
Research on motion detection algorithm of figure skaters based on SAT-GCN
-
摘要: 针对花样滑冰运动人体运动轨迹复杂、动作类型多样、普通人肉眼难以区分且常规的行为识别方法识别准确率低的问题,提出了一种基于时空图卷积网络与多通道注意力机制融合方法(SAT-GCN)的花样滑冰动作识别算法。该算法首先将视频提取成连续的单独帧,使用OpenPose算法提取人体骨骼关键点数据,降低背景噪声干扰;然后使用时空图卷积算法对骨骼关键点数据进行动作分类。算法对时空图卷积算法进行改进,加入了多通道时空注意力机制融合模块,使得模型更加关注重要的关键点、时间帧片段、特征;使用时序卷积网络(TCN)提取人体骨架关键点在时间序列上的特征;使用SoftMax对提取后的特征进行动作分类。在花样滑冰数据集FSD-10和公开的人类行为数据集Kinetics-Skeleton上进行训练和测试,与改进前的时空图卷积网络(ST-GCN)进行对比,本文所提算法的预测准确率在2个数据集上均有所提升,验证了多通道注意力机制融合方法在花样滑冰选手动作检测任务中的有效性。Abstract: Aiming at the problem that the accuracy of conventional behavior recognition methods is low and that it can be hardly distinguished due to the complexity of human movement trajectory and the diversity of movement types in figure skating, a new figure skating movement recognition algorithm is proposed based on the fusion of spatial-temporal graph convolution network and multi-channel attention mechanism(SAT-GCN). Firstly the video is extracted into continuous individual frames, and OpenPose algorithm is used to extract the key points data of human skeleton to reduce the interference of background noise, and then spatiotemporal graph convolution algorithm is used to classify the key points data of skeleton. The convolution algorithm of spatial-temporal graph is improved by adding a multi-channel spatial-temporal attention mechanism fusion module, which makes the model pay more attention to important nodes, time frame segments and features. Temporal convolutional network(TCN) is used to extract the key point features of human skeleton in time series. SoftMax classifier is used to classify the actions of extracted features. By training and testing on figure skating data set (FSD-10) and public human behavior data set (Kinetics-Skeleton), and comparing the result with the spatial-temporal graph convolution network(ST-GCN) before improvement, the prediction accuracy of the proposed algorithm is improved in both data sets, verifying effectiveness of the improved GCN and multi-channel attention mechanism fusion method in human behavior recognition and detection.
