 2019, Vol. 65
2019, Vol. 65
文章信息
- 吴文君, 张玲, 肖春霞
- WU Wenjun, ZHANG Ling, XIAO Chunxia
- 基于深度信息的单幅图像自动阴影检测
- Automatic Shadow Detection from Single Image Based on Depth Cues
- 武汉大学学报(理学版), 2019, 65(5): 441-449
- Journal of Wuhan University(Natural Science Edition), 2019, 65(5): 441-449
- http://dx.doi.org/10.14188/j.1671-8836.2019.05.004
-
文章历史
- 收稿日期:2019-01-03



引用本文

|



阴影是生活中常见的自然现象, 可以为视觉场景的理解提供重要信息, 例如光照环境、场景几何结构等。这些信息对于光照分析、重光照、增强现实等方面的应用具有重要作用。因此, 在计算机视觉领域, 阴影检测工作是一个重要课题。
阴影检测算法根据是否需要人工交互可分为交互式阴影检测算法和自动阴影检测算法。1)交互式阴影检测算法[1, 2]需要人为标记阴影区域和非阴影区域样本, 根据标记信息以及色度等特征信息进一步对图像进行分割。Zhang等[1]利用简单的人工交互, 对图像阴影区域和非阴影区域进行标记, 再结合Levin等[2]提出的抠图算法, 将阴影区域分离出来。这类算法能有效处理单幅简单场景图像, 提高阴影检测的精度, 但对于复杂场景, 即场景结构多样, 阴影复杂的场景, 该方法需要更多的交互信息, 才能得到较完善的检测结果, 耗费人力且无法进行批处理。2)自动阴影检测算法分为传统方法和深度学习方法。①传统方法[3]主要通过对图像进行分区和分类处理, 对阴影区域进行标注。Guo等[3]利用基于分区的方法, 先将图像根据颜色等特征分成多个区域, 再对不同区域预测其相对光照条件, 并将阴影区域与非阴影区域按对分类, 最后通过训练分类器划分出阴影区域和非阴影区域。该类算法适用于硬阴影, 即颜色较深且边界梯度变化较大的阴影, 对于颜色较浅且没有明显边界的软阴影及半影区域处理效果较差, 可能将图像中的软阴影划分为非阴影区域。②深度学习方法[4~9]是通过对大量数据集进行学习, 训练神经网络模型, 提取出图像更深层次的特征, 从而预测图像的阴影区域。其中, Khan等[4]将深度学习引入图像的阴影检测中, 通过训练卷积神经网络对图像中的阴影进行标注。Nguyen等[7]将条件生成式对抗神经网络引入阴影检测中, 结合更高层级的语义关系及全局场景特征, 得到了较好的阴影检测结果。Wang等[8]进一步基于栈, 结合生成式对抗神经网络提出了新的阴影检测算法。Hu等[9]通过分析方向已知的空间上下文信息, 学习图像的全局语义并进行阴影检测。该类基于深度学习的方法对于简单场景的硬阴影检测效果非常好, Hu提出的方法对于软阴影的检测也有一定的效果。但是由于深度学习的方法依赖于训练集, 大多数训练集中的图像都是简单场景, 并且阴影类型也比较简单; 对于复杂场景和复杂阴影, 如树影等, 人工标注的代价比较大, 难以构建较多训练集, 且对于软阴影, 存在人工标注困难等问题。
近年来, Kinect等深度信息采集设备迅速发展, 为计算机视觉的发展带来了更多的可能性。深度信息有助于图像场景结构的分析以及三维平面的获取, 在图像处理中引入图像的深度信息, 可进行图像的本征分解[10]、阴影消除[11]等工作。Xiao等[11]提出利用图像深度信息进行阴影消除工作, 利用Kinect采集到的深度信息, 估计每个像素点的法线信息, 利用每个像素点与其局部邻域的邻居像素点间的法线、色度、空间位置等特征信息的相似度, 估计每个像素点的阴影置信度, 进一步进行阴影消除。该算法有效地利用了深度信息, 极大地提高了复杂场景中的阴影消除效果。但该算法没有提出具体的阴影检测方法, 由于阴影置信度对阴影边界附近的像素点更敏感, 离边界较远的像素点无法检测完全; 且置信度的估计容易受到纹理信息的影响, 对于纹理复杂的场景, 如草地等, 阴影检测较为困难。
