 2009, 20 (2): 179-185
2009, 20 (2): 179-185


在农业、水文和环境等领域, 随机天气模拟器 (或生成器) 有着广泛应用。它可生成长序列天气变量值, 为有关数学模型提供必要的数据输入, 还可满足其他一些数据需求, 如:为缺少观测的地区插补逐日天气; 在空间分析中, 对每日天气数据做网格化处理以及构造气候变化情景。
天气生成器通常涉及多变量, 如降水、辐射、最高气温和最低气温等, 其中关键变量是降水。相应的降水模型普遍采用两状态一阶Markov链 (简称Mc) 和日降水量Gamma分布函数的耦合结构[1-8]。在这类模型中, 随机天气干湿状态由Mc决定, 但用该模型生成的干湿期序列统计误差较大。而持续干旱和连绵霪雨, 恰恰是影响我国经济民生、尤其是困扰农业生产的灾害性天气。
前人对干湿期的统计规律早有研究。人们曾假设逐日天气变化过程遵循柏努利测验, 认为无论干日 (或湿日) 均对随后的干日 (或湿日) 无任何影响, 或彼此随机不相干, 以此推算干湿期的期望频数。Jorgensen根据Gold和Cochran提供的方法, 绘制了雨期延长概率图, 用以估算雨期持续若干日后, 至少再持续若干雨日的概率[9]。Steinhäuβer [10]用简单的Poisson分布代表干湿期的频数分配, 计算了各种长度的干期与湿期频数。Gabriel等[11]认为干湿期序列遵循简单的Markov过程, 提出干湿期的概率分布。Longley[12]根据天气资料, 用实验方法指出, 干湿期序列长度与其累积频数间有对数关系。么枕生[13]认为, 干日和湿日彼此并不独立, 逐日天气变化不符合Bernoulli测试, 而是有后效作用的链锁现象; 并用Polya分布 (亦称概率传染分布) 计算了干湿期的期望频数。然而, 已有的研究表明, 所有尝试过的经典理论分布, 似都不能满意地配合干期频数。
为满足农业研究对长序列逐日天气数据的需求, 弥补现有天气生成器的不足, 作者应用数据建模 (modeling of data) [14]方法, 构造了干湿期随机模型DWS。与Mc不同, 该模型使用的随机变量是干 (或湿) 期, 而不是干 (或湿) 日; 并直接应用经验分布来描述随机变量的统计特性, 而不寻求分布函数的理论表述[15]。实践表明, 该模型是可用的, 且性能比Mc模型好。本文主要介绍建模步骤和测试结果。
1 干湿期观测值的生成干湿期由干湿日组成。定义干 (或湿) 期, 首先须定义湿日。通常将日降水量大于等于某个阈值 (如0.1mm) 的日子规定为湿日, 小于阈值者为干日。持续为湿日的一段时期为湿期, 持续为干日则为干期。因干、湿持续可能跨月和跨年, 为实现按年、月统计, 特别约定将干湿持续期的第1日所在年、月, 定义为相应持续期所属年、月。图 1说明某i月的统计约定。其中D表示干日, W表示湿日。i月的最后1天为干日, 由此延续到i+1月, 又10个干日, 这一干期长度共有11 d, 按约定, 该干期应统计在i月的干期频数内, 尽管这个干期有10 d是在i+1月。

|
|
| 图 1. 干湿期长度的统计约定 Fig 1. Definition of dry and wet spells length monthly | |
因为在规范的气象记录中, 并无显式的干、湿期统计数据, 所以欲获取其观测值, 只能从逐日降水资料中提取。本文设想逐日降水资料以某种数据库形式储存在计算机里。当从数据库中依次读取逐日天气记录时, 遵循如下干﹑湿期观测值统计算法。
如读到1个干日 (即该日降水量小于阈值) 记录, 则执行干期算法:
Ld=Ld-+1, 若前条记录为干日。
Wj=Lw, j=0, 1, 2, …, nw,