-
人体行为识别作为当前多数领域的研究热点问题,其迅速发展并得到了广泛应用。人体动作分析技术多应用于影视创作、自动驾驶、安防异常事件的监测、体育竞技分析和动作康复等实际场景中[1]。在人体运动分析的研究中涉及到众多学科知识的交叉,包括但不限于计算机科学、环境行为学、材料科学和运动人体科学等。花样滑冰运动拥有优雅的舞姿,备受年轻人的喜爱,但因其动作复杂、细分种类多样,作为普通观众很难区分动作优劣。而且现有的行为识别方法,难以胜任花样滑冰动作复杂度级别的动作检测任务。
在人体行为识别研究方面,目前主要有3种主流的研究方法。1)基于卷积神经网络的研究方法,该方法的经典模型有双流卷积模型以及时间分段网络等[2]。双流卷积模型拥有2个独立的卷积神经网络分支,2支网络分别并行地提取视频特征。该方法容易受到图像噪声的干扰,在复杂的环境中难以推广[3]。2)基于循环神经网络的研究方法,学者分别使用不同的方法对循环神经网络(recurrent neural network, RNN)进行改进,演化出了长短时记忆模型(long short-term memory, LSTM)和门控单元模型(gate recurrent unit, GRU)。循环神经网络能够对视频中的人体骨架数据进行时序序列建模,该方法的优点在于能够充分地提取时间序列特征,但却忽略了空间信息的重要性[4]。3)采用本文所提到时空图卷积方法(spatial-temporal graph convolution network,ST-GCN)。该方法通过图卷积学习视频帧中关键点之间的位置特征信息,使用时序卷积网络学习关键点在连续的视频帧中的位置变化特征[5]。该方法相较于前2种方法,不仅能够有效降低图像噪声的干扰,而且能够同时将人体在动作骨架的空间变化特征以及时间序列变化特征提取出来,在人体行为识别的准确率上,有较大的提升。然而,在一段连续的视频序列中,往往只有小部分视频帧的信息对某一动作的判断具有决定性的意义,同时许多动作也仅涉及到部分关键点的活动,如果在训练时,对所有的视频帧以及关节运动统一进行训练和学习,会造成许多冗余的参数以及资源的浪费,并且对识别的准确率造成影响[6]。
针对ST-GCN存在的问题,本文提出了时空图卷积网络与多通道注意力机制融合(spatial attention temporal graph convolution networks, SAT-GCN)行为识别算法,借鉴了ST-GCN的方法,在其基础上对GCN进行改进,加入多通道时空注意力机制模块让模型自主学习,合理分配资源,使其更加关注动作片段中更重要的视频片段、人体骨架关键点等特征,增强模型的性能,提高行为识别的准确率。
1. 网络结构
本文提出的基于SAT-GCN的动作识别模型结构如图1所示。模型结构的输入为1段含有人体动作行为的视频,对于视频,首先使用人体姿态估计算法OpenPose,提取视频帧的关键点骨架特征,获得的数据包含每一个骨骼关键点的
$(X, Y)$ 坐标和置信度,降低背景噪声,减少干扰。其次,对输入数据进行批量归一化,通过在GCN加入时空−通道注意力机制融合模块,实现在训练中动态分配关节,视频帧的权重信息。将加入了注意力机制的图卷积网络与时序卷积网络进行组合,合并成SAT-GCN网络单元。SAT-GCNs包含9个SAT-GCN单元,以实现在网络中交替使用GCN图卷积网络和时序卷积网络(temporal convolutional network, TCN),最后通过平均池化层(average pooling)、全连接层(fully connected layer)后,采用SoftMax对特征进行分类输出。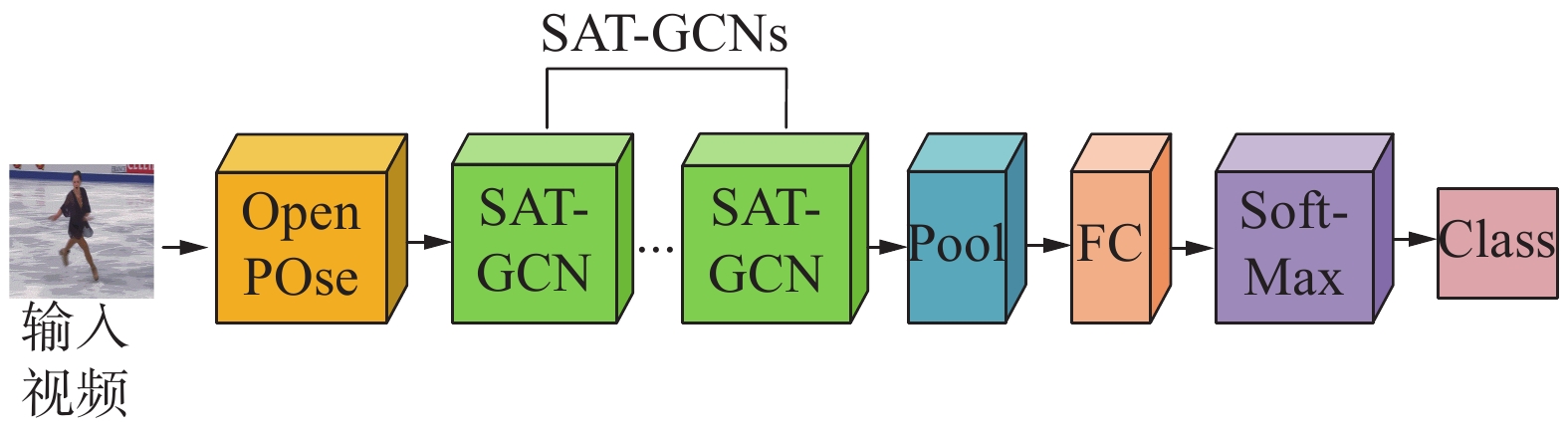 图 1 SAT-GCNS网络整体结构
图 1 SAT-GCNS网络整体结构 下载:
全尺寸图片
下载:
全尺寸图片
1.1 人体姿态估计算法
人体姿态估计算法,因为要先检测关键点再进行姿态估计,所以又称人体关键点检测算法(human key-points detection)。传统方法关键点检测算法采用“自上而下”的方式,先对视频帧的图片进行目标检测,框选出所有的单个目标,再对单个目标进行姿态估计。一般来说“自上而下”的姿态估计检测精度更高,但很难在多人的场景下快速检测。另外一种是“自下而上”的检测方法,先检测图中所有的关键点,再对关键点进行匹配分组连接。本文采用“自下而上”的OpenPose姿态估计算法,该方法能够实现对人的实时关键点检测,而且检测速度与视频中的人数无关,能够实现多人的快速检测。该算法首先检测视频中所有存在的关键点,然后再根据优化算法进行匹配、聚类,拼接成完整的骨架信息[7]。
