
Scene text detection based on attention mechanism and adaptive scale fusion
-
摘要: 在场景文本检测任务中,由于图像背景复杂、文本实例尺度不一等问题,导致现有模型的文本检测精度不高。为此,本文设计了一种基于注意力机制与自适应尺度融合的场景文本检测模型。首先,通过引入高效通道注意力机制,提高了特征提取网络的表征能力,降低了文字的漏检率和误报率;其次,通过设计自适应尺度融合模块,动态融合不同尺度特征,增强了模型对不同尺度文本实例的检测和定位能力。实验结果表明,本文提出的模型在Total-Text和MSRA-TD500共2个数据集上的F综合指标分别达到85.1%和84.1%,在同类型算法中处于领先水平。Abstract: At present, due to complex image background and different scales of text instances in scene text detection tasks, the text detection accuracy of existing models is not high. Aiming at this problem, we design a scene text detection model based on attention mechanism and adaptive scale fusion. The introduction of high-efficiency channel attention mechanism improves the representation ability of feature extraction network and reduces the false positive rate and false negative rate of texts. At the same time, an adaptive scale fusion module is designed to dynamically fuse the features of different scales, which enhances the detection and localization ability of the model for text instances of different scales. The experimental results show that the comprehensive index of F in Total-Text and MSRA-TD500 datasets is up to 85.1% and 84.1%, respectively, which proves its leading level in the same type of algorithms.
-
场景文本检测作为场景文本理解的一个重要组成部分,旨在对自然场景图像中的文本实例进行定位。因其在图像检索、自动驾驶、智能机器人和盲人辅助系统等场景的广泛应用,近年来受到了越来越多的研究者的关注。然而由于自然场景下的文本形态多样,如存在水平文本、多方向文本和曲线文本、文本实例之间的尺寸变化差距较大,同时还会受到复杂背景或噪声的影响,因此高精度定位每个文本实例的区域仍然是一项具有挑战性的任务。早期的场景文本检测方法通常需要手工设计复杂的特征[1],然后利用分类器来学习文本信息,这种方法精度较低,且不能进行端到端训练。近年来,深度学习技术在目标检测、实例分割等计算机视觉领域取得突破性进展,结合深度学习进行场景文本检测研究逐渐成为研究热点[2]。目前基于深度学习的场景文本检测主要分为:1)基于回归的方法。该类方法通常受到Faster-RCNN和SSD(single shot multiBox detector)等目标检测算法的启发[3],通过预测锚点和像素的偏移定位文本位置,从而直接回归文本实例边界框。具有代表性的有Liao等[4]提出了TextBoxes,采用长条形的卷积核和适应性的锚点,成功地将SSD目标检测框架用于文本检测;Textboxes++[5]增加角度的预测来检测任意方向的文本区域;Ma等[6]提出RRPN (rotation region proposal network)算法,在Faster-RCNN的基础上引入一系列旋转的候选框检测倾斜文本。