 2007, 18 (3): 365-372
2007, 18 (3): 365-372


2. 中国气象局大气探测技术中心, 北京 100081;
3. 湖北省气象局, 武汉 430074;
4. 北京市气象局, 北京 100089
2. Atmospheric Observation Technology Center, CMA, Beijing 100081;
3. Hubei Provincial Meteorological Bureau, Wuhan 430074;
4. Beijing Municipal Meteorological Bureau, Beijing 100089
降雨量的研究在防灾减灾以及水资源利用、工农业生产中具有重要意义[1-2], 同时降雨量也是重要的气候变量, 对气候变化特别是季风研究等许多方面有着重要影响[3-5]。降雨量的预测是一个难点, 涉及微观与宏观物理过程, 与大尺度气候系统及小尺度天气系统密切相关, 受大气热力学条件和局部地形的影响[6], 目前, 直接观测仍然是获得降雨量资料的根本途径。随着我国经济和社会发展对气象服务需求的不断增长, 我国不少省 (区) 根据地方服务需求布设了大量的自动雨量站, 对降雨量进行了加密观测。WMO在地面气象观测业务准确度要求与常用仪器性能的规定中, 对雨量器的准确度有明确的要求[7], 然而, 我国的加密自动雨量站来自国内二十多个厂家, 其中大部分没有经过统一考核。从目前国内一些科研和业务单位降雨量资料的使用情况来看, 降雨量资料的准确性差, 给实际工作带来了较大影响[8-9]。为了确保我国自动雨量观测网建设质量和采集数据的准确性, 对不同型号自动雨量站降雨资料进行质量评估和考核显得十分必要。
2005年, 根据中国气象局下达的任务①, 中国气象局大气探测综合试验基地对目前我国各省 (区) 已布点的20种自动雨量站进行了考核。20种自动雨量站中, 除1种未通过计量检定和静态测试以外, 其余19种分别在我国具有地域代表性的3个站点:北京 (54511)、宜昌 (57461) 和南京 (58238) 进行了为期4个月 (2005年6—9月) 的对比观测和动态考核。
①中国气象局监测网络司.关于下发自动雨量站定型考核方案的函.2005.
1 资料及质量评估内容 1.1 资料来源和处理本文的资料来源为3个考核站点内19种自动雨量站的每日分钟降雨数据文件 (R文件) 以及作为降雨量参考标准的人工雨量筒定时观测记录和业务自动气象站分钟降雨数据文件 (Z, R和J文件)。资料对比评估以小时降雨量作为对比数据。对比评估之前, 首先对每月各自动雨量站和业务自动气象站的分钟降雨数据进行小时降水数据转换, 然后将各自动雨量站的小时降雨量与参考标准的小时降雨数据进行对比和评估。
1.2 资料质量评估内容参照WMO仪器和观测方法委员会 (CIMO) 主办的各次国际比对工作报告[10-11]以及国内相关对比试验[12], 对自动雨量站的动态考核包括数据完整性、可靠性和准确性3个方面。
1.2.1 数据完整性通过统计每月缺测次数对各自动雨量站数据进行完整性考核。自动雨量站分钟降雨量统计小时降雨量时, 若分钟降雨量在某小时内全部缺测, 则对应的小时记录认为缺测, 否则认为不缺测, 其小时降雨量按实有记录进行统计。
1.2.2 数据可靠性通过统计每月有无降水一致率、每月粗差次数对各自动雨量站进行可靠性考核。
有无降水一致率 当小时降雨量参考标准为0, 而自动雨量站对应小时降雨量≥0.2 mm, 或当小时降雨量参考标准≥0.2 mm, 而自动雨量站对应小时降雨量为0, 作为一次不一致统计, 否则为一致。
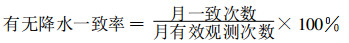
|
(1) |
粗差率 逐个检查各自动雨量站数据与降雨量参考标准的对比差值, 设Xi为各自动雨量站某小时的观测降雨量, X为对应该小时的降雨量参考标准, 如果两者的差值超过一定的范围, 即为粗差。采用的具体评估标准如下:
参考标准小时降雨量 > 0.5 mm且≤10.0 mm时, |Xi-X|≤0.4 mm; 参考标准小时降雨量 > 10.0 mm时, |Xi-X|≤X×4%。

