 2018, Vol. 64
2018, Vol. 64
文章信息
- 宋勇, 蔡志平
- SONG Yong, CAI Zhiping
- 大数据环境下基于信息论的入侵检测数据归一化方法
- Normalized Method of Intrusion Detection Data Based on Information Theory in Big Data Environment
- 武汉大学学报(理学版), 2018, 64(2): 121-126
- Journal of Wuhan University(Natural Science Edition), 2018, 64(2): 121-126
- http://dx.doi.org/10.14188/j.1671-8836.2018.02.004
-
文章历史
- 收稿日期:2017-08-01



引用本文

|


2. 国防科技大学 计算机学院,湖南 长沙 410073
2. College of Computer, National University of Defense Technology, Changsha 410073, Hunan, China
网络和通信技术的快速发展和改进促进了互联网在电子商务、电子政务和新闻媒体等领域的广泛应用,并积累了海量的数据资源,使人们进入到大数据的时代.用系统加固和防火墙等静态防御技术已经无法解决多元化、复杂化的网络攻击,因此出现了通过检测和分析网络流量和系统日志等有关审计数据的入侵检测系统(intrusion detection system,IDS).IDS可以通过各种学习算法对网络数据进行误用检查和异常检测.这些学习算法在进行检测之前,一般要通过样本集的训练和学习得到能够对新的输入预测其结果的模型.在训练和学习过程中,为了提高学习算法的效率和模型检测的精度,一般都会对数据集进行预处理.数据集的预处理一般包括数据清理、特征提取、归一化处理等工作.归一化处理作为数据分析技术中的一项重要的预处理步骤,在机器学习领域具有重要的研究价值.数据归一化处理的目的是为了消除特征属性之间的量纲影响,以解决数据特征属性之间的可比性.
本文在对当前大数据环境下网络入侵检测数据归一化方法进行了分析和讨论,提出了一种以联合信息增益作为连续特征属性的分割评估方法,以类别信息的信息熵与分布情况作为取值或区间标准化依据的网络入侵检测数据归一化方法.
1 相关研究用于网络入侵检测学习算法的数据集,它的特征属性主要有两种类型:1)连续型.它表示特征属性的可测性,取值是不可数的,且这些值之间具有一定的线性顺序关系.例如特征属性:src_bytes、count、serror_rate.2)离散型.它的取值使用标识或几个离散值来表示,是可数的,且这些值之间没有明确的顺序关系.例如特征属性:protocol_type、service、flag.
1) 对连续特征属性归一化.文献[1]在计算它的平均绝对偏差的基础上提出了利用统计特性将原始样本的特征属性映射到一个标准的属性空间上,实现特征属性的归一化.文献[2]在计算出训练样本每个特征属性的均值和标准差的基础上,提出将特征属性的取值转换为这个取值偏离均值时标准差的倍数,把样本的属性值从它自己的取值空间映射到标准的取值空间.
2) 对离散特征属性归一化.一般根据其每个值在取值空间中出现的频率进行标准化.文献[3]分析了基于平均绝对偏差方式的连续特征属性离散化和基于标准差方式的连续特征属性离散化两者的优劣,指出前者比后者对孤立点具有更好的鲁棒性.文献[4],对于符号型的特征属性利用不同的数据值进行替换,例如:分别取tcp=1,udp=2,icmp=3;对于数值型特征属性,在进行标准差变换后,再进行极差转换归一到[0,1]区间.文献[5],对离散型的特征属性先进行二进制编码,然后再对这些二进制编码进行拆分,得到n个属性,这样转换的优点是可以确保所有记录的同一离散型特征值之间距离相等.文献[6]提出了几种常用的数值归一化方法,例如:标准化变换、极差变换、对数转换和反正切函数变换等,并且对这些归一化方法存在问题进行了分析.
除了上述对离散型特征属性和连续型特征属性进行分别处理的归一化方法外,还有一些文献将离散型特征属性和连续型特征属性采用同一方式进行归一化处理.例如:文献[7],将两种特征属性都转换成了对应的二进制,例如:数值型特征属性src_bytes转换成了16位二进制字符串,字符型特征属性protocol_type转换成了4位二进制字符串,这样可以保证算法初始种群的完整性与多样性.
