 2008, 19 (2): 243-249
2008, 19 (2): 243-249


2. 国家气象信息中心, 北京 100081
2. National Meteorological Information Center, Beijing 100081
数值预报是现代天气预报、气候预测业务和气象科学研究的重要手段, 以数值预报理论为基础的气象、气候计算机模拟在近几年得到迅速发展。随着模式分辨率的提高, 模式算法的不断改进以及新型资料的应用, 应用程序需要处理的数据量迅速增长, 这些都对高性能计算机中的文件系统提出更高的要求。
高性能计算机系统在近20年, 尤其是近10年的时间里有迅猛发展, 而集群系统已经成为近年来高性能计算领域的主流趋势。表 1列出了到目前为止top500网站公布的最新世界超级计算机排名[1]。从表 1可以看出, 当今最快的计算机系统中CPU的数量基本上都在10000个以上, 而第一位包含超过13万个处理器, 前10位的超级计算机全部为多节点组成的集群计算机系统, 通常都配置了内部全局共享的文件系统。
|
|
表 1 2006年11月top500前10位系统所采用的集群文件系统 Table 1 Cluster filesystem adopted for the top 10 super-computers in the top500 list in Nov, 2006 |
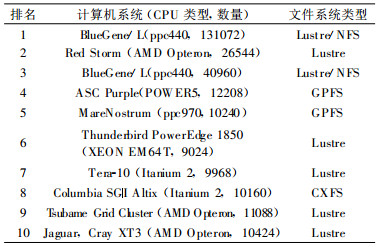
在集群系统中运行的大多是并行作业, 这些应用的实际性能在很大程度上取决于并行文件系统运行效率和性能。高性能计算产生数据量的迅速增长, 尤其是集群内以及多个集群之间高速数据访问和共享, 都对并行文件系统的设计和实现提出了巨大的挑战。从美国的三大国家实验室 (The TriLabs:Los Alamos, Livermore, Sandia) 到欧洲粒子物理研究所 (CERN) 对数据存储需求的趋势可以看出, 大型数据中心都希望未来的文件系统既能支持超大规模的在线数据存储 (1~103PB), 同时又能具备极高的I/O性能 (1~101GB/s, 甚至102GB/s)。目前, 在集群系统环境中存在着多种共享/并行文件系统技术, 例如NFS, PVFS[2], OpenGFS或GFS, Lustre, GPFS[3], CXFS[4]等, 其中, Lustre是近几年来在大型集群环境中应用最为广泛的并行文件系统。如表 1所示, 在目前最快的前10名计算机系统中, 有7个采用了Lustre, 而且包括排名前3位的系统。这些集群系统中应用包括核武器相关模拟[5]和与之相关的分子动力学模拟[6]以及其他工程物理模拟及高分辨率可视化等, 均为非常关键的应用。因此, 可以说Lustre在高性能计算领域已经逐步走向成熟。
1 Lustre的发展和应用Lustre是一个开放源代码的并行分布式文件系统[7], 其发展最早可以追溯到20世纪80年代对象存储 (Object Storage) 概念的提出[8]。以此原理为基础, 在Carnegie Mellon University (CMU) 首先实现了一个早期的规模较大的文件系统, 这是CMU的NASD (Network Attached Secure Disks) 项目的一部分。NASD主要将文件系统体系结构中的数据块分配功能抽象出来, 为系统软件提供一个基于对象存储 (Object-based Storage) 的抽象访问层。基于对象存储是实现Lustre文件系统的重要原理之一。1999年, Lustre项目在CMU启动, 最初目的是建立一个基于对象的文件系统 (Object-based File System), 同时要在整个集群范围内实现UNIX兼容的语义, 但随后又在此基础上发展了一系列新的功能。原型版本的Lustre可以运行在内核为2.4的Linux平台上, 并以开放源代码的形式在Internet上共享。2000年, 在“美国三大国家实验室”等机构对高可扩展性文件系统需求的影响下, Lustre在文件系统功能, 可靠性, 可扩展性, 高性能, 安全性等方面做了进一步的改进, 这些改进也不断在新的高性能计算机系统中得到采用。
Lustre目前可下载最新稳定版本为1.4.9/1.6.2(Lustre有2套版本并行开发), 在稳定性和可用性方面有了很多改进, 在安装规模和性能方面也有一定的提高。从最近的测试 (2004—2005年) 情况来看[9], 单一客户端文件访问性能可达2.0 GB/s, 文件系统聚合性能达到130.0 GB/s。最大规模配置中, 可支持客户端数量为25000。
2 Lustre文件系统的组成和原理Lustre文件系统中最重要的组成部分有3个, 分别是Metadata Server (MDS), Lustre Client和Lustre Object Storage Target (OST), 如图 1所示。

