
Comparative learning graph neural network for session-base recommendation model
-
摘要: 针对现有会话推荐方法难以从携带噪声的匿名会话序列中精确获取用户偏好的挑战,提出融合对比学习的图神经网络会话推荐模型。首先,将全部会话数据构建为图,通过图神经网络聚合图上物品信息获取节点局部嵌入表示;其次,利用含有噪声滤除器的注意力机制显示地过滤掉不重要的节点表征,得到去噪增强的全局嵌入表示;同时引入对比学习技术设置优化策略指导模型进行去噪学习;最后,采用门控机制为局部和全局表征自适应分配权重,并对其进行加权求和得到用户会话表示,通过预测层生成推荐列表,并在Diginetica和Tmall 共2个公开基准数据集上进行实验测试。结果证明所提模型相较于其他基线模型推荐效果明显提升,其中与基于会话推荐的自监督超图卷积网络(S2-DHCN)相比,Tmall上MRR@20提高5.4%,性能显著提高。Abstract: Aiming at the problem that existing session recommendation methods are difficult to accurately extract user preferences from anonymous sessions carrying noise, a graph neural network model for session-based recommendation is presented in this paper. Specifically, this method first constructed all the session data as a graph, obtaining the local embedded representation of the node by aggregating the item information on the graph through the graph neural network. Secondly, the attention mechanism of the noise filter was used to visually filter out the unimportant node representations to obtain the global embedding representation of denoising enhancement, and the comparative learning technology was introduced to set the optimization strategy to guide the model for denoising learning. Finally, the gating mechanism was used to adaptively assign weights to local and global representations, the weighted summation was used to obtain the user session representation, and then the recommendation list was generated through the prediction layer. Experimental tests were carried out on two public benchmark datasets of Diginetica and Tmall. The results show that the recommendation effect of the proposed model is better than other baseline methods, and the MRR@20 on Tmall is improved by 5.4% compared with the self-supervised hypergraph convolutional network based on session recommendation (S2-DHCN), and the recommendation performance is significantly improved.
-
在互联网信息呈爆炸式增长的时代,推荐系统已经成功进化为信息服务的基础工具之一,它能够帮助用户做出合理的选择和决策,提高数据处理的效率,有效缓解信息过载问题[1-2]。传统的推荐算法需要借助用户个人简介以及历史评分(如网页的浏览数据、购买记录、社交网络和地理位置)等语义信息来构建推荐任务以预测用户真正感兴趣物品,然而在实际应用中,由于隐私策略或用户匿名访问的限制,用户的档案资料和长期历史配置文件大多都无法直接获得,唯一可用的有效信息只有当前会话中的点击行为记录[3]。因此,基于会话的推荐方法诞生并受到了学术界和工业界的广泛关注。
会话推荐旨在根据短期匿名会话交互轨迹行为构建交互行为模式,进一步预测用户要点击的下一项物品的概率[4-5]。最初,所做工作主要是马尔可夫链的浅层方法捕捉序列数据中随时间推移而动态变化的用户兴趣[6];近几年,以神经网络为首的深度学习技术发展火热,深层的神经网络已被广泛用于从非结构化数据内容中提取高阶信号特征的场景中,相关研究者也将深度神经网络引入了会话推荐中,对蕴含在不同类型会话数据中的潜在价值进行深入挖掘,极大地带动了会话推荐的研究进程[7]。循环神经网络[8] (recurrent neural networks, RNN)通过状态变量将上一时刻输出和此刻输入进行结合共同作用影响获得此刻的输出结果,实现了神经网络的“记忆存储”功能。由于循环神经网络对序列型数据有着与生俱来的天然建模优势,文献[9]首次将循环神经网络纳入会话推荐系统中提出一种基于GRU4Rec的方法,该方法通过多层门控循环单元和采用并行架构批量处理方式学习序列信息,聚焦于单个会话的兴趣演变,优化了训练策略 ;相比而言,作为深度学习领域最活跃的研究方向之一,图神经网络[10](graph neural networks,GNN)凭借其卓越的性能已经被广泛应用于个性化推荐等日常生活中,在新冠药物研发等科学前沿领域也不乏其身影,Wu等[11]开创性地将会话序列构建为图数据结构来提取会话级特征,显示出了可观的推荐性能。然而尽管研究者们在图会话建模方面已经取得了不错的进展,但基于图的会话推荐方法依然存在一定的局限性和挑战性[12],主要总结如下:
