 2007, 18 (1): 21-28
2007, 18 (1): 21-28


2. 江苏省气象台, 南京 210008
2. Jiangsu Provincial Meteorological Observatory, Nanjing 210008
随着数值预报技术的发展, 基于数值预报产品释用的客观要素预报已成为日常预报业务中的重要参考手段, 同时预报业务的需要也大大促进了数值预报产品释用技术的研究和应用。我国气象工作者在这方面进行了大量的工作, 很多的研究成果在实际预报业务中起到了重要的作用[1-4]。
客观降水预报一直是数值预报产品释用中的难点问题, 相比较温度和湿度预报来说, 降水预报效果一直不是很理想。近年来, 我国气象工作者就如何提高客观降水预报效果进行了大量的研究工作, 这些工作大体分为两个方面, 一是从预报因子上下功夫, 寻找更合理的预报因子, 比如在预报因子中加入了数值化的预报经验[5-6]; 另一方面是在建立预报模型前对降水进行一定的预处理[7-8], 对降水量的处理主要是分级处理, 或者分别建立不同量级降水概率预报模型, 这些研究工作在一定程度上取得了提高预报效果的作用。
客观降水预报效果较差, 尤其是客观定量降水预报效果较差的重要原因是降水不是连续变量, 也不是一个时间点上的观测值, 而是一段时间内的累积值, 同时降水是严重偏态分布的变量, 利用传统的统计方法直接对降水量进行预报是存在问题的, 因此人们往往采取分级的方法对降水量进行处理[9]。但降水还存在与其他要素完全不同的特点:不同的天气形势在降水量中没有得到完全的反映, 换句话说, 对于零降水量的情况包含了很多种不同的信息, 例如, 雷声很大但没有下雨, 湿度很大也没有下雨, 天空有厚厚的层云也没有下雨, 天空没有一丝云同样没有下雨, 这些天气形势千差万别, 但在降水量中却得不到反映, 这使得在建立预报方程时因子与预报量的关系不能得到很好的反映, 影响了预报模型的质量。这个问题在分级处理中是得不到解决的, 因此在建立预报模型前, 如果通过一定的方式对降水量进行处理, 使得不同零降水量的情况在处理后的序列中得到一定程度的区分, 而不是直接用降水量建立预报模型可能会对预报结果产生较大的影响。
另一方面, 从预报业务的需求来说, 分级降水预报不能完全满足需要, 与气象要素有关的一些专业预报, 比如, 地质灾害预报、森林火险预报等需要的是定量降水预报结果, 因此客观定量降水预报问题也就变得重要起来。
基于以上的考虑, 为了探讨提高定量降水预报效果的有效途径, 本文将利用相对湿度来对降水量进行预处理, 并就同样方法、同样因子、同样时段、同样参数, 分别建立未处理和处理后的降水量预报模型, 进行试报, 通过以下的分析可以看到对降水量的这种处理方式能够提高预报效果。
1 神经网络方法简介文中采用神经网络中的BP网络方法, 它是一种单向传播的多层前向网络[10]。BP网络包括了输入层、隐层和输出层3个部分, 隐层可以是多层也可以是一层, 隐层上的节点称为隐节点。输入信号向前传播到隐层节点, 通过权值和作用函数的作用形成隐节点的值, 隐节点的值再向前传播到下一层, 最后获得输出结果, 每一层节点的输出只影响到下一层节点的输出。作用函数决定了网络节点的特性, 设oi为节点i的输出, ni为节点i的输入, 则oi=f(ni), 其中f(x) 为作用函数, 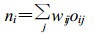
BP网络可以看成是一个从输入到输出的高度非线性映射。作用函数通常为Sigmoid型函数, 本文中采用的作用函数如下所示:
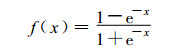
|