OpenPose算法使用VGG-19网络的前10层作为骨干网路,对输入图片进行低层次的特征提取。将生成的特征图(feature maps, F)并行输入到2条连续的卷积神经网络(convolutional neural networks, CNN)分支,进入到多阶段网络中。第1条网络分支用于预测骨骼关键点的置信度(part confidence maps, PCM),用于获取图片在关键点附近的高斯热图(heatmap);第2条网络分支用于预测关节亲和场(part affine fields, PAF),学习和预测骨架的连接方向和骨架所在的位置,对肢体的位置和方向进行编码。在单人环境下,使用二分图匹配的方法将关节点连接成单人骨架结构。多人环境下,使用匈牙利算法求解最佳匹配问题,从而优化骨骼关键点之间的连接。
分支1用S表示,分支2用L表示,2个分支的末尾使用式(1)和式(2)来分别计算PCM分支和PAF分支的误差损失。训练时,每个阶段都会产生损失,为避免梯度消失,在预测阶段只使用最后一层的输出,计算方法如式(1)~式(2)所示:
$$ {f}_{S}^{t}={\displaystyle \sum _{j=1}^{J}{\displaystyle \sum _{p}^{}W(p)}}\cdot \left|\right|{S}_{j}^{t}(p)-{S}_{j}^{*}(p)|{|}_{2}^{2} $$ (1) $$ {f}_{L}^{t}={\displaystyle \sum _{c=1}^{C}{\displaystyle \sum _{p}^{}W(p)}}\cdot \left|\right|{L}_{c}^{t}(p)-{L}_{c}^{*}(p)|{|}_{2}^{2} $$ (2) 式中:
$f_S^t$ 为S分支PCM的损失函数;$f_L^t$ 为式L分支PAF的损失函数;p为像素点在图像中的位置;${L^*}$ 为PAF骨骼关联向量场真实值;${S^{\text{*}}}$ 为PCM真实值置信度;$W$ 为二元掩码,当$ p $ 的位置被标记时,$ W(p){\text{ = }}0 $ ,当p未被标记时,$ W(p){\text{ = 1}} $ 。由于OpenPose网络具有一定的深度,为了避免梯度消失,算法在训练过程中,按照周期进行梯度补充。最后对2个分支的目标函数按照视频帧的位置进行加权求和,得到最终的目标函数,如式(3)所示:
$$ f = \sum\limits_{t = 1}^T {(f_S^t + f_L^t)} $$ (3) 式中T为视频总帧数。
对于人体骨架图的定义,相关数据集和姿态估计算法给出了不同的定义方法。例如姿态估计算法Hr-Net和OpenPose对于人体骨架关键点的定义分别为17和18个,数据集Kinetics-skeleton和数据集NTU-RGB+D分别为18个和25个。本文利用OpenPose定位人体的18个关键点。其中每个关键点点的编号对应的部位或关节点如表1所示。
表 1 关键点编号编号 名称 编号 名称 0 鼻 9 右膝 1 首 10 右足首 2 右肩 11 左腰 3 右肘 12 左膝 4 右手首 13 左足首 5 左肩 14 右目 6 左肘 15 左目 7 左手首 16 右耳 8 右腰 17 左耳 OpenPose对于人体标注的方式如图2所示,其中点与点之间的连接线称为边。OpenPose首先检测图片存在的所有关键点,再根据关键点的连接方式,将关键点拼接成骨架。
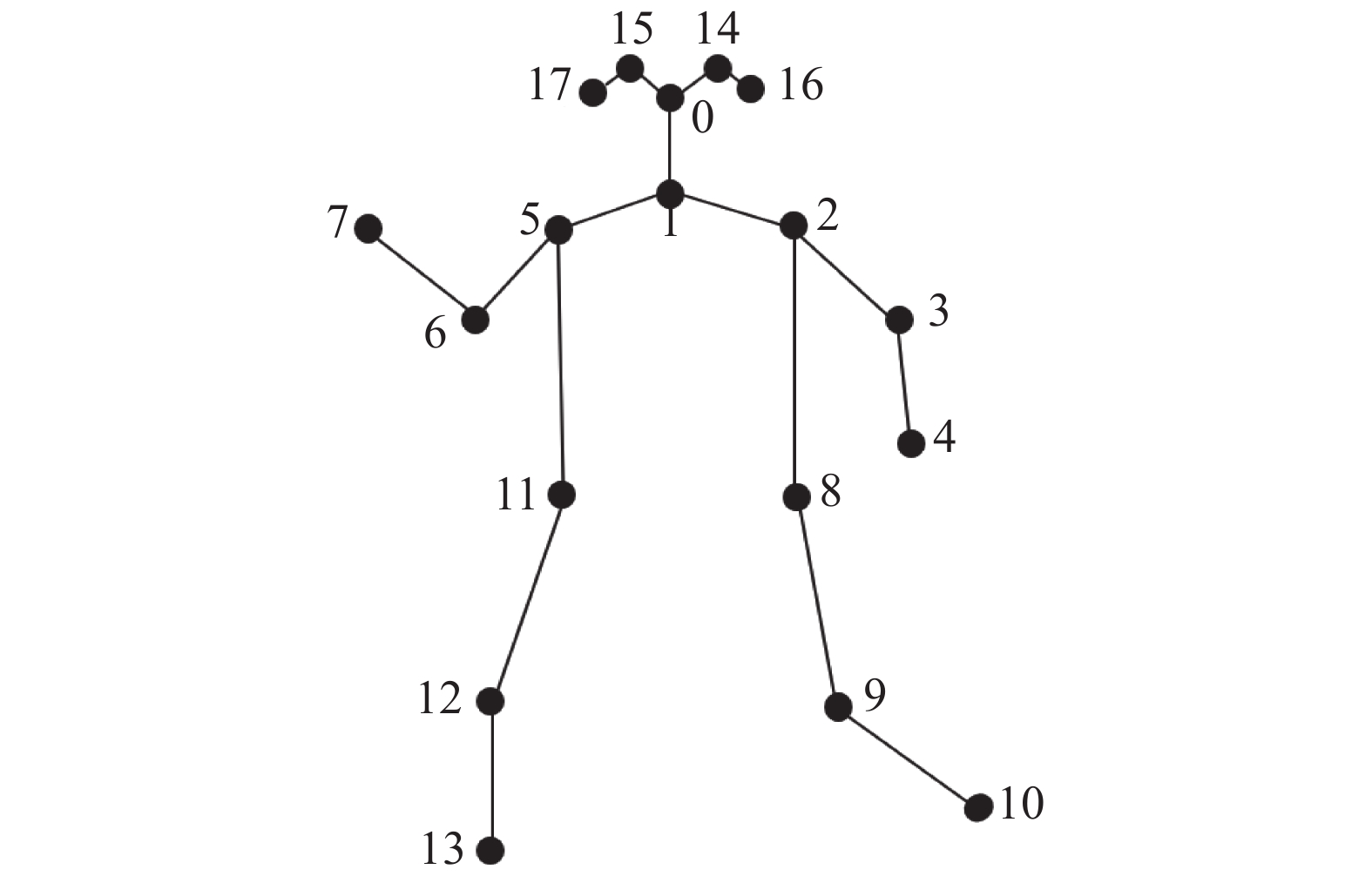 图 2 OpenPose关键点骨架模型下载:
全尺寸图片
图 2 OpenPose关键点骨架模型下载:
全尺寸图片
1.2 动作特征提取网络
对于结构化的图像数据的特征提取,通常使用卷积神经网络,采用卷积核在图像上滑动的方法来实现。结构化数据比较常见,比如图像等形式。而人体骨骼关键点数据属于非结构化数据,是拓扑图的一种,称为图结构的数据。现实中大多数的数据都是以图结构的数据进行存储的,例如社交网络信息、万维网、交通道路规划等。这类非欧几里德类型的数据结构称为拓扑图,常规的卷积神经网络很难处理。目前的解决方案是使用图卷积网络GCN,核心思想是将与节点相连的边的信息进行整合得到新的节点信息[8]。基于此,本文采用GCN来处理骨骼关键点数据。
