 2018, Vol. 34
2018, Vol. 34


2. 江苏省地理信息资源开发与利用协同创新中心, 南京 210023
2. Jiangsu Center for Collaborative Innovation in Geographical Information Resource Development and Application, Nanjing 210023, China
2012年,美国地质调查局发布《美国地质调查局核心科学体系科学战略(2013~2023)》,提出了大数据背景下的地球科学研究新思维,强调树立大数据理念以提升地质调查数据的获取、挖掘和分析能力(杨宗喜等,2013)。地质大数据是指在地质调查、矿产勘查和科研工作中形成的各种成果,通常以文本、图表、声像、标本等多种数据形式存在。数据主要来源包括全国地质资料馆和各级地质图书馆、全国矿产资源评价资料、中国地质调查数据库和相关地学文献数据库(朱月琴等,2015)。近年来,我国依托地质调查“九大计划、五十个工程”建立了专业齐全、分布合理的国家地质数据库体系,构建了由基础调查类、专题调查类、综合集类组成的多层次、全方位的地质资料信息服务产品体系(王翔等,2015),打造了覆盖全领域的地质大数据支撑平台,实现了地调局系统内的互联互通和信息共享(谭永杰,2016)。总体上来看,地质大数据平台建设技术日趋成熟,基本实现了结构化、半结构化、非结构化数据的高效存储、索引和全文检索,而地质大数据的深度挖掘和应用尚处于初步探索阶段(李超岭等,2015;周永章等,2017)。因此,迫切需要引入先进的人工智能技术,解决地质大数据的信息整合、数据挖掘和知识服务等关键问题,形成地质对象、现象和规律的智能化“重建、模拟、预测”(黄少芳和刘晓鸿,2015;于萍萍等,2015;张旗和周永章,2017)。
文本数据挖掘是指从大量文本数据中抽取事先未知的、可理解的、有潜在实用价值的模式或者知识的过程。随着自然语言处理、信息抽取、机器学习技术的不断发展,文本数据挖掘已经从实验性阶段进入到实用化阶段。近年来,文本数据挖掘在面向自然语言的时空数据获取方面取得了突破性进展。具体体现在三个方面:一是制定地理实体特征的标注规范,构建多语种、大规模的标注语料库,解决文本中非结构化、非显式时空信息的规范化表达问题(Mani et al., 2010;张雪英等, 2012a, b;张春菊,2013);二是针对地理实体、时间、空间关系和属性等要素的语言描述特点,构建规则模型和机器学习模型(比如常用的条件随机场、支持向量机和隐马尔可夫模型等),解决文本中时空和属性数据的结构化抽取问题(Egenhofer and Shariff, 1998;Shariff et al., 1998;周俊生等,2006;蒋文明,2010;刘臻熙,2010;Hall et al., 2011;张春菊,2013);三是构建多层次的空间语义计算模型和时空匹配模型,实现文本中时空数据的定量化、空间化和可视化(蒋文明,2010;张春菊,2013)。地质大数据中包括海量的非结构化或半结构化的文本数据,以模糊的、定性的、不确定性的自然语言进行描述。与结构化的数据库相比,地质文本数据的丰富性和普及性具有显著优势。因此,文本数据挖掘有望突破数据量和认知模式的限制,更加全面地揭示文本中隐含的时空、属性和相关关系等地质信息(吴冲龙等,2016)。
在地质信息表达中,地质体通常是指地壳内占有一定的空间、有其固有成分并可以与周围物质相区别的地质作用产物,是人们观察和研究的具有一定体积的天然岩石单元。这些客观存在的地质体构成了地质领域一个个不同类型的地质实体,代表地壳内不能再划分为同种类型的现象。地质文本是对一定区域范围内地质条件及地质事件的记录,其中包含大量地质实体且实体类型多样。然而,无论是对地质状况的描述、地质变化的说明还是地质灾害的统计,本质上都是对地质实体、相关附属信息及其之间关系的表达。可以看出,地质实体是地质文本中的核心要素,其它属性和关系的描述都以地质实体为基础。同时,伴随着传感器、测绘、定位等技术手段的不断发展,文本中对于地质实体的内容描述更加丰富、时空刻画更加精细、更新频率更加迅速。在这种情况下,地质实体是文本中相关地质知识的主要体现,对于地质实体的识别有利于对于地质文本的深度挖掘。因此,地质实体识别不仅能够有效辨别文本中的基本信息单位,帮助正确理解文本内容,而且基于提炼出的地质知识,还能为广义文本数据挖掘中的信息抽取、信息检索、机器翻译、文摘生成等一系列工作提供全面支持(何炎祥等,2015)。
目前机器学习是文本命名实体识别的重要方法之一,该方法依靠对人工经验抽取样本特征的学习来获得实体识别模型(Borthwick,1999;Mayfield et al., 2003;McCallum and Li, 2003;Zhao,2004; Lake et al., 2015)。但传统机器学习工作的有效性在很大程度上依赖于训练数据表达的设计与输入特征的有效性,很难适应地质实体识别的实际需求。与传统机器学习方法相比,深度学习更强调通过逐层构建一个多层网络使得机器自动学习,在学习过程提取出不同水平、不同维度的数据特征。深度学习还试图自动完成数据表达与特征提取工作,提高不同抽象层次上对数据的解释能力(郑胤等,2014)。因而深度学习方法具有优异的深层次特征学习能力,对于类型多样、结构复杂的地质实体信息识别表现出巨大潜力。深度学习方法中常见的网络模型主要包括三类,分别是:前馈深度网络,如多层感知机(multi-layer perceptrons,MLP)、卷积神经网络(convolutional neural networks,CNN)等;反馈深度网络,如反卷积网络(deconvolutional networks,DN)、层次稀疏编码网络(hierarchical sparse coding,HSC);双向深度网络,如深度玻尔兹曼机(deep Boltzmann machines,DBM)、深度信念网络(deep belief networks,DBN)、栈式自编码器(stacked auto-encoders,SAE)。