1)由于会话数据存在随机性和嘈杂性的特点,在会话行为序列中并不是所有的交互行为都对下一项物品预测有帮助,且模型在形成兴趣表征时无法越过与用户主要兴趣不相关的物品,这阻碍了模型进行有效的意图学习,使学习到的会话表示可能存在鲁棒性差和不准确的问题[13]。
2)对于用户行为中的噪声点击,传统解决方法通常采用注意力机制由softmax加权的方式削弱与用户主要目的不相关物品的影响,即赋予不重要物品较小的权重比例,属于一种隐式去噪方式,但是经过多次迭代后,这种小权重嘈杂点击仍会积累大量的噪声,容易形成无效的意图学习[14]。
3)虽然现有的基于会话预测方法利用强大的表示学习方法在低维空间中编码项目的顺序相关性,但它们也存在一定的局限性。用户兴趣本质上是由用户意图驱动,而用户意图会随时间推移发生动态性变化,用户对物品的兴趣也会随之不断改变,这种变化容易使得模型存在无法准确分析隐式反馈数据内部复杂的相互依赖关系和不能充分捕捉用户真实偏好动态变化规律的问题[15]。
为此,提出融合对比学习的图神经网络会话推荐模型(comparative learning graph neural network for session-base recommendation,CLSR-GNN),该模型首先将会话数据转换为图,并通过图神经网络的图拓扑结构聚合图上项目的特征信息,得到项目隐含向量表示,作为局部会话表示,这种特征提取方式能够增强模型表达能力,可以更为充分和准确地学习具有丰富语义的项目表示;其次,为了更好地了解用户的真实意图、降低噪声行为干扰作用、避免嘈杂点击的累积,对基于项目的隐含向量先用软注意力分配给每个项目不同注意力分数值生成注意力参数矩阵,利用噪声滤除器对注意力系数进行更加细致的处理,过滤掉权重低于特定阈值的项目,生成有效的全局会话向量表示,显示过滤掉与用户主要目的不相关的物品;再次,为使模型去噪效果达到更佳,将经过噪声过滤的全局嵌入表示和原会话全局嵌入表示分别作为正样本和负样本,联合对比学习框架对两者建立监督信号进行优化训练,达到更好地抑制噪声干扰的效果,获得高质量的会话特征向量表示,更为有效地挖掘项目之间深层次的关联,增加模型鲁棒性和可解释性;最后,采用门控机制来自适应地融合全局偏好和局部偏好表示,有效建模会话中用户与项目交互序列中的复杂转换关系,结合全局和局部物品特征来揭示会话序列中用户的兴趣变化规律,获得更准确的会话向量表示,从而形成个性化推荐,预测用户将要点击的下一项物品。实验结果表明,该算法显示出了较好的推荐性能,具有合理性和优越性。
1. 相关工作
1.1 基于图神经网络的会话推荐
随着深度学习的发展,图神经网络异军突起,成为了图计算和图挖掘任务的最佳方法[16]。从图的视角重新看待传统推荐模型,不难看出,传统模型一般只利用了图上的一阶邻居节点信息,如在矩阵分解模型中,对于给定的用户,它仅用到了其一阶邻居的信息,因此导致模型的推荐性能受限[17]。与传统模型相比,图神经网络模型可以通过消息传播机制让节点聚合到大部分高阶邻居的信息,即有效地捕获高阶关系以实现更准确的表征学习[18-19]。图作为一种通用类型的数据结构,也被引入了会话推荐任务建模中,Wu等[11]采用门控图网络作为项目特征编码器,并利用软注意力机制将项目特征和会话特征聚合在一起,进行用户兴趣学习;Xu等[20]设计了多层自注意力网络,利用了自注意力机制和图神经网络的互补性,以获得情境化的非局部表征,保持了模型的简单性和灵活性,实现了较好的推荐效果;Qiu等[21]提出了一种加权注意力图结构和一个读出函数来学习物品和会话的嵌入的模型框架来协同处理会话图中的潜在顺序关联;Wang等[22]提出了一种结合上下文信息加强的模型,以更加细粒度的方式考虑所有会话中的物品转换,更好地推断出了用户在当前会话中的兴趣偏好;Yang等[15]利用图卷积神经网络构建多关系物品图,同时考虑目标行为和辅助行为信息,构建全局item2item关系图,进而建模用户动态兴趣。
1.2 对比学习
自监督学习[23]是一种新兴的机器学习方法,旨在通过自监督的方式从原始数据中学习更好的数据表示。最初它被用于计算机视觉领域进行表征学习[24],然后又将自监督学习扩展到图表示学习中[25]。而对比学习(contrastive learning)是自监督学习中的一种,用来解决"标注少或无标注"的问题。对比学习是通过对比具有互信息最大化的一致和不一致视图来帮助模型学习不同视图中相似性较大的表征,进而形成编码丰富的图或节点表示[26],简而言之,其主要思想为利用对比学习可以使模型中样本和与之相似的正样本之间的距离远大于样本和与之不相似的负样本之间的距离。随着对比学习在CV和NLP领域的成功应用,它也被相关研究者引入了推荐系统任务中。Zhou 等[27]使用特征掩码来创建自监督信号,但由于会话数据的稀疏性,屏蔽特征不能产生强大的自监督信号,因此并不适用于会话推荐建模;Xia等[28]将会话数据构建为超图,创新性地把自监督学习融入到了网络训练中,通过最大化地学习模型里2个通道中会话表示之间的互信息,并将其作为改进推荐的辅助任务来进一步提升模型整体性能;Yang等[29]设计了一个通用的知识图谱对比学习框架,利用来自知识图谱增强过程的额外监督信号来指导跨视图对比学习,在梯度下降中为无偏的用户–商品交互分配更大的权重,并进一步抑制噪声,在具有稀疏性用户–商品交互、长尾和嘈杂的知识图谱实体的推荐场景中取得了较好的推荐性能。
2. CLSR-GNN模型
2.1 符号定义
会话推荐是要预测下一项要点击的物品,无需访问用户的长期历史数据。假设有n个匿名会话序列,所有会话序列涉及的物品数有m个,它们组成的集合分别为S=(vs,1,vs,2,···,vs,n)和V={v1,v2,···vm}。其中,Si∈V表示在会话S中用户点击的某一项。会话推荐任务是预测给定的会话S中用户在下一时刻要点击的所有物品的概率分布,取前k项形成排名列表进行top-k推荐。
2.2 模型总体框架
CLSR-GNN模型的整体框架如图1所示。模型主要由3部分组成:1)特征提取部分。会话数据注入模型中,全部构建为会话图,然后利用图神经网络组件捕捉会话图中的物品转换关系的高阶结构信息,生成物品局部特征嵌入。2)去噪优化部分。为更好地刻画用户兴趣表征,对得到的物品嵌入先通过软注意力机制获取不同物品的注意力权重向量,然后对权重矩阵设置相应去噪函数,过滤掉权重低于特定阈值的项目,越过与用户主要目的不相关的项目,形成去噪增强的全局特征嵌入表示。采用对比学习框架对去噪增强的全局特征嵌入和原会话全局嵌入构建优化策略,进而辅助模型去噪,形成更加准确的会话级全局特征表示。3)模型预测。结合门控机制来自适应地融合局部和全局嵌入表示获得最终会话表示,进行推荐预测。
