 2000, 11 (1): 47-54
2000, 11 (1): 47-54


我国作物遥感估产经过几年的努力, 利用气象卫星 (NOAA/AVHRR) 数据估测小麦、玉米和水稻种植面积取得了试验性的成功, 形成了具有一定业务运行价值的模型, 江南 (1995) 等人在太湖平原以TM数据提取水稻种植面积的试验基础上, 采用TM与NOAA综合利用的方法, 在江苏省范围内, 对水稻种植面积信息的提取进行研究[1].该方法综合了多种信息源, 用光谱混合分解模型对混合象元进行分解, 达到了较高的统计数量精度.吴炳方 (1995) 等人以江汉平原为主要试验区, 采用TM遥感数据提取水稻种植面积作本底资料, 然后用NOAA/AVHRR数据估计水稻种植面积与本底数据的变化趋势[2], 有较好的数量和空间位置精度.吴健平 (1995) 等人以航片作为定位资料, 利用NOAA/AVHRR数据在模糊监督分类的基础上估算上海地区的水稻种植面积, 具有较高的统计数量精度[3].
但目前的研究和试验, 较多地集中在平原地区, 方法上也较多地依赖于高分辨率的遥感数据和水稻生长期间的多幅NOAA/AVHRR影像.由于我国南方云覆盖率高和地形复杂、植被多样化, 对于业务化运行来说, 丘陵地区大范围水稻种植面积遥感信息的提取, 仍然是值得探讨的课题.
本文以浙江省作为试验区, 在GIS支持下, 利用多种地理信息, 在NOAA/AVHRR数据的基础上, 进行水稻种植面积遥感信息提取的比较试验, 包括:(1) 以传统的单象元统计分类识别方法作为分类器, 试验提取丘陵地区大范围水稻种植面积信息的可行性; (2) 试验混合象元分解方法在丘陵地区的有效性和适用性; (3) 在遥感资料的基础上, 试验结合地形数据提取水稻种植面积信息的可行性和有效性.
1 试验区的地理背景及试验资料的采集和预处理浙江省 (118°~123°E, 27°12’~30°30’N) 陆地面积1.018×105 km2, 其中丘陵山地面积占全省土地总面积73.4%, 平原占26.6%, 习惯称为“七山一水二分田”.水稻种植区主要分布在杭嘉湖平原、宁绍慈平原、金华盆地及温州、台州沿海地区, 集中了全省72%的耕地, 而浙西南山区的龙泉、庆元、遂昌、景宁、开化、淳安、临安和安吉, 水稻种植面积占各自土地总面积不足10%.
本研究所用的地理信息包括浙江省行政边界、水系、城镇居民点、地形高程、土地利用现状、植被分布等数字化图件, 这些图件利用ARC/INFO地理信息系统软件, 分别编辑整理成有针对性的GIS专题图件.
遥感影像采用1996年9月5日和1997年11月9日的两幅浙江省区域的NOAA/AVHRR数据.经过太阳高度角订正、临边变暗订正和投影变换, 在GIS支持下进行严格的配准.其误差 (RMS) 均小于0.5个象元.其中1996年9月5日的平均误差为0.47象元; 1997年11月19日的平均误差为0.46象元.
2 数字地形模型的建立在资源与环境等方面的研究中, 地形是不可忽视的重要因素, 它对区域的自然生态环境, 如植被分布、土地利用等都有重要的影响.由于本试验是针对丘陵地区水稻种植面积遥感信息提取的, 考虑到地形因素对水稻的种植分布具有控制性的影响, 以及地物光谱响应深受地形地貌等环境条件的干扰而往往出现同物异谱和同谱异物等复杂现象, 单按地物光谱特性进行解译和分类, 其可靠性会受到一定的限制.因此本试验引入数字地形模型, 结合遥感图像象元灰度数据, 对丘陵地区水稻种植面积遥感信息提取的可行性进行探讨.
数字地面模型 (Digital Terrain Models简写为DTM) 是本世纪50年代由C. L. Miller提出的.三十多年来, 随着计算机和环境遥感技术的发展, 数字地面模型得到了深入研究和广泛应用[4~8].它描述地面诸特性空间分布的有序数值阵列, 可用二维函数系列取值的有序集合来概括地表示[9]:

|
(1) |
式中, Rp为第p号地面点上的第k类地面特征信息的取值, μp、νp为第p号地面点的二维坐标, m≥1, 为地面特征信息类型的数目, n为地面点的个数.
若地面特性是地貌信息, 如高程、坡度、坡向、地面形态以及其它描述地表起伏情况的地貌因子, 则这种模型称为数字地形模型.本试验考虑到地貌因子中对水稻的种植分布影响较大的只有高程和坡度, 故只建立数字高程模型 (Digital Elevation Model, 缩写成DEM) 和数字坡度模型 (Digital Slope Model, 缩写成DSM).
2.1 数字高程模型 (DEM) 的建立由于采用的原始数据是由国家基础地理信息中心提供的等值线数字高程数据 (ARC/INFO数据), 它是以平面曲线轨迹的坐标串实现二维地理空间定位的, 在数据格式上是矢量格式, 由于卫星遥感的解译需要网格化的数字地形模型, 因而数据的位置和密度不能满足本试验专题应用的要求, 为此要进行数字地形模型的内插.
数字高程模型内插的数学基础是二元函数逼近, 即利用已知离散点集的三维空间坐标数据, 展铺一张连续数学曲面, 将任一待求点的平面坐标代入曲面方程, 可算得该点的高程数值.内插有多种方法, 其基本的数学表达式如下:

|
(2) |
式中, Q(x, y, xj, yj) 是简单的单值数学面, n为简单数学面的层数, Cj (j=1, 2, …, n) 为待定系数.
数字高程模型的内插是在ARC/INFO和IDRISI共同作用下完成的.生成的栅格图像以512×512数据集存放, 它的格式和位置信息与卫星遥感资料是匹配的.结果见图 1.

|
|
| 图 1. 浙江省数字高程模型 (DEM) 影像图 | |
2.2 数字坡度模型 (DSM) 的建立
由规则网格的数字高程模型 (DEM) 可衍生出许多地貌因子, 如坡度、坡向、坡度变化率等.其中地面坡度与水稻种植分布有密切联系, 所以我们选用地面坡度作为水稻种植分布的一个地貌限制因子.
生成的数字坡度模型也以512×512数据集存放, 结果见图 2.

|
|
| 图 2. 浙江省数字坡度模型 (DSM) 影像图 | |
3 分类识别方法的选择
传统的基于单象元分类的统计学方法 (如最大似然法等), 它主要根据地物光谱的平均量, 应用统计分类识别方法, 对象元进行逐点判别.后来发展的混合象元分解方法, 是针对遥感图像含混度大的情况提出的, 在理论上既有不同于单象元面积信息提取的方法, 又有某些沿用之处.从方法论的角度看, 混合象元分解方法可分为二类:一是光谱混合模型法, 如江南 (1995) 等人利用线性光谱混合模型提取江苏省水稻种植面积信息[1]; Shimabukuro (1991) 和Smith (1990) 等人用线性混合模型在陆地卫星资料的基础上评价森林结构变化和沙漠地区植被覆盖情况[10, 11], Cross (1991)、Hlavka (1995) 和Quarmby (1992) 等采用NOAA/AVHRR资料, 进行森林覆盖及再生长情况评价和作物面积测算[12~14]; 二是Fangju Wang在概率统计分类中的最大似然法的基础上引入模糊数学中的隶属度思想的模糊监督分类法[15].如吴健平 (1995) 等人利用模糊监督分类在NOAA/AVHRR数据的基础上提取上海地区水稻种植面积[3].
基于单象元分类的统计学方法中, 最大似然法由于有严密的理论基础, 对于呈正态分布的数据, 判别函数易于建立, 而且有很好的统计特征[16, 17], 因而, 在遥感数据的分类识别中已成为一种有效的方法[18~20].
基于光谱混合模型的象元分解法是建立在象元灰度线性可加的理论基础上的, 它的基本模型为:

|
(3) |
其中DNk为象元第k幅图像的灰度值 (k=1, 2, …, n), fi为该象元中第i类地物所占的比例 (I=1, 2, …, m), Rki为第i种典型地物的灰度值, Ek为拟合误差.若令E=(E1, E2, …, En) T, 则当‖E‖ (通常取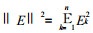
方程 (3) 实际上是带约束条件的线性方程组, 它的求解取决于地类的种数, 地类越多, 所需不同期的遥感图像就越多, 这对于大范围的水稻种植面积提取业务来说, 是不容易满足的.因此它的实用性受到一定的局限.
出于业务化运行的考虑, 本研究选用基于单象元分类的最大似然法、最小距离法和基于混合象元分解的模糊监督分类法进行试验, 分析它们在丘陵地区大范围提取水稻种植面积的可行性和有效性.
4 土地利用分类本试验地类划分的原则主要依据一是研究区实际土地利用特点, 二是AVHRR数据的光谱特征.根据浙江省土地利用现状图的分类, 地类有稻田、旱地、菜地、果园、茶园、桑、林地、草地、内塘、江海涂、盐场、棉地棉稻轮作地、麻地麻稻轮作地、城镇居民地、水域.为便于分类及结合AVHRR的光谱特征, 在上述分类的基础上进行一些归并.由于采用的两幅AVHRR图像都在浙江省南部局地山区存在云体 (水稻含量很低), 在分类时, 我们将云体直接当作一类来处理; 另外在实际分析AVHRR影像资料时, 存在一类光谱特征较明显的地物, 经过实地调研, 确定为河网区地物, 也作为单独一类来处理.因此, 最终将地类划分为以下几个大类:稻田、林地 (包括果园、茶园、桑地、林地)、旱地 (包括菜地、草地、盐场)、水域、城镇居民地、云体、水网地物等7类.
5 水稻种植面积遥感信息提取的比较试验结果及分析 5.1 纯光谱分类的结果与分析将AVHRR的1~5通道数据, 分别用最大似然法、最小距离法和模糊监督分类法进行分类识别, 结果见表 1.从表 1可看出, 仅利用光谱值作为分类的数据, 最大似然法和模糊监督分类的分类精度都可达到92%以上, 模糊监督分类的精度略高于最大似然法, 1996年和1997年的分类精度分别为96.8%和98.7%, 且稳定性要比最大似然法好.而最小距离法的分类精度则较差, 最大的分类精度不过76.4%, 因而该方法难以满足业务化运行的精度要求.
|
|
表 1 分类识别方法的试验结果 |

5.2 数字地形模型作为辅助数据层参与分类的结果与分析
为了提高分类精度, 人们作了许多尝试, 主要的有在GIS支持下, 增加光谱之外的辅助信息和改进分类识别方法.但在卫星传感器的空间分辨率保持不变的情况下, 单纯利用只包含有限信息的多光谱图像, 分类精度必然会有一个极限, 并且从以往的情况来看, 往往是虽然分类的数字精度可以满足要求, 但其结果却缺乏空间意义.因此要进一步提高分类精度则必须在多光谱分类过程中加入一些其它辅助数据[20, 21].
地形是最重要的也是用得最多的一种辅助数据[5~8], 它对地物的分布, 比如植物种类和植被密度、土壤性质、地质条件等起着重要的作用, 因而, 在分类中可利用地形来帮助区分地物类别, 提高分类精度.
利用数字地形信息参与分类有许多方法, 如Hotchinson曾总结过修改先验概率方法和分层分类方法[8].修改先验概率方法是利用地形分层随机抽样, 决定地形分布概率模型在采用最大似然法分类器的过程中, 用地形信息修改各种地类在某象元出现的先验概率.这种方法要求深入分析地面调查实况, 对大范围的业务化运行来说, 是难于实现的; 分层分类是利用地形辅助数据对光谱数据进行预分类, 各类地物也相应地按地形分组, 按类合并, 这种方法的实质是预先将非某地物的分布区从光谱数据中剔除掉, 在操作上较复杂.
本试验将数字地形信息作为逻辑通道, 直接参与遥感光谱数据的分类.将数字高程模型 (DEM) 和数字坡度模型 (DSM) 作为数据层, 形成CH1~CH5、DEM和CH1~CH5、DSM等两种组合类型进行试验分类, 试验结果见表 2.表 2表明, 地貌因子参与分类, 地面坡度的分类效果比数字高程 (DEM) 的分类效果要好得多, 地面坡度的参与分类使1996年的分类数量精度从92.8%提高到98.7%, 1997年的精度也稳定在98%的水平.从表 2还可看出, 引进地貌因子不仅改善了面积测算的数量精度, 而且对估算的种植面积的年际变化趋势也有较好的改善, 即用最大似然法估算的1996年和1997年的变化趋势是增加趋势 (由1996年的11742.8 km2增加到1997年的12452.6 km2), 这与实际不符, 而引入坡度因子进行分类后, 1996年和1997年的变化趋势是下降的 (由1996年的12812.5 km2下降到1997年的12806.7 km2), 这与实际是相符的.由此可看出, 坡度因子作为遥感影像分类的辅助数据, 对于提高丘陵地区水稻种植面积的遥感信息提取是有实际意义的.
|
|
表 2 地貌因子参与分类的结果 (最大似然法) |