与其它适用于自然语言处理的深度学习模型相比,卷积神经网络由于其监督学习的方式需要大规模标注预料用于模型训练。堆叠去噪自动编码器的构成要素去噪自动编码器(Denoising Auto-encoders, DAE),本身不适用于拟合多维复杂函数(刘帅师等,2016)。在地质实体类型众多、文本描述复杂、且当前地质领域语料资源相对匮乏的状况下,本文选取多种特性组合更加灵活且易于拓展的深度信念网络(DBN)作为地质实体识别训练模型。深度信念网络的训练需要有相关标注语料作为基础,为保证人工标注文本信息时的标准统一,制定地质实体标注规范是必不可少的。本文从文本数据中地质实体信息的描述特点入手,制定面向自然语言的地质实体信息标注规范,并借鉴深度学习方法构建地质实体信息要素识别模型,从前期原始数据标注到后期文本信息抽取提出完整的地质实体识别方法。
1 文本中地质实体信息的规范化表达 1.1 地质实体信息的要素分类体系地质实体信息描述了实体对象的特定属性及发展状态,是对其包含自然属性与人文属性的定性或定量化表达。地质实体信息中包含了基本概念、空间分布、属性信息及其相互关系的表达,其要素组成可以按照对象、特征和关系三个层次进行划分(见表 1)。
|
|
表 1 地质实体信息的要素分类体系 Table 1 Element classification system of geological entity information |
标注体系用于对文本中特定信息的语言结构(比如词汇、句法和语义等)进行分析,并建立描述它们的元数据。因此,文本中地质实体信息描述将以体名称为关联核心,按照从“单要素-多要素”、“简单-复杂”和引用次序关系,制定地质实体信息的标注框架,以规范各个要素及其相互关系的信息特征(见图 1)。

|
图 1 地质实体信息的标注框架 Fig. 1 Basic framework of geological entity information annotation |
GATE是一个开源的自然语言处理软件,可接受XSD格式的Schema文件,使用户按照一定标注框架对文本进行标注,经过GATE处理的语料可统一存储为XML格式。因此,地质语料库利用GATE平台进行预处理和标注,并将标注完成后的语料统一存储为XML格式(见图 2)。标注过程中,按照标注规范中要素的先后顺序依次进行标注。图 1中[1]、[2]、[3]、[4]表示要素标注的先后顺序。由于人类空间认知的差异和自然语言的语义模糊性,不同标注者对同一表达语句的理解会存在歧义。为确保标注语料库的质量和对领域知识的覆盖度,需要对标注数据进行交叉检验和统计分析(张雪英等, 2012a, b)。

|
图 2 地质实体信息标注结果XML样例 Fig. 2 XML example of geological entity information annotation results |
深度学习利用含有多个隐含层的网络结构和标注训练数据,能够学习获得高维度、深层次的特征,使得分类和预测更加容易,在文本数据挖掘领域具有显著优势(余凯等,2013)。深度信念网络模型(Deep Belief Network,DBN)是深度学习模型中的一个重要类型,是一种深层次多节点的网络结构,由一系列受限玻尔兹曼机(RBM)单元叠置组成。由于其善于挖掘自然语言中相互独立的语言特征,被广泛应用于文本分类、情感分类、词汇分析、篇章语义分析等研究(Liu,2010;Yan et al., 2015;Chaturvedi et al., 2016;Liu et al., 2016)。基于DBN的地质实体识别方法主要包括字符向量化、网络结构参数计算与字符概率阈值选择三个部分(见图 3)。

|
图 3 基于深度信念网络模型的地质实体识别流程 Fig. 3 Geological entity recognition process based on Deep Belief Network model |
为了对文本中蕴含的语言特征进行有效计算,需要原始数据中每个字符表示为由多个数值构成的二值化字符向量。字符向量维度是指一个字符向量表达的数值个数,用以衡量字符蕴含语义信息的丰富程度。通常情况下,维度过高将会占用大量的计算和存储资源,维度过低则会限制语言特征的表达。字符向量维度确定需考虑两方面因素:一是原始数据字符个数规模和字符向量维度的不同应用需求,能够确定字符向量维度的初步取值范围;二是字符向量维度与地质实体识别性能的相关关系,用于得到合理的字符向量维度。面向地质实体识别的字符向量维度参考取值范围约为100~200(Mnih and Hinton, 2008)。
2.2 网络结构参数计算网络结构是将输入数据进行语言特征解析的框架体系,直接影响着字符二元分类概率的计算结果。网络结构参数包括网络层次参数和网络层间迁移参数。其中,网络层次参数用于确定网络层数和每层节点数目,二者分别影响着数据特征解析的深度和粒度。在实际应用中,既可以根据经验进行参数定义,也可采用贪心算法对两者进行单变量分析(潘广源等,2015)。通常情况下,DBN模型性能与网络层数和每层节点数目存在正相关关系,并会表现出一定的收敛性(孙虹和陈俊杰,2014)。因此,分析两者与地质实体识别性能的变化趋势,利用变化趋势的收敛特征能够得到较优的取值。确定网络层间迁移参数则需要计算隐含层之间迁移参数和顶部隐含层的迁移参数,分别记为θi和μ。通常情况下,求解θi与μ会使用经典贪婪算法,计算过程分为逐层训练和反向调优两个部分(Tariyal et al., 2016)。在逐层训练中,将相邻两层可视为一个RBM结构,DBN模型即可视为叠置的RBMs。逐层训练采用逐层迭代方法,通过计算每一个输入层Vi概率分布P(vi|θi)的极大值,求解θi。在反向调优中,将顶部隐含层视为单层神经网络模型,底部的叠置RBMs视为有向图。反向调优采用BP算法,通过梯度下降方法计算每层参数传递的误差的最小值,从而确定整个模型的参数θi与μ
