
Research on the disassembling of semi-automatic labeling test paper layout using lightweight models
-
摘要: 为了提升数据标注速率,本文采用了一种应用轻量模型、后处理实施半自动化标注的方法,实现试卷版面拆解的快速开发与应用。使用LCNet改进PicoDet网络的轻量预训练模型,对已经标注的小样本训练基础模型修改网络输出,基础模型预测剩余样本的数据转换为标注格式,经过人工校验以后的全样本标注数据使用更大规模主干网络的PicoDet网络训练最终模型。经过实验验证,本文提出的半自动标注的方法与人工标注相比,数据标注速率提升195%,标注所花费时间周期缩短86.47%,项目开发周期得到大幅度缩短,经过版面拆解处理的文档图像调用百度OCR接口,可快速实现文档图像到文档的转换。Abstract: This paper adopts a method of using a lightweight model and post-processing to implement semi-automatic labeling to realize the rapid development and application of test paper layout disassembly. Using LCNet to improve the lightweight pre-training model of the PicoDet network to train the basic model for small samples that have been labeled, modify the network output, and convert the data of the remaining samples predicted by the basic model into a labeled format. After manual verification, the full-sample labeled data is trained by a large-scale backbone network—PicoDet, deriving the final model. The semi-automatic labeling method proposed in this paper is compared with the manual labeling method, and an experiment is carried out to verify it. It shows that the data labeling rate is increased by 195%, the time period spent on labeling is shortened by 86.47%, and the project development cycle is greatly shortened, the document image processed after layout disassembly calls the Baidu OCR interface, which can quickly realize the conversion from picture format to text format of a document.
-
教育资源以文档图像的格式广泛存储于互联网,当教师运用文档图像进行组卷、整理错题题库等试题录入场景时,利用光学字符识别(optical char- acter recognition, OCR)系统输出文本,可减少教师手工录入文本信息的时间成本。然而实际应用中,OCR系统对多栏试卷按照文字区域从左到右进行识别,并不会对栏目进行划分,而人类阅读习惯是按照同页的栏目内容优先原则,从左到右再自上而下的阅读[1],版面跨栏、图表等复杂内容对文档图像OCR造成严重的干扰,试卷文档图像的OCR输出内容无法转换为人类阅读习惯的文档。正确地标识试卷版面的位置和图表而提出的版面拆解技术是文档图像识别系统中必不可少的关键步骤。
