 2017, Vol. 63
2017, Vol. 63
文章信息
- 王鹏, 方志军, 赵晓丽, 黄勃, HwangJenq-Neng
- WANG Peng, FANG Zhijun, ZHAO Xiaoli, HUANG Bo, Hwang Jenq-Neng
- 基于深度学习的人体图像分割算法
- Human Segmentation Based on Deep Learning
- 武汉大学学报(理学版), 2017, 63(5): 466-470
- Journal of Wuhan University(Natural Science Edition), 2017, 63(5): 466-470
- http://dx.doi.org/10.14188/j.1671-8836.2017.05.013
-
文章历史
- 收稿日期:2017-01-02



引用本文

|



2. 华盛顿大学 电机工程系, 华盛顿州 西雅图市 98195
2. Department of Electrical Engineering, University of Washington, Seattle, WA 98195, USA
人体图像分割,是将人体从包含人体的图像中分割出来(如图 1),它对图像分割的准确度及实时性都有较高的要求,是一项具有挑战性的任务.作为人体行为分析和理解的基础,人体图像分割效果的好坏直接决定后续工作的效果,如对于人体三维建模、模式识别、检测与追踪等任务.由于人体图像分割的这些挑战,目前关于人体图像分割的研究与应用还一直处于探索阶段.

|
| 图 1 人体图像分割过程 Figure 1 Human segmentation process |
人体图像分割任务的实质是将一幅图像中的每一个像素点分类为前景和背景.图像分割算法大致可划分为:基于图像图形学的图像分割[1, 2]、基于浅层机器学习的图像分割[3, 4]及基于深度学习的图像分割[5~7].基于图像图形学的方法是直接利用图像中的像素值进行分析.如林川等[1]运用颜色分量RGB作为颜色特征粗分类器的特征输入,计算得到颜色相似度特征灰度图,通过改进的最大类间方差方法,实现待检测目标最终的分割.Chuang等[2]采用直方图反向投影的方法实现图像的语义分割.该方法首先通过双局部阈值变换(double local thresholding)解决光照变化的问题,然后运用直方图反向投影,产生待检目标在两个不同阈值下的分割结果,最后通过指定区域像素值得平均值微调待测目标边界,实现语义分割.
相对于图像图形学的分割方法,基于浅层机器学习的方法应用了浅层特征,获得较好的分割效果.毛凌等[3]针对条件随机场模型难以利用全局形状特征的缺陷,提出一种改进的高阶条件随机场模型,将基于全局形状特征的目标检测结果和点对条件随机场模型统一在一个概率模型框架中,同时完成图像分割、目标检测与识别的任务.Liu等[4]提出的SIFT-flow方法通过对图像定位,根据输入的图像,在数据库中寻找与之相匹配的图,最终在输入图像找到相应的标定,实现图像分割.
虽然上述方法使得图像分割的性能有所提高,但当被分割的物体所处背景复杂并有多种姿态时,浅层的像素级特征无法很好地应对,而基于深度学习的方法经过学习得到的深层视觉结构特征有利于处理这些问题.
卷积神经网络(convolutional neural networks,简称CNN)[8, 9]是深度学习领域比较好的图像特征提取的方法,在人体图像分割方面也取得了令人满意的分割精度.Wu等[5]通过卷积神经网络对输入图像进行分层处理,短距离的语义块描述局部信息,长距离的语义块捕获图像中的对应场景关系,通过组合不同距离的语义块最终获得输入图像像素类别,实现人体图像分割.Song等[6]在人体图像分割领域的研究比较深入,提出了应用卷积神经网络分割人体图像的方法,这是一种端到端(end-to-end)的人体图像分割模型,他们的方法在人体图像分割速度上具有很大的优势,也具有较高的分割精度.Long等[7]的FCN(fully convolutional networks)也是一种端到端(end-to-end)的语义分割方法,首次提出了全卷积网络的概念,将传统网络最后用来分类的内积层换成卷积层,构成全卷积网络,使得分割效果得到了极大地提高,堪称里程碑式的进展.
文献[7]使用的方法拥有较高的语义分割精度,由于在文献中取得最优语义分割结果的网络模型属于非常深(very deep)网络结构[10],将其应用在人体图像分割系统中不能满足实时性要求,因此本文参照FCN[7]的处理方法,针对文献[7]所用网络结构的不足,结合深度学习框架caffe[11]优化了卷积神经网络的结构,在保证较高重叠率的情况下,兼顾了实时性.
1 人体图像分割网络及参数为了获得比较好的分割效果,本文构建了如图 2所示的深度全卷积神经网络(pool5-net),它是由多个卷积层(C1~C8)串接而成,为了减小网络中的学习参数个数,在部分卷积层(C1,C2,C5)后面加入了池化层(P1,P2,P5)来降低网络运算量,以达到优化深度学习网络的目的.层与层之间通过归一化层(LRN1,LRN2) 来连接,并在网络中使用Dropout[12]防止训练模型过拟合.通过对最后的输出特征进行反卷积操作,将特征尺寸恢复到输入图像大小,从而实现像素级别的人体图像分割.

