
An object detection method of underwater image based on improved Deformable-DETR
-
摘要: 针对由于水下复杂环境造成的目标检测效果较差、检测精度较低的问题,基于Deformable-DETR算法提出一种改进的水下目标检测算法Deformable-DETR-DA。使用空间注意力模块结合标准Transformer块设计了一个用于增加模型深度的深度特征金字塔(deep feature pyramid networks,DFPN)模块,将其嵌入到模型中提高模型对深层纹理信息的提取能力。使用注意力引导的方式对原模型中编码器部分进行改进,加强了对特征信息的聚合能力,提高了模型在复杂环境下的检测能力。针对URPC数据集,模型各交并比尺度的平均准确度(average precision,AP)为39.5%,相比原模型提升1%,与一些DETR(detection transformer)类的模型相比,不同目标尺度的平均准确度均有1%~4%左右的提高,表明改进的模型能够很好解决复杂环境的水下目标检测的问题。本文提出的模型可作为其他水下目标检测模型设计的参考。
-
关键词:
- 水下光学图像 /
- Deformable-DETR /
- 目标检测 /
- Transformer /
- 注意力机制 /
- 深度学习 /
- 图像处理 /
- 残差网络
Abstract: Aiming at the problem of poor object detection effect and low detection accuracy caused by complex underwater environments, an improved underwater target detection algorithm Deformable-DETR-DA is proposed based on the Deformable-DETR algorithm. Using the spatial attention module and the standard Transformer block, a DFPN block is designed to increase the depth of model, and the DFPN block is embedded into the model to improve the ability of the model to extract the deep texture information. The encoder part of the original model is improved by using attention guidance, which strengthens the aggregation ability of feature information and improves the detection ability of the model in a complex environment. For the URPC dataset, the average precision(AP) of each intersection over union scale of the model is 39.5%, which is 1% higher than the original model. Compared with some DETR-like models, the average precision of different object scales is improved by 1%~4%, which shows that the improved model can well solve the problem of underwater object detection in complex environments. The model proposed in this paper can serve as a reference for the design of other underwater object detection models. -