本文搭建了行为特征提取模块,再利用OpenPose构造完成视频帧的人体骨骼数据后,对骨骼数据提取空间和时间特征,并将2种特征融合,对行为进行分类。根据骨骼关键点数据图结构的特征,本文采用GCN作为基础特征提取方法,提取每一帧骨骼关键点结构的特征,采用时序卷积网络TCN网络提取相同关键点在不同帧之间的特征。并以此为基础构建了时空图卷积模块(SAT-GCN-Block),如图3所示。1个时空图卷积模块包括GCN模块、时空通道注意力机制融合模块(spatial temporal channel,STC)、时序卷积TCN模块以及1个从输入到输出的残差结构,残差结构用于减缓网络退化以及梯度消失问题。
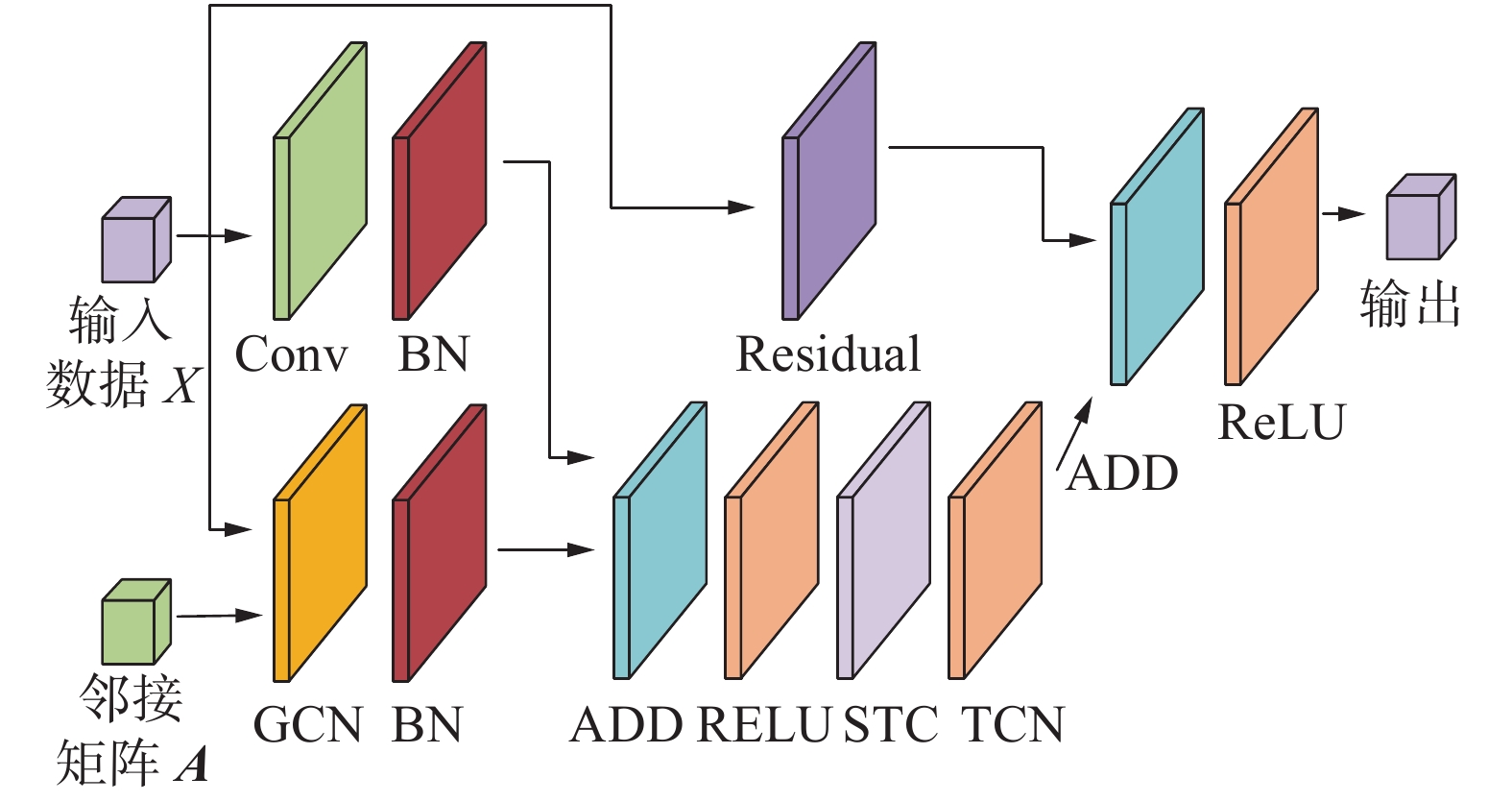 图 3 SAT-GCN-Block结构示意下载:
全尺寸图片
图 3 SAT-GCN-Block结构示意下载:
全尺寸图片
1.2.1 空间图卷积网络GCN
本文将人体骨骼关键点及其按照人体架构连接成的边看作拓扑图。借助图谱的理论实现空间骨架图上的特征提取,使用图的度矩阵、邻接矩阵以及拉普拉斯的特征值和特征向量来研究人体关节骨架图的拓扑性质[9]。图卷积的数学公式如式(4)所示:
$$ {f_{{\text{out}}}} = {\Lambda ^{ - \frac{1}{2}}}({\boldsymbol{A}} + {\boldsymbol{I}}){\Lambda ^{ - \frac{1}{2}}}{f_{{\text{in}}}}{\boldsymbol{W}} $$ (4) 式中:
${f_{{\text{out}}}}$ 为图卷积提取的特征输出,I为单位矩阵,A为关键点邻接矩阵,${f_{{\text{in}}}}$ 为图卷积输入,W为待学习的空间矩阵。在本文中,将人体骨架关键点按照空间划分成3个分区,分别是近心点、远心点、自身点。根据划分的方式,将权值邻接矩阵设成3个大小为(18, 18)的邻接矩阵,并堆叠成形状为(3, 18, 18)的邻接矩阵A。式(4)仅适用于单一结构划分的骨架图结构方式,其中每个关节点的矩阵
${\boldsymbol{W}}$ 都是一样的,无法应对拥有多个子集的划分方式,对式(4)进行改进,首先将邻接矩阵A划分成多个子矩阵${{\boldsymbol{A}}_j}$ ,如式(5)所示:$$ {\boldsymbol{A}} + {\boldsymbol{I}} = \sum\limits_j {{{\boldsymbol{A}}_j}} $$ (5) 将划分的邻接矩阵A的子邻接矩阵
${{\boldsymbol{A}}_j}$ 带入上述图卷积数学公式,如式(6)所示:$$ \begin{gathered} {f_{{\text{out}}}} = \sum\limits_j {\varLambda _j^{ - \frac{1}{2}}} {{\boldsymbol{A}}_j}\varLambda _j^{ - \frac{1}{2}}{f_{{\text{in}}}}{{\boldsymbol{W}}_j} \\ {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} \varLambda _j^{ii} = \sum\limits_k {({\boldsymbol{A}}_j^{ik})} + \alpha \\ \end{gathered} $$ (6) 式中
$\alpha $ 是为了避免$\varLambda $ 存在全为0的行。图卷积实现流程如图4所示,其中N表示每次输入的样本数;C表示3通道,分别是关节的坐标值$X$ 和$Y$ 以及坐标的置信度;T表示视频帧的长度;V表示单人关键点的总数。图4中多次使用Reshape改变数据格式,以满足矩阵乘法,并使输入和输出保持相同的数据格式。虚线内为邻接矩阵的3个子图矩阵。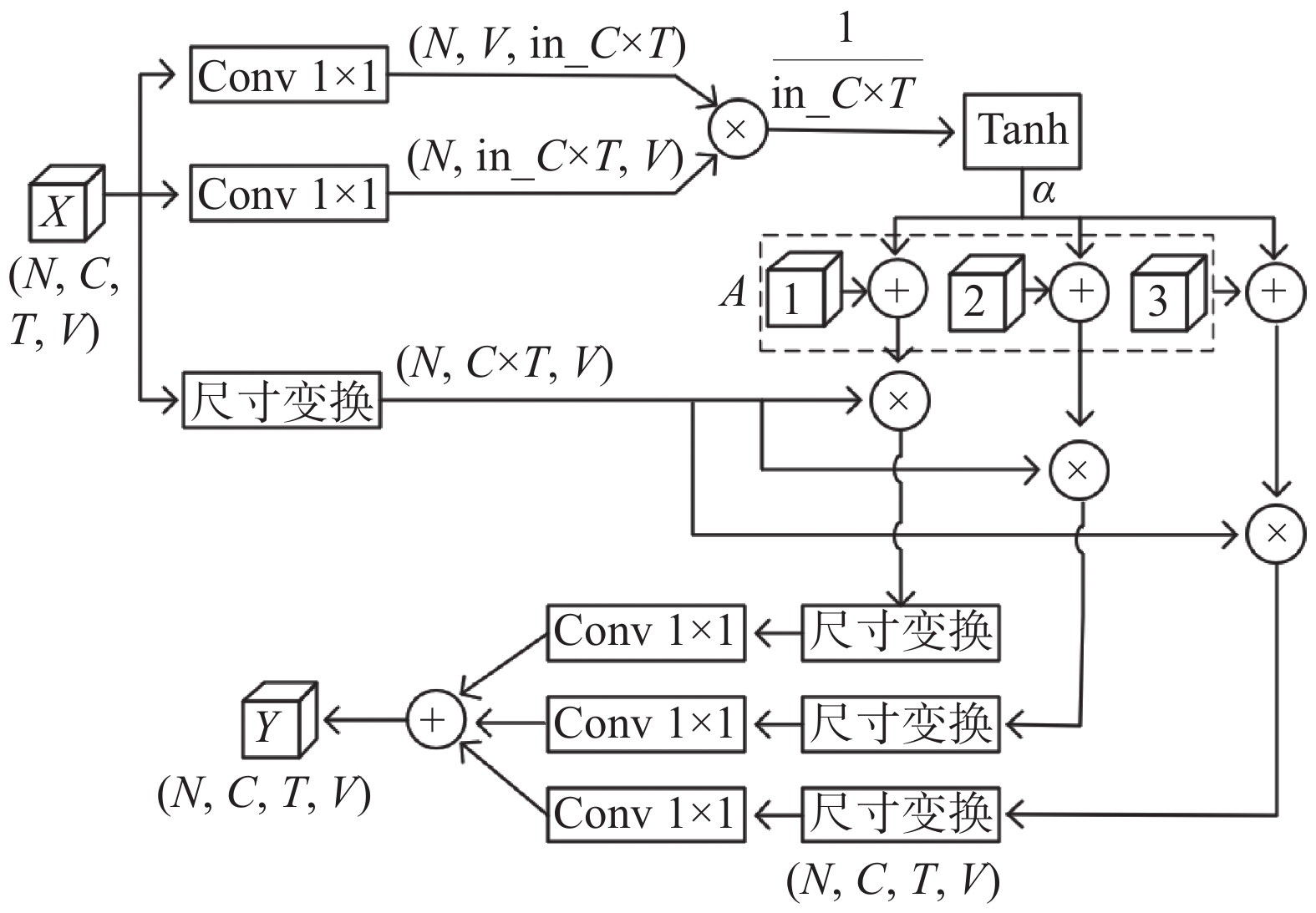 图 4 图卷积的实现流程下载:
全尺寸图片
图 4 图卷积的实现流程下载:
全尺寸图片
1.2.2 多通道注意力机制融合模块
注意力机制可认为是一种资源重新分配机制,核心思想是在原有的数据中间找到关联性,对于基于骨骼关键点的动作识别有很大的研究价值[10]。从空间的角度来看,人的某个动作可能仅需要移动部分关键点;从时间的角度来看,一个包含多帧的动作流,可能存在多个不同的关键阶段,对于最后的识别具有不同的重要性[11];从特征角度来看,卷积的多个通道通常包含着不同层次的语义信息,对于不同的动作识别具有不同的价值。然而在ST-GCN原文中,没有考虑到这些信息,动作识别效果仍然存在很大的提升空间。
