 2016, Vol. 62
2016, Vol. 62
文章信息
- 吴胜, 刘茂福, 胡慧君, 张志清, 顾进广
- WU Sheng, LIU Maofu, HU Huijun, ZHANG Zhiqing, GU Jinguang
- 中文文本中实体数值型关系无监督抽取方法
- Unsupervised Extraction of Attribute-Value Entity Relation from Chinese Texts
- 武汉大学学报(理学版), 2016, 62(6): 552-560
- Journal of Wuhan University(Natural Science Edition), 2016, 62(6): 552-560
- http://dx.doi.org/10.14188/j.1671-8836.2016.06.011
-
文章历史
- 收稿日期:2016-01-07



引用本文

|



2. 智能信息处理与实时工业系统湖北省 重点实验室,湖北 武汉 430065 ;
3. 武汉科技大学 管理学院,湖北 武汉 430081
2. Hubei Province Key Laboratory of Intelligent Information Processing and Real-Time Industrial System, Wuhan 430065, Hubei, China ;
3. School of Management, Wuhan University of Science and Technology, Wuhan 430081, Hubei, China
随着互联网信息爆炸式增长,人们迫切需要从海量数据中获取有价值的信息.传统行业在应对当前的市场环境时,更需要拥抱互联网,需要从互联网信息中分析当前行业市场发展前景.互联网上的大量信息都是非结构化的电子文本,如新闻、博客、政府文件等,这些文本中含有大量的数值信息,通过信息抽取将这些带数值型的文本转化为结构化的信息,并以特定的格式存储,供用户查询以及进一步分析利用,具有非常重要的现实意义.
实体指文本中包含的特定信息,如人物、位置等;数值指描述实体的相关特征属性值.实体数值型关系抽取的主要目的是将无结构的带有数值的文本转化为结构化或半结构化信息.中文实体数值型关系抽取涉及到实体对象抽取和实体属性值抽取,通过实体属性值判断该实体关系是否是有用的信息,进而提取并分析实体对象、实体特征,最后生成“(实体对象,实体特征,实体属性值)”三元组结果.
信息抽取IE (information extraction)技术是自然语言处理NLP (natural language processing)的一个重要分支.传统的实体关系抽取需要预先定义,例如美国国家标准技术研究的自动内容抽取ACE (automatic content extraction)[1]评测定义了7种实体关系类型,然而预先全面定义实体关系类型或者模式需要花费很多时间和精力,且比较困难.当前针对中文语料的实体关系抽取,大多数研究都是实体之间的人物关系、地理关系、组织关系等,而涉及到带有属性值的类属关系研究的比较少.在研究方法上一般是需要预先定义关系类型和相关特征,采用有监督方法实现关系种子集的自动构建;或者利用自定义关系模式,来实现实体关系的自动发现.文献[2~4]采用有监督方法通过给定的目标实体种子属性集合来提取属性值,该类方法需要为每类实体对象都提供一个种子属性集合;文献[5]采用半监督学习,以少量种子产生训练数据,训练属性值抽取器;文献[6]采用基于知识库的弱监督方法,利用知识库中已有关系实例从未标注数据中产生训练语料.采用有监督或半监督方法进行属性值抽取需要大量的训练语料或给出特定的模式,弱监督方法则依赖于知识库.
采用无监督方法的实体关系抽取,能够避免预先定义关系类型和相关特征.基于词汇-句法模式的属性值抽取方法是无监督的典型做法,其中“attribute of entity is value”模式是目前使用最广泛的抽取模式[7, 8], 基于句法树的方法要求比较高,且只考虑了句子中实体个数低于两个的情况.实际上,网络文本中的中文句子都很复杂,包含3个以上实体的句子是很常见的,这就会导致抽取结果在意义上与原句差别很大.面向特定领域的抽取模式,例如,针对微博的“my attribute is”模式[9],文献[10]提出了抽取数量型属性值的“实体+系动词+量词+属性名”模式.在英文领域的实体关系抽取中,华盛顿大学的人工智能研究组在这方面做了大量代表性的工作,并且开发了一系列原型系统:TextRunner、ReVerb等.文献[11]首先开发出一个完整的系统TextRunner,它能够直接从网页纯文本中抽取实体关系,文献[12]提出了基于句法和词汇约束的实体关系识别器ReVerb,此外Schmitz提出了基于上下文语境分析的抽取方法[13].中文领域最新的研究有:文献[14]提出一种无监督方法,将属性值看作命名实体,利用频繁模式挖掘和关联分析,从文本中抽取类别属性.文献[15]提出结合全局特征的感知机器学习算法,降低了全局特征的求解复杂度,在开放领域的属性值抽取上取得不错的效果.
