 2017, Vol. 63
2017, Vol. 63
文章信息
- 蒋万伟, 刘娟
- JIANG Wanwei, LIU Juan
- 基于条件随机场的词结构分析方法
- Title Word Structure Analysis Based on Conditional Random Fields
- 武汉大学学报(理学版), 2017, 63(3): 251-258
- Journal of Wuhan University(Natural Science Edition), 2017, 63(3): 251-258
- http://dx.doi.org/10.14188/j.1671-8836.2017.03.010
-
文章历史
- 收稿日期:2016-06-06



引用本文

|



中文分词的任务是将一段连续的汉字序列分隔成一个个独立的词.然而,汉语中的字、词、短语之间并没有明确的边界划分.即使对以汉语为母语的人来说,中文词语划分的平均认同率也只有0.76左右.许多情况下就连语言学家也很难确定词的边界.这就导致了实践中人工标注的分词语料库之间存在严重的不一致性,这种不一致性给汉语的后续处理工作带来了很大的障碍.
不同的分词语料库通常具有不同的分词标准.例如,以人名“张悦”为例,在PKU语料库中被切分为“张”和“悦”两个词,而在MSR语料库中被切分成一个独立的词.而且在同一个语料库内其分词标准也存在不一致性,例如,在PKU语料库中,“副主席”被切分为“副”和“主席”两个词,而“副教授”却是一个词.如果能够给出这些词的内部结构标注“[张悦]”、“[副[主席]]”、“[副[教授]]”,这种结构上的标注更容易取得分词标准上的一致性.另一方面,不同的自然语言处理应用需要不同粒度大小的词,单一的分词标准难以满足多样的需求.例如,对于“多渠道”这个词,机器翻译偏好于将其切分为“多”和“渠道”两个词,而信息抽取更倾向于将其视为一个词.
此外,未登录词识别一直是影响中文分词性能的主要因素,本文统计了Bakeoff 2005语料库中伪未登录词的出现情况,结果如表 1所示,从表中可以发现其中的大多数都属于伪未登录词.伪未登录词是指没有出现在训练语料库中的未登录词,但是该词的各个组成部分却是频繁出现的词[1].例如,在PKU语料库中,“陈列室”是一个未登录词,然而其组成部分“陈列”和“室”分别在语料中出现了10次和358次,通过词的内部结构标注“[[陈列]室]”可以将其转换为已登录词.
| 语料库 | 未登录词 | 伪未登录词 | 比例/% |
| PKU | 2 860 | 1 936 | 64.2 |
| CITYU | 1 665 | 1 110 | 66.0 |
| AS | 3 020 | 2 143 | 71.0 |
| MSR | 1 783 | 1 307 | 73.3 |
综上所述,词的内部结构分析在实践中可以解决分词标准不一致、分词粒度不一和未登录词的识别问题[2],有助于提高后续中文自然语言处理任务的性能,在理论上可以加深对汉语词法分析的理论认识,提高对人类语言本质的理解,从而促进认知科学以及人工智能的发展.因此,本文提出了一种基于条件随机场的词结构分析方法,通过采用词结构特征与词结构标记集来高效地标注词的边界和词的内部结构信息.
1 相关工作许多研究者针对中文分词存在的上述问题做了一些工作,但还主要停留在识别词边界的基础上.在分词标准不一致的问题上,Jiang等[3]提出了基于错误驱动的方法来自动转换不同标准间的语料库.孟凡东等[4]在Jiang的基础上进行异种语料的融合研究.在词的粒度选择上,Wu[5]提出一种基于规则的方法输出可调粒度的词来满足不同应用的需要.Zhang等[6]提出了一种基于二叉树构建与剪枝的方法来克服粒度不匹配的问题.在未登录词的识别上,Sun等[7]通过从大规模的无标注语料中抽取统计特征来提高未登录词的识别率,Cheng等[8]为了把伪未登录词转换为已登录词,提出了一种先进行细粒度分词,然后在输出的词序列上进行再分词的方法.这些工作都还属于传统中文分词领域内的工程性质的研究,其通常需要进行多个步骤的后续处理,不能保证足够的分词精度.