本文在ST-GCN的基础上引入注意力机制,提出了空间时间通道注意力融合模块(STC-Attention)。分别从空间、时间、通道3个角度建立3个注意力机制模块,以重新分配关节点、动作阶段以及语义层次在不同动作特征中的关系。将输入的特征图依次输入到3个模块中,提取不同维度的注意力特征图,将这些特征图与原始特征图相乘,强化相应的特征。接下来将分别介绍3个注意力机制模块的实现方式。
空间注意力机制模块(spatial attention mechanism, SAM):在不同的动作特征中,强化不同的关键点特征,使得模型对不同的关键点给予不同的关注度,实现方式如式(7)所示:
$$ {M_s} = \sigma \left( {{g_s}\left( {{\text{AvgPool}}\left( X \right)} \right)} \right) $$ (7) 式中:
$X \in {{\bf{R}}^{C \times T \times N}}$ 是输入特征,采用${\text{AvgPool}}$ 将其在所有空间帧上取均值,${\text{AvgPool}}\left( X \right) \in {{\bf{R}}^{C \times 1 \times N}}$ ;${g_s}$ 表示在空间维度上进行一维卷积(Conv1D),输出通道数为1,用来生成注意力的值,编码强调或抑制的关节位置;$\sigma $ 表示激活函数,这里使用${\text{Sigmoid}}$ 函数来实现,这是因为${\text{Sigmoid}}$ 函数能够提供更加灵活、更加适合数据驱动的神经网络,更有利于强化注意力机制的作用;${M_s} \in {{\bf{R}}^{1 \times 1 \times N}}$ 是输出特征图,并将其与输入特征图点乘后相加,进行特征融合。时间注意力机制模块(temporal attention mechanism, TAM):与空间注意力机制模块相似,它的作用是帮助模型在动作识别时对于重要的某一阶段,模型框架给予更多的关注,实现方式如式(8)所示:
$$ {M_t} = \sigma \left( {{g_t}\left( {{\text{AvgPoo}}{{\text{l}}_s}(X)} \right)} \right) $$ (8) 式中:输出特征
${M_t} \in {{\bf{R}}^{1 \times T \times 1}}$ ,与空间注意力机制模块的输出操作一样,与输入特征点乘并相加;${\text{AvgPoo}}{{\text{l}}_s}$ 表示沿空间特征维度进行平均;${g_t}$ 为沿时间维度进行一维卷积运算。通道注意力机制模块(channel attention mechanism, CAM):该模块根据数据输入样本强化特征识别通道,增强特征判别。实现方式如式(9)所示:
$$ {M_c} = \sigma \left( {{g_{c2}}\left( {\delta \left( {{g_{c1}}\left( {{\text{AvgPoo}}{{\text{l}}_{st}}\left( X \right)} \right)} \right)} \right)} \right) $$ (9) 式中:
${M_c} \in {{\bf{R}}^{C \times 1 \times 1}}$ ;${\text{AvgPoo}}{{\text{l}}_{st}}$ 表示在空间和时间维度上进行平均运算;${g_{c1}}$ 和${g_{c2}}$ 为沿2个通道作用的线性函数,使用2个全连接层进行实现;$\delta $ 为ReLU激活函数。将空间、时间、通道注意力机制模块按图5方式连接,按照SAM-TAM-CAM进行排列,图5中每个模块用虚线包围,模块的输出与输入点乘并相加后进入下一个模块,以实现将3个注意力机制模块特征进行融合。融合后的输出送入下一步时序卷积网络进行时序特征提取。
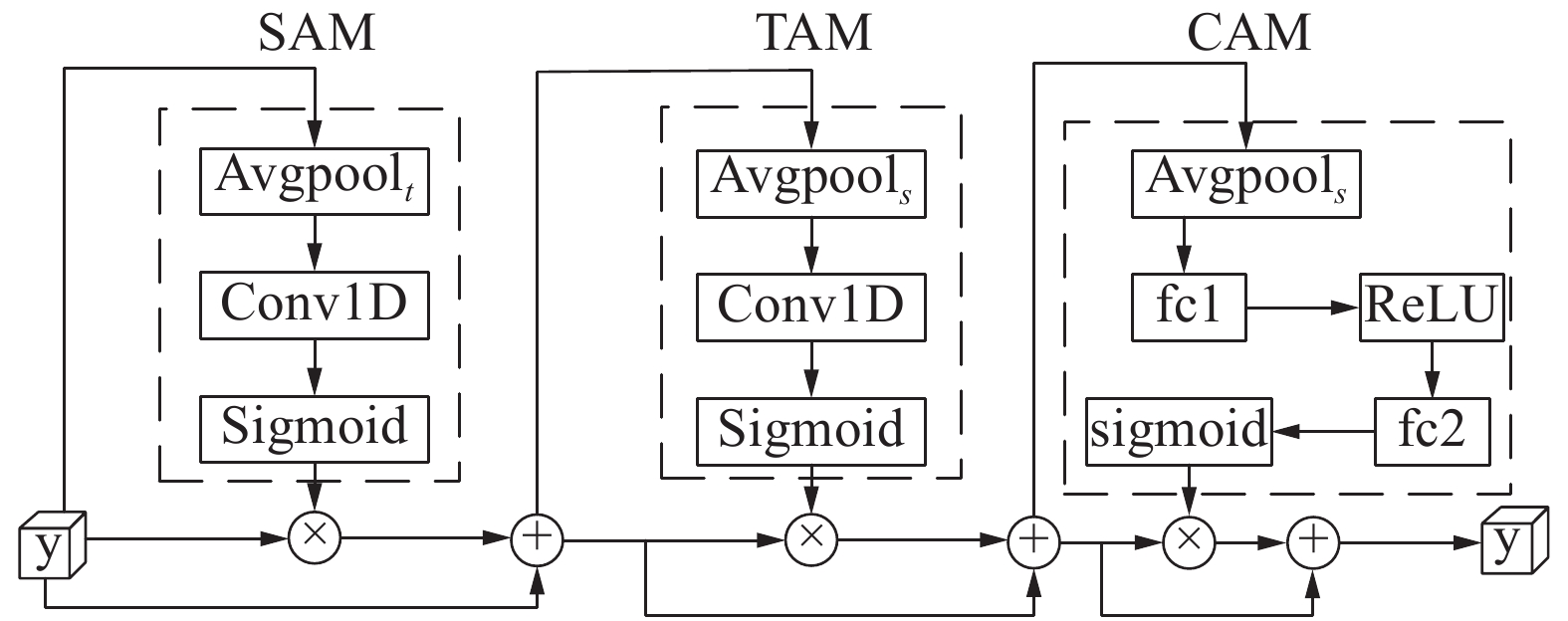 图 5 STC注意力机制融合模块下载:
全尺寸图片
图 5 STC注意力机制融合模块下载:
全尺寸图片
1.2.3 时序卷积网络TCN
时序卷积网络用于学习在连续的视频帧中关节点的局部变化特征,时序卷积网络采用与ST-GCN原文相同的实现方式,相比于普通的卷积需要多层卷积才能提取一段完整的视频帧时间特征,本文采用膨胀卷积,将卷积核大小设为