Lw=0,
Ld=Ld-+1, 若前条记录为湿日。
如读到一个湿日 (即该日降水量不小于阈值) 记录, 则执行湿期算法:
Lw=Lw-+1, 若前条记录为湿日。
Di=Ld, i=0, 1, 2, …, nd,
Ld=0,
Lw=Lw-+1, 若前条记录为干日。
其中, Ld, Lw分别是读出某天气记录时的干﹑湿持续日计数; Ld-, Lw-分别是读出前条记录时的干﹑湿持续日计数; Di, Wj分别为干期第i个和湿期第j个观测值; nd和nw分别为干期和湿期观测值频数。
由于干湿期长度通常有显著的年变化, 因此, 至少按月提取观测值, 并按月建立相应的经验分布, 是必须的。
2 干湿期随机建模 2.1 经验分布函数及其统计设某随机变量ξ的n次观测值为x1, x2, …, xn。
所谓经验分布函数Fn (x), 系指由下式规定的函数:
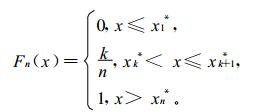
|
(1) |
式 (1) 中, x1*≤x2*≤…≤xn*是按大小排序的观测值, xk*是第k个观测值。显然, Fn(x)=P*{ξ < x}, 其中P*表示事件发生的频率。
根据Γливенко定理[16], 当观测次数n增大时, 经验分布函数Fn(x) 将接近理论分布函数F(x), 即
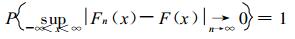
|
显然, 在构建Fn(x) 时, 总希望使随机变量观测样本足够大。为避免观测值频数为0, 在建立干、湿期长度的经验分布函数时, 实际是按下式:
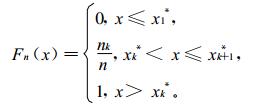
|
(2) |
式 (2) 中, k是将x 1*, x2*, …, xn*进行分组的组序, nk表示第k组内的观测值频数。
考察干湿期长度观测值, 不难发现, 较短的干湿期常有较大的频数, 而较长的干湿期, 频数常常较小。因此, 在实践中, 试验了等距和不等距两种分组方案。
根据分组统计, 可得各组端值 (xi*, xi+1*) 和干湿期累积频率值Fi (i=1, 2, …, k)。它们将被映射成计算机内一张累积频率分配表, 或模拟参数表, 将其绘制成图, 即得经验分布函数曲线。
2.2 干湿期随机模拟根据干湿期的统计分布, 在计算机上进行随机抽样, 可生成干湿期随机变量值序列。这个过程也称蒙特卡罗模拟 (Monte Carlo Simulation)
已知其统计分布, 对随机变量进行直接抽样, 是常用的一种随机抽样方法。
设ζ是某随机变量, 且其分布函数F(x) 连续。
因分布函数F(x) 是在[0, 1]上取值、且单调递增的连续函数, 所以, 如令随机变量R=F (ζ), 当ζ在 (-∞, x) 内取值时, 则R在[0, F(x)]内取值, 且对应于[0, 1]上的一个r值, 至少有一个x满足
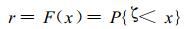
|
用F1(r) 表示随机变量R的分布函数, 则有
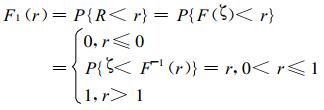
|
(3) |
故R均匀分布在[0, 1]上。
任一随机变量ζ和均匀分布随机变量R的上述关系, 是通过随机数r对随机变量ζ进行直接抽样的理论基础。
在统计获得干、湿期累积频率分配表之后, 再应用计算机里的随机数生成函数, 生成[0,1]均匀分布随机数, 进而对干 (或湿) 期随机变量进行如图 2所示的直接抽样, 即可生成有关随机变量的模拟值。

|
|
| 图 2. 基于经验分布的直接抽样 Fig 2. Direct sampling based on empirical distribution | |
