
Insulator string pin detection method based on YOLOv5-nS algorithm
-
摘要: 针对变电站绝缘子更换机器人在单片绝缘子更换中多姿态的绝缘子销钉检测困难和检测速度慢的问题,提出了基于YOLOv5所改进的一种快速、可靠的绝缘子销钉检测方法YOLOv5-nS。首先,针对原网络Backbone部分提出了一种新的骨干网络结构,该结构基于ShuffleNetV2所改进的nSNet所构建;其次,对网络的Neck进行了轻量化的同时增加特征融合层;再次,改变边界框回归损失函数,以提升边界框预测的准确率;最后,进行了先验框(Anchor)尺度重选取。实验结果表明:改进后的YOLOv5-nS算法模型在精度基本不变的情况下,参数减少了89.7%,模型尺寸减小了87.5%,帧率提升了7 f/s。Abstract: When a substation insulator replacement robot is used to replace single-piece insulator, it is hard to detect the multi-gesture insulator pins and the detection speed is slow. To solve these defects, a fast and reliable insulator pin detection method YOLOv5-nS is proposed on the basis of YOLOv5. First, a new backbone network structure is proposed for the Backbone part of the original network. Backbone is built on the basis of nSNet obtained by improving ShuffleNetV2; Secondly, a feature fusion layer is added at the same time of lightening the Neck of network; And further, by changing the bounding box regression loss function, the prediction accuracy of bounding box is lifted; Finally, Anchor scale is reselected. The experimental results show that, under the condition that the accuracy of the improved YOLOv5-nS algorithm model is kept basically unchanged, the parameters are reduced by 89.7%, the model size is reduced by 87.5%, and the frame rate is increased by 7 f/s.
-
Keywords:
- Yolov5 /
- insulator string pins /
- computer vision /
- deep learning /
- artificial intelligence /
- target detection
-