在版面拆解相关研究中,郭镭斌[2]提出了一种使用Faster R-CNN算法识别图像文档中文档组件(图表),Y轴分隔线用于分割同一张图片上不同的排版栏区域,该研究方法对双栏试卷文档图像能取得较好的效果,但无法应用于三栏或者多栏试卷文档图像;Baralas等[3]提出首先训练1个人工神经网络(artificial neural networks, ANN)对文档图像的文字区域和非文字区域进行二分类,再设计空格分析算法区分文档图像版面区域边界,通过文字块的后处理完成版面的分割,该研究方法对表格区域识别效果较差。不同学科的试卷之间的版面差异较大,文档图像特征不一。上述算法仅仅能够定位,针对某一学科训练模型所需要的标注数据量大,因而需要投入的人力和物力是一笔不小的开销。
在小样本数据相关研究中,刘春磊等[4]提出图卷积神经网络、数据增强等方法,通过公开数据集试验,对比分析不同方法的优缺点;Dhaene等[5]提出一种基于重采样数据,利用统计学对小样本数据进行自助法(bootstrap)和去一法(jackknife)结合采样。已有的深度学习试卷版面拆解研究中,由于文档图像OCR干扰组件的随机分布性,模型的训练成果都是基于大量标注数据的基础上,缺少对小样本数据有效利用,利用高效的轻量网络检测不均衡数据目标,减弱小样本数据偏差。
本文提出使用PP-PicoDet-LCNet轻量模型有效利用小样本数据实施半自动化标注,有效减少资源浪费、缩短项目迭代周期,是一项非常有意义的研究。
1. 算法设计
1.1 无锚框目标检测算法
基于锚框(anchor-base)的目标检测算法中,以Faster R-CNN为代表的二阶段目标检测算法对特征图中每一个点生成多个比例不一的锚框,经过筛选的目标检测框与标记真实框编码,训练目标检测模型,解码得到预测框,算法在预测速度上存在明显的缺陷[6]。以YOLO v3-v4系列为代表的一阶段目标检测算法[7]将特征图分解为若干网格,通过聚类的方法得到预测锚框,与真实框比较,编码得到训练目标。主流YOLO系列算法在试卷版面检测场景应用时存在:一是试卷中图表的大小无法度量,过度调参导致模型预测负样本多;二是市场教辅资料版面更新周期短、速率快,需要对模型周期性调参,并且根据锚框的超参数的重新训练,模型维护成本高[8];三是训练过程中锚框相关的计算复杂度高导致出现模型训练效率低和预测时间长等。YOLOX 在YOLO v3-v4算法的基础上优化,通过聚类分析,确定最优锚框,实现了无锚框检测,但是开源的YOLOX模型存在应用场景非泛化、算法更新迭代周期长的情况。
本文中使用基于无锚框目标检测PP-PicoDet算法,算法框架基于PaddlePaddlede开源的深度学习平台,PicoDet算法的结构如图1所示,输入的图片经过主干网络处理,输出特征图到网络颈部,网络颈部输出特征图,网络输出层捕捉特征图特征,预测分类和锚框。
 图 1 PicoDet算法结构
图 1 PicoDet算法结构 下载:
全尺寸图片
下载:
全尺寸图片
1.2 主干网络优化
PP-PicoDet主干网络的优化:ESNet是基于Sh-uffleNetV2参考MobileNetV3改进的轻量网络,PP-PicoDet的主干网络使用LCNet替换了ESNet,其主干网络结构图LCNet-1.0x如图2所示,假设输入的图片像素为640 pix×640 pix,卷积层采用计算速度更快的h-swish激活函数替换swich函数,经过步长为2的3×3普通卷积。可分离卷积模块由逐通道卷积和点卷积构成[9]。LCNet在最后2个可分离卷积尾部增添压缩激励(squeeze excitation,SE)模块解决了小样本数据训练中存在的过拟合问题, SE模块由1个全局平均池化层和2个全连接层组成,主要应用于图像类型识别,在GoogLeNet之后,全局平均池化(global average pooling, GAP)直接到网络输出层,但在轻量网络中,直接网络输出层会导致GAP提取的特征没有经过融合和加工[10],GAP后接更大的1×1的FC层,融合GAP特征,网络推理速度不受到影响的同时大幅度提升了网络的精度,网络尾部的SE模块实现了速度与精度的平衡。计算量更小的h-sigmoid替换sigmoid函数增添在卷积网络尾部充当激活函数,提升网络的非线性映射能力。前6个可分离卷积模块使用3×3可分离卷积、3×3逐通道卷积、1×1点卷积,后7个分离卷积模块使用5×5可分离卷积网络层、5×5逐通道卷积、1×1点卷积,网络末端使用5×5卷积核替换3×3卷积核获得更低的延迟和更高的精度。
