
Design of lightweight pig detection network based on YOLOv5
-
摘要: 为了现代养殖业能够实现无人化、智能化,本文以目标检测网络YOLOv5为基础,设计了一个更轻量级的猪只检测神经网络。新的网络以YOLOv5为基础,舍弃了原主干网络中Focus结合CSP的结构,采用MobileNetV3中的深度可分离卷积的倒残差结构。这种结构的卷积操作计算量更少,进一步降低了运算成本,同时加入通道注意力机制来衡量特征图的不同通道所占的重要性,以此增强目标特征。经过用自制数据集在此网络和YOLOv5及其他改进方法上分别进行实验对比,证实了此网络在精度几乎不下降的前提下检测速度有了较好提升。同时相比于其他常见目标检测网络,该网络的模型效果依然表现良好,验证了本文改进方法的有效性。Abstract: In order to realize the unmanned and intelligent modern breeding industry, this paper designs a more lightweight pig detection neural network based on the target detection network YOLOv5. Based on YOLOv5, the new network discards the structure of Focus combined with CSP in the original backbone network and adopts the inverse residual structure of deep separable convolution in MobileNetV3. The convolution operation of this structure has less computation, which further reduces the operation cost. At the same time, the channel attention mechanism is added to measure the importance of different channels of the feature map, so as to enhance the target feature. Through experimental comparisons with YOLOv5 and other improved methods respectively with self-made data sets, it is confirmed that the detection speed of this network has been better improved on the premise of almost no decrease in accuracy. At the same time, compared with other common target detection networks, the model effect of this network is still good, which verifies effectiveness of the improved method in this paper.
