 2008, 19 (2): 201-208
2008, 19 (2): 201-208


在数值天气预报和日常气象分析中, 经常需要将不规则的站点资料插值到规则的网格, 如资料同化中的客观分析和站点资料的等值线分析等。目前气象中的站点资料分析方法常用基于以距离函数为权重的插值方法, 如反距离平方法和逐步订正法等[1]。1959年Гандин等采用统计手段分析欧洲28个测站2年观察资料, 研究500 hPa位势高度结构函数; 1963年Bertoni等根据大西洋和欧洲55个测站地面气压资料绘制了相关系数分布图[2]。他们使用统计工具分析气象要素的空间相关结构, 为基于气象要素的空间相关结构统计插值方法做了理论准备。1963年Gandin提出了最优插值法 (Optimal Interpolation), 其原理就是通过最小二乘法确定样本点的插值权重使得分析场误差方差极小[3], 并在气象上得到广泛的应用。
Kriging方法是一种基于空间统计的插值方法, 南非地质工程师Krige于1951年提出, 并由法国数学家Matheron于1962年发展完善[4-5]。其核心思想是根据样本点空间位置与相关程度的关系, 赋予每个样本点不同权重, 使得估计误差最小[1, 5]。Kriging方法是以区域化变量理论为基础, 以半变异函数为主要工具, 通过引入物理量场的空间相关特征结构来研究那些在空间分布上既有随机性又有结构性的物理量[6-10]。Kriging方法可看作是一个空间随机函数的最优线性无偏估计子[6-9, 11]。目前Kriging方法已经日趋完善, 广泛应用于地质、地理、海洋和气象等地球科学领域。
Kriging方法通常包括普通Kriging方法 (Ordinary Kriging) 和泛Kriging方法 (Universal Kriging) 等。普通Kriging方法假设区域化变量符合二阶平稳假设和本征假设, 而泛Kriging方法假定区域化变量具有某种以多项式表征的倾向, 从而无需平稳假设, 适合于非平稳情形[1, 6-7]。非对偶Kriging方法是一个局部插值方法, 对每一个插值点都需要重新建立Kriging线性方程组并求解该方程组, 因此计算时间非常大。Le等[12]针对非对偶Kriging方法的计算效率问题, 通过等价变换将泛Kriging方法转换成对偶Kriging方法 (Dual Kriging) 实现了区域化变量的全局插值, 全局插值使得仅需一次构造和求解Kriging线性系统, 所以减少了大量的计算时间, 而且与泛Kriging方法是完全等价的。
1 对偶Kriging插值方法Kriging方法假定一个空间物理变量可以用一个随机函数F(X) 表示, 其中X是空间位置向量。假如在N个不同的空间位置Xi的物理量观测值为fi, 其中1≤i≤N。Kriging方法就是构造F(X) 的一个近似函数f(X), 使得
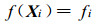
|
(1) |
近似函数f(X) 的最简单形式可以取为fi的不同权重θi的线性组合:
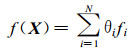
|
(2) |
泛Kriging方法假定区域化变量是一阶非平稳的, 因此随机函数F(X) 可表示成区域倾向项d(X) 与残差项e(X) 之和:
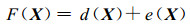
|
(3) |
泛Kriging方法的有效性在于倾向项表示物理现象的区域倾向, 而残差项起到修正作用使得插值函数在样本点Xi完全与观测值fi吻合, 因此泛Kriging方法是真正的插值算子。其中倾向项d(X) 一般表示为空间位置向量X的多项式:
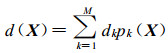
|
(4) |
式 (4) 中, M的取值和pk(X) 的形式由位置向量X的维数和pk(X) 多项式的最高次数决定。pk(X) 多项式的最高次数一般采用一次或两次, 次数太高容易产生上冲或下冲现象。因此倾向项d (X) 与向量X的维数、pk(X) 多项式最高次数的关系见表 1, 而M(M=1时, 退化为普通Kriging法) 就取等于倾向项相加项的个数。
|
|
表 1 倾向项d(X) 与向量X的维数和pk(X) 多项式的最高次数的关系 Table 1 The relationship between the trend d(X) and the dimension of vector X, the order of polynomial pk(X) |
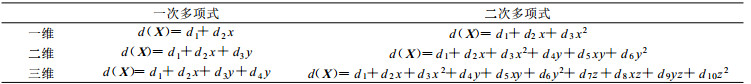
Kriging的无偏条件要求随机函数F(X) 的平均值等于各个样本点随机量不同权重θi的线性组合平均值:
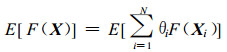