 图 2 LCNet-1.0X结构下载:
全尺寸图片
图 2 LCNet-1.0X结构下载:
全尺寸图片
主干网络将特征图F3~F5输入到网络颈部进行特征融合。表1中不同规模的LCNet网络模型对应的F3~F5的输出通道数[11],实际应用中可根据移动端深度学习能力以及任务需求设计算法,选择合适规模的网络模型。
表 1 不同规模LCNet对应F3~F5输出通道数模型 F3 F4 F5 LCNet-0.35X 48 88 176 LCNet-0.75X 96 192 384 LCNet-1.0X 128 256 512 LCNet-2.0X 256 512 1024 1.3 网络颈部优化
路径聚合网络(path aggregation network, PAN)在特征金字塔网络(feature pyramid network, FPN)后增加1个自底向上的金字塔,将底层的强定位特征传递到顶层。网络颈部使用的LCPAN改良了轻量模型的网络颈部常使用的CSPPAN网络结构,使用更大的1×1卷积层对输入到网络颈部F3~F5的通道数进行压缩,对每一层输入的宽度进行统一的同时,顶部添加特征地图比例用于检测更多的图像特征信息[7]。1×1卷积实现了跨通道的信息融合,其他所使用的卷积为5×5深度可分离卷积,以更大的感受野、更少的参数提升了网络的精度[4]。
2. 试验与验证
2.1 试验设置
2.1.1 试验数据
试验数据采集网络的各省市中学语文、历史、政治3门学科期中、期末、中考考试试卷资源,保存为图像像素为5954 pix×4210 pix的JPG格式文档图像,试验数据为互联网采集自制数据集,试验中总共采集图片3340张,标签和数据分布情况如表2。试卷栏目大多数是两栏,少部分存在单栏、三栏的情况,跨栏目(Column)信息、图像(Image)和表格(Table)对OCR输出干扰大,图像和表格在栏目内,且随机分布,设置“Column”、“Image”、“Table”3种标签。
表 2 试验数据集数据集参数 小样本数据 全样本数据 测试集 标签“Column” 834 6625 408 标签“Image” 961 6912 154 标签“Table” 172 1283 96 标签总数 1976 14820 678 图片总数量/张 420 3340 210 训练数据集划分为小样本标注数据和全样本标注数据两类,全样本数据为3340张图片,小样本数据为全样本数据中随机抽选,标注格式为COCO2017,额外补充210张测试集检测全样本训练模型性能。
2.1.2 对比算法
试卷图片尺寸较大的情况下,预训练模型的输入图片选择尺寸过小会出现性能滑坡现象,因此本文选择输入图片尺寸较大的预训练模型设计算法,并进行比较,筛选最适合应用在试卷版面拆解检测场景的模型。 1)PicoDet-Xs-416-LCNet算法:使用超轻量主干网络PP-LCNet-0.35x,网络颈部使用LCPAN,网络头部使用PicoHeadV2,输入图像的尺寸为416×416。
2)PicoDet-S-416-LCNet算法:使用轻量主干网络PP-LCNet-0.75x,网络颈部使用LCPAN,网络头部使用PicoHeadV2,输入图像的尺寸为416×416。
3)PicoDet-L-640-LCNet算法:主干网络使用更大规格的PP-LCNet-2.0x,网络颈部使用LCPAN,网络头部使用PicoHeadV2,输入图像的尺寸为640×640。
4)PicoDet-S-416-ESNet算法:主干网络使用ESNet,网络颈部使用CSPPAN,网络头部使用Pico- HeadV1,输入图像的尺寸为416×416。