此外,通过借助网页中的半结构化信息,如表格、字体等HTML标签,也可以实现属性值抽取.文献[16]以含有类别词语的大量Web文档为数据源,利用词频统计、文本模式和HTML标签提取属性词;文献[17]根据给定的属性从半结构化HTML文档中抽取实例和属性值.该类方法具有很大的灵活性和语义不确定性,处理的数据类型有限,这将影响所抽取属性值的质量.
本文提出的无监督方法主要是从中文网络文本中抽取实体数值型关系,并且能够有效解决包含3个以上名词实体的复杂文本句子的抽取问题.该方法首先通过正则表达式发现和定位包含数值的文本句子,对可能的目标句子利用中文分词、词性标注等自然语言工具进行处理,采用构建的名词实体选择树,生成实体对象候选集,然后结合提取的实体特征和实体属性值,生成三元组实体数值型关系候选集,之后判断包含候选实体数值型关系的句子与原句的相似度,从而较为准确地提取需要的数值型三元组实体关系.
1 无监督抽取方法 1.1 方法框架在中文文本中实体数值型关系无监督抽取方法中,经过文本预处理、句式分析、候选集生成、关系抽取等四个阶段的处理后,最终生成“(实体对象,实体特征,实体属性值)”三元组结果,该方法的框架如图 1所示.

|
| 图 1 中文实体数值型关系无监督抽取方法框架图 Figure 1 Framework of attribute-value entity relation extraction from Chinese texts |
在网络文本的预处理阶段,首先对文本进行中文分词、去除停用词、词性标注,然后在此处理结果上过滤数词,判断该句是否是数值型句子,最后根据自定义单位词表,抽取实体属性值;接着进行句式分析,包括去除数词干扰项、并列关系名词、句子中补充成分、修正词性标注错误、修正谓语补语成分、根据规则将复杂句拆分为简单句等处理,获得句子片段集合;然后针对句子片段,第一步是提取所有的名词,利用选择树算法构建可能的实体对象,从而得到实体对象候选集,第二步是提取动词或动词短语,或提取离数词左边第一个名词,作为实体特征;最后将前面提取的实体属性值、实体特征、实体对象生成候选三元组,经过相似度计算,选择最优的三元组集合作为数值型实体关系结果.
文本预处理主要有网络文本提取、包含词性标注在内的自然语言文本处理等步骤.针对从网页中获取的文本信息,通过分词、去停用词、词性标注等处理,得到包含自然语言处理标记的句子集合.
1)网页正文提取:采用网络爬虫技术抽取网页中的文本内容,并存储为需要的格式文本.
2)自然语言处理:首先使用斯坦福分词工具对网页文本分词、词性标注;接着使用停用词表删除不需要的词;最后根据词性标签选择需要的句子.
1.2 句式分析文本句子表达形式是复杂多样的,为了更好地抽取关系和提高准确率,对文本句子进行了如下定义.
定义1(复杂句) 包含3个或3个以上的实体对象且有多个属性值的句子.
定义2(简单句) 包含2个或2个以下实体对象且只有一个属性值的句子.
根据上面的定义,本文通过大量的文本语料分析,利用自然语言处理方法和汉语语法知识,引入下面的抽取规则.
规则1 假如某文本句子符合“(实体对象,特征词,属性值)”模式,如图 2所示,抽取路径关系则没有多选的复杂情况,根据汉语语法将文本句子中不是名词、数词和动词的词都删减掉,余下部分按照原句顺序重新构建在一起,就可以得到抽取结果.

|
| 图 2 规则1图示 Figure 2 The situation of Rule 1 |
规则2 假如某文本句子符合“((实体1,实体2,…),特征词,属性值)”模式,如图 3所示,文献[18]指出谓语前的介词结构的语义指向的是主语,在利用分词工具时谓语前面的部分可以分出多个名词,它们可能都是特征对象的一部分,也就是出现了多个实体关系,多个实体之间是并列关系,并且都位于特征词的前面,则提取特征对象词候选结果就是从“(实体1,实体2,…,实体n)”中按照顺序选择若干个组合在一起,整个实体关系的抽取就为“(实体组合选择,特征词,属性值)”.