绝缘子主要用于电气绝缘和机械支撑,是架设输电线路过程中的必要部件。绝缘子在长期运行过程中受高压场强、机械负荷、酸雨、雷击以及大气环境的影响,导致其电气性能与机械性能下降,以致其被击穿或破坏。对于这些劣化的绝缘子必须及时更换,若不及时处理则会引发一系列的突发事件,在经济上造成巨大的损失,严重时甚至会导致电力系统运行的停滞[1-2]。目前,变电站更换绝缘子的作业方式主要采用人工现场作业,这种作业方式危险性高、劳动强度大、效率低而且更换作业难以操作[3]。因此研发具有更换绝缘子功能的机器人成为了电力系统的实际迫切需求。在机器人进行更换作业时,机器人需要具备识别出绝缘子销钉位置的能力,因此在户外复杂光景环境中准确地识别绝缘子销钉位置是本文的研究重点。
近年来,深度学习技术已在图像检测和识别方面取得了突出成果,主要包含一步检测算法与两步检测算法2类。一步检测典型算法主要有单次多边框检测(single shot multibox detector,SSD)[4]和YOLO系列[5-7]等,该类算法将目标检测转换为先验框(Anchor)回归问题,能在满足实时性的同时保持较高检测精度;两步检测典型算法主要有基于区域的卷积神经网络(region-based convolution neural networks,R-CNN)[8]、Fast R-CNN[9]、Faster R-CNN[10]等,该类算法第一阶段提出候选目标边界框,第二阶段采用感兴趣区域(region of interest,ROI)操作,从每个候选框中提取特征用于接下来的分类和边界框回归任务。
目标检测作为目前任务场景理解感知的重要组成部分,已经在实际工程中得到广泛应用,但是,基于深度学习的绝缘子销钉识别任务研究起步较晚,研究成果较少。李瑞生等[11]采用基于SSD单阶段检测算法改进优化来检测输电线路中存在缺陷故障的销钉,并与传统检测方法进行对比实验,结果显示所提出的方法检测精度更高。郝帅等[12]在基于YOLOv3网络算法模型中添加了性能突出的视觉注意力机制模型,并验证了该方法相比于其他目标检测算法模型如SSD、Faster R-CNN等在全类别平均正确率(mean average precision,mAp)和帧率上都具有较好的性能表现。徐文静等[13]基于YOLOv5网络算法模型针对绝缘子图片实现自动标注,该方法能够快速、有效地对绝缘子图进行自动标注,但如果目标处于相对复杂光照的背景条件下,图片中有效目标特征难以获取,且模型体积庞大、检测速度低。
本文为了降低模型复杂度、提高识别速度,基于ShuffleNetV2[14]所改进的nSNet模块提出一种轻量型神经网络主干部分;为了更好地实现不同尺度下目标特征的高效融合,在Neck中增加了特征融合层并对原有Neck进行了轻量化操作;用Alpha-IoU[15]作为边框回归损失函数,以提升检验框检测的准确率;采用K-means聚类算法对Anchor尺寸重选取,以提高对绝缘子串销钉的检测精度和训练效率。
1. YOLOv5算法原理
YOLOv5是目前较为先进的单阶段目标检测算法,其Backbone借鉴参考了CSPNet[16]思想,采用改进版的CSPNet作为主干网络的主要结构,并在Neck端进行多尺度融合,以提高预测精度[17]。同时,它采用Pytorch框架使其网络规模比YOLOv4更小。YOLOv5网络结构如图1所示。
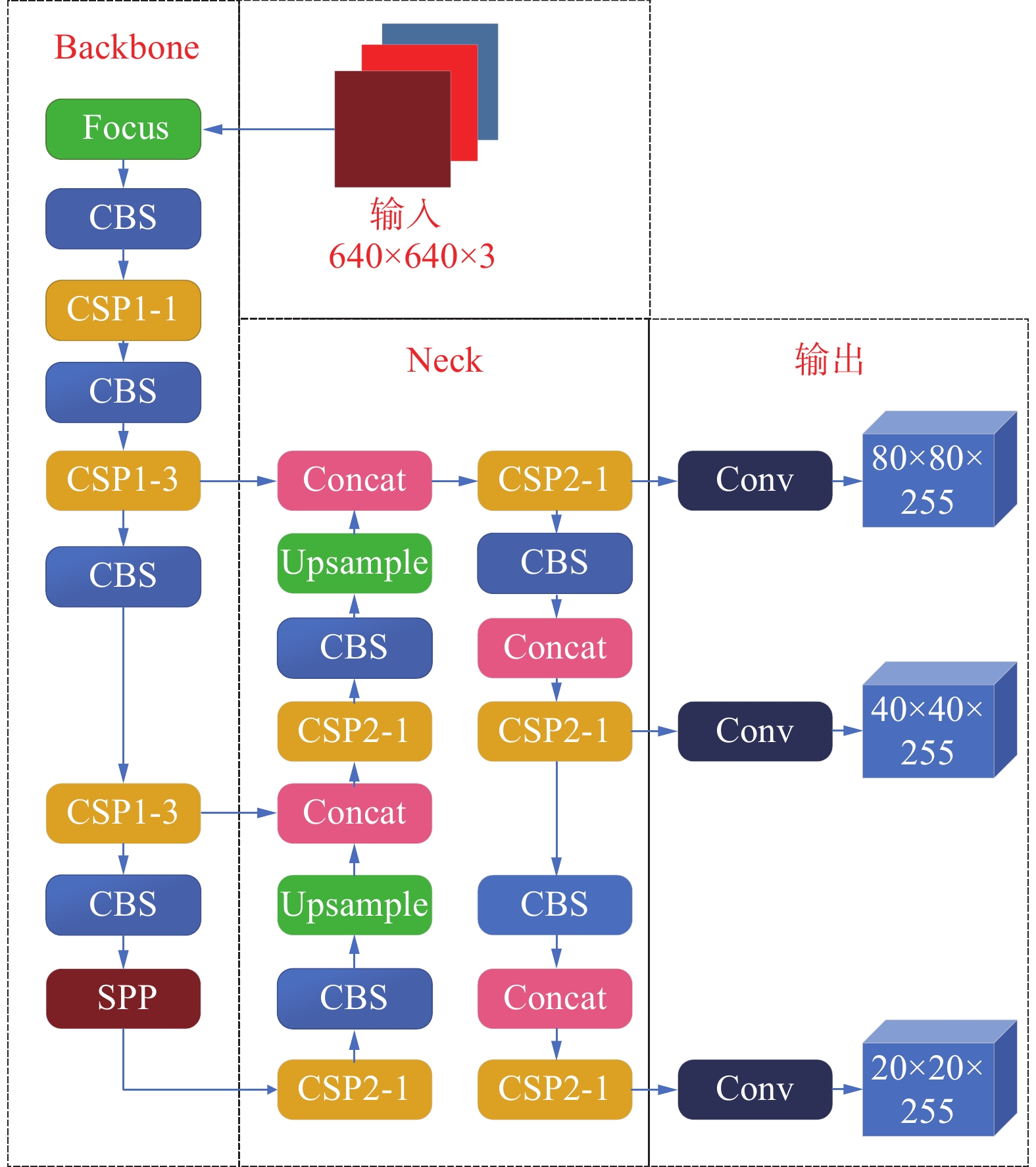 图 1 YOLOv5模型结构
图 1 YOLOv5模型结构 下载:
全尺寸图片
下载:
全尺寸图片
输入部分主要完成图像预处理。将输入图像尺寸转换为网络的输入大小、数据增强以及自适应锚框计算工作。