尽管基于回归的方法在四边形文本检测中取得了良好的性能,但它们往往无法为自然场景中的长文本或弯曲文本表示精确的边界框。2)基于分割的方法。该类型的方法主要从经典语义分割网络FCN(fully convolutional networks)和FPN(feature pyramid network)中汲取灵感[7],首先通过卷积神经网络检测出基本的文本组件,用来表示描述文本区域,然后利用特定的后处理方式重建文本实例。具有代表性的有Wang等[8]提出的PSENet为每个文本实例生成对应的内核,然后采用渐进式尺度算法,逐步扩展预先定义的内核。但是由于PSENet的后处理复杂,模型的前向效率较低,于是作者又提出了像素聚集网络[9](pixel aggregation network,PAN)。PAN是一种高效的任意形状文本检测器,具有低成本的分割头和可学习的后处理。Liao等[10]提出了DB (differentiable binarization)算法,在分割网络中进行自适应二值化处理,简化了后处理步骤,提高了检测性能。Sheng等[11]提出CentripetalText,将文本实例分解为文本内核和向心偏移的组合,更好地检测任意形状的文本。由于像素级分割可以更好地应对文本形态的多样性,因此近年来基于分割的方法在场景文本检测任务中非常流行。但是这类方法的性能很大程度上受到分割精度的影响,同时图像背景杂乱以及文本尺度变化大的特点也给场景文本检测带来了极大的挑战。
针对上述问题,本文对基于分割的方法进行了深入研究,为了解决场景图像中背景特征干扰、文本尺度多变导致的文本检测效果不理想等问题,主要进行了如下的工作:
1)在特征提取阶段引入了高效通道注意力机制 [12],使网络学习到更多有意义的前景特征,解决由于背景特征干扰造成的文字漏检误检的问题。
2)在特征融合阶段设计了自适应尺度融合模块,强化算法应对文本尺度变化的能力,有效提高分割模型的尺度鲁棒性。
3)在曲线文本数据集Total-Text、长文本数据集MSRA-TD500上进行测试和评估,证明了本文算法的有效性和先进性。
1. 模型框架
本文提出的基于高效通道注意力机制和自适应尺度融合模块的场景文本检测模型如图1所示。首先利用ResNet-18[13]作为特征提取网络,并利用高效通道注意力机制来获得不同通道之间的跨通道交互信息,以增强特征提取网络的表征能力,提取的特征经过特征金字塔增强模块以增强不同尺度特征的表现力;然后设计自适应尺度融合模块实现不同尺寸特征的动态融合;最后,利用融合后的特征预测概率图和向心偏移图,用于生成文本实例边界框。下面将详细介绍网络中的各个部分。
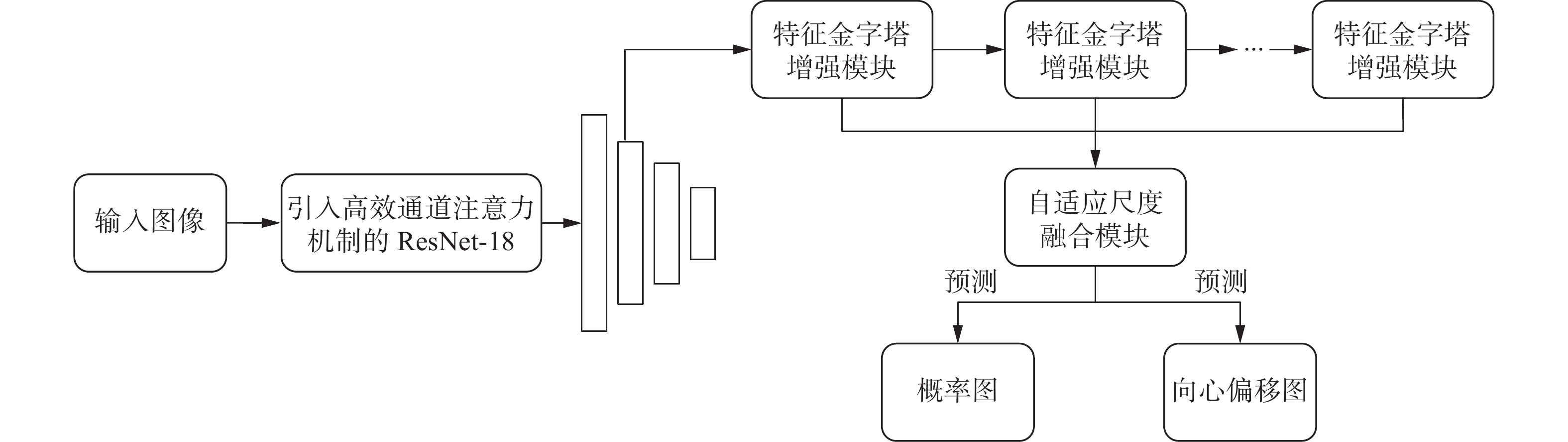 图 1 注意力机制与自适应尺度融合的场景文本检测
图 1 注意力机制与自适应尺度融合的场景文本检测 下载:
全尺寸图片
下载:
全尺寸图片
1.1 高效通道注意力机制
场景图像构图复杂且文字表现形式丰富,这些问题对场景文本检测任务的骨干提取网络提出了较高的要求。通常来讲,网络的深度越深,获取的特征越丰富。但是深度的增加容易造成网络退化或梯度消失的问题。ResNet利用残差连接的方式使网络更容易优化,同时增加了网络深度来获取不同等级的丰富特征,提升了对文本特征的提取能力。ResNet-18网络作为残差网络的典型代表,其性能优异且模型参数较少,仅占用较少的内存空间就能实现较高的准确率[14],因此本文将其作为骨干特征提取网络。
为了筛选出对网络训练更加有利的特征,提高算法对文本实例定位的准确性,本文在ResNet-18的每一个残差结构中引入高效通道注意力机制(efficient channel attention,ECA)。该注意力机制以SE[15](squeeze-and-excitation)模块为原型,并从通道维度缩减和跨通道交互2方面入手对其进行优化。避免通道的降维操作,通过适当的跨通道信息交互,可以有效减少信息丢失,在显著降低模型复杂度的同时提高检测精度。具体实现过程如图2所示。
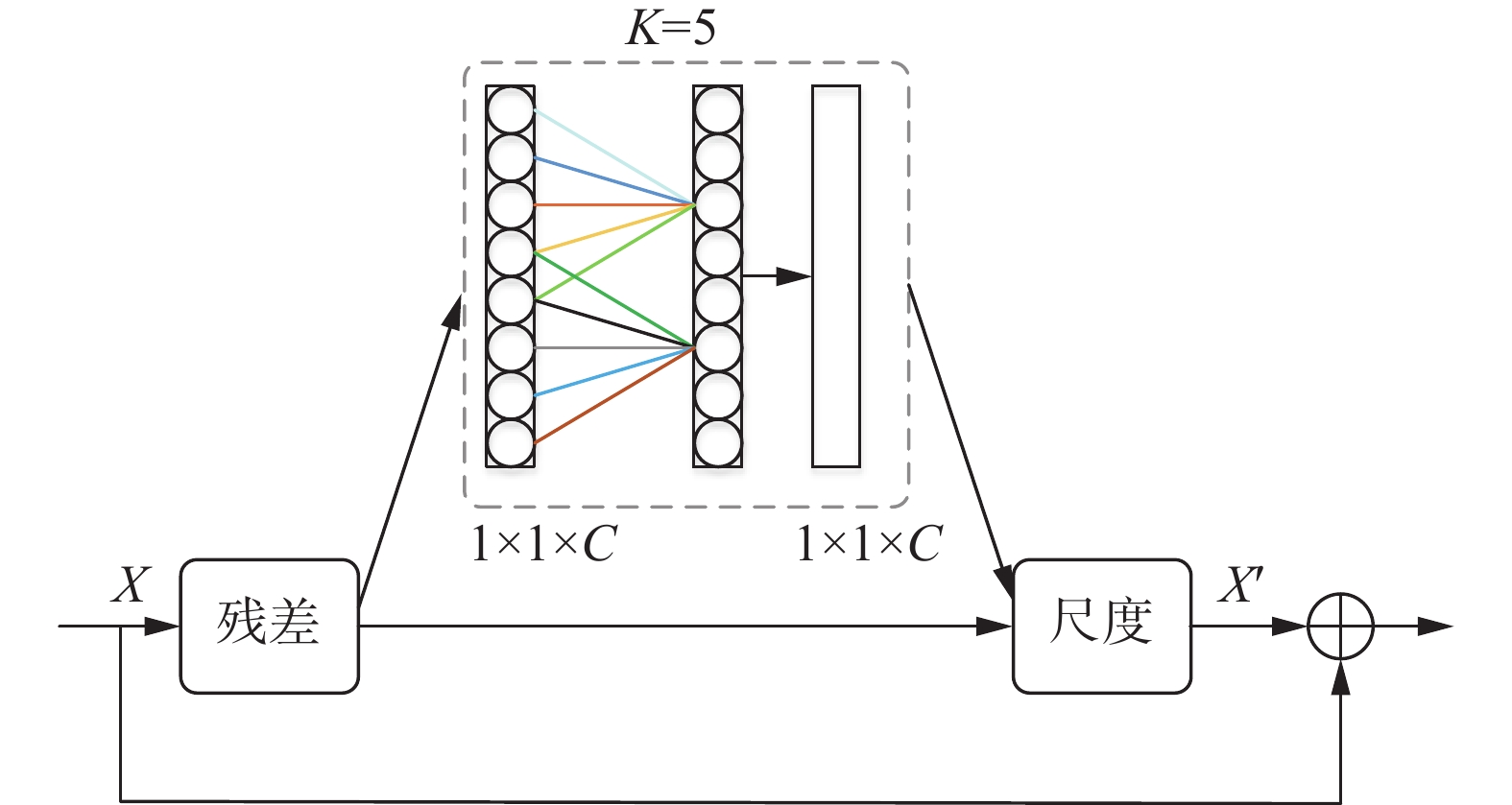 图 2 残差单元中引入高效通道注意力机制下载:
全尺寸图片
图 2 残差单元中引入高效通道注意力机制下载:
全尺寸图片
假设输入特征为