网络的权值通过学习获得, 这里的学习方法采用的是误差反向传播算法, 误差反向传播算法的基本过程为:①初始化, 即给网络权值赋以初值, 一般是赋予一个不为零但接近零的值; ②有了网络权值以后分别计算各个样本隐层和输出层的值, 并由此可以得到输出结果与实况之间的误差; ③根据误差结果由后向前采用梯度下降法修正各层各节点的权值; ④重复②, ③直到网络收敛或达到一定的误差要求, 学习结束。
2 资料处理及试验方案设计 2.1 资料及处理方法本文所使用的资料为中国国家气象中心T213模式 (以下简称T213模式)、德国气象局业务模式 (以下简称德国模式) 和日本气象厅业务模式 (以下简称日本模式)12:00(世界时, 下同) 起报的降水量预报以及我国多个站点一天8次的观测资料。
T213模式资料为0.5625°×0.5625°的经纬网格点资料; 德国模式资料为1.5°×1.5°的经纬网格点资料; 日本模式资料为1.25°×1.25°的经纬网格点资料。
预报对象为00:00的24 h累积降水量, 预报因子为3个模式不同预报时效与实况相应的24 h累积降水量预报, 即12~36 h的累积降水量预报, 36~60 h的累积降水量预报, 依此类推。为了避免由插值引起的误差, 因子不插值到站点, 而以站点周围4个点都作为预报因子。
对降水量的预处理过程如下: ①由观测资料计算降水时段内的平均相对湿度; ②计算建模时段内逐日的平均相对湿度标准化变量fhs; ③计算建模时段内平均降水量er; ④根据fhs和er对降水重新赋值。
2.2 试验方案设计方案1 降水量不做任何变化, 直接作为预报对象建立预报模型, 并进行预报试验。
方案2 当降水量为0时, 若fhs < 0, 则把降水值赋为fhs×er; 重新赋值后的时间序列作为预报对象建立预报模型, 进行预报试验, 预报结果中小于0的降水量样本重新赋值为0。
方案3 当降水量为0时, 若fhs < 0, 则把降水值重新赋为1.5×fhs×er, 重新赋值后的时间序列作为预报对象建立预报模型, 进行预报试验, 预报结果中小于0的降水量样本重新赋值为0。
以上3个方案是定量降水预报, 通常情况下人们把降水分级处理, 并认为能很好地提高预报效果, 为了比较定量降水预报与分级预报的预报效果, 同时增加了试验方案4。
方案4降水实况分为5级, 分别代表无雨、小雨、中雨、大雨、暴雨及以上量级, 具体处理过程请参阅文献[11]。
3 预报模型的建立建立模型所用的资料为2003年和2004年6—8月的资料, 预报因子为12:00起报的T213模式、德国模式、日本模式预报降水量和T213模式预报对流降水量共16个因子, 对应的实况资料为00:00的24 h降水量。
4个试验方案分别就同样的资料同样的方法建立预报模型, 对2005年6—8月北京、拉萨、乌鲁木齐、西安、上海、南昌和广州进行试报, 并对试报结果进行检验, 下面以36 h预报为例给出检验结果分析。
4 试验结果分析下面从TS评分、空报率、漏报率以及预报偏差4个方面来对比分析不同降水处理方案预报效果的差异。
4.1 TS评分36 h预报的小雨TS评分如图 1所示, 方案1的评分最低, 乌鲁木齐、南昌和西安TS评分不到0.3, 说明直接对降水量进行预报, 其预报效果是很差的。分级预报 (方案4) TS评分有所提高, 除乌鲁木齐外, 都达到了0.4以上, 但评分仍然低于方案2和方案3。利用相对湿度对降水进行处理后的方案2和方案3评分最高, 乌鲁木齐的评分分别达到了0.68和0.70。方案2和方案3相比较方案1和方案4的预报效果都有明显的提高, 尤其是乌鲁木齐从0.26和0.38提高到了0.68和0.70, 南昌从0.29和0.43提高到了0.75和0.75。从整体情况看, 方案1和方案3的评分差别不是很大。