Backbone部分主要完成提取图像的特征信息。在该部分中,Focus模块将图片进行切分、连接再卷积,相当于下采样操作,目的在于保留图像的全部信息;CBS模块由卷积操作Conv层、归一化操作、BN层以及SiLU激活函数组成;CSP1_X结构中X代表CSP结构中使用的残差组件,每个残差组件都使用了2个CBS结构,目的在于减小模型大小的同时保证精度不会下降;SPP模块通过使用内核为1×1、9×9以及13×13来进行最大池化,满足最终输入一致。
Neck部分主要完成多尺度的特征融合,采用FPN+PAN的结构。
输出部分主要完成输出检测到的目标信息。
2. YOLOv5-nS 算法设计
在本节介绍了YOLOv5-nS模型Backbone的设计思想和策略,提出了Neck的增强优化策略,描述了对于边界框回归损失函数的改进方式,对于Anchor尺度重选取策略进行了描述。YOLOv5-nS结构如图2所示。
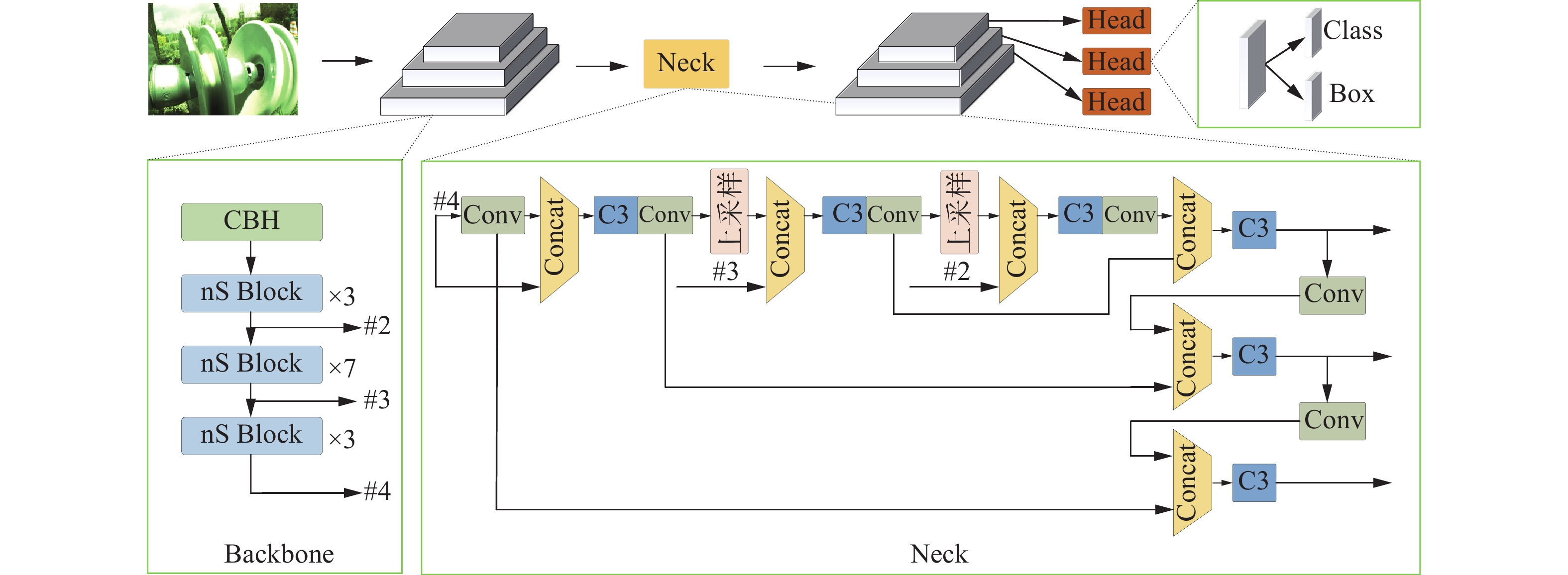 图 2 YOLOv5-nS结构下载:
全尺寸图片
图 2 YOLOv5-nS结构下载:
全尺寸图片
2.1 Backbone网络设计策略
现阶段在移动设备上ShuffleNetV2网络结构比其他网络更可靠。针对本文任务,为了进一步提高YOLOv5模型的性能,我们遵循PPLCNet[18]的一些方法来增强ShuffleNetV2网络结构并构建新的骨干网络,即nSNet(new ShuffleNetV2)。图3详细描述了nSNet的nS Block结构。
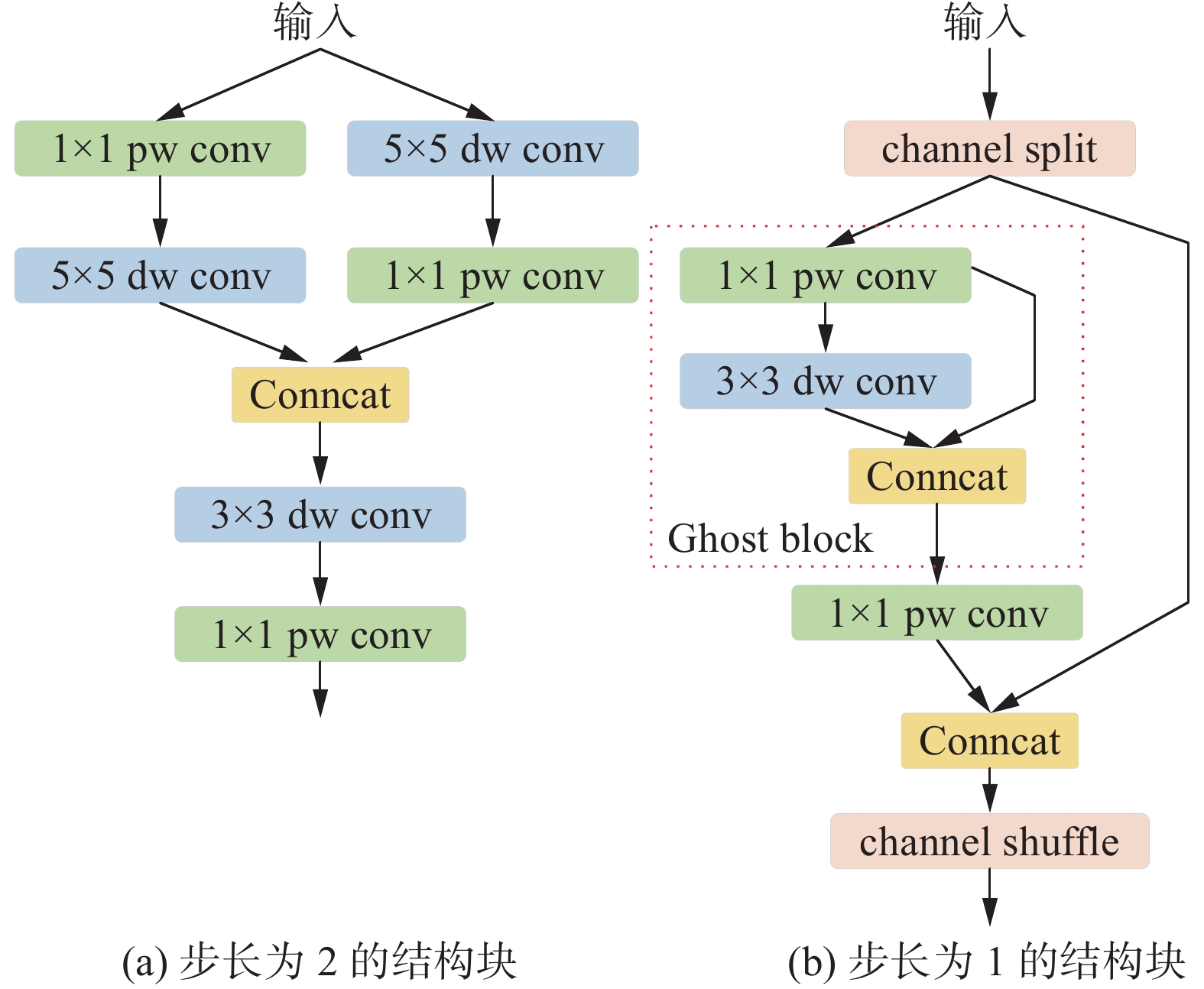 图 3 nS Block结构下载:
全尺寸图片
图 3 nS Block结构下载:
全尺寸图片
Channel shuffle为ShuffleNetV2网络结构提供了信道间的信息交换,但会导致融合特征的丢失。为了解决这个问题,在步长为2的结构块中,增加了深度可分离卷积和点卷积用来整合不同信道间的信息。此外,还采用了卷积核为5×5的深度可分离卷积结构扩展接受野,这种结构以增加少量参数带来了精度的提高。
GhostNet[19]的作者提出了一种新的Ghost模块,可以用更少的参数生成更多的特征图,以提高网络的学习能力。在步长设置为1的区块中添加Ghost模块,以进一步增强nSNet的性能。
深度可分离卷积[20]由2种不同的卷积操作组成:第一步先进行逐通道卷积,对输入层的每个通道独立进行卷积运算,省略了通道域中的卷积,大大降低了计算量,但是没有融合通道间信息;第二步再进行逐点卷积运算操作,将上一步的特征图在其通道间进行加权线性组合,生成新的特征图。深度可分离卷积的参数的数量约是常规普通卷积的1/3,可以降低原网络的计算量和参数个数。其简要结构原理如图4所示。
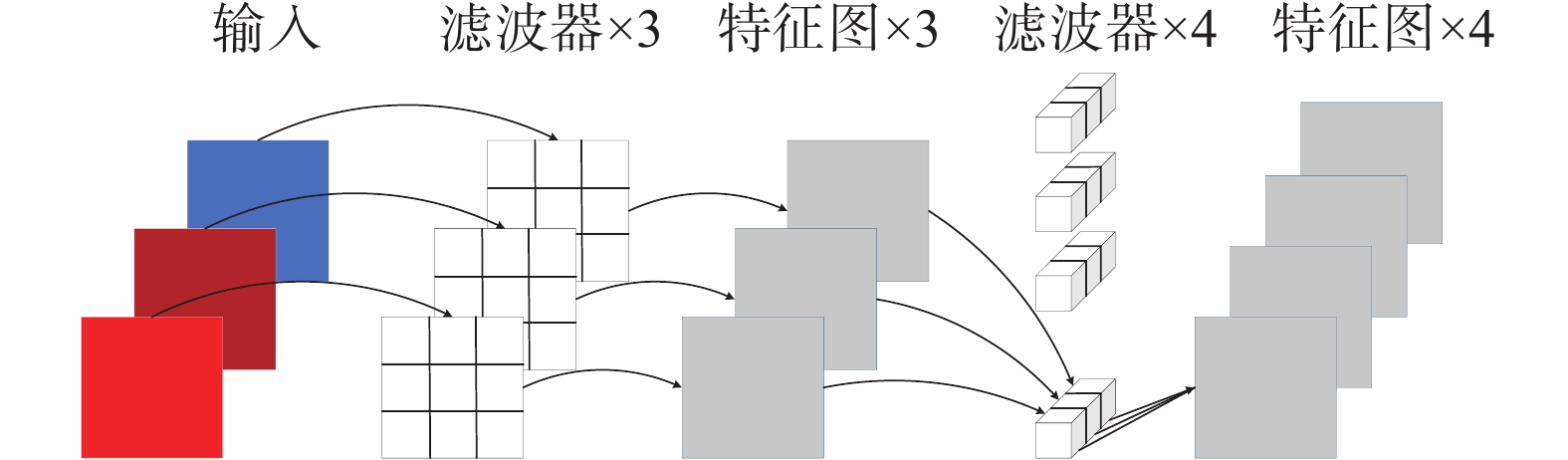 图 4 深度可分离卷积原理下载:
全尺寸图片
图 4 深度可分离卷积原理下载:
全尺寸图片
2.2 Neck端改进策略
YOLOv5模型以FPN+PAN结构对Backbone提取的多尺度特征图进行融合。由于这种融合方式将特征图变换成相同尺寸后进行级联,无法充分利用不同尺度间的特征,造成网络模型的检测精度受到限制。为了提高网络模型对于多尺度特征图的融合性能,在YOLOv5的Neck中增加了一层特征融合,使网络模型在多尺度特征融合过程中获得更多的有效信息,对于目标物体的检测更加准确;同时,增加了网络模型的感受野层次结构,使网络模型的多尺度特征融合更加充分。