以上文献提出的处理方法较好解决了特征属性的归一化问题,但是也存在如下问题:对特征属性进行归一化时,只考虑了特征属性取值本身的分布情况,而没有客观地评估它对类别信息或其他特征属性的作用,因此会影响归一化的结果,导致学习算法精度降低.因此本文的基于信息论的网络入侵检测数据归一化方法,从特征属性本身及其与关键特征属性两方面进行评估,以解决上述问题.
2 数据归一化方法对离散型和连续型特征属性分别进行归一化处理.对前者归一化,采用一定策略对离散型取值直接标准化而完成.对后者的归一化,由于连续型的特征属性的取值是不可数的,本文通过分割点选取和区间的标准化实现归一化处理.
2.1 问题模型及相关定义设网络入侵检测训练数据集为D,s=|D|表示其样本的容量,即样本个数.根据样本标记,设数据集中类别为C={C1, C2, …, Ck},数据集中样本标记集合F是类别C的一种组合,在本文中将入侵检测数据集类别简化为normal和anomaly两类,即所有不同的攻击行为均被标记为anomaly,因此|C|=2.设数据集的特征属性集合为T={t1, t2, …, tn},n=|T|表示其特征的个数.
定义1 连续型特征属性取值的有序序列OS.ti为数据集D特征属性T的一个连续型特征属性,它的取值V={vi1,vi2,…, vim|vi1≠vi2≠… ≠vim,1≤i≤n,1≤m≤s},对V进行排序得到OSi={osi1,osi2,…, osim|osi1 < osi2 < … < osim,osix∈V},OSi就是连续型特征属性ti取值的有序序列.
定义2 有序序列的分割点序列SP.SPi={sp1,sp2,…, spk|spx=(osip+osiq)/2,1≤x≤k,1≤p≤m-1,q=p+1},那么SPi就是OSi的一个分割点序列.
定义3 划分区间Interval.划分区间是序列SPi对序列OSi分割后形成的区域,其结果为(min, sp1],(sp1, sp2],…,(spk, max).
根据以上定义,归一化方法的基本思想是:如果特征属性的取值是连续型,那么首先需要采取定义2的方法获得OS的SP,其次利用这个SP对OS进行划分,然后根据划分形成若干个Interval,最后将各Interval标准化为[0,1]之间的数值;如果特征属性的取值是离散型,则可以直接采用2.3节提出的标准化公式(6)将离散值标准化为[0,1]之间的数值.
在信息论中,Shannon利用信息熵表示信号的信息量,根据这个理论,在连续特征属性的OS区间,对数据集类别进行信息量计算,得到如下定义:
定义4 特征属性tx的OSx区间关于类别的信息熵
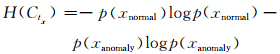
|
(1) |
(1) 式中p(xnormal)表示在tx的OSx区间中数据集正常类别出现的概率,p(xanomaly)表示在tx的OSx区间中数据集所有攻击类别出现的概率.该公式反映了在没有对特征属性tx的OSx区间进行划分之前,数据集类别的信息熵.
在对连续特征属性tx的OSx区间划分后,对数据集类别进行信息量计算,得到如下定义:
定义5 特征属性tx的OSx区间分割后关于类别的信息增益
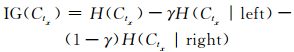
|
(2) |
(2) 式中,H(Ctx|left)和H(Ctx|right)分别表示连续特征属性tx的OSx区间被分割后,分割点左右两边区间对应数据集类别的信息熵,γ表示左边区间对应数据集类别相对整个区间对应数据集类别的占比.该公式反映了特征属性tx的OSx区间被分割之后,数据集类别确定性变化情况,该值越大,说明增加该分割点后,类别的不确定性降低得越多.