阴影检测不仅受图像局部纹理材质信息的影响, 还受场景中的全局结构信息及光照环境信息的影响。因此, 本文提出一种基于深度信息的单幅图像自动阴影检测算法。首先利用深度信息估计图像的法线信息和三维点云位置信息, 并对原图像进行多尺度滤波, 减少纹理对图像阴影置信度估计[11]的影响; 然后利用法线、点云和色度信息对不同尺度下的滤波图像进行阴影置信度和亮度置信度的估计[11], 再将不同尺度下估计的阴影置信度和亮度置信度分别进行阴影边界相关的多尺度融合; 最后利用基于拉普拉斯算子[2]的插值优化算法, 得到更全面的阴影检测结果。
1 置信度估计方法为了解决复杂场景的阴影检测问题, 本文利用文献[11, 12]方法, 估计各像素点的初始阴影置信度和图像的阴影边界置信度。
1.1 基于图像深度信息的阴影置信度估计方法文献[11]提出利用图像深度信息估计阴影置信度。不同于传统阴影检测方法的二值检测结果, 在该算法中, 阴影置信度图为灰度图像, 通过为每个像素点赋予一个0~1之间的值表示该像素点为阴影的可能性。阴影置信度值越大, 该点的阴影强度越大, 则该像素点越可能为阴影点。文献[11]的算法首先利用图像的深度信息, 估计每个像素点的法线信息和点云信息。然后, 对于每个像素点p, 估计它的空间邻域范围Np, 通过计算p与邻域像素点q (q ∈ Np)间的法线相似度αpqn、空间位置相似度αpqd以及色度相似度αpqc, 估计邻域内像素点间的相似度αpq:
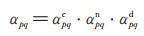
|
(1) |
求得每个像素点p与邻域像素点q间的相似度后, 利用(2)式和(3)式可以求得像素点p处的阴影置信度CpS和亮度置信度CpB:
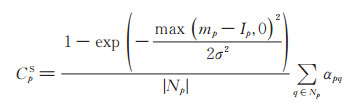
|
(2) |
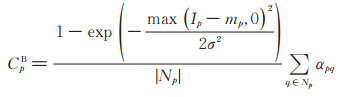
|
(3) |
其中, p点所在邻域的加权平均光照强度mp为:
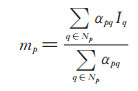
|
Ip和Iq分别表示像素点p和q的强度, σ为可调参数, 通常将其设为0. 1, |Np|表示邻域范围Np中的像素点个数。
由(2)式可以推测, 当邻域范围Np内同时存在阴影像素点和非阴影像素点时, 若p点为阴影像素点, 则Ip将小于局部邻域内像素的平均强度mp, CpS将被赋予0~1间一个较高的阴影置信度值。如果p点为非阴影像素点, 则Ip将大于mp, (2)式中指数函数的结果为1, CpS的值为0。当局部邻域Np内只有阴影像素或非阴影像素时, Ip与平均强度mp的值将非常接近, 因此, CpS的值将趋近于0。同理, 亮度置信度CpB有类似的性质, 当p为非阴影像素点且其邻域内同时包含阴影像素点和非阴影像素点时, CpB将被赋予较高的亮度置信度值, 否则, 其值将趋近于0。
利用文献[11]提出的算法, 可以较准确地估计阴影边界附近像素点的阴影置信度值。但对于距离阴影边界较远的像素点, 其阴影置信度的结果可能趋近于0, 即无法检测为阴影像素点。
1.2 基于邻域变差的阴影边界置信度估计方法类似于阴影置信度, 阴影边界置信度用以估计图中每个像素点可能是阴影边界部分的可能性。文献[11]和[12]通过计算各像素邻域内的全变差和固有变差, 估计阴影边界置信度:
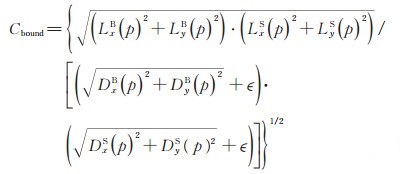
|
(4) |