-
我国是一个世界养猪大国,养猪业已成为我国农业及农村经济中十分重要的支柱产业之一。规模化、智能化养殖已成为未来的发展趋势,规模化养殖企业的自动化生产体系及标准化管理流程,有利于减少人工成本,提高劳动生产率和精细化程度,进而提高产品质量。随着深度学习技术的不断发展[1],智能养猪的技术日益完善,智能养猪将成为大势所趋。通道猪只盘点计数、在栏计数、个体识别等是大规模生猪养殖场需要频繁执行的重要任务。要在完成以上任务时能够达到检测实时性的效果,就要对目标检测网络的检测速度提出较高的要求。因此,对目标检测网络的结构进行优化来提高网络检测速度十分重要[2]。
深度学习中常用的目标检测算法一般分为one-stage和two-stage两类。One-stage是单阶段算法[3],输入图片、输出bounding box和分类标签由1个网络完成,代表算法有SSD[4]、YOLO系列[5-8]等;Two-stage是双阶段算法[9],输入图片后先生成建议区域(region proposal),然后再送入分类器分类,2个任务由不同的网络完成,代表算法有Faster R-CNN[10]、Mask R-CNN[11]等。如今随着单阶段算法的不断优化[12],单阶段网络在速度快的前提下有了与双阶段算法媲美的精度。由于经典算法YOLOv1检测性能较低,YOLOv2提出新网络框架Darknet-19并提出联合训练方法;之后YOLOv3在YOLOv2的基础上做了一些小改进,使用新网络Darknet-53提取特征;之后YOLOv4又在YOLOv3的基础上采取了多方面的改进包括网络结构CSPDarknet53、Mosaic数据增强、Mish激活函数等;最终YOLOv5在YOLOv4的基础上对速度进行优化,已经达到精度与速度兼得的效果。SqueezeNet[13]在2016年被提出专门用来压缩参数量以便于嵌入式部署[14]。SqueezeNet将3×3卷积换成1×1卷积,通过更深的深度置换更少的参数量,虽然减少了参数但失去了网络并行能力,测试时间反而会更长。之后Face++提出了ShuffleNetv1[15],主要思路是使用Group convolution和Channel shuffle改进ResNet,通过分组卷积实现计算量的降低,是ResNet的改进版。同年Google提出了第1版MobileNet,MobileNetv1使用深度可分离卷积代替标准卷积,并使用宽度因子减少了参数量。次年Face++提出ShuffleNetv2[16]使用直接指标(运算速度)代替间接评价指标(floating-point operations per second, FLOPS),并在ARM等移动端进行评估,但并没有提出如何实现提高准确率、推断延迟等评价指标。