定义6 特征属性tx的OSx区间分割后特征属性tx与ty关于类别信息增益(联合信息增益)
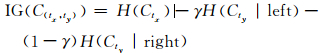
|
(3) |
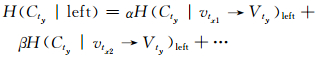
|
(4) |
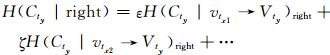
|
(5) |
(3) 式中,H(Ctx)表示对连续特征属性tx的OSx区间划分前,对应数据集类别信息熵.γ同(2)式.(4)式中,vtx1→Vty表示特征属性tx的第一个取值对应特征属性ty取值的集合.H(Cty|vtx1→Vty)left表示tx的OSx区间分割点左边第一个取值对应的特征属性ty取值集合关于数据集类别的信息熵.α表示tx的OSx区间分割点左边第一个取值对应的数据集类别相对tx的OSx左边区间对应的数据集类别的占比,β表示第二个取值对应的占比,并且α+β+…=1(表示所有左边的取值对应的占比).H(Cty|left)表示对连续特征属性tx的OSx区间划分后,分割点左边区间所有tx取值对应的特征属性ty取值关于数据集类别的信息熵.H(Cty|right)的意义与H(Cty|left)相同,其中ε和ζ的意义与α和β类似,只是对应tx的OSx右边区间.(3)式显示了特征属性tx的OSx区间被分割后,与相应的特征属性ty对数据集类别信息增益,该值越大,说明数据集类别越确定.
2.2 分割点选取网络入侵检测系统连续特征属性OS的分割是实现归一化的重要步骤,分割点选取的优劣将影响特征属性归一化后对学习算法的精确度和效率.如何划分数据集中连续特征属性的OS,得到最好的分割点是一个NP-hard[8]问题.本文中分割点的选取包括如下3个步骤:1)分割点预设;2)分割点评价与选择;3)分割终止条件.
2.2.1 分割点预设分割是对连续特征属性的OS设置的断点,包括断点的位置和断点的数量.关于断点的位置设置,文献[9]中提出了取vi值或计算(vi+vi+1)/2值的方法;文献[10]中提出了根据Fayyad原理,在连续属性分界点处设置几个分割点的方法.考虑到网络入侵检测学习算法中训练数据集小样本问题,数据集样本远远少于真实网络数据,本文采用文献[9]中的断点设置方法,具体见定义2.根据定义2,可以得到断点的数量为m-1个.
2.2.2 分割点评价与选择通过分割点预设可以得到特征属性的OS中的m-1个候选分割点,下一步工作是对m-1个候选分割点进行评估,以便从m-1个候选分割点中选择出最优分割点.常用的评估方法有卡方统计量法[11]、信息增益法[10]、训练样本集出错率法等.本文设计的评估方法基于联合信息增益的方法,具体设计思想如下:利用(3)式计算所有候选分割点的联合信息增益,并从中选择联合信息增益最大的分割点,得到最优分割点.这种方法与其他信息增益方法不同点在于,它不仅考虑到了连续特征属性自身对数据集类别信息的增益,还考虑到了它与其他特征属性共同对数据集类别的信息增益.这样考虑的原因是一些机器算法在进行学习和检测过程中,往往是多个特征属性共同计算的结果,所以在对特征属性进行归一化时,如果同时考虑特征属性之间的相互作用,将有助于提高归一化的质量.
2.2.3 分割终止条件通过第一次最优分割点选取后,连续特征属性的OS区间被划分为两个部分,再分别根据第一次的搜索策略,在这两个区间中分别寻找它们的联合信息增益最大分割点,得到两个区间的最优分割点,依此递归直到满足某个终止条件.常用的分割终止条件有最小描述长度原则[12]、互信息理论[13]、小于一个阈值、区间的分割个数大于阈值等.本文中采用联合信息增益小于某个预先给定的阈值和区间分割个数大于某个阈值为终止分割条件.由于数据集中连续特征属性的OS范围不一样,所以预先给定的阈值和区间划分个数也不一样.一般情况下,预先给定的阈值初始设置为第一次最大联合信息增益的1/10,区间划分个数设置为区间取值个数的1/2(在真实网络数据中,可以用某值±Δx区间替代某值).在本文的实验当中,根据学习算法的准确程度,适当的调整了这两个值.