$ {\boldsymbol{X}} \in {{\boldsymbol{R}}^{H \times W \times C}} $ ,其中H、W、C分别为输入特征图的高度、宽度、通道维数。首先,对输入特征${\boldsymbol{X}}$ 进行全局平均池化(global average pooling,GAP)操作,计算每个通道上特征图的像素均值,从而获得通道维度上的全局特征$ {{\boldsymbol{X}}_{{\text{avg}}}} \in {{\boldsymbol{R}}^{1 \times 1 \times C}} $ 。$$ {{\boldsymbol{X}}_{{\rm{avg}}}} = \frac{1}{{{{W}} \times {{H}}}}\sum\limits_{i = 1,j = 1}^{H,W} {{{\boldsymbol{X}}_{i,j}}} $$ 式中
$ {{\boldsymbol{X}}_{i,j}} \in {{\boldsymbol{R}}^C} $ 为$ {\boldsymbol{X}} $ 在$ (i,j) $ 位置的全通道特征。然后,为了避免全连接层的降维操作导致整体网络的性能下降,采用卷积核大小为K的1维卷积来替代全连接层,获得每个通道及其K个邻域通道之间的跨通道交互信息,使用Sigmoid激活函数得到特征权重向量,运算公式为
$$ {\boldsymbol{\omega}} = \sigma (C1{D_K}({{\boldsymbol{X}}_{{\rm{avg}}}})) $$ 式中:
$ C1{D_K} $ 为卷积核大小为K的1维卷积,在本文中K取值为5;$ \sigma $ 为sigmoid激活函数;${\boldsymbol{ \omega}} $ 为生成的通道权重。最后,将权重系数
$ {\boldsymbol{\omega}} $ 与原始输入特征$ {\boldsymbol{X}} $ 相乘,从而完成对$ {\boldsymbol{X}} $ 各通道特征的重新编码。$${\boldsymbol{ X}}' = {\boldsymbol{\omega }} \otimes {\boldsymbol{X}} $$ 式中:
$ \otimes $ 为逐元素相乘,${\boldsymbol{X}}'$ 为经过高效通道注意力模块输出的特征图。1.2 特征金字塔增强模块
尽管在骨干提取网络中引入ECA模块能够使网络更加关注前景特征,提升文本检测的性能,但由于场景图像的模糊、遮挡、光线不均匀等问题,整体提取效果依然不够理想。为此,本文引入了特征金字塔增强模块(feature pyramid enhancement module,FPEM),它是一种可级联模块,计算成本低,可以连接在主干提取网络后面使不同尺寸的特征更深、更具表征能力,从而弥补了特征提取网络感受野受限、特征表示能力较弱的问题[16]。通过对ResNet-18中Conv2、Conv3、Conv4、Conv5阶段产生的4个特征图执行
$ 1 \times 1 $ 的逐点卷积,从而将每个特征图的通道数减少为128,得到1个精简的特征金字塔,然后将此特征金字塔送入后续的FPEM进行特征增强。FPEM是一个U型模块,由上采样增强和下采样增强2部分组成,其结构如图3所示。上采样增强作用于输入的特征,以32、16、8和4的步长在特征图上迭代增强。增强细节如图3黄色虚线框内所示,首先将较高层次特征进行2倍上采样后与较低层次特征对应像素相加,然后经过
$ {\rm{stride}} = 2 $ 的$ 3 \times 3 $ 深度卷积(depthwise convolution,DWConv)和$ 1 \times 1 $ 卷积来增大感受野,同时利用批量归一化(batch normalization,BN)和ReLU激活函数增强网络的非线性表达能力,以此类推得到新的特征金字塔。下采样增强作用于上采样增强阶段的输出特征图,以4、8、16和32的步长在特征图上迭代增强,最终输出增强后的整体特征图。下采样增强细节如图3绿色虚线框内所示。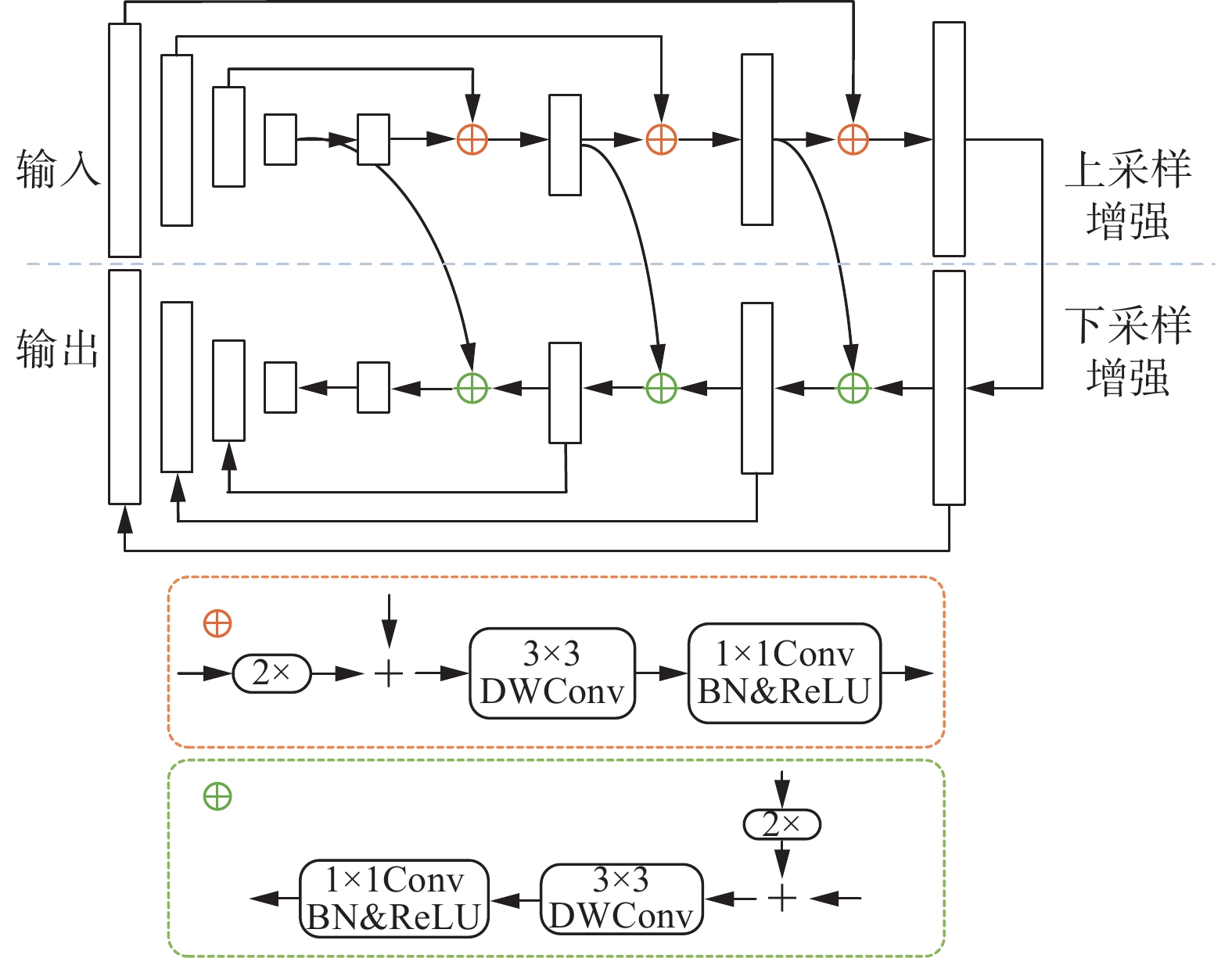 图 3 特征金字塔增强模块下载:
全尺寸图片
图 3 特征金字塔增强模块下载:
全尺寸图片
为了充分利用不同深度的FPEM生成的特征,将相同大小的特征图按元素进行相加,从而得到FPEM的最终输出。具体细节如图4所示。
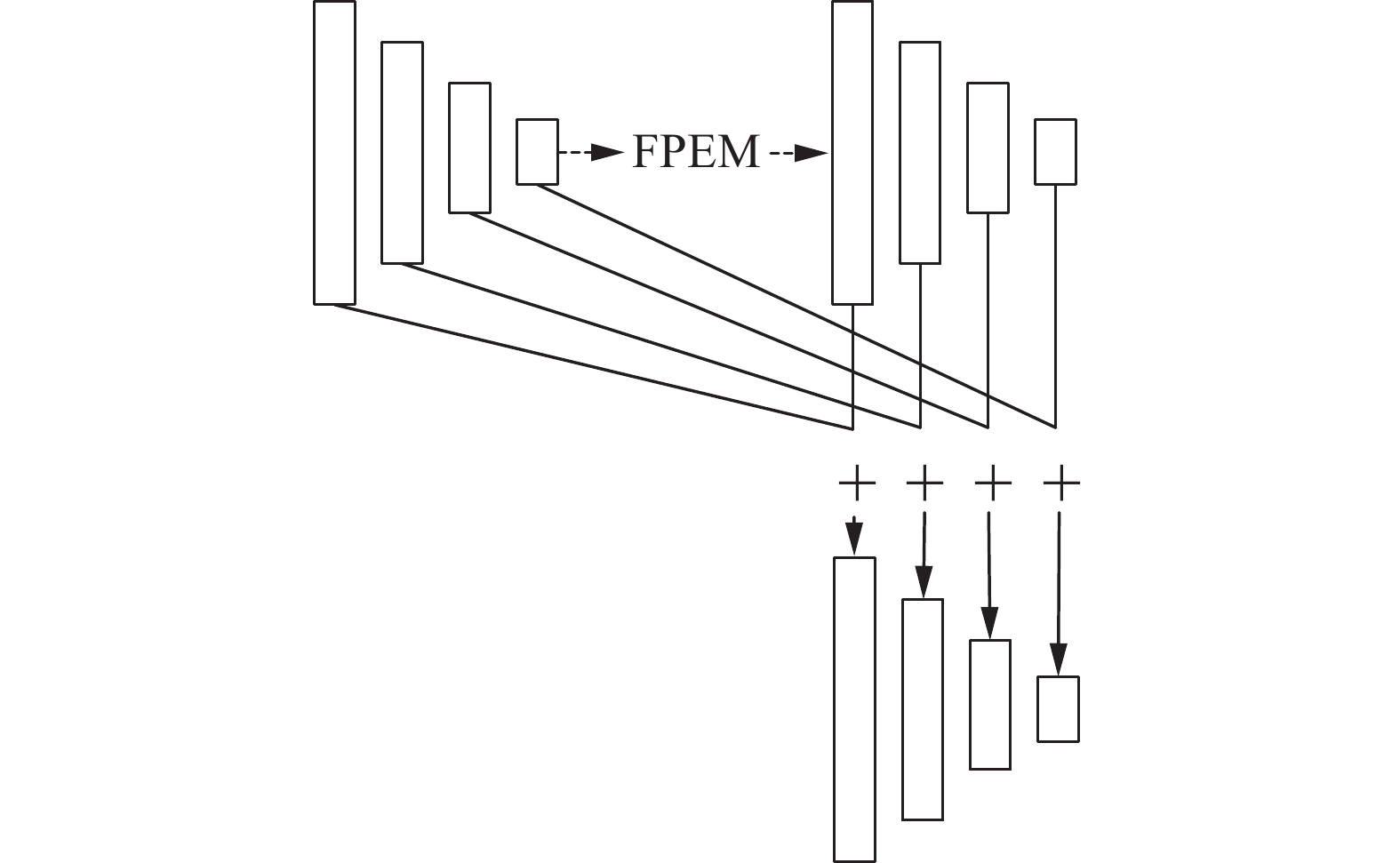 图 4 多个特征金字塔增强模块的最终输出下载:
全尺寸图片
图 4 多个特征金字塔增强模块的最终输出下载:
全尺寸图片
1.3 自适应尺度融合模块
不同尺度的特征具有不同的感受野,因此它们侧重于描述不同尺度的文本实例。其中,大尺寸特征可以感知小文本实例的细节,但不能捕获大文本实例的全局视图,而小尺寸特征则相反。以往基于分割的方法通常采用上采样和拼接的方式直接融合不同尺度特征,没有充分考虑多尺度特征信息,导致模型对不同尺寸文本的检测性能不佳。为了动态融合不同尺寸特征,本文设计了自适应尺度融合模块(adaptive scale fusion module,ASFM)。ASFM采用空间注意力模块计算注意力权重,这些权重参数将会通过网络的学习而进行自适应的更新,同时将学习到的权重沿通道维度拆分与不同尺度特征加权相乘,从而实现了不同尺度特征的自适应融合。图5为自适应尺度融合模块的具体结构。
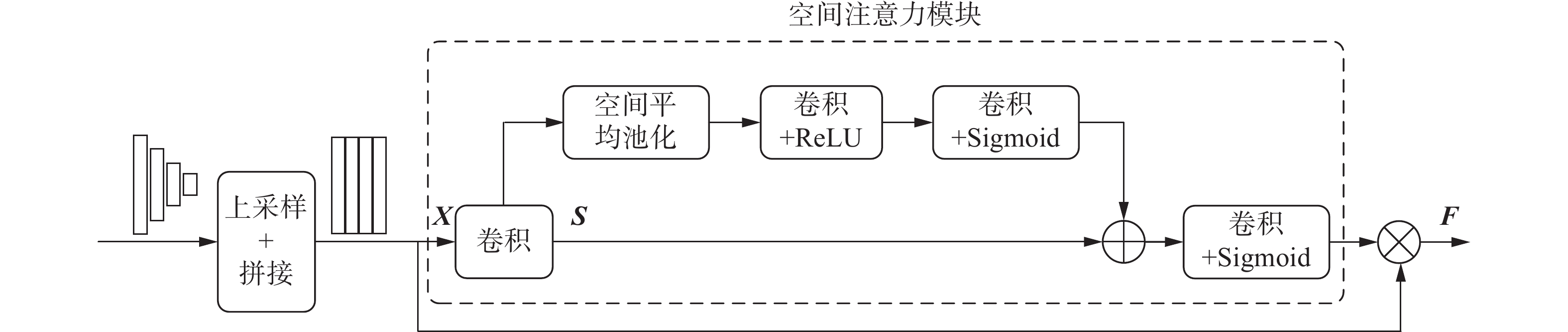 图 5 自适应尺度融合模块下载:
全尺寸图片
图 5 自适应尺度融合模块下载:
全尺寸图片
如图5所示,ASFM将不同尺度的特征图上采样至相同分辨率,假设上采样后的
$N$ 个特征图为$ {{\boldsymbol{X}}}_{i}\in {{\boldsymbol{R}}}^{C\times H\times W}=[{{\boldsymbol{X}}}_{{{0}}},{{\boldsymbol{X}}}_{{{1}}},\cdots,{{\boldsymbol{X}}}_{{{N-1}}}],0\leqslant i \leqslant N-1 $ ,其中$ N = 4 $ ,C、H、W分别表示特征图的通道维数、高度、宽度。首先,将特征图$ {{\boldsymbol{X}}_i} $ 进行拼接得到$ {\boldsymbol{X}} \in {{\boldsymbol{R}}^{N \times C \times H \times W}} $ ,对拼接后的特征图${\boldsymbol{X}}$ 执行$ 3 \times 3 $ 卷积得到中间特征$ {\boldsymbol{S}} \in {{\boldsymbol{R}}^{C \times H \times W}} $ ,计算公式为$$ {\boldsymbol{S }}= {\rm{Conv}}({\rm{concat}}([{{\boldsymbol{X}}_{{0}}},{{{{\boldsymbol{X}}_1}}},\cdots,{{\boldsymbol{X}}_{{{{\boldsymbol{N}} - 1}}}}])) $$ 式中:
$ {\rm{concat}} $ 表示拼接运算,$ {\rm{Conv}} $ 表示$ 3 \times 3 $ 卷积操作。然后,对中间特征
$ {\boldsymbol{S}} $ 应用空间注意力模块,计算出注意力权重${\boldsymbol{A}} \in {{\boldsymbol{R}}^{N \times H \times W}}$ 。$$ {\boldsymbol{A}} = {\rm{Spatial}}\_{\rm{Attention}}({\boldsymbol{S}}) $$ 最后,将注意力权重
$ {\boldsymbol{A}} $ 沿通道维度分成$N$ 个部分,与相应的尺度特征加权相乘,得到最终的融合特征$ {\boldsymbol{F}} \in {{\boldsymbol{R}}^{N \times C \times H \times W}} $ 。$$ \boldsymbol{F}=\operatorname{concat}\left(\left[{{{\boldsymbol{A}}_0 {\boldsymbol{X}}_0, {\boldsymbol{A}}_1 {\boldsymbol{X}}_1,}} \cdots,{{ {\boldsymbol{A}}_{{\boldsymbol{N}}-1} {\boldsymbol{X}}_{{\boldsymbol{N}}-1}}}\right]\right) $$ 式中
$ {\rm{concat }}$ 表示拼接运算。1.4 文本轮廓重建
借鉴CentripetalText[11],将文本实例分解为文本内核和向心偏移的组合,文本内核为原始文本区域的收缩版本,将其作为像素聚合的簇,向心偏移则引导着外部文本像素的聚类。