图 2中, F(x) 是干湿期的累积频率; r是 (0, 1) 均匀分布随机数, 一般可由计算机生成, 也可用专门的算法产生。当然, 两者生成的都是伪随机数; F1, F2是紧邻r的两个累积频率多边形节点; x1, x2是随机变量观测值某分组区间端点值, 它们分别对应于F1, F2; x是随机变量抽样值。
因此, 不难导出随机变量抽样公式为:
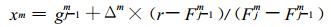
|
(4) |
式 (4) 中, xm为m月随机变量 (干、湿期长度) 抽样值; r为[0, 1]均匀分布随机数; Fj-1m, Fjm分别为模拟参数表中最接近r的第j-1和第j个累积频率值; gj-1m为模拟参数表中与第j-1累积频率相对应的随机变量值; Δm为模拟参数表中与上述两个累积频率相对应的随机变量值差。
逐日天气序列的生成算法, 如图 3所示。由该算法可知, 在生成湿期的同时, 还相应地生成日降水量。

|
|
| 图 3. 基于干湿期的逐日降水生成算法 Fig 3. A lgorithm of generating daily rainfall based on dry and wet spells | |
3 DWS模型测试①
① 取自DWS模拟器输出, 该模拟器是DWS的Java实现。
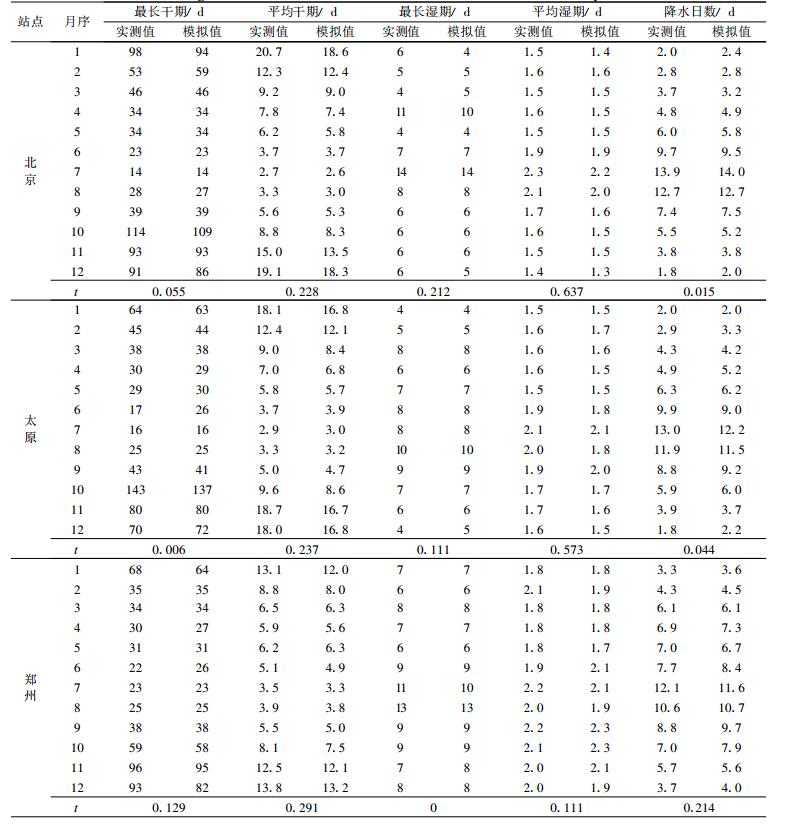
测试所用数据为北京、太原和郑州1951-2005年逐日降水资料。设日降水量≥0.1 mm为湿日, 反之为干日。首先统计各月干湿期观测值、各月干湿期频数和累积频率分配 (即干湿期的经验分布), 并将其存入数据库。为建立累积频率分配表 (即模型参数表), 实践中, 对两种资料分组方案都做了试验。因不同气候区, 干、湿期统计特性各异, 同一地点, 不同季节, 其统计特性也有明显差异, 故需分站按月计算干、湿期模型参数。然后应用计算机提供的 (0, 1) 均匀分布随机数生成函数和式 (4), 按图 3, 依日、月、年时序, 对干 (或湿) 期进行随机抽样, 如此生成100年干湿期模拟序列。为了查明这个序列的可用性, 将以月气候观测值为参考, 对模拟实测值进行差异显著性检验。所涉项目包括最长干期、最长湿期、平均干期、平均湿期和平均降水日数 (表 1)。
|
|
表 1 模拟与实测降水序列统计平均值差异显著性t-检验 (t0.01=2. 819, df=22) Table 1 Significance test of difference between simulated and observed daily rainfall |
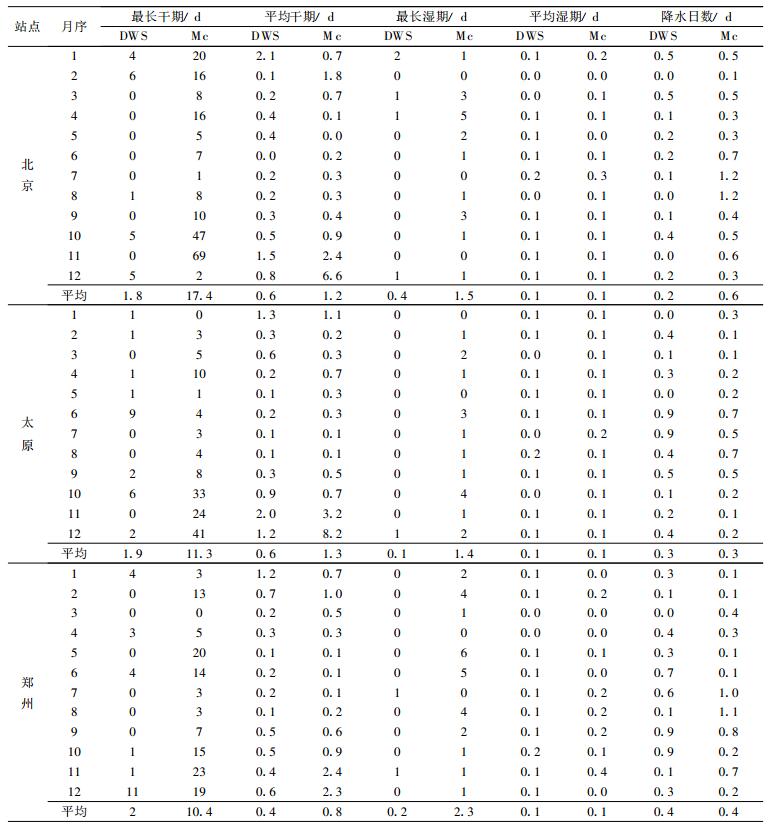
另外, 根据同样的历史逐日降水资料, 应用Mc模型, 统计各月干湿日转移概率, 用以生成100年干湿日模拟序列②, 计算上述各统计量, 求其和实测值差, 最后与DWS的有关统计结果一起列于表 2。
② 借助于逐日天气模拟系统WG4E, 它集成了WGEN (Richardson C W, Wright D A, 1984) 和Shu Geng (1986) 的转移概率计算模型, 用C语言实现。
|
|
表 2 DWS和Mc模拟值的绝对误差 Table 2 Absolute deviations of simulated values with DWS and Mc |