2.3 标准化针对网络入侵检测数据的两类特征属性分别进行标准化.离散特征属性某离散值的标准化公式如下所示:
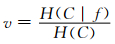
|
(6) |
(6) 式中,f表示离散特征属性的某一离散值;H(C)表示数据集类别的信息熵;H(C|f)表示某一个离散特征属性的离散值为f时,数据集类别的条件熵;根据信息熵的性质,可知H(C)>H(C|f),所以离散特征属性的离散值f标准化后的v值,其范围在[0,1]之间.这种标准化方法的优势是在将离散化的标识符数据转换成[0,1]之间的数值时,包含了类别信息.
连续特征属性的标准化过程是先通过分割点选取得到分割点后,再按下式对区间进行转换:
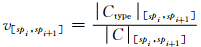
|
(7) |
(7) 式中C[spi, spi+1]表示区间[spi, spi+1]中数据集类别的总数;Ctype|[spi, spi+1]表示区间[spi, spi+1]数据集正常类别或者异常类别的数量;v[spi, spi+1]的取值范围在[0,1]之间.
2.4 算法描述综合上面的分割点选取和取值或区间的标准化讨论,具体算法描述如下:
Step 1 关键特征属性选取.关键特征属性是数据集中与类别相关程度最高的属性,它对学习算法的精度起关键性作用,因此本文选取关键特征属性作为其他特征属性进行联合信息增益计算时的特征属性ty.关键特征属性选择方法为:max{MI(t1; C), MI(t2; C),…,MI(tn; C)},MI是特征属性与类别的互信息;
Step 2 输入某一特征属性,判断特征属的类型,如果是离散型特征属性,利用(6)式计算该特征属性所有离散值的标准化结果,并跳转到Step 7;如果是连续型特征属性,则进行下一步;
Step 3 获得连续型特征属性的OS;
Step 4 根据前面讨论的分割点预设方法预设分割点,并利用(3)式对预设分割点评估,选择出最优分割点,得到左右两个区间;
Step 5 判断是否满足终止条件,如果不满足终止条件,则分别对左右区间重复Step 4;如果满足终止条件,则进行下一步;
Step 6 根据上一步分割得到的分割点输出划分区间,然后利用(7)式计算各区间标准化后的值,得到该连续型特征属性的归一化结果;
Step 7 判断其他特征属性是否完成归一化处理,若没有,则重复Step 2,否则进行下一步;
Step 8 输出所有连续型特征属性的归一化处理结果.
3 实验结果与分析为了验证本文方法的有效性,实验以入侵检测数据集NSL-KDD[14]为评测数据,用本文的方法和文献[1, 2]方法分别进行归一化处理,都采用SVM算法对处理的数据进行分类检测,通过时间、检测率(DR=被检测出来的异常样本数/异常样本总数)和误报率(FPR=被误检测出来的样本数/总样本数)3个指标衡量3种归一化方法对SVM算法精度的影响.
3.1 实验数据本文采用的NSL-KDD数据集是一种新的网络入侵检测实验数据集,它在KDD’99数据集基础上进行了改进,去掉大量冗余记录.整个原始数据集包括训练集和测试集,其中训练集有125 973条记录,测试集有22 545条记录,所有的记录都由3个字符型属性和38个数字型属性组成.分析该数据集,可以发现它共包含了22种攻击方法,这些攻击方法分为4个类型:DoS、R2L、U2R和Probe.
由于原始训练集过于庞大,为了提高实验的效率,又保证训练数据不失真,因此在实验前对原始训练集进行合理精简.考虑到在真实网络中,如果发生DoS和Probe类型攻击,正常数据流量和攻击数据流量在数量上相差不大,因此在精简训练集中正常记录和DoS类型攻击记录混合比为5:3,正常记录和Probe类型攻击记录混合比为5:1;如果发生R2L和U2R类型攻击,正常数据流量比攻击数据流量在数量上大很多,因此在精简训练集中正常记录和R2L类型攻击记录混合比为100:1,正常记录和U2R类型攻击记录混合比为1 000:1.通过上述方式从原始训练集中进行的抽取,最终形成了22 857条记录的实验训练集.实验测试数据使用NSL-KDD的测试集,其中正常记录9 712条,异常记录12 833条.
