 2008, 19 (5): 564-572
2008, 19 (5): 564-572


2. 国家气象中心, 北京 100081;
3. 兰州大学大气科学学院, 兰州 730000
2. National Meteorological Center, Beijing 100081;
3. College of Atmospheric Sciences, Lanzhou University, Lanzhou 730000
在我国北方及沿海地区, 平均风速≥12 m/s的大风就会造成严重影响, 甚至灾害。因此, 大风预报在天气预报服务中占有相当重要的地位。
风是人们能直接感觉到的气象要素之一, 它不仅受大中尺度风压定律所制约, 也受边界层动力和热力湍流作用的影响, 同时局地地形、地貌对当地地面风的影响也不可忽视, 这一切给各地地面风预报带来了较大困难。不少台站利用多年积累风资料, 寻找相关因子, 并根据天气形势, 用统计方法制作本地日常风的预报[1]。国家气象中心利用T213数值预报产品建立了日最大风速的MOS预报方法[2]。而对于大风预报, 主要是根据历史形势场资料建立大风预报模型, 然后根据数值预报的形势场作为预报因子来确定是否可能有大风出现, 如杨忠恩等[3]、林良勋等[4]、胡波等[5]分别用人工神经网络和完全预报 (PP) 方法建立了大风预报模型, 取得了一定的预报效果。但是, 由于风要素的地域性和瞬变性强, 特别是作为小概率事件的大风, 使用这些客观方法的预报效果并不是十分理想。
KNN (K-nearest neighbor) 非参数估计技术[6]是近几年来在数值预报释用中颇为重要的一种方法, 它是基于范例进行推理的人工智能领域中发展较快的一种求解问题技术, 利用过去的范例或经验来解决当前问题的类比推理方法, 亦称为相似方法。由于气象要素样本较长, 并且获取资料较为及时, 这使得KNN技术得以在天气预报, 特别是在定性要素的判别中发挥作用。该方法不需要建立预报方程, 直接根据训练数据 (历史天气样本) 建立概率天气预报的K近邻非参数估计仿真模型, 利用训练数据中蕴含的输入输出关系进行预报, 可以避免统计方法的一些弊病和概率密度估计误差的影响。翟宇梅等[7]、邵明轩等[8]利用该方法制作云量及全国600多站点的风和降水预报, 均有较好的效果。
某地某时的风是在天气系统的风压定律制约下, 由当地地形、地貌影响以及边界层局地热力和动力条件相结合而激发的最终产物。在目前尚无法精确描述这些物理过程情况下, 用KNN相似预报方法, 认为相似条件下发生的“行动”会产生相似的结果, 因此对于风的预报, 应用相似方法是合理的。
曾晓青等[9]提出基于交叉验证的KNN方法, 该方法在搜索K邻近域过程中, 考虑天气事件出现的概率不同, 利用交叉验证方法, 分别求取有天气事件的正样本K+值和无天气事件的负样本K-值作为最佳邻近域的组合, 并利用这一方法对我国不同代表站点的晴雨和不小于10 mm的降水预报进行试验, 使降水预报评分得到提高。但这一工作没有考虑天气类型对降水的影响, 即无论是何类环流背景、何种影响系统都提取同一组预报因子, 显然会影响降水预报效果。本文在改进的KNN方法基础上, 尝试从模式识别思想出发, 针对风的预报提出一个基于自组织神经网络的聚类天气分型的KNN方法, 以克服上述方法的不足。
1 资料及其因子处理本文着重考虑我国西北地区的天气影响系统, 研究区域为35°~50°N, 90°~115°E, 所用资料包括2003—2006年冬半年的1—5月和10—12月及2007年1—5月T213数值预报格点场资料及宁夏24个测站日最大风速实况资料。其中, 2003—2006年样本作为训练数据 (经过质量控制, 剔除错误数据), 2007年样本作为预测检验数据。本文选定日最大风速≥6 m/s为预报对象, 一方面是考虑4级以上风对人们日常活动已经造成影响, 另一方面日最大风速≥6 m/s的样本数不至于太少。