MDS主要功能是负责Metadata (元数据) 的管理。元数据指文件系统中文件和目录的属性及其他相关信息, 包括文件和目录创建或访问时间、状态信息、真实数据的分布和地址、其他文件系统的挂接点信息、符号链接文件的信息等。通常, 在本地文件系统中, 文件的元数据和真实数据本身都直接存放在本地存储设备上, 例如与系统直接相连的硬盘系统。而Lustre文件系统的设计是将元数据和真实数据分开存储, 即元数据存储在一组MDS (元数据服务器) 上, 而真实数据存储在独立的一组OST (对象存储服务器) 上。MDS可以为单一服务器, 一主一备的双机系统, 也可以是多机组成的MDS集群 (当前未实现)。MDS集群一方面可以实现高可靠性, 也可以提供可扩展的Metadata访问性能。
OST将真实数据以对象的方式存储在OST后端的物理存储设备上, 这里的对象可以是文件, 跨越多个OST的文件条带 (Stripes) 或文件的多个扩展单元 (Extents), 还可以是其他某种形式。文件在MDS中被看作是容器对象, 而在OST中则以连续的对象被管理。OST所提供的接口服务包括数据块分配、加锁管理、并行I/O、存储网络中的优化以及存储策略管理等。
在集群系统中, Lustre Client通常安装在计算节点中, 通过这一客户端软件与LDAP Server (LDAP, 即Lightweight Directory Access Protocol, 轻量级目录访问协议)、MDS及OST进行数据通信, 如图 2所示。应用程序访问文件时, 首先向MDS发出访问请求, MDS根据收到请求的具体信息, 进行相关的元数据操作, 包括文件或目录的查找、创建、更新等属性的修改, 并以交易处理的方式实现元数据操作的一致性。MDS对客户端请求处理完毕以后, 立刻通知客户端应用, 同时, 对真正的数据I/O操作进行引导, 使客户端应用直接与OST进行通信, OST把来自于客户端的I/O操作和数据转发给后台的Object-based Disks (OBD), OBD是真正的物理存储设备。所有Lustre Client节点透过Lustre客户端软件看到的是一个统一POSIX (Portable Operating System Interface for uniX) 兼容的VFS (Virtual File System) 文件系统, Client应用通过POSIX接口直接访问VFS, 存取文件的方式与使用传统的本地文件系统基本相同。

Lustre的网络体系结构。Lustre目前能够支持大多数开放的高性能网络互联设备[9], 例如传统以太网 (TCP Networks), Quadrics Elan 3/4, 从2004年底的1.4版本开始, Lustre提供对Infiniband的支持, 另外还支持在同一个节点中配置多个网络适配器。此外, 在一个完整的Lustre环境中, 可以包含混合的网络类型 (如图 1所示)。在多个Lustre Client组成的集群中, 可以有一部分使用Quadrics网络与MDS及OST相连, 而另一部分使用千兆以太网, 客户端应用可以访问任意一组OST中的数据, 这是通过Lustre中的Portals Routers (门户路由) 来实现的, Router负责在不同的网络之间对Lustre中的协议进行路由转发。
Lustre是具有高度可扩展性的并行文件系统, 支持多个客户应用对文件数据的并发访问。为了避免并发存取数据带来的潜在的数据访问冲突, 保证高性能并发访问时数据的一致性, Lustre借鉴了成熟的VAX集群中的相关技术[10], 采用类似的分布式锁机制 (Distributed Locking), 在MDS Cluster的节点间以及OST组成的集群内通过加锁语义保证并发数据访问时文件系统的一致性。MDS Cluster内部的通信依赖于一个紧耦合的文件系统, 对元数据并发访问的服务通过分布式加锁机制进行协调; 而在OST集群中, 文件加锁分布在所有的OST中, 每个OST管理在本地保存的对象加锁。
3 对象存储Lustre是一个高性能的并行文件系统, 既能够提供很高的单一客户端性能, 也具有很高的总体聚合性能。这一方面是因为Lustre采用了Metadata与File Data分离的体系结构, 但更主要的应归功于对象存储 (Object Storage) 的概念、发展和应用。
对象存储采用中间层次共享数据方式。目前市场中常见的存储系统连接方式有直连存储设备 (DAS)、网络附加存储 (NAS) 和存储域网的存储系统 (SAN)。在高性能计算环境中, 需要为集群中的计算节点共享数据, 因此通常不采用DAS; NAS或NFS提供了文件级别的高层次的访问共享, 这种共享通用性较好, 但不能为高性能集群所需要的高带宽; SAN存储系统可在较低层次的数据块级别进行数据共享, 能够为计算集群提供很高的数据访问性能, 但为了维护全局文件系统的一致性进行的数据同步成为性能提高的瓶颈。而对象存储提供了介于NAS和SAN之间的接口层次[11], 即Object Storage Device (OSD) 接口, 这一接口通过一组独立的存储集群来实现, 在物理存储设备与计算集群之间建立一个高速并行数据通道。