目前,词结构分析的相关研究较为匮乏,但也有许多研究者已经意识到了词的内部结构分析在词法分析中的重要作用.Zhao[9]研究了当前分词范式存在的问题,采用字与字之间的依存关系来表述词语,从而实现基于字的依存分析.Li[10]从理论和应用两个角度分析了目前分词规范的不足,论证了词结构分析的必要性,通过把词结构分析融入句法分析模型识别出词语的内部结构.Zhang等[11]通过引入词的结构实现了基于字符级别的分词、词性标注、句法分析的联合模型.上述方法虽然能有效地进行词结构分析,但过高的时空复杂度使得这些模型很难应用于大规模的文本处理.
为了克服句法分析的复杂性,提高词结构的分析效率,方艳等[2]定义了单独的词结构分析任务,提出了一种基于层叠CRF模型的词结构分析方法.该方法首先使用传统的分词方法实现句子的细粒度分词,然后在输出的细粒度的词序列上使用层叠CRF模型来识别词语的内部结构.孙静等[12]在此基础上提出了一种基于词缀的词结构分析方法,通过给词缀标注特定的标记集将词结构分析问题转换为序列标注问题,从而一步到位实现了词结构自动分析,避免了细粒度分词导致的错误传递.
虽然孙静等[12]的方法的总体性能达到了实用水平,但该方法分析的只限于包含前后缀的复合词,而将联合型、偏正型、动宾型、主谓型等复合词视为无结构的词.同时,由于词缀标记需要额外考虑前后缀与词干结合的优先级,这不仅增加了模型的复杂度,而且容易导致词结构的歧义,在理论上还存在不能识别的两类结构.为此,通过分析伪未登录词的构词特点以及词的内部结构表示,本文提出了词的结构特征来提高未登录词的识别率及词结构分析的性能.此外,本文从词结构的形式化表示出发,提出了更一般化的词结构标记集,很好地统一了词边界标记和词内部结构标记.
2 词结构分析方法 2.1 词结构分析任务词结构分析的任务与传统的中文分词任务不同,它不仅需要标注出词的边界,还要标注出词的内部结构.本文以方括号作为词边界与词内部结构的分隔符,对比了不同粒度的中文分词结果与词结构分析结果.如下列句子所示:
1) 邓小平是中国改革开放的总设计师
2) [邓] [小平] [是] [中国] [改革] [开放] [的] [总] [设计师]
3) [邓小平] [是] [中国] [改革开放] [的] [总设计师]
4) [邓[小平]] [是] [中国] [[改革] [开放]] [的] [总[[设计]师]]
其中,句1是未经分词的原始句子,句2是细粒度的分词结果,句3是粗粒度的分词结果,句4是词结构分析的结果.对比可知,词结构分析结果不仅包括了各种粒度的分词结果,而且标注出了词的内部层次结构.例如,“[[改革] [开放]]”表示“改革”和“开放”这两个词构成“改革开放”,“[总[[设计]师]]”表示“设计”和“师”这两个词首先构成“设计师”,然后与“总”结合构成“总设计师”.
2.2 条件随机场模型条件随机场(conditional random fields,CRFs)模型是一种条件概率模型[13],常用于标注和切分结构化的数据,例如序列、树结构、网格结构等.其基本思想是在给定一个观测序列的基础上,计算出现对应标签序列的条件概率.设X为观测序列(中文文本中的句子),Y为隐藏标签序列(句子中字的标记).线性链条件随机场定义了条件概率如下:
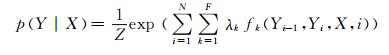
|
(1) |
其中,标量Z是归一化因子,也称为分配函数,主要用于确保概率合法.Z的定义如下:
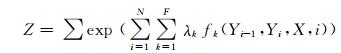
|
(2) |
通常来说Z是很难计算的,我们注意到Z隐式地决定于X和参数λ.fk是特征函数,λk是特征函数fk的权重,由于fk和λk可以取任意实值,则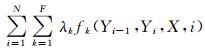
特征函数的选择是CRFs模型的关键,在本文使用的线性链条件随机场中,特征函数的一般形式是fk(Yi-1, Yi, X, i),其输入参数有邻接状态量Yi-1, Yi-1Yi, Yi,整个输入序列X以及序列中的当前位置i,它可以是任意产生实数值的函数.例如,可以为“他是一名工程师”中的“工”字定义一个产生二元值的简单特征函数:
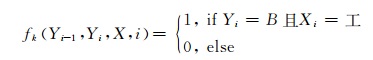
|
(3) |
特征的选择对于CRFs模型的性能至关重要,从理论上来说,CRFs模型可以使用任意多的特征,但基于性能上的考虑,选择的特征不宜太多,通常只在一个有限的上下文中选择特征, 本文中采用5字窗口的特征.CRFs模型常用的特征如表 2所示,主要包括字符n-gram特征、字符重复特征和字符类别特征这三种[14].其中Reduplicate(Ci, Cj)表示两个字符是否相等,Type(Cs)表示字符的类别,类别可分为:英文字母、阿拉伯数字、中文数字、标点符号及其他等五类.在该特征模板中,C指的是字符,下标0表示当前位置,正号表示向后的位置,负号表示向前的位置.