3.2 实验设置与环境支持向量机(SVM)检测技术是一种异常检测技术,目标是寻找一个最优的分类超平面,将样本正确地划分为正常和异常两类,因此实验采用SVM作为归一化处理结果的检测算法.本文利用编写的归一化处理程序和基于matlab的SVM工具箱进行实验,SVM核函数使用径向基函数:exp(-γ‖x-xi‖2),r=0.49, 惩罚因子C=110.
实验环境为CPU:Inter Core i7 2.50 GHz,内存:8.00 GB,操作系统:Windows 8 64位.
3.3 实验步骤与结果分析本实验分为三个阶段:第一阶段数据归一化处理,即分别利用本文的方法、文献[1]和文献[2]对训练数据进行归一化处理;第二阶段训练,即将3份归一化处理后的数据集分别输入SVM算法中进行训练得3个分类模型;第三阶段检测,用第二阶段训练好的分类模型对测试数据进行检测.通过上述三个阶段的工作,得到实验结果如表 1和表 2.
从表 1中可以得出,虽然本文的归一化方法所需要的时间比其他两个方法都要长,但是在检测时间相差不大的情况下,训练时间明显的缩短.说明本文的归一化方法使得训练模型得到更快的收敛.
3种归一化方法处理的结果通过SVM算法训练得到分类模型,使用分类模型对测试集进行验证.表 2对比结果表明,本文归一化方法的结果相对其他两个方法使得SVM算法得到了更高的检测率和更低的误报率,验证了本文归一化方法是有效的和优越的.
4 结论归一化处理是网络入侵检测算法数据预处理中的一个重要环节,它的优劣决定了算法检测的精确度.本文以信息论为理论依据,提出了一种网络入侵检测数据归一化处理方法,它克服了其他网络入侵检测算法归一化处理方法存在的一些缺陷.在特征属性归一化时,区间或取值的标准化本文采用定值的方式,可能会导致训练模型过快的收敛,因此如何根据特征属性划分的区间或取值所在的环境动态的进行标准化,将是下一步的研究工作[15].
| [1] |
肖立中, 邵志清, 马汉华, 等. 网络入侵检测中的自动决定聚类数算法[J]. 软件学报, 2008, 19(8): 2140-2148. XIAO L Z, SHAO Z Q, MA H H, et al. An algorithm for automatic clustering number determination in networks intrusion detection[J]. Journal of Software, 2008, 19(8): 2140-2148. DOI:10.3724/SP.J.1001.2008.02140(Ch) |
| [2] |
李洋, 方滨兴, 郭莉, 等. 基于主动学习和TCM-KNN方法的有指导入侵检测技术[J]. 计算机学报, 2007, 30(8): 1464-1473. LI Y, FANG B X, GUO L, et al. Supervised intrusion detection based on active learning and TCM-KNN algorithm[J]. Chinese Journal of Computers, 2007, 30(8): 1464-1473. DOI:10.3321/j.issn:0254-4164.2007.08.029(Ch) |
| [3] |
刘珊珊, 谢晓尧, 景凤宣, 等. 基于PCA的PSO-BP入侵检测研究[J]. 计算机应用研究, 2016, 33(9): 2795-2798. LIU S S, XIE X Y, JING F X, et al. Research on network intrusion detection based on PCA PSO-BP[J]. Application Research of Computers, 2016, 33(9): 2795-2798. DOI:10.3969/j.issn.1001-3695.2016.09.054(Ch) |
| [4] |
钱燕燕, 李永忠, 余西亚. 基于多标记与半监督学习的入侵检测方法研究[J]. 计算机科学, 2015, 42(2): 134-136. QIAN Y Y, LI Y Z, YU X Y. Intrusion detection method based on multi-label and semi-supervised learning[J]. Computer Science, 2015, 42(2): 134-136. DOI:10.11896/j.issn.1002-137X.2015.2.029(Ch) |
| [5] |
罗敏, 王丽娜, 张焕国. 基于无监督聚类的入侵检测方法[J]. 电子学报, 2003, 31(11): 1713-1716. LUO M, WANG L N, ZHANG H G. An unsupervised clustering-based intrusion detection method[J]. Acta Electronica Sinica, 2003, 31(11): 1713-1716. DOI:10.3321/j.issn:0372-2112.2003.11.028(Ch) |
| [6] |
