 2017, Vol. 63
2017, Vol. 63
文章信息
- 纪祥敏, 田刚, 纪家沂, 向騻
- JI Xiangmin, TIAN Gang, JI Jiayi, XIANG Shuang
- 信任关系辅助的隐反馈Web服务推荐研究
- Trust Aided Web Service Recommendation Using Implicit Feedback
- 武汉大学学报(理学版), 2017, 63(2): 172-176
- Journal of Wuhan University(Natural Science Edition), 2017, 63(2): 172-176
- http://dx.doi.org/10.14188/j.1671-8836.2017.02.011
-
文章历史
- 收稿日期:2015-07-19



引用本文

|



2. 武汉大学 计算机学院,湖北 武汉 430072;
3. 山东科技大学 信息科学与工程学院,山东 青岛 266590
2. School of Compute, Wuhan University, Wuhan 430072, Hubei, China;
3. College of Information Science and Engineering, Shandong University of Science and Technology, Qingdao 266590, Shandong, China
Web服务推荐能够从大量互联网Web服务中为用户推荐合适的服务,成为服务发现的一种关键技术.
在Web服务推荐领域有两种常见的协同过滤推荐模型:基于最近邻的协同过滤方法和基于模型的协同过滤方法.
基于最近邻的协同过滤方法主要通过最近邻方法计算用户或者物品之间的关系[1, 2].常见的最近邻方法包括基于用户的最近邻方法和基于物品的最近邻方法.这两类方法在Web服务推荐领域都已经得到广泛应用.例如,Shao等[2]提出了一种典型的基于用户的协同过滤方法进行QoS值预测,并且假设相似的用户会取得类似的QoS值.Zheng等[3]提出了一种融合基于用户和基于物品的协同过滤方法,有效提高了QoS预测的准确率.然而,总体而言,基于最近邻的模型容易受到数据稀疏的影响.
为了提高服务推荐性能,文献[4]在服务推荐模型引入了用户的位置信息,文献[5]引入了用户的查询历史信息,文献[6]引入了时间特性.这些研究工作在各自的情境下取得了很好的效果,但由于在Web服务领域缺乏显式打分数据,这些模型在实际应用中的效果还有待进一步验证.
因此,基于隐反馈的服务推荐方法引起了研究者的关注.目前在Web服务推荐领域,基于隐反馈的服务推荐方法是一个新颖的研究方向,研究成果较少.文献[7, 8]通过引入隐反馈知识以尝试进行基于隐反馈的服务发现,从而取得了很好的效果.
ProgrammableWeb (PW) 网站 (http://www.programmableweb.com) 是著名的Web服务注册网站,收集了大量的服务注册信息和用户使用服务的隐反馈知识.文献[7]提出一种伪评分生成器,将PW的隐反馈知识建模表示成为一种评分,然后基于该评分实现了基于协同过滤的服务推荐.文献[8]分析了PW网站中隐反馈知识随时间变化的特征,建立一种时间感知的Web服务推荐方法,从而有效提高了服务推荐的性能.这两种方法都能够使用隐反馈知识为用户推荐服务,并在一定程度上提高了服务发现的效率.
然而,正如传统的推荐方法一样,不论是基于最近邻的还是基于模型的协同过滤方法,在进行服务推进的时候,都会面临缺乏显示反馈、数据稀疏的问题.隐反馈反映用户同服务之间交互关系,在用户访问系统的时候将会产生大量的数据,数据量远远超过显式反馈的数量,因而常常被用来和显式反馈结合在一起从而缓解数据稀疏问题.因此,引入更多的外部知识以缓解数据稀疏问题,提高服务推荐模型的性能,已经成为一个值得重视的问题.