$9 \times 1$ ,通过更宽的卷积核,在不增加卷积层数量的情况下,采样更宽的时间特征。卷积核首先完成一个关键点在所有帧上的特征提取,再移动到下一个关键点进行时间序列特征提取,直到完成整个骨架上所有关键点的时间序列特征提取。再对输出进行批量归一化,以保持数据分布的稳定性,加速模型的收敛。如图6所示,一个TCN模块包含4个不同的子模块。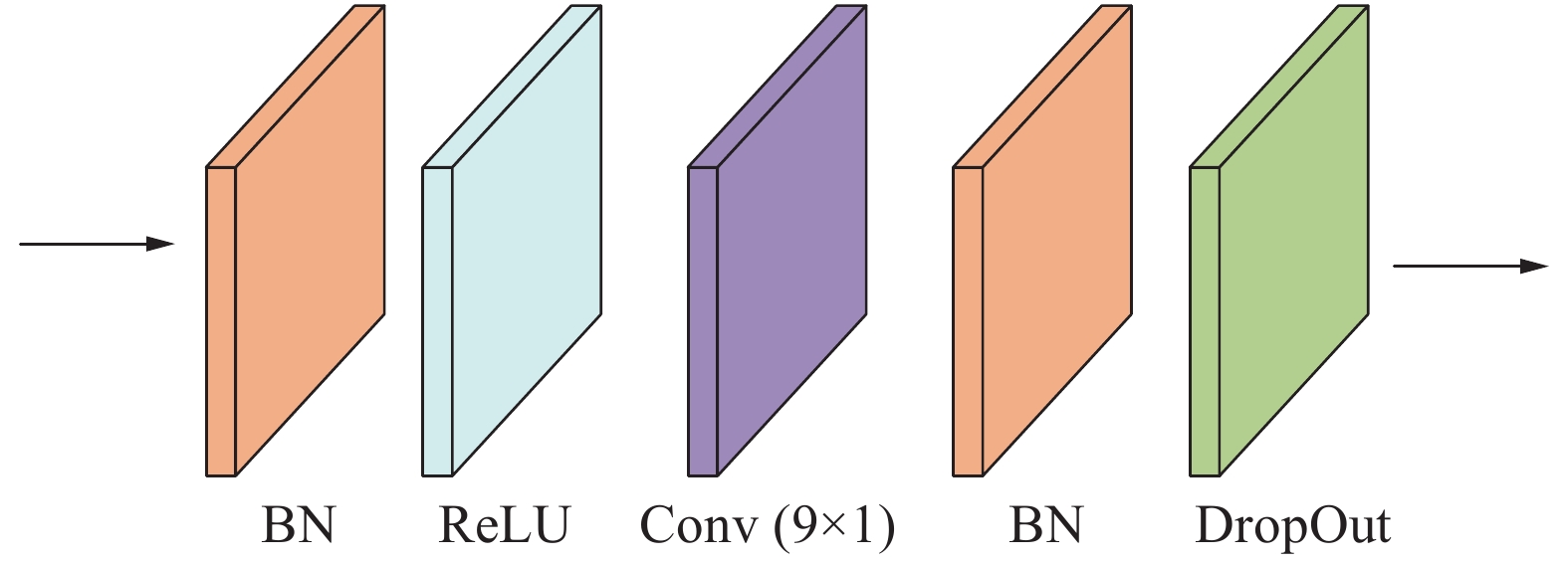 图 6 时序卷积网络下载:
全尺寸图片
图 6 时序卷积网络下载:
全尺寸图片
2. 网络性能对比实验
2.1 实验环境
本文所进行的所有实验都是基于Ubuntu18.04操作系统,硬件方面,GPU采用2块Nvidia RTX1080Ti,单块GPU显存大小为11 GB,最大功率250 W,CPU采用Intel Core I7-8700 K,主频最高可达3.7 GHz,运行内存大小为32 GB;软件方面,使用pytorch-1.6.1,CUDA版本为10.1。
2.2 数据集
本文将搭建的网络分别在公开数据集Kinetics-Skeleton[12]和花样滑冰数据集Figure Skating Dataset(FSD-30)进行训练和测试。
Kinetics-Skeleton人类行为数据集含有多达30×104个从YouTube下载剪辑的视频片段。其中动作的种类涵盖齐全,共包含400类人类动作,从日常的人类活动、体育场赛事场景到一些复杂的互动场景。该数据集只提供原始视频经剪辑过的视频片段,剪辑后的视频片段时长10 s左右。其中训练集包含24×104个片段,测试集包含2×104个片段。为评估本文算法的识别分类性能,评价指标采用数据集top-1和top-5分类精度协议进行评价。
Figure Skating Dataset数据集是北京智源人工智能研究院在2022北京冬奥会来临之际发布的,旨在解决目前行为识别数据集缺乏人体运动特性、深度学习正确率低问题,助力花样滑冰运动的普及与发展。相比于其他运动,在花样滑冰项目中,人体姿态以及运动轨迹更加复杂、细分动作类别多样,非常适合细粒度深度学习模型的研究[13]。FSD数据集中的视频是采集于2017–2018年的花样滑冰锦标赛,为保证数据样本规格的统一性,视频的帧率统一为30 f/s,图像大小为
$1\; 080 \times 720$ ppi。数据集部分样本如图7所示。本文使用FSD-10数据集进行训练和测试,来验证本文提出方法的有效性,该数据集包含了30种动作分类。 图 7 FSD数据集样本下载:
全尺寸图片
图 7 FSD数据集样本下载:
全尺寸图片
2.3 数据预处理
首先将视频分辨率大小调整为
$340 \times 256$ ,并将视频帧率统一转化为30 f/s,然后使用人体姿态估计算法OpenPose提取视频中的每一帧的人体骨架。视频帧中的关节坐标以及置信度用$(X, Y,C)$ 表示,每个人体包含18个关节坐标。采用张量$(3,T,18,M)$ 来表示1个视频剪辑的输出。其中3表示坐标以及置信度的3个通道;T=300表示视频的帧数,不足300帧的视频,在结尾将视频帧重复排列以填充到300帧;M表示视频中的人数,将骨架关键点数据保存成 .npy格式的数据集。图8是FSD-10数据集部分样本连续动作骨架数据可视化图。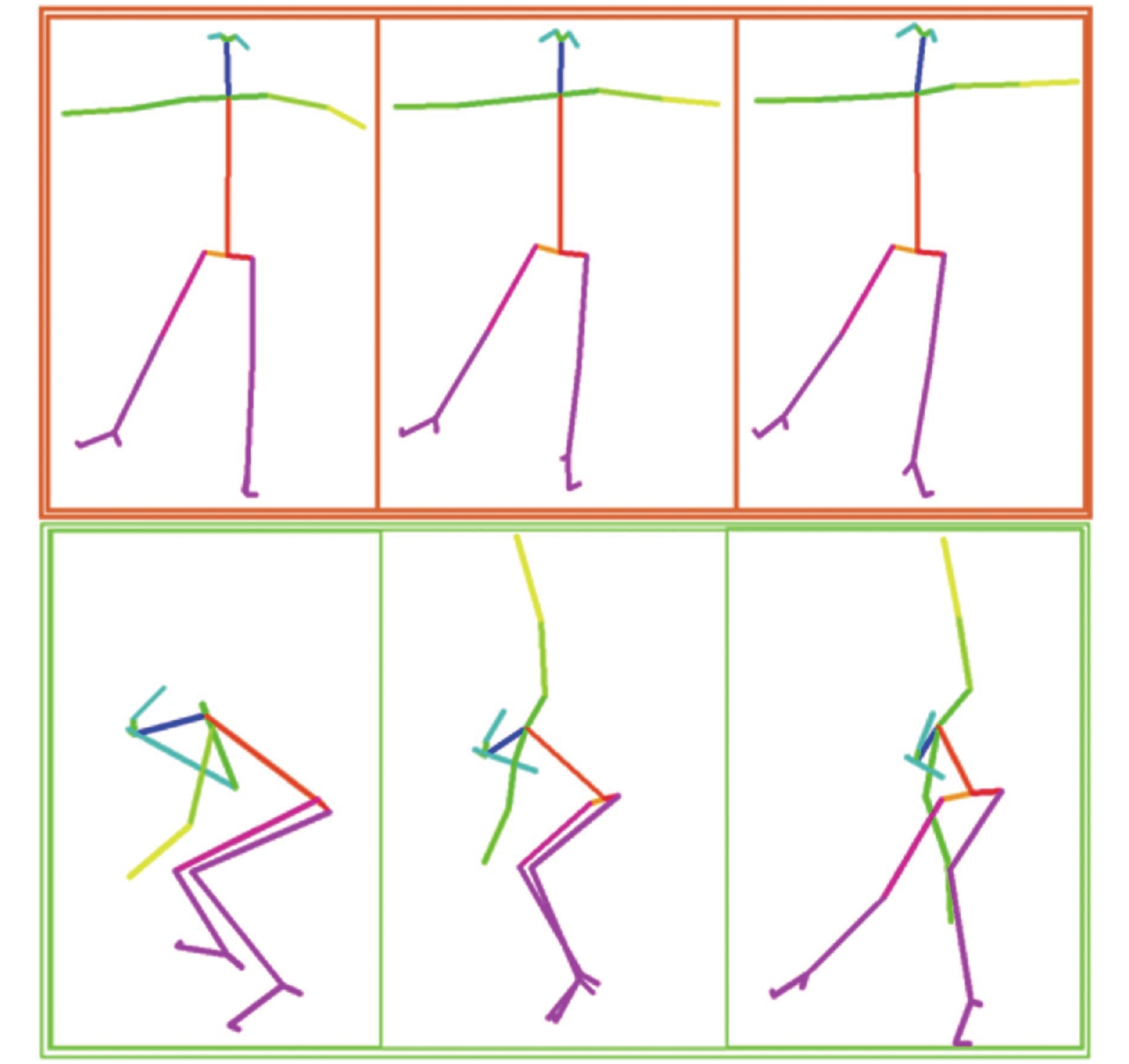 图 8 FSD-10骨架数据可视化图下载:
全尺寸图片
图 8 FSD-10骨架数据可视化图下载:
全尺寸图片
2.4 实验评估分析
2.4.1 Kinetics-Skeleton数据集实验
首先使用Kinetics-Skeleton数据集对本文提出的模型进行验证实验,训练50个epoch,初始学习率为0.1,在第10、20、30和40轮时设置学习率衰减,除以10。如图9所示,训练过程中损失曲线阶梯式下降并收敛。
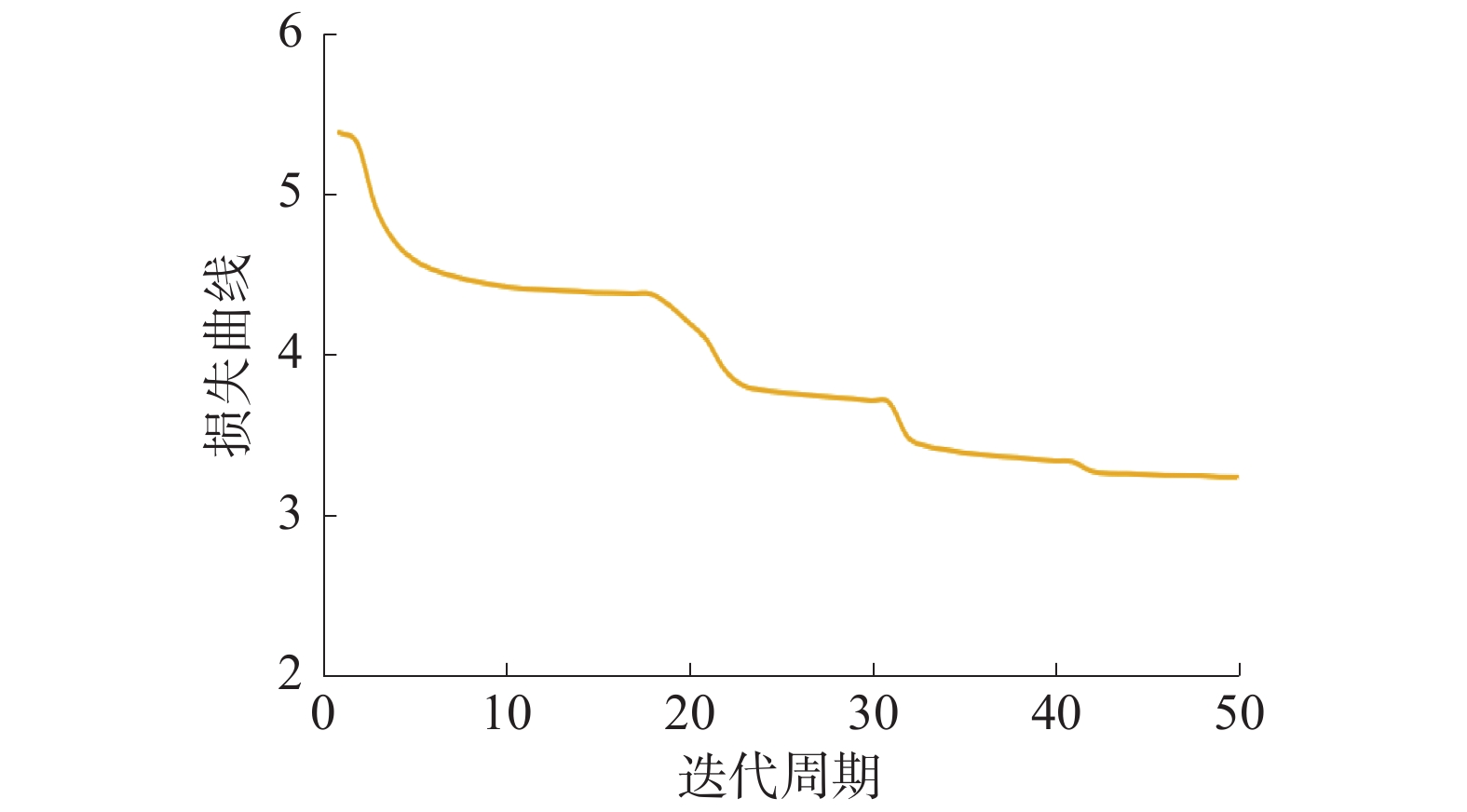 图 9 Kinetics-Skeleton损失变化曲线下载:
全尺寸图片
图 9 Kinetics-Skeleton损失变化曲线下载:
全尺寸图片
将本文算法实验结果与Feature Enc[14] 、Deep LSTM[15]、TCN和ST-GCN[16]进行对比。由表2 可知,根据Top-1和Top-5共2种评估协议,本文提出的SAT-GCN算法相比ST-GCN算法在Kinetics-Skeleton数据集上有了显著提升,2种评估协议的评价指标结果分别为32.1%和54.9%。
