 2017, Vol. 63
2017, Vol. 63
文章信息
- 彭燊, 杨璐, 顾进广
- PENG Shen, YANG Lu, GU Jinguang
- 一种高密度关联数据压缩方案
- A High Density Linked-Data Compression Method
- 武汉大学学报(理学版), 2017, 63(5): 453-458
- Journal of Wuhan University(Natural Science Edition), 2017, 63(5): 453-458
- http://dx.doi.org/10.14188/j.1671-8836.2017.05.011
-
文章历史
- 收稿日期:2017-05-01



引用本文

|



2. 智能信息处理与实时工业系统湖北省重点实验室, 湖北 武汉 430065;
3. 湖北语言与智能信息处理研究基地(武汉大学), 湖北 武汉 430072
2. Hubei Province Key Laboratory of Intelligent Information Processing and Real-Time Industrial System, Wuhan 430065, Hubei, China;
3. Hubei Research Center for Language and Intelligent Information Processing(Wuhan University), Wuhan 430072, Hubei, China
W3C最先提出将RDF(Resource Description Framework)[1]作为处理元数据的基础,其目的在于定义一种广泛认可的资源描述机制.RDF基于主谓宾原子三元组〈S, P, O〉进行建模,其中主语“S”是被描述的资源,谓语“P”是资源属性,宾语“O”是资源属性值.
尽管RDF被广泛的使用,但是它并没有定义一种关联数据序列化的标准. W3C的RDF研究团队收集并推荐了几种实用的序列化标准,最原始的RDF/XML语法仍作为一种推荐的序列化标准,但是新生Turtle语法比它更受欢迎.W3C推荐的这些序列化标准采用了明文数据进行存储,为了保证可读性而包含了很多的冗余信息.近几年, 这些冗余信息导致关联数据在数据网络上存储时浪费了很多磁盘空间,同时让关联数据在网络上发布和传输变得更加困难.因此寻找一种高效的关联数据压缩方法,减少关联数据的体积具有重要意义.
1 研究现状文献[2]根据对现有的关联数据压缩方案的总结,将现有的压缩方法分为语法压缩和语义压缩两类.语法压缩是在序列化时采用更简洁的数据结构[3]来减少冗余信息的存储,而语义压缩是利用规则推理减少关联数据中三元组的数量,经过语义压缩的数据可再采用语法压缩方案进行压缩.两种方法都能在一定程度上压缩关联数据体积,但语义压缩的效果并没有语法压缩好.
HDT[4]是一种使用二进制格式存储关联数据的序列化标准,它取代了明文数据存储,减小了存储占用空间.HDT使用简洁的结构来减少冗余信息,因此是一种语法压缩方案,它将关联数据中的信息分解成三个部分:头部(Header)、字典(Dictionary)和三元组(Triples).头部保存了描述整个数据集的逻辑和物理元数据,例如数据集的来源、编辑信息以及数据集的一些统计信息等;字典将数据集中的资源映射为惟一标识ID,它用更简洁的ID代替资源实体字符串,减少了重复的资源实体字符串携带的巨大冗余信息存储;三元组部分用一种图结构存储了ID化的三元组关系,它采用了一种紧凑的线性比特预测位结构来表示资源实体直接的关系图.HDT保存了数据集的底层结构,同时避免了数据集中较长及重复的资源描述,并且提供了一种非常紧凑的存储结构,在实际应用中,HDT的组件拆分设计让RDF数据更容易管理.
HDT是一种比较有效的压缩方案,经过HDT压缩的文件还可通过文件压缩技术进行多次压缩.受HDT方案的启发,一些基于HDT方案的压缩技术相继被提出,如HDT FoQ[5]、WaterFowl[6]和HDT++[7].
K2-triple[8, 9]也是一种语法压缩方案,它采用了基于谓词的方法将数据集中的三元组拆分为不相交的主语和宾语子集对,并使用K2-tree的稀疏矩阵压缩方法对这些子集对进行高密度的压缩,实验表明K2-triple具有较好的压缩效果,但K2-triple作为一种内存模型被提出来,并没有给出一种序列化方案.