|
| 图 2 pool5-net Figure 2 pool5-net |
C1(96@11×11+S4+pad100) 指在C1卷积层中滤波器的个数为96,卷积核大小为11,卷积步长S为4,填充尺寸pad大小为100.为保证经过多个卷积层之后输出的特征尺寸不至于太小,所以我们在第一个卷积层中直接对原图加了100的padding,考虑到padding操作会引入噪声,其他卷积层的padding设置较小.ReLU表示该层的激活函数,本文中均选用修正线性单元[13](rectified linear unit,ReLU)作为本层的激活函数.D8表示反卷积层.
在第一个卷积层C1中,训练数据x1通过权重矩阵w1得到第一层网络的输出特征,经非线性激励函数优化后,最终输出96个特征映射值{yi1}i=196,每个特征映射值由(1) 式计算得到:
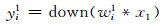
|
(1) |
(1) 式中“*”表示卷积操作,在传统的卷积神经网络模型中常包含偏置参数b,输出形式可以表示为:f(w*x+b),本文中为了表示的简洁性,将偏置项b省略.为了减少网络中学习参数的个数,本文采用最大池化函数[14]对特征映射进行下采样.最后将Rectified linear unit作为本层的激活函数对yi1逐个进行计算,其表达式如下:
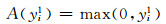
|
(2) |
同样,其后的卷积层也经过与第一个卷积层相同的变换,只是有些层(C3,C4)的输出端没有连接池化层.为了将C8层中输出的特征尺寸恢复到输入图像大小,最后一层D8为反卷积层,其作用可以用(3) 式表示:
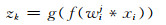
|
(3) |
(3) 式中f(wij*xi)表示经过多个卷积层得到的特征映射,g(·)表示对输入的特征映射进行反卷积操作,反卷积过程为卷积过程的逆运算,zk是输入数据预测为类别k的线性计算的结果.最终得到输入数据中像素点所属类别的预测pk:
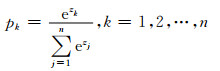
|
(4) |
网络训练的目的是最大化输入数据x属于正确类别k的概率:
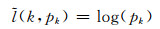
|
(5) |
本文目标函数的最终形式为:
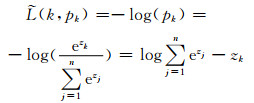
|
(6) |
(6) 式中k表示训练样本的类别标签,n表示预测类别的数目,j代表具体的类别,zk是输入数据预测为类别k的线性计算的结果.本文通过优化(6) 式,采用随机梯度下降(stochastic gradient descent)的方法,实现网络模型权重的更新.
2 实验与分析 2.1 实验环境实验基于Ubuntu14.04,64位操作系统,训练平台为伯克利大学视觉与学习中心(BVLC)的开源深度学习架构Caffe[11].硬件配置为Inter Core(TM)i5-2450Mcpu@2.50 GHZ,RAM 4.00 GB,NVIDIA GeForce GTX 960.数据来源为百度人体图像分割数据库(http://www.cbsr.ia.ac.cn/users/ynyu/dataset/),该数据库中的数据是从各个角度下拍摄的包含人体的图像.数据库中训练图片及标注样本各5 387张.本文将其中的4 848张图片作为训练集,剩下的部分作为测试集.试验中网络输入图像尺寸固定为500×500.
2.2 结果与分析为了准确客观的评价所得分类器的性能,用重叠率来度量本文人体图像分割模型的性能.重叠率的计算如下:
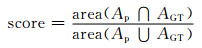
|
(7) |
其中,Ap为人体图像分割网络预测的人体区域,AGT为实际的人体区域.
表 1中Pool5-net-16s是本文基于文献[7]的浅层特征辅助理论在pool5-net的基础上构建的模型.
由表 1可以看出,本文提出的方法重叠率为88.77%,单张图片平均耗时为60.7 ms,将其运用到实时人体图像分割系统中,每秒传输帧数(frames per second)约为16.3,能流畅输出人体图像的分割结果.文献[6]所使用的方法在单张图片测试上耗时最少,但是其准确率仅为80.2%,距离实际应用还有差距.本文提出的方法虽然在耗时上多于文献[6],但是重叠率显著高于文献[6],在重叠率和实时性上获得了比较好的平衡,故网络模型的综合性能优于文献[5, 6].
加入浅层特征辅助的Pool5_net-16s网络模型获得了86.41%重叠率,单张图片平均耗时为60.9 ms,与本文提出的方法相比,不论在重叠率还是单张图片耗时上,均不占优势,这与Long等[7]的结果相反.本文认为浅层深度(not very deep)网络结构的浅层特征,虽然对于输入图像的边界轮廓等细节信息保留较好,但是几乎不包含深层视觉结构特征,这样的特征加入到最终的输出结果中,会对输入图像像素点的正确分类造成干扰,而Long等[7]使用的非常深(very deep)网络结构,由于其浅层特征包含足够多的深层抽象特征,从而掩盖了上述问题.该对比实验也证明,对于浅层深度网络结构,通过引入浅层特征来提高人体分割的效果并不是一个可取的方案,由于浅层深度网络模型的浅层特征几乎不包含输入数据深层视觉结构特征,导致训练模型挖掘训练数据的能力不足,因此对于类似本文构建的浅层深度网络结构,并不适用这种优化方式.
本文所设计分割模型的最终结果如图 3所示.从图中可以看出,对于复杂背景及多种姿态下的人体图像,本文构建的模型仍能够得到较好的分割效果.

