 2010, 21 (1): 55-62
2010, 21 (1): 55-62


2. 中国气象局培训中心, 北京100081;
3. 国家气象中心, 北京100081
2. China Meteorological Administration Training Center, Beijing 100081;
3. National Meteorological Center, Beijing 100081
人工神经网络 (ANN) 由于其具有自学习、自组织的非线性映射能力,适合于一些信息复杂、知识背景不清楚和推理规则不明确问题的建模.20世纪80年代中期开始被应用于如气象资料同化、数值预报产品释用、天气预报、预报质量保证等各个方面,在气候模式、短期气候预测、中短期天气预报、强对流天气和卫星资料处理等领域也得到广泛应用[1-10].
近20年来,在数值预报产品提供的大量信息基础上,预报员根据前期实况观测及其演变所蕴涵的天气动力学特点对数值预报产品进行修正、解释,使之达到人们对气象要素预报的要求.目前基于统计理论的相关分析和回归方法在数值预报产品的释用中仍发挥着重要作用[11],如模式输出统计方法 (MOS)[12]、卡尔曼滤波 (KF)[13-14]、K最近领域 (KNN) 非参数估计技术[15-16]等,但是这些方法多数是基于线性相关的基础上,在处理一些具有非线性特征的气象要素或天气现象 (降水) 时,具有较大的局限性.近年来,一些具有处理非线性问题能力的方法在气象上开始广泛应用,如支持向量机 (SVM) 和人工神经网络[17-20].SVM的性能主要依赖于核函数的选择,在应用中需要人为干预,同时对于大规模数据集,训练速度异常缓慢,不适于实时监控[21],以及其他参数不易调整等缺陷,使其在应用中具有一定的限制.
BP算法是目前应用最广泛的神经网络方法之一,它具有很强的信息处理能力.然而,在传统BP算法的应用中存在许多亟待解决的问题,例如,在学习算法上,存在收敛速度缓慢、易陷入局部极小等缺陷;在实际应用中,存在网络结构参数和学习训练参数难以确定的问题,这些问题在一定程度上影响了神经网络的推广应用.不少学者[22-25]已对BP网络进行了深入研究,并针对上述问题提出了许多改进算法,但都不是普遍适用的.对此,本文提出一种自动确定各种参数的BP算法,使得在实际应用中不需要人为确定任何参数,并能有效解决网络模型泛化能力差和局部极小等问题.
降水是大尺度环流与中小尺度系统相互作用的综合结果,同时也是本地流场、热力场与当地的地形、地貌相结合的产物,正是由于存在这样一系列复杂的物理过程,使降水量具有非线性变化的特点,因而,定量降水的客观预报比较困难.为了验证改进的BP算法的可行性,尝试用改进的BP算法来建立降水预报模型,使预报适应于具有非线性变化特点的气象要素.试验结果表明,改进的BP算法对降水的预报效果相比传统算法有较明显的提高,由于改进方法还具有自优化确定参数的优点,在实际应用中更加方便.
该方法已应用于国家气象中心的“气象要素客观预报集成系统”中,并在多个省气象局推广,进一步促进了神经网络方法在气象部门中的应用,取得了较好的效果.
1 BP神经算法的介绍 1.1 传统算法的介绍BP (back propagation) 网络,是一种单向传播的多层前向网络,网络含有输入层、输出层和处于两层之间的隐含层,隐含层可以是单层或多层,隐含层上的节点称为隐节点.雷景生等[25]详细介绍及绘制了3层前馈神经网络的结构.