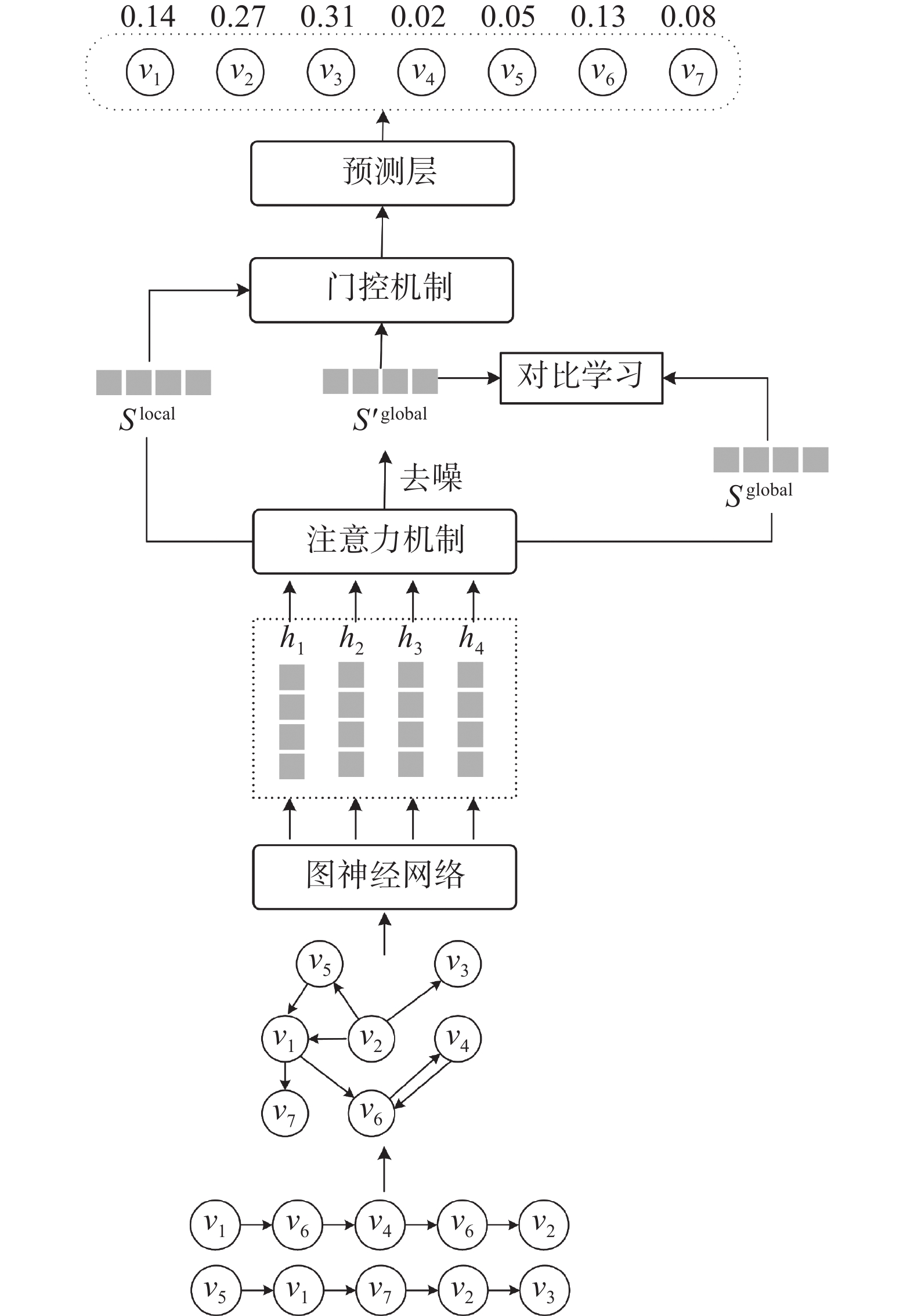 图 1 CLSR-GNN模型整体框架
图 1 CLSR-GNN模型整体框架 下载:
全尺寸图片
下载:
全尺寸图片
2.3 图上学习项目隐含向量
2.3.1 会话图构建
首先,将每个会话序列构建为有向图Gs,公式为
$$ G_{{\rm{s}}}=(V_{{\rm{s}}},E_{{\rm{s}}}) $$ 式中:Gs为所有会话序列有向图的集合,Vs为图中节点集合,Es为边的集合。Vi,s为会话S中的第i个节点(物品),(Vi-1,s,Vi,s)∈Es在图上显示为Vi-1,s 指向Vi,s的有向边,(Vi-1,s,Vi,s)对应边的值为1,两物品之间无交互记为0。因此,每个会话中物品转移关系可以用2个矩阵来存储,分别是MIn、MOut共2个加权矩阵,来诠释图中项目的转移顺序。此外,为防止序列中重复行为的影响,需对每条边作归一化加权处理,这里的加权操作由该边出现次数除以该边起始节点的出度数计算获得,结果如图2所示。
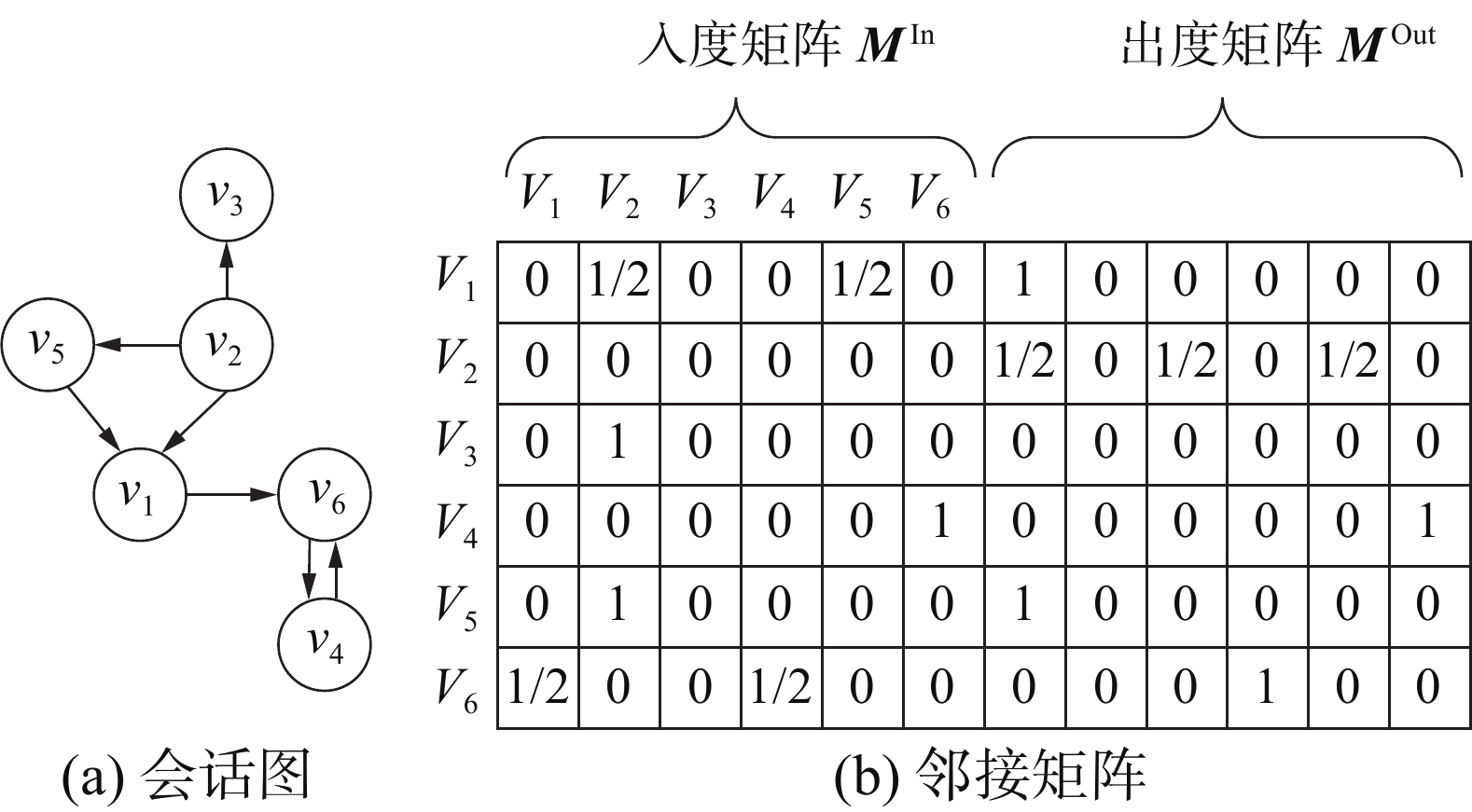 图 2 会话图和邻接矩阵示例下载:
全尺寸图片
图 2 会话图和邻接矩阵示例下载:
全尺寸图片
2.3.2 图神经网络学习
本文利用图神经网络学习项目的表征。为更加结构化地利用交互数据,GNN经过逐次迭代邻居节点信息和消息传播机制,进行动态融合用户核心兴趣。会话序列推荐模型采用均值方式归一化求和邻接矩阵进行信息聚合,每个节点根据邻节点的信息进行更新[22],公式为
$$ \begin{array}{c}{{\boldsymbol{a}}}_{t}=\text{Concat}({{\boldsymbol{M}}}_{t}^{\text{In}}([{s}_{1},{s}_{2},\cdots,{s}_{n}]{{\boldsymbol{W}}}_{{a}}^{\text{In}}+{b}^{\text{In}}), \\ {M}_{t}^{\text{Out}}([{s}_{1},{s}_{2},\cdots,{s}_{n}]{{{W}}}_{{a}}^{\text{Out}}+{b}^{\text{Out}}))\end{array} $$ 式中:WaIn,WaOut∈Rd×d均为可训练的参数矩阵,bIn,bOut∈Rd是偏差向量,MtIn,MtOut∈R1×n分别指节点vi,s对应的出度和入度邻接关系矩阵,[v1,v2,···,vn]为t−1时刻会话中所有物品的节点嵌入向量。提取节点vit的邻域信息,然后将它们和上一时刻的状态vit−1输入到图神经网络中,最后GNN层的输出hit计算如下:
$$ {it{z}}_i^t = \sigma {{(}}{{\boldsymbol{W}}_{{z}}}{\boldsymbol{a}}_i^t + {L_{{z}}}{\boldsymbol{v}}_i^{t - 1}{{)}} $$ $$ r_i^t = \sigma {{(}}{{\boldsymbol{W}}_{{r}}}a_i^t + {{\boldsymbol{L}}_{{r}}}{\boldsymbol{v}}_i^{t - 1}{{)}} $$ $$ \tilde h_i^t = {\text{tan}}h({{\boldsymbol{W}}_{{h}}}{\boldsymbol{a}}_i^t + {{\boldsymbol{L}}_{{h}}}{\text{(}}r_i^t \odot {\boldsymbol{v}}_i^{t - 1}{\text{))}} $$ $$ {\boldsymbol{h}}_i^t = {\text{(}}1 - {\textit{z}}_i^t{\text{)}} \odot v_i^{t - 1} + {\textit{z}}_i^t \odot {\boldsymbol{\tilde h}}_i^t $$ 式中:Wz,Wr,Wh∈R2d×d、Lz,Lr,Lh∈Rd×d均为可学习参数,vit和vit−1分别表示t时刻和t−1时刻节点的嵌入向量,ait∈R2d表示提取vit的邻节点信息,
$ \sigma ( \cdot ) $ 代表激活函数,$ \odot $ 指元素型乘法,zit、rit分别是更新门和复位门发挥保留和丢弃功能。最终获得所有节点表示。2.4 注意力机制
2.4.1 注意力权重计算
将得到的局部节点表示输入到软注意力机制中用来捕获全局会话偏好表示,注意力权重计算公式为
$$ {\alpha _{\text{i}}} = {{\boldsymbol{q}}^{\rm T}}\sigma {\text{(}}{{\boldsymbol{W}}_1}{v_n} + {{\boldsymbol{W}}_2}{v_i} + c{\text{)}} $$ $$ {{\boldsymbol{S}}^{{\text{global}}}} = \sum\limits_{i = 1}^n {{\alpha _i}{v_i}} $$ 式中参数q∈Rd和W1,W2∈Rd×d控制项目嵌入向量的参数矩阵。
最后将获得的Sglong和vi∈V对hi进行刻画,计算 vi对应的概率
$\hat{{\textit{z}}}_i$ ,结合softmax得到$\hat{y}_i$ ,具体公式为$$ \hat{{\textit{z}}}_i = {{\boldsymbol{S}}^{{\text{global}}}}{{\boldsymbol{h}}_i} $$ $$\hat{y}_i= {\text{softmax(}}\hat{{\textit{z}}}_i {\text{)}} $$ 式中:
$\hat{{\textit{z}}}_i$ ∈Rm为全部的被点击可能性,$\hat{y}_i$ ∈Rm表示在会话S中节点vi下一次被点击的概率。选取会话推荐中广泛使用的交叉熵损失函数作为模型的训练函数:
$$ {l^{\text{r}}} = - \sum\limits_{i = 1}^m {{y_i}} {\text{ln(}}\hat{y}_i{\text{)}} + {\text{(}}1 - {y_i}{\text{)ln(}}1 -\hat{y}_i{\text{)}} $$ 2.4.2 噪声滤除器