Google在MobileNetv1的基础上进行改进提出了MobileNetv2[17],在深度可分离卷积的基础之上增加了Skip Connection使前向传播时提供特征复用。同时采用Inverted Residual Block结构减少ReLU对特征层的破坏,取得了较好结果。以上ShuffleNet、MoblieNet都是人工手动设计网络结构,这样根据人的经验设计网络是一个漫长而繁琐的试错过程且不一定获得最优解。因此,Google使用自动网络架构搜索(neural architecture search,NAS)设计出性能更好的MobileNetv3[18]。MnasNet[19]是Google提出的使用强化学习设计移动端模型的自动化神经架构搜索方法。MobileNetv3使用MnasNet-A1作为起点,使用NetAdapt进行优化,NetAdapt是一种可自动简化预训练模型的算法。再加上作者的手工改进,相较于之前取得了较大提升。
鉴于YOLOv5算法对速度与精度的优化权衡,本文设计的轻量级网络以YOLOv5为基础架构。由自动网络架构搜索所得的MobileNetv3有着比人工设计网络更少的设计时间与更好的实际效果。因此,本文设计的轻量级网络借鉴MobileNetv3的结构类型和改进方案对YOLOv5进行优化。
1. 网络结构
本文改进后的YOLOv5整体网络结构如图1所示。输入图像首先经过1个以h-swish为激活函数的3×3卷积层,紧接着进入11层bneck结构,bneck结构是以深度可分离卷积加SE(squezze-and-excitation)通道注意力机制组成的倒残差结构。所得特征图送入FPN+PAN结构中进行卷积和采样操作,卷积借鉴了CSPnet设计的CSP2结构,加强网络特征融合的能力。最后经过YOLOv5头部检测器将不同尺度的特征信息进行整合,得到预测结果。
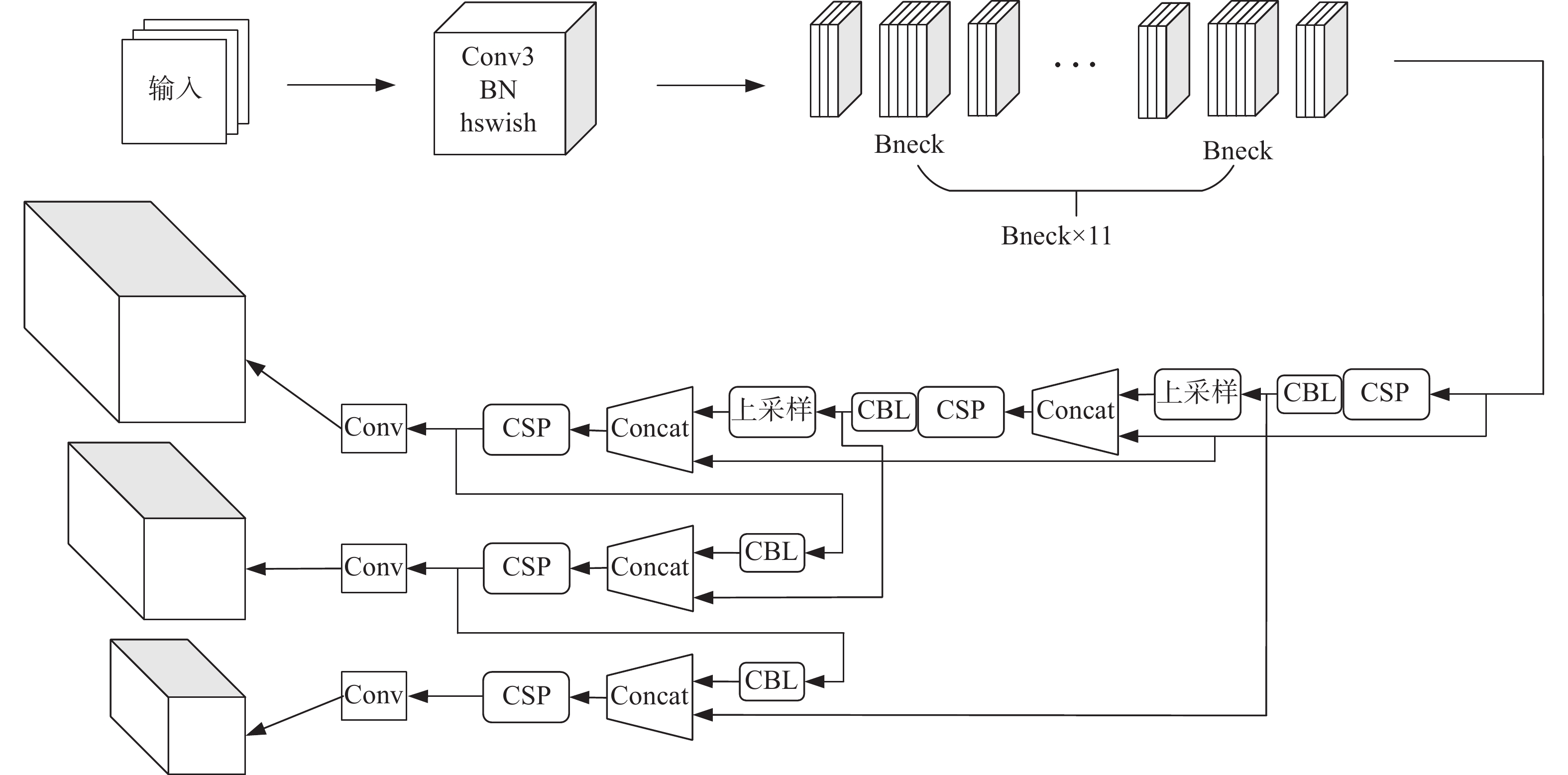 图 1 整体网络结构
图 1 整体网络结构 下载:
全尺寸图片
下载:
全尺寸图片
1.1 主干网络
主干网络由1个3×3卷积和11个连续bneck结构组成,bneck结构融合了以往MobileNet结构的特点,整体依然采用MobileNetv2的线性瓶颈的倒残差结构,采用深度可分离卷积,首先1×1卷积进行升维,然后进行3×3深度可分离卷积,选择性地在所得特征图后加入SE通道注意力机制,最后经过1×1卷积得到最后特征图。Bneck结构如图2所示。
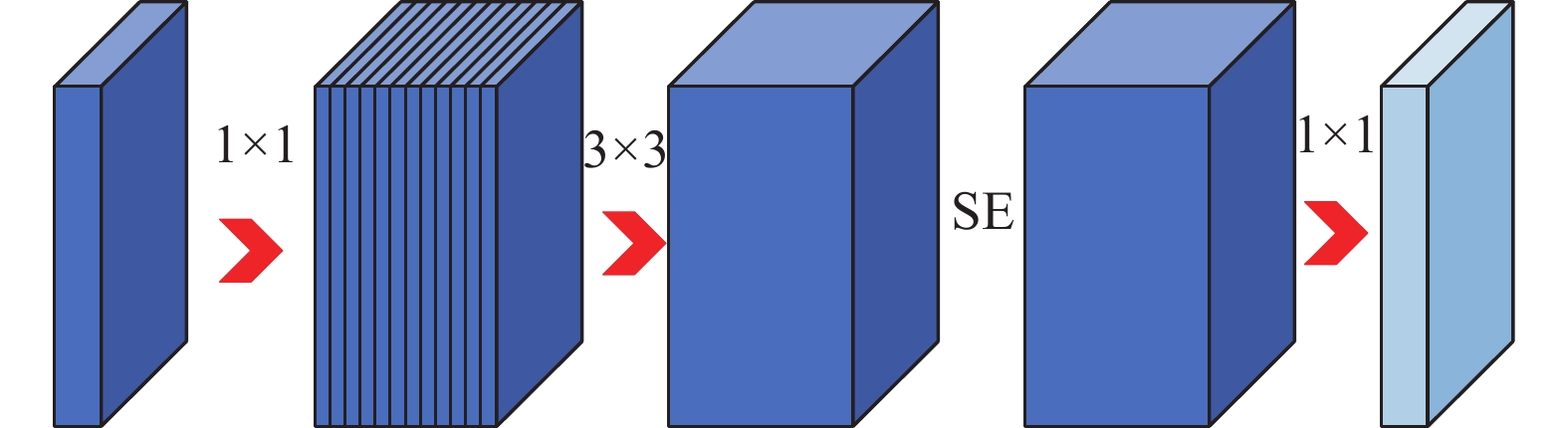 图 2 bneck结构下载:
全尺寸图片
图 2 bneck结构下载:
全尺寸图片
1.1.1 深度可分离卷积
深度可分离卷积的运用是MobileNet系列减小参数计算量的最主要原因,它采用深度卷积和逐点卷积进行特征图的提取,如图3所示。
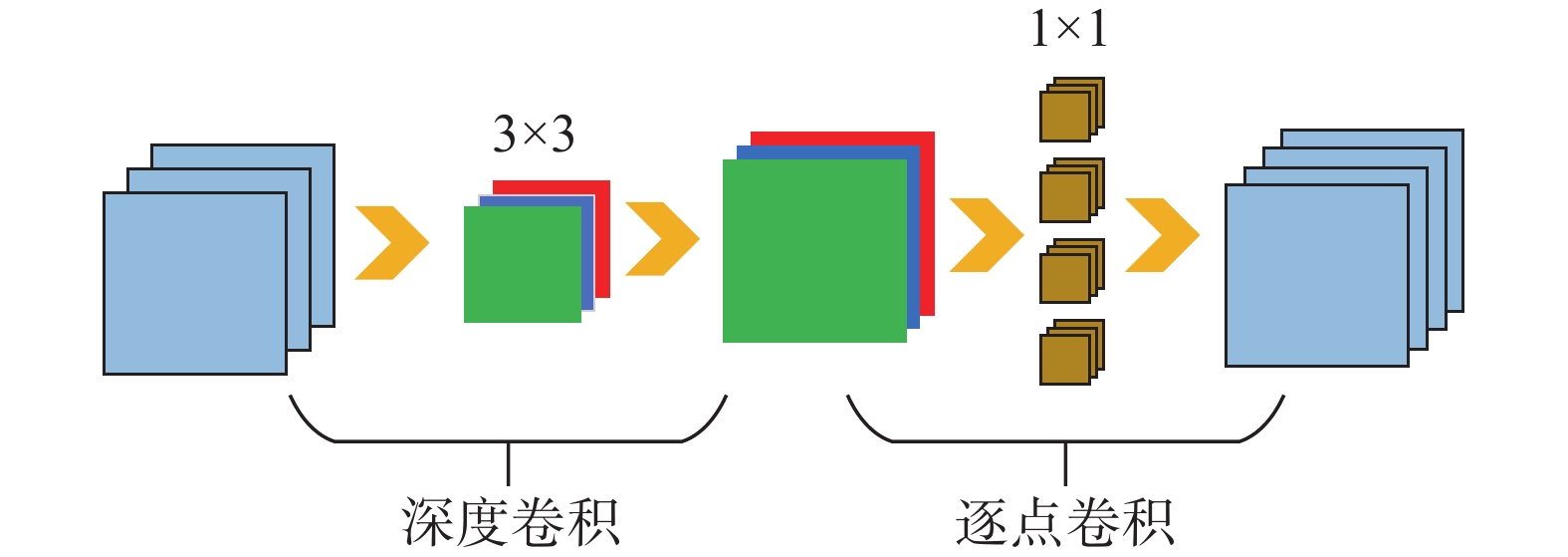 图 3 深度可分离卷积示意下载:
全尺寸图片
图 3 深度可分离卷积示意下载:
全尺寸图片
