 2008, 19 (3): 307-314
2008, 19 (3): 307-314


2. 中国科学院大气物理研究所, 北京 100029;
3. 中国华阴兵器试验中心, 华阴 714200;
4. 解放军理工大学气象学院大气科学系, 南京 211101
2. Institute of Atmospheric Physics, Chinese Academy of Sciences, Beijing 100029;
3. Chinese Huayin Ordnance Test Center, Huayin 714200;
4. Department of Atmospheric Sciences, Institute of Meteorology, PLA University of Science and Technology, Nanjing 211101
暴雨是我国的主要自然灾害之一, 气象工作者利用包括数值预报[1-3]在内的各种方法研究其机理, 并对暴雨已经形成了一套较为完善的认识体系[4-7]。在天气预报技术方面, 也形成了相对成熟的包括暴雨在内的关于各类天气现象的众多预报方法技术[8-10]。近年来, 不少学者在相似预报领域进行了很多理论和业务上的探索[8, 11-16]。金荣花等[12]引入地转西风动量经向输送和经向温度梯度诊断量以及对流层中、低层500 hPa高度和850 hPa温度的大尺度环流背景场, 研制了双层多因子长江中下游旱涝中期预报模型。邵明轩等[13]设计了一种根据过程相似性从近邻子集中挑选最佳样本的方法, 完成了用K近邻非参数估计技术制作风预报的试验。张延亭等[14]利用相似系数和相关特征量作参数, 以预报拟合率为判据, 通过逐个引进因子场的方法组建出最优相似预报方程, 制作客观要素预报。
分析目前的相似方法研究, 在相似样本描述方面, 大多采用单因子求相似判据, 最终描述样本相似程度的标准还是单因子。是否可以采用因子组合来计算相似判据对样本进行综合相似描述是本文工作的突破口。包括相似方法在内的这些预报手段可以得到基本结论, 但其预报准确率不够理想, 空报率和漏报率不能达到很好的一致。因此, 本文以暴雨为研究对象, 试图探索出一种更加创新的预报技术, 以弥补这些不足。文章在对某一预报区内不同型的暴雨天气进行相似预报试验的基础上, 研制出一种新的综合多级相似预报技术。
1 新技术试验与模型建立以某一区域未来24 h暴雨的落区、落点、落时和雨量的相似试验为例, 以12 h为单元, 将1 d分为0~12 h和12~24 h两个预报时段, 分别对应08:00 (北京时, 下同) 和20:00两个起报时次, 介绍综合多级相似技术的试验方案、具体流程和结果。
1.1 资料的准备与选取 1.1.1 模式介绍及资料的采集、准备和初步质量控制本文采用国家气象中心1990—2002年逐日探空资料, 每日两个时次, 08:00和20:00, 将其作为最基本资料, 对这些原始报文资料进行解报, 然后对解报出的资料做客观分析, 利用最小二乘法思想, 将其插值到规定的网格点, 并对格点资料做初步的质量检验和控制[17], 将其作为本文做相似预报试验的资料。
在处理资料及研究过程中, 采用最初由Anthes等提出[18], 并由PSU/NCAR发展的最新版本的中尺度非静力模式MM5。本文有限区域数值模式网格分配方案: x方向81个格点, y方向61个格点, 中心网格点为30°N, 115°E, 垂直方向为11层, 水平分辨率为45 km, 对于区域性暴雨, 该分辨率可以满足捕捉暴雨过程的要求。
同时在第三级预报中将该模式积分若干小时后的资料作为一级产品[19]进行试验, 完成动力过程的相似描述。
1.1.2 资料的选取、分配方案试验样本库资料:选用1990—1999年资料进行试验, 建立、调试预报模型。独立样本库资料:选用2000—2002年资料进行试报。统计分析试报指数, 初步检验模型的预报能力, 并进行修正。