此外,文中对Neck端还进行了轻量化的改进,将Neck端原有的3个残差结构降为1个残差结构;对原有将Neck端的卷积通道数进行了降维,使其算法模型加轻量化。
2.3 边界框回归损失函数改进
YOLOv5的损失函数L的定义为
$$ L = {l_{{\text{obj}}}} + {l_{{\text{cls}}}} + {l_{{\text{box}}}} $$ 式中:
${l_{{\text{obj}}}}$ 为置信度损失,${l_{{\text{cls}}}}$ 为分类概率损失,${l_{{\text{box}}}}$ 为真实框和预测框的位置损失。YOLOv5网络模型中真实框和预测框的位置损失函数采用CIoU Loss损失函数实现:
$$ {L_{{\text{CIoU}}}} = 1 - {R_{{\text{IoU}}}} + \frac{{{\rho ^2}(b,{b^{{\text{gt}}}})}}{{{c^2}}} + \beta v $$ 式中:
$\rho $ 为计算预测目标框中心点$b$ 与真实目标框中心点${b^{{\text{gt}}}}$ 这2个中心点之间的欧氏距离;$c$ 是可以框住预测目标框和真实目标框最小长方形的对角线的长度;RIoU为预测目标框与真实目标框的交集与并集之比;$\beta $ 为权衡长宽比例造成的损失和IoU部分造成的损失的平衡因子:$$ \beta = \frac{v}{{(1 - {R_{{\text{IoU}}}}) + v}} $$ 其中
$v$ 为预测框和真实框长宽比归一化值:$$ v = \frac{4}{{{{\text{π}} ^2}}}{\left(\arctan \frac{{{w^{{\text{gt}}}}}}{{{h^{{\text{gt}}}}}} - \arctan \frac{w}{h}\right)^2} $$ 式中:
$h$ 、${h^{{\text{gt}}}}$ 分别为预测目标框和真实目标框的高度,$w$ 、${w^{{\text{gt}}}}$ 分别为预测目标框和真实目标框的宽度。本文任务中,数据集小并且需要高精确度的目标定位,因此采用性能更优的Alpha-IoU来计算真实框和预测框的位置损失。Alpha-IoU是基于IoU Loss采取幂变换提出了一个新的损失函数,通过调节参数α,使探测器更灵活地实现不同水平的边界框回归精度,对含有噪声的小数据集上鲁棒性更强。Alpha-IoU损失函数为
$$ {L_{\alpha {\text{-CIoU}}}} = 1 - {R_{{\text{IoU}}}}^\alpha + \frac{{{\rho ^{2\alpha }}(b,{b^{{\text{gt}}}})}}{{{c^{2\alpha }}}} + {(\beta v)^\alpha } $$ 2.4 Anchor尺度重选取策略
在大多数应用场景下的目标检测任务中,对于初始Anchor大小的选取非常重要,Anchor大小是否合适将直接影响目标物体检测的结果,同时还会影响训练速度。YOLOv5模型算法对COCO数据集设计生成不同大小的9种Anchor,有3种不同尺度,且每种尺度对应3种不同大小的比例。针对本文任务,被检测目标的真实框尺寸较小且变化幅度小。在训练之前采用K-means聚类算法对Anchor尺度进行重选取,提高对绝缘子串销钉的检测精度和训练效率。K-means聚类算法采用欧氏距离聚类得到n个Anchors,再使用遗传算法随机对Anchor的长宽进行变异,变异后效果更好的保留,否则跳过。通过以上操作完成Anchor的重新选取,先验框尺度如表1所示。