其中, ϵ通常设为0. 001, 避免出现分母为0的情况。D和L分别为全变差和固有变差:
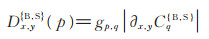
|
(5) |
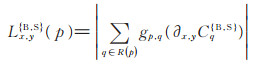
|
(6) |
式中, R (p)是以p为中心点的矩形邻域, gp, q表示由高斯滤波定义的权函数, CqS和CqB可分别通过(2)式和(3)式计算得到。通常置信度图阴影边界区域的偏导数比纹理区域的偏导数更大, 从而会有更大的固有变差L, 因此会得到更大的阴影边界置信度Cbound。
2 本文算法本文提出一种基于图像深度信息的自动阴影检测算法。该算法利用图像及其对应的深度信息, 实现单幅图像的自动阴影检测。具体流程如图 1所示。

|
| 图 1 算法流程图 Fig. 1 Algorithm flow chart |
具体步骤如下:
1) 获取图像深度信息。
2) 采用纹理滤波算法对输入图像进行多尺度滤波, 在不同程度上减少纹理对阴影置信度估计的影响; 同时, 利用图像的深度信息计算原图中各个像素点的法线和点云信息;
3) 利用置信度估计算法[11], 计算像素点间的色度、点云和法线特征的相似度, 估计不同尺度滤波图像的的初始阴影置信度和亮度置信度;
4) 将估计的阴影置信度和亮度置信度分别进行阴影边界相关的多尺度融合;
5) 利用基于拉普拉斯算子[2]的插值优化, 在得到更完善的阴影检测结果的同时保留阴影边界梯度信息。
下文将详细介绍每一个步骤。
2.1 图像深度获取复杂场景中, 图像深度信息是一个非常重要的信息, 它可以为图像场景结构分析以及空间距离分析提供帮助, 利用这些信息可以更好地检测阴影。深度信息可以通过两种途径获取:
1) 利用Kinect等深度信息采集设备扫描, 直接获取场景图像及其对应的深度信息。
2) 对于既有的图像, 无法采集对应的深度信息, 可以利用现有的深度估计算法[13]估计图像的深度信息, 进而进行阴影检测。
本文算法利用Godard等[13]提出的算法估计图像深度信息。该算法为非监督学习, 训练时不需要高质量的真实图像深度信息, 且在损失函数中加入了左右一致性矫正, 估计得到的图像深度信息比较理想。图 2为采用文献[13]提出的算法对既有图像的深度进行估计的结果。如图 2(b)所示, 深度图较好地保留了原图中椅子的几何形状, 且背景深度未受到树丛纹理的影响, 与实际深度较相符。

|
| 图 2 图像及对应的估计深度图 Fig. 2 Image and its corresponding estimated depth map |
由于初始阴影置信度估计对阴影边界附近的像素点估计结果较为准确, 而对于远离边界的像素点估计结果较差; 对于纹理复杂的区域, 在光照条件相同的情况下, 可能将纹理中颜色较深的像素点检测为阴影点, 而把颜色较浅的像素点检测为非阴影点, 得到错误的阴影检测结果。对于纹理复杂的图像, 可通过(7)式进行多尺度纹理滤波处理[14, 15], 尽量减少纹理对初始置信度估计的影响。纹理滤波的结果为:
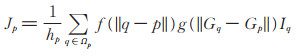
|
(7) |
其中, Ωp为以p为中心像素的c × c矩形邻域, q为邻域Ωp内的邻居像素点, Iq为像素点q对应的强度, Gp和Gq分别为由输入图像计算得到的像素点p和q对应的纹理描述算子, f和g为高斯函数, hp为归一化项。