水下目标检测技术是水下探测任务中的重要技术[1]。由于水下环境的复杂性和待检测目标的多样性,常规的目标检测方法在水下环境中通常缺乏足够的能力处理这些问题[2]。深度学习技术在多个领域的任务中表现出了良好的效果。在目标检测领域,常见的深度学习算法经过多年间不断的更新和优化,已经可以在多种目标检测任务上表现出良好的检测效果[3-5]。基于区域的卷积神经网络(regions with CNN features,RCNN)系列[6-8]目标检测方法是将卷积神经网络(convolutional neural networks, CNN)引入到检测领域的开山之作,其引入的卷积网络能大幅提升检测的准确度。在此之后,YOLO(you only look once)系列[9-12]的检测方法是应用较为广泛的一类检测技术,有着较快的推理速度和较好的检测精度,被广泛用于各种各样的检测任务中。类似的一阶段或二阶段检测方法还有很多[13-14],大多会引入预先设计好形式的锚框或者感兴趣区域作为检测的基准位置。近些年来,随着硬件条件不断的提升,训练一个较为复杂的模型已经成为检测任务的常态了[15-18],将Transformer模块由自然语言处理任务引入到检测中的DETR(detection transformer)类方法就是这样的类型。DETR类方法通常有着简单的模型结构设计和相对较多的模型参数,其各个部分之间较低的耦合性使其很容易同一些性能较好的单个组件或者模块进行结合,以提升模型整体的性能。除此之外,DETR类的方法没有预设的锚框,其采用查询向量作为一种软锚框的形式以获取目标的位置。但是由于这样的设计,软锚框通常不能较快的收敛,这导致了原始的DETR方法通常需要较长的训练时间。为了解决这样的问题,研究者们提出了较多的改进方法,这使得模型的收敛速度大大提升。在大量的改进弥补方法自身存在的一些问题后,DETR类方法成为一类较为新颖且相对成熟的一类检测方法。目前很少有研究者将这一类的方法引入到水下检测的任务中。本文将其引入水下目标检测并进行改进,以提高模型在水下检测任务中的性能。
1. 水下光学图像目标检测方法介绍
为了实现水下光学图像目标检测任务,解决由于水下复杂环境造成的检测精度低的问题,本节将主要介绍基于改进Deformable-DETR水下检测模型设计。
1.1 改进的Deformable-DETR模型总述
Deformable-DETR模型是DETR模型的一个性能良好的改进模型Deformable-DETR-DA。本文以此为基础改进并设计水下检测模型。模型结构主要包含主干网络、深度特征金字塔、改进编码器组、解码器组和用于预测的预测头。具体结构如图1所示。模型输入经过预处理后的图像,由主干网络部分进行特征提取,为了平衡模型的参数量和训练时间,这里选择ResNet-50作为模型的主干网络,并输出4、8、16、32倍下采样的特征图。经过一个用于增加模型深度的深度特征金字塔模块后,将多级特征分别进行序列化后进行拼接,获得特征向量。在获得特征图的同时也对其进行位置编码并序列化及拼接,这里沿用了可学习位置编码的形式。将特征向量和编码向量叠加输入到添加了注意力引导模块的编码器进行特征的强化,并将结果输入解码器中进行预测,最终获得模型预测的预测框和类别,经过用于匹配的匈牙利算法获得最后的检测结果。
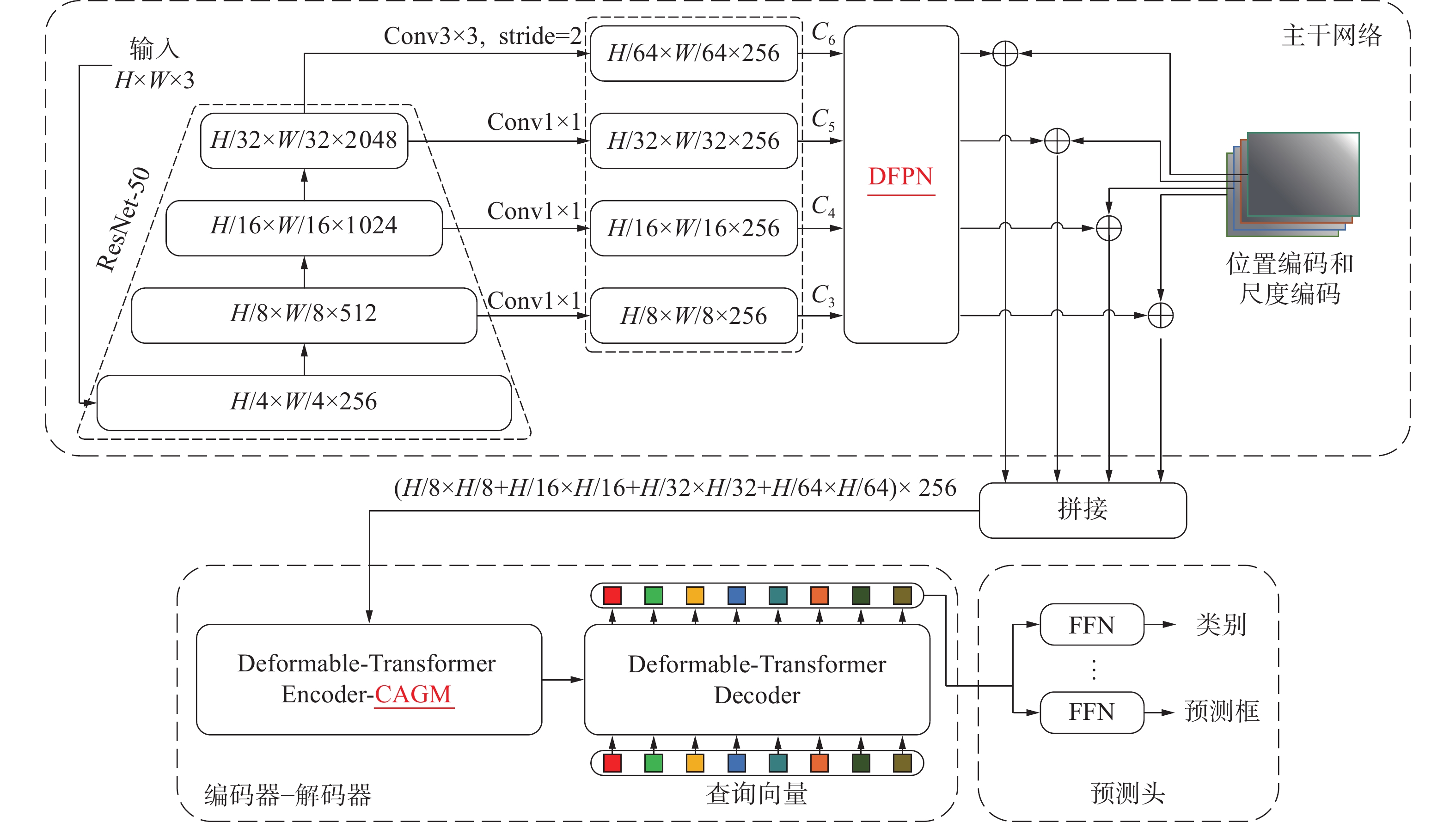 图 1 改进后的 Deformable-DETR-DA 模型结构
图 1 改进后的 Deformable-DETR-DA 模型结构 下载:
全尺寸图片
下载:
全尺寸图片
1.2 深度特征金字塔模块
在模型中设计了一个容易嵌入的深度特征金字塔(deep feature pyramid networks,DFPN)模块,用于增加模型的深度,同时此模块也容易嵌入到其他的模型中以获得性能上的提高。
DFPN部分的主要结构如图2(a)所示,采用了通常特征金字塔的结构设计,使用标准的Transformer编码器块作为深度特征的强化部分,这里设置N为6。获得的深度强化特征经过上采样后同输入的多级特征进行融合,经过嵌入空间注意力模块进行融合,多次重复这个过程直到获得深化的多级特征。其中,用于融合特征的空间注意力模块是深度可分离卷积同SAM[19]模块的结合,其结构如图2 (b) 中的空间注意力(spatial attention,SA)模块所示。SA模块首先是由一个3×3的深度可分离卷积作为输入部分,输出的结果形式为(b, c, h, w), 分别经过通道方向的均值池化和最大值池化后进行维度拼接,获得通道方向经过压缩的结果,为(b, 2, h, w)。接下来经过1×1卷积和Sigmoid激活函数后,获得空间维度的注意力权重,为(b, 1, h, w)。将注意力权重和深度可分类卷积的输出相乘即可获得注意力强化后的特征。将强化过的特征由残差连接后得到的结果即为模块输出。
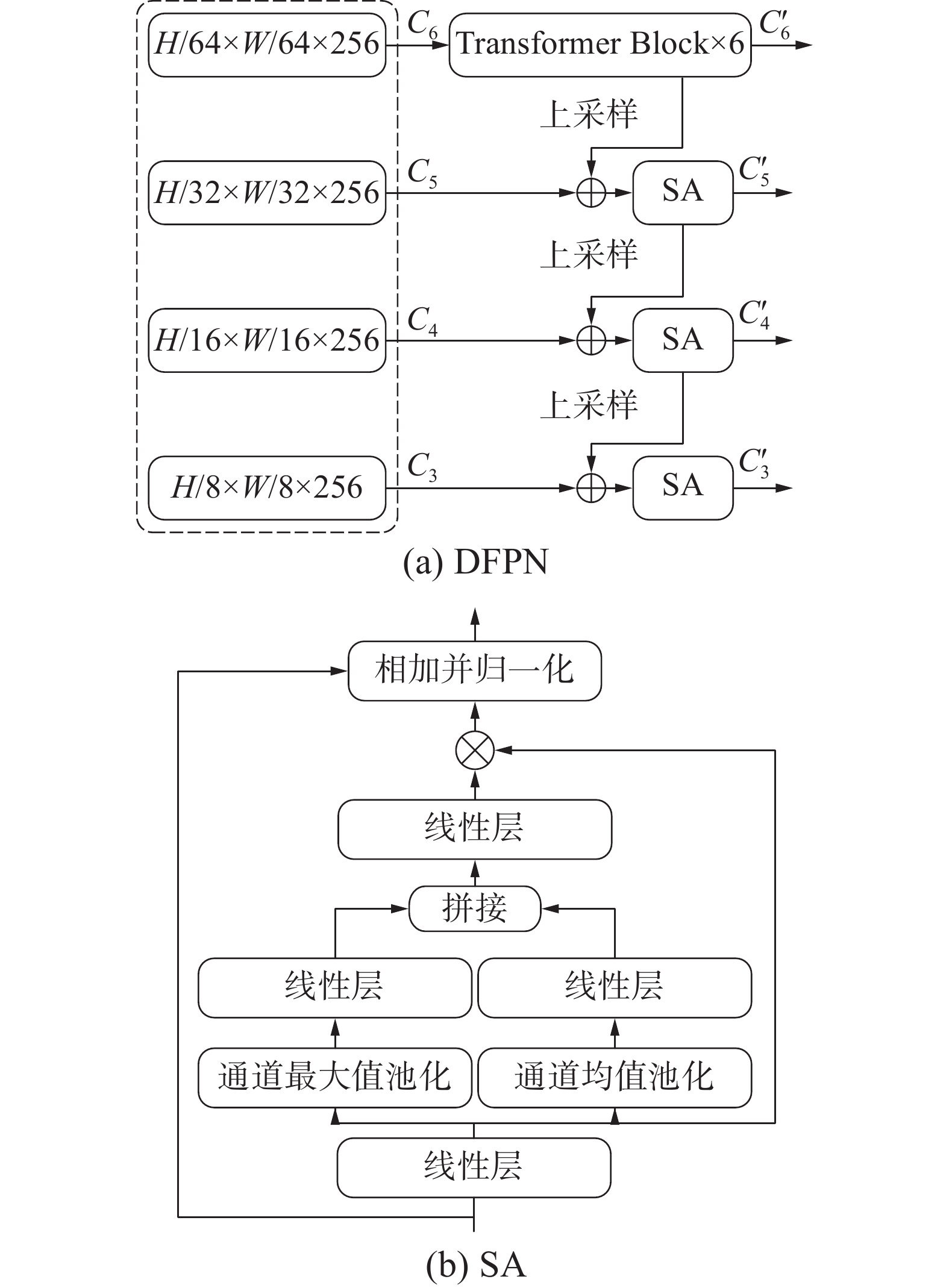 图 2 DFPN结构及空间注意力结构下载:
全尺寸图片
图 2 DFPN结构及空间注意力结构下载:
全尺寸图片
SA部分的计算过程如下:对于特征图