梁碧珍, 陆月然, 杨旭光. 一种基于相对距离竞争激活的网络入侵检测算法[J]. 计算机工程与科学, 2011, 33(9): 13-18. LIANG B Z, LU Y R, YANG X G. A network intrusion detection algorithm based on relative distance competitive activation[J]. Computer Engineering & Science, 2011, 33(9): 13-18. DOI:10.3969/j.issn.1007-130X.2011.09.003(Ch) |
| [7] |
魏明军, 王月月, 金建国. 一种改进免疫算法的入侵检测设计[J]. 西安电子科技大学学报, 2016, 43(2): 126-131. WEI M J, WANG Y Y, JIN J G. Intrusion detection design of the improved immune algorithm[J]. Journal of Xidian University, 2016, 43(2): 126-131. DOI:10.3969/j.issn.1001-2400.2016.02.022(Ch) |
| [8] |
YOON M K, MOHAN S, CHOI J, et al. Learning execution contexts from system call distributions for intrusion detection in embedded systems[J]. Computer Science, 2015, 42(1): 349-355. |
| [9] |
张逸群. 对决策树连续值找分割点的算法的改进[J]. 计算机光盘软件与应用, 2013(23): 116-117. ZHANG Y Q. The Improvement of the algorithm for determining the splitting point of continuous decision tree[J]. Computer CD Software and Applications, 2013(23): 116-117. |
| [10] |
姚亚夫, 邢留涛. 决策树C4.5连续属性分割阈值算法改进及其应用[J]. 中南大学学报(自然科学版), 2011, 42(12): 3772-3776. YAO Y F, XING L T. Improvement of C4.5 decision tree continuous attributes segmentation threshold algorithm and its application[J]. Journal of Central South University(Science and Technology), 2011, 42(12): 3772-3776. |
| [11] |
张辉宜, 谢业名. 一种基于概率的卡方特征选择方法[J]. 计算机工程, 2016, 42(8): 194-198. ZHANG H Y, XIE Y M. A method of CHI-square feature selection based on probability[J]. Computer Engineering, 2016, 42(8): 194-198. DOI:10.3969/j.issn.1000-3428.2016.08.035(Ch) |
| [12] |
黄东. Bad:基于最小描述长度的均衡离散化方法[J]. 计算机工程与科学, 2011, 33(12): 130-135. HUANG D. Bad:A balanced discretization algorithm based on the minimum description length[J]. Computer Engineering and Science, 2011, 33(12): 130-135. DOI:10.3969/j.issn.1007-130X.2011.12.024(Ch) |
| [13] |
CHEN T, HONG Z. A novel feature gene selection method based on neighborhood mutual information[J]. International Journal of Hybrid Information Technology, 2015, 7(8): 277-292. DOI:10.14257/ijhit.2015.8.7.26 |
| [14] |
TAVALLAEE M, BAGHERI E, LU W, et al. A detailed analysis of the KDD CUP 99 data set[C]// IEEE International Conference on Computational Intelligence for Security and Defense Applications. New York: IEEE Press, 2009: 53-58.
|
| [15] |
CAI Z P, WANG Z J, ZHEN G K, et al. A distributed TCAM coprocessor architecture for integrated longest prefix matching, policy filtering, and content filtering[J]. IEEE Trans Computers, 2013, 62(3): 417-427. DOI:10.1109/TC.2011.255 |