T213数值预报产品与文献[9]相同, 包括14个基本要素15层格点场资料, 利用这些基本要素通过动力诊断得到一些反映热量、能量、对流不稳定等的热力、动力因子以及一些时间累积因子, 共有888个扩充因子。然后将这些因子通过双线性插值方法插值到所预报的站点上, 建立站点因子库。
由基本因子和扩充因子构成的T213因子库种类繁多、数量庞大, 在预报对象与预报因子单点相关普查的基础上, 选取相关系数大而且相互独立的高相关因子, 按不同站点不同时效建立KNN方法的基本因子库, 通过逐步回归方法, 经过F检验对因子进行排序筛选, 剔除了一些与预报量相关不大而且物理意义不明显的因子, 将最后入选的10~20个相关系数最高的因子组成站点预报因子集。这些因子在计算前均作了归一化处理。
2 预报方法 2.1 SOM聚类的天气分型聚类分析是数据挖掘中的一类重要技术, 是分析数据并从中发现有用信息的一种有效手段。它将数据对象分组成为多个类或簇, 使得在同一个簇中的对象之间具有较高相似度, 而不同簇中的对象差别很大。聚类算法有多种, 本文采用自组织特征映射网络算法SOM (Self-Organizing Feature Map) 聚类分析。该算法是由Kohonen[10]提出的, 其学习过程可分为两步[11]:①神经元竞争学习过程。对于每一个输入向量, 通过输入向量值xi与权重值wj之间的比较, 在神经元之间产生竞争。权重向量与输入模式最相近的神经元被认为对输入模式反映最为强烈, 将其标定为获胜的神经元, 并称此神经元为输入模式的“像”, 相同的输入向量会在输出层产生相同的“像”, 即为同一种类型。②神经元侧反馈过程。应用侧反馈原理在每个获胜神经元附近形成一个“聚类区”。学习的结果总是使聚类区内各神经元的权重向量保持向输入向量逼近的趋势, 从而使具有相近特性的输入向量聚集在一起, 这个过程被称为自组织。
与传统的模式聚类方法相比, SOM是一种模式分离方法, 这种聚类毋须知道样本的属性, 而是通过自组织的方法将输入样本在指定的相似测度下, 按样本间的相似程度将其映射到输出层的某个节点中[12-13]。图 1为Kohonen自组织特征映射神经网络结构示意图, 由图 1可知, SOM分为输入和输出两层, 输入层用于接受输入样本, 而输出层完成对输入样本的分类。

设网络的输入模式为Pk=(P1k, P2k, …, Pnk), k表示第几个输入模式, k=1, 2, …, q; n是输入向量的维数。竞争层神经元j与输入层神经元之间的连接权矢量为:
Wj=(Wj1, Wj2, …, Wjn),
i=1, 2, …, n; j=1, 2, …, M
输出层分布着网络的M个神经元。SOM的具体算法详见文献[14]。
刘还珠等[15]应用该方法在多模型气象综合预报中针对样本选择问题, 提出了先用SOM方法对样本聚类, 再对多层前向网络进行训练的方法, 实现了SOM串行性多层前向网络的综合预报系统。
SOM方法应用在天气分型中, 可将物理量 (如高度场、风场等) 格点场中每个格点值视为输入层的一个节点, 然后根据聚类目的而确定分类数目, 通过SOM算法, 输出层的节点存在一个权值与输入的节点最接近, 该节点就是此次迭代中竞争获胜的节点。随着邻域在迭代过程中线性减小, 最终对该输入产生最大的响应附近形成一个聚类区, 由此可将物理量场分为几种不同类型。在这一思路指导下, 黄卓等[16]曾经对我国除西北地区外的五大区域高度场和风场进行聚类分型, 进行逐日降水等级相似预报试验。
为了预报宁夏各站日最大风, 考虑到风与大形势下的高度场和风场关系密切, 由于宁夏地势较高, 经过反复对比试验, 最后确定700 hPa高度场及u, v风场作为聚类的基本背景场。反映物理量格点场之间的相似, 一要考虑两个场之间数值的差异, 二要考虑格点场分析出的等值线形状之间的差异, 也就是说, 既考虑值的相似又要考虑形的相似, 根据预报经验, 高度场形的相似更为重要。而高度距平场为该场各格点高度值都减去该场的平均高度值, 即Xi, k=xi, k-Ek, 其中Ek=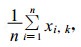

