 2009, 20 (2): 232-239
2009, 20 (2): 232-239


2. 中国科学院东亚区域气候-环境重点实验室, 北京 100029;
3. 南京军区空军气象中心, 南京 211101
2. Key Laboratory of Regional Climate-environment Research for Temperate East Asia, Chinese Academy of Science, Beijing 100029;
3. Nanjing Airforce Command Weather Center, Nanjing 211101
客观要素预报是随着科学进步、经济发展以及人们需求提出来的。目前, 定时、定点、定量的客观要素预报是建立在数值预报基础上的。数值预报集大气探测、天气学、动力气象学以及计算机、通信技术为一体, 生成大量可用信息, 既包含天气过程发展演变, 也包含某些天气现象产生的热力-动力学机理, 当然还包括由于种种局限而产生错误和虚假的信息, 在研究、解读过程中需要将其中的信息通过释用技术满足实际需求。解释应用是对数值预报这一综合性结果, 运用动力学、统计学技术再一次加工、修正, 使预报精度得到进一步提高, 以达到有价值的要素预报水平[1]。丑纪范[2]曾明确指出, 要提高短期气候预测准确率, 需要走统计与动力相结合之路, 这同时也是我国近代气候业务系统发展的要求。实践证明:通过对数值预报产品的释用, 要素预报比模式直接输出的预报有明显提高[3-7]。
目前, 国内大部分解释应用工作是建立在Glathn和Lowry提出的模式输出统计法(Model Output Statistics, 简称MOS)基础上的[1]。具体做法是先将所选站点周围格点资料插值到该站点上, 然后通过某种统计方法与预报要素建立回归方程[8]。在实际应用中, 将插值后的数值预报产品代入相应的预报关系式中, 即可得到预报值。这一方法会在插值时引入误差, 此外也不能综合、有效地利用数值预报产品的场信息。尤其对于短期气候预测来讲, 站点周围的格点资料不能完全反映气象要素平均态的变化, 而其他格点上信息可能与站点要素场存在某种关系, 若引进反应预报物理量场面信息(即两维信息)的因子, 也许会使预报得到改善。图 1是MM5输出10m经向风场与平潭站10月旬平均温度相关系数分布图。由图 1可知, 与平潭站温度相关性最好的经向风场格点并不在站点周围, 而是在站点的西南方向, 这是具有物理意义的。

|
|
| 图 1. MM5输出 10 m 经向风场与平潭站10月旬平均温度相关系数分布图 Fig 1. The coefficient between MM5 output of 10-meter wind and 10-day average temperature in October of Pingtan | |
典型相关分析(CCA)是近年发展起来的一种新的统计方法, 在交叉相关极大的条件下, 找出两个场之间最高相关的典型分布型, 客观定义了因子场与预测场高相关的类型, 并可利用主要典型分布型作预测方程的回归, 提取预报场与因子场之间线性相关信息中的主要成分。美国国家气候预测中心已将CCA为基础的统计预报模式应用于长期预报业务[5]。该方法用于数值预报产品的解释应用, 可以综合利用场信息与站点气象要素的关系建立预报模型。CCA方法在建模的过程中, 只能选用一个因子场建立预报模型, 而单个因子场很难反映出气象要素复杂的变化规律, 而且典型因子的回归亦属于线性回归, 因此也很难对单站要素做出精确预报。在短期内无法有效提高数值预报产品质量的情况下, 寻找一种能综合有效利用全场信息的非线性释用方法提高预报精度, 正是本文的目标。
