 2016, Vol. 37
2016, Vol. 37文章信息
- 李镒冲, 赵寅君, 王丽敏, 张梅, 周脉耕.
- Li Yichong, Zhao Yinjun, Wang Limin, Zhang Mei, Zhou Maigeng.
- 考虑多阶段抽样设计的误差估计
- Variance estimation considering multistage sampling design in multistage complex sample analysis
- 中华流行病学杂志, 2016, 37(3): 425-429
- Chinese Journal of Epidemiology, 2016, 37(3): 425-429
- http://dx.doi.org/10.3760/cma.j.issn.0254-6450.2016.03.028
-
文章历史
- 收稿日期: 2015-07-27




2. 100050 北京, 慢性非传染性疾病预防控制中心
2. Chinese Center for Disease Control and Prevention, Beijing 100050, China
多阶段分层整群随机抽样是目前我国公共卫生领域大规模流行病学调查常用的抽样设计之一[1, 2, 3]。由此产生的样本具有复杂样本特征,即群效应或数据不独立,若忽略此特征,易低估抽样误差或增加统计推断Ⅰ类错误的风险[4, 5]。此时,对抽样误差的估计通常采用基于设计(design based)的统计分析方法[5, 6]。由于复杂样本抽样误差的估计形式较为复杂,当初级抽样单元(primary sampling unit,PSU)采用有放回的抽样或入样比非常低的无放回抽样时,一般采用极群方差估计策略(ultimate cluster variance estimate,UCVE)简化样本结构,即假设样本来自一阶段整群抽样,忽略除第一阶段抽样外的所有抽样设计[7],从而实现对误差的近似估计。UCVE也是目前专业统计软件估计抽样误差的常用默认处理方式。然而,在PSU采用无放回抽样或入样比较大时,不可忽略后继抽样阶段对误差的贡献,故自统计分析软件TREE后[8],更多的专业统计软件具有处理多阶段抽样设计的抽样误差估计功能,包括Sudaan、Stata、R等。虽然有些研究比较了UCVE和考虑多阶段抽样设计的误差估计差异,并认为二者差别很小[9],但毕竟研究数据较局限,也未探讨更多条件下二者的适用性,限制了结果的外推。本文介绍考虑多阶段抽样设计下的误差估计方法,并通过对现实数据进行多阶段模拟抽样,比较不同抽样设计下UCVE和考虑多阶段抽样设计下的误差估计差异,并探讨不同抽样误差估计策略的使用条件,为抽样调查数据分析提供应用参考。
基本原理本文比较样本简化的UCVE策略和考虑多阶段抽样设计的误差估计差异。二者利用泰勒级数线性化法得到的误差估计形式如下。
1. UCVE:只考虑PSU的抽样设计,即仅考虑PSU的分层设计。以均值(x)为例,误差估计量为[10, 11]
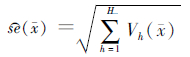
式中h代表PSU的层代码,共H层;Vh(x)为第h层均数的方差估计量。在考虑和不考虑有限总体矫正(finite population correction,FPC)时,且第h层的初级抽样单元数nh>1时,Vh(x)可表示为
考虑FPC:
不考虑FPC:
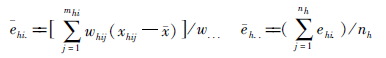
式中,nh为第h层中的群数; fh为第h层的抽样比;mhi为第h层中第i群的观测数;xhij为第h层中第i群第j观测的值;whij为xhij的权重;x为样本总均数;w...为所有观测权重合计。
2. 考虑多阶段抽样设计的误差估计:考虑多阶段抽样设计的误差可看作各抽样阶段误差项之和。计算时需知晓每个抽样阶段各层抽样单元的数量,并对各阶段均进行PFC。为方便理解,此处以二阶段抽样设计为例:首先从第h层中等概率的抽取nh个PSU,然后从第h层的第i个入样的PSU中等概率的抽取mhi个二级抽样单元。此时,均值的误差估计量为[12, 13]
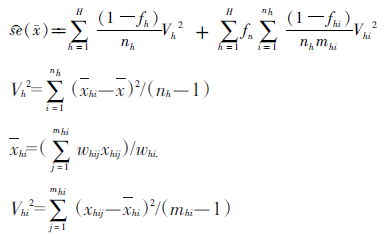
式中Vh2为PSU间方差;Vhi2为初级单元内方差,即二级抽样单元间方差;x为总体均值;whi.为第h层的第i个入样的PSU中各单元权重合计。根据Cochran的估计方式[12],该方法可以允许任意多阶段的方差估计,仅需将后续抽样阶段的方差项加入上述的公式中。