|
|
| 图 2. SOM聚类分析的4种天气型 (粗黑线为700 hPa等高线, 单位:gpm; 细黑带箭头线为700 hPa u, v风场合成的流线) Fig 2. Four weather patterns of SOM cluster analysis (black bold lines are contours at 700 hPa, unit:gpm; arrow lines are stream lines at 700 hPa) | |
从图 2的天气分型结果来看, 冬半年影响西北地区的天气形势主要有4种:第一类为平直气流型, 中高纬度地区气流较平, 青藏高原到河套南部有小股弱冷空气活动; 第二类为西高东低型, 河套以西高度场较高, 为反气旋控制, 河套东部有一明显的低涡; 第三类为强西北气流型, 整个中高纬度地区处在乌拉尔山脊前西北气流控制; 第四类为蒙古高脊型, 95°E到河套东部被蒙古高压脊控制, 从新疆低槽底部有扩散的冷空气影响西北地区。4种天气形势对宁夏日最大风速的影响不同, 其中在第二、三类天气形势下, 宁夏日最大风速≥6 m/s的正样本比例超过60 %, 而在第四类天气形势下不到50 %。可见, 冬半年影响宁夏大风的环流形势以西高东低型和强西北气流型为主。
2.2 改进的KNN方法引用文献[9]改进的KNN方法, 对于不同站点, 采用欧式距离作为相似判据, 根据正负样本数在总体样本中的比例分类求取K值:
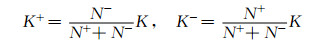
|
(1) |
式 (1) 中, N+为训练样本中的正样本数, N-为训练样本中的负样本数, K+为正样本的K值, K-为负样本的K值。其中负样本代表没有出现的天气事件, 正样本代表出现了天气事件, 它们都来自历史实况资料库。
利用交叉验证的方法, 取一部分样本作为预报测试集, 将剩余部分作为训练样本集, 通过不断的交叉更换预报测试样本, 直到遍历整个样本集为止。将每次预报的结果汇集并进行检验, 得到一组评分结果, 再改变K值, 得到另外一组评分结果, 不断重复, 直到K值试验完毕。
为了使准确率和正样本的概括率都达到相对最好, 既要考虑总体样本的准确率, 又要考虑正样本的概括率和TS评分, 这里为了减少漏报率, 提高预报准确率和正样本的概括率, 用如下K值选择公式:

|
(2) |
式 (2) 中,

|
(3) |
通过L次交叉验证后, 不断调整K+, K-两个值, 反复比较上述预报试验的预报评分结果, 选出准确率和正样本的概括率都达到相对最优的组合作为最终结果。实际预报中, 将某站点实时预报因子, 依据上述确定的KS+, KS-, 从历史样本中选取最邻近域, 用以下预报判别方法得到预报结果:
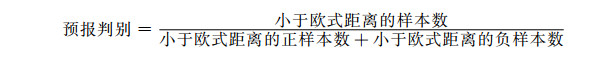
|
(4) |
预报判别值是通过历史资料的试预报结果比较判断给出。制作预报时, 根据式 (4) 计算出的预报判别值大于历史的预报判别值时, 则认为有天气事件发生, 反之无。
2.3 实现改进后的KNN方法步骤改进后的KNN方法具体计算步骤可归纳为: ①对经过质量控制后的历史样本的700 hPa高度距平场 (每个格点值逐一求距平值)、u及v风场进行归一化处理; 运用SOM方法求得4种类型的样本群; 对每种样本群的700 hPa高度场、u及v风场分别合成, 得到4种不同类的典型天气型; ②预报因子归一化, 对聚类分析的每一种天气型的样本群所对应的因子与某站点的预报对象之间求相关系数, 利用逐步回归对因子进行排序筛选, 最终选取10~20个因子作为该站点KNN的预报因子集; ③循环K值 (比如从2~50), 利用式 (1) 分别得到K+, K-; ④在每一次K值试验中, 将模型样本分为与预报测试样本和训练集样本, 通过不断的交叉提取, 计算每个预报测试样本中正负样本的欧式距离, 做出每一个子样本的预报, 将交叉所得的预报结果汇集起来, 而后得出该K+, K-值所对应的预报评分; ⑤最后通过式 (2) 和式 (3) 选出预报评分最优K+, K-值; ⑥对由历史资料确定的K+, K-值, 寻求最邻近域, 利用式 (4) 确定每一种天气型对应预报判别值。