|
|
| 图 1. 2005年6—8月36 h降水预报小雨TS评分 Fig 1. TS score of 36 h light rain forecast averaging from June to August in 2005 | |
4.2 空报率
图 2给出了4个处理方案的空报率:方案1的空报率最大, 乌鲁木齐达到了0.74, 西安达到了0.72, 而南昌也达到了0.71, 空报率最小的拉萨也达到了0.38, 这表明方案1空报严重。方案2和方案3空报率较小, 除西安外, 其余站点的空报率都在0.3以内, 南昌方案2和方案3的空报率为0。方案4的空报率从整体上看大于方案2和方案3。说明相对于方案4而言, 方案2和方案3对空报的情况也有所改进。

|
|
| 图 2. 2005年6—8月36 h降水预报小雨空报率 Fig 2. No-hitting rate of 36 h light rain forecast averaging from June to August in 2005 | |
4.3 漏报率
从图 3中漏报率可以看到, 方案1的漏报率最小, 除西安的漏报率为0.15外, 其余站点都小于0.1, 北京和乌鲁木齐的漏报率为0, 这和方案1空报率较大是一致的。由于方案1的空报率很大, 即使它的漏报率很小, 它的TS评分仍然很低。方案4的漏报率最大, 其中南昌达到了0.5, 也就是说50%的降水没有报出来, 而乌鲁木齐也达到了0.45;方案2和方案3的漏报率大于方案1而小于方案4, 但方案2和方案3本身的漏报率并不是很大, 都在0.3以内, 由于方案2和方案3空报率和漏报率都小于方案4, 所以它们的TS评分明显高于方案4。

|
|
| 图 3. 2005年6—8月36 h降水预报小雨漏报率 Fig 3. Fault-hitting rate of 36 h light rain forecast averaging from June to August in 2005 | |
4.4 预报偏差
预报偏差是衡量预报效果好坏的另一个重要指标, 是预报样本数 (区域) 与实况发生该天气现象的样本数 (区域) 的比值, 因此预报偏差接近或等于1最好, 偏离1越大, 说明预报样本数 (区域) 与实况样本数 (区域) 大小相差得越远。图 4给出了上述7个站点小雨预报的预报偏差, 从图中可以看到方案1预报偏差较大, 除拉萨为1.54、广州为1.86外, 其余站点都大于2.0, 其中预报偏差最大的乌鲁木齐达到了3.85, 南昌达到了3.29, 西安达到了3.0, 说明这些站点预报样本数远远大于实况的样本数; 方案2、方案3和方案4的预报偏差相近, 整体上看没有明显差异, 都接近1, 说明预报样本数和实况样本数大小接近。

|
|
| 图 4. 2005年6—8月36 h降水预报小雨预报偏差 Fig 4. Forecast bias of 36 h light rain forecast averaging from June to August in 2005 | |
以上的分析结果表明, 利用相对湿度对零降水量的样本进行处理后, 预报效果不论是从TS评分、空报率、漏报率还是从预报偏差上看都有提高, 预报效果不但好于未对降水进行处理的预报方案, 而且也好于对降水进行分级处理的方案。
4.5 与模式预报评分的比较前面的分析表明利用相对湿度对降水进行预处理后可以提高降水的预报效果。但是该处理方案与T213模式、德国模式和日本模式直接降水预报的预报效果相比又如何呢?如果预报效果没有模式的直接预报效果好, 那么所有的改进也毫无意义, 因此, 对T213模式、德国模式和日本模式的相应降水预报进行了插值, 并对2005年6到8月的预报结果进行了检验, 以方案2为例, 给出了与模式的预报检验结果的对比分析。
从TS评分结果 (图 5a) 可以看到, 所有站点方案2的评分明显高于3个模式直接降水预报的TS评分, 除西安和广州外差别不是很大外, 其他站点方案而较3个模式都有明显的优势。而3个模式评分没有明显差别, T213模式评分略大于德国模式和日本模式。这表明方案2的预报效果较单个模式直接输出预报有明显提高。

|
|
| 图 5. 2005年6—8月36 h降水预报小雨TS评分 (a) 和空报率 (b) Fig 5. TS score (a) and fault-hitting rate (b) of 36 h light rain forecast averaging from June to August in 2005 | |
方案2的TS评分明显高于模式直接输出预报, 那么空报和漏报的情况又如何呢?由图 5b可以看到3个模式空报率基本相当, 日本模式略大于其他两个模式, 而方案2的空报率较3个模式预报有明显降低, 说明方案2的空报情况远远小于模式的直接预报。而漏报率 (图略) 总体上方案2较模式预报有所增加, 但方案2的漏报率本身并不是很高, 漏报率最大的广州站是0.27, 其次是西安, 漏报率是0.23, 其他站点小于0.2, 而北京和乌鲁木齐漏报率小于0.05, 其中北京站的漏报率还小于T213模式和德国模式预报的漏报率。
从预报偏差 (图略) 也可以看到, 方案2的预报偏差接近1, 而模式预报的预报偏差接近或大于2, 最大的达到4.2, 说明模式预报区域远大于实况区域。与模式直接预报结果的对比分析表明, 利用相对湿度对降水量进行适当的预处理, 其预报效果同样明显好于模式直接预报。说明了该预处理方法切实可行, 并且比较有效。
4.6 中雨及以上量级的检验结果前面的检验结果是针对小雨预报的。图 6则给出了方案1、方案2、T213模式、德国模式和日本模式中雨、大雨的TS评分。从中雨的TS评分 (图 6a) 可以看到:7个站中有5个站, 方案1和方案2的评分较3个模式有非常明显的提高, 而其他两个站的评分与3个模式相当, 因此从整体上看经过释用以后中雨的预报效果有较大改进。两个释用方案的评分基本相当。大雨的评分情况与中雨相似。