| 特征类型 | 特征形式化描述 |
| 字符n-gram特征 |
Cs(s∈{-2, -1, 0, 1, 2}) CSCS+1(∈{-2, -1, 0, 1}) C-1C1 |
| 字符重复特征 | Reduplicate(Cs, cs+1) (s∈{-2, -1, 0, 1}) Reduplicate(Cs,==cs+2) (s∈{-2, -1, 0}) |
| 字符类别特征 | Type(CS)(s∈{-1, 0, 1}) Type(C-1)Type(C0)Type(C1) |
针对当前词结构分析主要还是基于传统中文分词的基本特征模板这一情况,根据伪未登录词的各个组成部分出现频次高的特点,通过提取词的结构特征来提高未登录词的识别率,从而提高中文分词系统和词结构分析系统的性能.词的结构通常能够使用一棵二叉树来表示,词的子结构也就是其左右子树.根据词结构库中词的左右子结构信息,从上下文窗口中提取出对应的子串看其是否构成左右子结构,从而来定义词的结构特征模板.
中文文本序列中的词语大都具有一定的结构,我们设计了如表 3所示的词结构特征模板(WSF).词结构特征表示一个词语中包含的子结构信息,其中LS(left structure,左子结构)表示上下文窗口内的字符串是否为词的左子结构;RS(right structure,右子结构)表示上下文窗口内的字符串是否为词的右子结构.例如,句子“他是一名优秀的总工程师”里存在词结构“[总[[工程]师]]”,则可知“总”、“工”、“工程”为左子结构,而“程”、“师”为右子结构.若当前字符是“工”,则当前字的左子结构特征LS(C0)、LS(C-1C0)、LS(C0C1)分别为1、0、1;当前字的右子结构特征RS(C0)、RS(C-1C0)、RS(C0C1)分别为0、0、0.
| 特征类型 | 特征形式化描述 |
| LS | LS(C0) LS(C-1C0) LS(C0C1) |
| RS | RS(C0) RS(C-1C0) RS(C0C1) |
基于字的序列标注法的根本思想是通过给汉字序列中的每个字标注它们在词中的位置来达到分词的目的.汉语中的词都是由一个或多个字组合而成的,构成词的每个汉字在词语中都有一个固定的位置,我们把这个位置称作词位.不同的分词方法对词位的划分也有区别,常用的有2词位标记法、4词位标记法、6词位标记法等[15].对于同一个词来说,采用不同的标记集得到的标注结果也不同,但最终我们得到的分词结果都是等价的.不同的标记方法具有各自不同的优缺点,标记的个数越少的,要达到相当的准确率需要设计更复杂的特征模板,但模型训练和预测的时间复杂度和空间复杂度较低;标记的个数越多的,其对于多字词的识别效果更好,但模型训练和预测的时间复杂度和空间复杂度较高.
与传统的基于词边界划分的中文分词任务不一样,词结构分析任务不仅要标注出词与词之间的边界,还要标注出词的内部结构.当前对于词结构标记集的研究还处于起步阶段,主要的工作集中在识别词的前后缀上.孙静等[12]在4词位标记集的基础上增加了词的前后缀标记N(人名中的姓)、P(优先结合的前缀)、T(后结合的前缀)、F(优先结合的后缀首字)、H(后结合的后缀首字)、G(后缀尾字).该方法把前后缀视为特殊的词,通过特定的标记来标识前缀、后缀和词根的结合优先级,词的内部结构分析就可以通过识别词的前后缀来实现.此方法对词结构有比较好的识别率,但是它只考虑了基于前后缀的结构简单的词,对于一些结构复杂的词(短语结构词、非前后缀构词的词、双前缀或双后缀的词)在理论上来说不能识别.