实际预报时, 先判别该日属于何类天气型, 即用该日T213数值预报的24 h, 48 h预报的700 hPa高度距平场、u及v风场与已分型后得到的平均700 hPa高度距平场、u及v风场分别进行比较 (求对应的各格点的欧式距离), 最小欧式距离所对应的天气型应为当日24 h, 48 h预报的天气类型 (24 h, 48 h也可能类型不相同), 再用不同时效这种天气型已确定的K+, K-值, 计算实时预报因子与历史样本对应预报因子的最邻近域, 并以预报判别值为标准, 最后给出预报结论。逐站按此步骤进行, 即得到宁夏全区各站点未来24 h, 48 h有无日最大风速≥6 m/s的预报结论。
3 预报试验评估由于文献[9]通过降水预报已验证:分类交叉验证求取K值较传统KNN方法的预报结果有明显提高。因此本文仅就聚类天气分型对KNN预报的影响, 分别利用不分型和分为4种天气型的KNN方法, 以日最大风速≥6 m/s作为预报对象, 以2003—2006年冬半年的1—5月和10—12月经加工 (如第1章所述) 的T213数值预报产品作为建模样本 (如某日最大风速≥6 m/s, 则该日为正样本), 建立了宁夏24个测站冬半年24 h和48 h日最大风速≥6 m/s的预报模型, 并对2007年1—5月进行了预报试验, 各站评估结果如图 3, 图 4所示。为了对该模型的预报效果有一个总体评价, 同时给出表 1的评估结果。

|
|
| 图 3. 2007年1—5月宁夏各站24h日最大风速≥6 m/s预报的TS评分 (a)、空报率 (b) 和概括率 (c) Fig 3. TS (a), absent forecast quotiety (b), general probability (c) of 24-hour forecast for weather stations with daily maximum velocity≥6m/s from Jan to May in 2007 of Ningxia | |

|
|
| 图 4. 2007年1—5月宁夏各站48 h日最大风速≥6 m/s预报的TS评分 (a)、空报率 (b) 和概括率 (c) Fig 4. TS (a), absent forecast quotiety (b), general probability (c) of 48-hour forecast for weather stations with daily maximum velocity≥6 m/s from Jan to May in 2007 of Ningxia | |
|
|
表 1 2007年1—5月24 h和48 h宁夏日最大风速≥6 m/s预报评估结果 Table 1 Average skills of 24-hour and 48-hour forecast of daily maximum velocity≥6 m/s from Jan to May in 2007 of Ningxia |
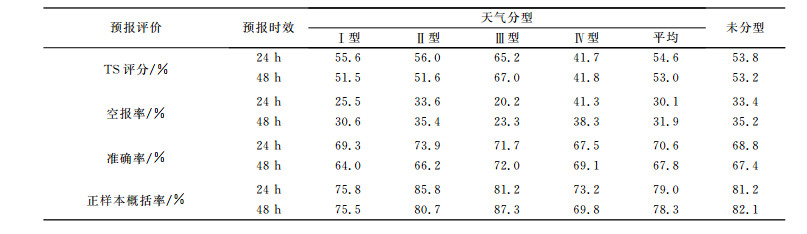
①从总体预报TS评分看, 除第四类天气型, 24 h其他3种天气型的预报效果总体高于未分型, 48 h第三类天气型TS评分超过未分型, 而且无论是24 h或48 h, 第三类天气型都远远高于未分型和其他3种天气型的预报评分; 从单站预报效果看, 除了24 h的泾源和48 h的海原, 其他测站至少有一类天气型的TS评分高于未分型, 其中24 h的六盘山4种天气型的TS评分均高于未分型, 另外除了24 h的银川和泾源及48 h的海原, 其他测站第三类天气型的预报评分都高于未分型。这可能与这些站历史上出现日最大风速≥6 m/s的气候概率有关。