|
(2) |
通过自动雨量站与降雨量参考标准的小时降水百分误差对自动雨量站数据的准确性进行考核和评估。当月降雨总量≤10 mm时, 不进行准确性评估, 当月降雨总量 > 10 mm时, 月降水百分误差的计算表达式为:
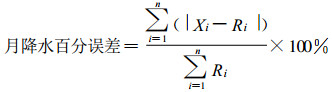
|
(3) |
式 (3) 中, Xi为自动雨量站某小时的观测降雨量, Ri为对应的参考标准的小时降雨量, n为当月小时降水有效对比总次数。
2 降雨量参考标准的选择对自动雨量站进行动态考核, 降雨量参考标准的选择十分重要。可以直接作为降雨量参考标准的有:业务化自动气象站分钟降雨数据文件 (Z, R和J文件) 和雨量筒人工定时观测记录。其中, Z文件和R文件是自动站采集的原始数据文件, J文件是原始数据文件经过一定质量控制后的数据文件。鉴于此, 可以直接采用自动气象站J文件和雨量筒人工定时观测记录作为降雨量参考标准对自动雨量站进行评估。
2.1 自动气象站J文件评估采用自动气象站J文件作为降雨量参考标准, 可以实现和自动雨量站小时降水的逐一对比, 具有较高的时间对比精度。从整个考核期内北京、宜昌和南京3站19种自动雨量站实测降雨量对比结果 (图 1) 可以看出:采用自动气象站降雨量作为参考标准, 各自动雨量站的降雨量百分误差普遍偏高 (超过8%)。

|
|
| 图 1. 2005年6—9月19种自动雨量站降雨量分别与自动气象站和人工雨量筒的百分误差对比 Fig 1. Comparison of monthly precipitation errors among 19 automatic precipitation stations, AWS data and timed man-made observations | |
经检查发现, 自动气象站有时会出现翻斗雨量器被杂物堵塞而造成观测粗大误差, 这种误差与自动气象站单次观测存在的潜在随机误差和系统误差正位叠加[7, 13], 导致自动气象站所测降雨量在某些时刻与真实情况出现较大偏差, 特别是在大的降雨过程, 这种偏差更为明显。事实证明, 由于自动气象站观测不确定性因素造成的降雨量误差是导致各自动雨量站降雨量百分误差普遍偏高的主要原因。
2.2 雨量筒人工定时观测记录评估采用雨量筒人工定时观测记录作为降雨量参考标准, 由于降低了观测仪器本身造成的系统误差, 评估结果具有较高的可信度。从图 1可以看出:采用雨量筒人工定时观测记录作为参考标准, 19种自动雨量站的降雨量百分误差比以自动气象站降雨量为参考标准平均降低了2%左右。
但是, 雨量筒人工定时观测记录是6 h累计降雨量, 必须将自动雨量站降雨量进行6 h累加后再与其进行对比评估。这种累加过程, 降低了时间对比精度。另外, 由于雨量筒观测本身的蒸发和粘湿误差、风场变形误差[14-16], 以及存在非正点观测或正点漏测等潜在人为失误导致的降水粗大误差, 也会增加观测结果的不确定度, 最终影响评估结果的准确性。但对于自动气象站, 这种不确定性的影响要小得多。
2.3 拟合降雨量评估鉴于对以上两种降雨量参考标准评估的优缺点分析, 要提高自动雨量站评估的可信度, 需要建立一个既具有较高时间对比精度, 又具有较高可信度的标准降雨序列。一种简单的思路是通过对自动气象站降雨资料进行严格的质量控制, 剔除不确定性产生的粗大值后作为标准降水序列, 然而, 目前的质量控制技术并不能对自动气象站的降雨量粗大值进行有效判断。在大量试验的基础上, 将基于各自动雨量站观测结果的拟合降雨量作为参考标准, 并以此进行降雨量准确性评估。
2.3.1 拟合降雨量评估的可行性为验证采用拟合降雨量作为降雨量参考标准的可行性, 分别从考核期内北京、宜昌和南京3站中选取1个典型降水日 (北京时, 下同) 进行各雨量站实测降雨量对比 (图 2), 从图中可以看出:在一次典型的降水过程中, 19种雨量站中除个别雨量站外, 绝大多数雨量站在同一地点同一时刻所测降雨量落入一个相对集中的区域并呈点 (拟合点) 状分布, 小时降雨量集中落区在2 mm范围以内, 而且降雨集中落区与自动气象站所测降雨量基本吻合。作者对考核期间的降雨过程进行了广泛验证, 事实证明:这种降雨落区的点状分布具有普遍性, 用多种雨量站的拟合点降雨量作为真实降雨量的一种估计值具有可行性。