1.1.3 客观分析方法迄今为止, 不少学者作过客观分析理论和应用方面的研究[20-23], 给本文的客观分析工作提供了参考和指导。王跃山[22]从理论上分析了多项式插值法、逐步订正法、最优插值法的数学原理及其优缺点、应用价值。李建通等[23]通过对要素场相关函数和校准雨量站的分布对最优插值中最优权重系数影响问题的研究, 利用3种相关函数模型对113个时次的雷达和雨量计资料进行计算、检验, 较好解决了利用最优插值法提高区域降水量精度的问题。理论上, 根据大量统计资料建立的气象场统计结构和观测误差, 决定出最小二乘法意义上的最佳权重, 使得分析误差在统计意义上达到最小, 这就是包含最小二乘法思想的最优插值法。
1.2 预报区域选取以及天气形势分型预报区范围为我国浙江省东南沿海 (简称浙东南) 区域, 地理范围为25°~31°N, 118°~124°E。根据当地小气候特征制定相应标准 (如台风型标准为:台风中心位于20°~30°N, 128°E以西附近, 且未来有西移趋向), 将发生暴雨的天气形势按冷锋型、台风型、准静止锋型、气旋型、倒槽型等情况进行分型, 统计分析1990—2002年暴雨季期间出现暴雨以及未出现暴雨的各型天气的历史样本。统计以当日08:00和20:00地面天气图上的形势场为依据, 当日出现暴雨是指在预报区内有1站出现暴雨。
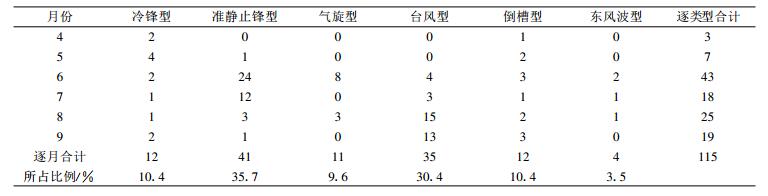
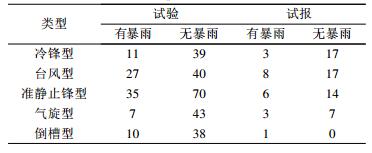
表 1给出了1990—2001年各类型天气发生暴雨的统计结果, 由此可分析出预报区内暴雨的分布特征 (预报区内暴雨年际、月际分布图略)。区域性暴雨平均每年出现11次, 其中2000年出现15次, 为最多年份; 1992年、1996年、2001年都只出现了9次, 为最少年份。区域性暴雨主要出现在6—9月, 其中6月出现次数最多, 共43次, 出现频率为2.75次/月; 最少是2月, 没有出现; 其次是1月和12月, 仅出现了1次。台风型暴雨和准静止锋型暴雨是该地区常见的暴雨形式, 所占比率都超过30%。因此本文研究时段选为每年的4—9月。
|
|
表 1 1990—2001年4—9月预报区域内暴雨类型统计表 Table 1 The rainstorm distribution in the forecast range from April to September during 1990—2001 |
1.3 相似判据及其计算问题 1.3.1 相似判据的选取
相似判据包括:互相关系数判据、海明距离、欧氏距离、距离系数、域块距离、相似度、高分辨相似系数等。经过对比试验, 文章选取相似离度作为相似判据, 并且将相似离度拓展为多格点、多因子的相似判据, 有利于从整体上描述相似。
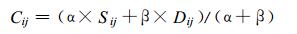
|
(1) |
其中
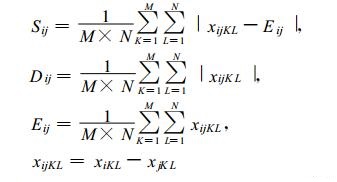
|
式 (1) 中, M为所计算的相似场的格点数 (或测站数), N为因子数, 对应的K, L分别为格点、因子序号。Cij为第i、第j两个样本的相似离度, N=1时, 为单因子相似, 否则为多因子相似离度。x为相似因子。Eij为第i样本对第j样本中所有因子和格点之间的总平均差值。Dij为值系数, 反映了样本之间在总平均数值上的差异程度; Sij为形系数, 反映了两个样本中的各个因子和格点之间的差值xijKL对Eij的离散程度。α, β分别为它们对总相似程度的贡献系数。
1.3.2 相似判据计算前数据资料的标准化基于不同因子量级的差异, 考虑到因子之间可比性的要求, 在相似判据计算之前需要对数据因子资料进行标准化处理, 公式如下:
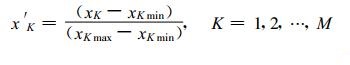
|
(2) |
