 2010, 21 (3): 352-359
2010, 21 (3): 352-359


2. 国家气候中心, 北京 100081
2. National Climate Center, Beijing 100081
在全球增暖背景下, 无论是发生频次、影响范围或是破坏程度, 极端气候事件均表现出越来越明显的群发性特征。极端气候事件群发性特征的已有研究可归纳如下:一是不同种类极端气候事件的群发, 比如干旱、高温或干热风等极端事件同时发生, 例如2006年夏我国四川、重庆等地发生了百年一遇的干旱, 与之相伴的是历史罕见的高温热浪[1]; 二是相同种类极端气候事件在时间上的群发, 或称之为持续性极端事件, 例如2008年10月—2009年1月发生在我国东部的持续性少雨事件, 造成了淮河以北地区的严重干旱[2]; 三是极端气候事件在空间上的区域性群发, 或称之为区域丛集特征, 是区域集中性和区域群发性的一种体现, 例如2008年1月—2月初, 我国南方地区出现了历史罕见的低温雨雪冰冻灾害, 造成的直接经济损失达上千亿元[3]。上述3种群发性极端事件均可能造成严重的社会影响和经济损失, 是目前在全球变暖背景下国际上研究的热点问题之一。本文从空间角度研究了极端事件的群发性, 为极端事件的研究提供一种新的视角和思路。
在年代际尺度上, 极端气候事件具有明显的空间丛集特征[4-8]; 从天气尺度上来讲, 高温、暴雨等极端天气事件的区域群发性也非常显著[9-15]。极端气候事件的区域群发性具有明显的年际变化规律, 这为从年际尺度来研究极端气候事件提供了一种可能性, 对极端气候事件年总频数进行统计[16]发现, 年总频数大的极端气候事件往往密集分布, 而这些密集分布的极端气候事件所呈现的灾害性特征更值得关注。高频密集分布是极端气候事件区域群发性的一种体现, 如果能将高频密集分布的群发性区域进行客观定量化描述, 将为极端气候事件群发性的影响评估和机理分析提供帮助, 具有很强的现实意义。本文将空间点过程理论中的k阶最近邻距离丛集点提取算法与极端气候事件的群发性研究有机结合, 以极端气候事件的年际区域群发性为切入点, 探讨了该方法用于极端气候事件区域群发性研究的可行性和有效性。
1 空间点过程理论的k阶最近邻距离丛集点提取算法基于空间点过程理论的k阶最近邻距离丛集点算法, 能够将空间上分布不均匀的点较为客观地区别, 即将空间上分布相对密集的点归为一类, 称之为丛集点, 将空间分布相对零散的点归为一类, 称之为背景点。该算法的核心思想是结合概率统计的基本原理, 通过计算所研究区域内各点的k阶最近邻距离, 从而得到各点的丛集点隶属度, 以此来判断各点是否属于丛集点[16-23]。
1.1 k阶最近邻距离丛集点提取算法假设Y为一定范围内单一的二维泊松过程点集, 其中任一点si的k阶最近邻距离为Wk, 其概率密度函数gWk(x) 为:
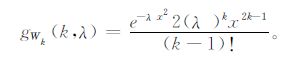
|
(1) |
式 (1) 中, k为距离阶数, λ为所研究点集Y的分布参数。在实际研究中, 丛集点和背景点分别代表不同参数λ的空间点过程, 它们在空间上互相叠加, 因此, 以两个叠加的二维泊松过程为例, 其Wk分布服从以下的混合分布:
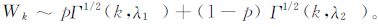
|
(2) |
式 (2) 中, p为比例系数, λ1和λ2分别为丛集区域和背景区域的分布参数, k为距离阶数[15-20]。结合式 (1) 和式 (2), 它们的Wk服从以下分布:
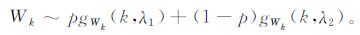
|
(3) |
λ1和λ2的计算采用Byers和Raftery提出的期望最大化算法 (EM算法) 来计算, EM算法的核心思想是通过赋予所求参数 (文中所求参数为λ1和λ2) 一初始值, 通过多次迭代, 所求参数将收敛于与其真实值最为接近的某一稳定值, 则该收敛值即为所求的参数值, 所以该方法又称之为期望最大化算法。具体包括E-步骤和M-步骤 (详细阐述可参见文献[17]):
E-步骤:
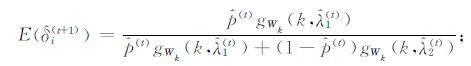
|
(4) |
M-步骤:
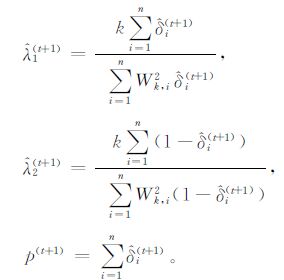
|
(5) |
其中, n代表事件总数, Wk, i表示第i(i=1, 2, …, n) 个事件的k阶最近邻距离, t表示迭代次数, 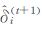
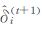