直接用高程数据 (DEM) 参与分类, 效果不如坡度数据, 其原因可能是种植在不同海拔高度的水稻, 在分类过程中被认为是不同的类型.而坡度因子则较好地反映了水稻种植分布的地形条件.
5.3 分类的空间位置精度分析在我国, 水稻种植面积信息遥感提取的精度分析, 较少使用空间位置精度的概念, 这主要是由于NOAA/AVHRR数据的低空间分辨率的原因.空间位置精度分析是以分类的最小单元 (通常是象元) 为检验单元, 通过与参考图上对应单元进行对照来确定分类精度.在实际工作中, 通常采用抽取一定数量的样本来进行[23], 分类结果的空间精度可以用抽样象元中实际类型与分类类型的数量来表示.
本试验采用的参考数据为浙江省土地利用现状数字化图件.取置信水平为95%, 误差允许范围为±1%, 计算出的最少样本数为3456.实际操作时, 在研究区取3600个抽样点, 得到的抽样数据见表 3.从表 3可以看出, 1996年和1997年的空间精度分别为73.8%和75.3%, 引入坡度因子进行分类后, 1996年和1997年两年的空间位置精度分别提高到81.2%和83.1%.由此可见, 坡度因子参与分类, 不仅可以使分类的数量精度提高, 而且还可以使分类的空间位置精度提高, 因而提高了分类的可靠性.
|
|
表 3 稻区分类的空间位置精度分析表 |