深度卷积也称逐通道卷积,对于来自上一层的多通道特征图,首先将其全部拆分为单个通道的特征图,分别对它们进行单通道卷积,然后重新堆叠到一起,只对上一层的特征图尺寸做调整而不改变通道数大小。再将前面得到的特征图进行逐点卷积,卷积核的大小都是1×1的,滤波器含与上一层通道数相同的卷积核,每个滤波器输出1张特征图。正是这样的卷积方式相较于常规卷积可以大大减少计算量。
1.1.2 h-swish激活函数
采用h-swish代替swish作为激活函数也是MobileNetv3相较于MobileNetv2取得性能提升的1个重要因素。Swish函数在深层模型上优于ReLU,函数计算公式为
$$ f(x) = x \cdot {\text{sigmoid}}(\beta x) $$ 式中β是常数或者可训练的参数。单单使用swish单元替换ReLU就能把Mobile NASNetA在ImageNet上的top-1分类准确率提高0.9%,InceptionResNet的分类准确率提高0.6%。但是sigmoid函数计算较为复杂,sigmoid函数计算公式为
$$ {\text{sigmoid}}(x) = 1 + \exp ( - x) ^{( - 1)} $$ h-swish采用ReLU6代替sigmoid函数改进swish函数,h-swish函数表达式为
$$ {\text{h-swish}}(x) = x\frac{{{\text{ReLU}}6(x + 3)}}{6} $$ ReLU6是限制最大输出为6的ReLU函数,这样做的目的是在移动端设备float16/int8的低精度时也能有很好的数值分辨率。几乎所有的软件和硬件框架上都可以使用ReLU6实现优化,能够有效减少使用sigmoid带来的耗时。但并非整个模型都使用h-swish,除开第1个卷积层,模型的前一半使用的是常规ReLU,后半部分才使用 h-swish。因为h-swish在较深的层上面才有用,特征图在浅层时更大,计算激活成本更高,所以在浅层简单地使用ReLU可以比h-swish更省时。
1.1.3 改进的SE通道注意力机制
SE是用来解决在卷积池化过程中特征图的不同通道所占的重要性不同带来的损失问题。传统池化卷积中,默认特征图每个通道重要程度都是相等的,而在实际问题中,不同通道的重要性往往是不相同的。
SE模块首先将特征图通过1个Squeeze操作得到1×1×C的包含通道信息的tensor,压缩操作所得信息要能综合所有层的信息,采用1个较为直接的方法:每一层值全部加起来取平均,也叫全局池化。全局池化公式为
$$ {z_c} = {{{F}}_{{{sq}}}}({u_c}) = \frac{1}{{H \times W}}\sum\limits_{i = 1}^H {\sum\limits_{j = 1}^W {{{{u}}_{{c}}}} } (i,j) $$ 式中:zc为压缩后的1×1×C的第c个值,uc(i,j)是前面输出的第c层,第i行第j列的值。压缩完后这个tensor通过1个非线性Excitation过程得到整合了各个通道信息的权重。对于1×1×C的tensor进行信息的整合要求是非线性的,这样表达能力强一些。原SE的Excitation采用了2个全连接层中间加1个ReLU,最后通过1个sigmoid函数的结构。本文中将sigmoid函数改用h-sigmoid替代,计算公式为