一般情况下,采用注意力机制对无关项目分配小的权重也可以起到去除噪声作用。但是,通常会假设将最后一项作为用户当前意图的线索,最后一项会被用来计算其他项的重要性。这种做法就可能产生2个问题:1)用于计算其他项目注意权重的所选项目(即最后1个项目)也可能是嘈杂的点击;2)小权重的嘈杂点击仍然会积累大量的噪声,阻碍用户有效的意图学习。为有效缓解噪声带来的干扰作用,本模型设置噪声滤除函数来显示去除掉无用的特征增强模型鲁棒性,噪声滤除函数具体表达式为
$$ {\alpha }^{\prime }{}_{i}=\left\{\begin{array}{l}{\alpha }_{i},\quad {\alpha }_{i}-{\lambda }_{\text{avg}} > 0\\ 0,\quad 其他\end{array}\right. $$ $$ {\alpha _{{\text{avg}}}} = \frac{1}{t}\sum\limits_{k = 1}^t {{\alpha _k}} $$ 式中λ是控制去噪程度的参数,通过λ与平均注意力权重的乘积计算得出阈值大小。留下超出阈值的权重值,低于阈值的权重置为0。该做法可以显式地过滤掉有噪声的点击,并学习当前会话的精确嵌入,以增强会话意图学习。
此时去噪增强后的全局会话嵌入表示计算如下:
$$ {S^\prime }^{{\text{global}}} = \sum\limits_{i = 1}^n {{\alpha ^\prime }_i{v_i}} $$ 2.5 联合对比学习优化策略
本模型从获取全局会话级表示角度出发,采用对比学习框架对去噪增强的全局特征嵌入和原会话全局嵌入构建优化策略,进而辅助模型去噪,形成更加准确的兴趣表征。前后思路各异,但均以获得全局特征表示为目的,它们的区别在于有无去噪学习处理,即它可以双向促进更好的监督对方,相辅相成更好的表示数据。本模型对比学习的损失函数为
$$ {l^{\text{s}}} = - \ln \sigma \left( {{f_D}({S^{{\text{global}}}},{S^\prime }^{{\text{global}}}) - \ln \sigma (1 - {f_D}({S^{{\text{global}}}},\mathop {{S^{{\text{global}}}}}\limits^ \sim ))} \right) $$ 式中:Sglong和
$ {{{S}}^\prime }^{{\text{glong}}} $ 表示模型无去噪处理和有去噪处理学习到的2种全局会话序列表示;$ \mathop {{{{S}}^{{\rm{global}}}}}\limits^ \sim $ 是负样本,对Sglong进行操作获取;fD有辨识功能,它以2个向量作为输入,评估相似性。具体来说,2个向量之间的点积被记为fD函数,σ是sigmoid激活函数。双方可以进行最大限度的信息利用,促进同一全局嵌入表示不同处理方式的一致性,将不同点尽可能放大便于发现。最后推荐部分和对比学习共同产生效果:$$ L = {l^{\text{r}}} + \delta {l^{\text{s}}} $$ 式中
$ \delta $ 代表对比损失的权重。通过以上操作能够结合序列中的各种信息,同时考虑到噪声干扰,推荐性能有效提高。
不同的用户可能有不同的行为习惯。例如,一些用户可能会频繁地浏览项目页面并任意地单击各种项目,经过长时间反复比较查看测评才会决定下单。而另一种用户可能会只单击他们想要购买的项目,较短时间内做出决策。不言而喻,在这些情况下,全局会话嵌入和局部会话嵌入对下一个项目预测的贡献是不同的。所以,定义了以下门控机制来计算最终的用户偏好表示:
$$ \alpha = \sigma ({W_{\text{g}}}[{{{S}}^\prime }^{{\text{global}}};{{{S}}^{{\text{local}}}}]) $$ 式中:[ ; ]表示拼接操作,σ为sigmoid激活函数,Wg∈R1×2d为模型的可训练参数。最后,通过对Sglabol 和Slocal的加权求和得到当前会话的用户偏好表示:
$$ {{{S}}^v} = \alpha \cdot {{{S}}^\prime }^{{\text{global}}} + (1 - \alpha ) \cdot {{{S}}^{{\text{local}}}} $$ 3. 实验及分析
3.1 实验数据集
本模型旨在根据用户匿名会话序列预测用户的近期行为,为验证模型的准确性和优越性,在公开的Diginetica和Tmall[30]2个数据集上进行训练和测试。其中,Diginetica数据集来自CIKM Cup 2016挑战赛,是从搜索引擎日志中提取的电商交易型用户会话数据,包括600 684个用户对184 047件商品共计993 483次用户点击记录,每条数据包含会话ID、项目ID、项目类别、时间戳等信息;Tmall数据集源于IJCAI-15竞赛,是中国最大在线购物平台(天猫)记录的用户行为日志,大约有963 923个户对235 320 7个商品的44 528 127次交互记录,有时间戳、商品类别信息等。上述2个数据集均是电商场景下的数据集,在规模大小和稀疏性方面各不相同。为方便起见,在实验过程中,参照文献[30-31]对3个数据集进行如下预处理,过滤出现次数少于5次的项目对应的数据,移除少于2个项目的所有会话数据。此外,将最后一周的会话数据设置为测试数据,剩下的反复实验可以用到。最后如表1所示。
表 1 实验数据集的统计信息项目 Diginetica Tmall 点击次数 982 961 818 479 商品数量 184 047 40 728 训练集 719 470 351 268 测试集 60 858 25 898 平均长度 5.12 6.69 3.2 评估指标
为评估提出模型的推荐性能,本文采用Precision@k和MRR@k 共2种推荐系统常用的top-k评价指标来对模型准确性进行测试。Precision@k表示准确率,用于衡量推荐预测的准确性;MRR@k表示平均倒数排名,推荐列表中正确物品倒数等级的平均值。
3.3 基准模型及实验设置
为了证明提出的 CLSR-GNN 算法的有效性,本文从多个角度对所提模型分析实验:
1)基准模型
为了评估该模型性能,实验选取以下模型作为对比模型:
Pop[32]:仅利用基于重复出现的项目进行推荐。