1 基于CCA-BP-BPNN的统计释用技术原理与方法 1.1 CCA-BP方法及其被引入的原理CCA方法往往被用来分析两个天气系统 (包含多个网格点的气象要素场) 之间的关系, 即找出两组变量典型代表的新变量, 这两个新变量可以由原两组多个变量的线性组合构成, 就气象意义说, 这两个典型代表的新变量可以看成是原两个天气系统包含的若干天气或气候指标综合而成的综合指标。如果考虑使用一个因子场与一个单站要素做典型相关分析, 就可以得到一对典型向量, 那么用所得到的左权重典型向量乘因子场矩阵就可以得到一维的典型因子, 这个典型因子不仅综合了全场各点信息, 而且体现了原因子场与站点要素值线性组合中最佳的线性关系, 代表了因子场与站点预报要素之间的全部协方差关系。根据χ2检验, 就可以确定这个因子场所组成典型因子是否能很好地反映站点要素值变化。
CCA-BP法是主成分分析基础上的CCA[8]。大气科学中分析场格点数往往很多, 或者说维数很高, CCA识别出的模态数目很多, 反映的信息不够集中。而EOF能够提取场的时空变化的主要信息, 或者说压缩变量的自由度, 保留时空尺度大的变化成分的方差, 而消除一些小尺度变化及噪声的影响。再者, 对因子场进行EOF展开, 提取前m个主分量, 可以避免CCA过程中可能出现的逆矩阵蜕化现象。需要说明的是, EOF分解出的前m个主分量仅代表了原因子场的大部分方差, 因此组合而成的典型因子也只代表了原因子场与站点要素的大部分协方差。使用CCA-BP法得到典型因子的数学模型如下[8] :
记分析对象为S场(因子场), 有NS个格点, 有相对应的n次观测, 样本资料经过标准化处理。
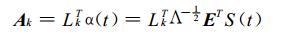
|
(1) |
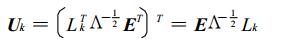
|
(2) |
通过式(1)和式(2)可以直接由因子场得到典型因子及其转换矩阵。其中, Lk为主成分基础上CCA的左权重向量, Λ为由特征值构成的N1阶对角矩阵, E为特征向量, Uk为转换矩阵, Ak为典型因子矩阵。
1.2 与神经网络方法的结合对于非线性统计预报方法, 本文采用基于人工神经网络误差后传算法(BP模型), 简称BPNN。BPNN是一个非线性动力系统, 它由许多并行运算的神经元构成, 其特色在于信息的分布式存储和并行协同处理, 能够描述和模拟许多复杂的行为。神经网络系统具有集体运算能力和自适应的学习能力, 可实现函数逼近、数据聚类、优化计算、自适应模式识别和非线性预测等功能。在理论意义上BPNN模型能在相当高的精度上逼近任意复杂的天气系统, 因而可有效移植应用于许多用常规方法不易处理的系统辨识和复杂天气预测, 并为建立合理、可靠和准确的预报模型提供依据[9-10]。
实际应用时, 对于确定的单站要素, 通过不同的因子场得到多个典型因子, 进而通过BPNN实现典型因子场与站点要素之间的非线性建模。由于BPNN自身不提供筛选因子的方法, 本文通过逐步回归方法来构造BPNN的学习矩阵。
2 预报试验及其效果分析 2.1 资料选用平潭 (25.31°N, 119.47°E)、福州 (26.05°N, 119.127°E) 作为释用站点, 预报对象为两站10月旬平均温度和旬降水距平百分率, 实况资料来自于国家气候中心提供的1983 -2005年每日4次地面资料, 均处理成旬平均的形式, 共69个样本。用1983-2001年资料建模, 2002-2005年资料做独立预报试验。