混合象元分解方法得到的结果不是整个象元的从属类型, 而是每个象元之中各种地类光谱所占的比例.由于一个象元内部各种地类的位置无法确定, 因而这种方法的空间位置精度无法计算.本试验只计算了模糊监督分类的分类数量精度.
6 结论和讨论(1) 在丘陵地区的地形条件下, 引入坡度因子作为遥感影像分类的辅助数据层, 参与分类, 可以有效地提高分类精度和分类质量 (如分类精度的稳定性、可靠性、较好的空间位置精度等).其原因是地面坡度较好地体现了水稻种植分布的地形条件, 直接反映了水稻种植的位置信息.
(2) 最大似然法具有坚实的理论基础, 在GIS的支持下, 可充分利用多种地理信息, 获得满意的结果.模糊监督分类法由于是在最大似然法的理论上加以外延, 因而可看作是最大似然法的一种延伸, 它在某种程度上可突破卫星传感器空间分辨率的限制, 将象元内的空间信息提取出来.试验结果表明模糊监督分类的分类精度优于最大似然法, 它对象元的分解不需要多幅不同期的卫星影像支持; 可靠性也较强, 是较适合于业务化运行的分类方法.
(3) 本试验采用的土地利用参考数据来源于土地利用现状图, 训练样点的选取、样点的净化程度和空间位置精度都依赖于土地利用现状图的分辨率及有效性, 在业务化运行过程中, 如能采用强有力的地理定位工具, 则结果的可靠性和客观性定会有所改观.
| [1] | 江南, 何隆华, 王延颐. 江苏省水稻遥感估产研究. 长江流域资源与环境, 1996, 2, (5): 160–165. |
| [2] | 吴炳方, 刘海燕. 水稻种植面积估计的运行化遥感方法. 遥感学报, 1997, 1, (2): 1–8. |
| [3] | 吴健平, 杨星卫. 用NOAA/AVHRR数据估算上海地区水稻种植面积. 应用气象学报, 1996, 7, (2): 190–194. |
| [4] | 陈军. DTM在遥感影像分类中的应用. 武汉测绘学院学报, 1984, 5, (1): 36–42. |
| [5] | Jones A R, Settle J, Wyatt B K. Use of digital terrain data in the interpretation of Spot-1 HRv multispectral imagery. Int. J. Remote Sens, 1988, 9, (4): 669–682. DOI:10.1080/01431168808954885 |
| [6] | Schut C. Review of Interpolation Methods for Digital Terrain Models. 13th Congress of the Intersociety for Photogrammetry, Helsinki, 1976, 346~363. |
| [7] | Frelerick, Doyle J. Digital terrain models:An overview. Photogram. Eng. Remote Sens, 1978, 44, (12): 235–252. |
| [8] | 傅乐元. 数字地形模型及其地形分析. 遥感信息, 1986, 5, (2): 34–40. |
| [9] | 柯正谊, 何建邦, 池天河. 数字地面模型. 北京: 中国科学技术出版社, 1993: 1–11. |
| [10] | Shimabukuro Y E, et al. The least-squares mixing models to generate fraction images derived from remote sensing multispectral data. IEEE Trans. Geosci. Remote Sens, 1991, 29, (1): 16–19. DOI:10.1109/36.103288 |
| [11] | Smith M O, et al. Vegetation in deserts:A regional measure of abundance from multispectral images. Remote Sens. Environ, 1990, 31, (2): 1–26. |
| [12] | Cross S M, et al. Subpixel measurement of tropical cover using AVHRR data. Int. J. Remote Sens, 1991, 12, (5): 1119–1129. DOI:10.1080/01431169108929715 |
| [13] | Hlavka C A, et al. Unmaxing AVHRR imagery to assess clearcuts and forest regrowth in Oregon. IEEE Trans. Geosci. Remote Sens, 1995, 33, (3): 788–795. DOI:10.1109/36.387594 |
| [14] | Quarmby N A, et al. Linear mixture modeling applied to AVHRR data for crop area estimation. Int. J. Remote Sens, 1992, 13, (3): 15–25. |
| [15] | Fangju Wang. Fuzzy supervised classification of remote sensing images. IEEE Trans. Geosci. Remote Sens, 1990, 28, (2): 194–201. DOI:10.1109/36.46698 |
| [16] | 李四海. 提高遥感数据分类应用性的有效途径. 国土资源遥感, 1995, 8, (12): 1–7. |
| [17] | Jayantha E, Siamak K. Hierarchical maximum-likelihood classification for improved accuracies. IEEE Trans. Geosci. Remote Sens, 1997, 35, (4): 810–816. DOI:10.1109/36.602523 |
| [18] | Bolstad P V, Lillesand T M. Rapid maximum-likelihood classification. Photogram. Eng. Remote Sens, 1991, 57, (3): 64–74. |
| [19] | Maselli F, Conese C, Petkov L, Resti R. Inclusion of prior probabilities derived from a nonparametric process into the maximum-likelihood classifier. Photogram. Eng. Remote Sens, 1992, 58, (4): 201–207. |
| [20] | Mather P M. A computationally-efficient maximum-likelihood classifier employing prior probabilities for remotely sensed data. Int. J. Remote Sens, 1993, 14, (5): 1223–1342. |
| [21] | 杨凯, 陈军. 辅助数据在遥感影像计算机分类中的应用. 环境遥感, 1986, 1, (3): 56–65. |
| [22] | Ray S S, Pokharna S S, Ajai, et al. Cotton production estimation using IRS-1B and meteorological data. Int. J. Remote Sens, 1994, 15, (5): 1085–1090. DOI:10.1080/01431169408954141 |
| [23] | 吴键平. 遥感数据分类结果的精度分析. 遥感技术与应用, 1995, 6, (2): 45–56. |