 2004, 15 (2): 181-191
2004, 15 (2): 181-191


2. 山东省气象台, 济南 250031
2. Weather Serv ice of Shandong Prov ince , J inan 250031
客观要素预报是随着科学的进步、经济的发展以及人们的需求而提出来的。目前,定时、定点、定量的客观要素预报是建立在数值预报的基础上。作为集大气探测、天气学、动力气象学以及计算机、通信技术为一体的综合性科学的数值预报,并由此而生成大量可用信息,这些既包含天气发展演变,也包含某些天气现象产生的动力机理的信息,当然还包括由于种种局限而产生错误的和虚假的信息,需要气象工作者去深入研究和解读。在研究、解读过程中必然将其中的信息直接或间接(经过变换)地用于满足实际的需求。这样,数值预报产品的释用课题应运而生,它是对数值预报这一综合性的结果,运用动力学、统计学技术再一次加工、修正,使预报精度得到进一步提高,以达到有价值的要素预报水平。
实践证明通过数值预报的释用,确实使要素预报比模式直接输出的预报有了明显的提高。由图 1 可见模式直接输出的温度预报误差远远大于释用预报的结果,这就显示了释用预报的意义。而且随着经济的发展和人们生活质量的提高对天气预报的精度和时效的要求日益提高,定时、定点、定量的要素预报势在必行。因此,数值预报产品释用预报不仅是可行的,也是必要的。

|
|
| 图 1. 2001年7月4日最高温度预报误差对比分析(54区共51站) (◆—MOS,■—DMO,△—神经元,× 综合集成) | |
另外,从数值预报本身的发展过程可以预见,在资料同化、物理过程和并行计算等方面将会进一步达到更好的境界,但是数值预报的初值条件永远不可能达到真实大气状况。对各种天气过程发生发展的机理认识也是永久的课题,更何况大气并不是封闭系统,海气、陆气相互作用使大气动力过程更为复杂。这一切都说明数值预报不可能尽善尽美,对其产品释用的研究也将是一个长期的课题。数值预报产品的释用技术,不仅需要具备动力学、统计学、天气学知识,而且还需要了解各种大气探测原理及如何运用这些探测所获取的资料,熟悉资料加工的处理技术。所以,对这一高难度和高度综合性的课题必须要花相当工夫,不可掉以轻心。
经过实践证明做好要素预报最好要具备如下条件: ① 高质量的数值预报产品; ② 实况观测资料和各种探测信息; ③ 合适的预报技术路线; ④ 符合要素特点的预报方法; ⑤具备处理资料、业务试验、对比分析的软硬件环境; (存储空间、计算、网络) ⑥ 有一套功能齐全、调度灵活的人机交互系统。
国家气象中心正在朝这些方面逐步努力,不断完善。
1 MOS预报方法早在20世纪50年代末,美国气象学者克莱因[1]提出用历史资料与预报对象同时间的实际气象参量作预报因子,建立统计关系。实际应用时,假定数值预报的结果是“完全”正确的(perfect),用数值预报产品代入到上述统计关系中,就可得到与预报相应时刻的预报值,这种称为完全预报法(PP法)。它的长处可利用大量的历史资料进行统计,因此得出的统计规律一般比较稳定可靠。但是该方法除含有统计关系造成的误差外,主要是无法考虑数值模式的预报误差,因而使预报精度受到一定影响。Glathn和Low ry (1972) 提出了模式输出统计(Model Output Statist ics,简称MOS)法[2]。具体做法是从数值预报模式的归档资料中选取预报因子向量 ※t,求出预报量y t的同时或近于同时预报关系式,在实际应用时,就把数值预报输出的结果代入相应的预报关系中。