${\boldsymbol{C}} \in {\mathbb{R}^{N \times C}}$ ,线性映射后分别经过通道方向的一维自适应最大值池化层和一维自适应均值池化层,获得2个尺寸为$N \times 1$ 的向量${{\boldsymbol{w}}_1}$ 和${{\boldsymbol{w}}_2}$ 。将二者在通道方向进行拼接,而后经过全连接层压缩通道维度,获得空间注意力权重向量, 并使用Sigmoid函数对其规范化。空间注意力权重生成过程如下式所示:$$ {{\boldsymbol{w}}_1} = {\text{linear}}({\text{MaxPooling}}({{\boldsymbol{C}}_{{\text{in}}}})) $$ $$ {{\boldsymbol{w}}_2} = {\text{linear}}({\text{AvgPooling}}({{\boldsymbol{C}}_{{\text{in}}}})) $$ $$ {{\boldsymbol{W}}_{\text{C}}} = {\text{Sigmoid}}({\text{linear}}({\text{concat}}[{{\boldsymbol{w}}_1},{{\boldsymbol{w}}_2}])) $$ 式中:
${{\boldsymbol{C}}_{{\rm{in}}}}$ 由${\boldsymbol{C}}$ 经过线性映射获得。将获得的权重
$ {{\boldsymbol{W}}_{\text{C}}} $ 同特征向量$ {{\boldsymbol{C}}_{{\text{in}}}} $ 相乘获得强化空间关注的特征$ {{\boldsymbol{C}}_{{\text{out}}}} $ ,如下式所示:$$ {{\boldsymbol{C}}_{{\text{out}}}} = {{\boldsymbol{C}}_{{\text{in}}}} \cdot {{\boldsymbol{W}}_{\text{C}}} $$ 1.3 使用注意力引导改进的编码器模块
DETR类模型中编码器部分主要的作用是增强主干网络部分提取的多尺度特征,而在编码器中起主要作用的是多头自注意力(multi-head self-attention, MHSA)部分。虽然MHSA能够使模块对特征中的重要部分给予更多的关注。但是,MHSA的设计上仍然存在一些问题。MHSA的计算过程可以分解成几个部分:由输入向量生成用于计算的
${\boldsymbol{Q}}$ 、${\boldsymbol{K}}$ 、${\boldsymbol{V}}$ 共3个向量;分别将${\boldsymbol{Q}}$ 、${\boldsymbol{K}}$ 、${\boldsymbol{V}}$ 多次线性映射而后计算自注意力,即“多头”设计;将每个“头”计算获得的注意力结果进行通道维度的拼接;对拼接后的结果进行线性映射,获得输出。在整个过程中,“多头”设计能够较明显地降低计算时所需的内存。但是,“多头”设计同样会使高维特征的不同通道组之间降低关联性,不同的“头”对物体关注的倾向性不同,这制约了编码器部分对特征有效部分的增强和特征整体的关注性。DETR类模型在注意力部分后级联了一个前馈神经网络(feed-forward networks,FFN)结构,用于调整通道特征。普通的FFN结构虽然能扩展和重组单一特征并聚合信息,但其忽略了某一通道或某一“头”的特征的重要程度。Deformable-DETR模型作为DETR类模型中比较高效的模型之一,其MHSA部分使用可形变注意力进行改进,但类似“多头”和FFN的设计仍然有所保留,因此Deformable-DETR模型同样存在上述问题。为了解决这个问题,提高模型的精度和鲁棒性,Deformable-DETR-DA模型设计了一个改良的编码器块进行替代。改良编码器块的具体结构如图3所示,其将原始Deformable-DETR模型的编码器部分转变成一个全注意力结构。具体来说,改良编码器块的结构设计上仍然保留了多尺度可形变注意力部分,用于在空间维度强化特征。不同的是,改良编码器块在FFN部分额外添加了一个通道注意力引导结构,用于在通道维度聚合特征信息。这样的设计能促进FFN部分形成更多的特征组合形式,使模块充分考虑每个通道特征的重要性,并赋予重要信息更高的权重。受卷积注意力机制模块启发,结合通道注意力引导机制(channel attention guided mechanism,CAGM)的通道注意力引导前馈神经网络FFN-CAGM如图4所示,对应的计算过程如下:
 图 3 改良编码器部分结构下载:
全尺寸图片
图 3 改良编码器部分结构下载:
全尺寸图片
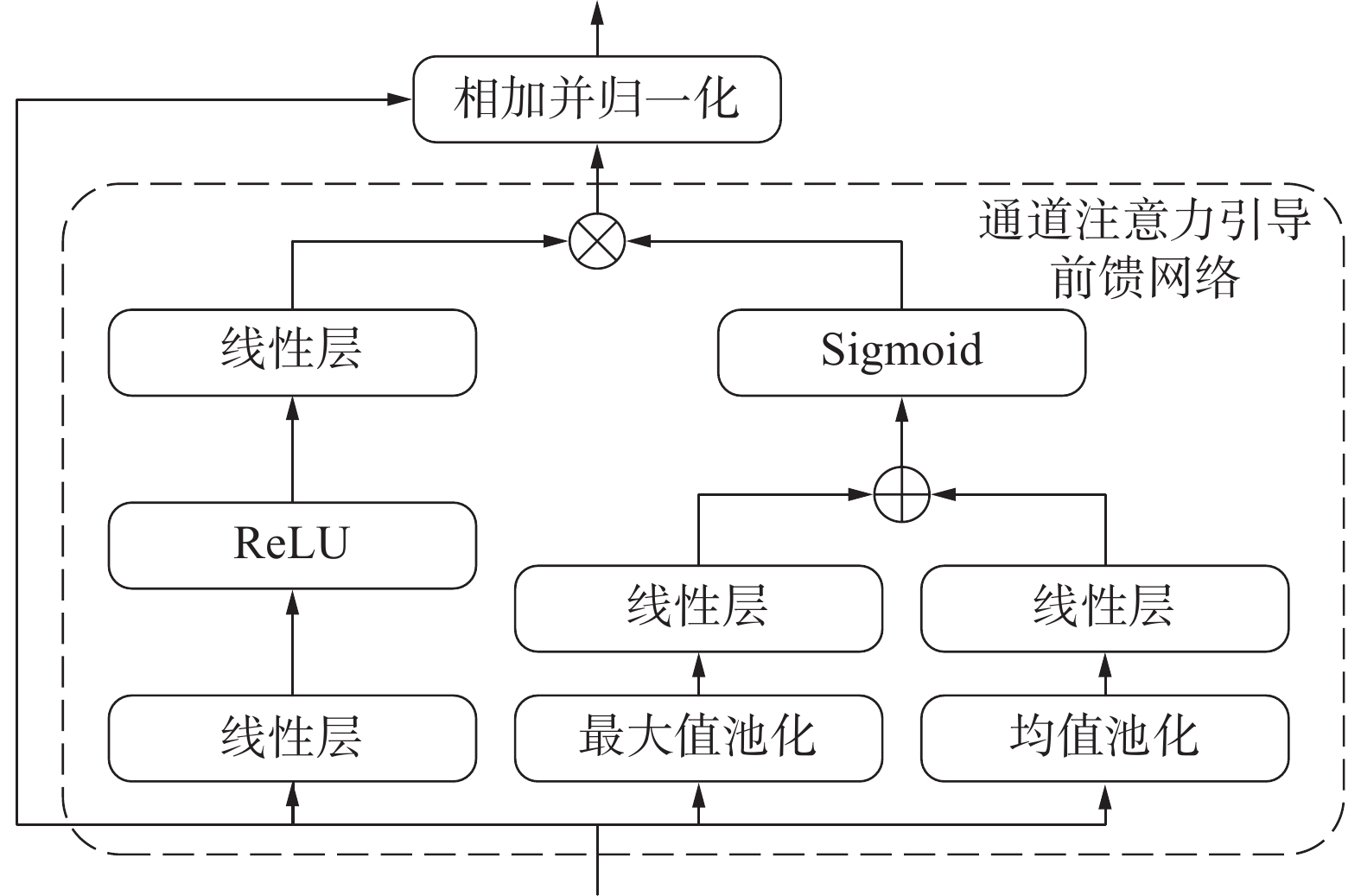 图 4 通道注意力引导前馈神经网络部分结构下载:
全尺寸图片
图 4 通道注意力引导前馈神经网络部分结构下载:
全尺寸图片
模块使用多尺度可形变注意力部分的输出作为FFN-CAGM部分输入的特征向量