IitemKNN[33] :考虑项目向量之间的余弦相似度捕捉用户兴趣。
FPMC[34]:经典的基于一阶马尔科夫链和矩阵分解的传统推荐算法。
GRU4Rec[35]:使用GRU对会话序列进行建模,并将用户兴趣编码为最终状态。
Caser[36]:采用卷积神经网络学习序列特征,为学习序列模式提供了一个灵活的网络结构。
SR-GNN[11]:在会话推荐中首次使用图神经网络会话序列的经典模型。
LSKGCN[37]:考虑到长短兴趣来对用户意图建模。
S2-DHCN[28]:将数据建模为超图获取高阶项目特征并结合图卷积网络进行学习。
2)超参数设置
实验设定隐藏向量维度为100,训练批次大小设定为100,初始学习率为0.001且每训练迭代3次学习率衰减10%,正则化系数 L2=10−5,在实验中,按照 8∶1∶1的比例在用户维度上随机划分数据集来构建训练集、验证集和测试集,对所有参数采用均值为0、标准差为0.1的高斯分布进行初始化,使用Adam算法优化模型参数,训练迭代轮数(epochs)设定为500,并且当验证集上的评测指标在 10 轮内没有变化时提前结束训练。
3.4 实验结果及分析
3.4.1 基准模型比较
在会话推荐任务中,设置不同的推荐个数会直接影响测评的结果。为了将所提模型和基准模型进行更加准确的比较,将推荐个数k的范围设置为20进行测试。将提出的模型和基准模型在Diginetica数据集和Tmall数据集上的Precision@20、MRR@20的实验结果分别如表2所示,其中基线模型中最优结果已用下划线标出。
表 2 CLSR-GNN和基准模型在2个数据集上的性能比较数据集 Metric Pop IitemKNN FPMC GRU4Rec Caser LSKGCN S2-DHCN SRGNN CLSR-GNN 改进率/% Diginetica Precision@20 0.0086 0.0327 0.0153 0.0295 0.0204 0.033 0.0416 0.0419 0.0429 2.4 MRR@20 0.0177 0.0948 0.0656 0.0710 0.1016 0.1639 0.197 7 0.1820 0.2067 4.6 Tmall Precision@20 0.0373 0.0756 0.1316 0.0950 0.0978 0.0913 0.040 2 0.0139 0.0422 5.0 MRR@20 0.0269 0.0351 0.0719 0.0579 0.1164 0.1443 0.1258 0.171 5 0.1808 5.4 从表2中可以直观地看出在不同的数据集上:1) CLSR-GNN模型和SRGNN以及S2-DHCN模型明显优于设置的传统的会话推荐模型,原因是这些模型考虑到了会话数据中蕴含的顺序信息,同时结合了用户的长短期兴趣,捕捉用户兴趣的动态变化性,进而达到了高效的推荐性能。该结果还可以表明利用图神经网络增强的会话偏好编码器表现出不凡的效果,能够从会话序列中学习更为精确的会话表示。2) 纵观表2中所有数据,基于深度学习的模型虽然都表现出了一定的效果,但是引入自监督对比学习技术的CLSR-GNN模型和S2-DHCN模型表现略胜一筹。这是因为2个模型都考虑到了噪声问题,并且都经过对比学习辅助任务的引入探索了会话中内在的序列依赖性,通过提供的自监督目标任务来发现额外的语义信息,使得学习到的会话表征更清晰,进而使得模型表现出更加优秀的性能。3) 同样使用图神经网络和注意力机制的SRGNN提取会话级表示的能力没有联合对比学习去噪优化的CLSR-GNN强。这进一步证实CLSR-GNN中过滤掉用户无关行为数据的重要性,基于对比学习的辅助任务和目标监督任务构成了一种相互补充的模式机制,通过学习适用于基于会话的推荐的鲁棒表示,可以解决隐式反馈和弱监督问题原则上表征固有的数据相关性问题。
3.4.2 模型稳定性分析
为保证模型稳定性和实验结果的可靠性,本小节将推荐数量k的范围设置为10~100,间隔设置为 10,总共分为10组实验。在Diginetica数据集上运行的Precision@20和MRR@20指标结果值如图3所示。
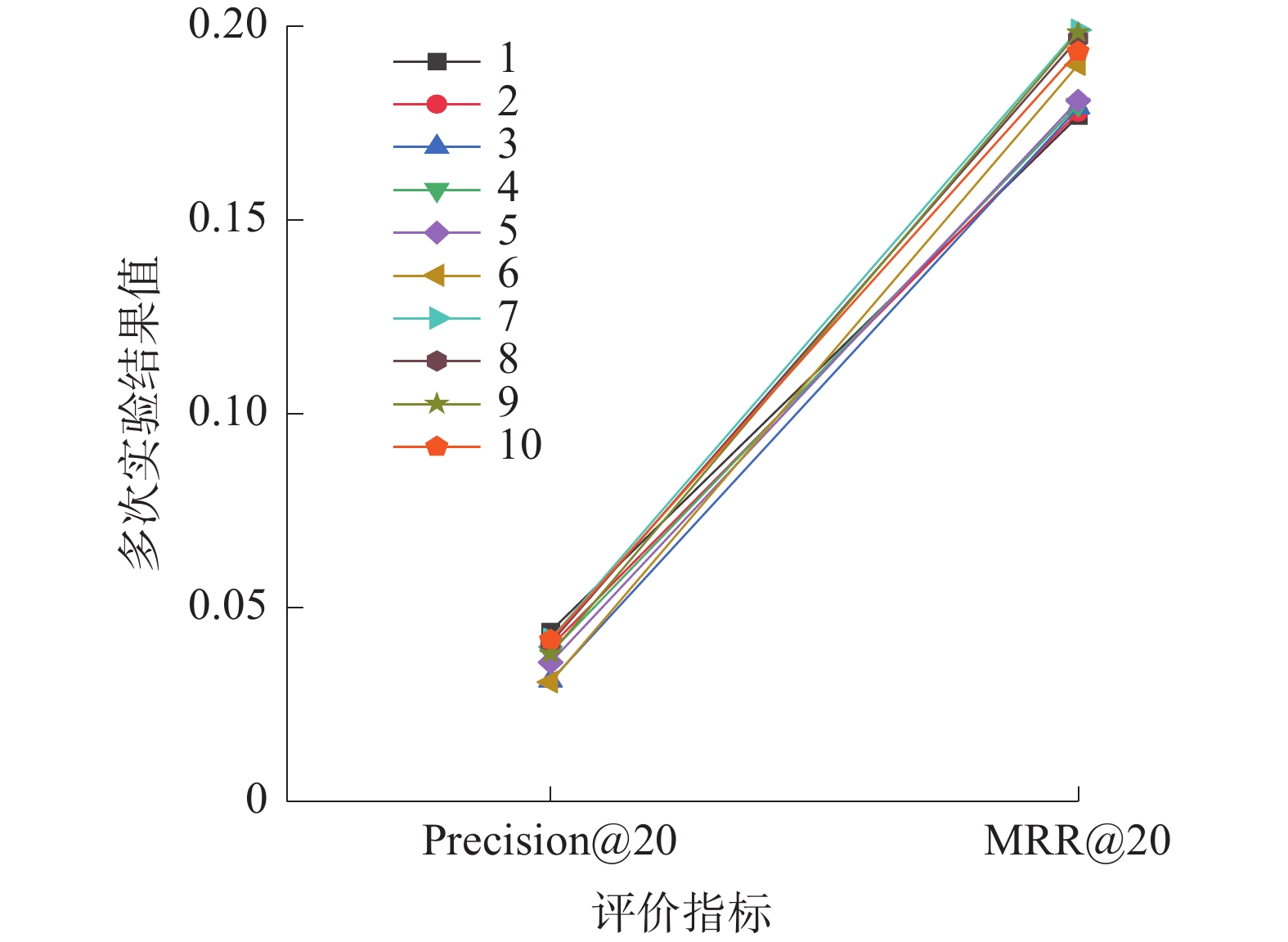 图 3 模型稳定性分析下载:
全尺寸图片
图 3 模型稳定性分析下载:
全尺寸图片
然后通过运行得到的结果计算出每组实验对应的Precision@20、MRR@20共2种评价指标的方差值,为更好地观测方差的变化情况将数据绘制成如图4的折线图来呈现变化情况。从图4中可以看出随着实验组数的逐渐增加,方差值在局部位置有起伏,但是基本上保持平稳,其中Precision@20的方差大致稳定在0.007附近上下波动,MRR@20在0.002上下波动。
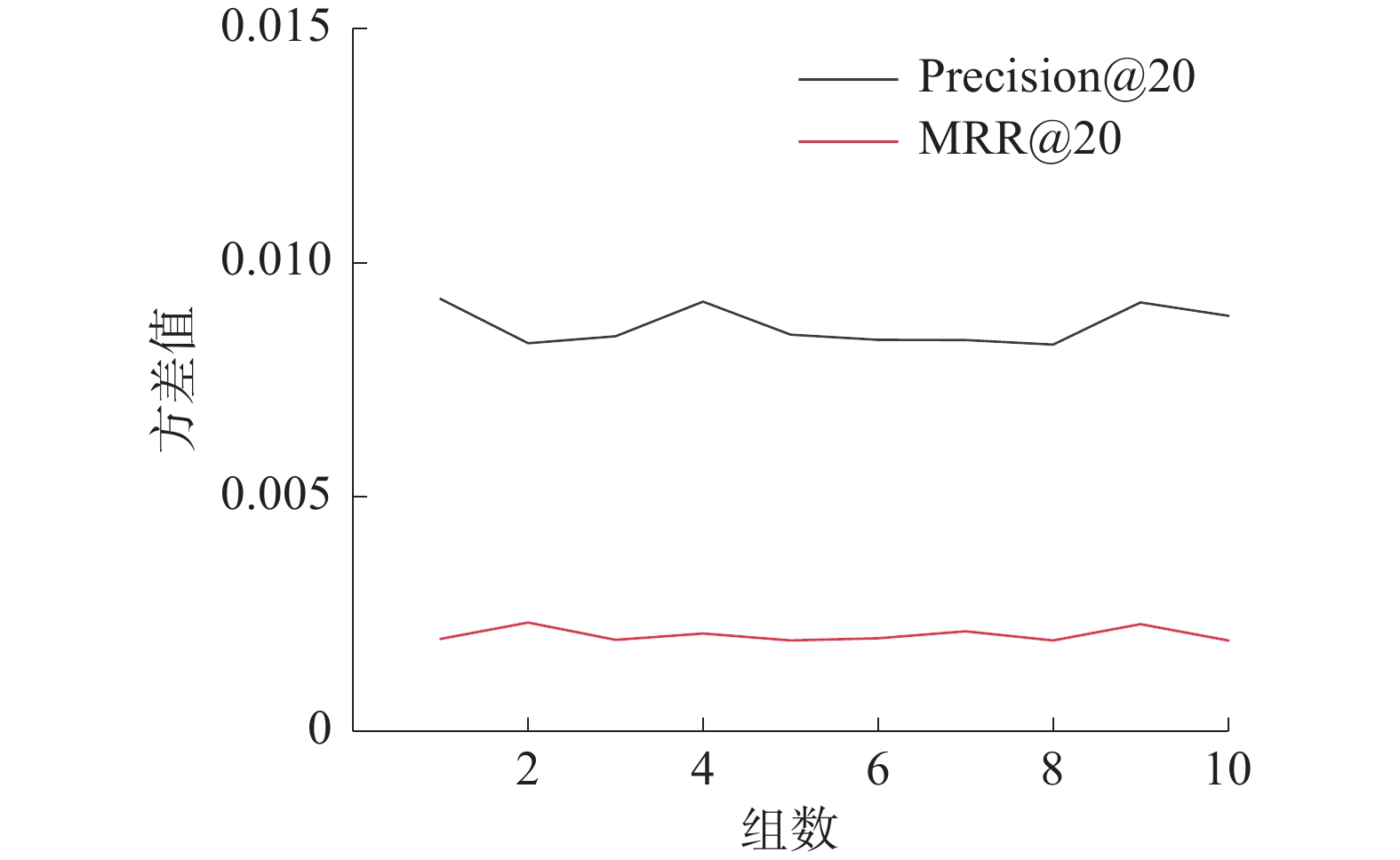 图 4 方差波动情况下载:
全尺寸图片
图 4 方差波动情况下载:
全尺寸图片
3.4.3 向量嵌入维度对模型影响
为了研究向量嵌入维数d对模型推荐性能的影响。将向量嵌入维数的范围设置为[32,64,96,128],分别在Diginetica和Tmall数据集上进行实验,并使用Precision@20值和MRR@20值对不同向量嵌入维数的模型效果进行评价,实验中其他参数值保持原默认值。
如图5所示,随着向量嵌入维数的增加,2个数据集上准确率和平均到排名数都呈上升趋势,但是可以观察到的嵌入维度取d=64时模型的推荐性能优秀,具有较强的表示能力。
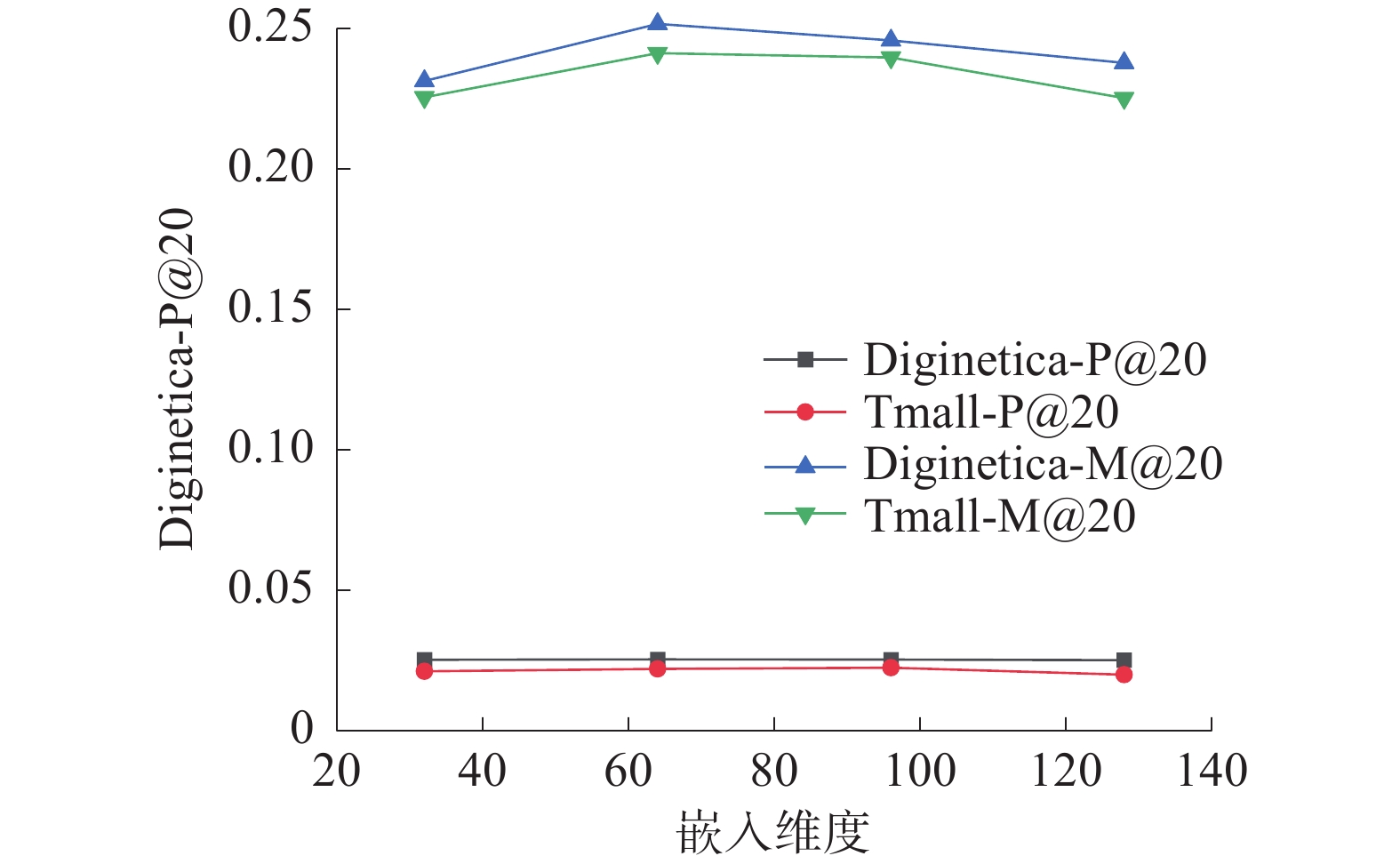 图 5 向量嵌入维度对模型影响下载:
全尺寸图片
图 5 向量嵌入维度对模型影响下载:
全尺寸图片
3.4.4 对比学习参数影响
对比学习可以自动提取与目标项目相关的项,通过训练获取一个有效的去噪模型来增强模型对用户兴趣的理解。在所提方法中,利用超参数
$ \delta $ 来控制对比学习的程度。为了研究对比学习对CLSR-GNN整体性能的影响。将超参数$ \delta $ 的范围设置为{0.0001,0.0005,0.001,0.002,0.005,0.01,0.02},分别在Diginetica和Tmall数据集上进行实验,并使用Precision@20与MRR@20对不同幅度对比学习下模型的性能进行评估,且实验中其他参数取默认值保持不变。当与对比学习任务联合优化时,CLSR-GNN推荐性能得到了不错的提高,不同参数$ \delta $ 值对应的实验结果如图6所示。从图6可以看出,对于这2个数据集,使用较小的$ \delta $ 值进行学习可以同时促进Precision@20和MRR@20,但随着$ \delta $ 逐渐变大时,性能就会下降。这可能是因为较大的$ \delta $ 造成模型过度学习,有用信息可能被去除,形成不太准确的引导,使模型表现不佳。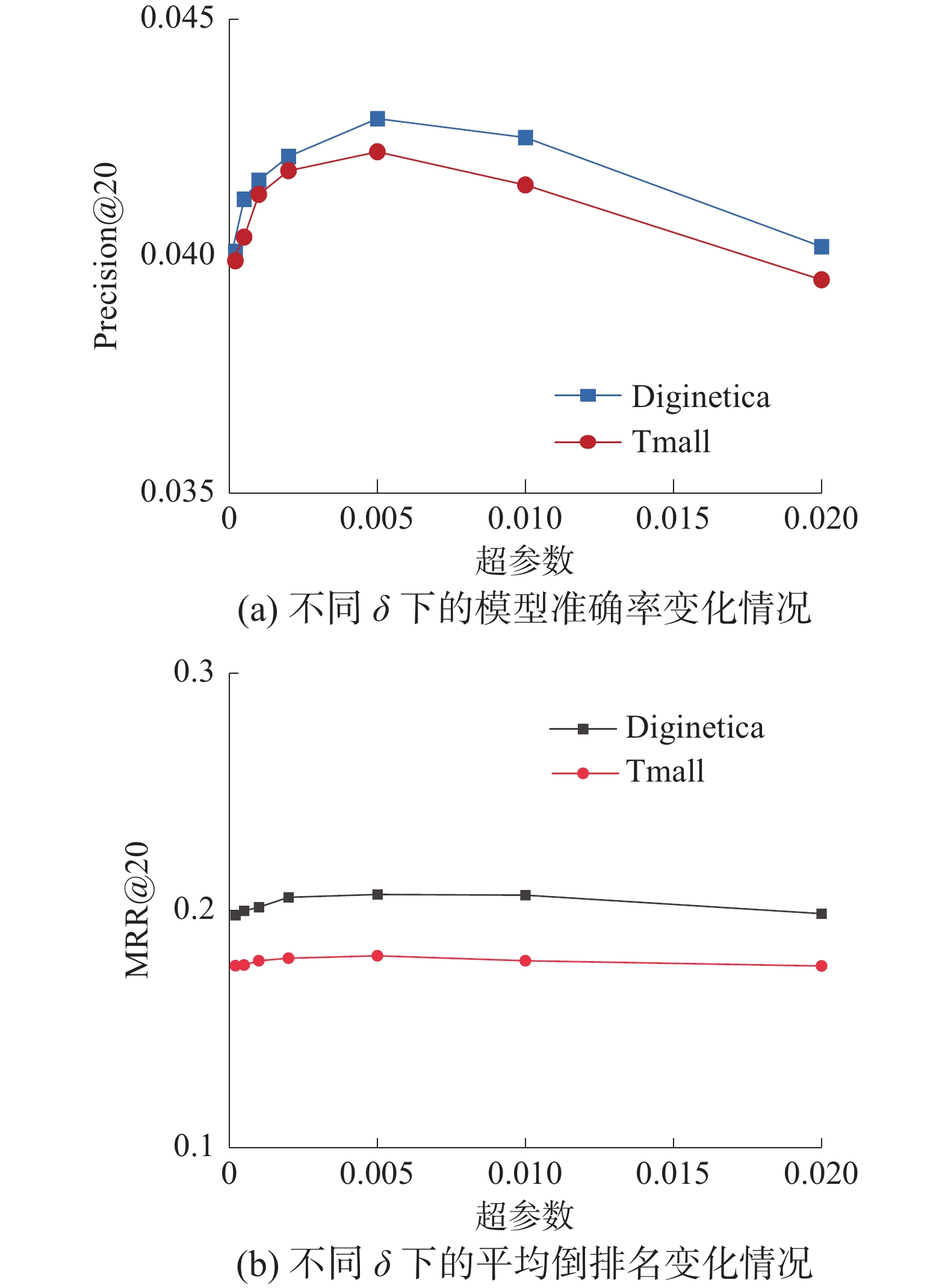 图 6 对比学习参数