5)YOLOX-S-300E算法:基干网络使用CSPD-arkNet,网络颈部使用YOLOCSPPAN,网络头部使用YOLOXHEAD,输入图片的尺寸为640×640。
2.1.3 试验环境
试验训练环境:32 GB内存;CPU:4 cores Intel (R) Xeon(R) Gold 6271C @ 2.60 GHz;GPU:NVIDI- A Tesla V100 SXM2 32 GB。
模型部署环境:Windows10;16 GB内存;CPU:Intel(R) Core (TM) i7-10875H CPU @ 2.30 GHz;GPU:N-VIDIA GeForce RTX 2060 14 GB。
编码环境:Python V3.7.4;框架版本为Paddle- Paddle V2.3.2。
2.1.4 试验评价指标
目标检测中模型预测框的面积
$ {S_i} $ 和真实标注框的面积$ {S_u} $ ,2个矩形框的交集面积与并集面积的比值(intersection over union , IoU)为$$ {\text{IoU}} = \frac{{{S_i} \cap {S_u}}}{{{S_i} \cup {S_u}}} $$ 目标检测任务中,常将IoU≥0.5得分的预测框视为正确检测区域。真阳性(true positive, TP):一真实标注框只参与1次计算的情况下,模型预测框IoU得分大于等于设定阈值的框数量;假阳性(false positive, FP):模型预测框得分IoU小于设定阈值的框数量,或者真实框已经参与计算的情况下,模型预测框的多余检测数量;假阴性(false negative, FN):模型预测框没有与之匹配的真实框数量[12]。精确度(Precision)和召回率(Recall)的计算公式为
$$ {\text{Precision = }}\frac{{{\text{TP}}}}{{{\text{(TP + FP)}}}} $$ $$ {\text{Recall = }}\frac{{{\text{TP}}}}{{{\text{(TP + FN)}}}} $$ 所有模型预测框的数量为
$ {\text{TP + FP}} $ ,所有真实标注框的数量为$ {\text{TP + FN}} $ 。Precision-Recall(P-R)曲线指Recall值放X轴,Precision值放Y轴上的1条衡量模型性能的曲线,在P-R曲线基础上提出每一个X轴上Recall值对应的Y轴线上的Precision值的平均值称为AP[13],作为衡量模型与模型之间在特定类别检测性能比较的评价指标。给定某一Recall值为r,插值$ {P_{{\text{interp}}}}{r_i} $ 为当前Recall值与下一个Recall值之间最大的Precision值[14],达到减少P-R曲线抖动影响、平滑P-R曲线的效果。特定类别AP计算公式为$$ {\text{AP = }}\sum\limits_{{{i = 0}}}^{{{n - 1}}} {{\text{(}}{r_{{{i + 1}}}} - {r_{{i}}}{\text{)}}{P_{{\text{interp}}}}{\text{(}}{r_{{{i + 1}}}}{\text{)}}} $$ 式中:
$ {r_{\text{1}}} $ ,$ {r_2} $ ,…,$ {r_{\text{n}}} $ 是按照升序排列的Precision插值段第1个插值处对应的recall值[5],对于k种类别的目标检测任务中,均值平均精度(mean average precision,mAP)的计算公式为$$ {\text{mAP = }}\dfrac{{\displaystyle\sum\limits_{{{i = 0}}}^{{k}} {{\text{A}}{{\text{P}}_{{i}}}} }}{{{K}}} $$ 2.2 试验过程
试验数据的标注过程如下:
1)随机抽取全样本的中440张图片,使用开源软件Labelme V4.6.0,按照实验数据中设置的“Column”、“Image”、“Table”3种标签对OCR版面栏、图像、表格进行标注,标注方式如图3,生成JSON格式Labelme标注文件,产生小样本数据集。