②空报率无论24 h或48 h, 加入SOM聚类天气分型后的KNN总体低于未分型的KNN, 其中第一类天气型低于未分型5 %~8 %, 尤其是第三类天气型空报率低于未分型达12 %~13 %; 单站空报率, 第一类天气型24 h除了银川、麻黄山、隆德和泾源, 其他测站都低于未分型, 第三类天气型除了24 h的陶乐和48 h的麻黄山, 其他测站都低于未分型, 其中六盘山站第一类24 h和第三类48 h的空报率都为0。相比空报率, 漏报率总体上分型高于未分型。从实际预报效果看, 虽然天气分型后漏报次数相对增加导致正样本概括率下降, 但减少了空报次数, 从而提高了预报准确次数, 如第三类天气型总体上24 h漏报率较未分型高1.8 %, 但空报率却下降了13.2 %, 结果是预报准确率较未分型提高了1.4 %。可见, 天气分型后, 总体上降低了空报次数, 有利于预报效果的提高。
③正样本的概括率总体上天气分型后的KNN低于未分型的KNN, 只有24 h的第二类天气型和48 h的第三类天气型高于未分型, 24 h第三类天气型与未分型的概括率基本持平; 单站的概括率24 h第一类有17个测站高于未分型, 48 h第三类有23个测站高于未分型, 其他类天气型的概括率有超过60 %的站低于未分型。
④总体上, 天气分型后预报准确率高于未分型的, 24 h表现得尤为突出。
分析结果可见, 加入SOM聚类天气分型后的KNN方法虽然降低了正样本的概括率, 但克服了预报空报偏多的现象, 总体上提高了预报效果, 尤其是第三类天气型的预报效果较未分型提高更为显著, 说明改进后的KNN预报模型挑选的预报因子总体上能够反映宁夏大风的预报信息。
4 历史样本和预报因子分析本文使用历史样本共921个, 各站正样本 (日最大风速≥6 m/s) 数约占总样本的56 %, 六盘山、麻黄山、石炭井、通信、兴仁正样本比例超过70 %, 其中六盘山达97 %; 青铜峡、贺兰、平罗、西吉、银川达30 %~40 %。对比这些站的TS评分, 正样本大的测站TS评分也高, 反之亦然。天气分型后也有同样情况。可见, 历史正样本的多少对预报模型的建立及预报效果的好坏有至关重要的作用。从历史样本中寻求相似, 这种“相似”也仅仅是相对而言, 如果历史正样本多, 这种相似的可靠性更高, 因而预报的效果会更好; 反之, 历史正样本少, 相似可靠性低, 因而预报效果差。
分析两种预报模型挑选的预报因子, 绝大部分测站预报因子的相关系数不超过0.45, 逐步回归使用的F检验值在0.25左右, 其中未分型选择的预报因子相关系数基本在0.15~0.3之间, 分型后的预报因子相关系数在0.25~0.45之间; 所选的预报因子基本集中在中低层风速、纬向风、经向风、风切变及反映温度、气压梯度等方面, 未分型的预报因子相对分散, 天气分型后的预报因子相对集中, 主要反映与本天气型影响系统物理意义明确的因子。这说明大风的形成既与大气环流背景有关, 又与中小尺度天气系统密切相联, 相对海上大风[17-18], 陆地受地形、地貌的影响很大, 所以天气分型所选的预报因子应能更好地反映这些影响因素, 建立的预报模型更符合当地实际情况。
5 结果与讨论上述分析表明, 同时利用SOM聚类天气分型和交叉验证的KNN方法对宁夏冬半年日最大风速≥6 m/s的预报效果更好。在天气分型的前提下, 针对不同天气环流背景选择的预报因子更有代表性, 物理意义更明确, 也更有助于邻近域的选择和预报模型的建立, 从而提高预报准确率。特别是对前3种类型, 均好于未分型的。而对于西低东高有利于降水的第四种类型, 预报时, 须用其他方法给予进一步关注。值得指出的是, 本文所用历史数据库 (范例库) 容量只有4年921个样本, 分型后, 每种天气型样本数大大减少, 大约是原未分型的四分之一, 这在一定程度上影响了分型的预报效果。对那些正样本多的测站预报效果显著, 如六盘山站; 而正样本相对少的测站预报准确率相对较低, 第四种类型正样本数更少, 预报效果较差, 大概也是这一原因。但大部分测站的预报准确率已基本达到业务预报要求, 如果拥有能反映系统状态变化范围的较长历史数据, 预报准确率将会逐步提高, 因此该预报模型具有业务应用价值。