数值预报产品来自国家气候中心全球大气-海洋耦合模式 (CGCM_1.1) 的输出产品。国家气候中心新建立的动力模式业务系统包括月动力延伸预报模式 (全球大气环流模式T63)、季节气候预报模式(全球海洋-大气耦合模式和区域气候模式)、ENSO年变化预测模式(简化海气耦合模式), 以此为平台, 逐步形成了月、季到年际时间尺度的模式预测业务。经过一年多的试验性业务运行和20年的历史回报试验检验, 表明模式预测系统的预报效果良好。本文用MM5对其进行回报, 形成适合动力解释预报使用的高分辨率格点化数值产品。这样做既可以解决原始资料分辨率过低的缺陷, 也使被选因子种类更加丰富。
2.2 因子场的选取与处理预报因子选取对于释用结果的优劣具有决定性作用, 因此在选用因子时应具有客观性, 广泛选取具有天气学意义及物理意义的因子。本文依据天气学理论和已有的预报经验选取了58个基本预报因子和综合预报因子, 它们基本反映出形势场、温湿场、扰动场、平流场和环流动态的演变。
使用CCA-BP法分别对平潭站、福州站的旬平均温度和旬降水距平百分率建立典型因子。对于旬平均温度, 分别有33, 16个典型因子通过显著性为0.01的χ2检验; 对于旬降水距平百分率, 分别有16, 13个典型因子通过显著性为0.05的χ2检验。
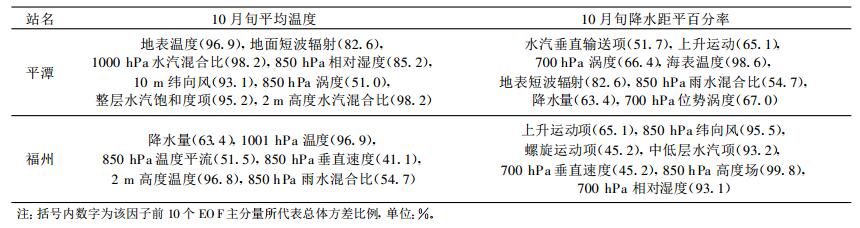
通过逐步回归方法构建BPNN的学习矩阵时, 为了使最终建立方程有比较好的预报效果, 避免拟合好、预报差, 应该对进入方程的典型因子进行长期稳定性检验[11-12], 并选用那些稳定性好的因子。按照文献[13]的方法, 对典型因子进行相关稳定性检验, 表 1列出了最终入选的典型因子。
|
|
表 1 最终入选的典型因子 Table 1 Final selected canonical variables |
2.3 典型因子与插值因子的对比分析
图 2为使用插值法得到的因子场和综合场信息建立的典型因子场分别与平潭站10月旬平均温度做相关得到的复相关系数图。可以看出, 综合了场信息的典型因子能更好地反映出温度变化规律, 79.3 %的复相关系数达到0.5以上, 除了700hPa相对湿度 (0.39) 和中低层水汽项 (0.36) 以外, 其他复相关系数均在0.4以上, 最大复相关系数为0.73, 平均复相关系数达到0.54。而插值法得到的因子, 最大绝对复相关系数为0.39, 最小为0, 平均复相关系数只有0.17。两者相比而言, 每一个因子场构成的典型因子均比插值得到的因子相关系数要高, 最小提升0.15, 最大提升0.61, 平均提升0.37。旬降水距平百分率及福州站情况类似。可见, 综合了全场信息的典型因子比使用插值得到的因子包含了更多的预报信息。

|
|
| 图 2. 插值因子和典型因子与平潭站 10 月旬平均温度复相关系数 Fig 2. The coefficient of interpolation variables and canonical variables to 10-day average temperature in October of Pingtan | |
2.4 BPNN建模及两种模型的对比检验
本文采用3层网络建模, 考虑到网络的稳定性及过拟合问题, 通过反复试验确定隐层节点数。隐含层采用tansig传递函数, 输出层采用线性传递函数。网络的学习算法采用LM算法, 该算法收敛速度快, 计算精度高, 往往可以获得比其他任何一种算法更小的均方根误差[14]。为了提高网络泛化能力[15], 使网络按照归一化法进行训练, 当误差不再下降且小于给定阈值时停止训练。当误差不再下降但仍很大时, 重新调整网络参数再训练。
为了检验CCA-BP-BPNN模型 (下面简称“C-B模型”) 拟合、预报的效果以及全局因子的作用, 本文采用插值模型与其做对比检验。在统计回归方法上, 两种模型均使用BPNN方法, 不同的是, C-B模型使用集合了全场信息的典型因子, 而插值模型使用的是只反映局地信息的插值因子, 这样做的目的是凸显全局因子相比插值因子的作用。两种模型选用相同的预报要素建立预报因子。