然而图像滤波后有一个弊端, 即大尺度纹理滤波结果可能会将复杂细小的阴影模糊掉, 比如阴影边界复杂的树影等。考虑到单尺度纹理滤波的不足, 本文利用多尺度滤波算法[14, 15], 对不同尺度下的置信度结果进行融合, 减少纹理影响的同时保留阴影边界信息。首先对输入图像进行多尺度下的纹理滤波, 滤波尺度主要依靠邻域边长a和滤波迭代次数t进行控制, 图像滤波结果用Jat表示。如图 3所示, 图 3(a)为输入的原图像, 图 3(b)和图 3(c)为迭代次数等于3, 滤波块分别为5×5和7×7时, 纹理滤波的效果图, 将图 3(b)和图 3(c)所示滤波结果记为J53、J37。实验中, 通常当t=3时即可得到理想的滤波结果; 滤波块为7×7时, 足以平滑大多数纹理信息。然而考虑到滤波尺度过大时可能模糊一些小尺度结构信息和阴影边界信息, 因此考虑将滤波大小为5×5的结果作为中间值, 尽可能减少小尺度信息的损失。

|
| 图 3 图像及其不同尺度下的滤波结果 Fig. 3 Image and its filtering results of different scales |
利用多尺度滤波可以从不同尺度上削弱纹理对阴影检测的影响, 有助于算法对小尺度阴影信息和结构信息的保留。为了更好地估计复杂场景阴影信息, 本文基于阴影置信度估计算法[11]对不同尺度下的滤波图像进行阴影置信度的估计。
文献[11]中利用简单的高斯相似度计算法线特征相似度, 在一定程度上减少了空间法向量的三维优势, 削弱了方向特征的权重。虽然对于检测法平面上的阴影点较为有效, 但对于法线变化的弧平面, 难以估计准确的法线相似度, 可能会将弧平面上明暗渐变的投影信息估计为阴影。为了解决这个问题, 改进法线相似度的计算, 本文构造如下优化方程:
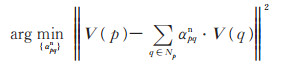
|
(8) |
其中, Ω表示包含图像中所有像素点的点集, V (p)和V (q)分别为p及其邻域像素点q的法向量。利用优化方程(8)可以更好地约束法线相似度的权重, 尤其是对于曲面上的像素点, 计算所得的法线相似度更准确。因此, 将由(8)式计算所得的αpqn代入(1)式可以得到更准确的邻域内像素点间的相似度αpq, 再将αpq代入(2)式和(3)式, 可得到更理想的初始阴影置信度和亮度置信度估计值。
图 4为利用改进后的阴影置信度算法对原图和不同尺度滤波图进行阴影置信度估计的结果。图 4(a)为输入的原图像对应的阴影置信度C0S; 图 4(b)和图 4(c)分别为滤波图像J53和J73对应的阴影置信度结果Cf1S和Cf2S。阴影置信度通过(1)式、(2)式和(8)式计算得到。

|
| 图 4 图像及其对应的阴影置信度结果 Fig. 4 Images and their corresponding shadow confidence results |
如图 3(b)和图 3(c)所示, 滤波后图像中结构信息以及投影信息仍然保留, 但在一定程度上损失了小尺度阴影信息, 不利于复杂阴影边界信息的保留。图 4(a)中, 在纹理复杂的地面上, 受纹理的干扰, 阴影置信度算法检测出的阴影边界模糊, 杂点较多; 图 4(b)和图 4(c)虽然在一定程度上降低了纹理影响, 减少了杂点, 却损失了不少阴影边界信息。为了减少这些细节损失, 在降低纹理影响的同时尽可能保留阴影边界信息, 算法将对不同尺度下的置信度检测结果进行阴影边界相关的融合。
2.4 置信度多尺度融合为了保留复杂的阴影边界信息并减小图像纹理对阴影检测的影响, 对于阴影边界附近的像素点, 采用由原图像估计的C0S, 以保留更精确的边界估计结果; 对于其他区域像素点, 采用两个不同尺度下滤波后的图像估计的Cf1S和Cf2S, 进行阴影边界相关的融合, 在尽量保留阴影边界信息的同时减少纹理细节对阴影检测结果的影响。