2.3 字符概率阈值选择字符概率阈值是判断一个字符是否属于地质实体名称组成部分的重要依据。字符概率阈值偏高会降低单个字符的识别数目,从而降低地质实体识别的召回率;相反则会降低地质实体识别的准确率。因此,字符概率阈值选择在极大程度上决定了地质实体识别性能。假设字符概率阈值用Δ表示,那么本文集合的地质实体识别概率可以用公式(1)进行表达。其中,D表示文本集合; ci表示每个字符;Ej表示每个地质实体;p(ci|Δ)表示第i个字符属于地质实体名称组成部分的概率。通常情况下,字符概率阈值Δ会转化为极大对数似然logp(ci|Δ)的估计,化简可得公式(2) (宗成庆,2008)。通过对Δ求偏导,利用离散值间隔采样方式进行梯度下降算法,即可得最佳字符概率阀值Δ。
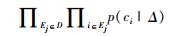
|
(1) |
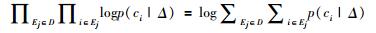
|
(2) |
实验数据来源于中国地质调查局全国地质资料馆网站(http://www.ngac.cn/DownloadCenter.aspx),以矿产资源地质调查报告为主(共计3万字),共标注1166个地质实体。
对于深度信念网络模型训练,实验借鉴相关文本实体识别的深度学习方法(Collobert and Weston, 2008;Huang et al., 2012),在参考的取值范围中设置训练参数(如表 2)。构建地质信息抽取的原型系统,实现地质实体信息识别等主要功能,如图 4所示。程序运行环境为Windows 10操作系统,处理器为Intel Core i7-6700 3.4 GHz,内存16GB。
|
|
表 2 深度信念网络模型训练参数设置 Table 2 Training parameter settings for Deep Belief Network model |

|
图 4 面向文本数据的地质信息抽取原型系统 Fig. 4 A prototype system for geological information extraction based on text data |
采用准确率(P)、召回率(R)和F度量值对信息识别性能进行评价,具体计算公式如公式(3)、公式(4)、公式(5)所示。其中,nij是指标注实体i和识别实体j之间相同的数,ni是指标注内容i的信息条数,nj是指模型识别内容j的信息条数,F(i, j)是指i和j之间的F度量值。本实验总F度量值计算采用公式(6),max函数扫描所有概率阈值设定下的检测结果,查找与i有最大F度量值的j。
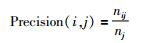
|
(3) |
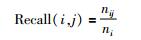
|
(4) |
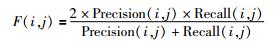
|
(5) |
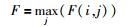
|
(6) |
实验结果表明,DBN模型的识别效果在P值、R值与F值等评价指标上都达到较好的效果,各指标基本都保持在90%以上(如表 3)。但是,模型的识别效果与模型层数增长并非正相关关系,在一定范围内识别效果随着层数增加而有所降低。同时,随着模型层数的递增,训练时间呈指数型增长,会对模型训练调试效率产生极大影响。从本次实验结果来看,在深度信念网络模型只有1层的情况下,地质实体识别也能达到较好效果。因此,实际应用中需要通过相关测试分析选择适合的DBN层数,保证模型在识别效果与训练时间上实现整体的性能最优。
|
|
表 3 实验结果评价指标统计 Table 3 Statistics of experimental evaluation indexes |
更为重要的是,在目前语料规模较小的情况下,本文方法较好适应了文本中地质实体识别的需求。自然界中地质实体类型多样,涉及信息要素类型众多。并且地质文本中大量存在的是复杂无结构数据,这也为地质实体识别制造了障碍。若采用其它深度学习方法,如卷积神经网络,由于其监督学习的方式,需要大量具有类标号的样本数据用于模型训练,以保证获得具有较高泛化能力的模型结果。而深度信念网络模型通过无监督贪婪逐层预训练加上有监督微调的方式,让机器自动地从训练数据中学习到表征这些样本的更加本质的特征,减小了标注语料资源规模对于模型训练的限制。此外,本文提出的方法同样适用于从其它地质类文本中识别相关地质信息。只需基于不同类型地质文本训练合适的深度信念网络模型,便可实现对不同类型地质文本中地质信息的识别,具有良好的移植性。
现有实验中仍有部分文本信息识别失败(表 4),通过分析可以发现主要原因有以下三点。首先,实验数据出现的部分地质实体名称或涉及的属性信息字符数过多,远远超出深度学习训练时训练窗口设置的参数(参数为5)大小,如“钙质长石石英粉砂岩”、“石英砂岩质中砾岩”、“含砾粗粒长石砂岩”等。由于在模型训练时受到窗口大小的限制,造成上下文特征空间中特征信息的缺失,从而影响模型识别效果。其次,DBN模型在对连续出现的、仅有标点符号分隔的地质实体识别时,常出现部分漏字状况。同样考虑到训练窗口的有限性,连续出现的多个地质实体实际上为词语的堆叠,并不包含常有的语义信息。加之模型自身的偶然性,不利于结果的精准识别。再次,部分地质实体信息在训练用文本中缺失或信息标注不够完整,模型在训练时缺乏相应的学习认知,这也会对准确率或召回率产生影响。对于目前导致识别错误的几类问题,可以通过增加规则模型和丰富地质实体标注语料库的方法解决。例如,提取地质实体信息描述时常用的特征词,通过相关规则赋予特征词更高的概率值,提升识别的准确性;搜集更为多源的地质文本,使得标注的地质实体信息更加全面完整,有利于深度信念网络模型的完善。
|
|