文本轮廓重建的具体流程如下:1)经过前馈后,网络预测出概率图和向心偏移图;2)用恒定阈值(0.2)对概率图进行二值映射,得到二值图;3)从二值图中找到每一个文本实例对应的文本内核,作为像素聚合的簇;4)根据每个像素点的向心偏移可以将其移动到相应的文本内核或背景区域内;5)为每组文本像素构建文本轮廓。
1.5 损失函数
本文方法的损失函数
$ L $ 由$ {L_{{\text{seg}}}} $ 、$ {L_{{\text{reg}}}} $ 共2部分组成。$$ L = {L_{{\text{seg}}}} + \lambda {L_{{\text{reg}}}} $$ 式中:
$ {L_{{\text{seg}}}} $ 为文本内核的分割损失;$ {L_{{\text{reg}}}} $ 为向心偏移的回归损失;$ \lambda $ 设置为0.05,用来平衡分割损失和回归损失。文本内核的预测是一个像素级的二分类问题,可以采用diceloss[17]进行监督。分割损失的定义如下:
$$ {L_{{\text{seg}}}} = \sum\limits_j {\left( {{M_j} \cdot \left( {1 - \frac{{2 \displaystyle\sum\limits_j {{c_j}{{\hat c}_j}} }}{{ \displaystyle\sum\limits_j {{c_j} + \displaystyle\sum\limits_j {{{\hat c}_j}} } }}} \right)} \right)} $$ 式中:
$ {\hat c_j} $ 和$ {c_j} $ 分别为文本内核分割结果预测的第$ j $ 个像素值、文本内核标签中的第$ j $ 个像素值;$ {M_j} $ 为训练掩膜,将文本区域中非文本内核部分的像素权重置为0,其他像素权重置为1。向心偏移的预测利用SmoothL1loss来计算:
$$ {L_{{\text{reg}}}} = \sum\limits_j {\left( {{R_j} \cdot {\text{Smoot}}{{\text{h}}_{L1}}\left( {{s_j},{{\hat s}_j}} \right)} \right)} $$ $$ \operatorname{Smooth}_{L 1}\left(s_j, \hat{s}_j\right)=\left\{\begin{array}{l} \dfrac{1}{2}\left(s_j-\hat{s}_j\right)^2,\left|s_j-\hat{s}_j\right|<1 \\ \left|s_j-\hat{s}_j\right|-\dfrac{1}{2}, \text { 其他 } \end{array}\right.$$ 式中:
$ {\hat s_j} $ 和$ {s_j} $ 分别为像素点$ j $ 的预测的向心偏移以及向心偏移的真值;${R_j}$ 表示回归掩码,在训练过程中,任何将像素移到正确区域的向心偏移,其权重都被置为1,否则置为0。2. 实验结果及分析
2.1 数据集
Total-Text[18]是1个曲线文本数据集,由1255张训练图像和300张测试图像组成,包含水平、多方向和曲线文本实例。文本区域是由一定数量关键点构成的多边形进行标注的,且注释级别为单词级。
MSRA-TD500[19]是1个长文本数据集,包含300个训练图像和200个测试图像,以文本行级进行标注。由于其规模较小,无法学习深度模型,因此额外使用HUST-TR400数据集中的400张图像作为训练图像。
2.2 实验条件
本文所有实验均是在64位的Ubuntu16.04系统中进行,采用的深度学习框架为Pytorch,在训练过程中利用NVIDIA TESLA V100S显卡进行加速,并且采用python3.7编程语言完成代码的编写。训练数据的扩充包括随机缩放、随机翻转、随机旋转和随机裁剪。在网络训练过程中,采用Adam优化器进行优化,训练批次大小为16,迭代训练600次。学习率衰减采用poly策略,计算公式为
$$ \eta_t=\eta \times \left(1-\frac{\lambda}{\lambda_{\max }}\right)^p $$ 式中:初始学习率
$ \eta$ 为0.001,$\lambda $ 表示当前迭代次数,$\lambda_{\max} $ 表示最大迭代次数,动量P设为0.9。2.3 评价指标