${\boldsymbol{D}} \in {\mathbb{R}^{N \times C}}$ ,其中N指的是输入特征向量的长度,C表示特征向量的通道数目。特征向量${\boldsymbol{D}}$ 分别经过一维的自适应最大值池化层和一维的自适应均值池化层,并分别经过全连接层进行映射,获得带有不同通道权重信息的向量$ {{\boldsymbol{D}}_1} $ 和${{\boldsymbol{D}}_2}$ ,将二者叠加后作为特征向量${\boldsymbol{D}}$ 通道方向的权重,并使用Sigmoid函数对其进行规范化。通道权重的生成过程如下式所示:$$ {{\boldsymbol{D}}_1} = {{\rm{linear}}} ({{\rm{MaxPooling}}} ({\boldsymbol{D}})) $$ $$ {{\boldsymbol{D}}_2} = {{\rm{linear}}} ({{\rm{AvgPooling}}} ({\boldsymbol{D}})) $$ $$ {{\boldsymbol{W}}_{{D}}} = {{\rm{Sigmoid}}} ({{\boldsymbol{D}}_1} + {{\boldsymbol{D}}_2}) $$ 输入向量
${\boldsymbol{D}}$ 还需要经过FFN处理。FFN部分由两个全连接层结合一个线性整流(rectified linear units,ReLU)激活函数组成,FFN首先对输入向量${\boldsymbol{D}}$ 的通道维度进行扩展,其中,通道维度的扩展系数设置为4。扩展后的向量${\boldsymbol{D}}$ 经过激活函数处理后增添了非线性因素,再次通过全连接层将通道维度压缩至初始大小,输出FFN处理后的特征向量。这一过程中,FFN对向量${\boldsymbol{D}}$ 的特征进行了丰富和重组。最后,将处理后的特征向量与权重$ {{\boldsymbol{W}}_{\text{D}}} $ 相乘,实现通道注意力引导的过程。这个过程如下式所示:$$ {{\boldsymbol{D}}_{{\rm{out}}}} = {{\rm{FFN}}} ({\boldsymbol{D}}) \cdot {{\boldsymbol{W}}_{\text{D}}} $$ 2. 水下目标检测实验
2.1 水下目标检测数据集及数据预处理
本文使用URPC2020水下目标检测数据集作为实验用的数据集。URPC2020是由大连市人民政府和鹏城实验室等共同主办的URPC 2020(大连)水下目标检测算法赛中提出的真实水下环境目标检测数据集,数据来源于真实水下环境中拍摄,涵盖包括海参、海胆、扇贝和海星4个目标类别。本文使用的训练集共有5543张图片,测试集共有800张图片。
本文的模型使用多尺度训练的方式。模型首先使用随机翻转。随机选择以下2种方式:一种是使用随机图像大小调整。这个过程先将图像的短边调整大小,随机选择[480, 768]中每隔32的取样数值之一作为短边的长度,长边依照原图像的纵横比进行放缩。设置最大长边尺寸为768,若放缩后图像长边大于768,则改变图像大小调整方式为长边调整至768,短边依原图纵横比进行调整。另一种方式是先使用随机尺寸调整,将图像的短边调整至[400, 500, 600]其中之一,长边依比例调整。之后使用随机剪裁,将剪裁的结果依照第一种图像大小调整的方式再次进行调整,获得输入图像。模型使用上述过程进行训练集的数据增强并归一化。针对测试集,模型将测试图像的尺寸固定至
$768 \times 768$ 并归一化。2.2 实验环境和参数设置
本文中所有模型均使用PyTorch框架和Python语言构建,在Pycharm平台中进行模型的训练和评估。硬件环境包括Intel i7-10700 处理器(CPU),64 GB内存,NVIDIA GeForce GTX 3060(12 GB)图形处理器(GPU),操作系统为Window10。程序运行环境具体版本如下:Python版本为3.9.12,Pytorch-gpu版本为1.11.0,CUDA版本为11.2。
模型参数设置上,批处理大小(batch_size)设置为1,主干网络使用ResNet-50,加载torchvision中其在ImageNet数据集上训练的权重,并给这部分权重设置学习率为
$1 \times {10^{ - 5}}$ 。设置模型的其余部分参数的初始学习率为$1 \times {10^{ - 4}}$ ,训练代数(epoch)设置为50,在40 epoch的时候将这部分参数的学习率下降至原来的0.1倍。模型使用AdamW作为优化器,dropout设置为0.1,随机数种子设置为42。模型设置编码器和解码器的深度均为6层。FFN中线性层的扩张维度设置为1024,每一尺度的特征图通道维度统一调整至256,设置查询向量的尺度为300。2.3 损失函数设置