$$ {\text{h-sigmoid}}(x) = \frac{{{\text{ReLU}}6(x + 3)}}{6} $$ 第1个全连接层降维,第2个升维如式(1)所示:
$$ s = h\sigma ({W_2}\delta ({W_1}z)) $$ (1) 式中:δ为ReLU,W1、W2指2个全连接层,z为前面全局池化后的结果,hσ为h-sigmoid函数。SE整体结构示意如图4所示。
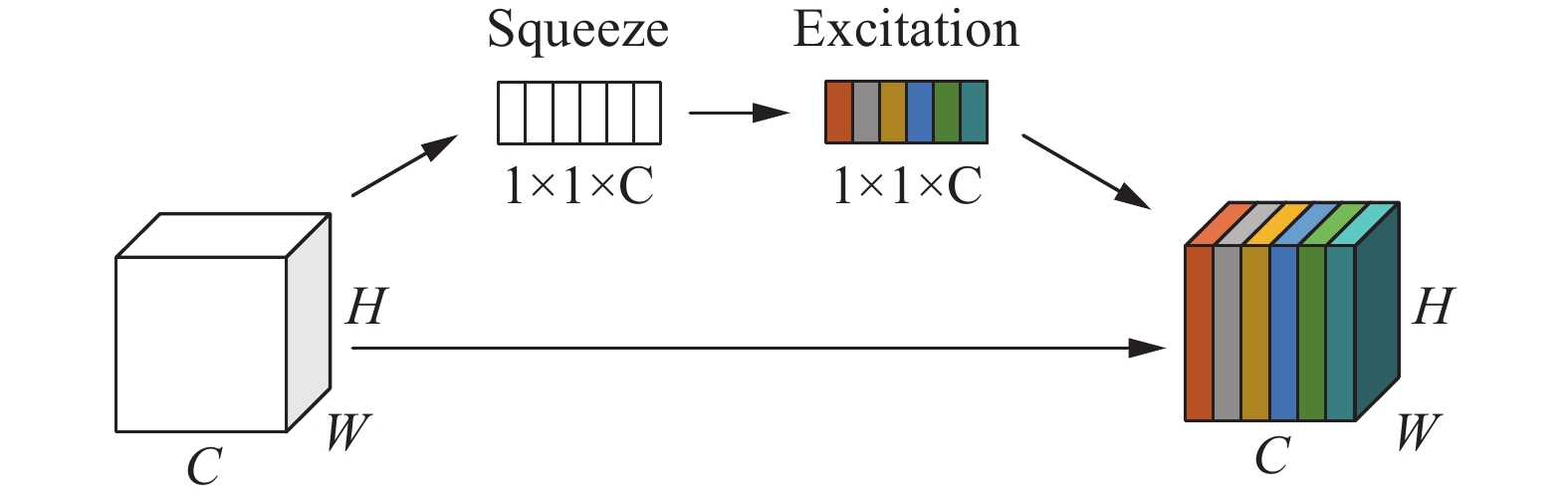 图 4 SE通道注意力机制整体结构示意下载:
全尺寸图片
图 4 SE通道注意力机制整体结构示意下载:
全尺寸图片
1.2 FPN+PAN结构的Neck
网络Neck部分沿用YOLOv5的FPN+PAN的网络结构设计。由FPN层自顶向下传达语义特征,把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征自上而下进行融合,使所有尺度下的特征都有丰富的语义信息。在FPN层后添加1个自底向上的特征金字塔,塔中间包含PAN结构。FPN中间经过多层的网络后底层目标信息已经非常模糊了,PAN自底向上的路线可以弥补加强定位信息。FPN+PAN结构示意如图5所示。
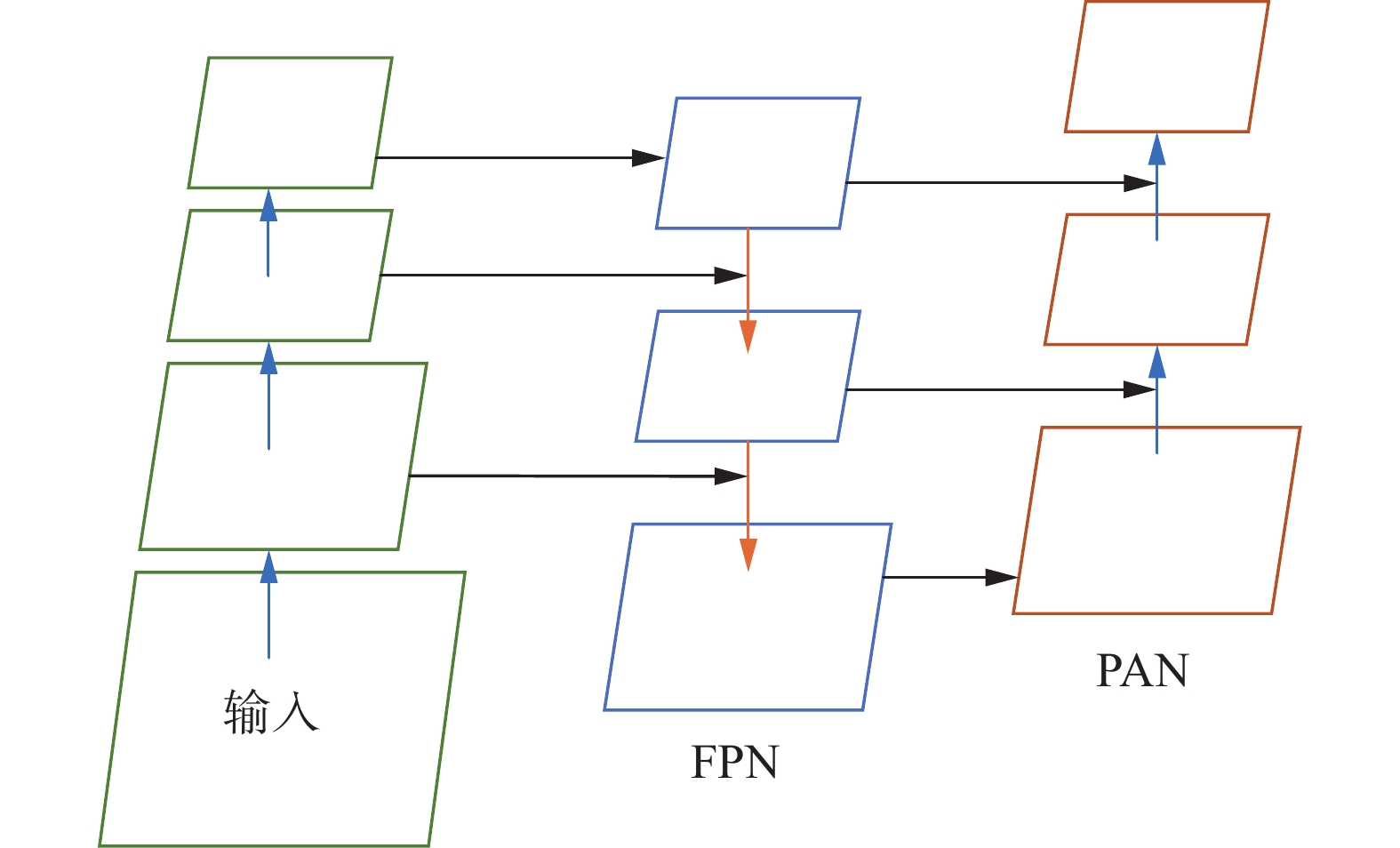 图 5 FPN+APN结构示意下载:
全尺寸图片
图 5 FPN+APN结构示意下载:
全尺寸图片
另外,YOLOv4的Neck结构中,采用的都是普通卷积的操作,在YOLOv5中采用了借鉴CSPnet设计的CSP2结构来加强网络特征融合的能力。
2. 网络性能对比实验
2.1 数据集制作
实验使用的数据集为自定义数据集,数据采集来自不同养殖猪场过道中移动的猪只视频,摄像头拍摄角度为从过道上方垂直向下拍摄。各不同过道场景下的拍摄视频经过拆帧处理后,对图片进行手工标注,共计标注实验数据10000张。实验划分训练集图片8000张,验证集1000张,测试集1000张,目标检测类别有两类,分别为过道中通过的猪只和赶猪的人。网络输入端采用Mosaic数据增强方式对输入图片进行随机缩放、裁剪、排布,丰富数据集。经Mosaic数据增强后的训练图片如图6所示。
 图 6 Mosaic数据增强后的训练图片下载:
全尺寸图片
图 6 Mosaic数据增强后的训练图片下载:
全尺寸图片
2.2 实验环境配置
本实验所用系统为64位、Ubuntu18.04;CPU采用i7-8700K,内存64 GB;GPU采用GeForce GTX 1080Ti×2,显存12 GB;图像处理加速库CUDA11.1;深度学习框架torch1.11;训练批尺寸batch_size设置为16;迭代epoch为300;输入图片大小input_size为640 ppi×640 ppi。
2.3 实验结果
2.3.1 主干网络性能对比实验