图 6 对比学习参数$ \delta $ 对模型影响下载:
全尺寸图片
4. 结束语
本文设计了一种融合对比学习的图神经网络会话推荐模型来解决基于会话的推荐中的2个挑战,即用户意图的动态变化和用户行为的不确定性。不同于在之前的研究,CLSR-GNN模型设计一种噪声滤除器显示地过滤掉会话中的噪声项目。结合对比学习策略进行联合优化去噪,在2个真实数据集上进行的设置对比实验,证明了CLSR-GNN模型的有效性。直接过滤掉会话中的噪声项有助于挖掘用户的真实意图。以上这些研究拓宽了对基于会话的推荐任务的理解,并赋予了推荐系统准确预测用户行为的新的潜力。下一步将研究如何赋予模型多尺度特征功能和轻量化模型结构,以实现更加快速且精确的推荐模型设计。
-
图 1 CLSR-GNN模型整体框架
下载:
全尺寸图片
图 2 会话图和邻接矩阵示例
下载:
全尺寸图片
图 3 模型稳定性分析
下载:
全尺寸图片
图 4 方差波动情况
下载:
全尺寸图片
图 5 向量嵌入维度对模型影响
下载:
全尺寸图片
图 6 对比学习参数
$ \delta $ 对模型影响下载:
全尺寸图片
表 1 实验数据集的统计信息
项目 Diginetica Tmall 点击次数 982 961 818 479 商品数量 184 047 40 728 训练集 719 470 351 268 测试集 60 858 25 898 平均长度 5.12 6.69 表 2 CLSR-GNN和基准模型在2个数据集上的性能比较
数据集 Metric Pop IitemKNN FPMC GRU4Rec Caser LSKGCN S2-DHCN SRGNN CLSR-GNN 改进率/% Diginetica Precision@20 0.0086 0.0327 0.0153 0.0295 0.0204 0.033 0.0416 0.0419 0.0429 2.4 MRR@20 0.0177 0.0948 0.0656 0.0710 0.1016 0.1639 0.197 7 0.1820 0.2067 4.6 Tmall Precision@20 0.0373 0.0756 0.1316 0.0950 0.0978 0.0913 0.040 2 0.0139 0.0422 5.0 MRR@20 0.0269 0.0351 0.0719 0.0579 0.1164 0.1443 0.1258 0.171 5 0.1808 5.4 -
[1] YANG Huaiyuan, ZHOU Hua, LI Yucheng . A review of academic recommendation systems based on intelligent recommendation algorithms[C]//2022 7th International Conference on Image, Vision and Computing. Bordeaux: IEEE, 2022: 958-962. [2] MA Miao, ZHANG Xijing. An intelligent recommendation model for health culture based on short video content analysis in the mobile internet environment[J]. Journal of environmental and public health, 2022, 9(16): 21−30. [3] MALTE Ludewig, DIETMAR Jannach. Evaluation of session-based recommendation algorithms[J]. User modeling and user-adapted interaction, 2018, 28(4): 331−390. [4] WANG Shoujin, CAO Longbing, WANG Yan, et al. A survey on session-based recommender systems[J]. ACM computing surveys, 2021, 54(7): 1−38. [5] DIETMAR Jannach, MALTE Ludewig, LUKAS Lerche. Session-based item recommendation in e-commerce: on short-term intents, reminders, trends and discounts[J]. User modeling and user-adapted interaction, 2017, 27(3): 351−392. [6] WANG Wen, ZHANG Wei, LIU Shukai, et al. Beyond clicks: modeling multi-relational item graph for session-based target behavior prediction[C]//Proceedings of The Web Conference 2020. Lyon: Association for Computing Machinery, 2020: 3056-3062. [7] YING Rex, HE Ruining, CHEN Kaifeng, et al. Graph convolutional neural networks for web-scale recommender systems[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. London: Association for Computing Machinery, 2018: 974-983. [8] LIN ChunWei, SHAO Yinan, DJENOURI Y, et al. ASRNN: a recurrent neural network with an attention model for sequence labeling[J]. Knowledge-based systems, 2021, 212: 106548−106569. doi: 10.1016/j.knosys.2020.106548 [9] WU Sai, REN Weichao, YU Chengchao, et al. Personal recommendation using deep recurrent neural networks in NetEase[C]//2016 IEEE 32nd international conference on data engineering. Finland: IEEE Computer Society, 2016: 1218-1229. [10] 朱志国, 李伟玥, 姜盼, 等. 