为了将不同尺度下的阴影置信度融合, 首先需要对阴影边界范围进行估计, 然后对二值边界检测图进行膨胀处理, 估算各尺度下阴影置信度的融合范围。本文采用(4)式估计图像的边界置信度, 为了减少纹理细节的影响, 通常用7×7滤波图像计算阴影边界置信度。图 5展示了阴影置信度图的优化过程。其中, 图 5(a)为原图(图 3(a))经7×7滤波后计算得到的阴影边界置信度Cbound。令Cbound > 0.1, 可得到阴影边界的二值检测图, 为了更直观地展示融合过程, 对二值检测图进行适当的开操作, 仅保留两条较明显的阴影边界, 如图 5(b)所示。在图 5(b)中, 对二值检测结果做两次膨胀处理, 估算融合范围, 其中红色区域为M1, 代表阴影边界区域; 蓝色区域为M2, 代表过渡区域。为了更精确地检测复杂的阴影边界, 在阴影边界区域M1使用较精确的阴影检测结果C0S, 以保留更完整的阴影边界梯度信息, 其他部分使用较粗糙的阴影检测结果Cf1S和Cf2S, 以减少纹理信息的干扰。M2区域使用5×5滤波下的置信度Cf1S进行融合, 其他区域使用Cf2S进行融合, 得到纹理噪声较小的阴影置信度Cs0S
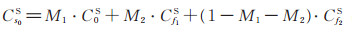
|
(9) |

|
| 图 5 置信度的多尺度融合及优化 Fig. 5 Multi-scale fusion and optimization of the confidence maps |
同理, 利用多尺度滤波算法优化可得到纹理噪声较小的亮度置信度Cb0B。Cs0S和Cb0B的结果分别如图 5(c)和图 5(d)所示。
在阴影置信度估计算法中, 为了得到更准确的阴影检测结果, 通常设置阴影检测半径为50~100像素。然而对于范围较大的阴影, 仅利用多尺度纹理滤波算法无法准确估算离阴影边界较远的阴影像素点的置信度。
2.5 插值优化由上文可知, 利用多尺度优化求得的阴影置信度Cs0S和亮度置信度Cb0B仍不够完善。为了更好地检测阴影, 本文利用拉普拉斯坐标法(Laplacian coordinate methodology)[2, 16]进行插值优化, 将阴影置信度Cs0S和亮度置信度Cb0B作为数据约束项的权重, 从而对离阴影边界较远的像素点进行插值估计, 得到更完整的阴影置信度图, 构造的能量方程如下:
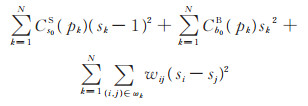
|
(10) |
其中, 前两项为数据约束项, 第三项为平滑项。pk表示第k个像素点, N为图像中阴影总个数, sk为第k个像素点的阴影置信度优化结果, ωk为第k个像素点所在的局部窗口, si和sj为窗口ωk内的两个像素点i和j对应的阴影置信度优化结果, 用于平滑窗口内的像素点, wij是邻域内i和j点的matting Laplacian值[2], 定义如下:
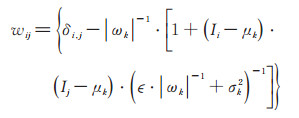
|
(11) |
其中, δi, j是克罗内克函数, ϵ为正则化参数, Ii和Ij为像素点i和j处的图像强度, μk和σk2分别是第k个局部窗口ωk的图像强度的均值和方差, |ωk|是该窗口内像素点的个数。利用该平滑项, 不仅可以完善阴影检测结果, 也能提高对边界复杂的软阴影的检测精确度。
对于阴影置信度比较大的像素点k, (10)式中第一项数据项将约束sk趋近于1, 而对于阴影置信度较小的点, 即亮度置信度较大的点, 第二项数据项将约束sk趋近于0。由(2)式分析可知, 对于检测邻域中只存在阴影像素点或只有非阴影像素点的情况, 可能导致该点阴影置信度和亮度置信度都很小, 这种情况下, 前两项数据项都无法对sk有较强的约束, 因此引入第三项平滑项。图 6为将融合后的置信度图Cs0S和Cb0B带入优化方程式(10)得到的优化后的阴影置信度s(原图为图 5(a))。

|
| 图 6 阴影置信度优化结果s Fig. 6 Optimized shadow confidence result s |
不同于传统的二值阴影检测结果, 本文算法的阴影检测信息用一个灰度图像代替, 完整地保留了阴影信息及阴影边界的梯度信息。该阴影置信度图中, 每个像素点的值代表该像素位于阴影区域的可能性, 是本文算法最终的阴影检测结果。