|
(5) |
式 (5) 中, E表示取数学期望值, 是一个线性算子, 而残差项e(X) 的均值为零, 因此无偏条件变成:
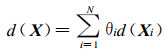
|
(6) |
式 (6) 对任意倾向函数d(X) 都成立, 因为倾向函数d(X) 是由基函数pk(X) 支撑, 所以式 (6) 对基函数pk(X) 也成立, 因此无偏条件变成:
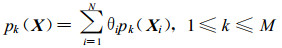
|
(7) |
Kriging的最优条件要求在无偏条件式 (7) 下使得估计误差方差最小, 也就是要求
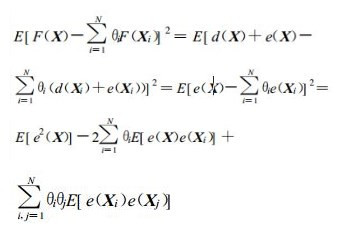
|
(8) |
在无偏条件式 (7) 下取极小值, 应用Lagrange乘数法得到泛Kriging的方程组:
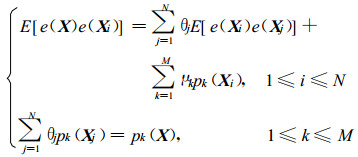
|
(9) |
式 (9) 中, μk为Lagrange乘子。
为了求解式 (9), 必须知道残差项e(X) 的协方差E[e(X) e(Xi)]和E[e(Xi) e(Xj)], 如果残差项是各向同性的, 那么协方差只是距离的函数
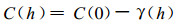
|
(10) |
式 (10) 中, γ(h) 为半变异函数
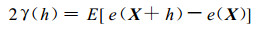
|
(11) |
应用式 (11), 通过大量的数据统计和拟合得到半变异函数γ(h) 的表达形式, 然后通过式 (10) 得到协方差C(h), 代入方程组 (9) 即可使用LU分解法[13]求解。常用的半变异函数的理论模型有:
球状模型
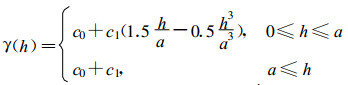
|
指数模型
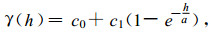
|
高斯模型
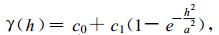
|
线性模型
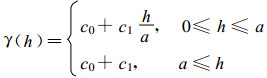
|
式 (9) 可以写成矩阵形式:
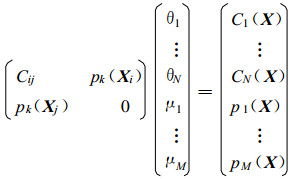
|
(12) |
其中, Cij=C(hi(Xj)) 和Ci(X)=C(hi(X))。由于式 (12) 的右端项依赖于插值点的空间位置向量X; 因此对于每个插值点X, 都要重新求解方程组 (12), 得到权重θi代入式 (2), 才能得到插值点X的值f(X)。如果样本数和网格数都非常庞大, 式 (12) 变成一个大型线性系统, 求解大型线性系统非常耗时, 因此泛Kriging方法的计算量将会非常大。对偶Kriging方法通过等价变换将式 (12) 变换为不依赖于插值点的形式, 因此只需求解一次方程组, 从而大大提高计算效率。
首先, 由于式 (12) 的系数矩阵是对称的, 其逆形式如下:
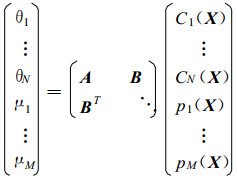
|
(13) |
于是式 (2) 变成
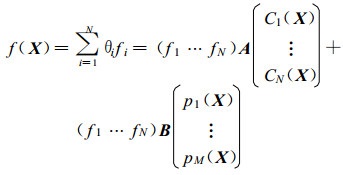
|
(14) |
设
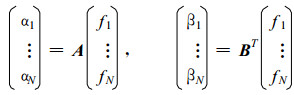
|
(15) |
显然, 式 (15) 可以写成
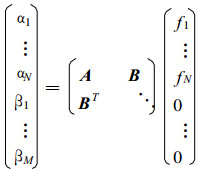
|
(16) |
将式 (16) 写成其逆形式得
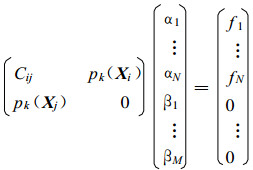
|
(17) |
因为A是对称的, 所以由式 (14) 和式 (15) 得
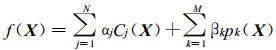
|
(18) |
通过以上等价变换, 得到了对偶Kriging系统式 (17) 和式 (18)。由于式 (17) 不依赖于插值点X, 因此只需求解一次得到系数αj和βk, 然后代入式 (18) 即可计算不同插值点X的值f (X)。对偶Kriging方法将泛Kriging方法的多次求解大型线性系统的计算转移到式 (18) 的计算, 式 (18) 的计算量相对求解方程组式 (12) 的计算量少了很多。可见, 对偶Kriging方法严格与泛Kriging方法等价, 而且比泛Kriging方法省时。
2 Kriging计算方案的实现Kriging方法是一种最优线性无偏估计的插值方法, 但其应用包含半变异函数的统计与拟合、以及高效精确求解Kriging线性方程组等几个复杂的过程, 从而影响Kriging方法的广泛应用。因此, 在Linux/Unix系统下采用Fortran 90的模块化功能, 设计编写了Kriging软件包。该软件包包括半变异函数统计、半变异函数模型拟合、普通Kriging和泛Kriging方法以及对偶Kriging方法计算等功能。