|
| 图 3 规则2图示 Figure 3 The situation of Rule 2 |
规则3 假如某文本句子符合“((实体1,实体2,…),特征词,(属性值1,属性值2,…))”模式,如图 4所示,句子结构中包含递进、并列、补语等复杂关系时,往往使用逗号和分号进行递进或者补充,导致出现多个属性值的情况,而递进、并列、补语部分的语义一般同主语或谓语有关,如果递进、并列、补语部分作为独立成分是毫无意义的,也就是它必须依赖于前面的主谓部分,抽取的属性值,必须依赖前面的实体,此时特征关系抽取的结果将是在规则2的基础上根据属性值的个数来提取相应个数的候选结果.

|
| 图 4 规则3图示 Figure 4 The situation of Rule 3 |
规则4 对于特征而言,出现一些状语,即谓语补语,文献[19]指出状语成分的语义是指向谓语的,说明在某些情况下加上这个状语,谓语的意义更清楚.比如:“同比增长”、“增长”这个词在关系抽取中就是特征,但是加上“同比”这个词会让抽取的关系与原句意义更近,所以必须加上.
针对网络复杂文本,经过大量的实验发现,不仅词性标注需要做得更准确,而且需要去除干扰项,例如表示时间的数词、句中补充说明的成分等,所以需要对选择的句子进行句式分析,具体的处理过程如算法1所示.
算法1 句式分析算法
名称:句式分析算法
输入:经过预处理后的句子
输出:经过句式分析过的句子片段
步骤1:for (每一个句子) do
步骤2: if (句子中存在表示时间数词干扰项) then
步骤3: 去除句子中含有纯数字时间干扰项的词;
步骤4: end if
步骤5: if (句子中存在有破折号或大括号) then
步骤6: 去除破折号及其后面的内容;
步骤7: 去除大括号及其包裹的内容;
步骤8: end if
步骤9: if (句子中存在谓语动词有状语的成分) then
步骤10: 修正动词状语;
步骤11:end if
步骤12:if (句子中存在词性标注错误的词) then
步骤13: 修正词性标注错误问题;
步骤14:end if
步骤15:if (句子中存在多个名词是并列关系) then
步骤16: 删除多余的并列关系词;
步骤17:end if
步骤18:if (句子符合复杂句拆分的条件) then
步骤19: 判断原句子结构,提取动词集合与数词集合;
步骤20: for (每一个动词或者数词) do
步骤21: 根据规则生成简单句,并存入句子片段集合;
步骤22: end for
步骤23:else if (句子是简单句) then
步骤24: 直接将该句存入句子片段集合
步骤25:end if
步骤26:end for
1.3 候选集生成因为在一个文本句子中名词实体个数不确定,而动词和数词基本上是有限的,导致对每一个文本句子的关系抽取将会产生很多种不同的选择,故而需要生成实体对象候选集,为了更好的描述这一问题,例1给出了一个句子抽取实例.
例1 原句:全国累计销售家电下乡产品2.83亿台
分词结果:全国/NN累计/AD计销/VV销售/NN家电/NN下乡/NN产品/NN 2.83亿/CD台/M
分析结果:
1)全国销售2.83亿台
2)销售家电2.83亿台
3)销售产品2.83亿台
4)销售家电产品2.83亿台
5)销售家电下乡产品2.83亿台
6)全国销售家电下乡产品2.83亿台
输出结果:
实体对象:全国家电下乡产品,实体特征:累计销售,实体属性值:2.83亿台.
例1中,从原句中实际可以抽取31种符合中文表达的句子片段,有些句子片段是没有意义的,有些句子片段跟原文在意义上有差距,当然也有非常符合原句意义的句子片段.上例中只给出6种可能的结果,因为实体对象存在很多种情况,所以需要生成实体对象候选集合,本文提出了一种选择树方法,用于生成实体对象候选集.