最近Pan等[10]提出了一种语义和语法的混合压缩方案SSP,实验结果表明SSP+bzip2相对于HDT+bzip2压缩率有一定提高,但是SSP+bzip2是一种综合了语义、语法和文件压缩三种技术的方案,压缩效率并不高.
字典的设计让关联数据中实体压缩达到极限,所以本文借鉴了HDT的头部和字典结构设计方案,重点提高三元组部分的压缩率.三元组通过主语、谓语和宾语进行建模,根据数据集的三元组集合,可以建立一个以主语、谓语和宾语为坐标系的三维矩阵空间,本文称之为三维关系矩阵.存储这些原始的三维关系矩阵会浪费很多存储空间,本文将三维关系矩阵拆分为3个二维矩阵对三维矩阵进行降维.同时受K2-triple压缩方案的启发,用K2-tree方法压缩3个二维稀疏矩阵.这两种方法极大了减少了存储三维关系矩阵占用的空间.
2 三维矩阵的降维在关联数据的压缩方案中,三维关系矩阵是一种直观的数据集关联关系的描述方式,如图 1(a)所示(本文实验数据集CN2012的三维关系矩阵).三维坐标轴分别表示数据集的主语、谓语和宾语,在三维坐标系中,离散点表示存在关联关系的数据,其他的空白空间是冗余信息.图 1(b)的主语-谓语坐标系是图 1(a)中的三维坐标系在宾语轴方向上的投影,图 1(c)的主语-宾语坐标系和图 1(d)的谓语-宾语坐标系分别是图 1(a)在谓语轴和主语轴方向上的投影.

|
| 图 1 三维矩阵的映射图(不同的颜色代表不同的谓语) Figure 1 Projection of three-dimensional matrix(different colours means different predicates) |
下面本文将证明投影后的3个二维矩阵能够还原原始的三维矩阵,即使用图 1(b)、图 1(c)和图 1(d)推导图 1(a).
本文用〈x, y, z〉spo表示图 1(a)三维矩阵空间中的任意点,用〈x, y〉sp表示图 1(b)主语-谓语空间中的任意点,用〈x, y〉so表示图 1(c)主语-宾语空间中的任意点,用〈x, y〉po表示图 1(d)谓语-宾语空间中的任意点,其中x、y和z是变量.
假设图 1(a)三维矩阵空间中存在一个点〈a, b, c〉spo,那么根据投影规则,图 1(b)主语-谓语空间中必然存在点〈a, b〉sp,图 1(c)主语-宾语空间中必然存在点〈a, c〉so,图 1(d)主语-谓语空间中必然存在点〈b, c〉po.因此三维矩阵和投影的二维矩阵中的点存在一一对应的关系,如(1) 式所示
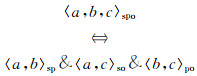
|
(1) |
因此,图 1(a)中的三维关系矩阵可以转化为3个二维矩阵,反之亦然.
假设一个三维矩阵的边长分别为m、n和p,存储一个三维矩阵所需要的空间为m×n×p,而存储3个二维矩阵所需要的空间为m×n+n×p+m×p.
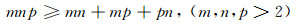
|
当m、n和p大于2时,存储3个二维矩阵存储所需要的磁盘空间比存储原始的三维矩阵少很多,而在实际关联数据集中,三维关系矩阵的边长通常都大于2.
3 K2-tree稀疏矩阵压缩K2-tree最先被提出来用作网络图表的一种压缩结构,它利用了邻接矩阵中存在的大量空白区域进行压缩.
K2-tree的原理是将输入的矩阵细分为大小相等的K2个子矩阵,不规则的矩阵用零值补齐.每个子矩阵将成为根节点的孩子节点,如果子矩阵中包含至少一个非零元素,那么这个孩子节点的值为1,否则孩子节点的值为0.如果子矩阵不包含非零元素,树在该节点的分解就结束了.K2-tree在第一层结构建立后,在孩子节点为1的地方递归该过程,当孩子节点的值与矩阵元素值一一对应时,树结构就到达了最后一层.如图 2所示,其中图 2(a)是一个稀疏的零一矩阵,图 2(b)是取K=2时根据图 2(a)构建出的K2-tree.因为二维矩阵被转换成一个四叉树模型,丢弃了大部分零值空间的存储,然后通过层次序列化的方法将四叉树转换成一个紧凑的比特串,因此它的压缩率非常高.