MOS方法可以引入许多其它方法难以引入的预报因子(如垂直速度、涡度等物理意义明确、预报信息量较大的因子)。它还能自动地订正数值预报的系统性误差。因此,在目前数值预报水平下,MOS的预报精度普遍优于PP方法。
MOS预报是建立在多元线性回归技术[3]基础上,研究预报量Y与多个因子之间的定量统计关系:
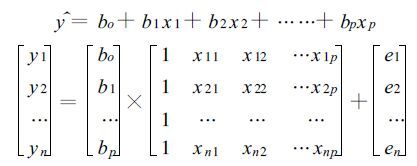
|
(1) |
式中,[Y]为预报对象、[B]为回归系数、[X]预报因子、[E]为误差距阵。为了检验预报量与预报因子之间是否确有线性关系,这里用F检验,在显著水平α下,若F >Fα则否定它假定,即认为回归关系是显著的。反之,则认为回归关系不显著。就这样,使用求解求逆紧凑算法,对因子逐步剔除和引进。其中,在用F检验时,要求误差分布,也是预报量本身的分布是正态的。因此,对于除温度、相对湿度外的要素需要进行恰当的正态变换。
在回归计算前,以图 2 界面通过设置一定的参数,如确定最小因子数、最大因子数、初设Fα值等,并以批量形式建立全国约2230个站点的最高最低温度、最高最低相对湿度、日最大风速、日降水量、总、低云量及能见度等逐要素逐时效共约22万个预报方程。

|
|
| 图 2. 建立MOS预报方程的界面 | |
2 资料的选用、处理和技术方案的确定
在进行MOS预报前,首先须确定预报量及预报时段,针对具体的预报对象进行资料选取和季节划分。为了提高预报精度,将资料按自然季节,以12月至次年2月、3~5月、6~8月、9~11月划分为冬春夏秋四季,为克服样本量偏少,也考虑季节偏早、或偏晚问题,我们将每季分别向前后跨半个月,如春季为2月16日~6月15日、夏季为5月16日~9月15日等。对于预报量,按照上节的正态变换思想,将降水量、风速、能见度等进行简单的转换,如能见度先缩小10倍,再开平方,使之向正态分布靠近。对于预报因子,由于全球T106模式资料年代较长(1995~2000年),这里仍采用T106模式输出的物理量资料。并且,在此基础上对输出格点场进一步诊断加工、组合和非线性化的处理(如平方、立方、开方等),最后约得到1000多个因子。这些因子除了1000~200 hPa各层的高度、温度、相对湿度、u、v 风和涡度、散度等基本预报场外,还包括某些层次的垂直速度、温度露点差、位温、假相当位温、湿位涡、锋生函数、螺旋度、K 指数、压能、Q 矢量、涡度散度以及由此派生出的有关水平或垂直梯度、平流、日变量等诊断物理量。这样一方面扩大因子选取的范围以供不同预报对象的选择,另一方面,也在一定程度上克服回归方程解决不了的预报对象与预报因子之间的非线性关系。在进入回归过程前,还需将因子格点场资料插值到确定的站点上,并根据与预报对象相关程度预先从1000多个因子中,依据预报因子和预报对象之间相关关系大小初选近200个因子,连同该站的实况要素资料进入回归计算。