2.4.2 词结构标记集在基于字的条件随机场词结构分析中,为字符选择的标记集不仅要能标识出词的边界,还要能表示出词的内部结构情况.我们以方括号作为词的内部结构表示,这与传统的基于空格划分的词边界表示法不同.每个字都能以方括号的类型和个数来区分词的边界和内部结构信息.字符Cs的标记为T(Cs),则T(Cs)可以形式化的表示为
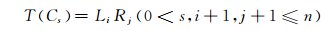
|
(4) |
由词结构的性质可知其满足约束条件式
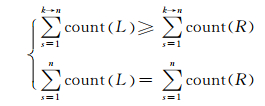
|
(5) |
其中, Li表示左方括号的个数为i个,Rj表示右方括号的个数为j个,n表示句子的长度,count(L)表示从左到右数左方括号的个数,count(R)表示从左到右数右方括号的个数.如表 4所示,使用4词位标记集{S, B, M, E}表示词边界,以方括号表示的词结构可以转换为以LR标记集表示.
| 句子 | 中 | 国 | 改 | 革 | 开 | 放 | 的 | 总 | 设 | 计 | 师 |
| 中文分词 | [ | ] | [ | ] | [] | [ | ] | ||||
| B | E | B | M | M | E | S | B | M | M | E | |
| 词结构分析 | [ | ] | [[ | ] | [ | ]] | [] | [ | [[ | ] | ]] |
| L1 | R1 | L2 | R1 | L1 | R2 | L1R1 | L1 | L2 | R1 | R2 |
由表 4可知,4词位标记集与词结构标记集存在如下的关系:
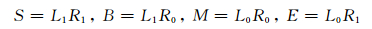
|
(1) |
由此可知,4词位标记集是词结构标记集的子集,然而,在词结构分析任务中,4词位标记集{S, B, M, E}和词结构标记集子集{L1R1, L1R0, L0R0, L0R1}并不是一一对应的关系.对于S、M标记来说,其与L1R1、L0R0是完全对应的,然而对于B、E来说,其与L1R0、L0R1并不完全对应.譬如,词结构“[副[教授]]”的结构标记为“L1R0 L1R0 L0R2”,此时第一个L1R0标记对应的是B标记,第二个L1R0对应的词却不是B标记,L0R2对应的是E标记.因为词首字和词尾字不仅具有词边界标记,还具有词结构标记,而词中字只具有词结构标记.然而,由(5) 式可以根据词中字的结构标记推导出词首字和词尾字的结构标记.词首字C1的结构标记为T(C1),如下
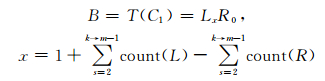
|
(6) |
词尾字Cm的结构标记为T(Cm),如下
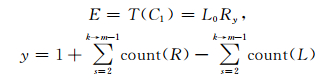
|
(7) |
其中,m为词的长度.
词结构标记集可以分为词边界标记集和词中结构标记集.由于语料库中99%的词长度不大于5,故使用4个词中结构标记{L1R0,L2R0,L0R1,L0R2}可以满足绝大部分的情况.除了单字词对应的词结构标记L1R1外,其余字的词结构标记中左方括号和右方括号不会同时出现,即可以省略数目为0的标记.如表 5所示,我们最终的词结构标记集为{S,B,E,M,L1,L2,R1,R2}.对于B和E标记而言,最终结果需要使用公式(6) 和(7) 配平左右方括号数目.