2.5 旬平均气温预报效果检验图 3为平潭站两种模型的拟合结果 (福州站图略), 可以看出, 两种方法对历史样本的拟合效果都较好, 基本能将历史气温的演变趋势再现。相比而言, C-B模型的拟合效果更好一些, 复相关系数平潭站达到0.921, 福州站为0.931。插值法有个别极值没有拟合出来, 而且普遍存在着拟合值偏小的现象, 复相关系数平潭站为0.822, 福州站为0.810。对于个别年份 (如1983年10上旬、1998年10中旬), 两种方法的拟合结果都不好, 这可能与数值预报产品质量有关系。

|
|
| 图 3. 平潭站1983-2001年10月旬平均温度拟合图 Fig 3. Fitting of 10-day average temperature in October during 1983-2001 of Pingtan | |
图 4给出了平潭站、福州站两种预报模型的预报结果, 从气温的演变趋势上看, 插值模型和C-B模型的预报趋势都较好, 而模式直接输出2 m气温普遍偏小。为了客观定量分析, 采用平均绝对误差、均方根误差、距平相关系数、预报准确率4种统计评价指标进行分析[10-11]。

|
|
| 图 4. 平潭站 、福州站2002-2005年10月旬平均温度预报图 Fig 4. Forecast of 10-day average temperature in October during 2002-2005 of Pingtan and Fuzhou | |
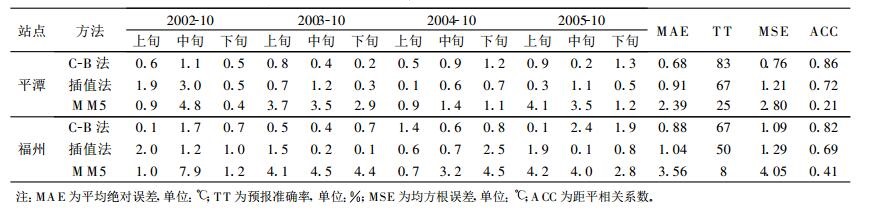
两种模型的预报统计评价结果列于表 2中, 可以看出, 两种解释预报的各项指标均高于模式直接输出产品, 说明解释预报对数值预报产品的订正效果明显。对两种解释预报模型预报统计指标进一步比较可以看出, C-B模型平均绝对误差平潭站、福州站分别为0.68, 0.88℃, 插值模型分别为0.91, 1.04℃, 而对于各旬来说, 两者互有高低, 平潭站C-B模型小于插值模型的有6个, 插值模型小于CB模型的也有6个, 福州站情况相同, 反应出插值模型绝对误差浮动较大, 不够稳定。平潭站均方根误差分别为0.76, 1.21℃, 距平相关系数分别为0.86, 0.72, 预报准确率分别达到83%和67%。C-B模型的平均绝对误差比插值模型的小0.23℃, 均方根误差小0.45℃, 距平相关系数大0.14, 预报准确率大16%。福州站均方根误差分别为1.09, 1.29℃, 距平相关系数分别为0.82, 0.69, 预报准确率分别达到67%和50%。C-B模型的平均绝对误差比插值模型的小0.24℃, 均方根误差小0.20℃, 距平相关系数大0.13, 预报准确率高17%。可见, 对于同一站点, C-B模型的拟合精度和预报能力均优于插值模型; 对于不同站点, 平潭站与福州站两种模型的拟合率较为接近, 但平潭站的预报效果明显高于福州站。从两站模式输出2 m温度评估指标来看, 平潭站优于福州站。因此, 两站间预报效果的差异可能是数值预报产品质量导致的。
|
|
表 2 两种模型对平潭站 、福州站 2002-2005年10月旬平均温度预报结果检验 Table 2 The result of forecast of 10-day average temperature in October during 2002-2005 of Pingtan and Fuzhou from two models |
2.6 旬降水距平百分率预报效果检验