3 预报产品及结果检验建立方程过程中,随机选取其中五分之一的样本不参加回归计算,而是作为预报试算而获得预报误差,并以此来衡量所建预报方程质量的好坏。如试算结果的误差太大,首先需要检查所用资料是否有错,然后调整因子及因子个数,以改善方程质量。方程建立后还需不断验证、改进,使预报质量稳定。日常预报时,只需将数值预报资料按原定的诊断程序计算、并插值到各个站点,代入建好的方程中,获得全国2000多个站的要素预报值。最后,据预报服务的要求,以MICAPS图或文件形式生成产品,传递到服务器上,供预报员使用。图 3 为整个MOS预报系统的业务流程。

|
|
| 图 3. MOS方法预报流程 | |
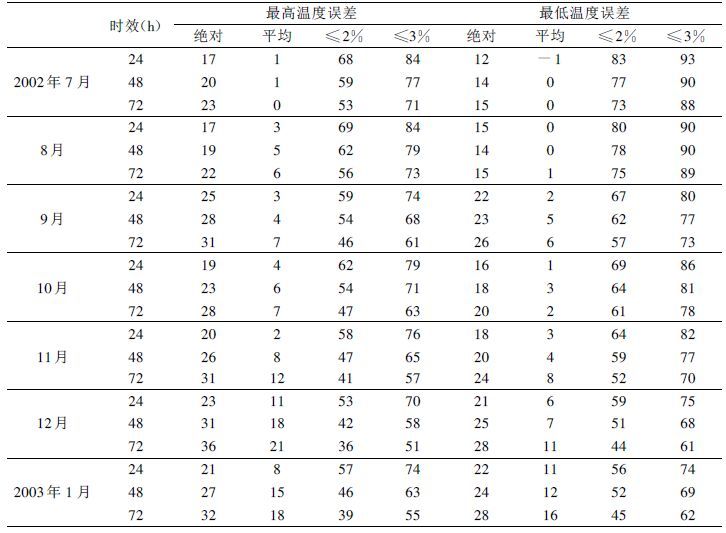
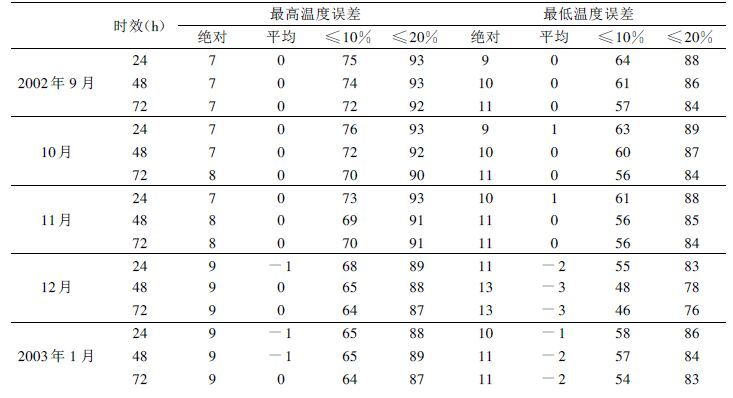
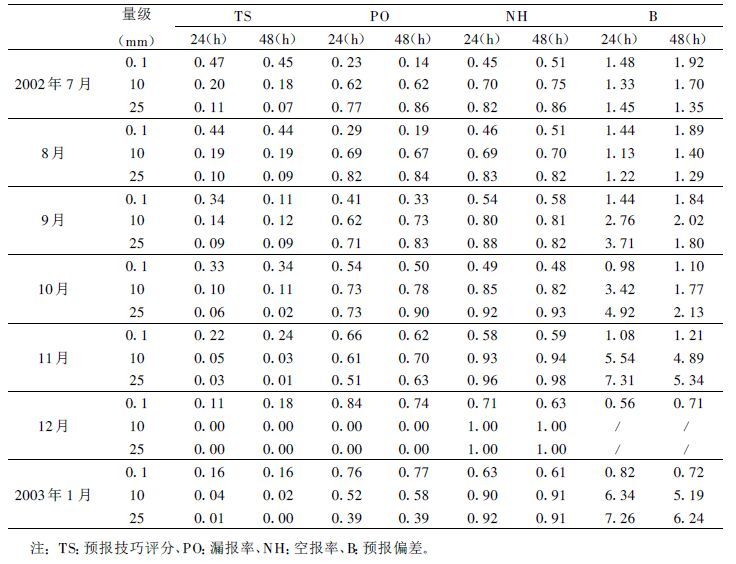
鉴于全国2000多个站点的日最大风速、云量和能见度等要素日常收集资料有困难或者可靠性较差,故在此仅列出2002年7月~2003年1月的温度、降水量和相对湿度(2002年9月开始)预报检验结果(表 1~3) 。由表可见: ① 最高温度预报平均绝对误差24~72 h分别在1.7~2.5℃、1.9~3.1℃、2.3~3.6℃; 最低温度预报平均绝对误差2~72 h分别在1.2~2.2℃、1.4~2.5℃、1.5~2.8℃; 从夏到冬温度变异逐渐增大,其预报误差也随之加大。因此,冬季比夏季误差大,最高温度比最低温度误差大; ② 绝对误差小于2℃的站数占总站数的百分比,24 h预报最低温度在56%以上、最高温度达53%以上; 48 h分别为51%和42%以上。如果以大于或等于50%的站预报误差小于或等于℃为可用预报标准,那么以这7个月平均情况而言,最高温度预报误差小于或等于2℃的平均百分率24~72 h分别是61%、52%和45%,最低温度分别是68%、63%和58%。由此可见,最低温度可用预报达72 h ; 最高温度达到48 h ; ③ 当天气形势变化较平稳时,预报误差较小,一般可不订正,当形势转变或天气状况变化较大时须对影响区进行温度订正; ④ 最高相对湿度预报24~72 h绝对误差小于或等于10%的站数占总站数的百分率为64%以上,绝对误差小于或等于20%的占87%以上; 最低相对湿度预报24~72 h绝对误差在13%以内,绝对误差小于或等于10%的站数占总站数的百分率在46%以上; 可以认为,在大多数情况下,72 h以内的相对湿度预报已达到可用预报水平。⑤ 24 h 0.1 m以上降水预报TS评分24 h在0.47~0.11,随雨季转旱季而逐渐降低; 漏报日和空报日分别为0.23~0.84、0.45~0.71,可见漏报日和空报日随雨季转旱季而增大明显,冬季降水预报参考性明显下降。中雨以上的降水预报TS评分迅速下降,达0.20以下,25 m以上降水达0.09以下。因此,中雨以上的降水量不可参考。48 h降水预报比24 h稍差,但差别不算特别明显。
|
|
表 1 全国MOS最高、最低温度预报2002年7月~2003年1月平均检验结果(单位: 0.1℃,%) |