本文采取准确率(precision,P)、召回率(recall,R)、F综合指标(f-measure,F)作为场景文本检测的3个评价指标,准确率表示正确检测的文本框数量占所有检测出的文本框数量的比例,召回率表示正确检测的文本框数量占真实文本框数量的比例,F综合指标表示准确率与召回率的调和平均值,用于评价检测的总体性能。计算公式分别如下:
$$\begin{split} &\quad P = \frac{{{N_{{\text{True}}}}}}{{{N_{{\text{Det}}}}}} \\& \quad R = \frac{{{N_{{\text{True}}}}}}{{{N_{{\text{GT}}}}}} \\& F = \frac{{2 \times P \times R}}{{P + R}} \end{split}$$ 2.4 模型有效性验证
为了验证FPEM模块在检测过程中发挥的作用,本文在Total-Text和MSRA-TD500数据集上进行了有无FPEM模块的实验对比,具体实验结果如表1所示。
表 1 有无FPEM模块检测结果对比数据集 骨干网络 FPEM ECA ASFM P/% R/% F/% Total-Text ResNet-18 × √ √ 87.4 80.5 83.8 √ √ √ 88.9 81.6 85.1 MSRA-TD500 ResNet-18 × √ √ 86.8 79.9 83.2 √ √ √ 88.1 80.5 84.1 由表1可以看出,对于ResNet-18骨干网络,FPEM在Total-Text(弯曲文本数据集)和MSRA-TD500(长文本数据集)上的F综合指标分别实现了1.6%和1.1%的性能提升,从而证明了FPEM模块可以进一步提高主干提取网络的表征能力,提高算法对文本定位的准确性。
为了验证ECA模块和ASFM模块的有效性,本文在Total-Text和MSRA-TD500数据集上进行了消融实验,其中骨干网络为ResNet-18,具体实验结果如表2所示。
表 2 不同数据集上的消融实验结果数据集 骨干网络 FPEM ECA ASFM P/% R/% F/% Total-Text ResNet-18 √ × × 87.2 80.3 83.6 √ √ × 87.8 81.0 84.3 √ × √ 88.6 81.3 84.8 √ √ √ 88.9 81.6 85.1 MSRA-TD500 ResNet-18 √ × × 87.1 79.3 83.0 √ √ × 86.5 80.4 83.3 √ × √ 87.6 80.7 84.0 √ √ √ 88.1 80.5 84.1 由表2可以看出,ECA模块和ASFM模块的使用显著提高了原模型在Total-Text和MSRA-TD500上的检测性能。首先,在原模型中引入ECA模块后,F综合指标在Total-Text数据集上有0.8%的提升,在MSRA-TD500数据集上有0.4% 的提升,证明本文在ResNet-18的残差单元中引入的ECA模块能够提高模型对于有效特征的提取能力,提升了网络的检测性能;其次,在原模型中添加ASFM模块后,F综合指标在Total-Text数据集上有1.4%的提升,在MSRA-TD500数据集上有1.2%的提升,证明ASFM模块能够降低不同尺度文本特征在融合时的不一致性问题,有效提高模型对于文本尺度的鲁棒性;最后,在原模型中联合使用ECA模块和ASFM模块后,F综合指标在Total-Text数据集和MSRA-TD500数据集上分别提升了1.8%和1.3%,性能达到最优,从而证明上述2个改进点是有效的。
2.5 模型先进性验证
为了验证本文改进算法的先进性,在Total-Text数据集和MSRA-TD500数据集上将本文方法与近年来的3种优秀算法进行了对比实验,对比结果如表3和表4所示。
表3为Total-Text数据集上的结果比较。从表3可以看出,本文算法的准确率P、召回率R、F综合指标分别为88.9%、81.6%、85.1%,均高于目前先进的对比算法,且F综合指标相较于表3中最好方法提升1.8%。
不同方法在MSRA-TD500数据集上的检测结果如表4所示。从表4可以看出,本文方法在召回率R和F综合指标上均取得最优。其中F综合指标高达84.1%,与对比算法相比,最小提升幅度达到1.3%,最大提升幅度达到6.6%。