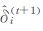
关于算法中参数k的讨论已有一些研究, 裴韬等[18-20]发现, 当k在合适范围内取值时算法的错误率较低, 较为有效。杨萍等对该算法的适用性进行了进一步分析[16], 发现样本总量、丛集点与分散点的疏密差异比等参数对计算结果有较大影响, 并定义了参数R(丛集点与分散点疏密差异比值) 来定量化地界定算法的适用范围; 此外对数据点的设置进行了拓展研究, 对于重叠的数据点, 可引入权重思想, 对不同类型的重叠数据点赋予不同的权重, 从而实现客观提取丛集点的目标。上述结果为极端气候事件的群发性研究提供了有力的理论依据和算法基础。
有别于常规极端气候事件的研究主要针对单站点的不同要素, 本研究的目标在于通过k阶最近邻距离丛集点提取算法将单站点极端气候事件的研究扩展到相互联系的多站点极端气候事件空间分布的讨论中, 即将极端事件的研究范围从对点的讨论扩展到面的研究。用站点重复出现的次数来体现站点极端气候事件发生的频次 (强度), 使高权重区域的分布密度进一步加强, 从而实现高频 (强度) 丛集站点的提取工作, 达到对极端气候事件群发性进行定量化描述的目标, 并进一步分析极端气候事件群发性的时间变化趋势和空间分布特征, 从而为极端气候事件群发性的定量化评估和分析提供了一种新的思路。
2 空间点过程理论在极端气候事件中的应用 2.1 区域范围和所用资料我国不同区域内观测站点的不均匀分布是客观存在的, 为尽量克服该现象对丛集点提取结果的影响, 本文去除了分布较为稀疏的西部区域测站 (新疆、西藏、内蒙古3省区), 主要研究东亚季风区极端气候事件的群发性。
所用资料为我国大陆740个测站的日最高温度、最低温度、日降水资料集, 由于资料限制, 温度和降水资料均存在一定缺测, 分别对其进行处理。去除西部测站以及东部区域缺测的站点后, 最后取全国426个测站的逐日最高温度、最低温度资料, 资料的时段为1960—2005年; 降水资料的时段为1960—2006年, 最后取全国437个测站的逐日降水资料。
2.2 极端气候事件的定义 2.2.1 极端温度事件的定义本文中极端温度事件的定义为:将某站点1960—2005年的日最高 (低) 温度资料样本概率位于x%(x视实际情况而定) 的值作为极端高 (低) 温事件的上 (下) 阈值, 定义夏季高温 (冬季低温) 事件; 此外, 温度严重偏离 (高于或低于) 该天的多年平均状态, 也可看作是另一种极端高温 (低温) 事件, 即距平值定义异常偏高 (低) 事件。通过控制百分位的取值, 从而定义不同强度的极端温度事件, 共计12种 (表 1)。
|
|
表 1 极端温度事件的定义 Table 1 Different defintions of temparture extreme |

2.2.2 极端降水事件的定义
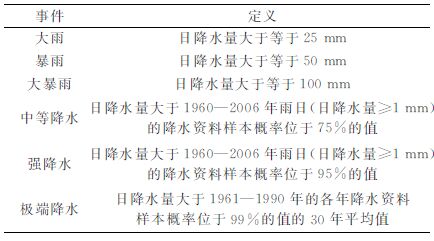
极端降水事件的定义方法有多种, 传统上采取绝对阈值法, 即采用降水量大于等于某一固定阈值的方法; 百分比阈值法也是极端降水事件定义的常用方法[24]; 此外, 也有研究者利用气候平均态 (30年的平均值) 作为阈值来定义极端降水事件[25]。参考已有的极端降水事件定义标准, 本文具体定义见表 2。
|
|
表 2 极端降水事件的定义 Table 2 Different defintions of precipitation extreme |
2.3 权重的定义
结合k阶最近邻距离丛集点提取算法, 并参考关于引入权重的研究结果[23], 在本文极端气候事件群发性的研究中, 采取如下两种方法定义权重, 即分别从极端事件的年总频数和年总强度的角度定义权重。
2.3.1 从年总频数的角度定义权重给各站点赋予权重, 用该站点重复出现的次数体现权重大小。例如, 某站点的坐标为 (x, y), 权重为5, 则该数据点即其坐标 (x, y) 出现5次。由于极端降水事件和极端温度事件在定义上非常类似, 本文以极端温度事件为例进行权重定义的说明。
设样本概率取值为q% (q分别取90, 95, 99), 逐日温度观测资料为1960—2005年共记16802d。以任一站点为研究对象, 按样本概率取值为q%的值作为极端高 (低) 温事件的阈值, 极端高 (低) 温事件共发生 (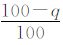
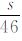
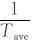