 图 3 labelme标注图下载:
全尺寸图片
图 3 labelme标注图下载:
全尺寸图片
2)PaddleDetection中开源脚本将Labelme标注的JSON文件转换为COCO2017训练格式,数据集按照训练集∶验证集=8∶2进行划分、训练。
3)选择最优模型,自主研发的脚本将模型的预测结果保存为Labelme标注格式的JSON文件,根据预测结果人工使用Labelme软件修改标注,完成剩余图片标注,得到全样本数据集。
4)全样本数据再次重复步骤2),测试集上测试最终模型性能,后处理后外接百度OCR识别接口,实现图像到文档地快速转换。
模型的训练过程中,每5个迭代轮次(epoch)保存一次模型进行验证,小样本训练中训练55个epoch,对比5种算法选择最优算法,全样本训练中训练选择小样本中最优的2种算法,训练55个epoch,对比选择最优性能模型。
2.3 试验结果
2.3.1 小样本学习结果
本文设计算法的小样本学习性能表现如图4和表3所示 。图4(a)在训练40 个epoch后,PicoDet-S-416-ESNet开始收敛,PicoDet主干网络LCNet替换ESNet,训练速度提升150%,最终模型mAP提升3.9%。
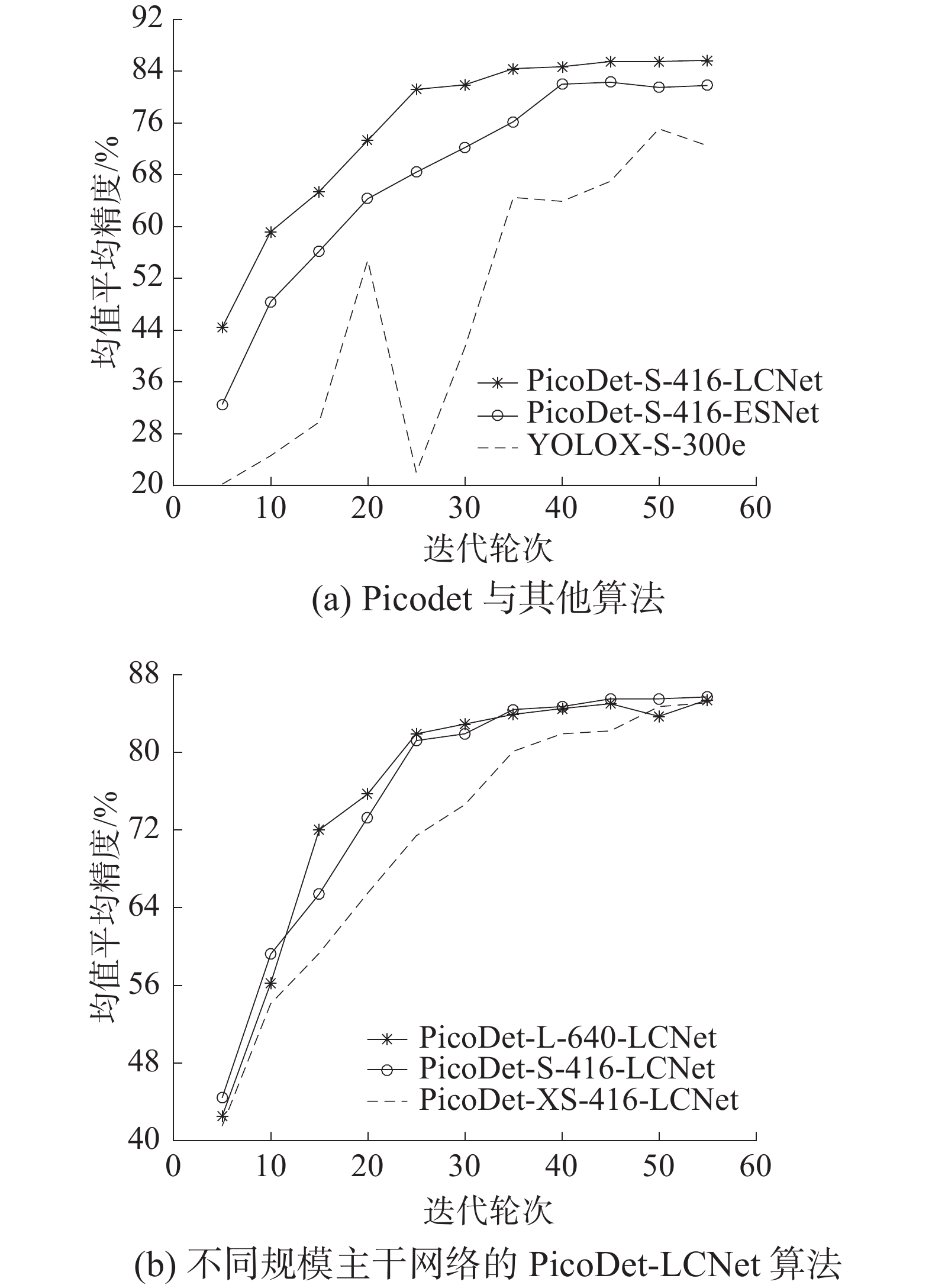 图 4 IoU=0.5各模型小样本验证集mAP变化下载:
全尺寸图片
表 3 各模型小样本学习表现对比
图 4 IoU=0.5各模型小样本验证集mAP变化下载:
全尺寸图片
表 3 各模型小样本学习表现对比算法 epoch=54训练时间/min 验证集最高 $ {\text{mA}}{{\text{P}}_{{\text{IoU}}}}_{ = 0.5} $ PicoDet-Xs-416-LCNet 129 0.851(epoch=54) PicoDet-S-416-LCNet 132 0.857(epoch=54) PicoDet-L-640-LCNet 160 0.854(epoch=54) PicoDet-S-416-ESNet 198 0.823(epoch=54) YOLOX-S-300E 227 0.75(epoch=54) YOLOX在目标检测领域中取得了不错的成绩,但在小样本试卷版面拆解的目标检测任务中,训练速度滞后PicoDet-S-416-LCNet算法41.85%,经过55轮训练,YOLOX模型的最高
$ {\text{mA}}{{\text{P}}_{{\text{IoU}}}}_{ = 0.5} $ 也与PicoDet-S-416-LCNet模型相差0.106。图4(b)中对比PicoDet算法主干网络中3种不同规模LCNet,当IoU=0.5时mAP的性能,PicoDet-S-416-LCNet以最短的时间达到了$ {\text{mA}}{{\text{P}}_{{\text{IoU}}}}_{ = 0.5} $ =0.85的出色表现,且最终模型的$ {\text{mA}}{{\text{P}}_{{\text{IoU}}}}_{ = 0.5} $ =0.857也达到小样本学习最高水平。超轻量主干网络PP-LCNet-0.35x比PP-LCNet-0.75x和PP-LCNet-2.0x收敛慢,且训练耗费时长与PP-LCNet-0.75x相近。PP-LCNet-2.0x收敛速度较快,但较大的网络规模导致训练速度慢于PP-LCNet-0.35x和PP-LCNet-0.75x。各模型综合性能评估,选择PicoDet-S-416-LCNet算法训练的模型对剩余样本数据进行预测。
自主研发脚本转换预测结果,产生2930张文档图片的预测版本Labelme格式标注,人工矫正预测版本的标注,实现半自动标注,得到全样本的Labelme标注格式数据集。半自动标注和全人工手动标注效率对比如表4。根据平均标注效率可知,半自动标注效率比人工手动标注效率提升195%,标注所花费时间周期缩短86.47%。
表 4 半自动标注与人工手动标注效率对比标注方式 标注图片数量/张 耗时/min 平均标注速率/(张·min−1) 半自动标注 2930 562 5.214 人工手动标注 420 238 1.765 2.3.2 全样本学习结果