表 1 先验框尺度感受野 大 中 小 先验框 24×19 19×15 11×9 22×21 18×16 14×13 25×24 20×18 18×13 3. 实验
3.1 数据集以及实验环境
由于目前没有变电站悬式绝缘子的公开数据集,因此数据集为自行搭建,采集绝缘子图像进行筛选、标注等处理后,一共1400张图像,其中划分训练集1000张,验证集200张,测试集200张。
实验采用的操作系统为Windows10,GPU型号为NVIDIA GeForce GTX 1050 Ti,显存大小为4 GB,内存大小为8 GB,CPU型号为Intel(R) Core(TM) i5-10400F CPU @ 2.90 GHz,模型基于Pytorch1.7.1实现。
3.2 实验过程
3.2.1 nSNet与ShuffleNetV2性能对比实验
基于YOLOv5s网络模型,在绝缘子销钉的小型数据集上比较了nSNet模块构建的主干网络与ShuffleNetV2模块构建主干网络的性能,参数为主干网络参数个数,评价指标mAP@0.5是实际框与预测框交并比等于0.5时的目标检测准确率,mAP@0.5:0.95是指实际框与预测框交并比从0.5开始,以0.05间隔直到0.95的平均目标检测准确度,实验结果如表2所示。
表 2 nSNet与ShuffleNetV2性能对比主干网络 参数 mAP@0.5 mAP@0.5:0.95 nSNet 214272 0.973 0.614 ShufflNetV2 108204 0.908 0.515 表2表明,ShuffleNetV2构建的Backbone虽然结构更加简单、更加轻量化,但实验证明nSNet模块构建的Backbone性能更优,其mAP@0.5:0.95比ShuffleNetV2模块构建的主干网络高19.2%,mAP@0.5高7.2%。
此外文中还比较了卷积核分别为为3×3、5×5的深度可分离卷积的nSNet模块构建的主干网络的性能,参数为主干网络参数个数,实验结果如表3所示。
表 3 nSNet模块与卷积核为3×3与5×5性能对比卷积核尺寸 参数 mAP@0.5 mAP@0.5:0.95 3×3 205440 0.959 0.601 5×5 214272 0.973 0.614 表3表明,大尺寸卷积核比小尺寸卷积核在参数个数小范围增加下,其构建的nSNet性能更优。
3.2.2 消融实验
在绝缘子销钉的小型数据集上进行了消融实验,其结果如表4所示。
表 4 YOLOv5-nS的消融实验模型 模型大小/MB mAP@0.5:0.95 YOLOv5s 14.4 0.628 nSNet 1.7 0.579 nSNet+特征融合层 1.8 0.614 nSNet+特征融合层+K-means 1.8 0.615 nSNet+特征融合层+K-means+Alpha-IoU 1.8 0.617 消融实验结果显示,本文提出的Backbone结构可以有效降低网络算法模型大小,大大减小了特征提取的参数量,但是精度较原始算法模型有一定幅度的下降;通过增加特征融合层、提高感受野的层次结构,在参数量小幅度上升的情况下mAP@0.5:0.95提高了6%;采用K-means聚类算法对Anchor尺度重新选取、改进边界框回归损失函数,二者对于算法模型的检测精度均有一个较小的提升。
3.2.3 YOLOv5-nS先进性验证
为了验证本文YOLOv5-nS改进算法的先进性,我们与目前先进的相关目标检测算法在自建数据集上进行了模型算法对比。本文对比的模型有两阶段目标检测模型Faster-RCNN、单阶段目标检测模型SSD以及YOLOv3-SPP,其实验结果如表5所示。