为了进一步评估两种模型优劣, 本文选取预报难度更大的旬降水距平百分率作为预报对象。与温度预报不同的是, 依据经典的统计理论, 当预报因子和预报对象接近正态分布时, 建立的统计方程比较稳定, 所以对于降水这类偏态分布的要素要先进行正态化处理。具体做法是, 对降水量做开四次方变换, 然后再写成降水距平百分率的形式。另外, 将评价指标中的预报准确率评分换为PS评分。PS评分是按1999年中国气象局下发的《短期气候预测质量评定暂行办法》进行, 该评分反映的是预报与实况距平同号率[10]。
从1983-2001年平潭站10月旬降水距平百分率的拟合结果(图略)可以看出, 两种模型对历史样本都有较高的拟合精度, 尤其是极大值拟合效果较好, 例如1986和1998年10月下旬。复相关系数分别为0.873, 0.830, 而平均绝对误差分别为0.30, 0.12。福州站拟合结果类似, 复相关系数分别为0.842, 0.733, 而平均绝对误差分别为0.45, 0.56。
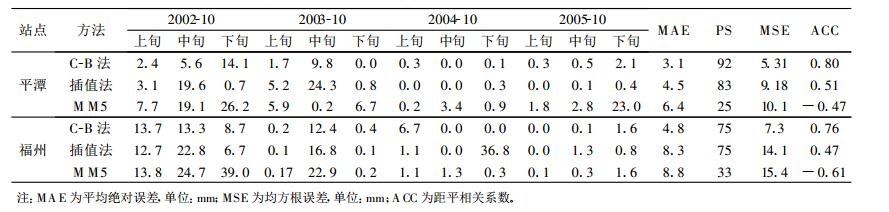
图 5为两种模型对平潭站、福州站独立样本的预报结果, 将降水距平百分率还原成降水量后的评价指标列于表 3中。从图 5可以看出两种模型的预报精度均高于模式直接输出产品, C-B模型的预报序列与实况吻合得更好, 整体趋势比较一致, 插值模型趋势略差, 尤其前两年。平潭站C-B模型的绝对误差只有1旬大于10 mm, 为14.1 mm, 而福州站的绝对误差有2旬大于10 mm, 最大为24.3 mm。两者PS评分分别达到92, 83, 平均绝对误差分别为3.1, 4.5 mm, 均方根误差分别为5.31, 9.18 mm, 距平相关系数分别为0.80, 0.51;福州站两种模型PS评分分别为75, 75, 平均绝对误差为4.8, 8.3 mm, 均方根误差为7.3, 14.1 mm, 距平相关系数为0.76, 0.47。各项指标均是C-B模型优于插值模型。另外, 两种模型的预报均为后两年比前两年好, 这主要是由于后两年的降水偏少。可见两种模型对小雨的预报效果好于中、大雨, 而C-B模型对中、大雨的预报能力要高于插值模型。与温度预报相同, 平潭站预报效果较好, 进一步说明, 数值预报产品质量对释用结果影响较大。

|
|
| 图 5. 平潭站 、福州站2002-2005年10月旬降水距平百分率预报图 Fig 5. Forecast of rainfall anomalous percentage in October during 2002-2005 of Pingtan and Fuzhou | |
|
|
表 3 两种模型对平潭 、福州站2002—2005年10月旬降水距平百分率预报结果检验 Table 3 The result of forecast of rainfall anomalous percentage in October during 2002—2005 of Pingtan and Fuzhou from two models |
3 小结与讨论
通过上述对比分析, 可得出以下结论:
1) 对于短期气候预测来讲, 站点周围的格点资料不能完全反映出气象要素平均态变化, 而其他格点上的信息可能与站点要素场存在某种关系。
2) 使用CCA-BP法建立可以反映场信息的典型因子, 相比只能反映局部信息的插值因子, 在与站点要素的相关性上有了很大提高, 预报效果也有一定提升。
3) 综合全场信息的因子可能受某些局地变化影响较大, 因此应该对进入方程的典型因子进行长期稳定性检验, 并选用稳定性好、具有物理意义的因子。
4) 从平潭站、福州站温度、降水要素试报来看, 解释预报对数值预报产品做了较大修正, 使预报产品具有一定使用意义及参考价值。从各项评价指标来看, C-B模型优于插值模型。