| 标记 | S | B | E | M | L1 | L2 | R1 | R2 |
| 意义 | 单字 词 |
词左 边界 |
词右 边界 |
词 中 |
一个 左方 括号 |
两个 左方 括号 |
一个 右方 括号 |
两个 右方 括号 |
根据以上分析,句子“高科技企业的市场价值通常为净资产的10倍至50倍”的标注结果可以表示成如(a)所示的方括号标注形式:
(a) [[高[科技]] [企业]]的[[市场] [价值]] [通常]为[净[资产]]的[1 0]倍至[5 0]倍
也可以表示成如(b)所示的逐字标注形式:
(b)高/B科/L1技/R2企/L1业/E的/S市/B场/R1价/L1值/E通/B常/E为/S净/B资/L1产/E的/S 1/B 0/E倍/S至/S 5/B 0/E倍/S
由于分析得到的词结构需要转换为可视化的形式,我们需要把(b)式转换成(a)式.此时需要分两步进行,第一步转换词结构标记,先把L1、L2、R1、R2标记替换为对应层级的方括号,然后根据公式(6) 和(7) 来配齐词头和词尾的左右方括号.配齐过程首先从右往左遍历词,计算右方括号与左方括号的个数差来决定词头位置的左方括号数,然后从左往右遍历,计算左方括号与右方括号的个数差来决定词尾位置的右方括号数,转换结果如(c)式所示:
(c) [高/B [科技]] [企业]/E的/S [市/B场] [价值]/E通/B常/E为/S净/B [资产]/E的/S 1/B 0/E倍/S至/S 5/B 0/E倍/S
第二步转换词边界标记,先去掉所有的SM标记,再把BE标记替换为左右方括号即可得到(a)式.
3 实验及结果分析 3.1 实验设置由于方艳等[2]标注的语料尚未公开,本文使用中文分词领域内使用最广泛的Bakeoff 2005语料库中的PKU语料.尽管Bakeoff 2005还提供了其他3个语料,但其中的2个属于繁体中文语料,与简体中文语料有较大区别,另一个是MSR简体中文语料,由于MSR语料比PKU语料更大,词的切分粒度较大,人工标注词的结构需要很大的工作量,因此本文在实验中采用PKU语料.由于现有语料只标注了词的边界信息,我们需要对词的内部结构进行人工处理.虽然词的内部结构复杂多样,但词的内部结构相对于其外部功能来说更为固定,它不取决于使用的上下文环境.因此在人工标注词结构的过程中避免了重复标注,大大降低了工作量.对语料的处理主要分为四步,首先从语料库中提取被切分的中文人名,中文人名是一类特殊的包含结构的词;然后提取被切分的有结构词,把语料库中相邻的三个词提取出来,人工检查其是否为复合词;再提取未被切分的有结构词;最后,根据现有的词结构库[11, 16]标注语料库中的所有复合词,对于不在词结构库中的复合词逐一人工标注.经过上述标注之后,不同层次结构的词在语料库中的分布情况如表 6所示,其中一层结构的词占有结构词中的大部分,三层及以上结构的词非常少.为了降低语料对实验结果的影响,我们将标注好的语料平均分成10份,选择其中的1份作为测试语料,其余的9份作为训练语料,共产生10种不同的训练语料和测试语料,最终的实验结果为这10种语料上的结果的平均值.语料处理完毕后,根据基本特征模板和词结构特征模板抽取出特征,使用CRFs模型可以很方便地实现中文分词和词结构分析.本文使用CRFSuite[17]工具包作为CRFs模型的实现,采用默认的lbfgs优化算法.本文使用方艳等提出的正确率P,召回率R和F值作为词结构分析评测的三个指标[11].
| 层次 | 中文人名 | 未切分的结构 | 已切分的结构 | 各层结构的词总数 | 占总标注词比/% |
| 一层 | 7 134 | 16 135 | 5 360 | 28 629 | 88.5 |
| 两层 | 0 | 1 744 | 1 571 | 3 315 | 10.3 |
| 三层及以上 | 0 | 254 | 134 | 388 | 1.2 |
| 总计 | 7 134 | 18 133 | 7 065 | 32 332 | 100 |
本文提出的基于条件随机场的词结构分析方法相对于传统的中文分词方法来说,其主要的不同在于增加了4个词结构标记.实质上该方法只是把原有的4词位标注集中大部分表示词中位置的M标记转换成了结构标记L1、L2、R1和R2,并没有改变S、B、E三个标记.因此,本文提出的方法相对于基于前后缀标记集的词结构分析方法,能够应用于传统的中文分词评测.
表 7是基于不同的特征与标记集的中文分词方法的实验结果.Baseline系统采用基本特征与4词位标记集,“+WSF”指的是在基本特征的基础上增加的词结构特征,“+WST”指的是在4词位标记集的基础上增加的词结构标记集.由表 7可以看出,与Baseline系统相比,增加了词的结构特征后,未登录词召回率性能提升明显,其中主要原因是提高了伪未登录词的识别率.使用词结构标记集也明显提升了分词性能,但其对于未登录词的识别率相比基于词结构特征的分词系统性能要低.结合词结构特征与词结构标记集后,分词性能取得了更显著的提升,未登录词的识别率和伪未登录词的识别率都提升明显.我们发现系统在伪未登录词的识别性能提升最大,这表明我们提取的词结构特征与使用的词结构标记集对于识别伪未登录词效果显著.