除依据年总频数定义权重外, 还可从年总强度定义权重。用极端气候事件的要素观测值与阈值之差的绝对值来表征强度, 以年为单位做累加求和。总体来说, 年总强度越大, 权重越大, 仍以极端温度事件为例进行说明。
设定样本概率取值为q% (q取90, 95, 99), 时间序列1960—2005年共计16802d。以任一站点为研究对象, 极端高 (低) 温事件的总发生日次为 (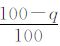
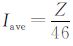
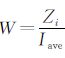
在极端气候事件和权重的定义的基础上, 结合k阶最近邻距离提取算法逐年进行极端气候事件群发区域的检测与提取工作, 检测流程如图 1所示。

|
|
| 图 1. 区域群发性极端气候事件的检测流程图 Fig 1. Checking flow chart of cluster extreme events | |
2.4.2 实际资料举例
以我国426测站1960—2005年夏季高温事件为例, 对极端事件群发性的检测流程进行说明。
任选一站点, 将1960—2005年的日最高温度资料样本概率为99%的值作为夏季高温事件的阈值, 大于该阈值记为夏季高温事件, 逐年统计各站点发生夏季高温事件的频次并据此赋予权重, 得到各年夏季高温事件空间点的数据集; 利用空间点过程理论的k阶最近邻距离丛集点提取算法, 得到群发性站点的逐年空间分布图集。以2000年为例, 其结果如图 2a所示。

|
|
| 图 2. 2000年夏季高温事件的空间分布 (a) 群发提取结果图 (“+”表示发生极端高温事件的站点, “●”表示提取出的群发性站点), (b) 权重分布图 (数字“1” “5”代表所在位置上站点的权重) Fig 2. Stations over China about temperature extremein 2000 (a) cluster distribution ("+"represent the station soccurring temperature extreme, "●"represent the cluster stations occurring temperature extreme), (b) power distribution (number "1"—"5" represent station spower) | |
图 2a中, “+”为2000年发生极端高温事件的站点, 即根据百分比阈值法以及权重的定义方法得到的数据集, “●”为利用空间点过程理论提取出的群发站点。与2000年极端高温事件的权重分布图 (图 2b) 进行对比, 发现高权重且密集分布的站点被提取出来。该方法避免了人为界定群发性区域所带来的主观性, 同时还可以检测出极端气候事件影响最为严重、最值得关注的区域。
3 算法有效性检测 3.1 有效性检测的说明和具体方法已有研究说明该算法有一定的适用范围[14]。当丛集点和背景点的疏密差异不太明显时, 提取结果的错误率较高, 有效性会随之降低。因此, 该算法在极端气候事件群发性研究中的有效性如何值得进行深入讨论。
样本量较小 (小于400) 时, 得到R的临界值为4.0, 样本量较大 (大于等于400) 时, R的临界值为2.9[14]。从极端气候事件实际发生站点数来看, 其没有统一的样本量范围, 为了保证结果的可靠性, 本文选取R的临界值为4;在R的修正研究中[7]发现, 一般而言, 未知状态下, R的计算值比理论值偏低0.2左右; 因此, 算法的有效性检测中, 本文实际R的临界值取3.8。
3.2 有效性检测方法 3.2.1 R的计算方法利用k阶最近邻距离丛集点提取算法, 逐年计算出丛集站点和背景站点的分布参数比值R, 对其进行求和平均, 记为R。
3.2.2 有效率的计算方法以3.8为临界值, 统计出大于等于3.8的年份, 记为n, 总年份记为N, 其比值定义为极端气候事件的有效率, 记为η。具体计算公式为:
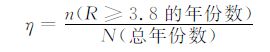
|
(6) |
基于前文定义的夏季高温、冬季低温、异常偏高、异常偏低4类极端温度事件, 通过控制百分位的取值, 定义了不同强度的极端温度事件, 共计12种极端温度事件 (参见表 1)。在权重定义中, 分别从频次和强度两个角度定义权重, 计算每一年的R值, 求和平均得R, 由式 (6) 可知η, 具体R和η如图 3所示。

|
|
