, Environment and Urban Systems, 2011, 35(4): 320–332. DOI:10.1016/j.compenvurbsys.2011.02.003 |
| [49] | GORDON A D. A Survey of Constrained Classification[J]. Computational Statistics & Data Analysis, 1996, 21(1): 17–29. |
| [50] | FENG C C, WANG Yichen, CHEN C Y. Combining Geo-SOM and Hierarchical Clustering to Explore Geospatial Data[J]. Transaction in GIS, 2014, 18(1): 125–146. DOI:10.1111/tgis.2014.18.issue-1 |
| [51] | ASSUNÇÃO R M, NEVES M C, CÂMARA G, et al. Efficient Regionalization Techniques for Socio-economic Geographical Units Using Minimum Spanning Trees[J]. International Journal of Geographical Information Science, 2006, 20(7): 797–811. DOI:10.1080/13658810600665111 |
| [52] | GUO D. Regionalization with Dynamically Constrained Agglomerative Clustering and Partitioning (REDCAP)[J]. International Journal of Geographical Information Science, 2008, 22(7): 801–823. DOI:10.1080/13658810701674970 |
| [53] | KULLDORFF M, RAND K, GHERMAN G, et al. SaTScan V2.1:Software for the Spatial and Space-time Scan Statistics[R]. Bethesda, MD:National Cancer Institute, 1998. http://www.sciencedirect.com/science/article/pii/S0143622813001689 |
| [54] | ALDSTADT J, GETIS A. Using AMOEBA to Create a Spatial Weights Matrix and Identify Spatial Clusters[J]. Geographical Analysis, 2006, 38(4): 327–343. DOI:10.1111/gean.2006.38.issue-4 |
| [55] | TAKAHASHI K, KULLDORFF M, TANGO T, et al. A Flexibly Shaped Space-time Scan Statistic for Disease Outbreak Detection and Monitoring[J]. International Journal of Health Geographics, 2008(7): 14. DOI:10.1186/1476-072X-7-14 |
| [56] | PEI Tao, WAN You, JIANG Yong, et al. Detecting Arbitrarily Shaped Clusters Using Ant Colony Optimization[J]. International Journal of Geographical Information Science, 2011, 25(10): 1575–1595. DOI:10.1080/13658816.2010.533674 |
| [57] | ESTER M, KRIEGEL H, SANDER J, et al. A Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise[C]//Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining. Portland, OR:AAAI, 1996:45-50. http://www.sciencedirect.com/science/article/pii/S0968090X13001630 |
| [58] | ANKERST M, BREUNIG M M, KRIEGEL H P, et al. OPTICS:Ordering Points to Identify the Clustering Structure[C]//Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data. Philadelphia:ACM, 1999:49-60. |
| [59] | ERTÖZ L, STEINBACH M, KUMAR V. Finding Clusters of Different Sizes, Shapes, and Densities in Noisy, High Dimensional Data[C]//Proceedings of the 2003 SIAM International Conference on Data Mining. San Francisco:Society for Industrial and Applied Mathematics, 2003:47-58. |
| [60] | 李光强, 邓敏, 刘启亮. 一种适应局部密度变化的空间聚类方法[J]. 测绘学报, 2009, 38(3): 255–263. LI Guangqiang, DENG Min, LIU Qiliang. A Spatial Clustering Method Adaptive to Local Density Change[J]. Acta Geodaetica et Cartographica Sinica, 2009, 38(3): 255–263. |
| [61] | PEI Tao, JASRA A, HAND D J, et al. DECODE:A New Method for Discovering Clusters of Different Densities in Spatial Data[J]. Data Mining and Knowledge Discovery, 2009, 18(3): 337–369. DOI:10.1007/s10618-008-0120-3 |
| [62] | PEI Tao, ZHOU Chenghu, ZHU Axing, et al. Windowed Nearest Neighbour Method for Mining Spatio-temporal Clusters in the Presence of Noise[J]. International Journal of Geographical Information Science, 2010, 24(6): 925–948. DOI:10.1080/13658810903246155 |
| [63] | LIU Qiliang, DENG Min, BI Jiantao, et al. A Novel Method for Discovering Spatio-temporal Clusters of Different Sizes, Shapes, and Densities in the Presence of Noise[J]. International Journal of Digital Earth, 2014, 7(2): 138–157. DOI:10.1080/17538947.2012.655256 |
| [64] | SANDER J, ESTER M, KRIEGEL H P, et al. Density-based Clustering in Spatial Databases:the Algorithm GDBSCAN and Its Applications[J]. Data Mining and Knowledge Discovery, 1998, 2(2): 169–194. DOI:10.1023/A:1009745219419 |