本文也与当前在PKU语料上最好的结果做了对比,相比Sun等[7]提出的从大规模无标注语料库中抽取统计特征的方法在性能上存在较大优势,在未登录词的识别上也具有一定优势.相比Zhang等[18]提出的半监督动态特征抽取的方法在性能上略有提升,但在未登录词的识别上具有明显优势.综合而言,基于词结构特征与词结构标记集的中文分词方法与现有最好的系统在分词性能和未登录词的召回率上处于同一水平.
对测试结果进行错误分析可发现,基于词结构特征与使用词结构标记集的分词系统对于伪未登录词的识别效果明显.一个主要原因是增加了词结构特征与使用词结构标记集后,其对伪未登录词的识别效率提升了.例如,“北大学生李宁按下火种采集器按钮”经分词后结果为“北大学生李宁按下火种采集器按钮”,它能够正确地切分出伪未登录词“采集器”.但是,某些应用广泛的子词结构也容易导致一些错误的切分,例如,“正如当年血腥镇压太平天国农民革命一样”被切分成“正如当年血腥镇压太平天国农民革命一样”,由于“镇”字作为右子结构出现频率很大导致“血腥镇”这一词的切分错误.
3.3 词结构分析实验基于结构标记集的词结构分析就是通过给词中的字赋予特定的结构位置标记来识别词的内部结构.零层结构词表示不含有内部结构的词,例如我”、“[我们]”、“[生物]”等词;一层结构词表示只含有一层内部结构的词,例如“[[朋友]们]”、“[总[经理]]”、“[老[干部]]”等词;两层及以上结构词表示含有两层及两层以上内部结构的词,例如“[年[[成交]额]]”、“[[[生态]学]家]”、“[[[功成] [名就]]者]”等词.
如表 8所示,本文与文献[2]及文献[12]提出的方法分别从总体性能F1值、零层结构词识别性能F1值、一层结构词识别性能F1值和两层及两层以上词识别性能F1值等4方面做了对比.
从表 8可以看出,本文提出的方法在各层结构的识别上取得了较高的性能,总体性能也达到了实用水平.虽然性能随着结构层数的增多有所下降,但是幅度较小.由于在语料中两层及两层以上的结构所占比例不大,其识别效率对整体性能的影响较小.
高层结构的识别性能下降的主要原因有:一是层次结构越多、训练数据越少从而导致的训练不充分;二是高层结构由于涉及到较多的标记导致识别复杂度高,低层结构的识别错误也影响到了高层结构的识别.
4 结论本文提出了基于条件随机场的词结构分析方法,该方法采用词结构特征与词结构标记集来提高中文分词和词结构分析的性能.实验结果表明,增加了词的结构特征和词的结构标记集不仅能有效地提高中文分词性能,显著提升未登录词和伪未登录词的识别率,而且能高效地分析词的内部结构,在总体性能和各层次结构的识别性能上均有明显的提高.本文提出的方法能够一步到位地标注出词的内部结构,不需要经过复杂的后处理.同时,词结构标记集能够更好地标注词的边界和词的内部结构,具有更高的通用性,理论上也不存在不能识别的词结构.我们接下来的工作是通过使用更多的语言学特征来进一步提升词结构的识别性能.
| [1] |
DONG Z, DONG Q, HAO C. Word Segmentation Needs Change—From A Linguist's View[DB/OL].[2016-04-09]. http://www.aclweb.org/anthology/W/W10/W10-4101.pdf.
|
| [2] |
方艳, 周国栋. 基于层叠CRF模型的词结构分析[J]. 中文信息学报, 2015, 29(4): 1-7. FANG Y, ZHOU G D. Word structure analysis based on cascaded CRFs[J]. Journal of Chinese Information Processing, 2015, 29(4): 1-7. DOI:10.3969/j.issn.1003-0077.2015.04.001(Ch) |
| [3] |
JIANG W, HUANG L, LIU Q. Automatic Adaptation of Annotation Standards: Chinese Word Segmentation and POS Tagging——A Case Study[DB/OL].[2016-04-03].http://aclweb.org/anthology/P09-1059.DOI:10.3115/1687878.1687952.