总体来说, 基于SOM聚类天气分型和交叉验证的KNN近邻非参数估计仿真模型是一种实用的概率天气预报制作方法, 可以根据天气学原理和天气预报经验进行天气分析和预报技术的研制。由于该方法对预报因子和预报量对象均不需加任何限制, 不需有关于模拟过程的先验知识, 仅用足够多的历史数据来建立系统输入和输出之间的内在关系, 因此利用该技术可实现多种要素或天气现象的同时预报。同时该方法原理清晰、计算方便, 随着历史样本数的不断累积, 该方法将取得更好的应用前景。
致谢 感谢中国气象局培训中心曹晓钟老师对本文的指导和修正!| [1] | 陈豫英, 陈晓光, 马金仁, 等. 风的精细化MOS预报方法研究. 气象科学, 2006, 26, (2): 210–216. |
| [2] | 刘还珠, 赵声蓉, 赵翠光, 等. 国家气象中心气象要素的客观预报———MOS系统. 应用气象学报, 2004, 1, (2): 181–191. |
| [3] | 杨忠恩, 陈淑琴, 黄辉. 舟山群岛冬半年灾害性大风的成因与预报. 应用气象学报, 2007, 18, (2): 80–85. |
| [4] | 林良勋, 程正泉, 张兵, 等. 完全预报方法在广东冬半年海面强风业务预报中的应用. 应用气象学报, 2004, 15, (4): 485–490. |
| [5] | 胡波, 杜惠良. 浙江省沿海海面日极大风预报. 海洋预报, 2006, 23, (增刊): 64–67. |
| [6] | Cover T M, Hart P E, Nearest neighbor pattern classification. IEEE Trans on Inf Theory, 1967, (IT-13): 21–27. |
| [7] | 翟宇梅, 赵瑞星. 概率天气预报的K近邻非参数估计仿真模型. 系统仿真学报, 2005, 17, (4): 786–788. |
| [8] | 邵明轩, 刘还珠, 窦以文. 用非参数估计技术预报风的研究. 应用气象学报, 2006, 17, (增刊): 125–129. |
| [9] | 曾晓青, 邵明轩, 王式功, 等. 基于交叉验证技术的KNN方法在降水预报中的试验. 应用气象学报, 2008, 19, (4): 471–478. |
| [10] | Kohonen T, Self-organizing Maps. Berlin: Springer-Verlag, 1998: 1-6. |
| [11] | 许文杰, 刘希玉. 基于无监督神经网络聚类算法的研究. 信息技术和信息化, 2006, (6): 85–88. |
| [12] | 孙世霞, 杨建池, 邱晓刚, 等. 基于BP网络的LSCS仿真可信性评估方法. 系统仿真学报, 2006, 18, (7): 2037–2041. |
| [13] | 王青, 祝世虎, 董朝阳. 自学习智能决策支持系统. 系统仿真学报, 2006, 18, (4): 924–926. |
| [14] | 夏文文, 王士同. 基于Voronoi距离的鲁棒的双自组织特征映射网络. 计算机应用, 2007, 27, (5): 1109–1112. |
| [15] | 刘还珠, 郝为, 林孔元, 等.基于智能计算的多模型气象综合预报∥刘还珠, 汤桂生.暴雨落区预报实用方法.北京:气象出版社, 2000:30-37. |
| [16] | 黄卓, 杨洪敏, 郝为, 等.基于智能聚类的综合相似预报∥刘还珠, 汤桂生.暴雨落区预报实用方法.北京:气象出版社, 2000: 53-59. |
| [17] | 廖木星. 海面风场预报的技术研究报告. 青岛远洋船员学院学报, 2003, 24, (2): 6–10. |
| [18] | 颜梅, 范宝东, 满柯, 等. 黄渤海大风的客观相似预报. 气象科技, 2004, 32, (6): 467–470. |