 2017, Vol. 63
2017, Vol. 63
文章信息
- 刘金硕, 李哲, 叶馨, 陈嘉敏, 邓娟
- LIU Jinshuo, LI Zhe, YE Xin, CHEN Jiamin, DENG Juan
- 文本情感倾向性分析方法:bfsmPMI-SVM
- Sentiment Orientation of Text: bfsmPMI-SVM
- 武汉大学学报(理学版), 2017, 63(3): 259-264
- Journal of Wuhan University(Natural Science Edition), 2017, 63(3): 259-264
- http://dx.doi.org/10.14188/j.1671-8836.2017.03.011
-
文章历史
- 收稿日期:2016-06-07



引用本文

|



2. 武汉大学 国际软件学院,湖北 武汉 430079
2. International School of Software, Wuhan University, Wuhan 430079, Hubei, China
文本情感倾向性分析(sentiment orientation)是从文本中挖掘出用户对于某个事物发表的想法或者观点,进而判断该想法或者观点是褒义还是贬义[1].文本情感倾向性分析可以分为倾向性情感信息抽取[2~4]和情感倾向性分类[5~9]两个阶段.
倾向性情感信息抽取是从文本中找到具有情感倾向性的信息.通常先将待分析文本转化为向量或者其他框架的形式,然后再进行分析[10].倾向性分类是对给定的词语、句子、文本(篇章)进行情感倾向性或者情感倾向极性判断[11].
目前,已经有研究应用点互信息信息汲取方法(point mutual information-information research,PMI-IR)进行情感倾向性信息抽取.PMI-IR是结合PMI和IR的一种词语相似性度量模型[12].其基本原理是计算待测词语与事先选取的情感基准词在语料库里的共同出现的概率,从而得出该词语的情感极性.IR是指使用搜索引擎后台数据库来替代上述的语料库.PMI-IR目前被广泛用于词语级的相似性计算.Kaur等[13]用PMI-IR计算相似词,预测网络用户的搜索行为;Jin等[14]利用PMI-IR提取微博中的情感倾向词汇;Li等[15]采用PMI-IR寻找和命名实体相似的词汇,进行话题领域提取.
在进行文本情感倾向性分类时,一个重要的步骤就是特征选择.过高的特征维度,会造成分类计算的效率与精度的下降.互信息(mutual information,MI)作为信息论里一种两个事件集合之间的相关的信息度量,已经和文档频率、信息增益、统卡方统计等被用于文本的特征选择[16],但是MI模型会受到低频词的影响,使分类效果较差.
针对MI模型的不足之处,郑俊飞[17]引入最小特征冗余度量法,加入特征类频度和特征类内分散度两个参数,在计算特征词文档词频时设置其在文本中需要出现的最小词频, 抑制低频词对结果的干扰;刘海峰等[18]用权重因子对正、负相关特性加以区分,以修正因子的方式在MI中引入词频信息对低频词进行抑制,增加了特征项的位置信息.上述对MI模型的改进抑制了低频词对分类效果的影响,但在分类的准确度和召回率上仍有不足.借鉴上述研究,本文设计了bfsmPMI-SVM方法.该方法用改进的PMI-IR-mPMI-IR算法对情感倾向性词语抽取,扩充了正负基准词集;在文本特征抽取时引入了词频因子(f)、类别差异因子(b)和符号因子(s)来计算MI.
1 本文算法算法的整体思路如图 1.

|
| 图 1 文本情感倾向性分类算法bfsmPMI-SVM Figure 1 Classification of sentiment orientation of text: bfsmPMI-SVM |
为了减少领域依赖以及上下文依赖的影响,我们对文本进行了按照话题的聚类和文本内相关内容的提取(文本切片).在大数据的处理压力下,为了提高运算速度,在预处理阶段,本文采用基于词库的比对的方法.尽管基于比对的方法会受到词库精度的影响以及词库容量大小的影响,但是此方法会大幅提高处理速度,同时方便对相关领域话题进行交互式的修改.基本流程如图 2.

|
| 图 2 领域话题聚类和文档切片基本流程 Figure 2 Basic procedure of topic cluster and text slice |
1) 基于比对的话题领域划分:首先将文章标题与领域相关的主题语料库比对,如果主题出现,则按照主题分类,结束主题领域划分;如果主题没有出现在标题中,则再爬取文本的第一段进行字符串的搜索比对,然后统计主题在第一段出现的频率,如果频率大于一定的阈值,则完成主题领域的划分.