真正的对象存储设备目前还处在发展阶段, 成熟的商业化产品并不多, 对象存储最终的发展方向是要对文件系统功能进行分离, 即改变现有文件系统工作方式, 对目前文件系统层的功能进行简化, 如图 3所示[12]。文件系统总体可分为两个层次, User Component这部分主要包含文件的层次结构、命名和访问权限管理等功能; Storage Component部分主要负责文件的数据块分配以及与物理设备之间的读写控制管理。根据SNIA关于OSD的工作描述[13], OSD将对未来文件系统的发展有重大影响, Storage Component这部分的功能将被下移到存储设备中, OSD Interface为客户端的操作系统和文件系统屏蔽了底层不同物理存储设备的差异, OSD为异构平台混合的集群提供一个统一的对象访问接口。

对象存储体系结构不但解决了异构平台数据共享问题, 还提供了很多新的附加功能, 使得像Lustre这样采用对象存储设备的文件系统具备了一些新优势。首先, 对象存储在存储容量方面为上层文件系统提供了很好的可扩展性, 对象存储设备可以在线加入到存储集群中, 例如OST的动态增加。新的存储资源加入后, Lustre将通知MDS, MDS会更新相关的配置信息, 新加入的存储资源即可提供给文件系统使用。其次, 对象存储在性能上也为文件系统提供高度的可扩展性, 在Lustre的实际应用中, 系统的综合聚合性能可以随着对象存储数量的增加而线性提高。同时, 为了实现客户端对Metadata的快速访问, 可以通过扩展MDS集群中服务器的数量, 按需提高Metadata的总体响应能力, MDS集群可以在内部自动实现动态负载均衡。第三, 目前需要借助第三方软件完成的层次化存储管理及数据生命周期管理功能也可以集成在对象存储中, 进一步降低客户端应用复杂度。第四, 与对象存储相连的物理存储设备可以是高性能SAN存储子系统, 但更多的是采用性能价格比较高且结构较为简单的磁盘系统甚至是JBOD, 很多大型用户在OST中使用的是容量较大的SATA硬盘。因此, 对象存储方案通常能够在不同程度上降低存储系统的总体采购成本。
4 Lustre对多个集群的文件系统整合由于气象应用对计算资源的特别需求, 气象系统长期以来一直拥有国内较为领先的大型计算机系统。目前在国家气象信息中心安装的IBM高性能计算机系统为国内规模最大、性能最好的计算机系统。另外, 国家气象信息中心还拥有多套其他的高性能集群系统, 其中较新安装的是3套神威集群。
神威集群采用了Linux操作系统, 由于规模较小, 并没有安装并行文件系统, 集群内的存储资源只与I/O服务节点相连, 计算节点通过NFS访问共享数据文件。通常, 集群系统综合应用效率不仅仅取决于集群的聚合计算能力, 应用程序是否能及时获取所需数据, 也往往是制约系统利用效率的一个重要因素。3套神威集群各配置了自己的内部存储资源, 但并不能做到在集群间共享, 某些作业必须等待所需的数据从其他集群传到本地才能启动。如果做到多个集群存储资源能够被任何集群随意访问, 且能提供较高的I/O访问性能, 那么, 多个计算集群的效率可以得到充分发挥, 同时也为用户在多个集群中工作提供方便, 简化了跨越多个集群系统的应用流程。
从高性能计算技术的发展趋势来看, Linux的应用将越来越普遍, 将Lustre应用到现有环境中, 既可以整合现有计算集群, 也能为将来计算资源扩展和更大规模的数据共享奠定基础。如图 4所示, 目前的3个神威集群采用了不同的内部高速互联网络技术, 其中1个配置的是Myrinet, 另外2个配置了Infiniband。利用Lustre支持多种不同网络的混合集群功能, 可以将现有的3套神威集群的存储资源通过Lustre整合成一个全局的共享并行文件系统。对于未来引进的Linux系统, 可能会采用新的内部互联网络技术, 例如, 10 Gbps以太网或更快的Infiniband, 但只要在Lustre的支持范围内, 采用Linux平台, 就可以立即融入到现有的Lustre环境中, 共享现有的存储资源。

|
|
| 图 4. Lustre与Infiniband相结合的物理连接 Fig 4. The physical layout of Lustre together with Infiniband | |
由于使用对象存储设备, 与传统的集群系统相比, Lustre环境中的存储资源与计算资源之间的关系更为松散, 存储设备几乎不依赖于计算集群, 这样, 计算资源和存储资源都可以根据各自的实际情况分别按需定制进行扩展。目前, Lustre已经发布了版本1.6, 能够支持在线存储资源扩展, 即在不影响业务正常运行的情况下动态增加新的存储资源; 而在2.0版本以后的产品中, 将支持32~256个MDS集群以及MDS的在线扩展, 这些特性将大大提高Lustre的扩展能力和总体可用性, 保证较高的业务连续性。
图 4配置模型主要体现了Lustre整合多个服务端的计算集群的情况, 不仅如此, Lustre的应用还可以扩展到最终用户的应用系统。Lustre可以通过Linux本身的功能对Windows系统提供数据共享, 而且, 根据Lustre的发展规划[14], 从版本1.6.x开始, 将支持对Windows客户端的并行数据共享, 因此全局的文件系统可以从高性能计算集群一直延伸到用户的桌面系统。这将为用户的应用提供很大的灵活性, 气象预报的整个流程, 从数据收集、数据前处理、模式计算和运行、模式后处理、预报结果显示、数据备份和归档等等就能够在一个全局统一的命名空间中进行。这样不仅减少了文件跨越多个集群系统的传输而提高了整个流程的运行效率, 而且由于数据和文件只有一个拷贝, 减少了冗余的存储资源消耗, 总的存储资源也得到有效利用。