3 实验结果与分析 3.1 视觉比较为了验证本文算法的有效性, 选取6张室外图像和3张室内图像作为实验对象, 将本文算法的阴影检测结果与其他方法的结果进行视觉比较。对6张室外图像使用深度估计算法[13]估计深度信息后, 进行阴影检测, 如图 7所示; 对3张室内图像用微软Kinect v2(深度图分辨率512×424)实时采集真实深度信息后计算阴影检测结果, 如图 8所示。

|
| 图 7 基于估计深度信息的图像阴影检测结果 Fig. 7 Shadow detecting results of the images based on estimated depth maps |

|
| 图 8 基于真实深度信息的图像阴影检测结果 Fig. 8 Shadow detecting results of the images based on ground truth depth map |
在图 7和图 8中, 将估算得到的阴影置信度结果同文献[1, 3, 8, 9, 11]的阴影检测算法估算结果进行了视觉比较。由比较分析可知, 文献[3]的方法对于复杂细小的阴影检测效果不够理想, 如图 7(b)第4行结果所示, 细小的阴影通常难以单独分离出来, 如图 7(b)中第1行结果所示, 该方法还可能将同一平面上的硬阴影和软阴影估计为阴影和非阴影区。文献[11]的方法虽然可以检测复杂场景的阴影, 但是该方法比较依赖真实深度信息, 利用估计的深度难以得到理想的检测结果, 且该方法容易受纹理信息的影响。如图 7(c)第3行和4行结果所示, 由于图像纹理比较丰富, 文献[11]的方法难以检测出明确的阴影信息。文献[1]的方法是基于人工交互的, 对于简单场景的阴影检测效果很好, 对于复杂场景, 如图 8(d)中第3行结果所示, 简单的人工交互无法检测出全部的阴影, 复杂的场景意味着更多的人工交互, 给用户带来巨大的不便。
文献[8]和文献[9]的方法是基于深度学习的, 对于大多数简单场景及简单阴影都有不错的检测效果, 然而对于复杂场景, 由于标注困难等原因, 缺乏类似的训练集, 阴影检测的结果并不理想, 如图 8(e)和图 8(f)中的结果所示。其中文献[8]的方法在网络训练时所需要的先验条件较多, 且存在网络不稳定的特性, 对于软阴影以及深色物体上的阴影检测效果较差, 如图 7(e)中第1行和第5行结果所示。文献[9]方法对于大部分简单场景内的硬阴影都有较好的检测效果, 但是对过于细小复杂的阴影难以检测完全, 如图 7(f)第2行和第4行结果所示。对于场景中的软阴影, 如图 8(f)最后一行结果所示, 桌布上的软阴影由于和非阴影区域差别较小, 无法检测出来。
本文算法的阴影置信度检测结果如图 7(g)和图 8(g)所示, 对于复杂场景和简单场景的阴影检测结果均较理想, 不仅检测出了场景中的硬阴影、软阴影及小尺度阴影(如图 8(g)第2行), 还保留了复杂的阴影边界梯度信息(如图 7(g)第6行), 阴影边界部分复杂的树影也被检测出, 且在纹理复杂的情况下能够尽量减少纹理信息的影响, 检测出较准确的阴影(如图 7(g)第3行)。在复杂场景的检测结果中, 本文算法利用深度信息, 在不同空间平面进行阴影检测, 有效避免了将非阴影深色区域检测为阴影, 如图 8(g)第3行所示。
3.2 客观评价为了考察本文算法的鲁棒性, 客观评价算法的阴影检测效果, 选取两个标准数据库进行量化分析。第一个数据库是SBU数据库[17], 该数据库包含大量不同场景的阴影图像以及对应的阴影标记结果, 其中有4 089张训练图像和638张测试图像; 第二个数据库是ISTD[8], 其中包含1 340张训练图像和530张测试图像, 并且包含了135种不同地面场景。本文采用2种常用的阴影量化比较标准进行评价, 准确度可由下式计算得到:
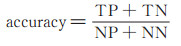
|
(12) |
其中, TP、TN、NP和NN分别是估计正确的阴影像素点个数(估计出的阴影像素点与真实阴影像素点的交集), 估计正确的非阴影像素个数(估计的非阴影像素点与真实非阴影像素点的交集), 真实阴影像素点个数和真实非阴影像素点个数。
由于自然图像中, 阴影像素点通常比非阴影像素点少, 为了平等比较两者估计的准确率, 本文使用的第二个度量标准为平衡出错率(balance error rate, BER):
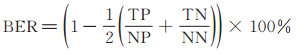
|
(13) |
accuracy越大说明阴影检测结果越准确, 而BER越小, 代表检测出错率越低。
将本文的阴影置信度二值化后与文献[3, 8, 9, 11]中的算法所得的阴影检测结果二值化后进行量化比较, 结果如表 1所示。由于文献[1]为交互式阴影检测, 因此不做量化比较。由表 1可知, 对于两个标准数据集中的图像, 本文算法的准确率和平衡出错率评价结果都较为可观。在SBU数据库中包含的复杂场景图像较多, 更能体现本文算法的优势, 本文算法对该数据库图像的阴影检测准确度最优, 平衡出错率最低。在ISTD数据库中, 其训练集多为简单图像, 这种情况下, 深度学习算法(文献[9])更占优势, 本文算法的量化结果虽为次优, 但与最优值非常接近。通过视觉比较和量化比较可以看出, 本文算法具有较好的鲁棒性, 对于复杂场景的阴影检测效果尤为突出。
本文提出一种基于深度信息的单幅图像自动阴影检测算法。首先利用深度信息估计每个像素点的点云信息以及法线信息, 再利用色度、点云及法线特征的相似度进行阴影置信度、亮度置信度以及边界置信度的估计; 然后通过多尺度滤波算法对图像进行滤波并计算各尺度下的阴影置信度和亮度置信度, 再将多尺度下的置信度检测结果进行融合, 在减少纹理信息对阴影检测影响的同时保留更精确的阴影边界附近的置信度; 最后, 利用拉普拉斯算子进行差值优化, 估计更完整的阴影信息且较好地保留阴影边界处的梯度信息。
本算法适用于复杂场景及复杂阴影的自动检测, 可以为阴影消除、图像本征分解、图像目标识别、场景分析等提供有效的预处理信息。未来的研究可将阴影检测算法运用于复杂场景视频阴影检测与消除工作中, 对本征图像分解中的阴影问题也有重要参考价值。
| [1] |
ZHANG L, ZHANG Q, XIAO C X. Shadow remover: Image shadow removal based on illumination recovering optimization[J]. IEEE Transactions on Image Processing, 2015, 24(11): 4623-4636. DOI:10.1109/TIP.2015.2465159 |
| [2] |
LEVIN A, LISCHINSKI D, WEISS Y. A closed-form solution to natural image matting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(2): 228-242. DOI:10.1109/TPAMI.2007.1177 |
| [3] |
GUO R Q, DAI Q Y, HOIEM D. Single-image shadow detection and removal using paired regions[C]//Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2011: 2033-2040. DOI: 10.1109/CVPR.2011.5995725.