|
|
表 2 MOS最高、最低相对湿度预报2002年9月~2003年1月平均检验结果(单位: %) |
|
|
表 3 全国MOS累计降水量预报2002年7月~2003年1月检验结果 |
要素预报误差随不同的区域也是有很大差别的,以2003年1月份为例,可以代表全年大多数月份的情况。图 4 为全国8个区24~168 h温度最高和最低预报绝对误差,可见,新疆、西北和东北预报误差较大,且随预报时效增大,预报误差也较其它地区增加明显。西藏和华南地区温度预报误差较小,尤其是我国华南沿海的站点。也就是说,在温度变化愈大的地区或季节,其温度愈难预测。

|
|
| 图 4. 全国8个区2003年1月份24~120 h温度最高(a)和最低(b)预报误差 (每组图依图例自上而下次序排列; 以下同) | |
若以个别站点的预报情况来看,在强冷空气袭击下,MOS温度预报难以反映这种剧烈的变化,有时预报误差可达到6~10℃以上。由广州、上海、北京、乌鲁木齐和哈尔滨等5个城市2003年1月~2月10日的预报和实况曲线演变(图略),可以看出,1月初的降温过程最低温度相对报得都较好,而最高温度乌鲁木齐和北京报得较差,24 h误差达6~9℃,48 h乌鲁木齐高达11℃。1月下旬的一次降温过程,北京最低温度差5℃,乌鲁木齐、上海和广州报得较好,最高温度乌鲁木齐的误差仍然很大,哈尔滨在下旬后期的这次降温过程中最高和最低温度预报都提早报了24 h,故温度预报误差也达到7~8℃。
4 MOS方程选取的预报因子分析多元回归统计方法最大的优点是可根据要求的Fα值自行选取与预报对象相关好的,而与其它因子间又相对较独立的预报因子,根据目前已经业务运行的冬季2230个站点最高最低温度1~6天的预报,所选取的因子次数按大小排列(表略)从中可得如下结论: ① 全国MOS温度预报所选因子前25个中厚度占5/25、假相当位温5/25、温度4/25、露点3/25、湿位涡2/25、水汽通量2/25、高度、可降水、沙氏指数和压能各1/25 ; 并且,这些因子绝大部分是属于850 hPa及以下低层的(占18/25) ,若将700 hPa也考虑在低层内,则几近90%以上了; ②如仅考虑72 h以内的预报,所选的因子与168 h及以内预报的因子尽管排次有所差异,但前17个因子都是相同的; 可见因子的选取随预报时效变化不大; ③ 各区域MOS温度预报所选因子与不考虑区域的全国总的统计情况相比,多数相同,1~8区所选的前25个因子属于全国所选前25个的分别为占20/25、19/25、22/25、18/25、11/25、18/25、21/25、15/25 ; ④ 第5区(高原)选的因子多数不同于其它地方,所不同的因子主要是500 hPa及以上的物理量(占13/25) ; 第8区(华南)所选因子与其它区也不尽相同,其中主要是反映风及风梯度的物理量的(占6/25) ; ⑤ 72 h以内的预报各区域所取的因子与全国的也比较一致,仅第2、5和8区较为特殊,所选的前25个因子属于全国所选前25个因子的分别各占15/25、14/25和15/25,第2区主要是与500 hPa物理量(占5/25) 有关,另两区的特征与第4条相近。