本文在以YOLOv5为框架的基础上借鉴MobileNetv3主干网络的改进思路,设计出1个轻量级目标检测网络。在以YOLOv5为框架的基础上,本文同时设计了以ShuffleNet为主干的网络,同YOLOv5原网络一起与本文改进的网络做实验对比。实验结果如表1所示。
表 1 不同主干网络性能对比算法 MAP 传输速率/(f·s−1) 参数量/106 原YOLOv5 0.908 111 7.0 YOLOv5+ShuffleNetv1 0.78 121 0.4 YOLOv5+ShuffleNetv2 0.82 130 0.4 YOLOv5-Lite 0.82 131 1.6 YOLOv5+MobileNetv2 0.84 123 3.7 本文改进YOLOv5 0.874 130 3.5 表1中均值平均精度(mean average precision, MAP)指的是并集上的交集(intersection over union, IOU)阈值从0.5~0.95的平均MAP,以此指标表示精度。传输速率为每秒检测图片数,以此衡量速度。参数量是网络整体参数量。表1中列举了原YOLOv5以及YOLOv5经过不同改进后的算法结果对比。与其他轻量级YOLOv5算法相比,本文改进后的YOLOv5在速度与精度之间有更好的效果。
2.3.2 算法性能对比实验
本文选取了3个常用其他算法与改进后YOLOv5进行性能比较,选择MAP、传输速率和模型大小作为衡量指标,如表2所示。由表2可知,改进后的YOLOv5在推理速度上远超其他算法,模型大小也要比其他算法小得多,但精度不低于甚至超过其他算法。
表 2 不同算法性能对比算法 MAP 传输速率/(f·s−1) 模型大小/MB CenterNet 0.740 28 173.0 Fcos 0.804 22 257.6 YOLOv4 0.893 16 256.0 改进YOLOv5 0.874 130 7.3 3. 结论
针对深度学习目标检测任务对实际场景应用的优化需求,本文设计了1个具有更快检测速度的轻量级目标检测网络。新网络结合了YOLOv5以及MobileNetv3中的优点,与原网络YOLOv5相比,新网络训练出的模型在精度损失较小的情况下取得了可观的速度提升,性能更适用于边缘设备的算力需求。同时,与其他目标检测网络相比,新网络模型在精度和速度的综合比较下有着更好的性能,现实场景应用价值较高。与YOLOv5+ShuffleNet的改进方式相比,后者精度下降较多,但参数量和模型大小很小,今后的研究方向将在保持精度的情况下进一步减小参数量、减小模型大小以更便于边缘设备的应用。
-
图 1 整体网络结构
下载:
全尺寸图片
图 2 bneck结构
下载:
全尺寸图片
图 3 深度可分离卷积示意
下载:
全尺寸图片
图 4 SE通道注意力机制整体结构示意
下载:
全尺寸图片
图 5 FPN+APN结构示意
下载:
全尺寸图片
图 6 Mosaic数据增强后的训练图片
下载:
全尺寸图片
表 1 不同主干网络性能对比