2) 文本切片:在领域相关的文本中,进行全文本的主题词比对,将含有主题词的句子提取出来,并且将无关的句子去掉,完成文本的切片.
3) 分词:将切片后的文本,利用分词工具分词.
4) 滤除停用词:去掉语气助词等非实体词.
例1:在食品领域选择下面文本

|
预处理时文本会被按照“花蛤”这个主题词进行主题聚类;其次,下划线的句子由于是包含主题词的句子,会被从文本中切片出来.
1.1.2 初始基准词集选取初始正、负基准词集的选取应满足如下特点:提取的基准词应为特定领域内比较常用的词语[19];正、负情感倾向要明显和强烈,具有代表性;上下文的关联度低.比如:“纸醉金迷”是比较强烈的贬义词,但这个词在食品安全领域就比较少用到,因此它不适合作为食品安全领域的初始基准词.
初始正、负基准词集由人工选取,各包含10个食品安全领域里的相关情感词语,如下:
初始正基准词集={满意,美味,健康,新鲜,卫生,营养,合格,达标,可口,很香}
初始负基准词集={差劲,致癌,昧良心,恶心,过期,虚假,超标,发霉,有毒,地沟油}
这些词语是食品安全领域比较常见的褒义词和贬义词.
1.2 文本情感倾向性词语扩充:mPMI-IR基于初始正、负基准词集的PMI-IR计算如下:

|
(1) |
其中,词语的概率p(x)是检索到词语x的页面个数与搜索的总页面个数的比值.而p(待测词, 基准词)则是把基准词和待测词放在一起使用搜索引擎进行检索得到的概率.
情感倾向性SO(sentiment orientation),可以通过PMI的如下运算得到:
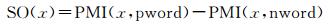
|
(2) |
其中pword表示正基准词,nword表示负基准词.由(2) 式可以得到词语x基于正、负基准集的情感倾向性表示为:
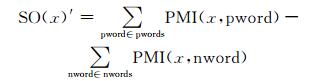
|
(3) |
pwords表示正基准词集,nwords表示负基准词集,(3) 式存在一定的局限性:随着正、负基准词集的逐渐扩充,正、负基准词集中元素的个数会发生变化,如果正、负基准词集中元素的个数相差很多,则互信息的值就会相差很多,有可能造成互信息相减的值有误甚至正、负极性判断错误,导致词性的褒贬性分析出现错误.所以基于正、负基准词中元素的个数不一的考虑,我们提出了一种改进的方法.将基准词集中词语的个数作为参数引入计算公式,计算出待测词语相对于基准词集平均互信息值求出SO.计算公式表示为:
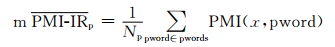
|
(4) |
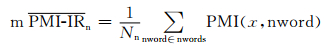
|
(5) |
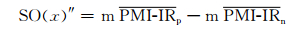
|
(6) |
其中, Np表示正基准词集中元素的个数,Nn表示负基准词集中元素的个数.
本文使用84 713条训练文本,通过mPMI-IR模型,得到扩充后的正、负基准词集,正基准词集扩充到461个,负基准词集扩充到574个.例1中:“花蛤的营养价值, 肉味鲜美、营养丰富,蛋白质含量高,氨基酸的种类组成及配比合理”, 因为“营养”已在正基准词集中,经过训练后,“鲜美”就会被加入正基准词集中.
1.3 基于改进MI的文本特征选取互信息MI是常用的语言学模型分析的计算方法,其计算公式如下:
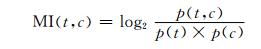
|
(7) |
其中t表示特征,c表示类别,MI(t, c)是互信息用来衡量类别与特征的相关度, p(t)表示出现特征t的文本频数与文本总数的比值,p(c)表示被归类到c的文本频数与文本总数的比值.p(t, c)表示同时出现t与c的文本频数与文本总数的比值.从计算公式看出,一个特征在整个文本中出现的概率越小则互信息MI的值就越大.