实例分析本研究数据取自中国慢性病及其危险因素监测2010年开展的横断面调查。该调查对全国31个省、直辖市、自治区以及新疆生产建设兵团的162个监测点(区、县或团)≥18岁常住居民进行多阶段随机抽样,共完成98 658人主要慢性病患病、相关行为危险因素和生理生化指标的信息收集。2010年调查的总体设计和主要内容见文献[1]。本文以该调查的所有调查对象SBP测量值作为研究对象,开展模拟抽样研究。
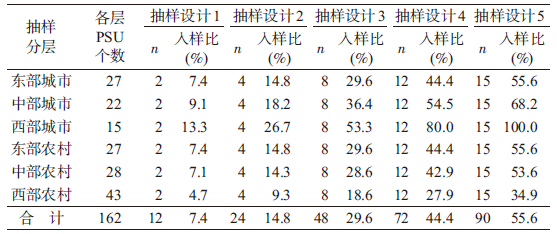
1. 模拟抽样设计:以162个监测点共98 587名调查对象的有效SBP测量值作为总体,开展多阶段随机模拟抽样。将162个监测点按城乡、东中西部划分为6层,各层独立进行模拟抽样,各层监测点数量见表 1。由于总体具有县/区、乡镇/街道、村/居委会的层次结构,多阶段抽样亦按此行政属性进行设计。为考察不同PSU入样比对误差估计的影响,第一阶段抽样采取5种不同设计:利用简单随机抽样(simple random sampling,SRS)在各层分别模拟抽取2、4、8、12和15个监测点;各抽样设计下PSU入样比例见表 1。第二阶段在抽中的监测点中采用SRS抽取2个乡镇/街道。第三阶段在抽中的乡镇/街道中采用SRS抽取2个村/居委会。为尽量减小各模拟抽样设计下样本量对误差估计的影响,第四阶段在各抽中的村/居委会中对应不同PSU入样比分别采用SRS抽取36、18、9、6和5名调查对象,使各抽样设计下样本量基本相当。对各抽样设计均模拟重复抽取1 000次,最终产生5 000个模拟复杂抽样样本。模拟抽样设计见图 1。

|
| 图 1 模拟抽样设计 |
2. 统计学分析:根据基于设计的估计方法[4],SPB的x估计可表示为x=∑(w·x)/∑w,式中w为设计权重,x为SBP值。按抽样设计,w=1/( f1·f2·f3·f4),f1、f2、 f3和f4分别代表4个抽样阶段的入样比,即监测点、乡镇/街道、村/居委会和个体的入样比。同时采用基于样本简化的UCVE策略和考虑多阶段抽样设计的误差估计策略,并利用泰勒级数线性化对每个模拟样本SBP均值的抽样误差进行估计[4, 6, 7]。一般入样比较大时,标准误的计算需要考虑有限总体校正(finite population correction,FPC)[13]。所以在UCVE策略下,为考虑FPC对误差估计的影响,分别估计考虑FPC(UCVE+FPC)和不考虑FPC(UCVE-FPC)时的抽样误差。得到各样本抽样误差的估计值后,采用正态法估计95%CI。通过计算各抽样设计下SBP样本x的标准误(真实标准误),并与UCVE和考虑多阶段抽样策略下误差估计值进行比较,可评价两种估计策略的表现优劣。此外,由于总体SBP的x已知,可以通过计算不同设计下95%CI包含总体均值的概率,用于评价两种估计策略在统计推断上的差异。所有模拟抽样和统计分析在SAS 9.4和Sudaan 10.0中完成。
3. 结果:
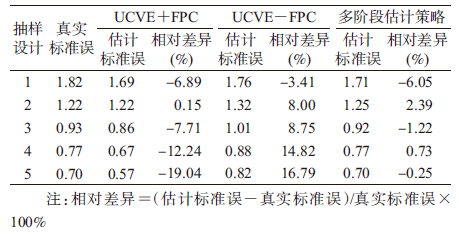
(1)抽样误差估计差异:表 2显示不同模拟抽样设计下,UCVE+FPC和UCVE-FPC的误差估计,及利用多阶段估计策略的估计差异。随着PSU总入样比从抽样设计1 的7.4%增加到抽样设计5的55.6%,在样本量保持不变的情况下,SPB样本x的标准误由1.82 mmHg(1 mmHg=0.133 kPa)减少至0.7 mmHg。随着入样比的增加,UCVE+FPC估计的误差出现不同程度的低估,估计误差与真实误差间相对差异由-6.89%增大至-19.00%;UCVE-FPC的估计则出现高估的趋势,估计误差与真实误差的相对差异由-3.41%增至16.79%;考虑多阶段设计的误差估计值与真实误差非常接近,误差的相对差异由-6.05%降至-0.25%。多阶段估计策略明显优于UCVE+FPC和UCVE-FPC的估计策略。
(2)统计推断比较:对于每次模拟抽样利用3种不同的方差估计策略,均可计算95%CI包含真实参数的概率(表 3)。模拟结果显示,随着PSU入样比的增加(从抽样设计1到抽样设计5),UCVE+FPC估计的95%CI包含参数的概率由93.4%减少至88.5%,判断趋于敏感;UCVE-FPC则相反,由93.9%增至97.9%,判断趋于保守;而多阶段估计策略计算的95%CI包含参数的概率则大致稳定在95%左右。

本文旨在避免冗长晦涩的数学表达,通过模拟抽样给予非数理统计背景的抽样调查分析人员更为直观的方法学比较结果。研究利用真实的全国性调查数据作为总体,根据5种不同PSU抽样比的抽样计划进行多阶段模拟抽样,比较了UCVE和考虑多阶段抽样设计的误差估计差异。结果显示PSU入样比对误差影响较大;在PSU入样比较大时,基于UCVE策略的误差估计会出现不同程度的偏倚,而考虑多阶段抽样设计的估计策略更可靠。