基于矩阵因子分解模型通过分析用户和物品关联模式,提供推荐结果,从而得到了广泛应用.文献[8]基于矩阵分解模型建立了一种时间感知的服务推荐方法,提高服务推荐的准确率.文献[9]提出一种社会正则化模型SoRec,该模型在矩阵分解时通过共享一个相同的用户-特征矩阵,建立推荐过程中的社会关系约束情况.Yang等[10]提出了一种组合信任者和被信任者混合模型 (TrustMF),通过分析信任关系对未知物品的打分影响以提升推荐性能.Bao等[9]从不同侧面研究社会信任关系的重要性,将社会关系分解成4个重要因素,融入到矩阵分解过程中.上述研究说明信任因素对推荐系统的影响.然而在Web服务推荐领域,使用信任关系进行服务推荐的研究还比较少见.
针对上述问题,如何引入其他知识进行服务推荐,充分利用各种外部信息有效提高Web服务推荐的性能是一个极具挑战的课题.本文拟利用PW网站提供的用户之间的社交网络信任信息进一步提高服务推荐的效果.一方面,基于文献[7]提出的伪评分生成器,建立用户隐反馈与显式评分之间的映射关系,将用户隐式偏好建模表达成为显式评分;另一方面,在推荐系统中引入社交网络的信任 (Trust) 信息以缓解数据稀疏等问题[10],扩展著名的服务推荐模型SVD++[11],从而使其能够融入社交网络信息,提升推荐系统的性能.
1 隐反馈Web服务推荐模型构建 1.1 伪评分映射模型本文使用文献[7]中提出的伪评分映射模型,将PW中用户隐反馈知识映射成为量化评分.文献[7]中的伪评分产生器由如下几矩阵组成:
基本评分矩阵A,表示用户在watchlist中是否加入了某个服务;平均评分矩阵B表示PW网站提供的对服务的平均打分;时间评分矩阵C表示用户偏好随时间衰减的权重;标签评分矩阵D采用PW网站提供的标签信息建立标签频率权重矩阵.
为了量化表达用户的偏好,建立如下混合评分矩阵
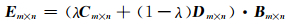
|
(1) |
建立最基本的矩阵因子分解模型.假设存在m个用户和n个物品,使用矩阵R=[ru, i]m×n存放用户-物品数据,其中ru, i表示用户u分配给物品i的评分值.矩阵R中的第i行表示用户ui,矩阵中的第j列表示物品sj.矩阵因子分解模型的目标是通过计算将R分解为两个低阶矩阵Pd×m(P∈ℝd×m) 和Q(Q∈ℝd×n),从而为每个用户建立一个潜在表达.为了近似矩阵R,需要最小化F范数‖R-PTQ‖.这样,用户u对物品i的预测评分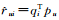
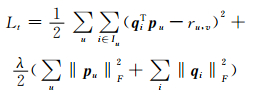
|
(2) |
λ为防止模型过拟合而引入的参数.该公式的目的是发现用户和物品发生不同评分行为的交互模式.然而,在服务推荐领域,隐反馈表达的用户偏好信息不足以完全反映用户的兴趣.因此,引入更多知识 (如社交信任信息) 以提高服务推荐的性能是可行的方法.
1.3 信任模型在基于信任的社会关系模型中,用户之间的信任关系可以使用图G=(V, E) 表示,其中V包含m个用户,E代表了m个用户之间的信任关系.E的结构可以使用一个邻接矩阵T=[tu, v]m×m来表示,其中tu, v代表用户u信任用户v.在基于矩阵分解的方法中,可以引入两个低维向量pu(pu∈ℝd) 和wv(wv∈ℝd) 来表示信任者u和被信任者v的潜在特征向量.基于这种方式,可以建立两个矩阵Pd×m(P∈ℝd×m) 和W(W∈ℝd×m) 来建立信任者-特征矩阵和被信任者矩阵.使用矩阵分解方法,可以建立矩阵T的近似T≈PTW.基于这个方式,通过计算信任者和被信任者特征之间的内积可以建立二者之间的信任关系,即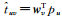
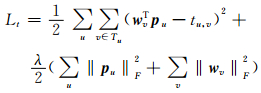
|
(3) |
其中,Tu是用户u的信任用户集合.