|
| [4] |
孟凡东, 徐金安, 姜文斌, 等. 异种语料融合方法:基于统计的中文词法分析应用[J]. 中文信息学报, 2012, 26(2): 3-8. MENG F D, XU J A, JIANG W B, et al. A method of merging corpora in different annotation standards: An application statistics Chinese lexical analysis[J]. Journal of Chinese Information Processing, 2012, 26(2): 3-8. DOI:10.3969/j.issn.1003-0077.2012.02.001(Ch) |
| [5] |
WU A. Customizable segmentation of morphologically derived words in Chinese[J]. Int Journal of Computational Linguistics and Chinese Language Processing, 2003, 8(1): 1-27. |
| [6] |
ZHANG K, WANG C, SUN M. Binary tree based Chinese word segmentation[J]. Decision Support Systems, 2013, 46(1): 149-157. |
| [7] |
SUN W, XU J. Enhancing Chinese Word Segmentation Using Unlabeled Data[DB/OL].[2016-03-16]. http://aclweb.org/anthology/D11-1090.
|
| [8] |
CHENG F, DUH K, MATSUMOTO Y. Synthetic Word Parsing Improves Chinese Word Segmentation[DB/OL].[2016-03-12]. http://aclweb.org/anthology/P15-2043. DOI: 10.3115/v1/P15-2043.
|
| [9] |
ZHAO H. Character-level Dependencies in Chinese: Usefulness and Learning[DB/OL].[2016-03-09]. http://aclweb.org/anthology/E09-1100. DOI: 10.3115/1609067.1609165.
|
| [10] |
LI Z. Parsing the Internal Structure of Words: A New Paradigm for Chinese Word Segmentation[DB/OL].[2016-02-23]. http://aclweb.org/anthology/P11-1141.
|
| [11] |
ZHANG M, ZHANG Y, CHE W, et al. Chinese Parsing Exploiting Characters[DB/OL].[2016-04-03]. http://aclweb.org/anthology/P13-1013.
|
| [12] |
孙静, 方艳, 丁彬, 等. 利用扩展标记集的词结构分析[J]. 中文信息学报, 2014, 28(5): 39-45. SUN J, FANG Y, DING B, et al. A word structure analysis by extending the word tag set[J]. Journal of Chinese Information Processing, 2014, 28(5): 39-45. DOI:10.3969/j.issn.1003-0077.2014.05.005(Ch) |
| [13] |
LAFFERTY J, MCCALLUM A, PEREIRA F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data [C]//Proceedings of the 8th International Conference on Machine Learning. Williamstown: Morgan Kaufmann, 2001:282-289.
|
| [14] |
张梅山, 邓知龙, 车万翔, 等. 统计与词典相结合的领域自适应中文分词[J]. 中文信息学报, 2012, 26(2): 8-13. ZHANG M S, DENG Z L, CHE W X, et al. Combining statistical model and dictionary for domain adaption of Chinese word segmentation[J]. Journal of Chinese Information Processing, 2012, 26(2): 8-13. DOI:10.3969/j.issn.1003-0077.2012.02.002(Ch) |
| [15] |
ZHAO H, HUANG C N, LI M, et al. Effective Tag Set Selection in Chinese Word Segmentation via Conditional Random Field Modeling[DB/OL].[2016-03-03]. http://aclweb.org/anthology/Y06-1012.
|
| [16] |
CHENG F, DUH K, MATSUMOTO Y. Parsing Chinese Synthetic Words with a Character-Based Dependency Model[DB/OL].[2016-02-06]. http://www.lrec-conf.org/proceedings/lrec2014/pdf/96_Paper.pdf.
|
| [17] |
OKAZAKI N. CRFsuite: A Fast Implementation of Conditional Random Fields (CRFs)[DB/OL]. [2008-03-05] http://www.chokkan.org/software/crfsuite.
|
| [18] |
ZHANG L, WANG H, SUN X. Exploring Representations from Unlabeled Data with Co-Training for Chinese Word Segmentation[DB/OL].[2016-02-03]. http://aclweb.org/anthology/D13-1031.
|