|
| 图 2 稀疏矩阵的K2-tree压缩 Figure 2 K2-tree compression of sparse matrix |
将三维矩阵降维和K2-tree的压缩方案相结合,对三维关系矩阵进行压缩,简称HDPK(Header Dictionary Projection K2).HDPK压缩过程见图 3,具体步骤如下:

|
| 图 3 HDPK的压缩流程 Figure 3 Compression process of HDPK |
1) 采用字典技术将数据集拆分为字典和ID关系三元组两部分,如图 3(a)所示.
2) 根据ID化的关系三元组构建三维关系矩阵,投影三维关系矩阵得到图 3((b)左)的主语-谓语矩阵、图 3(b)中)的主语-宾语矩阵和图 3((b)右)的谓语-宾语矩阵,并将投影后的二维矩阵补全以适应K2-tree压缩方法.
3) 使用K2-tree方法压缩主语-谓语矩阵、主语-宾语矩阵和谓语-宾语矩阵,得到3个四叉树结构,如图 3(c)所示,称叶节点为数据节点,非叶节点为索引节点.
4) 使用00000000表示图 3(c)中K2-tree的根节点,采用层次遍历方法将3个K2-tree序列化,得到压缩后的比特串(图 3(d)).
以二进制格式将压缩后的比特串存储到磁盘,能有效减少存储占用空间.以图 3为例,原始的明文三元组,每个三元组占用3 Byte,总共存储需要27 Byte,而压缩后的数据共有88个比特位,总共11 Byte.
为了保证压缩效率,本文构建三维和二维矩阵时,在内存中均采用了散点哈希集合存储,因为哈希集合查找的时间复杂度为O(1),在构建K2-tree的时候极大地提高了运行效率.
压缩算法如算法1所示.
初始条件:triples是输入的三元组集合,先将triples按照主语、谓语和宾语从大到小的优先级进行排序.通过映射操作获取降维后的3个二维矩阵的散点集合sp、so和po.创建返回结果对象result.
1) 将输入的sp、so和po作为一个集合,循环处理集合中的每个元素;
2) 将当前处理的元素重命名为origin;
| 算法1 压缩算法 |
| Input: set〈s, p, o〉 triples |
| 1 triples.sort() |
| 2 sp = triples.select((s, p, o)=>(s, p)).distinct.tohashset; |
| 3 so =triples.select((s, p, o)=>(s, o)).distinct.tohashset; |
| 4 po = triples.select((s, p, o)=>(p, o)).distinct.tohashset; |
| 5 result = newbitarray() |
| 6 |
| 7 foreach(item in range(sp, so, po)){ |
| 8 while(item.Count>= 1){ |
| 9 half =item.select(o=>(o.x/2, o.y/2)).distinct.tohashset; |
| 10 if (item.Count == 1) { |
| 11 result.headinsert(new bitarray(4)); |
| 12 }else{ |
| 13 bitset = new bitarray(half.count*4); |
| 14 count = 0; |
| 15 foreach (var point in half) { |
| 16 bitset[count++] = origin |
| .contains(2*point.x, 2*point.y); |
| 17 bitset[count++] = origin |
| .contains(2*point.x+1, 2*point.y); |
| 18 bitset[count++] = origin |
| .contains(2*point.x, 2*point.y+1); |
| 19 bitset[count++] = origin |
| .contains(2*point.x+1, 2*point.y+1); |
| 20 } |
| 21 origin = half; |
| 22 result.headinsert(bitset); |
| 23 } |
| 24 } |
| 25} |
| 26return result; |
3) 如果origin集合数量大于1,获取折半哈希集合half,half中存在的散点代表着它对应的索引节点值为1,这个索引节点包含4个子节点,这4个子节点的值可以根据origin获得,如算法的16~19行,通过变量bitset记录子节点的值;如果origin集合数量等于1,变量bitset的值为0000,并跳出循环,处理下一个元素;
4) 将折半哈希集合half赋值给origin,并将bitset头插法加入result,跳转到步骤1);
5) 最后result即为序列化结果.