由表 1可见:北京、太原和郑州各月平均干期误差 (即模拟值和实测值之差, 下同) 一般小于1 d; 最长干期误差虽普遍小于2 d, 但各站分别在2月、6月和12月相对较大, 郑州12月最大, 达11 d; 不过, 该月的平均干期误差小于1 d。除北京1月最长湿期误差为2 d外, 其他月份和太原、郑州各月湿期误差均小于1 d, 无论最长湿期或平均湿期。3站各月平均降水日数误差均小于1 d。t-检验显示, 在α=0.01的水平上, 模拟值和实测值的差异是不显著的。
由表 2可见, DWS模拟误差普遍小于Mc模型。虽然后者也能模拟出干湿期的季节变化, 但绝对误差大; 最长干、湿期的模拟效果, 远逊于DWS。如北京10, 11月和太原12月, 最长干期误差竟分别高达47, 69 d和41 d, 郑州11月误差也有23 d。月降水日数的模拟, 两者效果相近, 但是Mc的误差也相对偏大; 北京7, 8月和郑州8月的误差均大于1 d。
此外, 对模拟的干湿期均方差和累积频率也做了统计检验, 模拟和实测值均无显著差异, 限于篇幅未列表内。
DWS模拟器实际还模拟生成了湿期内的逐日降水量, 并且同样效果良好, 因本文仅讨论干湿期直接相关量, 故也未列表内。
4 讨论测试结果显示, 所建干湿期模型是可用的。
DWS模型性能比Mc模型相对较好。主要原因在于, 前者对干 (或湿) 期变量直接建模, 而后者定义的随机变量是干湿日状态, 它不能“识别”干湿期。为了生成干湿日状态的时间序列, Mc总是以前1日的干湿状态为条件, 按转移概率进行随机抽样。且每生成1个干 (或湿) 日, 总不能预知下1日状态; 下1日状态将由下1日的随机抽样来决定。至于干湿期, 则是在已生成干湿日序列之后被测定的。如测定出一个长度为N天的干期, 则它必是N次随机抽样的结果。
在DWS模型中, 随机变量干 (或湿) 期, 由经验分布函数给出其完整的描述, 干湿期序列的生成, 是依据分布函数对干 (或湿) 期变量作直接的随机抽样。每生成1个干 (或湿) 期, 可预知下一步一定是生成1个湿 (或干) 期。显然, 若生成一个长度也是N天的干 (或湿) 期, 它只是一次抽样的结果。
另外, Mc模型建立在一个假设条件之下, 即每次干湿日状态的转移, 仅仅依赖于前一次转移后的状态, 而与更以前的情况无关。这和天气变化的实际并不吻合。DWS模型基于经验分布函数, 它不使用任何理论假设, 唯一地依赖于天气资料样本。
虽然基于经验分布函数的DWS模型有较好的模拟效果, 但付出的代价是用了较多的参数。在建立经验分布时, 倘数据样本被分为N组, 则将产生2N+1个模型参数, 从数学角度看, 缺少数学美感。反之, Mc模型仅用了两个模型参数。
鉴于DWS模型的可用性, 它已作为核心部件被耦合到多要素随机天气模型中。有关细节, 将另文讨论。
致谢 本文所用气象资料承蒙国家气象信息中心提供, 作者谨表诚挚谢意。| [1] | Richardson C W, Wright D A, WGEN: A Model for Generating Daily Weather Variables. USDA, ARS-8 Washington D C, 1984. |
| [2] | Johnson G L, Hanson C L, Hardegree S P, et al. Stochastic weather simulation-Overview and analysis of two commonly used models. J App Meteorol, 1996, 35: 1878–1896. DOI:10.1175/1520-0450(1996)035<1878:SWSOAA>2.0.CO;2 |
| [3] | Larsen G A, Pense R B, Stochastic simulation of daily climatic data for agronomic models. Agronomy Journal, 1982, 74: 510–514. DOI:10.2134/agronj1982.00021962007400030025x |