表 4 文本地质实体信息识别结果示例 Table 4 Examples of text geological entity information recognition results |
近年来地质工作方式向数字化、信息化、智能化的趋势发展,积累形成了海量的地质资料与数据。在地质行业进入“地质大数据”时代的背景下,应以大数据的思维理念,应用大数据技术,解决地质大数据中的有关问题,实现地质大数据价值的充分利用。地质大数据中涉及数据类型众多,其中地质文本数据在丰富性与普及性上较传统结构化数据库具有显著优势。伴随着地质大数据平台建设推进,对地质文本数据的深度挖掘提出了更高要求。本文提出了一种面向文本数据的地质实体识别方法,将深度学习理念应用到地质实体文本信息识别中,制定了面向自然语言的地质实体信息标注规范和语料库,并基于深度信念网络构建了地质实体信息识别模型。实验结果表明,深度信念网络模型可以在目前较小规模语料库的情况下,有效识别地质调查文本中包含的相关地质实体信息。在后续研究中,将进一步扩大标注语料库的数据规模,同时考虑将深度信念网络模型和规则模型进行集成,实现地质实体属性和关系的信息抽取。
Borthwick AE. 1999. A maximum entropy approach to named entity recognition. Ph. D. Dissertation. New York: New York University, 27-35
|
Chaturvedi I, Ong YS, Tsang IW, Welsch RE and Cambria E. 2016. Learning word dependencies in text by means of a deep recurrent belief network. Knowledge-Based Systems, 108: 144-154. DOI:10.1016/j.knosys.2016.07.019 |
Collobert R and Weston J. 2008. A unified architecture for natural language processing: Deep neural networks with multitask learning. In: Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 160-167, doi: 10.1145/1390156.1390177
|
Egenhofer MX and Shariff ARBM. 1998. Metric details for natural-language spatial relations. ACM Transactions on Information Systems, 16(4): 295-321. DOI:10.1145/291128.291129 |
Hall MM, Smart PD and Jones CB. 2011. Interpreting spatial language in image captions. Cognitive Processing, 12(1): 67-94. DOI:10.1007/s10339-010-0385-5 |
He YX, Luo CW and Hu BY. 2015. Geographic entity recognition method based on CRF model and rules combination. Computer Applications and Software, 32(1): 179-185. |
Huang EH, Socher R, Manning CD and Ng AY. 2012. Improving word representations via global context and multiple word prototypes. In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1. Jeju Island, Korea: ACM, 873-882
|
Huang SF and Liu XH. 2015. Informatization and services of geological archives based on big data. Resources & Industries, 17(6): 56-61. |
Jiang WM. 2010. Research on spatial orientation relation extraction method for Chinese text. Ph. D. Dissertation. Nanjing: Nanjing Normal University, 1-63 (in Chinese)
|
Lake BM, Salakhutdinov R and Tenenbaum JB. 2015. Human-level concept learning through probabilistic program induction. Science, 350(6266): 1332-1338. DOI:10.1126/science.aab3050 |
Li CL, Li JQ, Zhang HC, Gong AH and Wei DQ. 2015. Big data application architecture and key technologies of intelligent geological survey. Geological Bulletin of China, 34(7): 1288-1299. |