本文全样本学习中使用PicoDet-L-640-LCNet和PicoDet-S-416-LCNet算法学习的性能表现如图5、表5。PicoDet-L-640-LCNet在训练轮数30~40收敛,PicoDet-S-416-LCNet在训练45~55收敛,IoU=0.5时PicoDet-L-640-LCNet的最高mAP比PicoDet-S-4-16-LCNet高0.012,IoU=0.75时,PicoDet-L-640-LCNet的mAP与PicoDet-S-416-LCNet差距更为明显。模型部署在本地,进一步在测试集中比较模型的性能。
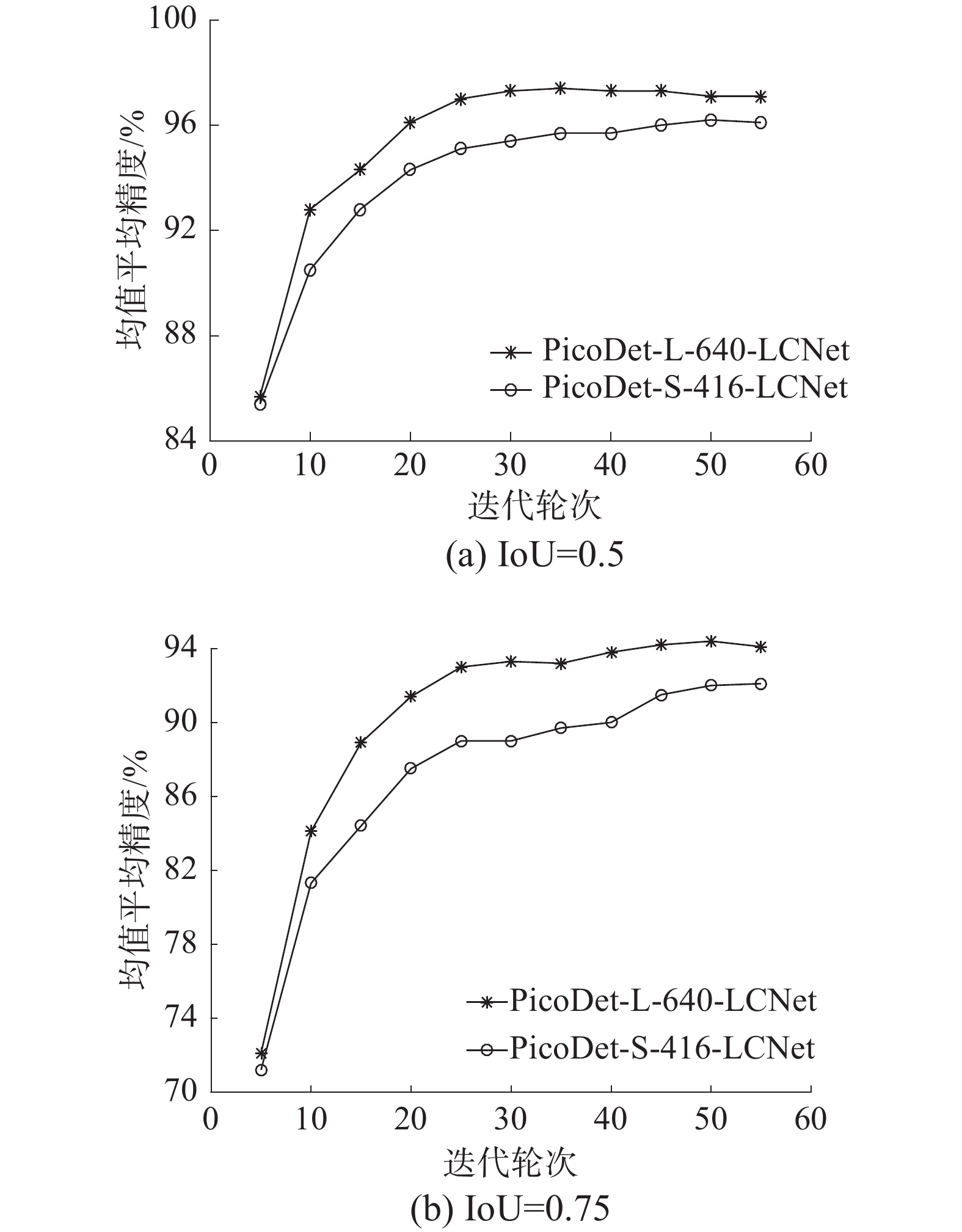 图 5 各模型全样本mAP变化下载:
全尺寸图片
表 5 各模型全样本学习表现对比
图 5 各模型全样本mAP变化下载:
全尺寸图片
表 5 各模型全样本学习表现对比算法 epoch=54
训练时间/min验证集最高
$ {\text{m}\text{AP}}_{\text{IoU=0.5}} $PicoDet-L-640-LCNet 1352 0.974(epoch=34) PicoDet-S-416- LCNet 1158 0.962(epoch=49) 部署在本地端的模型选择
$ {\text{m}\text{AP}}_{\text{IoU=0.5}} $ 得分最高的模型。模型的在额外补充测试集中CPU和GPU上推理时间、漏检、多检性能表现如表6,其中PicoDet-S-416-LCNet漏检的标签全部为“Table”,因为模型结构简单,训练样本中“Table”数据量不均衡,相比其他标签样本较少,导致模型出现欠拟合的情况,同时PicoDet-L-640-LCNet在IoU=0.5时,出现模型多检偏多的情况,在后续的研究中需要继续探查原因。综合模型验证集和测试集表现,选择IoU=0.65的PicoDet-L-640-LCNet模型,模型预测“Column”、“Image”和“Table”信息并锚框,输出信息中每个框包含上(top)、左(left)、高(height)、宽(width)4个位置信息,将试卷版面中的Column区域切割,定位切割图中的Image和Table区域信息并隐藏后,按照从左到右再自上而下的顺序调用百度OCR处理,经过处理后的图片返回的识别结果包含图片中从上到下的每一条文本内容(text)和所在位置的top、left、height、width共4个位置信息[15],根据OCR识别结果的位置信息和模型预测结果位置信息,将Text、Image和Table依次输入到文档中,实现文档图像到文档的转换。表 6 各模型全样本学习表现对比算法名称 GPU推理时间/ms CPU推理时间/ms 目标得分阈值0.5 目标得分阈值0.65 漏检标签数 多检标签数 漏检标签数 多检标签数 Picodet-L-640-LCNet 1113 1171 0 12 0 2 Picodet-S-416-LCNet 221.6 210 5 6 9 2 3. 结束语
本文深入研究了人工智能目标检测领域运用于试卷版面拆解的方法,提出了一种基于PicoDet-LCNet轻量预训练模型对小样本数据集训练实现半自动标注的方法,本研究具有以下优势:
1)高效开发:轻量模型能够有效缩短训练时间,自主研发的脚本将预测输出结果自动转换为标注格式,人工矫正的半自动标注方法,数据标注效率是人工手动标注的2.95倍,有效地将试验中全样本数据标注时间从所需要5912 min缩短至800 min,有效地节省了人力资源的消耗,项目开发周期得到大幅度的缩短。
2)PicoDet-LCNet应对小样本数据不均衡学习性能优越:文中对比的PicoDet-LCNet不同网络规格的LCNet应用于试卷版面拆解的各项性能指标,对比性能选择最优模型。相同的网络规格下的PicoDet-LCNet比PicoDet-ESNet在试卷版面拆解小样本模型的mAP提升0.034,同时训练时间缩短33.3%,YOLO相关研究中,YOLOX基于YOLO v3-v5改进并在目标检测取得更优的性能,文中PicoDet-LCNet比YOLOX在试卷版面拆解小样本学习表现中模型mAP提升0.106,训练时间缩短41.85%。