式 (2) 中, K表示格点数, xK为样本的原因子数据, x′K为标准化后对应的因子数值, xKmax, xKmin分别为所有历史样本中原因子数据的最大和最小值。
1.4 预报模型的分型、分级及合成 1.4.1 单类型、单级别相似预报试验方案①方案细则
以某一类型的暴雨为研究对象, 假设该类天气过程在10年历史个例中发生过M次暴雨, 记K为M次暴雨天气的序号, 同时选取N次未发生暴雨的该类天气个例。该类暴雨有p1种相似因子组合方案和p2种相似区域方案, 记L1, L2分别为因子组合方案和区域方案序号。
相似因子的选择:假定相似区域方案L2不变。对于相似因子组合方案L1, 以M次暴雨样本中的第K个个例为一个标准。对于10年该类型暴雨的历史样本而言, 此时还余 (M+N-1) 个个例, 将这些个例逐一与标准个例求相似离度, 此时算出 (M+N-1) 个相似离度, 其中必有 (M-1) 个相似离度反应的是暴雨样本之间的相似情况, 从中挑出最大值作为临界相似离度 (记为CT), 反映出现暴雨个例中与标准个例最不相似的情况。以CT为标准, 如果待报当日与标准个例的相似离度不低于CT, 预报该日出现暴雨; 否则不出现暴雨。(M+N-1) 个相似离度中有N个相似离度反应的是未出现暴雨样本与 (暴雨) 标准样本之间的相似情况。将这N个相似离度分别与CT进行比较, 记J为其中不低于CT的样本个数, 可以计算空报率为: J/N。空报率、CT是随着相似因子组合方案、相似区域方案、标准样本而变化。标准样本的循环和平均空报率的计算:逐一以M个出现暴雨的样本为标准, 分别计算其在不同标准样本下的CT和空报率 (共计M对), 然后计算此种因子方案的平均空报率 (记为aF)。
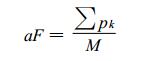
|
(3) |
式 (3) 中, pk表示任意标准样本的空报率。以此表示此种因子组合优劣的一个综合指标:平均空报率越大, 此种因子组合方案越差, 反之该种因子方案越好。相似因子组合方案的循环:按上述方法循环计算各因子组合对应的平均空报率 (共计p1个), 从中选出平均空报率最小值, 其对应的因子组合为最终选取的最佳因子组合方案。
相似区域的选择:将相似区域方案L2从1变化到p2。前面已经选定了最佳因子组合, 同样用循环方法求出在最佳因子组合下不同相似区域的平均空报率 (共计p2个), 反映了相似区域方案的优劣性。从中选出平均空报率最小值, 其对应的相似区域作为本级的最佳相似区域 (即关键区)。
标准样本的选择:对M次本型历史上的暴雨分别计算其在最佳相似区域、最佳相似因子组合下的空报率。将其中空报率最小的一次暴雨过程作为该级预报 (在预报本型暴雨天气时) 的最终标准样本, 有其对应的CT和空报率。将这些作为本级预报的最终相似参数 (最佳因子组合、空报率、最佳标准样本、CT、关键区)。
②单级预报结果判定
求取预报日样本与标准样本在最佳因子组合、关键区中的相似离度, 如果高于CT, 则该级相似预报报该日在预报区内无暴雨天气; 否则预报该日在预报区内出现暴雨天气。
③试验顺序设计
本文最终给出的方案中先固定区域得到最佳因子组合, 然后在变化区域中得到关键区。
本技术的研制过程, 有3个方面需要考虑:因子组合的变化与选取; 相似区域的变化与选取; 相似样本的变化与选取。同时需要考虑各项确定的先后次序, 无论先确定哪一项, 其他项的选取都受影响。问题的关键在于, 能否找到与预报当日天气过程最为相似的历史样本个例。所以在其他项的选取中, 引入平均空报率概念, 综合衡量其他项对于所有标准样本的平均贡献, 从中选取最优项。这样, 相似样本被设计到了最后一个进行最优选取, 而因子组合和相似区域的选取是首先要解决的问题。对此进行的试验表明, 因子组合对试验的贡献要远大于相似区域。从权重贡献角度考虑, 在设计试验时, 首先固定的是相似区域。其次, 从天气学概念中也可以知道, 某一天气事件之所以区别于其他天气事件, 主要是物理属性 (物理因子) 的不同, 其次才是地理属性 (地理区域) 的不同, 即其受物理因子变化的影响相对要大。