Liu HL, Li S, Jiang CF and Liu H. 2016. Sentiment analysis of Chinese micro blog based on DNN and ELM and vector space model. In: Cao JW, Mao KZ, Wu J and Lendasse A (eds. ). Proceedings of Extreme Learning Machines (ELM)-2015 Volume 2. Cham: Springer, 117-129
|
Liu SS, Cheng X, Guo WY and Chen Q. 2016. Progress report on new research in deep learning. CAAI Transactions on Intelligent Systems, 11(5): 567-577. |
Liu T. 2010. A novel text classification approach based on deep belief network. In: Proceedings of International Conference on Neural Information Processing. Guangzhou, China: Springer, 314-321
|
Liu ZX. 2010. Research on extraction of attribute of geographic entity from Chinese text. Master Degree Thesis. Nanjing: Nanjing Normal University, 1-65 (in Chinese with English summary)
|
Mani I, Doran C, Harris D, Hitzeman J, Quimby R, Richer J, Wellner B, Mardis S and Clancy S. 2010. Spatial ML:Annotation scheme, resources, and evaluation. Language Resources and Evaluation, 44(3): 263-280. |
Mayfield J, Mcnamee P and Piatko C. 2003. Named entity recognition using hundreds of thousands of features. In: Proceedings of the 7th Conference on Natural Language Learning at HLT-NAACL. Edmonton, Canada: ACM, 184-187
|
McCallum A and Li W. 2003. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In: Proceedings of the 7th Conference on Natural Language Learning at HLT-NAACL. Edmonton, Canada: ACM, 188-191
|
Mnih A and Hinton G. 2008. A scalable hierarchical distributed language model. In: Proceedings of the 21st International Conference on Neural Information Processing Systems. British Columbia, Canada: ACM, 1081-1088
|
Pan GY, Chai W and Qiao JF. 2015. Calculation for depth of deep belief network. Control and Decision, 30(2): 256-260. |
Shariff ARBM, Egenhofer MJ and Mark DM. 1998. Natural-language spatial relations between linear and areal objects:The topology and metric of English to language terms. International Journal of Geographical Information Science, 12(3): 215-246. |
Sun H and Chen JJ. 2014. Research on Chinese toponym recognition method with two-layer CRF and rules combination. Computer Applications and Software, 31(11): 175-177, 182. |
Tan YJ. 2016. Architecture and key issues of geological big data and information service project. Geomatics World, 23(1): 1-9. |
Tariyal S, Majumdar A, Singh R and Vatsa M. 2016. Greedy deep dictionary learning. arXiv: 1602. 00203
|
Wang X, Li JC, Chen H, Ru XL, Fan HM, Zheng X and Liang WJ. 2015. Big and geological data information services. Geological Bulletin of China, 34(7): 1309-1315. |