|
| [4] |
KHAN S H, BENNAMOUN M, SOHEL F, et al. Automatic feature learning for robust shadow detection [C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). New York: IEEE Press, 2014: 1939-1946. DOI: 10.1109/CVPR.2014.249.
|
| [5] |
VICENTE Y, TOMAS F, HOAI M, et al. Leave-one-out kernel optimization for shadow detection[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision(ICCV). New York: IEEE Press, 2015: 3388-3396. DOI: 10.1109/ICCV.2015.387.
|
| [6] |
VICENTE T F Y, HOAI M, SAMARAS D. Leave-one-out kernel optimization for shadow detection and removal[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(3): 682-695. DOI:10.1109/TPAMI.2017.2691703 |
| [7] |
NGUYEN V, VICENTE Y, TOMAS F, et al. Shadow detection with conditional generative adversarial networks [C]//Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2017: 4510-4518. DOI: 10.1109/ICCV.2017.483.
|
| [8] |
WANG J F, LI X, HUI L, et al. Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal[C]//Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2018: 1788-1797. DOI: 10.1109/CVPR.2018.00192.
|
| [9] |
HU X, ZHU L, FU C W, et al. Direction-aware spatial context features for shadow detection[C]//Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). New York: IEEE Press, 2018: 7454-7462. DOI: 10.1109/CVPR.2018.00778.
|
| [10] |
JEON J, CHO S, TONG X, et al. Intrinsic image decomposition using structure-texture separation and surface normal[C]//2014 European Conference on Computer Vision(ECCV). Berlin: Springer, 2014: 218-233. DOI: 10.1007/978-3-319-10584-0_15.
|
| [11] |
XIAO Y, TSOUGENIS E, TANG C K. Shadow removal from single RGB-D images[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2014: 3011-3018. DOI: 10.1109/CVPR.2014.385.
|
| [12] |
XU L, YAN Q, XIA Y, et al. Structure extraction from texture via relative total variation[J]. ACM Transactions on Graphics(TOG), 2012, 31(6): 139-1-139-10. DOI:10.1145/2366145.2366158 |
| [13] |
GODARD C, MAC AODHA O, BROSTOW G J. Unsupervised monocular depth estimation with left-right consistency[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 270-279. DOI: 10.1109/CVPR.2017.699.
|
| [14] |
CHO H, LEE H, KANG H, et al. Bilateral texture filtering[J]. ACM Transactions on Graphics(TOG), 2014, 33(4): 128-1-128-8. DOI:10.1145/2601097.2601188 |
| [15] |
FATTAL R, AGRAWALA M, RUSINKIEWICZ S. Multiscale shape and detail enhancement from multi-light image collections[J]. ACM Transactions on Graphics (TOG), 2007, 26(3): 51-1-51-9. DOI:10.1145/1275808.1276441 |
| [16] |
CASACA W, GUSTAVO NONATO L, TAUBIN G. Laplacian coordinates for seeded image segmentation [C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2014: 384-391. DOI: 10.1109/CVPR.2014.56.
|
| [17] |
VICENTE T F Y, HOU L, YU C P, et al. Large-scale training of shadow detectors with noisily-annotated shadow examples[C]//European Conference on Computer Vision(ECCV). Berlin: Springer, 2016: 816-832. DOI: 10.1007/978-3-319-46466-4_49.
|