表 2 Kinetics-Skeleton数据集实验结果算法 Top-1/% Top-5/% Feature Enc 14.9 25.8 Deep-LSTM 16.4 35.3 TCN 20.3 40.0 ST-GCN 30.7 52.8 SAT-GCN 32.1 54.9 2.4.2 FSD-10数据集实验
训练时采用学习率的衰减使用余弦退火衰减策略,其衰减曲线如图10所示。优化器采用SGD,并添加动量参数,加快梯度的下降速度,加快网络学习。
 图 10 学习率衰减曲线下载:
全尺寸图片
图 10 学习率衰减曲线下载:
全尺寸图片
将数据集按照9∶1划分成训练集和测试集,使用训练集进行训练,并使用测试集对训练好的模型进行测试,分别训练和测试了改进前的ST-GCN以及本文改进的SAT-GCN网络,评价指标预测准确率A的计算方式为
$$ {{A}} = 100 \times \frac{{{{T}}}}{S} $$ 式中:A表示对于给定的预测数据集,模型预测正确的样本数与实际总样本数之比;T表示对于给定的测试样本数据集,模型预测正确的样本数量;S为给定的测试集样本总数。数据集样本总量为2922个,种类数目30类,训练模型的测试结果如表3所示,改进前的ST-GCN算法准确率为53.92%,即在验证集的所有样本中,30种动作测试正确的样本数占测试样本总量的53.92%;本文算法达到了62.71%,相比改进前的网络性能提升了8.79%。验证了本文多通道注意力融合模块的有效性。
表 3 FSD-10数据集结果算法 准确率/% ST-GCN 53.92 SAT-GCN 62.71 3. 结论
针对花样滑冰运动轨迹复杂、类型多样、普通人难以用肉眼区分、常规动作检测算法准确率低的问题,本文在时空图卷积ST-GCN网络的基础上加入多通道注意力机制融合模块,提出了基于SAT-GCN的花样滑冰选手动作检测算法。
1)本文使用OpenPose算法进行骨架数据的提取,再输入到网络中训练,克服复杂背景环境的干扰,提高网络的鲁棒性;采用图卷积进行空间骨架特征的提取;使用时序卷积网络提取关节点在连续的时间帧上的特征;加入多通道注意力机制融合模块分别从空间关节点、时间连续帧、以及合并通道3个方面实现模型对资源的合理分配,以提高对不同动作视频的特征提取能力。
2)本文首次将时空图卷积算法应用于花样滑冰动作检测,并通过对时空图卷积进行改进,使用公开人体行为数据集Kinetics-Skeleton和花样滑冰数据集FSD-10进行训练和测试,验证了本文算法的有效性,相比ST-GCN在模型的性能上提高了8.79%。
3)本文将骨骼点提取算法以及时空图卷积动作识别算法应用于花样滑冰运动,克服光线、高度等复杂环境背景的影响,对动作进行识别和捕捉,辅助裁判对细微动作进行打分,帮助普通观众进行动作判别,也有利于花样滑冰运动的推广和普及。同时,该算法也能适应于更多其他复杂环境下的人体行为识别,具有较高的实际应用价值。
-
图 1 SAT-GCNS网络整体结构
下载:
全尺寸图片
图 2 OpenPose关键点骨架模型
下载:
全尺寸图片
图 3 SAT-GCN-Block结构示意
下载:
全尺寸图片
图 4 图卷积的实现流程
下载:
全尺寸图片
图 5 STC注意力机制融合模块
下载:
全尺寸图片
图 6 时序卷积网络
下载:
全尺寸图片
图 7 FSD数据集样本
下载:
全尺寸图片
图 8 FSD-10骨架数据可视化图
下载:
全尺寸图片
图 9 Kinetics-Skeleton损失变化曲线
下载:
全尺寸图片
图 10 学习率衰减曲线
下载:
全尺寸图片
表 1 关键点编号
编号 名称 编号 名称 0 鼻 9 右膝 1 首 10 右足首 2 右肩 11 左腰 3 右肘 12 左膝 4 右手首 13 左足首 5 左肩 14 右目 6 左肘 15 左目 7 左手首 16 右耳 8 右腰 17 左耳 表 2 Kinetics-Skeleton数据集实验结果
算法 Top-1/% Top-5/% Feature Enc 14.9 25.8 Deep-LSTM 16.4 35.3 TCN 20.3 40.0 ST-GCN 30.7 52.8 SAT-GCN 32.1 54.9 表 3 FSD-10数据集结果
算法 准确率/% ST-GCN 53.92 SAT-GCN 62.71 -