3)研究方法推广性良好:最终模型性能优异,在测试集上漏检率为0%、多检率为0.29%,同时模型广泛适用科学、地理等文本中没有复杂公式学科的试卷或教辅文档图像,可部署在CPU服务器,移动端可实现文档图像到文档的快速转换。
后续研究中,将针对文本信息中含有复杂公式的数学、物理、化学等学科设置公式检测模块,引入多模型集成学习,同时将进一步研究图像特征的无监督目标检测,实现更为高效的全自动标注。
-
图 1 PicoDet算法结构
下载:
全尺寸图片
图 2 LCNet-1.0X结构
下载:
全尺寸图片
图 3 labelme标注图
下载:
全尺寸图片
图 4 IoU=0.5各模型小样本验证集mAP变化
下载:
全尺寸图片
图 5 各模型全样本mAP变化
下载:
全尺寸图片
表 1 不同规模LCNet对应F3~F5输出通道数
模型 F3 F4 F5 LCNet-0.35X 48 88 176 LCNet-0.75X 96 192 384 LCNet-1.0X 128 256 512 LCNet-2.0X 256 512 1024 表 2 试验数据集
数据集参数 小样本数据 全样本数据 测试集 标签“Column” 834 6625 408 标签“Image” 961 6912 154 标签“Table” 172 1283 96 标签总数 1976 14820 678 图片总数量/张 420 3340 210 表 3 各模型小样本学习表现对比
算法 epoch=54训练时间/min 验证集最高 $ {\text{mA}}{{\text{P}}_{{\text{IoU}}}}_{ = 0.5} $ PicoDet-Xs-416-LCNet 129 0.851(epoch=54) PicoDet-S-416-LCNet 132 0.857(epoch=54) PicoDet-L-640-LCNet 160 0.854(epoch=54) PicoDet-S-416-ESNet 198 0.823(epoch=54) YOLOX-S-300E 227 0.75(epoch=54) 表 4 半自动标注与人工手动标注效率对比
标注方式 标注图片数量/张 耗时/min 平均标注速率/(张·min−1) 半自动标注 2930 562 5.214 人工手动标注 420 238 1.765 表 5 各模型全样本学习表现对比
算法 epoch=54
训练时间/min验证集最高
$ {\text{m}\text{AP}}_{\text{IoU=0.5}} $PicoDet-L-640-LCNet 1352 0.974(epoch=34) PicoDet-S-416- LCNet 1158 0.962(epoch=49) 表 6 各模型全样本学习表现对比
算法名称 GPU推理时间/ms CPU推理时间/ms 目标得分阈值0.5 目标得分阈值0.65 漏检标签数 多检标签数 漏检标签数 多检标签数 Picodet-L-640-LCNet 1113 1171 0 12 0 2 Picodet-S-416-LCNet 221.6 210 5 6 9 2 -
[1] 吴旭东, 罗荣良, 史庭蔚, 等. 基于百度人工智能的拍照切题系统设计[J]. 电脑知识与技术, 2021, 17(3): 199−200, 203. doi: 10.14004/j.cnki.ckt.2021.0181 [2] 郭镭斌. 数学试卷版面切割算法的研究及实现: 基于深度学习的文档组件提取方法[D]. 成都: 电子科技大学, 2020. [3] BARALAS P, ADAM S, CHATELAIN C, et al. A typed and handwritten text block segmentation system for heterogeneous and complex documents [C]//2014 11th, IAPR International Workshop on Document Analysis Systems. Tours: IEEE, 2014: 46-50. [4] 刘春磊, 陈天恩, 王聪, 等. 