|
|
| 图 6. 2005年6—8月36 h降水预报中雨 (a) 和大雨 (b) TS评分 Fig 6. TS score of 36 h moderate rain (a) and heavy rain (b) forecast averaging from June to August in 2005 | |
中雨和大雨空报率 (图略) 情况一致, 3个模式的空报率较高, 而4个释用方案的空报率除广州和西安较低外, 广州和西安4个方案的空报率与3个模式相当。漏报率 (图略) 的情况与空报率一样。这与TS评分是一致的。
分析表明对于中雨和大雨, 从整体情况看, 释用以后的效果明显好于模式预报。而利用湿度对降水量进行预处理的预报效果略好于不对降水量进行预处理和分级处理的预报效果。
5 结论和讨论以上分析表明:
1) 由于降水本身的特性, 在建立预报模型之前, 对降水量进行适当的处理, 能够对预报结果产生较大的影响。
2) 利用相对湿度对零降水量的情况进行一定的预处理, 再建立预报模型, 预报效果有明显的提高。从TS评分、漏报率和空报率以及预报偏差综合来看, 预报效果高于未对降水处理的预报效果, 同时也好于对降水进行分级处理的预报效果; 中雨和大雨的评分表明, 方案2的预报效果略好于不对降水进行处理的预报效果, 并好于对降水进行分级处理的预报效果。
3) 与T213、德国和日本模式直接降水预报效果的比较表明, 方案2的预报效果明显好于模式直接输出预报。
4) 从整体情况看, 该降水处理方案对客观降水预报, 尤其是定量的客观降水预报效果有改进, 并且该处理方案简单可行。本文对降水的预处理只是提供了一个思路和一种处理方法, 不同站点还可根据具体情况采用不同的要素来对降水进行处理, 例如云量等。
| [1] | 刘还珠, 赵声蓉, 陆志善, 等. 国家气象中心气象要素的客观预报———MOS系统. 应用气象学报, 2004, 15, (2): 181–191. |
| [2] | 胡江林, 涂松柏, 冯光柳. 基于人工神经网络的暴雨预报方法探讨. 热带气象学报, 2003, 19, (4): 423–428. |
| [3] | 刘爱鸣, 潘宁, 邹燕, 等. 福建前汛期区域暴雨客观预报模型研究. 应用气象学报, 2003, 14, (4): 420–429. |
| [4] | 赵声蓉. 多模式温度集成预报. 应用气象学报, 2005, 17, (1): 52–58. |
| [5] | 张万诚, 解明恩. 奇异值分解方法对降水的预测试验. 高原气象, 2002, 21, (1): 103–107. |
| [6] | 宋海鸥, 王永红, 顾善齐, 等. 应用K指数和TOT指数制作江苏中期降水预报的试验. 气象科学, 2002, 22, (2): 242–246. |
| [7] | 陈力强, 韩秀君, 张立群. 基于MM5模式的站点降水预报释用方法研究. 气象科技, 2003, 31, (5): 268–272. |
| [8] | 龚佃利, 王以琳, 谢考宪. 山东飞机增雨降水区分级预报方法研究. 应用气象学报, 2001, 12, (增刊): 139–145. |
| [9] | 曹晓岗. 利用T106数值预报产品作江西暴雨动态落区预报. 江西气象科技, 1998, 21, (1): 2–5. |
| [10] | 赵振宇, 徐用懋. 模糊理论和神经网络的基础与应用. 北京: 清华大学出版社; 南宁: 广西科技出版社, 1996. |
| [11] | 赵声蓉. 多模式降水集成预报∥章国材, 谢璞. 奥运气象保障技术研究. 北京: 气象出版社, 2004. |