Deformable-DETR-DA模型中延续了原始Deformable-DETR模型中使用的组合损失函数。DETR类模型是一类集合匹配模型,这类方法预测的结果同真实值之间主要存在两方面的差异:一方面,DETR类模型通常使用Hungarian 匹配方法将预测值和真实值关联,这个过程存在较大的匹配误差;另一方面,DETR类模型预测的目标框坐标同真实的标注框坐标之间存在一定误差。这2个方面直接影响模型的检测效果,因此损失函数对这2个方面进行约束,以提高模型性能。此外,由于DETR类模型中通常会一次性预测大量的目标,这些预测目标中有效的正样本只有少数部分,更多预测目标是错误的或者重复的负样本,因此损失函数中引入了聚焦损失(focal loss)解决这类预测目标中正负样本数量差异较大的问题。
匈牙利损失(Hungarian loss)是DETR类模型损失组成中的关键部分,其来源于DETR类模型预测目标和真实值之间的匹配过程。Hungarian loss的计算公式为
$$ {L}_{\text{Hungarian}}(y,{\widehat{y}}_{\widehat{\sigma }(i)})={\displaystyle \sum _{i=1}^{N}[{\lambda }_{\text{class}}}{L}_{\text{class}}({c}_{i})+\text{}{1}_{\{{c}_{i}=\varnothing \}}{L}_{\text{box}}({b}_{i},{\widehat{b}}_{\widehat{\sigma }(i)}) $$ 式中:
$ y $ 和$ \widehat y $ 分别为真实的标注集合和预测的目标集合;N为匹配的目标数目,表示目标的预测类别;$ \widehat \sigma (i) $ 为预测目标集合和真实值集合的最佳匹配;$ {\widehat b_{\widehat \sigma (i)}} $ 为最佳匹配时目标的预测坐标;$ {b_i} $ 为对应的标注坐标。DETR类模型预测集合中的元素包含2部分:一部分是目标预测类别及置信度;另一部分是目标预测框的坐标。而Hungarian loss主要包含类别的预测损失和预测框的坐标损失2个部分。对于类别的预测损失,使用最佳匹配下的预测目标置信度计算focal loss,计算公式为
$$ {L_{{\text{class}}}}({c_i}) = - \alpha {(1 - {\widehat p_{\widehat \sigma (i)}}({c_i}))^\gamma }\log ({\widehat p_{\widehat \sigma (i)}}({c_i})) $$ 式中:
$ {\widehat p_{\widehat \sigma (i)}}({c_i}) $ 为最佳匹配下的预测目标置信度;$\alpha $ 、$ \gamma $ 为调节损失的参数,默认值为$\alpha = 0.25$ ,$ \gamma = 2 $ 。对于预测框的坐标损失,使用广义交并比损失(GIoU loss)和L1损失进行衡量。其计算过程公式为
$$ {L_{{\text{iou}}}}({b_i},{\widehat b_{\widehat \sigma (i)}}) = 1 - (\frac{{\left| {{b_i} \cap {{\widehat b}_{\widehat \sigma (i)}}} \right|}}{{\left| {{b_i} \cup {{\widehat b}_{\widehat \sigma (i)}}} \right|}} - \frac{{\left| {B({b_i},{{\widehat b}_{\widehat \sigma (i)}})\backslash ({b_i} \cap {{\widehat b}_{\widehat \sigma (i)}})} \right|}}{{\left| {B({b_i},{{\widehat b}_{\widehat \sigma (i)}})} \right|}}) $$ $$ {L_{{\text{box}}}}({b_i},{\widehat b_{\widehat \sigma (i)}}) = {\lambda _{{\text{iou}}}}{L_{{\text{iou}}}}({b_i},{\widehat b_{\widehat \sigma (i)}}) + {\lambda _{{\text{L1}}}}{\left\| {{b_i} - {{\widehat b}_{\widehat \sigma (i)}}} \right\|_1} $$ 式中:
$ B({b_i},{\widehat b_{\widehat \sigma (i)}}) $ 为同时包含标注框和预测框的最小矩形框;${\lambda _{{\text{iou}}}}$ 和${\lambda _{{\text{L1}}}}$ 分别为GIoU loss和L1损失的权重,默认值为${\lambda _{{\text{iou}}}} = 2$ 和${\lambda _{{\text{L1}}}} = 5$ 。2.4 评价指标