传统的计算互信息方法存在着一定的缺陷:
1) 当p(t1, cn)=p(t2, cn), 且p(t1)>p(t2),则MI(t1, cn)<MI(t2, cn).从互信息的计算公式中很明显的发现计算互信息方法对低频词t2赋予了更高的权重.这些词通常对于词语情感倾向性分析的贡献很少,不应赋予更高的权重.
2) 在实际操作中,互信息不考虑特征词的词频信息,使得大量特征的互信息值相等,只能从这些互信息值相等的词语中随机选取一些作为特征,这种随机模式可能使得一些重要词被忽略.
为了解决上述问题,减小低频词在互信息计算中的权重,提高高频词的计算结果对分类的影响,我们改进了MI计算公式,引入了词频因子f和类别差异因子b, 以及符号因子s.
首先引入f和b,
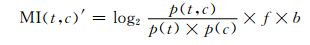
|
(8) |
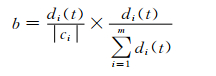
|
(9) |
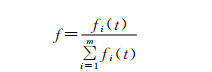
|
(10) |
其中di(t)表示在类别ci中,包含特征t的文档的数量,ci表示类别|ci|中文档的总数量.b值越大,表明特征t对分类的贡献程度越大.fi(t)表示ci类中特征t的出现次数,m表示文本包含的所有类别.
在计算特征的互信息量时,所有文本包含的类别不止一个,对所有的类别我们都会计算一个互信息值,而对这些所有类别的处理方法,通常采用选择最大值或者计算这些互信息的平均值.这些方法不考虑特征与类别之间的信息,使得在加权过程中效果欠佳.Forman[20]证明了正负相关对文本分类的特征选择和特征提取都有影响,缺一不可.不能只计算关于特征正相关的类别互信息量,而忽略负相关的类别.正相关的计算能够提高分类的准确率,起主要作用;负相关的计算能够提高分类的召回率,起次要作用.
考虑到所有正负相关类别对特征互信息值的影响,因此,再引入符号因子s(0<s<1),对(8) 式进行改进,当特征ti与类别正相关,其互信息公式可以表示为:
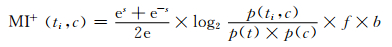
|
(11) |
当特征ti与类别负相关,互信息公式可以表示为:
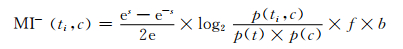
|
(12) |
假设文本集合有N个类别,则特征ti相对于整个文本集合的权值MI计算公式为:
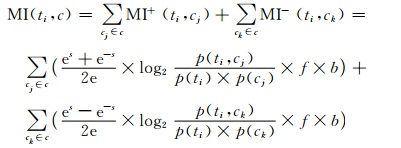
|
(13) |
在本文的文本情感倾向性分析研究中,一般类别就是两种:褒义和贬义.因此(13) 式就简化为:
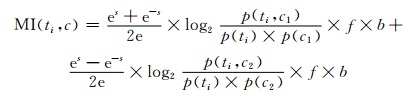
|
(14) |
其中,c1为正类别, c2为负类别.
1.4 SVM算法的文本褒贬分类经过改进的MI模型处理后,自动抽取文本中具有情感倾向性词汇,对词汇做正负极性判断, 抽取文本特征,再融合以下浅层特征:文档频率(document frequency, DF)、信息增益(information gain, IG)、卡方统计量、期望交叉熵(expected cross entropy, ECE)、词频逆文本频率(term frequency-inverse document frequency,TFIDF)、布尔权重、词频权重,作为SVM分类器的输入,输出文本的情感分类结果.
2 实验 2.1 实验环境与数据来源实验采用下列的软硬件环境:Intel Core i7 CPU,4GB内存和Windows7 32位操作系统,以Eclipse为开发环境,用Java开发语言.实验采用的数据集来源于网络爬虫爬取的数据,主要爬取自食品安全_99健康网、中国食品安全论坛官方网站、人民网食品频道、食品药品安全舆情网和新浪微博食品频道.在上述爬取的语料中,我们选取了6 300篇文本.用中科院的分词软件ICTCLAS,对文本集进行分词与停用词滤除.