求解Kriging线性系统采用部分选主元的LU分解和回代求解[13], 然后采用迭代订正, 使得对1~5000维的线性系统求解精度和效率都很高。为了避免相近数相减与大数加小数带来的计算向量内积的误差, 首先对两个向量逐数相乘的结果排序, 然后对正数采用从小到大的顺序相加, 对负数采用从大到小的顺序相加, 这样计算可以尽量减少计算机的舍入误差。
由式 (11) 可知, 半变异函数采用残差项e(X) 来计算, 统计与拟合半变异函数步骤:①最优曲面拟合倾向项d (X):采用了SVD奇异值分解的方法拟合[14]倾向项d(X)。使用大量样本统计半变异函数时, 拟合倾向项d(X) 的线性方程组有可能是奇异或接近奇异, 采用SVD奇异值分解拟合方法可以将小于指定阈值的奇异值设为零, 避免很小奇异值带来的很大舍入误差, 从而提高拟合精度。②计算残差项:
e(X)=F(X)-d (X)。③统计半变异函数:将样本对按分开距离分成N个组, 也就是样本对的分开距离h∈[(i-1)δ, iδ]就将其归入第i个组, 其中δ为组的宽度。那么第i个组的平均半变异函数γ(hi)=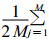
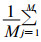
该软件包采用Fortran 90模块化设计, 因此其他程序可以通过模块接口非常灵活地调用其中的功能。而且半变异函数模型及其参数, 倾向项的阶数和M的取值, 以及半变异函数统计的分组数和组的宽度等都可以通过子程序的参数来设置。因此该软件包基本满足常规应用精度, 高效和灵活。
3 数值试验结果与分析 3.1 个例试验选用2005年6月19日08:00(北京时, 下同), 20°~40°N, 95°~125°E内319个站点24 h降雨量 (图 1), 半变异函数采用球状理论模式, 其中块金值c0=-10, 拱高值c1=600和变程a=3°。通过对偶Kriging方法、泛Kriging方法和GrADS绘图软件内置的Cressman客观分析方法将319个站点24 h降雨量插值到范围为20°~40°N, 95°~125°E的0.1°×0.1°网格。

|
|
| 图 1. 2005年6月19日08:00的24 h降雨量 (单位:mm) Fig 1. 24-hour accumulated precipitation at 08:00 on July 19, 2005 (unit:mm) | |
使用对偶Kriging方法、泛Kriging方法和Cressman方法将319个站点24 h降水量插值到相同的网格, 得到的插值结果分别如图 2a、图 2b和图 2c。可以看出, 3种方法分析得到的等值线形势是非常一致的, 但Kriging方法的效果更平滑美观, 而Cressman方法分析的等值线会出现一段一段不闭合的短等值线。对极值中心, Kriging方法的极值中心附近的等值线间隔各向比较均匀, 而Cressman方法的极值中心附近的等值线间隔明显出现各向异性的性质, 原因是Cressman方法只考虑周围站点的距离来确定其权重, 而不考虑它们之间的空间相关性, 也就是站点距离越近、变量值越大, 分析值就越靠近, 从而出现偏向的特征; 而Kriging方法假定物理量场是各向同性的, 因此其分析场各向比较均匀。整体来说, 3种方法的效果非常一致。

|
|
| 图 2. 3种方法分析的降水量等值线以及对偶Kriging方法与泛Kriging方法差异 (单位:mm) (a) 对偶Kriging方法, (b) 泛Kriging方法, (c) Cressman方法, (d) 对偶Kriging方法与泛Kriging方法之差 Fig 2. The precipitation contours by these three methods and the difference of the contour by Dual Kriging to that by Universal Kriging (unit:mm) (a) Dual Kriging method, (b) Universal Kriging method, (c) Cressman method, (d) the difference | |
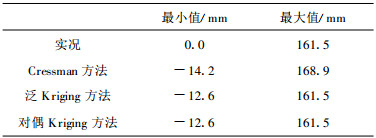
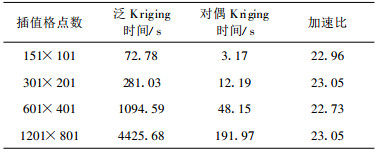