通过对比实验分析,证明本文算法在曲线文本和长文本中能够取得优异的检测性能,进而证明了本文算法的先进性。
3. 结论
1)为解决自然场景图像中文本检测效果差的问题,本文设计了一种基于高效通道注意力和自适应尺度融合的文本检测模型,相比于其他算法模型在各个指标上表现出优异的性能。
2)针对复杂背景导致文本特征提取不准确的问题,引入了高效通道注意力机制,有效增加特征提取过程中重要特征的权重,强化网络对于有用特征信息的利用。同时,设计自适应尺度融合模块,加强算法对不同尺度文本的定位能力,进一步提升场景文本的检测效果。
3)实验结果表明,本文提出的改进算法在各个指标上的结果均较为理想,为后续的场景文本识别工作奠定了较好的基础。今后将对场景文本识别相关工作展开研究, 将自然场景中的文本数字化应用在自动驾驶、智慧物流等实际情景中。
-
图 1 注意力机制与自适应尺度融合的场景文本检测
下载:
全尺寸图片
图 2 残差单元中引入高效通道注意力机制
下载:
全尺寸图片
图 3 特征金字塔增强模块
下载:
全尺寸图片
图 4 多个特征金字塔增强模块的最终输出
下载:
全尺寸图片
图 5 自适应尺度融合模块
下载:
全尺寸图片
表 1 有无FPEM模块检测结果对比
数据集 骨干网络 FPEM ECA ASFM P/% R/% F/% Total-Text ResNet-18 × √ √ 87.4 80.5 83.8 √ √ √ 88.9 81.6 85.1 MSRA-TD500 ResNet-18 × √ √ 86.8 79.9 83.2 √ √ √ 88.1 80.5 84.1 表 2 不同数据集上的消融实验结果
数据集 骨干网络 FPEM ECA ASFM P/% R/% F/% Total-Text ResNet-18 √ × × 87.2 80.3 83.6 √ √ × 87.8 81.0 84.3 √ × √ 88.6 81.3 84.8 √ √ √ 88.9 81.6 85.1 MSRA-TD500 ResNet-18 √ × × 87.1 79.3 83.0 √ √ × 86.5 80.4 83.3 √ × √ 87.6 80.7 84.0 √ √ √ 88.1 80.5 84.1 表 3 Total-Text数据集上算法先进性对比
% -
[1] 董建伟. 阅读场景下文本检测与识别方法研究[D]. 成都: 电子科技大学, 2022. [2] 宋彭彭, 曾祥进, 郑安义, 等. 基于DenseNet的自然场景文本检测[J]. 武汉工程大学学报, 2022, 44(3): 309−314. [3] 赵鹏, 徐本朋, 闫石, 等. 基于双分支特征融合的场景文本检测方法[J]. 控制与决策, 2021, 36(9): 2179−2186. doi: 10.13195/j.kzyjc.2020.0002 [4] LIAO Minghui, SHI Baoguang, BAI Xiang, et al. TextBoxes: a fast text detector with a single deep neural network[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI , 2017: 4161-4167. [5] LIAO Minghui, SHI Baoguang, BAI Xiang. Textboxes++: a single-shot oriented scene text detector[J]. IEEE transactions on image processing, 2018, 27(8): 3676−3690. doi: 10.1109/TIP.2018.2825107 [6] MA Jianqi, SHAO Weiyuan, YE Hao, et al. Arbitrary-oriented scene text detection via rotation proposals[J]. IEEE transactions on multimedia, 2018, 20(11): 3111−3122. doi: 10.1109/TMM.2018.2818020 [7] 陈静娴, 周全. 基于注意力机制特征融合与增强的自然场景文本检测[J]. 