图 5就是一个实体对象选择树,图中每个节点分别代表每个实体对象,每个节点有两条边和一个桥接线,实线表示向左遍历,代表选择该节点表示的实体;虚线表示向右遍历,代表不选择该节点表示的实体;带箭头弧线,也叫桥接线,方向只能是向右下方执行跳跃遍历,代表可以跳跃节点选择实体,且节点的选择顺序只能是从上往下,图中任意一个节点都可以作为开始节点,也可以作为结束节点.选择树表示了一个句子中实体对象构建的所有可能.

|
| 图 5 实体对象选择树 Figure 5 The selection tree of entities |
对例1进行实体对象候选集生成,采用选择树算法进行分析,例1原句分词中产生“全国”、“销售”、“家电”、“下乡”、“产品”共5个名词实体,分别用N1,N2,N3,N4,N5代替他们,具体过程如算法2所示.
算法2 实体对象候选集生成算法
名称:实体对象候选集生成算法
输入:经过句式分析后的句子片段
输出:输出实体对象候选集合
步骤1:获得每个句子片段中的所有名词对象集合;
步骤2:根据名词对象集合,生成实体对象选择树;
步骤3:for (每一个节点) do
步骤4: 遍历左下节点;
步骤5: if (左下存在节点) then
步骤6: 继续遍历左下节点,并保存当前节点路径;
步骤7: end if
步骤8:跳跃遍历右下节点;
步骤9: if (右下节点存在左节点) then
步骤10: 继续遍历左下节点,并保存当前节点路径;
步骤11: else
步骤12: 执行多级跳跃遍历右下节点,并保存当前节点路径;
步骤13: end if
步骤14: 对节点路径进行去重过滤,生成节点路径集合;
步骤15: for (每个节点路径) do
步骤16: 按照顺序还原名词对象,存入实体对象候选集合;
步骤17: end for
步骤18:end for
本文着眼于信息抽取在钢铁公司潜在下游行业自动发现中的应用,主要研究数据背后的行业用钢量需求,从而为钢铁公司制定钢铁年度生产计划服务.利用本文提出的方法,能够准确地从来源于家电行业的句子“今年全国电视销量9千万台,同比增长17%”中抽取三元组关系“(电视,销量,9千万台)”和“(电视,销量,同比增长17%)”,在某钢厂的研究中,它们的实际作用是:9千万台电视,特定的产品各个部件都是定型的,需要什么材质,生产什么样的钢材.如果能够知道生产一台电视需要多少钢铁,全部电视机需要多少钢铁就能预测,同时可以预测明年也有17%左右的增长,那么明年需要多少钢铁也可以预测,类似的研究在房地产、船舶行业中都有应用.研究人员通过提取的属性值,分析市场销量和耗材量,锁定最有前景的产品或者项目,做后续分析工作,从而辅助钢铁行业进行决策和制定计划,因此中文实体数值型关系抽取具有重要的现实意义.
1.4 语义相似度计算候选关系三元组中有些不符合原句意义,需要计算包含候选关系三元组的句子与原句的相似度,选择最符合原句意义的句子.本文采用余弦相似度和Jaro-Winkler距离进行对比分析来解决这个问题.
余弦相似度:在向量空间模型中,给定文本句子对(S, T),文本句子S和T的相似度可以转化为计算文本向量s和t之间的夹角余弦.两个文本的向量余弦相似度越高,它们表达的意思就越接近,文本句子T的概率就越大.余弦相似度可以使用公式(1)计算得到.
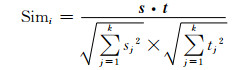
|
(1) |
其中,s和t是相对于文本句子S和T的向量,k是向量维度,每个分量使用传统的TF-IDF[20]方法计算得到.
Jaro-Winkler距离:这是一种计算两个字符串之间相似度的方法,它是Jaro距离算法的变种,Jaro-Winkler值越大,表明两个字符串的相似度越高,Jaro-Winkler尤其适合短字符串相似度的度量.0分表示没有任何相似度,1分表示完全匹配.
T和H为给定的字符串,先计算:
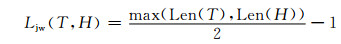
|
(2) |
其中,Len ()为计算字符串长度函数.如果两个分别来自T和H的字符相距不超过(2)式的结果值,则认为这两个字符是匹配的,然后计算Jaro-Winkler距离.