1.4.2 综合、多级别预报模型的建立①三级预报及结果输出
以某类型暴雨在10年历史中发生的M次暴雨和N次未发生暴雨的该类天气个例为对象, 通过试验方案建立模型。
对暴雨发生发展物理机制的认识日趋成熟, 在此基础上, 结合当地预报业务实践, 初步给出三级预报待选因子, 并进行因子筛选和试验。第一级初选因子要求能够反映样本之间各种综合形势场的相似情况, 是暴雨酝酿的背景场; 第二级初选因子要求能反映暴雨发生发展情况, 是暴雨的局地触发机制。在本级相似中, 由于是中尺度范畴, 相似判据也可以选用域块距离。按各物理量分别计算, 然后综合起来制作相似预报。这里不再详细描述。第三级试验采用动力释用方法, 利用模式积分若干小时之后的产品计算一批因子 (相对于模式直接积分而言, 经过计算后产生的相似因子为二级产品, 以3 h为最基本的间隔单元, 这些是初选出的反映系统发展、变化的动力过程相似情况的因子), 通过极值剔除法对二级产品进行筛选, 最终选取3×n (n取自然数) 时间步长的相似因子, 利用这些因子求取相似判据。
如果预报了当日有暴雨出现 (暴雨落区的判定), 接下来相似预报要进一步解决在预报区当中暴雨落点、落时、雨量 (暴雨级别) 等项的预报问题。通过一级相似, 从M个历史样本中选2个最佳相似个例, 通过二级相似, 从M个标准样本中选2个最佳相似个例, 通过三级相似, 从M个标准样本中选2个最佳相似个例。这时, 总共获得6个最佳相似个例。读出预报区所属测站对应日期的降水状况。暴雨落点:某预报测站在6次相似个例中有半数以上 (含半数) 出现暴雨, 就计该预报站有暴雨。并规定:相邻3个以上站 (含3个) 出现暴雨的为区域性暴雨, 相邻8个以上站 (含8个) 出现暴雨的为大范围暴雨; 暴雨落时:在暴雨预报日中, 暴雨出现时段按前12 h (第1时段) 和后12 h (第2时段) 分为两个时段。在6次相似历史个例中, 取出现暴雨频率大的时段为该预报站的暴雨出现时段; 暴雨雨量:一般来说, 在我国东部地区, 暴雨雨量 (R) 按50 mm≤R < 100 mm, 100 mm≤R < 200 mm, 200 mm≤R可依次分为3个量级:暴雨、大暴雨、特大暴雨。在6次相似历史个例中, 取出现暴雨级别频率最大的为该预报站的暴雨级别。
②双重滚动预报
分别用每日08:00和20:00的探空资料制作相似预报, 最终进行滚动预报, 有利于双重捕捉暴雨信息, 提高准确率。若是输入08:00的资料, 09:30—10:00可以收到并处理80%以上资料, 基本满足模型起转需求。预报时间界定为当日08:00—次日08:00;若输入20:00的资料, 21:30—22:00可以收到并处理80%以上资料, 基本满足模型起转需求, 预报时间界定:当日20:00—次日20:00。滚动预报互补了两次预报空缺时间段 (08:00预报填补了20:00—22:00时段; 20:00预报填补了08:00—10:00时段) 的预报问题。
1.4.3 有关相似因子和相似区域组合方案的补充说明在一级相似的因子组合方案中, 各类型的待选因子及其组合方案的取法一致 (共有58种方案, 表略)。在二级和三级试验时, 根据不同类型的暴雨天气及局地气候特征的差异性, 需要调节参与试验的因子及其组合方案。同时, 各级参选的相似区域方案也不相同。
1.5 预报模型的性能检验、修订、系统调试已有多种性能指标可以衡量预报方法的优劣性、测试预报水平, 并且在实践中取得了较好的效果。文章采用的性能指标包括:预报成功指数 (CSI)、预报正确率 (COR)、空报率 (FAR)、漏报率 (POD)。根据资料的选取、分配方案, 在模型建立前, 利用试验样本库资料 (样本个例M+N) 进行回报检验, 完善模型。在模型建立后, 利用独立样本库资料 (样本个例M2+N2) 进行试报检验, 调试模型。