|
|
| 图 2. 2005年19种自动雨量站与自动气象站实测降雨量对比 Fig 2. Comparison of 19 automatic precipitation stations data and AWS observations in 2005 | |
2.3.2 拟合降雨量的计算方法
由图 2可以看出, 确定拟合降雨量的关键在于有效排除存在明显误差降雨点的干扰, 准确找到降雨落点集中区域 (降雨拟合点) 的位置。对于降雨量使用传统的计算标准差剔除粗大值的方法, 会造成剔除值过多或过少, 导致降雨拟合点位置的偏差。根据降雨落区的特点, 本研究采用一种逐步逼近的方法计算拟合降雨量。该方法的具体步骤如下:①设置一个落区标尺 (对应纵坐标降雨量落区范围), 标尺长度 (L) 初始值为0, 标尺测量起点 (Y) 从0开始; ②标尺长度固定, 标尺起点从坐标原点开始沿纵坐标方向以0.1 mm降雨量的递增速度滑动, 直到达到当前时次的最大降雨点结束, 依次计算标尺滑动过程中进入标尺范围的降雨落点个数NY; ③设置一个达标参数 (拟合参数) a, 在标尺的整个滑动过程中计算降水落点个数大于a的次数k, 如果当前标尺长度下k=0, 则增加标尺长度, 重复步骤②, 直至k > 0为止; ④从最后一个标尺长度下挑选出降雨落点个数NY最大时对应的标尺位置, 该标尺位置下所有降雨落点对应降雨量的平均值即是该时次的拟合降雨量。拟合降雨量的计算流程如图 3所示。

|
|
| 图 3. 拟合降雨量计算流程图 Fig 3. The flow chart of fitting precipitation computation | |
利用该方法计算出每日逐小时的拟合降雨量, 并最终生成小时拟合降水文件作为雨量站评估的标准降水文件。为便于对比, 选用宜昌站7月10日各雨量站实测降水进行拟合降雨量效果检验, 从拟合效果 (图 4) 可以看出:根据上述方法计算出的拟合降雨量全部进入降水落点集中区, 同时避免了业务自动站在某些时次 (如图 4中09:00) 的测量值出现明显偏差的现象。进一步试验证明:为获得最佳的拟合效果, 拟合参数a的取值应当大于被考核雨量站个数的一半以上, a的取值越大拟合值越大。a的最佳取值应根据实际观测资料经过试验确定, 本文中a取值为15。

|
|
| 图 4. 宜昌站2005年7月10日拟合降水效果图 Fig 4. The fitting precipitation of Yichang on July 10, 2005 | |
2.3.3 拟合降雨量的准确度评估
为进一步验证拟合降雨量的准确性, 可以利用降水自记纸对拟合降雨量进行对比检验。在3个考核站点中, 鉴于南京站降水自记纸的资料具有较高可信度, 故以南京站降水自记纸的降水记录作为参考标准对拟合降雨量进行检验。分别从南京站6—9月的降水中选取几种不同雨强的典型降水日进行验证, 从图 5的结果可以看出:拟合降雨量与降水自记纸记录的降雨量基本保持一致, 在大雨强时段, 拟合降雨量比降水自记纸记录的降雨量略偏高。

|
|
| 图 5. 南京站2005年6—9月不同雨强典型降水比较 Fig 5. The precipitation under the conditions of different rainfall intensity from June to September in 2005 of Nanjing | |
2.3.4 降雨量对比检验
将考核期内3站 (北京、宜昌、南京) 中19种雨量站的拟合降雨量分别和业务自动站、人工雨量筒的实测降雨量进行对比, 表 1和表 2分别显示了对比误差大于8%的测量结果, 同时经与台站观测员核实确认, 并参考降水自记纸记录, 给出了误差原因。
|
|
表 1 拟合降雨量与业务自动站实测降雨量误差对比分析 Table 1 Comparison of fitting precipitation and AWS data errors |

|
|
表 2 拟合降雨量与雨量筒人工观测降雨量误差对比分析 Table 2 Comparison of fitting precipitation and timed man-made observation errors |

从表 1、表 2的对比结果可以看出:由于拟合降雨量是在相同测量环境下对同一地点同一时刻降水多个测量结果的拟合, 在拟合过程中剔除了明显的粗大测量值, 因而, 相比自动站或雨量筒的单次测量, 拟合降雨量有效地降低了随机误差、系统误差以及明显误测或漏测的粗大误差造成的测量不确定度, 结果更接近真值。另一方面, 由于拟合方法是建立在重复性测量取样的基础上, 因此要采用该方法必须保证测量样本数足够大。同时, 需要经过试验确定最佳的拟合参数, 以获得最接近真值的拟合值。
2.4 3种降雨量参考标准评估结果对比分别用自动气象站、雨量筒人工定时观测记录和拟合降雨量作为降雨量参考标准, 对19种自动雨量站2005年6—9月北京、宜昌和南京3站的实测降雨量进行降雨量百分误差综合检验, 检验结果见图 6。从图中可以看出:采用拟合降雨量作为降雨量参考标准, 各雨量站的降雨量百分误差相比自动气象站降雨量为降雨量参考标准平均降低了2%左右, 与雨量筒定时观测记录作为降雨量参考标准的统计结果大体相当。