复杂抽样设计中,影响统计量方差的通常有分层、群、不等概抽样、多阶段设计及各阶段样本量的分配等因素[4, 13]。多阶段设计作为公共卫生调查中常用的抽样设计,对其样本的统计分析方法理应得到分析人员的重视。目前,在默认情况下,常见的统计分析软件均假设多阶段抽样设计的第一阶段入样比非常小或者PSU采用了有放回抽样[9, 10, 14, 15],从而采用简化抽样设计后的UCVE测量对误差进行估计[7]。所以,PSU入样比的大小则成为了选择恰当误差估计方法的重要因素。据经验,PSU入样比<5%[13]或10%[16]时可近似看作有放回抽样,从而忽略后继阶段的抽样设计,亦可以不考虑FPC。但在我国公共卫生领域的应用中,笔者却很少看到根据入样比和抽样设计来选择合适估计方法的情况,更多的是直接采用默认估计方法[17, 18]。本文模拟抽样结果显示,随着PSU入样比的增加,利用一般统计软件默认的UCVE得到的误差估计会有不同程度的低估(考虑FPC时)或高估(不考虑FPC时),当入样比增加到约50%时,估计偏倚程度可达20%。误差估计偏倚直接导致统计推断Ⅰ类错误(考虑FPC时)或Ⅱ类错误(不考虑FPC时)发生概率的增加。相比之下,PSU入样比较高时,考虑多阶段抽样设计的估计策略给出了非常精确的误差估计,表现远超UCVE;在PSU入样比较低时,表现却与UCVE没有明显差别。因此,在估计多阶段抽样数据的误差时,考虑多阶段抽样设计的估计策略应作为首选。值得注意的是,该方法的应用需要分析人员掌握各阶段的抽样设计及各阶段样本信息,这增加了抽样实施中和后期数据整理的成本。特别是当分析者并不是抽样设计和实施者时,考虑完整抽样设计的分析方式显得并不可行。然而,抽样设计与实施作为抽样调查最重要的环节之一,理应对其进行完备的记录和整理,供将来使用。
利益冲突 无| [1] 赵文华,宁光,中国慢病监测(2010)项目国家项目工作组. 2010年中国慢性病监测项目的内容与方法[J]. 中华预防医学杂志,2012,46(5):477-479. DOI:10.3760/cma.j.issn.0253-9624.2012. 05.023. Zhao WH,Ning G,National Workgroup of China Chronic Disease Surveillance. Methodology and content of China chronic disease surveillance (2010)[J]. Chin J Prev Med,2012,46(5):477-479. DOI:10.3760/cma.j.issn.0253-9624.2012.05.023. |
| [2] Yang WY,Lu JM,Weng JP,et al. Prevalence of diabetes among men and women in China[J]. N Engl J Med,2010,362(12):1090-1101. DOI:10.1056/NEJMoa0908292. |
| [3] Wu YF,Huxley R,Li LM,et al. Prevalence,awareness,treatment,and control of hypertension in China:data from the China National Nutrition and Health Survey 2002[J]. Circulation,2008,118(25):2679-2686. DOI:10.1161/CIRCULATIONAHA.108.788166. |
| [4] Heeringa SG,West BT,Berglund PA. Applied survey data analysis[M]. Boca Raton,FL:CRC Press,2010. |
| [5] Lemeshow S,Letenneur L,Dartigues JF,et al. Illustration of analysis taking into account complex survey considerations:the association between wine consumption and dementia in the PAQUID study. Personnes Ages Quid[J]. Am J Epidemiol,1998,148(3):298-306. DOI:10.1093/oxfordjournals.aje.a009639. |