5 实验结果本文的实验结果展示的是分析存储三元组关系需要的磁盘空间,并没有将头部和字典的大小计算在内.表 1列出了来自各个领域的实验数据集,统计了数据集的大小,三元组数据和三元组文本大小及数据集的下载链接.
| 数据集 | 大小 | 三元组数量 | 三元组大小/MB | 下载链接 |
| CN2012 | 17.7 MB | 137 441 | 0.54 | https://datahub.io/dataset/combined-nomenclature-2012 |
| DogFood | 38.7 MB | 242 258 | 1.04 | https://datahub.io/dataset/scholarlydata |
| Archive Hub | 71.7 MB | 431 088 | 1.85 | https://datahub.io/dataset/archiveshub-linkeddata |
| Jamendo | 143.9 MB | 1, 047 950 | 4.87 | https://datahub.io/dataset/jamendo-dbtune |
| LinkedMdb | 850.0 MB | 6 148 121 | 34.00 | https://datahub.io/dataset/linkedmdb |
| DBpedia rdftypes | 1.20 GB | 9 250 078 | 49.62 | http://downloads.dbpedia.org/3.6/en/instance_types_en.nt.bz2 |
| DBLP | 8.84 GB | 55 586 971 | 337.95 | https://datahub.io/dataset/rkb-explorer-dblp |
表 2统计了不同的数据集在HDT、HDT++以及HDPK上的实验结果,其中Size表示压缩后的大小,Rate表示压缩率.根据表 2中结果可以计算得出,HDT在实验数据集上的平均压缩率为39.9%,HDT++的平均压缩率为63.6%,而HDPK的平均压缩率达到了75%.对于数据集DogFood,由于数据集三维关系矩阵的初始分布比较分散,导致构建的K2-tree中非叶节点存储的非零元素较多,压缩率并不高,但仍然高于HDT++.而对于数据集CN2012以及DBpedia rdftype,它们的三维关系矩阵的初始分布比较聚集,构建的K2-tree中非叶节点存储的非零元素较少,因此压缩率较高.由上可知,HDPK的压缩效率受到数据集的初始分布影响.通过表 2可以计算出在7个实验数据集上,HDPK压缩方法相对于HDT++方法,平均压缩率提高12%.
| 数据集 | HDT | HDT++ | HDPK | |||||
| Size/MB | Rate/% | Size/MB | Rate/% | Size/MB | Rate/% | |||
| CN2012 | 0.34 | 37.1 | 0.20 | 63.0 | 0.09 | 83.3 | ||
| DogFood | 0.64 | 38.5 | 0.40 | 61.5 | 0.39 | 62.5 | ||
| Archive Hub | 1.19 | 35.7 | 0.69 | 62.7 | 0.52 | 71.9 | ||
| Jamendo | 3.20 | 34.3 | 1.75 | 64.1 | 1.41 | 71.1 | ||
| LinkedMdb | 22.21 | 34.7 | 12.02 | 64.7 | 10.14 | 70.2 | ||
| DBpedia rdftypes | 21.14 | 57.4 | 17.64 | 64.5 | 7.77 | 84.4 | ||
| DBLP | 199.52 | 41.0 | 119.29 | 64.7 | 65.22 | 81.7 | ||
一种好的压缩方法不仅要考虑压缩率,同样也得注重压缩效率.表 3列出了在同样的实验环境下,将N-Triple格式的实验数据按照HDT、HDT++和HDPK进行压缩花费的时间.实验结果表明,由于数据集的初始分布不相同,在不同的数据集上HDPK的压缩效率相较于HDT和HDT++有不同程度的提高.在最大的数据集DBLP上,HDPK压缩方法用了2 019.46 s,而HDT压缩方法用了2 892.34 s,HDPK相对于HDT减少了30.2%的耗时.在DBpedia rdftypes数据集上,HDPK耗时65.29 s,HDT耗时142.42 s,HDPK相对于HDT减少了54.1%的耗时.通过表 3可以计算出在7个实验数据集上,HDPK压缩方法相对于HDT++方法,平均压缩耗时降低10%.