典型的3层BP网络,只有一层隐含层,BP网络的训练过程分为两个阶段:正向过程和反向过程.正向过程是将学习样本的输入值循环置入BP网络的输入端,由前往后,依次计算网络的隐节点和输出节点值;根据网络输出值与期望输出值之间的误差,开始反向计算,即由后往前,按照训练的目标函数,依次调整网络各层节点之间的连接权值,直到目标函数接近极小值为止,故称为误差反向传播网络[26].在BP网络的学习算法中,权值修正一般采用梯度下降法,各节点神经元的激励函数常采用Sigmoid函数,其形式为
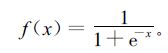
|
(1) |
本研究中,为将输出值归一化到-1~+1之间,取如下形式的函数作为神经元的激励函数
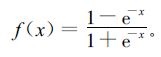
|
(2) |
在传统BP算法中,网络的结构参数和学习训练参数,一般都没有定量的方法来确定.在实际应用中,对于网络的结构参数,输入节点和输出节点数目可以根据预报因子和预报对象确定,而隐层和隐节点数目需要通过实验确定;对于网络的学习训练参数,包括学习速率、训练次数、期望的训练误差等参数,需要根据不同的实际应用,通过实验来确定.
传统BP算法在实际应用中的另一个主要问题就是在网络模型学习训练的过程中,容易陷入局部极小点,如图 1所示.当BP神经网络陷入局部极小点时,进一步的训练不能减小网络的输出与目标值之间的偏差,所得到的网络模型存在较大偏差.

|
|
| 图 1. BP训练过程中陷入局部极小点示意图 Fig 1. A schematic figure for the immer sion of the web to the local least solution in the BP training process | |
BP网络的训练,是为了建立一个合适的模型用于预报.但是BP网络在训练过程中,常常会出现网络模型对训练样本拟合得较好,而对没有参加训练的样本拟合的效果较差 (如图 2所示),这种情况称之为网络模型的泛化能力较差.从图 2可知,若对训练样本的训练次数较少,网络模型的偏差较大;若对训练样本训练次数过多,网络模型对新数据的预报能力反而减弱.因此怎样确定合适的训练程度,不仅可以使网络模型对训练样本具有比较精确的拟合,又具有较好的预报能力,是BP网络实际应用中需要解决的又一个重要问题.

|
|
| 图 2. 网络模型的泛化能力示意图 Fig 2. A schematic figure of gene ralization ability for a network model | |
1.3 改进的BP算法
针对BP网络在实际应用中遇到的上述3方面的问题,本文在传统BP算法的基础上,提出了一种改进的训练算法.
首先,设W(k) 为BP网络各层节点之间的连接权值,ΔW(k) 为网络权值的修正值,其中k表示训练次数,则权值的修正公式如下:
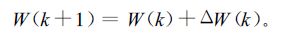
|
(3) |
设有N组训练样本,且第i组训练样本的目标值和网络实际输出值分别为Ti和Y i(k),训练误差函数和权重修正函数如下:
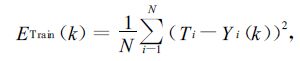
|
(4) |
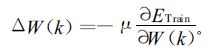
|
(5) |
式 (5) 中,μ表示学习速率.
另设有M组检测样本,且第j组训练样本的目标值和网络实际输出值分别为T j和Yj (k),则检测误差函数为:
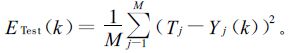
|
(6) |
对于隐含层的层数,许多学者做了理论研究.根据Lippmann[27]的研究可知,三层网络可以逼近任意一个连续的函数.后来Hecht-Nielsen[28]的研究进一步指出:只有一个隐层的神经网络,只要节点足够多,就可以以任意精度逼近一个非线性的函数.因此,在该方法中隐层的数目设定为一层.
隐节点数的选取比较困难,隐节点数较少时,学习过程可能不收敛;隐节点数较多时,网络泛化能力又可能较弱,有很多学者在这方面进行了研究[29-30].根据实践检验,隐节点数一般选在输入节点数的1~2倍之间时,能达到较好的效果.因此,在一个隐层、隐节点数为输入节点数的1~2倍之间这两个前提条件下,提出的改进学习训练算法如下:
① 确定训练样本和检测样本.首先根据总样本的数目,按不同比例将样本随机分为两类,一类为训练样本,用于网络的训练学习,设样本组数目为N;另一类为检测样本,在训练过程中,用于检测网络的输出误差,设样本组数目为M.在本方法中,主要根据训练样本和检测样本的误差变化,自适应确定网络结构参数和学习训练参数,同时保证对训练样本的训练精度及提高对检测样本的泛化能力.