1.4 信任关系辅助的推荐模型Hu等在文献[11]中提出,引入对评分的隐式影响因素可以提高模型的预测性能.因此,在本文的服务推荐过程中,拟扩展并修改SVD++模型[11],从而引入信任关系以提高服务推荐的性能.在文献[11]中,每个用户u给物品i的评分可以被预测为:
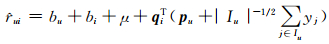
|
(4) |
其中bu和bi分别代表用户和物品的偏差,μ是全局平均评分,yj表示用户历史评分的隐式特性对未来评分的影响.因此可以使用yj融入预测模型,从而引入各种隐式特性,由此预测模型可以修改为:
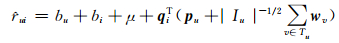
|
(5) |
其中,qiTwv表示由信任用户提供评分信息,即被信任者对评分预测的影响.
为了获得该模型的相关参数设置,建立 (5) 式所示的目标函数:
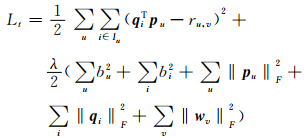
|
(6) |
为了取得目标函数 (5) 的局部最优解,使用经典的梯度下降方法优化该目标函数.
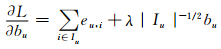
|
(7) |
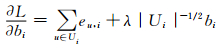
|
(8) |
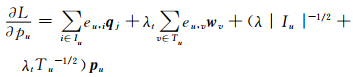
|
(9) |
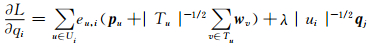
|
(10) |
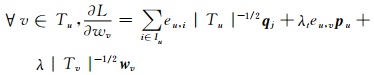
|
(11) |
其中,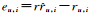
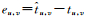
为了测试所提出的信任关系辅助的服务推荐算法的性能,本文基于文献[2]中使用的数据集设计了相关实验.如文献[2]所述,该数据集包含了280 611条用户-服务的交互数据.然而,大多数用户的Watchlist中仅仅含有很少的服务信息,因此本文使用同文献[2]一样的数据设定,即选择510个用户,这些用户的Watchlist中至少包含50条信息.这样,总共4 424个服务信息被选中.最后,将用户-服务交互数据存入了一个510×4 424大小的矩阵中.同样地,本文利用510个用户之间的follow关系建立信任矩阵,即如果在PW网站中,用户u1、u2之间存在follow关系,那么在矩阵中对应u1和u2的那个矩阵元素的取值为1,否则为0,利用这个方式建立一个510×510大小的信任矩阵.
在实验中,本文使用典型的均方根误差RMSE和平均绝对误差MAE度量,以测试算法的预测性能.RMSE定义如下:
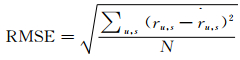
|
(12) |
平均绝对误差MAE定义为:
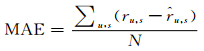
|
(13) |
其中,ru, s是用户u给服务s的打分信息,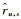
为了评测本文提出的服务推荐方法TIWSRec性能,本文将它与4个典型的推荐算法进行了比较,其中UPCC[1]、IPCC[5]和WSRec[3]算法是基于最近邻的协同过滤推荐算法,SVD++算法是基于模型的推荐算法.这几个算法简介如下:
UPCC:是一种典型的基于用户的协同过滤算法,使用Pearson相关系数作为相似度进行度量[1].
IPCC:是基于物品的协同过滤算法,采用Pearson相关系数算法度量物品相似度[5].
WSRec:是一种融合基于用户和基于物品的综合协同过滤方法,引入信任权重,从而能够平衡两种方法的预测值[3].
SVD++:是一个加入了偏差分解的SVD扩展模型[11].