| [65] | BIRANT D, KUT A. ST-DBSCAN:An Algorithm for Clustering Spatial-temporal Data[J]. Data & Knowledge Engineering, 2007, 60(1): 208–221. |
| [66] | LIU Qiliang, DENG Min, SHI Yan, et al. A Density-based Spatial Clustering Algorithm Considering Both Spatial Proximity and Attribute Similarity[J]. Computers & Geosciences, 2012, 46: 296–309. |
| [67] | JEUNG H, YIU M L, ZHOU Xiaofang, et al. Discovery of Convoys in Trajectory Databases[J]. Proceedings of the VLDB Endowment, 2008, 1(1): 1068–1080. DOI:10.14778/1453856 |
| [68] | LI Zhenhui, DING Bolin, HAN Jiawei, et al. Swarm:Mining Relaxed Temporal Moving Object Clusters[J]. Proceedings of the VLDB Endowment, 2010, 3(1-2): 723–734. DOI:10.14778/1920841 |
| [69] | LI Yuxuan, BAILEY J, KULIK L. Efficient Mining of Platoon Patterns in Trajectory Databases[J]. Data & Knowledge Engineering, 2015, 100: 167–187. |
| [70] | 宋长青. 地理学研究范式的思考[J]. 地理科学进展, 2016, 35(1): 1–3. SONG Changqing. On Paradigms of Geographical Research[J]. Progress in Geography, 2016, 35(1): 1–3. |
| [71] | ATKINSON P M, TATE N J. Spatial Scale Problems and Geostatistical Solutions:A Review[J]. The Professional Geographer, 2000, 52(4): 607–623. DOI:10.1111/0033-0124.00250 |
| [72] | DUNGAN J L, PERRY J N, DALE M R T, et al. A Balanced View of Scale in Spatial Statistical Analysis[J]. Ecography, 2002, 25(5): 626–640. DOI:10.1034/j.1600-0587.2002.250510.x |
| [73] | MARCEAU D J, HOWARTH P J, GRATTON D J. Remote Sensing and the Measurement of Geographical Entities in a Forested Environment:The Scale and Spatial Aggregation Problem[J]. Remote Sensing of Environment, 1994, 49(2): 93–104. DOI:10.1016/0034-4257(94)90046-9 |
| [74] | HAY G, MARCEAU D J, DUBé P, et al. A Multiscale Framework for Landscape Analysis:Object-specific Analysis and Upscaling[J]. Landscape Ecology, 2001, 16(6): 471–490. DOI:10.1023/A:1013101931793 |
| [75] | LEUNG Y, ZHANG Jiangshe, XU Zongben. Clustering by Scale-space Filtering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(12): 1396–1410. DOI:10.1109/34.895974 |
| [76] | 汪闽, 周成虎, 裴韬, 等. MSCMO:基于数学形态学算子的尺度空间聚类方法[J]. 遥感学报, 2004, 8(1): 45–50. WANG Min, ZHOU Chenghu, PEI Tao, et al. MSCMO:A Scale Space Clustering Algorithm Based on Mathematical Morphology Operators[J]. Journal of Remote Sensing, 2004, 8(1): 45–50. DOI:10.11834/jrs.20040107 |
| [77] | MU Lan, WANG Fahui. A Scale-space Clustering Method:Mitigating the Effect of Scale in the Analysis of Zone-based Data[J]. Annals of the Association of American Geographers, 2008, 98(1): 85–101. DOI:10.1080/00045600701734224 |
| [78] | SHEIKHOLESLAMI G, CHATTERJEE S, ZHANG Aidong. WaveCluster:A Multi-Resolution Clustering Approach for Very Large Spatial Databases[C]//Proceedings of the 24th International Conference on Very Large Data Bases. New York:Morgan Kaufmann Publishers Inc., 1998:428-439. https://link.springer.com/article/10.1007/s007780050005 |
| [79] | WANG Wei, YANG Jiong, MUNTZ R R. STING:A Statistical Information Grid Approach to Spatial Data Mining[C]//Proceedings of the the 23rd International Conference on Very Large Data Bases. Athens, Greece:Morgan Kaufmann Publishers Inc., 1997:186-195. https://link.springer.com/chapter/10.1007/978-3-540-73729-2_21?no-access=true |
| [80] | COMANICIU D, MEER P. Mean Shift:A Robust Approach Toward Feature Space Analysis[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(5): 603–619. DOI:10.1109/34.1000236 |
| [81] | GOODCHILD M F, QUATTOCHI D A. Scale, Multiscaling, Remote Sensing, and GIS[M]//QUATTROCHI D A, GOODCHILD M F. Scale in Remote Sensing and GIS. London:CRC Press, 1997:1-11. |