② 确定隐节点数.根据训练样本和检验样本网络误差的变化,在网络学习过程中自适应确定隐节点数.其中Ninput表示输入节点,Nhidden表示隐节点数,初始学习速率μ=0.2.ⓐ先设Nhidden=1.5 × Ninput,且Nhidden≥3,开始进行训练.当训练次数满足设定的最小训练次数时,检查ETrain (k) 和ETest (k) 的变化,若ETrain (k)<ETrain(k-1) 且ETest (k)<ETrain(k-1),由图 2可看出,此时随着网络训练的继续,网络性能将得到提高,网络的泛化能力不断增强,因此可继续训练,得到更优的网络,否则,若连续P次 (P一般大于10) 不能达到上述条件,停止训练,得到最终的ETrain(k) 和ETest (k);ⓑ再分别设Nhidden=1.4 ×Ninput,Nhidden=1.6 ×Ninput,重复ⓐ过程;ⓒ比较Nhidden分别为1.4倍、1.5倍、1.6倍的Ninput时,得到的最终ETrain(k) 和ETest (k) 值,选择最优的ETrain(k) 和ETest (k).若Nhidden为1.4倍的Ninput时最优,表明继续减少隐节点数进行训练,可能得到更优的网络,所以再设Nhidden=1.2 ×Ninput,重复ⓐ过程;相反,若Nhidden为1.6倍的Ninput时最优,则设Nhidden=1.7 ×N input, 重复上述ⓐ过程;若Nhidden为1.5倍的N input时最优,则设Nhidden=1.5 ×Ninput,转入③;ⓓ比较Nhidden分别为1.2倍、1.4倍或1.6倍、1.7倍的Ninput时最终的ETrain(k) 和E Test (k) 值,选择最优的ETrain (k) 和ETest (k),确定Nhidden的值,转入③.
③ 确定学习速率.设Nhidden为②中所确定的数值,再根据以下步骤来确定学习速率.ⓐ分别设学习速率μ=0.2,0.3,进行训练,训练次数每间隔100次,将μ设为0.8,进行一次训练,然后恢复μ为原值.当训练次数满足设定的最小训练次数时,检查ETrain(k) 和ETest (k) 的变化,若ETrain(k)<ETrain(k-1) 且ETest (k)<ETest (k-1),则继续训练,否则,若连续P次 (一般P >10) 不能达到上述条件,停止训练;ⓑ比较μ=0.2,0.3时最终的ETrain (k) 和ETest (k) 值,选择最优的ETrain(k) 和E Test (k).若μ=0.3时最优,转入ⓒ;若μ=0.2时最优,则转入④;ⓒ若μ<0.5,则设μ=μ+0.05,重复ⓐ过程和ⓑ过程,选择最优的μ,然后转入④.
在训练学习中,每隔一定的训练次数,学习速率进行一次跳变 (主要是增大学习速率),可以避免网络陷入局部极小点或从陷入局部极小点中跳跃出来.
④ 网络训练.使用按照上述步骤确定的N hidden和μ,进行网络训练.训练次数每间隔100次,将μ设为0.8,进行一次训练,然后恢复μ为原值.当训练次数满足设定的最小训练次数时,检查ETrain(k) 和ETest (k) 的变化,若E Train (k)<E Train (k-1) 且ETest(k)<E Test(k-1),则继续训练,否则,若连续P次 (一般P >10) 不能达到上述条件,训练结束,得到最优的网络模型.