图神经网络会话推荐系统综述[J]. 计算机工程与应用, 2023, 59(5): 55−69. [11] WU Shu , TANG Yuyuan , ZHU Yanqiao , et al. Session-based recommendation with graph neural networks[C]//Proceedings of the AAAI conference on artificial intelligence. Florence: Katia Sycara, 2019, 33(1): 346-353. [12] MICHAËL Defferrard, XAVIER Bresson, Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering[J]. Advances in neural information processing systems, 2016, 29(6): 32−46. [13] ZHANG Xiaokun, LIN Hongfei, XU Bo, et al. Dynamic intent-aware iterative denoising network for session-based recommendation[J]. Information processing & management, 2022, 59(3): 102936−102949. [14] QIN Yuqi, WANG Pengfei, LI Chenliang. The world is binary: contrastive learning for denoising next basket recommendation[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. Waseda: Association for Computing Machinery, 2021: 859-868. [15] 郑小丽, 王巍, 杜雨晅, 等. 面向会话的需求感知注意图神经网络推荐模型[J/OL]. 计算机工程与应用. http://kns.cnki.net/kcms/detail/11.2127.TP.20230403.1433.012.html. [16] HE Xiangnan, DENG Kuan, WANG Xiang, et al. Lightgcn: simplifying and powering graph convolution network for recommendation[C]//Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. Xi'an: Association for Computing Machinery, 2020: 639-648. [17] FAN Wenqi, MA Yao, Li Qing, He Yuan, et al. Graph neural networks for social recommendation[C]//The world wide web conference. New York: Association for Computing Machinery, 2019: 417-426. [18] WILLIAM L. HAMILTON, REX Ying, JURE Leskovec. Inductive representation learning on large graphs[J]. Advances in neural information processing systems, 2017, 30(6): 567−347. [19] 林幸, 邵新慧. 基于图神经网络的推荐系统模型[J]. 计算机应用与软件, 2023, 40(3): 325−330. [20] XU Chengfeng, ZHAO Pengpeng, LIU Yanchi, et al. Graph contextualized self-attention network for session-based recommendation[C]//IJCAI. 2019: 3940-3946. [21] QIU Ruihong, LI Jingjing, HUANG Huang, et al. Rethinking the item order in session-based recommendation with graph neural networks[C]//Proceedings of the 28th ACM international conference on information and knowledge management. Beijing: Association for Computing Machinery, 2019: 579-588. [22] WANG Ziyang, WEI Wei , CONG Gao , et al. Global context enhanced graph neural networks for session-based recommendation[C]//Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. Xi'an: Association for Computing Machinery, 2020: 169-178. [23] 杨长春, 王俊, 袁敏, 等. 