| 图 3. 12种极端温度事件有效性检测结果图 (a)12种极端温度事件的R, (b)12种极端温度事件的η Fig 3. Tempretureex treme's average of ratio R (a) and efficient η (b) | |
图 3a给出了12种极端温度事件的R, 其中白色的柱状直方图为频次定义权重下的R, 灰色柱状图是强度定义权重下的R, 虚线对应的值是R=3.8。图 3b给出了其各自的有效率η, 和R类似, 频次定义权重的有效率用白色直方图表示, 强度定义权重的有效率用灰色直方图表示, 虚线对应的值为50%的有效率。
由图 3可知:12种极端温度事件的R均大于临界值3.8, 有效率均大于50%, 可见, 算法检测出极端温度事件群发性的能力比较强。不同样本概率情况下的极端温度事件中, 极端温度事件99%的R最高, 有效率最大, 说明算法有效性与极端事件的极端程度有一定联系。对比频次和强度两种定义权重的方法, 差别不大, 计算各自R和η的平均值, 基于频次时R的平均值为4.73, 基于强度时的平均值为4.95, 有效率η的平均值几乎相同, 均为0.75。另外, 对有效性最强的情况, 即样本概率取99%时的各种极端温度事件进行了统计, 基于频次的R为5.62, 基于强度的为6.22, 有效率η平均值几乎相同, 均为0.80, 极端程度最高的极端温度事件的有效性远大于平均水平。
3.3.2 极端降水事件的有效性检测极端降水事件的定义主要分为绝对阈值法和百分比阈值法两种, 表 2中给出了6种极端降水事件的定义, R和η的大小如图 4所示。

|
|
| 图 4. 6种极端降水事件有效性检测结果图 (a) 极端降水事件的R, (b) 极端降水事件的η Fig 4. Precipitation extreme's average of ratio R (a) an defficient η (b) | |
图 4a和图 4b分别给出了6种极端降水事件R和η, 虚线分别为R和η的临界值。由图 4可知:较极端温度事件而言, 极端降水事件的有效性稍弱, 大部分R都达到了R的临界值, 除暴雨和极端强降水外, 其余极端降水事件均超过η的临界值。从R和η的大小看, 大暴雨的有效性高于暴雨和大雨; 百分比阈值定义下极端降水事件中, 中等降水和强降水事件的有效性相对较高。对比R和η在临界值以上的几种极端降水事件, 基于强度定义权重的结果略好于基于频次的结果, 但相差甚微。
4 结论极端气候事件的区域群发性是近年来极端事件研究中的新热点, 尽管目前关于极端气候事件群发性的研究已有不同程度的涉及, 将极端事件的区域群发性特征概括为极端事件的集中度, 如20世纪90年代以后长江流域降水在时间和空间上的集中度都有所增加[26], 但是对于群发性或集中度的研究未成系统, 对区域群发性进行系统阐述以及定量化研究还不成熟。本文将空间点过程理论k阶最近邻距离丛集点提取算法与极端事件群发性的研究进行了合理的结合, 通过一系列有效性检验探讨了该算法在极端事件区域群发性研究中的应用, 为极端气候事件群发性的研究和诊断提供了一个新的视角和思路。得到如下结论:
1) 通过合理利用k阶最近邻距离丛集点提取算法的基本理论, 发现该方法能够将单站点极端气候事件的研究扩展到相互联系的多站点空间分布的讨论中, 实现了极端气候事件研究范围的拓展。
2) 基于12种极端温度事件和6种极端降水事件, 将k阶最近邻距离丛集点提取算法应用于极端温度事件和极端降水事件的研究中, 研发出区域群发性极端温度事件和极端降水事件的检测流程。
3) 确定了算法有效性检验的判别指标R和η, 对各种定义下极端气候事件的区域群发性进行有效性检验, 检测结果表明:k阶最近邻距离丛集点提取算法适用于极端气候事件的区域群发性研究。
| [1] | 柳艳香, 王凌, 赵振国, 等. 2006年中国夏季降水预测回顾. 气候变化研究进展, 2007, 3, (4): 243–245. |
| [2] | 陶诗言, 卫捷, 孙建华, 赵思雄, 等. 2008/2009年秋冬季我国东部严重干旱分析. 气象, 2009, 35, (4): 3–10. |
| [3] | 丁一汇, 王遵娅, 宋亚芳, 等. 中国南方2008年1月罕见低温雨雪冰冻灾害发生的原因及其与气候变暖的关系. 气象学报, 2008, 66, (5): 808–825. |
| [4] | 符娇兰, 林祥, 钱维宏. 中国夏季分级雨日的时空特征. 热带气象学报, 2008, 24, (4): 367–372. |
| [5] | 秦爱民, 钱维宏, 蔡亲波, 等. 1960~2000年中国不同季节的气温分区及趋势. 气象科学, 2005, 25, (4): 338–345. |