调试方法包括调整各级相似参数中的CT值、调整各级的相似因子、相似区域、调整相似判据中的贡献系数。调试完毕, 需更改相关的相似参数, 重新统计各项回报、试报性能指标, 作为模型最终参数指标。
2 综合多级相似技术 2.1 综合多级相似方法的含义及特征综合是指多种气象要素、物理因子场描述相似的结合、大尺度和中尺度天气条件的结合、静态模拟与动力过程模拟的结合。多级是指三级相似分别考虑到3种不同的侧面和角度以及它们之间的相耦合性———用基本气象要素来反映大的环流形势场 (大尺度) 的相似、用特征物理因子来反映局地小气候特征 (中小尺度) 的相似、用3×n时间步长的二次产品来反映系统动力过程的相似。
该技术采用相似预报因子的组合与优化技术:互补利用各因子间在描述相似时的可用性, 避免因子间的重复性; 采用减空法技术选取关键区和相似因子:在历史资料回报试验漏报数为零的前提下, 尽量降低空报率。
2.2 系统的预报流程进入相似预报流程之前, 先对待报个例进行入型判别。一般地, 预报员对天气形势的认识比较一致。通过人机对话方式, 系统利用预报员的经验优势进行排空处理, 由预报员将待报日天气实况进行大尺度天气形势分型。确定其所属的大类型之后, 以预报当日样本进入所属类型的相似预报流程进行预报。由前两级相似试验给出初步预报结果, 引入第三级预报进行模式修正。前两级相似都报预报当日出现暴雨, 则认为该日预报区里出现暴雨; 否则认为不出现暴雨。引入第三级试验后的修订预报:两级或两级以上试验预报有暴雨, 该预报日预报区有暴雨, 按规定输出该日的预报结论 (暴雨落点、落时、雨量); 否则认为预报区内没有暴雨发生, 退出预报系统。预报模型的具体流程参见图 1。

|
|
| 图 1. 相似预报流程图 Fig 1. The whole procession press of analog forecast | |
3 试验方案设计及结果 3.1 试验方案介绍
表 2给出5种类型暴雨参加试验的资料样本库情况。统计工作中样本数量至少保持在50个以上才有可靠性。从表中可知, 各种类型的样本库资料在试验时都能保持50例以上, 试报阶段也有相当的样本容量。由于倒槽型过程属于当地少见气象情况, 其样本数稀少, 试报阶段以2000年6月19日1例样本做检测样本。
|
|
表 2 各种类型暴雨参加试验与试报情况统计 Table 2 The trial and test informations of various pattern rainstorm |
3.2 结果分析
图 2、图 3给出了不同类型暴雨试验的基本情况。每一种模型的CSI历史拟合值都在0.40~0.60之间, 试报CSI平均值为0.37。同时其他指标也能保持在一个理想的范围内。

|
|
| 图 2. 暴雨相似预报试验的历史拟合 (两级预报) Fig 2. The historical test indexes of rainstorm trial (the 1st and 2nd procession) | |

|
|
| 图 3. 暴雨相似预报试验的试报统计 (两级预报) Fig 3. The indexes of rainstorm model test trial (the 1st and 2nd procession) | |
引入第三级相似, 利用数值产品作修订预报, 比两级预报效果更好 (图 4)。前两级预报的思想在于宁空勿漏, 虽然漏报率很低, 但带来了空报率偏高的弊端。通过第三级预报的修订, 降低了空报率, 同时又提高了CSI等指标。

|
|
| 图 4. 相似预报试验中两级预报和三级预报的效果对比 (准静止锋型暴雨试验) Fig 4. The indexes contrast between double forecast and thrice forecast (quasi-stationary front pattern) | |