| [6] 李镒冲,于石成,赵寅君,等. 基于设计和基于模型方法在复杂抽样数据统计描述中的模拟比较研究[J]. 中华预防医学杂志,2015,49(1):50-55. DOI:10.3760/cma.j.issn.0253-9624.2015. 01.011. Li YC,Yu SC,Zhao YJ,et al. Simulation on design-based and model-based methods in descriptive analysis of complex samples[J]. Chin J Prev Med,2015,49(1):50-55. DOI:10.3760/cma.j.issn.0253-9624.2015.01.011. |
| [7] Wolter KM. Introduction to variance estimation[M]. New York:Springer-Verlag,1985. |
| [8] Bellhouse DR. Computing methods for variance estimation in complex surveys[J]. J Off Stat,1985,1:323-329. |
| [9] Lumley T. Complex surveys:a guide to analysis using R[M]. Hoboken,NJ:John Wiley & Sons,2010. DOI:10.1002/9780470 580066. |
| [10] SAS Institute Inc. SAS/STAT® 9.4 User's Guide[M]. Cary,NC:SAS Institute Inc,2008. |
| [11] Lohr SL. Sampling:design and analysis[M]. 2nd ed. Belmont,Calif.:Cengage Learning,2009:365-391. |
| [12] Cochran WG. Sampling techniques[M]. 3rd ed. New York:Wiley,1977. |
| [13] 金勇进,蒋妍,李序颖. 抽样技术[M]. 北京:中国人民大学出版社,2002. Jin YJ,Jiang Y,Li XY. Sampling techniques[M]. Beijing:China Renmin University Press,2002. |
| [14] Stata Corp. Stata survey data reference manual,Release 12[M]. College Station,TX:Stata Press,2011. |
| [15] Research Triangle Institute. SUDAAN language manual,release 10.0[M]. Triangle Park,NC:Research Triangle Institute,2008. |
| [16] United Nations. Household sample surveys in developing and transition countries[M]. New York:United Nations Publications,2005. |
| [17] 缪凡,童峰. 复杂抽样数据的logistic回归分析方法及其应用[J]. 中国卫生统计,2008,25(6):577-579. DOI:10.3969/j.issn.1002-3674.2008.06.005. Miao F,Tong F. The application of logistic regression in complex sample survey data[J]. Chin J Health Stat,2008,25(6):577-579. DOI:10.3969/j.issn.1002-3674.2008.06.005. |
| [18] 刘建华,金水高. 复杂抽样调查总体特征量及其方差的估计[J]. 中国卫生统计,2008,25(4):377-379. DOI:10.3969/j.issn.1002-3674.2008.04.012. Liu JH,Jin SG. Estimation of population quantities and their variances in complexsamplesurvey[J]. Chin J Health Stat,2008,25(4):377-379. DOI:10.3969/j.issn.1002-3674.2008.04.012. |