[1] 於鹏, 张铭, 李海兵. 基于深度卷积神经网络的辅助虚拟训练动作检测系统设计[J]. 现代电子技术, 2022, 45(4): 161−164. doi: 10.16652/j.issn.1004-373x.2022.04.030 [2] 刘文龙, 陈春雨. 基于多特征融合及Transformer的人体跌倒动作检测算法[J]. 应用科技, 2022, 49(2): 49-54, 62. [3] 李自强, 王正勇, 陈洪刚, 等. 基于外观和动作特征双预测模型的视频异常行为检测[J]. 计算机应用, 2021, 41(10): 2997−3003. doi: 10.11772/j.issn.1001-9081.2020121906 [4] 刘志鹏. 利用深度卷积神经网络的体育教学训练错误动作检测[J]. 三明学院学报, 2021, 38(3): 8−14. doi: 10.14098/j.cn35-1288/z.2021.03.002 [5] 刘唐波, 杨锐, 王文伟, 等. 基于姿态估计的驾驶员手部动作检测方法研究[J]. 信号处理, 2019, 35(12): 2062−2069. doi: 10.16798/j.issn.1003-0530.2019.12.015 [6] 闫晓炜, 张朝晖, 赵小燕, 等. 用于课堂教学评估的教师肢体动作检测[J]. 中国教育信息化, 2019(16): 88−91. [7] 周越, 陈琪然. OpenPose算法人体姿态识别应用研究[J]. 电子世界, 2021(18): 21−22. doi: 10.19353/j.cnki.dzsj.2021.18.010 [8] 王健宗, 孔令炜, 黄章成, 等. 图神经网络综述[J]. 计算机工程, 2021, 47(4): 1−12. doi: 10.19678/j.issn.1000-3428.0058382 [9] 丁雪琴, 朱轶昇, 朱浩华, 等. 基于时空异构双流卷积网络的行为识别[J]. 计算机应用与软件, 2022, 39(3): 154−158. doi: 10.3969/j.issn.1000-386x.2022.03.025 [10] 付云虎, 钱慧芳, 易剑平, 等. 基于多模型融合的双人交互行为识别[J]. 现代电子技术, 2022, 45(6): 175−179. [11] 宋真东, 杨国超, 马玉鹏, 等. 基于注意力机制的多模态人体行为识别算法[J]计算机测量与控制, 2022, 30(2): 276-283. [12] JOÃO Carreira, ERIC Noland, Chloe Hillier, et al. A short note on the kinetics-700 human action dataset.[J]. CoRR, 2019: abs/1907.06987. [13] LIU Shenglan, LIU Xiang, HUANG Gao, et al. FSD-10: a fine-grained classification dataset for figure skating[J]. Neurocomputing, 2020, 413: 360−367. doi: 10.1016/j.neucom.2020.06.108 [14] ZHENG Fang, ZHANG Xiongwei, CAO Tieyong, et al. Spatial-temporal slowfast graph convolutional network for skeleton-based action recognition[J]. IET computer vision, 2021, 16(3): 205−217. [15] YU Lubin, Tian Lianfang, Du Qiliang, et al. Multi-stream adaptive spatial-temporal attention graph convolutional network for skeleton-based action recognition[J]. IET computer vision, 2021, 16(2): 143−158. [16] GUO Jianping, LIU Hong, LI Xi, et al. An attention enhanced spatial-temporal graph convolutional lstm network for action recognition in karate[J]. Applied sciences, 2021, 11(18): 1227−1236.

















