2 应用实例及分析 2.1 资料本文以江淮流域降水为研究背景,利用2003-2007年5-9月江淮流域68个站点的数据资料,其中用2003-2005年5-9月的数据进行训练建立各站点的预报模型,2006-2007年5-9月的数据用于预报试验.选定该68个站点3个等级 (降水量≥0.1 mm, 降水量≥10 mm, 降水量≥25 mm)08 :00-08 :00(北京时,下同) 的24 h降水量为预报对象.采用国家气象信息中心提供的68个站2003-2007年5-9月逐日08 :00到次日08 :00的24 h降水量实况形成实况数据集.同时,根据国家气象中心T213全球中期数值预报模式的降水预报和网上下载的日本气象厅、德国天气在线取到的降水格点预报场文件,再通过插值得到所需站点的降水预报资料.
在资料选取上,首先利用国家气象中心2003-2007年5-9月逐日的T213数值预报产品作为基本因子资料.所使用的T213数值预报产品包括15层7个预报时效 (0,12,24,36,48,60,72 h) 格点场中的14个基本气象要素,包括:温度、高度、纬向风、经向风、垂直速度、比湿、相对湿度、海平面气压、地面温度、地面气压、10 m纬向风、10 m经向风、2 m温度、2 m相对湿度.利用这些基本气象要素,通过动力诊断得出反映降水的物理量,如涡度、散度、位温等100多个气象物理量,以及涡度、温度等平流项物理量和梯度项物理量,此外还有从地面到某层的垂直累积上升速度、水汽通量、水汽通量散度和一些时间累积的物理量,然后利用双线性插值方法将这些基本要素和扩充物理量插值到对应的站点上,形成预报所需要的站点因子库.
2.2 因子的选择预报效果的好坏,不仅与预报方法有关,与所选择的预报因子关系更为密切,故在选择因子时,必须选取有物理意义的因子作为预备因子,因为从众多因子中客观地选取出较好的因子可以提高预报效果.
为了选取较好的因子,首先确定某站点的预报对象,然后计算该站预报时效所对应的 (可跨前后1~2个时效) 预报因子与相应预报对象之间的相关,挑选出与实况降水量相关系数较大的不同层次的因子,最后再通过逐步回归方法,利用F检验在这批因子中选取其中相关最好的25个因子,形成该站点的预报因子集,对于不同站点、不同预报时效,选取的预报因子都不一样.根据预报员经验,日本、德国的数值预报结果有较好的参考价值,所以将日本、德国和T213的降水数值预报结果也插值到站点上作为因子,共得到28个因子.
由于预报因子之间的量级存在差异,在建模之前,使用式 (7) 对全部样本的每一个因子分别进行归一化处理,使每个因子的数据归一化到[0, 1]之间.
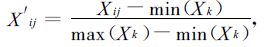
|
(7) |
式 (7) 中,X′ij为标准化后的因子,X ij为标准化前的因子,min (X k) 和max (X k) 分别表示第k个因子的所有样本中的最小值和最大值.
2.3 预报建模和试报结果为了验证改进BP算法的可行性,用改进和传统的BP算法对相同的降水预备资料进行建模及预报,并对两者的预报效果进行对比,同时,为了比较BP方法与数值预报方法的效果,在分析中对数值预报结果也做了简要对比分析.
2.3.1 BP网络的参数选择改进和传统的BP网,都采用雷景生等[25]的网络结构,在此试验中,有28个输入节点和1个输出节点.由上述分析可知,改进的BP网络可以自适应确定网络结构参数和学习训练参数,而传统的BP网络的参数一般都是经验值,根据实验确定:隐节点数取42,学习率取0.2,训练次数取1500.
2.3.2 区域预报结果分析选取江淮流域中的68个站点,利用2003-2005年5-9月的T213、日本、德国资料以及实况资料作为训练样本集,通过传统和改进BP方法对2006-2007年5-9月逐日08 :00-08 :00 24 h降水量进行24,48,72 h时效的降水量≥0.1 mm (小雨)、降水量≥10 mm (中雨) 和降水量≥25 mm (大雨) 降水预报,并结合T213、日本、德国数值预报产品进行比较.