Jaro-Winkler距离得分公式为
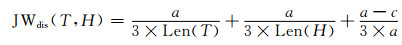
|
(3) |
其中a是文本句子T和H匹配的字符串个数,c是换位数目.当来自T和H的字符相匹配但是字符位置不一样时,就要发生换位操作,而(3)式中换位数目c,是不同顺序的匹配字符数目的一半,向下舍入.例如:一组字符串DWAYNE与DUANE,匹配的字符D-A-N-E,在各自的字符串中顺序相同,因而c=0, a=4;在另一组字符串CRATE和TRACE中,初看5个字符应该都匹配,但是实际只有R-A-E是匹配的,因为字符C和T的距离是2,(2)式得到的值是5/2-1=1.5,且顺序不一致,因此(3)式中的c=1, a=3.
Jaro-Winkler还给予了起始部分相同的字符串更高的分数.定义一个前缀p,对于两个字符串,如果前缀部分有长度为l的部分相同,则Jaro-Winkler距离得分为:
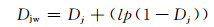
|
(4) |
其中Dj是两个字符串的Jaro距离,l是前缀的相同的长度,但是规定最大为4,p则是调整分数的常数,规定不能超过0.25,不然可能出现Djw大于1的情况,Winkler将这个常数定义为0.1.
设置增强得分0.7,这个值称为:温克勒阈值,或者温克勒奖金.如果当(2)式返回的值小于0.7,则两个字符串的Jaro-Winkler距离就是这个返回值,如果返回值大于设置的温克勒阈值0.7,则用(4)式来计算两个字符串的Jaro-Winkler距离.Luence提供了一个关于Jaro-Winkler距离算法的Java代码(http://lucene.apache.org/core/3_0_3/apilcontrib-spellchecker/org/apache/lucene/search/spell/JaroWinklerDistance.html).
2 实验 2.1 实验设置本文实验数据来源于网络,为了分析本文方法的领域适应性,分别在钢铁行业、船舶行业、房地产行业进行实验,验证抽取规则和自定义词表的泛化能力,主要涉及9个网站合计59 336个Web网页文本,网页文本开放且易获取,提取网页正文内容作为实验的目标数据集.此外,对于不同领域的网页,互联网数据差异主要体现在网页结构的不同,对于正文描述文本而言,语言的表达习惯基本相同,数据的来源并不会产生太大的影响.表 1给出了不同领域数据来源的详细描述.
| 行业 | 网页数 | 详细网站 |
| 钢铁 | 18 945 | 富宝资讯、中国钢铁新闻网、中国联合钢铁网 |
| 船舶 | 21 067 | 中国造船网、中国船舶新闻网、中国船舶网 |
| 房地产 | 19 324 | 中国房地产信息网、新浪地产、凤凰房产 |
表 2是本文关系抽取中使用到的部分自定义单位词,其中有些单位词是各个行业通用的,如“元,万元,亿元,万亿元,美元”等单位词,在钢铁、船舶、房地产行业都有使用.目前该词表还在继续补充完善中.
| 行业 | 部分单位词 |
| 钢铁 | 吨,万吨,元/吨,美元/吨,元,万元,亿元,万亿元,美元,亿美元 |
| 船舶 | 艘,吨,万吨,载重吨,万载重吨,净载重吨,总吨,万总吨 |
| 房地产 | 万平方米,公顷,万公顷,元/平方米,万/亩,万元/亩,万元/平米,万套 |
计算抽取结果与原句之间的相似度,采用了余弦相似度和Jaro-Winkler距离两种方案,使用了3种计算方法进行分析,如表 3所示.在本文关系抽取中,是抽取原句不同部分字符串,最终得到“(实体对象,实体特征,实体属性值)”结果,针对大量复杂的句子文本,其中实体对象可能是由很多名词实体字符串组成,为了选择最优且最少的名词实体,采用Jaro-Winkler距离算法,实验对比了分词和不进行分词两种情况,证明在分词条件下,Jaro-Winkler更适合短字符串相似度的度量;最后结合传统的余弦相似度进行对比,分词条件下Jaro-Winkler计算相似度效果最好.Jaro-Winkler距离方案中的温克勒阈值参数的默认值为0.7,经过实验优化,只有当Winkler阈值为0.7的时候,实验效果最好.