小样本目标检测研究综述[EB/OL]. (2022-8-12) [2022-09-15]. http://kns.cnki.net/kcms/detail/11.5602.tp.20220811.1539.006.html. [5] DHAENE S, ROSSEEL Y. Resampling based bias correction for small sample SEM[J]. Structural equation modeling:a multidisciplinary journal, 2022, 29(5): 1−17. [6] 陈永祺, 顾茜, 林郁. 基于PP-PicoDet的半自动标注烟丝异物检测研究[EB/OL]. (2022-8-24) [2022-09-15]. http://kns.cnki.net/kcms/detail/11.2985.TS.20220824.1458.008.html. [7] WAGDY M, AMIN K, IBRAHIM M. Detection and correction of multi-warping document image[J]. Interna- tional journal of image and graphics, 2022, 22(4): 2250034. doi: 10.1142/S0219467822500346 [8] 郑云亮. 基于改进YOLOv5网络的侧扫声纳图像目标检测方法[J]. 海洋测绘, 2022, 42(4): 18−21, 26. doi: 10.3969/j.issn.1671-3044.2022.04.005 [9] 吴兴蛟. 基于域内与域间知识的文档布局分析算法研究: 基于显式边缘嵌入网络的文档图像布局分析[D]. 上海: 华东师范大学, 2022. [10] QIN Zheng, LI Zeming, ZHANG Zhaoning, et al. ThunderNet: towards real-time generic object detection on mobile devices[C]//Proceedings of the IEEE/CVF International Conference on Computer VIsion. Seoul: ICCV, 2019: 6718-6727. [11] LEE S H, CHEN H C. U-SSD: improved SSD based on UNet architecture for end-to-end table detection in document Images[J]. Applied sciences, 2021, 11(23): 11446. doi: 10.3390/app112311446 [12] DONG Xuanyi, ZHENG Liang, MA Fan, et al. Few-example object detection with model communication[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 41(7): 1641−1654. [13] 崔磊, 徐毅恒, 吕腾超, 等. 文档智能: 数据集、模型和应用[J]. 中文信息学报, 2022, 36(6): 1−19. doi: 10.3969/j.issn.1003-0077.2022.06.001 [14] 李柯泉, 陈燕, 刘佳晨, 等. 基于深度学习的目标检测算法综述[J]. 计算机工程, 2022, 48(7): 1−12. [15] ZHAO Yu. Image retrieval model analysis of digital library based on texture characteristics[J]. Advances in mathematical physics, 2021(3): 1−10.

