同样的方法统计秋季温度预报方程所选因子,结果与冬季的大部分相同,排列前2个因子中与冬季相同的为16个。所选因子不同之处,在于多数偏向高层如500~300 hP的因子。
由此可见,应用数值预报产品的多元回归统计方法(MOS方法),能够较好地反映预报因子与预报对象之间的关系。并且,这种关系与天气学理论以及预报员的预报经验是一致的。因此,MOS方法不仅可以作为反映预报因子和预报对象近似线性关系的一种较为成熟的统计预报方法。而且,也可作为挑选预报因子的一种有效工具。
在回归运算过程中,发现方程质量好坏与所选取因子个数有关,并非因子个数越多越好。为此,选择不同的最大和最小因子个数如表 4 所列的6个方案进行并行试验。由2002年9~11月预报结果(略)比较得出: ① 各站(时效)建不出方程的个数: 方案1~6分别为5、8、3、1、3和3个; ② 各试验预报结果表明,24~48 h 9月方案1误差最小; 方案次之,其它相差不大。10~11月24~48 h方案4误差最小或与方案1接近; 120 h以上方案4误差明显小于其他,而方案1随预报时效增大而明显变大; 误差小于2℃的百分数(占总站数)9月份24~48 h方案1比方案4略高,但96 h以上方案4较其它方案高; 对于10~11月,方案4各时效均较其它高,特别是96 h以上; ③ 3个月试验的平均情况与逐月类似,由表 4 可见: 最高、最低温度24~48 h第1方案绝对误差比较小,而其它方案比较接近; 72 h方案4与第1方案相近,且均较其它方案误差小; 96 h以上方案4明显优于其它方案,而方案1的误差增长的非常快。④ 尽管因子数多,24~48 h预报误差有时比较小,但并不是因子数越多越好,有时因不确定因素多,预报误差反而增大,特别当预报时效增大时; ⑤ 最小因子数如确定的太大,达不到F检验的要求,有时建不出合适的方程; 最小因子数少,容易达到建方程的要求,但因子数太少,又会使预报精度降低。
|
|
表 4 MOS最高、最低温度6个方案预报试验2002年9~11月的平均误差(单位: 0.01℃,%) |
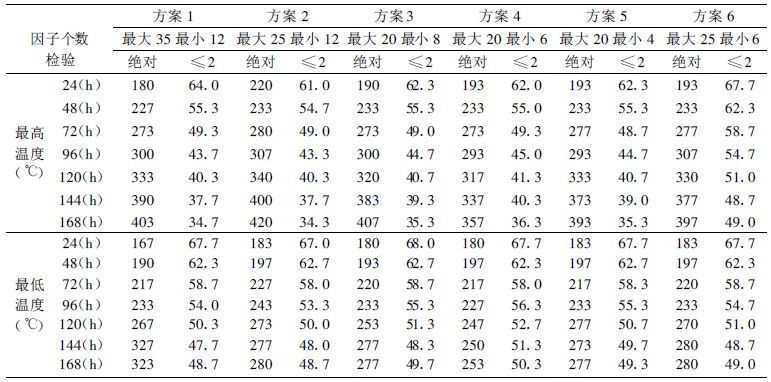
综合以上分析,对温度预报,取因子数以6~20个为最好。
方程建好后并非万事大吉,在具体预报时,发现个别站、个别时效会出现异常预报值。为了寻求其原因,这里剖析表 5 中3个站为例,发现预报出现异常,主要是选取的预报因子中含有梯度(如温度梯度、高度梯度、风的梯度)成分,并且,这些梯度因子的方程系数量级比较大,这就加大了预报的不确定性,容易造成预报值计算的异常。经过改变参数,重建方程,因子及其系数如表 6 所列,预报值就正常了。
|
|
表 5 三个有异常预报值的站所选因子情况 |

|
|
表 6 三个有异常预报值的站经重建方程后所选因子情况 |

5 与人工智能温度预报方法比较
自1999年以来,神经元网络的温度和相对湿度的客观预报一直在国家气象中心预报业务中运行。众所周知,人工神经元网络方法具有记忆和自学能力以及非线性和容错性特点,但这种方法对因子的选择无能为力。因此,与MOS预报方法比较,则各有千秋。