按照文献[8]的方法,本文将每个用户的用户-服务隐反馈数据划分为训练集和测试集.训练集与全部数据之间的比例从0.1到0.9中分布变化,从而形成不同稀疏程度 (data sparsity) 的矩阵,稀疏度介于0.993到0.999;当训练集比例 (train set ratio) 为0.9时,数据稀疏程度最低,为0.993,如表 1所示.
| datasparsity | trainset ratio | IPCC | UPCC | WSRec | SVD++ | TIWSRec | |||||||||
| RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | ||||||
| 0.993 | 0.9 | 0.763 8 | 0.368 0 | 0.109 5 | 0.076 7 | 0.106 3 | 0.066 7 | 0.099 1 | 0.058 7 | 0.092 8 | 0.057 7 | ||||
| 0.994 | 0.8 | 0.792 2 | 0.392 0 | 0.118 9 | 0.078 6 | 0.122 3 | 0.068 8 | 0.111 8 | 0.061 2 | 0.111 0 | 0.060 2 | ||||
| 0.995 | 0.7 | 0.768 7 | 0.384 0 | 0.137 9 | 0.079 5 | 0.126 2 | 0.069 6 | 0.127 5 | 0.067 5 | 0.139 1 | 0.066 4 | ||||
| 0.995 | 0.6 | 0.771 0 | 0.386 0 | 0.140 2 | 0.080 7 | 0.144 0 | 0.069 7 | 0.152 1 | 0.068 8 | 0.164 7 | 0.067 7 | ||||
| 0.996 | 0.5 | 0.794 7 | 0.397 6 | 0.165 1 | 0.088 3 | 0.182 3 | 0.078 6 | 0.165 5 | 0.072 3 | 0.154 1 | 0.071 1 | ||||
| 0.997 | 0.4 | 0.765 0 | 0.380 4 | 0.225 0 | 0.109 1 | 0.214 4 | 0.097 1 | 0.241 1 | 0.085 2 | 0.193 6 | 0.083 8 | ||||
| 0.998 | 0.3 | 0.734 8 | 0.342 6 | 0.368 4 | 0.172 0 | 0.286 8 | 0.162 1 | 0.279 8 | 0.097 5 | 0.254 2 | 0.095 9 | ||||
| 0.998 | 0.2 | 0.732 9 | 0.316 7 | 0.623 9 | 0.319 8 | 0.330 8 | 0.307 8 | 0.256 5 | 0.156 3 | 0.303 5 | 0.153 7 | ||||
| 0.999 | 0.1 | 0.952 3 | 0.506 5 | 0.881 7 | 0.634 7 | 0.385 6 | 0.622 7 | 0.358 0 | 0.238 5 | 0.353 4 | 0.234 5 | ||||
表 1结果表明,基于最近邻的方法如IPCC、UPCC和WSRec受数据稀疏影响较大,它们的RMSE取值变化十分明显.而基于模型的协同过滤方法如SVD++和本文方法TIWSRec则对数据稀疏有较好的鲁棒性.相对于SVD++模型,TIWSRec模型的RMSE取值平均提升了2.14%,MAE平均提升了1.77%.这说明,在服务推荐过程中,信任知识要素的引入有效提高了服务推荐的预测性能.
2.3 模型中参数设定不同的数据集有不同的数据分布,本文使用交叉验证方法,确定针对PW数据的最优参数设定.TIWSRec模型影响性能的参数主要有3个:潜在特征的数目D、正则化参数λ和针对信任的参数λt.文献[8]中,针对PW的数据集潜在特征的数目设置为20,本文在TIWSRec模型中也采用了相同的潜在特征数目;正则化参数λ和针对信任的参数λt通过10折交叉验证方法设定.如图 1所示,TIWSRec模型参数λ=0.4和λt=0.5时,模型取得了最优性能.