表 5 YOLOv5-nS与其他算法对比算法模型 mAP@.5 mAP@0.5:0.95 平均测试
时间/s模型
大小/MBFaster-RCNN 0.692 0.354 0.196 628 YOLOv3-SPP 0.798 0.467 0.059 322 SSD 0.856 0.55 0.034 100 YOLOv5-nS 0.959 0.617 0.018 1.8 由表5可以看出,本文改进算法YOLOv5-nS与其他检测算法相比,在mAP@0.5:0.95与mAP@0.5上取得了最优的识别效果;与SSD算法相比,mAP@0.5提高了12%、mAP@0.5:0.95提高了12.2%;在每张图片检测速度方面,YOLOv5-nS比SSD快了0.016 s,算法模型相对更小。
3.2.4 实验结果分析
对本文所提出的改进算法与原算法模型进行比对,其结果如表6所示。
表 6 YOLOv5-nS与YOLOv5s性能比对算法 参数 模型
大小/MBmAP@0.5:0.95 帧率/(f/s) YOLOv5s 7063542 14.4 0.628 48 YOLOv5-nS 725046 1.8 0.617 55 由表6可以看出,在mAP@0.5:0.95下降1.8%的情况下,YOLOv5-nS比YOLOv5s的参数少了89.7%,模型大小减小了87.5%,帧率提升了7 f/s。虽然YOLOv5-nS的mAP@0.5:0.95有所下降,但是满足绝缘子串销钉的检测任务需求,且检测速度更快,算法模型更加轻量化。
为了进一步验证YOLOv5-nS在户外复杂光照场景下对多姿态绝缘子销钉的检测的适用性,选取了数据集中非训练集的部分数据进行检测,结果如图5和图6所示。
 图 5 光照不充足场景下绝缘子销钉检测结果下载:
全尺寸图片
图 5 光照不充足场景下绝缘子销钉检测结果下载:
全尺寸图片
 图 6 强光场景下绝缘子销钉检测结果下载:
全尺寸图片
图 6 强光场景下绝缘子销钉检测结果下载:
全尺寸图片
由图5与图6可以看出,YOLOv5-nS可以有效地检测出不同光照场景下的多姿态绝缘子销钉,不易受到复杂光照与姿态的影响,具有良好的鲁棒性。
4. 结论
针对复杂光照场景中多姿态绝缘子销钉检测检测困难和检测速度慢的问题,本文基于YOLOv5提出了一种适应性强、更加轻量化的YOLOv5-nS算法模型。
1)基于nSNet模块所提出的一种新的Backbone网络结构,可以有效减少网络特征提取部分的参数,使其算法模型更加轻量化。
2)在特征融合部分,通过增加特征融合层的方式提高算法模型的感受野层次结构,使算法模型在多尺度特征融合过程中获得更多的有效信息,对于目标物体的检测更加准确。
3)采用K-means聚类算法对Anchor尺度重选取与改进边界框回归损失函数可以进一步提升算法模型的检测精度与训练效率。
虽然实验结果证明了本文方法的有效性,可以准确并快速地检测出不同光照场景下的多姿态绝缘子销钉,为变电站绝缘子更换机器人在单片绝缘子更换中提供有效地视觉信息,但其仍然有很大的改进空间。采用轻量级网络结构是轻量化算法模型的有效方式之一,但是如何保证检在测精度不变甚至提升的条件下进一步降低计算量和参数量需要进一步研究。
-
图 1 YOLOv5模型结构
下载:
全尺寸图片
图 2 YOLOv5-nS结构
下载:
全尺寸图片
图 3 nS Block结构
下载:
全尺寸图片
图 4 深度可分离卷积原理
下载:
全尺寸图片
图 5 光照不充足场景下绝缘子销钉检测结果
下载:
全尺寸图片
图 6 强光场景下绝缘子销钉检测结果
下载:
全尺寸图片
表 1 先验框尺度
感受野 大 中 小 先验框 24×19 19×15 11×9 22×21 18×16 14×13 25×24 20×18 18×13 表 2 nSNet与ShuffleNetV2性能对比
主干网络 参数 mAP@0.5 mAP@0.5:0.95 nSNet 214272 0.973 0.614 ShufflNetV2 108204 0.908 0.515 表 3 nSNet模块与卷积核为3×3与5×5性能对比
卷积核尺寸 参数 mAP@0.5 mAP@0.5:0.95 3×3 205440 0.959 0.601 5×5 214272 0.973 0.614 表 4 YOLOv5-nS的消融实验
模型 模型大小/MB mAP@0.5:0.95 YOLOv5s 14.4 0.628 nSNet 1.7 0.579 nSNet+特征融合层 1.8 0.614 nSNet+特征融合层+K-means 1.8 0.615 nSNet+特征融合层+K-means+Alpha-IoU 1.8 0.617 表 5 YOLOv5-nS与其他算法对比
算法模型 mAP@.5 mAP@0.5:0.95 平均测试
时间/s模型
大小/MBFaster-RCNN 0.692 0.354 0.196 628 YOLOv3-SPP 0.798 0.467 0.059 322 SSD 0.856 0.55 0.034 100 YOLOv5-nS 0.959 0.617 0.018 1.8 表 6 YOLOv5-nS与YOLOv5s性能比对
算法 参数 模型
大小/MBmAP@0.5:0.95 帧率/(f/s) YOLOv5s 7063542 14.4 0.628 48 YOLOv5-nS 725046 1.8 0.617 55 -
[1] 关志成, 刘瑛岩, 周远翔. 绝缘子及输变电设备外绝缘[M]. 北京: 清华大学出版社, 2006. [2] 蒋兴良, 易辉. 输电线路覆冰及防护[M]. 北京: 中国电力出版社, 2002. [3] 胡毅, 刘凯, 彭勇, 等. 带电作业关键技术研究进展与趋势[J]. 高电压技术, 2014, 40(7): 1921−1931. doi: 10.13336/j.1003-6520.hve.2014.07.001 [4] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]//European Conference on Computer Vision. Cham: Springer, 2016: 21-37. [5] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 779-788. [6] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6517-6525. [7] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020−04−23)[2022−08−03]. https://arxiv.org/abs/2004.10934. [8] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: ACM, 2014: 580-587. [9] GIRSHICK R. Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV). Piscataway: IEEE, 2016: 1440-1448. [10] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031 [11] 李瑞生, 张彦龙, 翟登辉, 等. 基于改进SSD的输电线路销钉缺陷检测[J]. 高电压技术, 2021, 47(11): 3795−3802. doi: 10.13336/j.1003-6520.hve.20201650 [12] 郝帅, 马瑞泽, 赵新生, 等. 基于卷积块注意模型的YOLOv3输电线路故障检测方法[J]. 电网技术, 2021, 45(8): 2979−2987. doi: 10.13335/j.1000-3673.pst.2020.0942 [13] 徐文静, 高云天, 陈晨, 等. 基于YOLOv5的绝缘子图像自动标注[J]. 科学技术创新, 2021(14): 15−17. doi: 10.3969/j.issn.1673-1328.2021.14.008 [14] MA Ningning, ZHANG Xiangyu, ZHENG Haitao, et al. ShuffleNet V2: practical guidelines for efficient CNN architecture design[C]//European Conference on Computer Vision. Cham: Springer, 2018: 122-138. [15] HE Jiabo, ERFANI S, MA Xingjun,. Alpha-IoU: A family of power intersection over union losses for bounding box regression[J]. Advances in neural information processing systems, 2021, 34: 20230−20242. [16] WANG C Y, MARK LIAO H Y, WU Y H, et al. CSPNet: a new backbone that can enhance learning capability of CNN[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2020: 1571-1580. [17] 吴睿, 毕晓君. 基于改进YOLOv5算法的珊瑚礁底栖生物识别方法[J]. 哈尔滨工程大学学报, 2022, 43(4): 580−586. [18] CUI Cheng, GAO Tingquan, WEI Shengyu, et al. PP-LCNet: a lightweight CPU convolutional neural network[EB/OL]. (2021−09−17)[2022−08−05]. https://arxiv.org/abs/2109.15099. [19] HAN Kai, WANG Yunhe, TIAN Qi, et al. GhostNet: more features from cheap operations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1577-1586. [20] SANDLER M, HOWARD A, ZHU Menglong, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4510-4520.


