在本文中使用coco数据集的评价指标形式对模型的检测效果进行评价,以目标的预测框和实际标注框之间的交并比(intersection over union,IoU)为阈值进行划分。平均准确度(average precision,AP)指的是交并比在[0.50,0.95]中每隔0.05取样后计算准确度的平均值。AP50、AP75分别表示IoU阈值为0.5、0.75时的AP测量值。APS、APM、APL分别表示像素面积小于
$32 \times 32$ 、大于$32 \times 32$ 且小于$96 \times 96$ 、大于$96 \times 96$ 的目标框的AP测量值,用于评估小目标、中型目标和大型目标。AP的计算公式为$$ {m_{{\text{AP}}}} = \int_0^1 {P(r){\text{d}}r} $$ 式中
$ {m_{{\text{AP}}}} $ 是以查全率(recall)为横轴、查准率(precision)为纵轴构成的P-R曲线下的面积。AP数值越大,说明目标检测的性能越好。其中,查全率${m_{{\text{recall}}}}$ 、查准率${m_{{\text{precision}}}}$ 计算公式为$$ {m_{{\text{recall}}}} = \frac{{{N_{{\text{TP}}}}}}{{{N_{{\text{TP}}}} + {N_{{\text{FN}}}}}} $$ $$ {m_{{\text{precision}}}} = \frac{{{N_{{\text{TP}}}}}}{{{N_{{\text{TP}}}} + {N_{{\text{FP}}}}}} $$ 式中:
$ {N_{{\text{TP}}}} $ 为IoU大于设定阈值的检测框数目,$ {N_{{\text{FP}}}} $ 为IoU小于设定阈值的检测框和对同一个标注多余的检测框数目,$ {N_{{\text{FN}}}} $ 为未检出的被标注目标数目。2.5 URPC2020数据集上目标检测的实验情况
本文将模型在URPC2020数据集上进行测试并同一些DETR类检测方法进行比较,结果如表1所示。其中,表1中的“模型尺度”一栏表示方法中模型主干网络输出的特征图形式,multi表示多尺度特征图,F5表示输入特征图尺寸为原尺寸的32倍下采样。表1可见,与原方法相比,改进后的方法AP值提升1左右。此外,改进后的模型在URPC2020数据集上获得了最佳的AP值,即有着最好的检测效果。和多数对比方法相比,在小目标的检测APS以及粗略检测AP50上均有着一定的提升。
表 1 URPC数据集的多模型检测效果定量比较模型 迭代数次 参数量/MB 模型尺度 AP/% AP50/% AP75/% APS/% APM/% APL/% DETR [20] 500 41 F5 32.5 65.2 26.9 25.5 21.8 36.1 Conditional-DETR [21] 50 44 F5 35.3 69.4 30.4 22.3 23.8 39.3 Anchor-DETR [22] 50 37 F5 36.6 71.7 31.7 24.7 24.6 40.7 DAB-DETR [23] 50 44 F5 36.4 71.1 32.6 23.6 23.8 40.6 DE-DETRs [24] 50 43 multi 37.0 69.1 34.5 25.2 25.7 40.9 Deformable-DETR [25] 50 40 multi 38.5 71.4 38.5 29.1 27.3 42.5 Deformable-DETR-DA 50 47 multi 39.5 73.0 38.1 30.4 28.7 43.4 本文还将各个方法的水下检测结果进行可视化,如图5。图5中表明改进后的方法有着更好的准确率,检测框的准确度更好。除此之外,改进后的方法同其他的方法相比误检率有所降低。在质量较低的水下图像中,没有使用图像增强之类的预处理方式,模型也有较好检测效果。
 图 5 各种对比方法的可视化结果下载:
全尺寸图片
图 5 各种对比方法的可视化结果下载:
全尺寸图片
2.6 消融实验
本文针对各部分的改进设计消融实验进行验证,结果如表2和图6所示,其中图6中红色框代表标注,黄色框代表检测结果。
表 2 Deformable-DETR-DA模型中改进模块的有效性实验结果比较% 模型 AP AP50 AP75 APS APM APL Deformable-DETR 38.5 71.5 38.5 29.1 27.3 42.5 Deformable-DETR + CAGM 39.1 71.9 39.0 30.4 28.0 43.1 Deformable-DETR + DFPN 38.5 72.8 37.0 28.9 26.1 42.6 Deformable-DETR-DA 39.5 73.0 38.1 30.4 28.7 43.4  图 6 URPC数据集上消融实验效果比较下载:
全尺寸图片
图 6 URPC数据集上消融实验效果比较下载:
全尺寸图片
由表2可知,单独添加CAGM部分能对模型的检测效果有着一定的提升。而单独添加DFPN对检测的效果几乎没有提升,这和Deformable-DETR论文中提到的相同,均由于可形变注意力具有融合多级特征的能力,可以替代特征金字塔的作用。但是,在DFPN和CAGM模块同时添加后,模型的性能又能在仅添加CAGM的基础上有所提升,这是因为CAGM模块带来更多的通道方向的关注,使得DFPN在通道方向对模型产生更深的影响,可以进一步针对通道方向进行调节,从而提升模型性能。由图6可见,在添加了DFPN和FFN-CAGM之后,模型的漏检和误检有所下降。这也可以体现模型改进的有效性。
3. 结束语
针对水下光学图像目标检测问题,本文将DETR类检测方法引入到水下检测任务中并加以改进。通过添加设计的DFPN和FFN-CAGM部分以提升模型的性能;通过在水下数据集上的对比实验和消融实验证明本文所用方法的有效性和设计改进的有效性,并通过可视化结果进一步体现。DETR类方法在水下目标检测任务上值得进一步探索。后续研究可进一步完善检测模型,针对模型的参数量和计算量进行轻量化设计,进一步提升模型的实用性,也可以通过添加图像增强等预处理方法进一步提升模型性能。
-
图 1 改进后的 Deformable-DETR-DA 模型结构
下载:
全尺寸图片
图 2 DFPN结构及空间注意力结构
下载:
全尺寸图片
图 3 改良编码器部分结构
下载:
全尺寸图片
图 4 通道注意力引导前馈神经网络部分结构
下载:
全尺寸图片
图 5 各种对比方法的可视化结果
下载:
全尺寸图片
图 6 URPC数据集上消融实验效果比较
下载:
全尺寸图片
表 1 URPC数据集的多模型检测效果定量比较
模型 迭代数次 参数量/MB 模型尺度 AP/% AP50/% AP75/% APS/% APM/% APL/% DETR [20] 500 41 F5 32.5 65.2 26.9 25.5 21.8 36.1 Conditional-DETR [21] 50 44 F5 35.3 69.4 30.4 22.3 23.8 39.3 Anchor-DETR [22] 50 37 F5 36.6 71.7 31.7 24.7 24.6 40.7 DAB-DETR [23] 50 44 F5 36.4 71.1 32.6 23.6 23.8 40.6 DE-DETRs [24] 50 43 multi 37.0 69.1 34.5 25.2 25.7 40.9 Deformable-DETR [25] 50 40 multi 38.5 71.4 38.5 29.1 27.3 42.5 Deformable-DETR-DA 50 47 multi 39.5 73.0 38.1 30.4 28.7 43.4 表 2 Deformable-DETR-DA模型中改进模块的有效性实验结果比较
% 模型 AP AP50 AP75 APS APM APL Deformable-DETR 38.5 71.5 38.5 29.1 27.3 42.5 Deformable-DETR + CAGM 39.1 71.9 39.0 30.4 28.0 43.1 Deformable-DETR + DFPN 38.5 72.8 37.0 28.9 26.1 42.6 Deformable-DETR-DA 39.5 73.0 38.1 30.4 28.7 43.4 -
[1] 史建柯, 乔美英, 李冰锋, 等. 基于注意力机制的水下遮挡目标检测算法[J]. 电子科技, 2023, 36(5): 62−70. [2] 董金耐, 杨淼, 谢卓冉, 等. 水下图像目标检测数据集及检测算法综述[J]. 海洋技术学报, 2022, 41(5): 60−72. [3] 张艳, 李星汕, 孙叶美, 等. 基于通道注意力与特征融合的水下目标检测算法[J]. 西北工业大学学报, 2022, 40(2): 433−441. [4] 叶赵兵, 段先华, 赵楚. 改进YOLOv3-SPP水下目标检测研究[J]. 计算机工程与应用, 2023, 59(6): 231−240. [5] 王蓉蓉, 蒋中云. 基于改进CenterNet的水下目标检测算法[J]. 