Wu CL, Liu G, Zhang XL, He ZW and Zhang ZT. 2016. Discussion on geological science big data and its applications. Science Bulletin, 61(16): 1797-1807. |
Yan Y, Yin XC, LI SJ, Yang MY and Hao HW. 2015. Learning document semantic representation with hybrid deep belief network. Computational Intelligence and Neuroscience, 2015: 650527. |
Yang ZX, Tang JR, Zhou P, Zhang T and Jin X. 2013. Earth science research in U. S. Geological Survey under the big data revolution. Geological Bulletin of China, 32(9): 1337-1343. |
Yu K, Jia L, Chen YQ and Xu W. 2013. Deep learning:Yesterday, today, and tomorrow. Journal of Computer Research and Development, 50(9): 1799-1804. |
Yu PP, Chen JP, Chai FS, Zheng X, Yu M and Xu B. 2015. Research on model-driven quantitative prediction and evaluation of mineral resources based on geological big data concept. Geological Bulletin of China, 34(7): 1333-1343. |
Zhang CJ. 2013. Interpretation of event spatio-temporal and attribute information in Chinese text. Ph. D. Dissertation. Nanjing: Nanjing Normal University, 1-157 (in Chinese with English summary)
|
Zhang Q and Zhou YZ. 2017. Big data will lead to a profound revolution in the field of geological science. Chinese Journal of Geology, 52(3): 637-648. |
Zhang XY, Zhu SN and Zhang CJ. 2012a. Annotation of geographical named entities in Chinese text. Acta Geodaetica et Cartographica Sinica, 41(1): 115-120. |
Zhang XY, Zhang CJ and Zhu SN. 2012b. Annotation for geographical spatial relations in Chinese text. Acta Geodaetica et Cartographica Sinica, 41(3): 468-474. |
Zhao SJ. 2004. Named entity recognition in biomedical texts using an HMM model. In: Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and its Applications. Geneva, Switzerland: ACM, 84-87
|
Zheng Y, Chen QQ and Zhang YJ. 2014. Deep learning and its new progress in object and behavior recognition. Journal of Image and Graphics, 19(2): 175-184. |
Zhou JS, Dai XY, Yin CY and Chen JJ. 2006. Automatic recognition of Chinese organization name based on cascaded conditional random fields. Acta Electronica Sinica, 34(5): 804-809. |
Zhou YZ, Li PX, Wang SG, Xiao F, Li JZ and Gao L. 2017. Research progress on big data and intelligent modelling of mineral deposits. Bulletin of Mineralogy, Petrology and Geochemisty, 36(2): 327-331, 344. |
Zhu YQ, Tan YJ, Zhang JT, Mao B, Shen J and Ji CF. 2015. A framework of Hadoop based geology big data fusion and mining technologies. Acta Geodaetica et Cartographica Sinica, 44(Supl.1): 152-159. |
Zong CQ. 2008. Statistical Natural Language Processing. Beijing: Tsinghua University Publisher: 1-163.