图 3a~3c是上述各种预报方法 (其中,改进和传统BP方法分别简称为“ANN改进”和“ANN传统”) 对3个等级降水 (降水量≥0.1 mm, 降水量≥10 mm, 降水量≥25 mm) 做出的24,48,72 h时效预报的平均TS评分、空报率、漏报率.

|
|
| 图 3. 2006-2007年5-9月各方法的降水量预报检验评分对比 (a) 平均TS评分,(b) 平均空报率,(c) 平均漏报率 Fig 3. Comparison of forecast verification for 24-hour precipitation among severalf orecasting methods from May to September during 2006-2007 (a) the average threat score (TS), (b) the ave rage false alarm rate (FAR), (c) the average missing alarm rate (MAR) | |
根据平均TS评分结果 (图 3a) 分析可知:对不低于0.1 mm、不低于10.0 mm、不低于25.0 mm降水的24,48,72 h时效预报,改进的BP方法预报效果最好,其预报结果的平均TS评分较传统BP方法有大幅度的提高.对于不低于0.1 mm的降水预报,传统BP方法的3个时效预报结果的平均TS评分分别是0.493,0.445,0.409,而改进的BP方法为0.55,0.538,0.476,分别比传统方法的评分高5.7 %,8.3 %,6.7 %.对于不低于10.0 mm降水的3个时效预报,改进的方法比传统的方法平均高出7.8 %,5.8 %,5.8 %,而对于不低于25.0 mm的降水预报,其平均TS评分要高出6.3 %,5.1 %,5.1 %.从分析结果可看出,相比传统BP方法,改进的BP方法对不低于0.1 mm降水48,72 h时效的预报效果更显著,而对不低于10.0 mm, 不低于25.0 mm降水24 h时效的预报效果更好.
根据平均空报率、漏报率的结果 (图 3b,3c) 分析可得知:改进的BP方法在做降水预报时,空报率和漏报率分别比传统方法平均降低了9 %和4 %,表明改进的BP方法在预报时,更多地减少了空报,对漏报情况也有所改进.对不低于0.1 mm降水预报中,日本数值预报的空报率较大,漏报率较小,而在不低于10.0 mm和不低于25.0 mm降水的预报中,改进的BP算法的空报率比日本稍微大些,漏报率却比日本小很多,而德国、T213的空报率和漏报率都比较大.
综上所述,无论是哪种时效、哪种降水级别,改进的BP方法的预报效果都较好,预报结果的平均TS评分比传统的BP方法有较大幅度提高,在空报率和漏报率上,改进的BP方法比传统的BP方法都有明显降低.同时从预报结果的比较分析可看出,相比数值预报方法的预报效果,改进的BP方法也有很大提高.
2.3.3 局部预报结果分析分析改进的BP方法对江淮流域降水的区域预报效果以后,为了检验它对局部地区的预报效果,选取代表不同地域的8个气象站点 (包括武汉、南岳、井冈山、南京、合肥、上海、杭州、南昌),检验改进方法对具体站点的预报效果,训练资料以及预报资料同上.
图 4、图 5、图 6分别是多个方法对2006-2007年5-9月不低于0.1 mm、不低于10.0 mm和不低于25.0 mm降水24,48,72 h时效预报的TS评分,由图可知:对大部分站点的小雨、中雨、大雨预报,改进的算法比传统算法的预报效果都有很大提高.

|
|
| 图 4. 2006-2007年5-9月各方法对不低于0.1 mm降水预报TS评分对比 Fig 4. Comparison of threat score (TS) for 24-hour precipitation (≥0.1 mm) among severalforecasting methods from May to Septembe rduring 2006-2007 | |

|
|
| 图 5. 2006-2007年5-9月各方法对不低于10.0 mm降水预报TS评分对比 Fig 5. Comparison of threat score (TS) for 24-hour precipitation (≥10.0 mm) among several for ecasting methods from May to September during 2006-2007 | |

|
|
| 图 6. 2006-2007年5-9月各方法对不低于25.0 mm降水预报TS评分对比 Fig 6. Comparison of threat score (TS) for 24-hour precipitation (≥25.0 mm) among severalfor ecasting methods from May to September during 2006-2007 | |
在降水量≥0.1 mm预报中,除了南京站 (58238)48 h时效预报的TS评分比传统方法低1.1 %外,其他站点的预报TS评分都有一定程度提高,特别是武汉站 (57494)、南岳站 (57776)、井冈山站 (57894) 等站点在24,48 h时效预报的TS评分都提高了10 %以上,有的甚至超过15 %,表明改进的BP方法对局部地区的预报也有一定参考意义.