2.2 实验结果为了评价本文的方法与模型的有效性,使用PMI-IR算法和MI算法进行文本特征提取,使用SVM分类作为对比试验.实验结果如表 1.
| % | ||||||||
| 算法 | 准确率 | 召回率 | F1值 | |||||
| 正向文本 | 负向文本 | 正向文本 | 负向文本 | 正向文本 | 负向文本 | |||
| PMI-IR-SVM | 68.3 | 75.6 | 69.5 | 74.8 | 68.8 | 75.2 | ||
| MI-SVM | 70.6 | 78.3 | 71.7 | 78.9 | 71.1 | 78.6 | ||
| 本文算法 | 76.2 | 84.3 | 75.8 | 83.2 | 75.9 | 83.2 | ||
与PMI-IR-SVM和MI-SVM算法分类结果相比,本文方法在准确率、召回率和F1值等评价标准方面都有提高.其中,负向文本的准确率和召回率相比于对比实验结果,有显著的提高, 分类精度明显提高.同时可见,文本算法在判断负向文本方面更有优势.本文实验的负向文本结果明显优于正向文本结果的原因可能在于训练文本中负向文本优于正向文本.
3 结论文本情感倾向性研究是对网络话题进行褒贬分类的一种有效方法.同传统的PMI-IR-SVM和MI-SVM的情感倾向分析算法相比,本文设计的bfsmPMI-SVM情感倾向性分类算法,提高了文本正负情感倾向性分类的准确率.
本文提出的情感倾向性分析算法,已应用于中国质量技术监督局“缺欠产品质量管理”项目.通过对微博、门户网站、论坛的文本进行正负情感倾向性进行分析,发现食品安全等问题.本文的方法对自然语言学习与网络舆情监控的相关领域的研究具有重要作用.同时,可以看出分类的准确率仍有较大的提升空间.下一步工作将继续改进MI算法模型,以期达到更好的分类效果.
| [1] |
徐琳宏, 林鸿飞, 杨志豪. 基于语义理解的文本倾向性识别机制[J]. 中文信息学报, 2007, 21(1): 96-100. XU L H, LIN H F, YANG Z H. Text orientation identification based on semantic comprehension[J]. Journal of Chinese Information Processing, 2007, 21(1): 96-100. |
| [2] |
张贺, 刘茂福, 胡慧君, 等. 基于信息单元融合的新闻原子事件抽取[J]. 武汉大学学报(理学版), 2015, 61(2): 139-144. ZHANG H, LIU M F, HU H J, et al. Atomic event based on information unit fusion[J]. Journal of Wuhan University(Natural Science Edition), 2015, 61(2): 139-144. DOI:10.14188/j.1671-8836.2015.02.006 |
| [3] |
朱少华, 李培峰, 朱巧明. 基于MLN的中文事件触发词推理方法[J]. 北京大学学报(自然科学版), 2016, 52(1): 89-96. ZHU S H, LI P F, ZHU Q M. A Chinese event trigger inference approach based on markov logic networks[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2016, 52(1): 89-96. DOI:10.13209/j.0479-8023.2016.012(Ch) |
| [4] |
尤涛, 徐伟, 杨凯. 广义无冗余情节规则抽取方法研究[J]. 电子学报, 2015, 43(2): 269-275. YOU T, XU W, YANG K. Research on extracting generalized non-redundant episode rules[J]. Acta Electronica Sinica, 2015, 43(2): 269-275. DOI:10.3969/j.issn.0372-2112.2015.02.010(Ch) |
| [5] |
陈豪, 刘功申. 基于句法分析的商品情感倾向性分析[J]. 信息安全与通信保密, 2013(2): 68-70. CHEN H, LIU G S. Sentiment classification of commodity based on the syntactic analysis[J]. Information Security and Communications Privacy, 2013(2): 68-70. DOI:10.3969/j.issn.1009-8054.2013.02.029(Ch) |
| [6] |
唐慧丰, 谭松波, 程学旗. 监督学习方法在语气挖掘中的应用研究[J]. 中文信息学报, 2007, 21(6): 88-94. TANG H F, TAN S B, CHENG X Q. Supervised learning in data mining of tone[J]. Journal of Chinese Information Processing, 2007, 21(6): 88-94. |
| [7] |
PAK A, PAROUBEK P. Twitter as a corpus for sentiment analysis and opinion mining[DB/OL][2016-06-10]. http://www.hughchristensen.co.uk/papers/socialNetworking/Twitter%20as%20a%20Corpus%20for%20Sentiment%20Analysis%20and%20Opin-ion%20Mining.pdf.