|
|
| 图 6. 2005年6—9月北京、宜昌、南京自动雨量站与自动站、雨量筒和拟合降雨量对比误差分布图 Fig 6. Comparison of precipitation errors in 19 automatic precipitation stations, AWS data and timed man-made observations among Beijing, Yichang and Nanjing from June to September in 2005 | |
3 小结
1) 自动气象站观测降雨量本身存在着不确定性, 以其作为降雨量参考标准对自动雨量站进行对比评估时, 评估结果误差较大。
2) 雨量筒人工定时观测的不确定度比自动气象站低, 观测资料具有更高的准确度, 采用其作为参考标准对雨量站进行对比评估, 评估结果较为可信。但雨量筒人工定时观测资料的时间精度较低, 限制了其作为降雨量参考标准在对比评估中的作用。
3) 在样本数较多时, 拟合降雨量可以比较准确地对实际降雨量进行估值, 基于拟合降雨量建立的降水序列既具有较高可信度, 同时又具有较高的时间对比精度。采用其作为参考标准对雨量站进行对比评估时, 与雨量筒降雨量作为标准的评估结果基本一致, 两者的一致性, 互证了各自的可信度。
拟合方法是建立在多器具重复性取样的基础上, 拟合值具有较高的可信度。在类似自动雨量站评估的气象仪器资料对比评估工作中, 如果样本数较多, 可以考虑使用拟合方法进行标准序列的建立, 这为自动气象仪器资料评估工作提供了一种新的思路。
致谢 北京、宜昌和南京3站的台站观测员为自动雨量站对比评估做了大量的工作, 在此谨表示感谢。| [1] | 李原, 黄资慧. 20世纪灾祸志. 福州: 福建教育出版社, 1992: 83-84. |
| [2] | 冯佩芝, 李翠金, 李小泉, 等. 中国主要气象灾害分析, 1951—1980. 北京: 气象出版社, 1985: 135-145. |
| [3] | 王绍武. 现代气候学研究进展. 北京: 气象出版社, 2001: 146-152. |
| [4] | 刘小宁, 王淑清, 吴增祥, 等. 我国两种蒸发观测资料的对比分析. 应用气象学报, 1998, 9, (3): 321–328. |
| [5] | 秦大河. 中国西部环境演变评估. 北京: 科学出版社, 2002: 29-70. |
| [6] | 崔茂常, 朱海, 白学志, 等. 中国日降水量变化特征分析. 大气科学, 2000, 24, (4): 519–526. |
| [7] | 中国气象局监测网络司, 译.气象仪器和观测方法指南 (第六版).北京:气象出版社, 2005. |
| [8] | 王绍武, 蔡静宁, 朱锦红, 等. 19世纪80年代到20世纪90年代中国年降水量的年代际变化. 气象学报, 2002, 60, (5): 637–639. |
| [9] | 陈隆勋, 朱文琴. 中国近45年来气候变化的研究. 气象学报, 1998, 56, (3): 257–271. |
| [10] | Sevruk B, Hamon W R.International Comparison of National Precipitation Gauges with a Reference Pit Gauge.WMO/TDNo. 38.Geneva:WMO, 1984. |
| [11] | Goodison B E.WMO Solid Precipitation Measurement Intercomparsion in Papers Presented at the WMO Technical Conference on Instruments and Methods of Observation (TECO-94). WMO/TD-No.588. Geneva:WMO, 1994:15-19. |
| [12] | 王颖, 刘小宁. 自动站与人工观测气温的对比分析. 应用气象学报, 2002, 13, (6): 741–748. |
| [13] | 中国气象局.地面气象观测规范.北京:气象出版社, 2003. |
| [14] | Sevruk B, Correction of Precipitation Measurements. WMO/TD, 1985, 104: 13–23. |
| [15] | Rinehart R E, Out-of level instruments:Errors in hydrometeor spectra and precipitation measurements. J Climate Appl Meteor, 1983, 22: 1404–1415. DOI:10.1175/1520-0450(1983)022<1404:OOLIEI>2.0.CO;2 |
| [16] | 任芝花, 王改利, 邹凤玲, 等. 中国降水测量误差的研究. 气象学报, 2003, 61, (5): 621–627. |