无线电工程, 2022, 52(1): 62−69. [8] WANG Wenhai, HU Wenbo, LI Xiang, et al. Shape robust text detection with progressive scale expansion network[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 9336-9345. [9] WANG Wenhai, XIE Enze, SONG Xiaoge, et al. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 8440-8449. [10] LIAO Minghui, WAN Zhaoyi, YAO Cong, et al. Real-time scene text detection with differentiable binarization[C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York: AAAI, 2020: 11474–11481. [11] SHENG Tao, CHEN Jie, LIAN Zhouhui. Centripetaltext: an efficient text instance representation for scene text detection[J]. Advances in neural information processing systems, 2021, 34: 335−346. [12] WANG Qiong , WU Banggu , ZHU Pengfei , et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]//IEEE Conference on Computer Vision and Pattern Recognition, Seattle: IEEE, 2020: 11531-11539. [13] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778. [14] 周啸辉, 余磊, 何茜, 等. 基于改进ResNet-18的红外图像人体行为识别方法研究[J]. 激光与红外, 2021, 51(9): 1178−1184. doi: 10.3969/j.issn.1001-5078.2021.09.011 [15] HU Jie, SHEN Li, SUN Gang. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132-7141. [16] 蔡鑫鑫, 王敏. 基于分割的任意形状场景文本检测[J]. 计算机系统应用, 2020, 29(12): 257−262. doi: 10.15888/j.cnki.csa.007707 [17] MILLETARI F, NAVAB N, AHMADI S A. V-net: Fully convolutional neural networks for volumetric medical image segmentation[C]//2016 Fourth International Conference on 3D Vision (3DV). Stanford: IEEE, 2016: 565-571. [18] CH'NG C K, CHAN C S. Total-text: A comprehensive dataset for scene text detection and recognition[C]//2017 14th IAPR International Conference on Document Analysis and Recognition. Kyoto: IEEE, 2017: 935-942. [19] YAO Cong, BAI Xiang, LIU Wenyu, et al. Detecting texts of arbitrary orientations in natural images[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012: 1083-1090.

































