从预报结果看, 各项性能指标在历史拟合 (回报) 时都比较理想。试报时, 性能指标呈普遍下降趋势: CSI值和COR值降低, FAR值增加, 且出现了漏报现象。从天气的可预测与不可预测的辩证性上看, 这种现象是正常的。
可以通过修正、调试对相似预报进行完善, 克服指标性能普通下降的不足。图 5中显示了3种调试方案, CSI值、COR值得到提高, FAR值也有所下降, 第3种方案将漏报率降为0。总体来讲, 对模型的修正是成功的。

|
|
| 图 5. 修正、调试效果 (台风型暴雨) Fig 5. The revising and adjusting effect (typhoon pattern) | |
与他人所作工作比较 (CSI在0.35左右), 本文采用综合多级相似技术作各种天气形势的暴雨预报试验研究, 修正后预报模型的平均CSI为0.392, 提高了4%。同时, 从图 6可知 (SMAT代表综合多级相似技术, REF代表预报员预报, LAFS代表中国数值预报, JMA代表日本数值预报), 相比之下, 就模型的准确率、漏报率而言, 该模型也有优势。只是在空报率上, 没有体现出明显优势。总体而言, 综合多级相似技术具有较强的平均预报能力。

|
|
| 图 6. 各种预报方法对比 Fig 6. The effect contrast of various forecast methods | |
4 结论与讨论
1) 通过对包括冷锋型、台风型、准静止锋型、气旋型、倒槽型等在内的不同型暴雨天气的相似预报方法试验, 其中包括08:00起报和20:00起报两种情形, 可以验证本预报技术的准确率、空报率及漏报率都比较理想。试验结果表明:在确保较高准确率的同时, 空报率和漏报率均被控制在低值范围和理想状态。
2) 综合多级相似技术采用减空法对因子进行筛选, 对预报条件进行组合优化, 采用多种气象要素和多种物理因子场的综合进行各级的相似试验和预报, 这比前人普遍采用的单因子求相似离度和分级试验更进一步, 提出相似判据在描述样本之间相似程度时随相似因子、相似区域不同而有较大差异的思想, 并采取如下办法解决这个技术难题:在因子筛选过程中采用因子组合的方法, 全面考虑各种优势因子及其组合, 对描述样本之间的相似程度发挥了较好的作用; 关键区的选取方面事先也给出多种可能的关键区域备选方案, 通过试验最终确定各级相似的关键区。通过每日两个时次的滚动预报来降低漏报现象, 双重捕捉暴雨过程, 对于灾害性天气起到了较好的预测预警作用。
由于本研究所获得的资料有限, 难以构成完整的时间序列, 可在资料更加丰富后对相似预报进行深入的试验研究工作。在今后工作中, 将非常规资料 (雷达、卫星云图等) 以及更详尽的数值产品资料引入预报模型中来进行同化应用, 全面完成第三级相似过程, 对前两级预报进行修订, 以期望达到更好的业务预报效果。
致谢: 本文得到中国人民解放军92919部队夏秋萍高级工程师、解放军理工大学寇正博士、程艳红博士、康健伟博士、裴蕾硕士的帮助, 谨在此表示感谢。| [1] | Liu Yubao, Zhang Dalin, Yau M K, A multiscale numerical study of hurricane Andrew (1992). Part Ⅰ: Explicit simulation and verification. Mon Wea Rev, 1997, 12: 3073–3093. |
| [2] | 张曼, 王昂生, 季仲贞, 等. 不同降水方案对"03.7"一次暴雨过程模拟的影响. 大气科学, 2006, 30, (2): 327–340. |
| [3] | 隆宵, 程麟生, 文莉娟. . "02.6"梅雨期一次暴雨β中尺度系统结构和演化的数值模拟研究. 大气科学, 2006, 30, (2): 327–340. |
| [4] | 倪允琪, 周秀骥, 张人禾, 等. 我国南方暴雨的试验与研究. 应用气象学报, 2006, 17, (6): 690–704. |