|
| 图 3 最终分割效果 Figure 3 The final segmentation result |
本文人体图像分割网络的实现利用了卷积神经网络强大的特征提取能力,通过反卷积层将输入图像特征与每个像素点一一映射,实现像素所属类别的预测,运用反卷积网络,得到像素级别的人体图像分割结果.
在百度人体图像分割数据集上的测试表明,实际应用场景下pool5-net获得了88.77%的重叠率,单张图片耗时为60.7 ms,满足实时性要求.
接下来的研究重点将会在pool5-net的基础上,尝试增加网络深度,修改网络结构,兼顾实时性,以期获得更好的人体图像分割效果.
| [1] |
林川, 潘盛辉, 韩峻峰, 等. 基于人类视觉系统的交通标志优化分割方法[J]. 武汉大学学报(理学版), 2011, 57(3): 236-240. LIN C, PAN S H, HAN J F, et al. Optimal segmentation of traffic signs based on human visual system[J]. J Wuhan Univ (Nat Sci Ed), 2011, 57(3): 236-240. |
| [2] |
CHUANG M C, HWANG J N, WILLIAMS K, et al. Tracking live fish from low-contrast and low-frame-rate stereo videos[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2015, 25(1): 167-179. DOI:10.1109/TCSVT.2014.2357093 |
| [3] |
毛凌, 解梅. 基于高阶CRF模型的图像语义分割[J]. 计算机应用研究, 2013, 30(11): 3514-3517. MAO L, XIE M. Image semantic segmentation based on high order CRF model[J]. Computer Application Research, 2013, 30(11): 3514-3517. DOI:10.3969/j.issn.1001-3695.2013.11.081 |
| [4] |
LIU C, YUEN J, TORRABLA A. Nonparametric scene parsing:Label transfer via dense scene alignment[C]//IEEE Conference on Computer Vision and Pattern Recognition. Washington, D C:IEEE Computer Society, 2009:1972-1979. DOI:10.1109/CVPR.2009.5206536.
|
| [5] |
WU Z F, HUANG Y Z, YU Y N, et al. Early hierarchical contexts learned by convolutional networks for image segmentation[C]//International Conference on Pattern Recognition. Washington, D C:IEEE Computer Society, 2014:1538-1543. DOI:10.1109/ICPR.2014.273.
|
| [6] |
SONG C F, HUANG Y Z, WANG Z Y, et al. 1000fps Human Segmentation with Deep Convolutional Neural Networks[DB/OL].[2017-02-20].http://www.nlpr.ia.ac.cn/english/irds/People/lwang/M-MCG_EN/Publications/2015/CFS2015ACPR.pdf.DOI:10.1109/ACPR.2015.7486548.
|
| [7] |
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. Washington, D C:IEEE Computer Society, 2015:3431-3440. DOI:10.1109/CVPR.2015.7298965.
|
| [8] |
SYAFEEZA A R, KHALILHANI M, LIEW S S, et al. Convolutional neural networks with fused layers applied to face recognition[J]. International Journal of Computational Intelligence & Applications, 2015, 14(3): 1550014. DOI:10.1142/S1469026815500145 |
| [9] |
CIRSHICK R, DONAHUE J, DARRELL T, et al. Region-based convolutional networks for accurate object detection and semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. Washington, D C:IEEE Computer Society, 2014:142-158. DOI:10.1109/TPAMI.2015.2437384.
|
| [10] |
SIMONYAN K, ZISSERMAN A. Very Deep Convolutional Networks for Large-scale Image Recognition[DB/OL].[2017-01-02].http://www.islab.atua.gr/attachments/article/92/1409.1556.pdf.
|
| [11] |
JIA Q Y, DONAHUE E, KARAYEV J, et al. Caffe:Convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM international conference on Multimedia. New York:ACM. 2014:675-678.DOI:10.1145/2647868.2654889.
|
| [12] |
KRIZHEVSKY A, SUTSKEVER I, HINTON G E.Imagenet classification with deep convolutional neural networks[DB/OL].[2017-01-09].http://202.114.96.204/cache/7/03/nips.cc/9f40a89952cb5b28127576139dd89779/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf.
|
| [13] |
NAIR V, HINTON G E. Rectified Linear Units Improve Restricted Boltzmann Machines Vinod Nair[DB/OL].[2017-02-21].http://machinelearning.wustl.edu/mlpapers/paper_files/icml2010_NairH10.pdfdoi:10.1.1.165.6419.
|
| [14] |
SERRE T, RIESENHUBER M, LOUIE J, et al. On the role of object-specific features for real world object recognition in biological vision[C]//Proceedings of the Second International Workshop on Biologically Motivated Computer Vision. London:Springer-Verlag, 2002:387-397. DOI:10.1007/3-540-36181-2_39.
|