| 方法 | 描述 |
| JARO-HS | 抽取结果进行分词之后与原句的分词结果进行相似度计算 |
| JARO-NS | 抽取的结果不进行分词直接与原句进行相似度计算 |
| TF-IDF/CS | 利用文本向量余弦相似度方法计算抽取结果和原句的相似度 |
表 3中,JARO代表使用Jaro-Winkler距离算法,HS代表进行分词,NS代表不进行分词,TF-IDF指文本向量,CS指余弦相似度,JARO-HS指进行分词的条件下采用Jaro-Winkler距离算法;JARO-NS指不进行分词的条件下采用Jaro-Winkler距离算法;TF-IDF/CS指采用文本向量余弦相似度.
对于从网络文本中抽取的数值型3元组结果,本文采用抽查的方式判断其准确性.分别随机从3个行业的抽取结果中,各选择1 000个三元组关系,共计3 000个,分为4组,每组由3个人进行人工评测,如果对某个结果评测有分歧,就以少数服从多数的规则确定评测结果.计算准确率(P)计算如下:
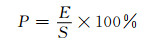
|
(5) |
其中E代表人工评测认为准确的三元组个数,S代表参与评测的具有属性值三元组抽取结果总数.
由于缺乏人工标注的训练语料,难以与现有的有监督方法进行比较.文献[7, 8]基于词汇-句法模式的属性值抽取方法是目前使用最广泛的抽取模式.本文的研究中也实现了基于词汇-句法模式的中文抽取方法,并与上述抽取的3 000个三元组关系对应的网页文本进行对比实验.将该模式抽取的结果也进行人工打分,对比实验中采用准确率,召回率(R)和F值作为三元组抽取结果的评价标准.计算召回率(R),F值如下:
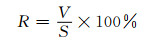
|
(6) |
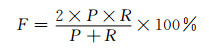
|
(7) |
V代表正确且有实际价值的三元组抽取结果数量.
2.2 实验分析表 4是对例1文本进行抽取的结果分析,Onm中的O代表文本句子中名词实体,n代表名词实体的总数,m代表从当前句子的名词实体集中选择的名词个数.
| 实体个数 | 随机实体对象 | 抽取结果 |
| On1 | 产品 | 产品销售2.83亿台 |
| On2 | 全国产品 | 全国产品销售2.83亿台 |
| On3 | 全国家电产品 | 全国家电产品销售2.83亿台 |
| On4 | 全国家电下乡产品 | 全国家电下乡产品销售2.83亿台 |
从表 4中可以看出,名词实体选择越多,抽取效果越好,但是当完全一样的时候,几乎与原句是一致的,这说明这种抽取方法能够达到实际目的.
表 5对数值型关系三元组结果进行语义相似度计算,表中的值是当前所有情况下的均值,其大小反应了抽取结果与原句的相似度.从表 5中可以发现,随着名词实体选取越多,抽取结果与原句的相似度也越高,其中采用JARO-HS方法计算的结果在与原句的相似度上明显比JARO-NS要低,但是采用分词之后再进行相似度计算效果更好,选取的名词实体个数少,更接近温克勒阈值0.7这个参数值;采用TF-IDF/CS方法计算的结果在与原句的相似度上明显比Jaro-Winkler方法要低,但是与温克勒阈值0.7参数值更接近.
| 实体个数 | JARO-HS | JARO-NS | TF-IDF/CS |
| On1 | 0.370 | 0.370 | 0.535 |
| On2 | 0.804 | 0.830 | 0.655 |
| On3 | 0.832 | 0.875 | 0.756 |
| On4 | 0.863 | 0.918 | 0.845 |
图 6是对选择的三种计算方法采用均值进行分析,其中AVG指的是三种方法的均值,Y轴是各种方法得到的结果值与温克勒阈值0.7的差值的绝对值,X轴是表示从当前分析的句子中存在的n个名词实体中选取的名词实体个数.以温克勒阈值0.7作为基准线,来衡量相似度,是因为对原句进行抽取之后不可能跟原句一样,会去掉原句的一部分,如停用词、并列名词实体等,如果相似度较低,比如小于0.5,肯定与原句意义不符;如果相似度很高,比如大于0.9,说明原句的很多部分都被保留,将导致抽取结果基本跟原句一样,这与抽取目标相悖.同时在使用Jaro-Winkler计算时也是以0.7作为基准判断是否需要重新计算相似度.通过直方图很明显的可以看出,当选择的名词个数为2或3的时候,差值的绝对值最小,也正符合抽取的目标,从原句中抽取2到3个名词实体构成对象实体;同时也可以看出JARO-HS的效果与AVG最接近,波动小,整体上效果最好,从图 6中可以直观的看出,采用JARO-HS有很大的优势.

