 2005, 16 (3): 408-412
2005, 16 (3): 408-412


2. 国家气象信息中心, 北京 100081;
3. 中国气象局气候研究开放实验室, 北京 100081
2. National Meteorological Information Center, Beijing 100081;
3. Laboratory for Climate Study, CMA, Beijing 100081
气候模式是自然科学领域中应用最复杂、最精细的计算机模式之一, 对计算资源有巨大的需求。全球海气耦合模式的大气部分最初来源于T63中期预报模式[1], 目前影响该模式运行效率的问题主要有两方面:一方面, 由于其物理过程复杂, 包含大量的科学运算, 对计算资源的需求很大; 另一方面, 经过再次开发、移植后, 部分程序结构不能充分利用现有Memory (内存)、Cache (高速缓存) 等硬件的优良特性。目前, 国家气候中心使用全球海气耦合模式进行8个样本的集合预报, 样本个数与运行平台CPU个数相同。我们对该模式进行串行优化, 不仅满足了现阶段业务需求的时效性, 也可以为将来模式的并行化打下良好的基础。
1 海气耦合模式运行平台简介本次模式调试是在IBM公司P670服务器 (集合预报系统运行平台) 上进行的, P670服务器有8颗1100 MHz POWER4 CPU, 16GB Memory。POWER4芯片采用MCM (多芯片模块结构, Multi-Chip Module), 有L1、L2、L3三级Cache。每颗CPU包含一个64 KB L1指令Cache和一个32 KB L1数据Cache; 每个芯片包含2颗CPU, 共享1.44 MB的L2 Cache; 每个模块包含4个芯片, 共有2×4颗CPU, 共享128 MB的L3 Cache。
2 海气耦合模式优化方法和过程对程序进行优化的过程中, 采用了编译器优化和手工优化两种方法。采用编译器特定的编译选项, 在编译的时候将程序的源代码尽可能的自动进行优化, 可以在很大程度上改善模式运行状况。这里我们主要介绍的是人工参与较多的手工优化方法。这种方法在一定程度上可以为编译器优化创造条件, 即先将部分语句手工修改成利于编译器识别的形式, 保证最大程度地利用编译器自身优点。同时, 手工调优方法也可以针对程序总体框架和部分数据结构进行, 这是编译器优化方法不能实现的。模式优化涉及到程序本身结构的调整和使其充分发挥运行平台软硬件资源特性两个方面。由于模式中大气部分的运算占了80 %以上的计算量, 因此针对大气模式部分进行优化, 对提高模式整体运行效率可以起到立竿见影的效果。
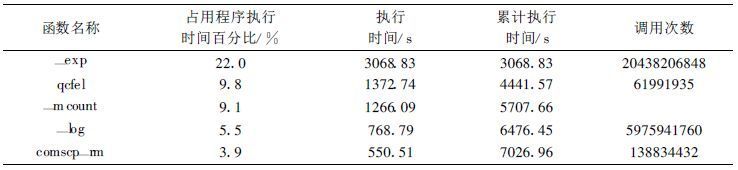
在模式优化之前, 我们采用gprof分析工具确定程序的“hot point”, 即程序中哪部分是CPU密集型代码。表1是模式优化之前积分1个月所得到的运行效率报告的部分内容, 由“调用次数”和“执行时间”可以看到程序调用_exp, _log数学运算的次数非常多, 占用了大量的CPU时间。如果单个函数执行大多数工作的话, 优化、加速该函数可能会使程序运行速度显著加快; 另一方面, 如果该函数极少调用并且无论如何都不会占用很长时间, 则对它的优化可能对总体性能不会有太大的改进。因此我们应该首先对这些占用CPU时间最多的函数进行优化。
|
|
表 1 模式优化之前积分1个月运行效率报告的部分内容 |
2.1 充分利用系统的硬件特性
通常的计算可以分为两部分:处理器实际计算的时间和对计算所需数据存取的时间, 其中后者占有相当大的比例, 也是我们可以设法改进的。Cache的使用缓解了CPU和Memory之间速度差距过大的矛盾。如图1所示, 当CPU在运算中访问某一数据时, 首先在Cache中查找, 如果在Cache中找到该数据, 称为命中; 如果没有找到, 则从Memory中查找该数据装载到Cache中。Cache和Memory交换数据是以“Cache line”为单位进行的。如果“Cache line”的大小是128字节, 则CPU每次从Memory装载连续存放的1 2 8字节数据到Cache中, 即CPU访问某一个数据时, 这个数据和与之相邻的共128字节数据会一起被装载到Cache中。我们可以对Memory中存放数据的顺序进行调整, 保证一次装载操作取到尽可能多的有用数据①, 提高Cache命中率。
① Liau Jang Shieh.Program Optimization Considerations.Presentation, 2002.