对于不低于10.0 mm降水的预报,除了武汉站 (57494)48,72 h时效、上海站 (58362)48 h时效,改进的方法比传统方法的预报效果差些,其他站点也有很大改进,尤其是对南岳站 (57776)、井冈山站 (57894)、南京站 (58238)、杭州站 (58457)、南昌站 (58606) 这几个站点的3个时效的预报效果都非常好.而对不低于25.0 mm降水预报,改进的BP方法除了对合肥站 (58321) 的48 h时效、上海站 (58362)72 h时效的预报效果比传统方法差,其他预报效果都有较明显提高.比如南岳站 (57776),改进的BP方法对3个时效的TS评分分别是0.5,0.375,0.222,传统的方法的预报结果分别是0.4,0.239,0.205,而数值预报最好的TS评分分别为0.233,0.207,0.107.
3 结语降水是一系列复杂的动力及热力过程相互作用的产物,具有典型的非线性性质,而人工神经元网络由于具有非线性映射能力,以及自学习、自组织和自适应能力,适合于这类气象要素的建模和预报.但是在实际应用中,传统的BP算法存在收敛速度慢、易陷入局部极小点等缺陷.本文在传统BP算法基础上提出了一种学习参数和结构参数自适应调整方法,使得网络在训练过程中能自动确定最优的网络结构参数和学习训练参数,并且克服了网络泛化能力差、局部极小等问题,提高了BP网络的学习效果.由于在整个学习训练过程中,不需要人工确定任何参数,因此该方法对推动人工神经元网络的应用具有重要意义.
本文利用改进的BP算法对2003-2007年5-9月江淮流域68个站的降水进行建模和预报,并结合传统BP算法的预报结果及T213、日本、德国数值预报产品进行对比,从分析结果可看出,改进的BP方法对降水预报效果较传统的方法有显著改善,相比数值预报结果也有很大优势,因此该方法具有较好的实用价值.
| [1] | Hall T, Brooks H E, Doswell C A, Precipitation forecasting using a neural network. Weather and Forecasting, 1999, 14: 338–345. DOI:10.1175/1520-0434(1999)014<0338:PFUANN>2.0.CO;2 |
| [2] | Jin L, Ju W M, Miao Q L, Study on ANN-based multi-step prediction model of short-term climatic variation. Advances in Atmospheric Sciences, 2000, 17: 157–164. DOI:10.1007/s00376-000-0051-4 |
| [3] | Marzban C, Witt A, A bayesian neural network for severe-hail size prediction. Weather and Forecasting, 2001, 16: 600–610. DOI:10.1175/1520-0434(2001)016<0600:ABNNFS>2.0.CO;2 |
| [4] | 施丹平. 人工神经网络方法在降水量级中期预报中的应用. 气象, 2001, 27, (6): 40–42. |
| [5] | 张韧, 蒋国荣, 余志豪, 等. 利用神经网络计算方法建立太平洋副高活动的预报模型. 应用气象学报, 2004, 11, (4): 474–483. |
| [6] | 李法然, 周之栩, 陈卫锋, 等. 湖州市大雾天气的成因分析及预报研究. 应用气象学报, 2005, 16, (6): 794–803. |
| [7] | 赵声蓉. 多模式温度集成预报. 应用气象学报, 2006, 17, (1): 52–58. |
| [8] | 胡文东, 沈桐立, 丁建军, 等. 卫星资料的非线性反演同化与一次强降水预报试验. 应用气象学报, 2006, 25, (2): 249–258. |
| [9] | 刘德, 李晶, 刘永华, 等. BP神经网络在长期天气过程预报中的应用实验. 气象科技, 2006, 34, (3): 250–253. |
| [10] | 赵声蓉, 裴海瑛. 客观定量预报中降水的预处理. 应用气象学报, 2007, 18, (1): 21–28. |