|
| 图 6 相似度均值与Winkler阈值差值的对比 Figure 6 Comparison of the difference between average similarity and Winkler threshold |
表 6是进行人工评测的结果,“抽取结果是否准确”的标准如下:如果该条结果符合“(实体对象,实体特征,实体属性值)”这种三元组形式,那么就认为这条结果是准确的,否则就不准确.从人工评测结果来看,本文使用的无监督抽取方法,能够抽取中文实体数值型三元组关系,其人工评测的准确率效果不错,在钢铁、船舶、房地产各自行业都有80%以上的准确率,说明该方法适用于不同领域的实体数值型关系抽取.
| 行业 | P/% | 抽取示例 |
| 钢铁 | 90.80 | 螺纹钢出厂价格2 260元/吨、唐山钢坯上涨30元/吨、热轧每吨降300元、中建钢构产值突破100亿元 |
| 船舶 | 81.60 | 现代重工造船订单60艘、散货船出口额4.2亿美元、液化气船订单量下降75%、招商轮船运营油轮订单10艘 |
| 房地产 | 85.50 | 房地产开发投资17 677亿元、住宅开发投资11 670亿元、商业营业用房开发投资2 712亿元、办公楼开发投资1 242亿元 |
从表 7可以看出,词汇-句法模式抽取方法的准确率跟本文方法基本相差不大,甚至比本文方法稍好,但是召回率较低,总体性能比本文方法稍差.
在实验中,存在抽取结果不理想的情况,主要原因有两个.首先是因为采用的斯坦福分词工具导致了名词对象识别错误,从而导致实体提取错误,对实验结果影响较大,例1的分词结果中就出现了“累计/AD计销/VV销售/NN”的组合歧义,正确结果应为“累计销售/VV”,对于复杂网络文本,本文方法还无法消解这种歧义;再者是因为在实验中采用人工评测的标准,判断抽取结果是否具有实用价值带有客观性的影响.
3 结论针对中文复杂文本,本文提出了一种无监督的中文实体数值型关系抽取方法,不需要大规模标注语料进行训练,也不需要预先定义模式进行提取,简单实用.这种方法在中文分词、词性标注等自然语言处理结果的基础上,首先经过句式分析,采用选择树算法构建候选集,接着利用Jaro-Winkler距离进行筛选,最后抽取数值型三元组关系,实验结果表明,中文实体数值型关系无监督抽取方法是有效的.目前,该方法已成功应用于某钢铁集团潜在下游行业客户的自动发现.
未来工作将继续尝试在船舶、家电、汽车、房地产等更大范围且更大规模的网络文本上进行实验,使得本文的方法具有更好的泛化能力,同时,将继续完善和降低预处理阶段名词对象分词错误对关系抽取的影响.