算法 MAP 传输速率/(f·s−1) 参数量/106 原YOLOv5 0.908 111 7.0 YOLOv5+ShuffleNetv1 0.78 121 0.4 YOLOv5+ShuffleNetv2 0.82 130 0.4 YOLOv5-Lite 0.82 131 1.6 YOLOv5+MobileNetv2 0.84 123 3.7 本文改进YOLOv5 0.874 130 3.5 表 2 不同算法性能对比
算法 MAP 传输速率/(f·s−1) 模型大小/MB CenterNet 0.740 28 173.0 Fcos 0.804 22 257.6 YOLOv4 0.893 16 256.0 改进YOLOv5 0.874 130 7.3 -
[1] 王军, 冯孙铖, 程勇. 深度学习的轻量化神经网络结构研究综述[J]. 计算机工程, 2021, 47(8): 1−13. doi: 10.19678/j.issn.1000-3428.0060931 [2] 谢也佳. 面向嵌入式场景识别的深度模型剪枝方法[D]. 西安: 西安电子科技大学, 2021. [3] 刘俊明, 孟卫华. 基于深度学习的单阶段目标检测算法研究综述[J]. 航空兵器, 2020, 27(3): 44−53. doi: 10.12132/ISSN.1673-5048.2019.0100 [4] Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector[C]// European Conference on Computer Vision. Cham: Springer, 2016: 21−37. [5] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Computer Vision & Pattern Recognition. Las Vegas: IEEE, 2016: 779−788. [6] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//IEEE Conference on Computer Vision & Pattern Recognition. Hawaii: IEEE, 2017: 6517−6525. [7] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08) [2021-01-08]. https://arxiv.org/abs/1804.02767. [8] BOCHKOVSKIY A, WANG C Y, LIAO H. YOLOv4: optimal speed and accuracy of object detection[J]. IEEE transactions on pattern analysis & machine intelligence, 2020, 12(16): 6317−6325. [9] 贺宇哲, 何宁, 张人, 等. 基于双阶段目标检测算法研究综述[C]//中国计算机用户协会网络应用分会2021年第二十五届网络新技术与应用年会论文集. 