图 5 为2002年7~12月两种方法对最高、最低温度预报月平均绝对误差的比较,图中显示最高温度预报24 h、48 h除9月份以外,两者相近。而9月份MOS在3个时次都报得较差,72 h MOS也比人工神经元网络预报的误差略大。对最低温度预报除9月份MOS预报误差较大外,10~12月份神经元网络预报比MOS报的明显差,主要是前者存在着较大的系统误差(约1℃左右),这是今后对神经元网络方法需要解决的问题。

|
|
| 图 5. 神经元网络ANN与MOS方法最高(a)最低(b)温度预报比较 | |
6 结论及释用预报改进的途径
综上所述,MOS方法具有很多优点,是一种比较成熟的释用方法。因此在国际上被广泛地采用。通过建立国家级要素预报MOS系统,认为预报因子和预报对象的处理,建方程前的参数选择以及预报因子的选取都会影响要素预报的质量,需要做大量的细致工作。对全国2000多个站最高、最低温度、最高、最低相对湿度和降水量7个月的预报检验结果表明,前4个要素的短期预报在大多数情况下是可用的或是可参考的。但是,如前所言,当天气变化剧烈时、当出现极端的天气时,该方法与一般的统计方法类似,只能望尘莫及。对于降水这类反映大中小尺度综合效应的天气,预报效果较差,因此MOS的降水预报尚未达到可用程度。
通过对温度预报所选取的因子分析,认为以取6~20个因子预报效果最佳,所选的因子多是与温度有关的大气低层的物理量,但对有关梯度的因子使用时须特别慎重。
目前,国家气象中心MOS方法所用的因子都是T106模式的产品,今后如采用T21模式产品可望预报质量会有所提高。此外,目前一般是采用将物理量场面上的信息通过插值处理变为点信息再与预报对象建立关系。从预报员经验和一些台站制作客观预报方法的实践反映,若引进反应预报物理量场面信息(即两维信息)的因子,会使预报得到改善。因此,需要探讨作为国家级预报取得反映预报场面信息的处理方法。
再者,对短时预报而言,如何充分利用现在可得到的各种信息,如卫星遥感、雷达等探测资料与数值预报产品资料结合起来以便改进降水客观预报。
如何提高预报水平,发达国家一方面采用集合预报或超集合预报以捕捉天气的“真值”。另一方面将中小尺度模式与雷达等探测技术结合,制作飓风或强对流天气的短时预报。看来,不久的将来,在具备了各种条件后,我国也会朝这方面努力。
致谢 吴迅英高工整理全国2000多站的实况要素,国家气象中心数控室系统运行科提供T106产品,在此一并感谢。| [1] | Klein W H, lewis F. Computer forecasts of maximum and minimum temperatures. J Appl Meteor., 1970, 9:350~359. |
| [2] | Facsimile Products: Max/Min temperature forecasts. National Weather Service Forecasting Handbook No.1(July 1979) U.S. Department of commerce NOAA National Weather Service. |
| [3] | 气象统计分析与预报方法, 北京: 气象出版社, 2000. |