|
|
| 图 1. Cache与Memory间数据交换示意图 | |
数据在Memory中以线性方式存储。stride (跨距) 指连续的数据元素存储在Memory中的间隔, 如stride=1, 表示顺序地存取Memory中的连续数据; stride=n, 表示连续存取的数据在Memory中存放的位置相隔n个元素。从上面关于Cache特性的介绍, 我们可以知道stride=1时, 可以最有效地利用Cache行。Fortran语言的数组元素按列优先顺序存储。所有与经圈I, 纬圈J, 层次K相关的三维数组结构都是按照a (i, j, k) 排列, 应保证数组索引的顺序和循环顺序一致, 如图2所示, 使Cache中数据具有空间的连续性。

|
|
| 图 2. 循环顺序示意图 | |
2.2 充分利用高效数学函数库
在气候模式的各物理过程中, 包含大量的科学运算。操作系统标准的数学函数库中一些复杂的运算, 如除法运算将占用20~24个CPU周期, 增加CPU的开销。IBM公司在AIX系统环境中, 提供了Mathematical Acceleration Subsystem (MASS) 函数库[2]。MASS函数库分为标量和矢量两种, 可以在应用程序链接时指定②。如果使用标量MASS函数库, 不用修改源程序, 程序运行过程中, 会自动调用MASS函数库中优化过的函数而不再调用标准函数。矢量MASS函数库中的函数可以将多个相同类型的数学运算, 作为一个矢量运算一次完成, 前提是需要对源程序代码进行一定的修改。使用矢量函数库, 可以获得更好的效果 (表2)。
② Christidis Zaphiris.Tuning Fortran Programs for Optimal Performance on RISC Superscalar Processors.2003.Liau Jang Shieh.Program Optimization Considerations.Presentation, 2002.
|
|
表 2 标准函数与MASS函数使用CPU周期个数及其加速比 |

引入矢量MASS库, 需要分段改写原来的程序, 使其能够符合调用矢量MASS函数库的语句特征。在表3的例子中, 用b (i)=exp (r *log (z (i)))(127个CPU周期) 替换了b (i)=z (i)**r (183个CPU周期), 在进一步修改时, 将log (z (i)) 的操作提到循环外部, 调用矢量函数vslog (), 一次完成了对z数组中max个元素的log () 运算, 结果保存在tmp数组中。减少了log () 运算的次数, 节省了代码运行时间。同理, 可以完成对exp () 运算的修改。
|
|
表 3 使用矢量MASS函数库修改程序代码例子 |

2.3 语句优化
(1) 将公共子表达式放在括号内, 利于编译器识别。
(2) 将循环内的常量计算提到循环外, 避免不必要的重复计算。
(3) 尽量减少在循环中使用if语句。
(4) 合并小规模的循环可以有效地减少系统开销[3]。
2.4 调整模式的输出方式过去由于受计算机系统内存容量的限制, 模式输出部分采用多次I/O写盘方式, 导致程序运行速度受到I/O的限制 (I/O-bound)。目前模式运行平台的内存容量比以往有了显著的提高, 因此修改了有关数据输出部分的程序, 采用以“空间换时间”的策略, 用缓冲写的方式, 在内存中开辟了一个较大的缓冲区, 将数据暂时存放, 到一定程度后, 一次性写盘, 这样减少写盘次数, 节省模式I/O时间。
3 海气耦合模式优化结果对模式部分子程序进行修改后, 使模式的运行效率有一定提高。在没有进行优化之前, 积分1个月需要28545.94 s, 优化之后为8611.23 s, 运行效率提高了近60 %。我们对优化前和优化后的模式分别做了10年积分试验, 取得一致结果, 证明优化过程没有影响模式运行的准确性。表4是模式经过各种方法优化后积分1个月所用时间的统计, 每一项是在前一项基础上进行的, 所得结果反映的是前面各项的总体效应。
|
|
表 4 模式积分1个月运行时间统计 |

4 结语
根据以上的试验结果, 我们可以认识到, 通过应用编译器调优和手工调优等成熟的优化技术, 可以在一定程度上提高模式的运行效率, 缓解计算资源紧缺的矛盾, 这将是促进气候模式发展的有效方法之一。我们在今后的工作中要进一步开展对气候模式优化方法的研究, 使其发挥出更大的作用。
| [1] | 董敏. 国家气候中心大气环流模式——基本原理和使用说明. 北京: 气象出版社, 2001. |
| [2] | http://techsupport.services.ibm.com/server/mass.Mathematical Acceleration Subsyst em for AIX. |
| [3] | http://www.redbooks.ibm.com.IBM.Opt imization and Tuning Guide f or Fort ran, C, and C++.1993. |