| [6] | 张勇, 曹丽娟, 许吟隆, 等. 未来我国极端温度事件变化情景分析. 应用气象学报, 2008, 19, (6): 655–660. |
| [7] | 支蓉, 龚志强. 利用幂律尾指数的中国降水突变检测与归因. 物理学报, 2008, 57, (7): 4629–4633. |
| [8] | 龚志强, 封国林. 中国近1000年旱涝的持续性特征研究. 物理学报, 2008, 57, (6): 3920–3931. |
| [9] | 杨萍, 刘伟东, 王启光, 等. 近40年我国极端温度变化趋势和季节特征. 应用气象学报, 2010, 21, (1): 29–36. |
| [10] | 封国林, 杨杰, 万仕全, 等. 温度破纪录事件预测理论研究. 气象学报, 2009, 67, (1): 61–74. |
| [11] | 陈波, 史瑞琴, 陈正洪. 近45年华中地区不同级别强降水事件变化趋势. 应用气象学报, 2010, 21, (1): 47–54. |
| [12] | 章大全, 杨杰, 王启光, 等. 中国近50年气候破纪录温度事件发生概率分析. 物理学报, 2009, 58, (6): 4354–4361. |
| [13] | 王遵娅, 丁一汇. 夏季长江中下游旱涝年季节内振荡气候特征. 应用气象学报, 2008, 19, (6): 710–715. |
| [14] | 侯威, 杨萍, 封国林. 中国极端干旱事件的年代际变化及其成因. 物理学报, 2008, 57, (6): 3932–3940. |
| [15] | 熊开国, 封国林, 王启光, 等. 近46年来中国温度破纪录事件的时空分布特征分析. 物理学报, 2009, 58, (11): 8107–8115. |
| [16] | 杨萍. 近四十年中国极端温度和极端降水事件的群发性研究. 兰州: 兰州大学, 2009: 8-12. |
| [17] | Byers S D, Raftery A E, Nearest-neighbor clutter removal for estimating features in spatial point processes. Journal of the American Statistical Association, 1998, 93: 577–584. DOI:10.1080/01621459.1998.10473711 |
| [18] | 裴韬, 周成虎, 杨明, 等. 混合二维泊松过程的分解算法及其在提取地震丛集模式中的应用. 地震学报, 2004, 26, (1): 53–61. |
| [19] | Pei T, Zhu A X, Zhou C H, et al. A new approach to the nearest-neighbour method to discover cluster features in overlaid spatial point processes. Inter-national Journal of Geographical Information Science, 2006, 19: 153–168. |
| [20] | Pei T, Zhu A X, Zhou C H, et al. Delineation of support domain of feature in the presence of noise. Computers & Geosiences, 2007, 33: 952–965. |
| [21] | 王启光, 侯威, 郑志海, 等. 东亚区域大气长程相关性. 物理学报, 2009, 58, (9): 6640–6650. |
| [22] | 封国林, 董文杰, 龚志强, 等. 观测数据非线性时空分布理论和方法. 北京: 气象出版社, 2006: 1-227. |
| [23] | 杨萍, 侯威, 支蓉. 利用空间点过程提取丛集点算法的适用性研究. 物理学报, 2009, 58, (3): 2097–2105. |
| [24] | CLIVAR, GC OS, W MO, Indices and Indicators for Changes in Climate Extreme. Asheville NC USA, 1997: 3–6. |
| [25] | 翟盘茂, 潘晓华. 中国北方近50年温度和降水极端事件变化研究. 地理学报, 2003, 58, (增刊): 1–10. |
| [26] | 李吉顺, 王昂生. 陈家田, 90年代局地气候变化与长江流域水旱灾害. 中国减火, 2000, 10, (3): 29–31. |