激光与光电子学进展, 2023, 60(2): 239−248. [6] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: ACM, 2014: 580-587. [7] GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2016: 1440-1448. [8] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031 [9] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-Time object detection[C]// Computer Vision & Pattern Recognition. Las Vegas: IEEE, 2016. [10] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6517-6525. [11] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018–04–08)[2022–12–02]. https://arxiv.org/abs/1804.02767. [12] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020–04–23)[2022–12–02]. https://arxiv.org/abs/2004.10934. [13] 任盼飞. 基于深度学习的水下目标检测方法研究[D]西安: 西安工业大学, 2021. [14] 赵晓飞, 于双和, 李清波, 等. 基于注意力机制的水下目标检测算法[J]. 扬州大学学报(自然科学版), 2021, 24(1): 62−67. [15] 葛慧林, 戴跃伟, 朱志宇, 等. 基于改进YOLOv7声光融合水下目标检测方法[J]. 舰船科学技术, 2023, 45(12): 122−127. [16] 叶志杨, 梁昊霖, 兰诚栋. 应用于水下目标检测的YOLOv5s算法模型[J]. 电视技术, 2023, 47(2): 39−43. [17] 乔美英, 史建柯, 李冰锋, 等. 改进损失函数的增强型FPN水下小目标检测[J]. 计算机辅助设计与图形学学报, 2023, 35(4): 525−537. [18] 乔美英, 赵岩, 史建柯, 等. 高频增强网络与FPN融合的水下目标检测[J]. 电子测量技术, 2023, 46(13): 146−154. [19] WOO S, PARK J, LEE J Y, et al. Cbam: convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 3-19. [20] CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]// European Conference on Computer Vision. Glasgow: Springer, 2020: 213-229. [21] MENG Depu, CHEN Xiaokang, FAN Zejia, et al. Conditional detr for fast training convergence[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 3651-3660. [22] WANG Yingming, ZHANG Xiangyu, YANG Tong, et al. Anchor DETR: query design for transformer-Based detector[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Vancouver: AAAI, 2022: 2567-2575. [23] LIU Shilong, LI Feng, ZHANG Hao, et al. DAB-DETR: dynamic anchor boxes are better queries for DETR[EB/OL]. (2022–03–30)[2022–12–02]. https://arxiv.org/abs/2201.12329. [24] WANG Wen, ZHANG Jing, CAO Yang, et al. Towards data-efficient detection transformers[C]//European Conference on Computer Vision. Tel Aviv: Springer, 2022: 88-105. [25] ZHU Xizhou, SU Weijie, LU Lewei, et al. Deformable detr: deformable transformers for end-to-end object detection[EB/OL]. (2021–03–18)[2022–12–02]. https://arxiv.org/abs/2010.04159.




































