|
| 图 1 TIWSRec模型参数选择 ((a)λ, (b)λt) Figure 1 Preferences choice of TIWSRec model ((a)λ, (b)λt) |
本文提出了一种信任知识辅助的隐反馈Web服务推荐模型.首先基于文献[7]中的方法构造一个伪评分生成器,将用户隐反馈知识映射成为显式打分.然后,基于这种隐反馈伪评分,建立一种融合社交信任信息的服务推荐模型.实验表明,信任知识加入到服务推荐过程中可以显著提升服务推荐的性能.在显式反馈无法获取的情况下,基于隐反馈的服务推荐有助于为用户提供Web服务推荐服务,具有较好的实际应用价值.
下一步,笔者将从如下方面展开深入研究:1) 进一步研究用户打分隐反馈随时间要素的变化特征;2) 研究能够进一步刻画用户的要素,例如位置信息等,从而为用户提供更个性化的推荐服务.
| [1] | BREESE J S, HECKERMAN D, KADIE C. Empirical analysis of predictive algorithms for collaborative filtering[C]//Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence. San Francisco: Computer Science, 1998:43-52. http://dl.acm.org/citation.cfm?id=2074100 |
| [2] | SHAO L, ZHANG J, WEI Y, et al. Personalized qos prediction forweb services via collaborative filtering[C]//Proceedings of ICWS'07.Washington D C: IEEE Computer Society, 2007:439-446. http://ieeexplore.ieee.org/abstract/document/4279629/ |
| [3] | ZHENG Z, MA H, LYU M R, et al. Wsrec: A collaborative filtering based web service recommender system[C]//Proceedings of ICWS'09.Washington D C: IEEE Computer Society, 2009:437-444. http://ieeexplore.ieee.org/abstract/document/5175854/ |
| [4] | ZHAGN Q, DING C, CHI C H. Collaborative filtering based service ranking using invocation histories[C]//Proceedings of ICWS'11.Washington D C: IEEE Computer Society, 2011:195-202. http://ieeexplore.ieee.org/abstract/document/6009389/ |
| [5] | KANG G, LIU J, TANG M, et al. AWSR: Active web service recommendation based on usage history[C]//Proceedings of ICWS'12.Washington D C: IEEE Computer Society, 2012:186-193. http://ieeexplore.ieee.org/abstract/document/6257806/ |
| [6] | AMIN A, COLMAN A, GRUNSKE L. An approach to forecasting QoS attributes of web services based on ARIMA and GARCH models[C]//Proceedings of ICWS'12.Washington D C: IEEE Computer Society, 2012:74-81. http://ieeexplore.ieee.org/abstract/document/6257792/ |
| [7] | ZHANG X, HE K Q, WANG J, et al. Web service recommendation based on watchlist via temporal and tag preference fusion[C]//Proceedings of ICWS'14.Washington D C: IEEE Computer Society, 2014:281-288. http://ieeexplore.ieee.org/abstract/document/6928909/ |
| [8] | TIAN G, WANG J, HE K Q, et al. Time-aware Web service recommendations using implicit feedback[C]//Proceedings of ICWS'14.Washington D C: IEEE Computer Society, 2014:273-280. http://ieeexplore.ieee.org/abstract/document/6928908/ |
| [9] | BAO Y, FANG H, ZHANG J. Leveraging decomposed trust in probabilistic matrix factorization for effective recommendation [C]//Proceedings of the 28th AAAI Conference on Artificial Intelligence. Washington D C: AAAI, 2014:350-356. |
| [10] | YANG B, LEI Y, LIU D, et al. Social collaborative filtering by trust[C]//Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence. Washington D C:AAAI, 2013: 2747-2753. http://ieeexplore.ieee.org/abstract/document/7558226/ |
| [11] | HU Y, KOREN Y, VOLINSKY C. Collaborative filtering for implicit feedback datasets[C]//Proceedings of ICDM'08. Washington D C: IEEE Computer Society, 2008:263-272. http://ieeexplore.ieee.org/abstract/document/4781121/ |