试验发现, 用本方法建立典型因子时, 需考虑因子场范围的选取。如选取不当, 引入与预报量关系不好的格点, 会影响到预报精度及稳定性。本文在这方面没有做更多讨论, 但应予以必要的注意。另外, 本文所用MM5输出产品的资料长度比较短, 统计规律并没有充分体现, 在一定程度上影响了预报模型的可靠性。再者, 旬尺度预报介于天气预报和短期气候预报之间, 其不确定性使得预报难度加大。如果将该模型用于长期、稳定的数值预报产品, 预报精度应当有所提升。另外, 受资料及计算条件限制, 本文仅选用了东南沿海两个站点做试验, 取得了令人满意的结果。至于对北方及西部气候变率大的地区, 该模型是否具有普适性, 仍需大量的个例予以验证。
| [1] | 刘还珠, 赵声蓉, 陆志善, 等. 国家气象中心气象要素的客观预报-MOS系统. 应用气象学报, 2004, 15, (2): 181–191. |
| [2] | 丑纪范. 为什么要动力-统计相结合? ————兼论如何结合. 高原气象, 1986, 5, (4): 367–372. |
| [3] | 陈豫英, 陈晓光, 马金仁, 等. 基于MM5模式的精细化MOS温度预报. 干旱气象, 2005, 23, (4): 52–56. |
| [4] | 吴滨, 蔡学湛. 用典型相关分析预测福建前汛期降水. 气象科技, 2005, 33, (1): 32–36. |
| [5] | 毛恒青, 李小泉. 典型相关分析 (CCA) 对我国冬季气温的短期气候预测试验. 应用气象学报, 1994, 5, (4): 386–391. |
| [6] | 林纾, 陈丽娟, 陈彦山, 等. 月动力延伸预报产品在西北地区月降水预测中的释用. 应用气象学报, 2007, 18, (4): 555–560. |
| [7] | Aristita Busuioc, Chen Deliang, Hellstrom Ccilia, Performance of statistical downscaling models in GCM validation and regional climate change estimates: Application for Swedish precipitation. Inter J Climatology, 2002, 21: 557–578. |
| [8] | 吴洪宝, 吴蕾. 气候变率诊断和预报方法. 北京: 气象出版社, 2005: 136-141. |
| [9] | 胡江林, 张礼平, 宇如聪. 神经网络模型预报湖北汛期降水量的应用研究. 气象学报, 2001, 59, (6): 713–719. |
| [10] | 何慧, 金龙, 覃志年, 等. 基于BP神经网络模型的广西月降水量降尺度预报. 热带气象学报, 2007, 23, (1): 72–77. |
| [11] | 陈桂英, 赵振国. 短期气候预测评估方法和业务初估. 应用气象学报, 1998, 9, (2): 178–185. |
| [12] | 谢考现, 崔秀兰, 刁秀广. 短期气候预测因子的选取及利用. 气象科技, 1999, (2): 26–30. |
| [13] | 马振峰, 陈洪. T63月延伸预报在西南区域短期气候预测中的应用研究. 应用气象学报, 1999, 10, (3): 368–373. |
| [14] | 周开利, 康耀红. 神经网络模型及其MATLAB仿真程序设计. 北京: 清华大学出版社, 2006: 69-101. |
| [15] | 武妍, 张立明. 神经网络的泛化能力与结构优化算法研究. 计算机应用研究, 2002, 19, (6): 21–25. |