尽管3种方法的整体效果非常一致, 但是从表 2可以看出它们的细微区别。首先两个Kriging方法的最大值、最小值比Cressman方法的更合理, Cressman方法的极值上冲下冲明显。由于采用了GrADS软件中内置的Cressman分析方法, 因此无法得到其准确的计算时间, 从而无法比较Cressman方法的计算时间与Kriging方法的计算时间。前面, 已经提到普通Kriging和泛Kriging方法是局部插值, 需要多次求解Kriging方程组, 因此非常耗费计算机时间。而通过等价变换得到的对偶Kriging方法, 只需求解一次Kriging方程组, 从而大大节省了计算时间。从图 2d可以看出, 对偶Kriging方法与泛Kriging方法之差, 单精度时为10-5量级, 而双精度时达到10-8量级 (图略), 属于计算机误差范围; 而且从表 2的最大值、最小值可以看出两者完全一致; 因此实际硬件等因计算证实了前面推导两者的等价性。计算时间受到编译器、编译选择和计算机素影响, 表 3是在中国气象局的IBMC LUSTER 1600上进行对偶Kriging与泛Kriging计算效率的对比结果, 对偶Kriging方法所用的计算时间远比泛Kriging方法少, 加速比达到23倍。
|
|
表 2 3种方法的最大值、最小值与实况对比 Table 2 The comparison among these three methods by comparing their max/min value with observations |
|
|
表 3 对偶Kriging与泛Kriging的计算效率对比 Table 3 The comparision of the efficiency between Dual Kriging method and Universal Kriging method |
3.2 半变异函数的确定与敏感性试验
为了增大样本数来提高统计可信度, 半变异函数统计采用3.1节个例试验的319个降水量资料, 以及同一时次同一区域的850个加密观测降水量资料。统计半变异函数的分组数N=200, 组的宽度δ=0.05°。一般认为物理量场的空间相关性随着分开距离的增大而逐渐消失, 因此虽然参与统计的样本最大分开距离达到30°, 实际只用分开距离小于等于N·
δ=10°的样本对来统计半变异函数。半变异函数的统计结果图 3也证明这样选择是合理的, 分开距离大于5°时半变异函数几乎不再变化。因此合理选择分组数N和组的宽度δ非常重要。组的宽度δ太小会导致组中的样本对个数太少从而统计缺乏可信度, 一般保证组中的样本对个数不少于50统计才是基本可信的。同理分组数N太小会使拟合的半变异函数不可信, 因此分组数N一般取为N·δ等于最大分开距离的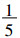

|
|
| 图 3. 半变异函数的统计与拟合 Fig 3. The statistics and fitting of the semivariance | |
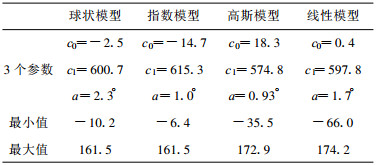
通过非线性参数拟合球状、指数、高斯和线性4类半变异函数模型得到4个半变异函数; 4个半变异函数见图 3的4条曲线, 具体参数见表 3第一行。从图 3可以看出球状、高斯和线性曲线比较类似, 而指数曲线比较光滑; 4条曲线的总拱高c0+c1 ≈ 600, 而球状曲线的变程a最大, 而高斯曲线的变程最小。使用拟合得到的4个半变异函数代入对偶Kriging方法重复3.1节的试验。使用拟合得到的半变异函数的对偶Kriging插值结果见表 4。可以看出球状和指数模型的结果比较一致, 基本与个例试验结果相当, 但个例试验中的最小值下冲更明显。然而, 高斯和线性模型的结果比较差, 出现很大的上冲下冲。理想试验结果证明各向同性场的变程a越大, Kriging方法的误差也小。气象场在4°范围以内可以看作各向同性, 而在这个范围内, 如果变程a取小说明只有近距离的测站对插值点有相关性贡献, 而实际上可能在各向同性范围内较远距离的测站对插值点也有重要的相关性贡献, 从而变程a取小忽略了较远距离测站的贡献使得误差增大。虽然指数模型的拟合变程a=1.0°, 但由于指数模型是渐进达到最大值, 从图 3可以看出其变程实际可达4°, 因此指数模型的效果最好, 球状模型次之, 高斯和线性模型最差。
|
|
表 4 4类半变异函数模型对对偶Kriging插值精度的影响 Table 4 The impact of four kinds of semivariance on the precision of Dual Kriging method |
4 结论与讨论