5 结论和讨论本文介绍了气象应用的特点及其对高性能计算的需求, Lustre并行文件系统的工作原理及特性。在了解和研究相关技术领域的过程中发现, Lustre已经发展成为比较成熟的并行文件系统解决方案。根据国家气象信息中心现有计算环境和未来的发展趋势, 设计了Lustre整合多集群文件系统的概念模型, 为今后高性能计算环境的发展提供一个参考依据。从这一模型中, 可以得到以下基本结论:
1) Lustre能够在基于Linux的多个异构集群系统环境中进行在线存储资源的整合, 实现文件系统全局统一命名空间。
2) Lustre能为气象模式的运行提供稳定、安全、高性能的文件访问和高度可扩展的存储资源, 尤其在保证业务连续性方面提供支持。
3) Lustre可以简化气象业务流程, 提高用户应用效率和存储资源利用率。
从某种角度上看, Lustre在技术发展上也存在着一些不足, 主要体现在兼容性方面。Lustre文件系统从诞生开始只应用在Linux平台上, 而目前的主流高性能计算机系统以及用于关键业务的服务器系统均采用主流UNIX操作系统, 因此气象领域目前利用Lustre技术进行文件系统的整合还存在一定的困难。但由于Linux无论在高性能计算还是在通用事务处理领域的发展都有明显的上升趋势, 在未来气象领域的应用中, Lustre仍然有很好的发展前景。
Lustre的发展一方面靠自身的不断改进, 另外也依赖于其他相关技术的革新和完善, 特别是对象存储技术和集群内的高速互联网络。值得一提的是在高速网络技术中, Infiniband已经从一个理想化的技术逐步发展为成熟的产品, 在高性能计算, 大规模数据处理等领域都得到了广泛的应用。Lustre和Infiniband[15]的结合可以更好地发挥这两个技术各自的优势, 为气象领域的应用提供更为高效、灵活的支撑平台。
| [1] | http://www.top500.org. |
| [2] | http://www.pvfs.org. |
| [3] | http://www-03.ibm.com/systems/clusters/software/gpfs.html. |
| [4] | http://www.sgi.com/products/storage/tech/file-systems.html. |
| [5] | http://www.llnl.gov/asci/overview/asci-mission.html. |
| [6] | http://www.llnl.gov/asci/platforms/bluegenel. |
| [7] | Cluster File Systems Inc. Lustre: A Scalable, High-Performance File System.http://www.lustre.org. |
| [8] | Birrell A D, Needham R M, A universal file server. IEEE Transactions on Software Engineering, 1980, SE-6, (5): 450–453. DOI:10.1109/TSE.1980.230493 |
| [9] | http://www.clusterfs.com/images/Docs/lustre-datasheet.pdf. |
| [10] | Roy Davis, VAX Cluster Principles. Digital Technical Press, 1993. |
| [11] | Garth A Gibson, Brent B Welch, David F Nagel, et al.Object Storage:Scalable Bandwidth for HPC Clusters. The Fourth Linux Clusters: The HPC Revolution 2003 Conference and ClusterWorld Conference and Expo, 2003. |
| [12] | Weber R O, Information Technology-SCSI Object Based Storage Device Commands (OSD). T10 Working draft NCITS TBD-200X Project 1355D, 2004. |
| [13] | http://www.snia.org/tech-activities/workgroups/osd. |
| [14] | http://www.clusterfs.com/roadmap.html. |
| [15] | http://www.infinibandta.org. |