基于weight-pooling词向量的上下文广告推荐算法[J]. 计算机应用与软件, 2016, 33(12): 224−229. [24] PHILIP Bachman, DEVON Hjelm R, WILLIAM Buchwalter. Learning representations by maximizing mutual information across views[J]. Advances in neural information processing systems, 2019, 32(6): 567−572. [25] ZHANG Tianqi, YONG Xiong, ZHANG Jiawei, et al. CommDGI: community detection oriented deep graph infomax[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. Ireland: Association for Computing Machinery. 2020: 1843-1852. [26] KAVEH Hassani, AMIR Hosein Khasahmadi. Contrastive multi-view representation learning on graphs[C]//International Conference on Machine Learning. Honolulu: The International Machine Learning Society, 2020: 4116-4126. [27] ZHOU Kun, WANG XIN Hui, Wayne, et al. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. New York: Association for Computing Machinery, 2020: 1893-1902. [28] XIA Xin, YIN Hongzhi, YU Junliang, et al. Self-supervised hypergraph convolutional networks for session-based recommendation[C]//Proceedings of the AAAI conference on artificial intelligence. New York: Association for Computing Machinery. 2021, 35(5): 4503-4511. [29] 曹杰. 基于KGCN与RippleNet的推荐系统核心特征提取研究[J]. 数字通信世界, 2023(6): 32−34. [30] 李利杰, 张君华. 基于循环神经网络和全局化领域的推荐算法[J]. 计算机与数字工程, 2022, 50(8): 1676−1679. [31] LUIS M. de Campos, JUAN M. Fernández-Luna, JUAN F. Huete, et al. Combining content-based and collaborative recommendations: A hybrid approach based on bayesian networks[J]. International journal of approximate reasoning, 2010, 51(7): 785−799. doi: 10.1016/j.ijar.2010.04.001 [32] ZHU Ziwei, HE Yun, ZHAO Xing, et al. Popularity Bias in Dynamic Recommendation[C]//Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. New York: Association for Computing Machinery, 2021: 2439-2449. [33] YANG Nan, CAO Sanxing, LIANG Yu, et al. Recommendation engine for online short video[C]//2016 4th Intl Conference on Applied Computing and Information Technology/3rd Intl Conf on Computational Science/Intelligence and Applied Informatics/1st Intl Conf on Big Data, Cloud Computing, Data Science & Engineering. Las Vegas: IEEE, 2016: 357-362. [34] 杨达森. DPLORE: 一种差分隐私保护位置推荐算法[J]. 广东工业大学学报, 2021, 38(1): 69−74. [35] ROBIN Devooght, HUGUES Bersini. Long and short-term recommendations with recurrent neural networks[C]//Proceedings of the 25th Conference on User Modeling, Adaptation and Personalization. New York: Association for Computing Machinery, 2017: 13-21. [36] JINSEOK Seol, YOUNGROK Ko, SANG-GOO Lee. Exploiting session information in bert-based session-aware sequential recommendation[C]// Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: Association for Computing Machinery, 2022: 2639-2644. [37] 顾军华, 佘士耀, 樊帅, 等. 基于用户长短期兴趣与知识图卷积网络的推荐[J]. 计算机工程与科学, 2021, 43(3): 511−517.


