| s | |||
| 数据集 | HDT | HDT++ | HDPK |
| CN2012 | 1.26 | 1.31 | 0.94 |
| DogFood | 4.07 | 4.22 | 3.42 |
| Archive Hub | 6.78 | 6.86 | 5.28 |
| Jamendo | 18.63 | 19.13 | 16.26 |
| LinkedMdb | 121.92 | 120.11 | 110.68 |
| DBpedia rdftypes | 142.42 | 139.14 | 65.29 |
| DBLP | 2 892.34 | 2 915.92 | 2 019.46 |
本文提出了一种新颖的关联数据压缩方法HDPK.它采用了一种极致的压缩方法存储关联数据的三元组结构,节省了大量的存储空间.实验结果表明在现有的压缩方法中,HDPK压缩方法是压缩率最高的,压缩效率也具有明显优势.
通过文献[9]可知K2-tree模型是支持简单查询的,当海量关联数据的三元组被压缩到非常小时,它可以在压缩状态下被完全加载到内存中,在全内存的状态下执行查询,查询效率具有明显的优势.因此探索基于HDPK压缩方案上的内存查询方案将是本文的后续工作之一.
| [1] |
PAN J Z. Resource Description Framework[M]. Heidelberg: Springer, 2009: 71-90. DOI:10.1007/978-3-540-92673-3_3
|
| [2] |
WU H, VILLAZON-TERRAZAS B, PAN J Z, et al. How redundant is it?-An empirical analysis on linked datasets[C]//Proceedings of the 5th International Conference on Consuming Linked Data-Volume 1264. Aachen:CEUR-WS, 2014:97-108.
|
| [3] |
NAVARRO G, MÄKINEN V. Compressed full-text indexes[J]. ACM Computing Surveys (CSUR), 2007, 39(1): 2. DOI:10.1145/1216370.1216372 |
| [4] |
FERNÁNDEZ J D, MARTÍNEZ-PRIETO M A, GUTIÉRREZ C, et al. Binary RDF representation for publication and exchange (HDT)[J]. Web Semantics Science Services & Agents on the World Wide Web, 2013, 19(1): 22-41. DOI:10.1016/j.websem.2013.01.002 |
| [5] |
MARTÍNEZ-PRIETO M A, GALLEGO M A, FERNÁNDEZ J D. Exchange and Consumption of Huge RDF Data[M]. Heidelberg: Springer, 2012: 437-452. DOI:10.1007/978-3-642-30284-8_36
|
| [6] |
CURÉ O, BLIN G, REVUZ D, et al. Waterfowl:A Compact, Self-Indexed and Inference-Enabled Immutable RDF Store[M]. Heidelberg: Springer International Publishing, 2014: 302-316. DOI:10.1007/978-3-319-07443-6_21
|
| [7] |
HERNÁNDEZ-ILLERA A, MARTÍNEZ-PRIETO M A, FERNÁNDEZ J D. Serializing RDF in compressed space[C]//Data Compression Conference (DCC). New York:IEEE Press, 2015:363-372. DOI:10.1109/DCC.2015.16.
|
| [8] |
ÁLVAREZ-GARCÍA S, BRISABOA N, FERNÁND-EZ J D, et al. Compressed vertical partitioning for efficient RDF management[J]. Knowledge and Information Systems, 2015, 44(2): 439-474. DOI:10.1007/s10115-014-0770-y |
| [9] |
ÁLVAREZ-GARCÍA S, BRISABOA N R, FERNÁND-EZ J D, et al. Compressed K2-triples for full-in-memory RDF engines[EB/OL].[2016-05-20]. https://arxiv.org/ftp/arxiv/papers/1105/1105.4004.pdf.
|
| [10] |
PAN J Z, GÓMEZ-PÉREZ J M, REN Y, et al. SSP:Compressing RDF data by Summarisation, Serialisation and Predictive Encoding[EB/OL].[2014-06-09].http://www.kdrive-project.eu/wp-content/uploads/2014/06/WP3-TR2-2014SSP.pdf.
|