| [4] | 林而达, 张厚宣, 王京华, 等. 全球气候变化对中国农业影响的模拟. 北京: 中国农业科技出版社, 1997: 23-53. |
| [5] | Semenov M A, Brooks R J, Barrow E M, et al. Comparison of the WGEN and LARS-WG stochastic weather generators for diverse climates. Climate Research, 1998, 10: 95–107. DOI:10.3354/cr010095 |
| [6] | 王世耆.随机天气模拟原理与模拟系统WG4E.计算机与农业 (增刊).作物管理软件研究专集, 1997, :67-82. |
| [7] | Shu Geng, A Simple Method for Generating Daily Rainfall Data. Agricultural and Forest Meteorology, 1986: 363–376. |
| [8] | Richardson C W, Stochastic simulation of daily precipitation, temperature, and solar radiation. Water Resources Research, 1981, 17, (1): 182–190. DOI:10.1029/WR017i001p00182 |
| [9] | Jorgenson D L, Persistency of rain and no-rain periods during the winter at San Francisco. Mon Wea Rev, 1949, 77, (9): 303. |
| [10] | Steinhausser H, Trocken-und Niederschlagsperioden und ihre Theoretische Behandlung. Arch Met Geoph Biokl, 1959, 10, (1): 38–58. DOI:10.1007/BF02243118 |
| [11] | Gabriel K R, Neumann J, On distribution of weather cycles by length. Quart J R Met Soc, 1957, 83: 357–375. |
| [12] | Longley R W, The length of dry and wet periods. Quart J R Met Soc, 1953, 79: 342–520. DOI:10.1002/(ISSN)1477-870X |
| [13] | 么枕生. 气候统计. 北京: 科技出版社, 1963: 170-172. |
| [14] | William H P, Brian P F, Saul A T, et al. Numerical Recipes in C:The Art of Scientific Computing. Cambridge: University Press, 1988: 517-518. |
| [15] | 诸叶平, 王世耆. 随机天气模型及其JAVA实现. 电子学报, 2007, 35, (12): 25–29. |
| [16] | 复旦大学数学系. 统计数学. 上海: 上海科技出版社, 1960: 67-69. |