|
何炎祥, 罗楚威, 胡彬尧. 2015. 基于CRF和规则相结合的地理命名实体识别方法. 计算机应用与软件, 32(1): 179-185. |
黄少芳, 刘晓鸿. 2015. 基于大数据的地质资料档案信息化与服务. 资源与产业, 17(6): 56-61. |
蒋文明. 2010. 面向中文文本的空间方位关系抽取方法研究. 博士学位论文. 南京: 南京师范大学, 1-63
|
李超岭, 李健强, 张宏春, 龚爱华, 魏东琦. 2015. 智能地质调查大数据应用体系架构与关键技术. 地质通报, 34(7): 1288-1299. |
刘帅师, 程曦, 郭文燕, 陈奇. 2016. 深度学习方法研究新进展. 智能系统学报, 11(5): 567-577. |
刘臻熙. 2010. 中文文本中地理实体属性信息抽取方法研究. 硕士学位论文. 南京: 南京师范大学, 1-65
|
潘广源, 柴伟, 乔俊飞. 2015. DBN网络的深度确定方法. 控制与决策, 30(2): 256-260. |
孙虹, 陈俊杰. 2014. 双层CRF与规则相结合的中文地名识别方法研究. 计算机应用与软件, 31(11): 175-177, 182. DOI:10.3969/j.issn.1000-386x.2014.11.043 |
谭永杰. 2016. 地质大数据与信息服务工程技术框架. 地理信息世界, 23(1): 1-9. |
王翔, 李景朝, 陈辉, 茹湘兰, 范海明, 郑啸, 梁婉娟. 2015. 大数据与地质资料信息服务:需求、产品、技术、共享. 地质通报, 34(7): 1309-1315. |
吴冲龙, 刘刚, 张夏林, 何珍文, 张志庭. 2016. 地质科学大数据及其利用的若干问题探讨. 科学通报, 61(16): 1797-1807. |
杨宗喜, 唐金荣, 周平, 张涛, 金玺. 2013. 大数据时代下美国地质调查局的科学新观. 地质通报, 32(9): 1337-1343. |
余凯, 贾磊, 陈雨强, 徐伟. 2013. 深度学习的昨天、今天和明天. 计算机研究与发展, 50(9): 1799-1804. DOI:10.7544/issn1000-1239.2013.20131180 |
于萍萍, 陈建平, 柴福山, 郑啸, 于淼, 徐彬. 2015. 基于地质大数据理念的模型驱动矿产资源定量预测. 地质通报, 34(7): 1333-1343. |
张春菊. 2013. 中文文本中事件时空与属性信息解析方法研究. 博士学位论文. 南京: 南京师范大学, 1-157
|
张旗, 周永章. 2017. 大数据正在引发地球科学领域一场深刻的革命——《地质科学》2017年大数据专题代序. 地质科学, 52(3): 637-648. DOI:10.12017/dzkx.2017.041 |
张雪英, 朱少楠, 张春菊. 2012a. 中文文本的地理命名实体标注. 测绘学报, 41(1): 115-120. |
张雪英, 张春菊, 朱少楠. 2012b. 中文文本的地理空间关系标注. 测绘学报, 41(3): 468-474. |
郑胤, 陈权崎, 章毓晋. 2014. 深度学习及其在目标和行为识别中的新进展. 中国图象图形学报, 19(2): 175-184. |
周俊生, 戴新宇, 尹存燕, 陈家骏. 2006. 基于层叠条件随机场模型的中文机构名自动识别. 电子学报, 34(5): 804-809. |
周永章, 黎培兴, 王树功, 肖凡, 李景哲, 高乐. 2017. 矿床大数据及智能矿床模型研究背景与进展. 矿物岩石地球化学通报, 36(2): 327-331, 344. |
朱月琴, 谭永杰, 张建通, 毛波, 沈婕, 汲超飞. 2015. 基于Hadoop的地质大数据融合与挖掘技术框架. 测绘学报, 44(S1): 152-159. |
宗成庆. 2008. 统计自然语言处理. 北京: 清华大学出版社: 1-163.
|