| [1] | ACE. The NIST ACE evaluation website[DB/OL].[2015-12-13]. http://www.nist.gov/speech/tests/ace/ace07/. |
| [2] | 陈立玮, 冯岩松, 赵东岩. 基于弱监督学习的海量网络数据关系抽取[J]. 计算机研究与发展 , 2015, 50 (9) : 1825–1835 CHEN L W, FENG Y S, ZHAO D Y. Extraction relation from the web via weakly supervised learning[J]. Journal of Computer Research and Development , 2015, 50 (9) : 1825–1835 |
| [3] | LI Q, YANG J, WANG J, et al. A new entity relation tuples filtration method for weakly supervised relation extraction[C]//Proceedings of the International Conference on Systems and Informatics. New York: IEEE, 2012:2393-2397. DOI: 10.1109/ICSAI.2012.6223535. |
| [4] | ZHAO Q, SUI Z. To extract ontology attribute value automatically based on WWW[C]//Proceedings of the International Conference on Natural Language Processing and Knowledge Engineering. New York: IEEE, 2008:1-7.DOI:101109/NLPKE.2008-4906749. |
| [5] | BAKALOV A, FUXMAN A, TALUKDAR P, et al. Scad: Collective discovery of attribute values[C]//Proceedings of WWW 2011. New York: ACM, 2011: 447-456. |
| [6] | HOFFMANN R, ZHANG C, LING X, et al. Knowledge-based weak supervision for information extraction of overlapping relations[C]//Proceedings of ACL-HLT 2011. Stroudsburg: ACL, 2011: 541-550. |
| [7] | LEE T, WANG Z, WANG H, et al. Attribute extraction and scoring: A probabilistic approach[C]//Proceedings of ICDE 2013. New York: IEEE Computer Society, 2013: 194-205. |
| [8] | 郭喜跃, 何婷婷, 胡小华, 等. 基于句法语义特征的中文实体关系抽取[J]. 中文信息学报 , 2014, 28 (6) : 183–189 GUO X Y, HE T T, HU X H, et al. Chinese named entity relation extraction based on syntactic and semantic features[J]. Journal of Chinese Information Processing , 2014, 28 (6) : 183–189 |
| [9] | BERGSMA S, VAN D B. Using conceptual class attributes to characterize social media users[C]//Proceedings of ACL 2013. Stroudsburg, PA: ACL, 2013: 710-720. |
| [10] | DAVIDOV D, RAPPOPORT A. Extraction and approximation of numerical attributes from the Web[C]//Proceedings of ACL 2010. Stroudsburg: ACL, 2010: 1308-1317. |
| [11] | CAFARELLA M J, BANKO M, ETZIONI O. Open information extraction from the Web: U. S.Patent 8938410[P]. 2015-1-20. |
| [12] | ETZIONI O, FADER A, CHRISTENSEN J, et al. Open information extraction: The second generation [EB/OL]. [2012-11-12]. https://turing.cs.washington.edu/papers/etzioni-ijcai2011.pdf. |
| [13] | SCHMITZ M, BART R, SODERLAND S, et al. Open language learning for information extraction[DB/OL].[2015-11-13]. http://anthology.aclweb.org/D/D12/D12-1048.pdf. |
| [14] | 贾真, 杨宇飞, 何大可, 等. 面向中文网络百科的属性和属性值抽取[J]. 北京大学学报:自然科学版 , 2014, 50 (1) : 41–47 JIA Z, YANG Y F, HE D K, et al. Attribute and attribute value extracted from Chinese online encyclopedia[J]. Acta Scientiarum Naturalium Universitatis Pekinensis , 2014, 50 (1) : 41–47 |
| [15] | 刘倩, 伍大勇, 刘悦, 等. 结合全局特征的命名实体属性值抽取[J]. 计算机研究与发展 , 2016, 53 (4) : 941–948 LIU Q, WU D Y, LIU Y, et al. Extracting attribute values for named entities based on global feature[J]. Journal of Computer Research and Development , 2016, 53 (4) : 941–948 |
| [16] | CRESTAN E, PANTEL P. Web-scale knowledge extraction from semi-structured tables[C]//Proceedings of WWW 2010. New York: ACM, 2010: 1081-1082. |
| [17] | YOSHINAGA N, TORISAWA K. Open-domain attribute-value acquisition from semi-structured texts[C]//Proceedings of the Workshop on Ontolex 2007. Berlin: Springer-Verlag, 2007: 55-66. |
| [18] | 吴春相. 现代汉语介词结构的语体考察[J]. 当代修辞学 , 2013 (4) : 52–61 WU C X. Study on the preposition structure in modern chinese[J]. Rhetoric , 2013 (4) : 52–61 |
| [19] | 钟浪生. 补语的认识与分析[J]. 语文教学通讯(学术刊) , 2014 (7) : 76–78 ZHONG L S. Cognition and analysis of complement[J]. The Communication of Chinese Teaching (Academic) , 2014 (7) : 76–78 |
| [20] | 黄承慧, 印鉴, 候昉. 一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J]. 计算机学报 , 2011, 34 (5) : 856–864 DOI:10.3724/SP.J.1016.2011.00856 HUANG C H, YIN J, HOU F. A text similarity measurement combining word semantic information with TF-IDF method[J]. Chinese Journal of Computers , 2011, 34 (5) : 856–864 |