北京: 中国计算机协会, 2021: 182-186. [10] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis & machine intelligence, 2017, 39(6): 1137−1149. [11] HE Kaiming, GKIOXARI G, P Dollár, et al. Mask R-CNN[J]. IEEE transactions on pattern analysis & machine intelligence, 2017, 24(7): 6159−6168. [12] 王燕妮, 刘祥, 刘江. 基于单阶段网络模型的目标检测改进算法[J]. 探测与控制学报, 2021, 43(2): 56−62,68. [13] IANDOLA F N, HAN S, MOSKEWICZ M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size[J]. Springer cham, 2016, 15(9): 21−29. [14] 胡皓翔. 嵌入式目标检测平台架构设计与实现[D]. 北京: 北京邮电大学, 2021. [15] ZHANG Xiangyu, ZHOU Xinyu, LIN Mengxiao, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[J]. Springer cham, 2017, 13(4): 423−431. [16] MA Ningning, ZHANG Xiangyu, ZHENG Haitao, et al. ShuffleNet V2: practical guidelines for efficient CNN architecture design[J]. Springer cham, 2018, 26(34): 84−92. [17] SANDLER M, HOWARD A, ZHU Menglong, et al. Inverted residuals and linear bottlenecks: mobile networks for classification, detection and segmentation[J]. Springer cham, 2018, 24(6): 126−134. [18] HOWARD A, SANDLER M, et al. Searching for mobileNetV3[C]//European Conference on Computer Vision. Cham: Springer, 2019: 654-662. [19] TAN Mingxing, CHEN Bo, PANG Ruoming, et al. MnasNet: platform-aware neural architecture search for mobile[J]. IEEE transactions on pattern analysis & machine intelligence, 2018, 19(45): 2453−2461.