| [11] | 叶笃正, 曾庆存, 郭裕福. 当代气候研究. 北京: 气候出版社, 1991: 164-177. |
| [12] | 刘还珠, 赵声蓉, 陆志善, 等. 国家气象中心气象要素的客观预报———MOS系统. 应用气象学报, 2004, 15, (2): 181–191. |
| [13] | 陆如华, 何于班. 卡尔曼滤波方法在天气预报中的应用. 气象, 1994, 20, (9): 41–46. |
| [14] | 寗春蓉, 冯汉中. 利用卡尔曼滤波方法释用数值预报产品. 四川气象, 2004, 24, (2): 16–19. |
| [15] | 陈豫英, 刘还珠, 陈楠, 等. 基于聚类天气分型的KNN方法在风预报中的应用. 应用气象学报, 2008, 19, (5): 564–572. |
| [16] | 曾晓青, 邵明轩, 王式功, 等. 基于交叉验证技术的KNN方法在降水预报中的试验. 应用气象学报, 2008, 19, (4): 471–477. |
| [17] | 陈永义, 俞小鼎, 高学浩, 等. 处理非线性分类和回归问题的一种新方法 (Ⅰ)———支持向量机方法简介. 应用气象学报, 2004, 15, (3): 345–354. |
| [18] | 冯汉中, 陈永义. 处理非线性分类和回归问题的一种新方法 (Ⅱ)———支持向量机方法在天气预报中的应用. 应用气象学报, 2004, 15, (3): 355–365. |
| [19] | 赵国令, 肖科丽. 支持向量机在天气预报中的应用. 陕西气象, 2004, (6): 1–4. |
| [20] | 燕东渭, 孙田文, 杨艳, 等. 支持向量机数据描述在西北暴雨预报中的应用试验. 应用气象学报, 2007, 18, (5): 676–681. |
| [21] | 罗坚. 基于SVM的分类方法及其应用. 浙江工贸职业技术学院学报, 2008, 8, (3): 29–33. |
| [22] | 曹均阔, 舒远仲, 叶水生. 一种结构自组织的改进BP网络. 计算机工程, 2005, 31, (17): 165–167. |
| [23] | 王正武, 张瑞平, 刘松. BP网络的一种改进学习方法. 数学理论与应用, 2005, 25, (1): 31–34. |
| [24] | 李宏刚, 吕辉, 李刚. 一种BP神经网络的改进方法及其应用. 中国工程科学, 2005, 7, (5): 63–65. |
| [25] | 雷景生, 康耀红. 一种改进的BP算法. 海南大学学报自然科学, 2003, 21, (4): 326–329. |
| [26] | Rumelhart D E, Hinton G E, Williams R J, Learning Inter-nal Representation by Error Propagation. Parallel Distributed Processing:Explorations in the Microstructure of Cognition, 1986: 318–362. |
| [27] | Lippmann R P, An introduction to computing with neural nets. IEEE ASSP Magazine, 1987, (4): 4–22. |
| [28] | Hecht-Nielsen R, Theory of the back-propagation neural net-work. IEEE International Joint Conference on Neural Networks, 1989, 1: 593–605. |
| [29] | Huang S C, Huang Y F, Bounds on number of hidden neu-rons in multilayer perceptrons. IEEE Transactions on Neu-ral Networks, 1991, 2: 47–55. DOI:10.1109/72.80290 |
| [30] | Reed R, Pruning algorithm-a survey. EEE Transactions on Neural Networks, 1993, 4: 740–747. DOI:10.1109/72.248452 |