| [82] | 李志林. 地理空间数据处理的尺度理论[J]. 地理信息世界, 2005, 3(2): 1–5. LI Zhilin. A Theoretical Discussion on the Scale Issue in Geospatial Data Handling[J]. Geomatics World, 2005, 3(2): 1–5. |
| [83] | BAATZ M, SCHÄPE A. Multiresolution Segmentation:An Optimization Approach for High Quality Multi-scale Image Segmentation[M]//STROBL J, BLASCHKE T, GRIESEBNER G. Angewandte Geographische Informationsverarbeitung. Karlsruhe:Wichmann-Verlag, 2000:12-23. http://www.mdpi.com/2072-4292/4/3/762/html |
| [84] | DRÃGŢ L, EISANK C, STRASSER T. Local Variance for Multi-scale Analysis in Geomorphometry[J]. Geomorphology, 2011, 130(3-4): 162–172. DOI:10.1016/j.geomorph.2011.03.011 |
| [85] | WONG Y F. Clustering Data by Melting[J]. Neural Computation, 1993, 5(1): 89–104. DOI:10.1162/neco.1993.5.1.89 |
| [86] | HUBEL D H. Eye, Brain, and Vision[M]. New York: Scientific American Library Series, 1995. |
| [87] | DICARLO J J, COX D D. Untangling Invariant Object Recognition[J]. Trends in Cognitive Sciences, 2007, 11(8): 333–341. DOI:10.1016/j.tics.2007.06.010 |
| [88] | SCHREUDER D A. Vision and Visual Perception:The Conscious Base of Seeing[M]. United States: Archway Publishing, 2014. |
| [89] | KOENDERINK J J. The Structure of Images[J]. Biological Cybernetics, 1984, 50(5): 363–370. DOI:10.1007/BF00336961 |
| [90] | TER HAAR ROMENY B M. Front-end Vision and Multi-scale Image Analysis:Multi-scale Computer Vision Theory and Applications, Written in Mathematica[M]. Dordrecht: Kluwer Academic Press, 2003. |
| [91] | LINDEBERG T, TER HAAR ROMENY B M. Linear Scale-space I:Basic Theory[M]//TERHAAR R B M. Geometry-driven Diffusion in Computer Vision. Dordrecht:Springer, 1994. http://www.egmont-petersen.nl/Journal-papers/Egmont-prl-1999a.pdf |
| [92] | LI Zhilin, OPENSHAW S. A Natural Principle for the Objective Generalization of Digital Maps[J]. Cartography and Geographic Information Systems, 1993, 20(1): 19–29. DOI:10.1559/152304093782616779 |
| [93] | 张讲社, 徐宗本. 基于视觉系统的聚类:原理与算法[J]. 工程数学学报, 2000, 17(S1): 14–20. S1):14-20. ZHANG Jiangshe, XU Zongben. Clustering Method by Visual System Method[J]. Journal of Engineering Mathematics, 2000, 17(S1): 14–20. |
| [94] | WITKIN A P. Scale-space Filtering[C]//Proceedings of the Eighth International Joint Conference on Artificial Intelligence. Karlsruhe, West Germany:Morgan Kaufmann Publishers Inc., 1983:1019-1022. http://www.sciencedirect.com/science/article/pii/B9780080515816500362 |
| [95] | LIU Qiliang, LI Zhilin, DENG Min, et al. Modeling the Effect of Scale on Clustering of Spatial Points[J]. Computers, Environment and Urban Systems, 2015, 52: 81–92. DOI:10.1016/j.compenvurbsys.2015.03.006 |
| [96] | LI Z L. Algorithmic Foundation of Multi-scale Spatial Representation[M]. London: CRC Press, 2007. |
| [97] | BENJAMINI Y, YEKUTIELI D. The Control of the False Discovery Rate in Multiple Testing Under Dependency[J]. The Annals of Statistics, 2001, 29(4): 1165–1188. DOI:10.1214/aos/1013699998 |
| [98] | LIU Qiliang, TANG Jianbo, DENG Min, et al. An Iterative Detection and Removal Method for Detecting Spatial Clusters of Different Densities[J]. Transactions in GIS, 2015, 19(1): 82–106. DOI:10.1111/tgis.2015.19.issue-1 |
| [99] | LIU Qiliang, DENG Min, SHI Yan, et al. A Density-based Spatial Clustering Algorithm Considering both Spatial Proximity and Attribute Similarity[J]. Computers & Geosciences, 2012, 46: 296–309. |
| [100] | 唐建波, 刘启亮, 邓敏, 等. 空间层次聚类显著性判别的重排检验方法[J]. 测绘学报, 2016, 45(2): 233–240, 249. TANG Jianbo, LIU Qiliang, DENG Min, et al. A Permutation Test for Identifying Significant Clusters in Spatial Dataset[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(2): 233–240, 249. DOI:10.11947/j.AGCS.2016.20140605 |