|
| [8] |
WHITELAW C, GARG N, ARGAMON S. Using Appraisal Groups for Sentiment Analysis [DB/OL].[2016-06-10].http://xueshu.baidu.com/s?wd=paperuri%3A%281c29464dbb5a542dfae6eeea3524e85e%29 & filter=sc_long_sign & tn=SE_xueshusource_2kduw22v & sc_vurl=http%3A%2F%2Fciteseerx.ist.psu.edu%2Fviewdoc%2Fdownload%3Fdoi%3D10.1.1.73.524%26rep%3Drep1%26type%3Dpdf & ie=utf-8 & sc_us=8944733647538512236.
|
| [9] |
彭敏, 汪清, 黄济民, 等. 基于情感分析技术的股票研究报告分类[J]. 武汉大学学报(理学版), 2015, 61(2): 124-130. PENG M, WANG Q, HUANG J M, et al. Stock research reports classification based on sentiment analysis[J]. Journal of Wuhan University (Natural Science Edition), 2015, 61(2): 124-130. DOI:10.14188/j.1671-8836.2015.02.004(Ch) |
| [10] |
黄萱菁, 张奇, 吴苑斌. 文本情感倾向分析[J]. 中文信息学报, 2011, 25(6): 118-126. HUANG X J, ZHANG Q, WU Y B. A survey on sentiment analysis[J]. Journal of Chinese Information Processing, 2011, 25(6): 118-126. DOI:10.3969/j.issn.1003-0077.2011.06.015(Ch) |
| [11] |
叶馨. 食品安全领域的倾向性分析算法研究[D]. 武汉: 武汉大学, 2015. YE X. Research of Sentiment Orientation Analysis of Food Safety Field [D]. Wuhan: Wuhan University, 2015(Ch). |
| [12] |
TURNEY P D. Mining the web for synonyms: PMI-IR versus LSA on TOEFL[J]. Computer Science, 2010, 2167: 491-502. |
| [13] |
KAUR I, HORNOF J A. A Comparison of LSA, WordNet and PMI-IR for Predicting User Click Behavior[C/OL].[2016-03-04]. http://ix.cs.uoregon.edu/~hornof/downloads/CHI05_Semantics.pdf.
|
| [14] |
JIN H, ZHU Y T, JIN Z Q, et al. Sentiment visualization on tweet stream[J]. Journal of Software, 2014, 9(9): 2348-2352. |
| [15] |
LI S, ZHOU L N, LI Y J. Improving aspect extraction by augmenting a frequency-based method with web-based similarity measures[J]. Information Processing & Management, 2015, 51(1): 58-67. |
| [16] |
PIERRE J M. On the Automated Classification of Web Sites [DB/OL].[2016-06-05].http://users.softlab.ntua.gr/facilities/public/AD/Text%20Categ-orization/On%20the%20Automated%20Classification%20of%20Web%20Sites.pdf.
|
| [17] |
郑俊飞. 文本分类特征选择与分类算法的改进[D]. 西安: 西安电子科技大学, 2012. ZHENG J F.Improvement on Feature Selection and Classification Algorithm for Text Classification [D]. Xi'an: Xidian University, 2012 (Ch). |
| [18] |
刘海峰, 陈琦, 张以皓. 一种基于互信息的改进文本特征选择[J]. 计算机工程与应用, 2012, 44(25): 1-4. LIU H F, CHEN Q, ZHANG Y H. Improved mutual information method of feature selection in text categorization[J]. Computer Engineering and Applications, 2012, 44(25): 1-4. DOI:10.3778/j.issn.1002-8331.2012.25.001(Ch) |
| [19] |
姚天昉, 程希文, 徐飞玉. 文本意见挖掘综述[J]. 中文信息学报, 2008, 22(3): 71-80. YAO T F, CHENG X W, XU F Y, et al. A survey of opinion mining for texts[J]. Journal of Chinese Information Processing, 2008, 22(3): 71-80. DOI:10.3969/j.issn.1003-0077.2008.03.010(Ch) |
| [20] |
FORMAN G. A Pitfall and Solution in Multi-Class Feature Selection for Text Classification[DB/OL].[2016-02-03].http://machinelearning.org/proceedings/icml2004/papers/107.pdf. DOI:10.1145/1015 330.1015356.
|