对偶Kriging方法的整体分析效果不仅与标准气象绘图软件GrADS中Cressman方法分析效果一致, 甚至在某些方面优于Cressman方法。而且, 对偶Kriging方法在数学上和实际计算中均与泛Kriging方法完全等价; 而对偶Kriging方法在计算速度上是泛Kriging方法的23倍。同时, 通过统计与拟合得到降水的4个半变异函数, 并进行半变异函数的敏感性试验, 发现在各向同性范围内, 变程a最大的指数模型的插值效果最好。总而言之, 对偶Kriging方法不仅在效果上能够达到标准气象绘图软件的水平, 而且在计算效率上比泛Kriging方法高很多, 因此对偶Kriging方法是一种高效的分析方法, 非常适合气象、海洋和地质等的大规模数据分析。
此外, 实际应用对偶Kriging方法必须注意如下几个方面:
1) 对偶Kriging方法的精度, 与Kriging系统式 (17) 的精确求解和式 (18) 的准确计算密切相关。采用共轭梯度法[15]等求解规模比较大的式 (17) 计算时间和精度均优于直接法如LU分解。为了避免相近数相减与大数吃小数, 计算式 (18) 最好先排序再相加。这样就可能将计算误差减少到最小。
2) 半变异函数对Kriging方法的准确性有很重要的影响, 因此对不同的区域化变量, 必须通过大量的数据统计和拟合得到比较准确的半变异函数。
3) 对于气象、海洋和地质等非常大规模的数据, 即使采用对偶Kriging方法, 其计算效率依然是一个大问题。因此, 采用区域分解, 将数据分成多个规模合适的子区域, 然后并行计算各个子区域。这样处理, 不仅能够大大提高效率, 而且能够进一步提高精度, 因为求解中等规模的线性系统比求解非常大规模的线性系统的精度要高。
综上所述, 影响计算精度不是方法本身, 如果在实际应用中能够处理好以上3个方面, 对偶Kriging方法作为高效的最优线性无偏的空间分析方法, 必将能够在气象、海洋和地质等领域得到广泛的应用。
| [1] | 常文渊, 戴新刚, 陈洪武. 地质统计学在气象要素场插值的实例研究. 地球物理学报, 2004, 47, (6): 982–990. |
| [2] | 张玉玲, 吴辉碇, 王晓林. 数值天气预报. 北京: 科学出版社, 1986: 382-384. |
| [3] | 曾忠一. 气象与遥测资料的客观分析. 台北: 中央研究院物理研究所, 1987: 93-97. |
| [4] | 洪玉振. 克里格统计理论研究新解. 河海科技进展, 1994, 14, (4): 31–34. |
| [5] | Matheron G, Principles of geostatistics. Economic Geology, 1963, 58, (8): 1246–1266. DOI:10.2113/gsecongeo.58.8.1246 |
| [6] | Chiles J P, Delfiner P, Geostatistics:Modeling Spatial Uncertainty. New York: John Wiley & Sons, 1999. |
| [7] | Christakos G, Modern Spatiotemporal Geostatistics. New York: Oxford University Press, 2000. |
| [8] | Cressie N, Statistics for Spatial Data. New York: John Wiley & Sons, 1993. |
| [9] | Ripley B D, Spatial Statistics. New York: John Wiley & Sons, 1981. |
| [10] | 岳文泽, 徐建华, 徐丽华. 基于地统计方法的气候要素空间插值研究. 高原气象, 2005, 24, (6): 974–980. |
| [11] | 刘峰. 应用Kriging算法实现气象资料空间内插. 气象科技, 2004, 32, (2): 110–115. |
| [12] | Le Roux D Y, Lin C A, Staniforth A, An accurate interpolating scheme for semi-Lagrangian advection on an unstructured mesh for ocean modeling. Tellus, , 49, (1): 119–138. |
| [13] | William H P, Teukolsky S A, William T V, et al.Numerical Recipes in C++, Second Edition. Beijing:Publishing House of Electronics Industry, 2003:46-59; 661-704. |
| [14] | 魏凤英. 气候统计诊断与预测方法研究进展. 应用气象学报, 2006, 17, (6): 736–742. |
| [15] | 《现代应用数学手册》编委会.现代应用数学手册:计算与数值分析卷.北京:清华大学出版社, 2005:399-421. |