| [5] | 鲍名, 黄荣辉. 近40年我国暴雨的年代际变化特征. 大气科学, 2006, 30, (6): 1057–1068. |
| [6] | 陈红, 赵思雄. 海峡两岸及邻近地区暴雨试验期间 (HUAMEX) 暴雨过程及环流特征研究. 大气科学, 2004, 28, (1): 32–47. |
| [7] | 张小玲, 陶诗言, 张顺利. 梅雨锋上的三类暴雨. 大气科学, 2004, 28, (2): 187–205. |
| [8] | 孔玉寿, 章东华. 现代天气预报技术. 北京: 气象出版社, 2000: 52-72. |
| [9] | 盛飞. 集成预报技术研究. 南京: 解放军理工大学大气科学系, 2003. |
| [10] | 王莉, 黄嘉佑. Kalman滤波的试验应用研究. 应用气象学报, 1999, 10, (3): 276–283. |
| [11] | 晁淑懿, 金荣花. 一种综合相似中期预报模型. 应用气象学报, 1996, 7, (3): 300–307. |
| [12] | 金荣花, 李月安, 晁淑懿, 等. 长江中下游旱涝中期预报方法及其业务应用. 气象, 2004, 30, (12): 47–52. |
| [13] | 邵明轩, 刘还珠, 窦以文. 用非参数估计技术预报风的研究. 应用气象学报, 2006, 17, (增刊): 125–129. |
| [14] | 张延亭, 单九生. 逐步引进因子场作相似预报. 气象, 2000, 26, (3): 22–27. |
| [15] | 张丰启, 崔晶, 王仁胜. 相似离度在入型判别和定时、定点、定量预报中的应用. 气象, 2002, 28, (9): 44–48. |
| [16] | 彭京备, 陈烈庭, 张庆云. 多因子多尺度合成中国夏季降水预测模型及预报试验. 大气科学, 2006, 30, (4): 596–608. |
| [17] | 刘小宁, 鞠晓慧, 范邵华. 空间回归检验方法在气象资料质量检验中的应用. 应用气象学报, 2006, 17, (1): 37–44. |
| [18] | Anthes R A, Warner T T, Development of hydrodynamics models suitable for air polloution and mesometeorological studies. Mon Wea Rev, 1978, 106: 1045–1078. DOI:10.1175/1520-0493(1978)106<1045:DOHMSF>2.0.CO;2 |
| [19] | 张立祥, 陈立强, 刘文明, 等. 东北区夏季月降水数值产品释用预报方法. 应用气象学报, 2000, 11, (3): 348–355. |
| [20] | Cressman G P, An operational objective analysis system. Mon Wea Rev, 1959, 87: 367–374. DOI:10.1175/1520-0493(1959)087<0367:AOOAS>2.0.CO;2 |
| [21] | Jimy Dudhia, Dave Gill, Kevin Manning, et al. PSU/NCAR Mesoscale Modeling System Tutorial Class Notes and User's Guide: MM5 Modeling System Version 3.2005. |
| [22] | 王跃山. 客观分析和四维同化 (Ⅱ) 客观分析的主要方法. 气象科技, 2001, 29, (1): 1–9. |
| [23] | 李建通, 杨维生, 郭林, 等. 提高最优插值法测量区域降水量精度的探讨. 大气科学, 2000, 24, (2): 263–270. |