 2019, Vol. 65
2019, Vol. 65
文章信息
- 刘文竹, 黄勃, 高永彬, 姜晓燕, 张娟, 余宇新
- LIU Wenzhu, HUANG Bo, GAO Yongbin, JIANG Xiaoyan, ZHANG Juan, YU Yuxin
- Item2vec与改进DDPG相融合的推荐算法
- Recommendation Algorithm Combining Item2vec with Improved DDPG
- 武汉大学学报(理学版), 2019, 65(3): 297-302
- Journal of Wuhan University(Natural Science Edition), 2019, 65(3): 297-302
- http://dx.doi.org/10.14188/j.1671-8836.2019.03.010
-
文章历史
- 收稿日期:2018-07-08



引用本文

|



2. 江西省经济犯罪侦查与防控技术协同创新中心, 江西 南昌 330103;
3. 上海外国语大学 国际金融贸易学院, 上海 201620
2. Center of Economic Crime Detection and Prevention and Control Technology Collaborative Innovation, Nanchang 330103, Jiangxi, China;
3. School of Economics and Finance, Shanghai International Studies University, Shanghai 201620, China
推荐系统(recommender system)作为一种高效的信息过滤技术,受到了广泛的关注。推荐系统挖掘用户偏好信息,对用户兴趣进行建模,从而为用户推荐可能满足其需求的物品。传统的推荐算法可以分为4类:协同过滤推荐算法[1]、基于内容的推荐算法、基于知识的推荐算法和混合推荐算法[2]。
近年来,推荐系统领域也产生了许多非传统的推荐算法。许多公司使用基于深度神经网络、多臂赌博机(multi-armed bandit)等推荐算法,希望能够提高推荐质量。Okura等[3]为雅虎新闻提出了基于RNN(recurrent neural network)的新闻推荐系统;Covington等[4]提出基于深度神经网络的推荐算法,为YouTube解决视频推荐问题。
现有的推荐算法多将推荐看作一个静态过程,由此产生固定的推荐策略,这样的推荐策略无法实时适应用户兴趣的改变,对兴趣变化较快的用户很难产生实时性的推荐[5],同时对于推荐系统中始终存在的数据稀疏性问题也没有很好地解决。因此,有些学者尝试采用强化学习[6] (reinforcement learning,RL)技术来解决现实场景中的推荐问题。
强化学习是机器学习领域一个重要的研究热点。Shani等[7]认为产生推荐的过程是一个连续决策的问题,于2005年提出可以将推荐问题看作一个马尔可夫决策过程(Markov decision process,MDP)。Taghipour等[8]在2008年提出将网页信息与Q学习算法结合解决网页推荐问题,但这种方法未能解决状态空间和动作空间过大的推荐任务。为了控制状态空间和动作空间的大小,Choi等[9]提出一种基于双聚类的Q学习算法,从用户和项目两个方面对用户-项目矩阵(useritem matrix)进行双聚类,然后再使用Q学习算法产生推荐。但是这种方法仅仅在一定程度上缓解了状态空间、动作空间较大的MDP问题。有研究者在Q学习中引入值函数估计(value function approximator),提出Deep Q-Net (DQN)方法[10, 11],但DQN是一个面向离散动作空间的算法,而现实中许多问题是连续的,比如控制问题等,此外Q学习算法和DQN算法都是Value-based的学习方法,通过对Bellman方程进行迭代最终收敛到最优价值函数,这种方法计算量大,而且在一些特殊的场景下Q值难以计算。Policy-based [6]的学习方法——策略梯度(policy gradient)则不存在这样的问题,这种方法可以直接对策略进行学习,但基于策略的方法只能进行回合更新,收敛速度较慢。Sliver等[12]结合Value-based和Policy-based的方法提出了Actor-Critic框架,但Actor的更新取决于Critic的价值判断,而Critic难收敛,再加上Actor的更新,导致Actor-Critic可能无法收敛。Lillicrap等[13]为了解决Actor-Critic存在的收敛问题,在此基础上融入DQN的优势,提出了深度确定策略梯度(deep deterministic policy gradient,DDPG)算法。Zhao等[14, 15]使用ActorCritic框架,采用DDPG算法来解决电商中的推荐问题。Munemasa等[16]使用隐狄利克雷分布(latent Dirichlet allocation,LDA)将商铺信息转化为分布式表示(distribute representation),然后再采用DDPG算法解决商铺推荐问题。本文提出一种基于DDPG强化学习算法来解决现实场景中的推荐任务,使用Item2vec [17]将离散的电影项目转化为连续的词向量表示,通过DDPG算法学习最优推荐策略,解决电影推荐问题。
1 问题描述和定义本文融合Item2vec和改进的DDPG算法来解决推荐问题,首先将推荐问题归纳为一个马尔科夫决策过程,如图 1所示,在t时刻,Recommender Agent接收用户此刻的状态st并根据该状态产生推荐at,user接收推荐at,推荐系统进入t+1时刻,user产生推荐对应的奖励同时状态更新再次传送给Recommender Agent。一般地,每一个马尔科夫决策过程由一个五元组组成(S,A,P,R,γ),以下为五元组各个元素在推荐系统中的定义[14]:

|
| 图 1 推荐问题在MDP中的表示 Fig. 1 Recommendation question in MDP |
S是所有环境状态的集合,st ∈ S表示Agent在t时刻所处的状态。本文使用电影网站movielens数据集进行测试,定义st = {moviet1,…,movietK },表示用户在t时刻的前K个(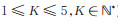
A是智能体(Agent)可执行动作的集合,在本文中A为所有可以推荐给用户的电影集合。at ∈ A表示Agent在t时刻所采取的动作,at在本文中表示为Agent根据当前的st为用户推荐的电影。
R:S × A → R是奖励函数,是用户针对Agent在t时刻推荐的电影at所给予的反馈。例如,在t时刻,对于Agent推荐的电影,用户会产生不同的反馈,此时Agent就根据用户的反馈获得立即奖励rt (st,at)。
P是状态转移概率,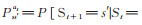
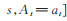
γ是折扣因子,γ ∈ [0, 1],用来权衡未来奖励对累积奖赏的影响。当γ = 0时,推荐系统只关注立即奖励;当γ = 1时,推荐系统关注长期累积奖励。
根据以上定义,推荐系统的学习目标就是通过最大化推荐系统的累积奖励找到一个最优的推荐策略π *,满足:
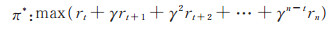
|
(1) |
本文融合Item2vec和深度强化学习中的DDPG算法实现电影推荐。DDPG是一种适用于连续动作空间的算法,Item2vec算法可以学习电影项目的词向量表示,将离散的电影动作空间转化为连续的电影动作空间。本文还提出将余弦距离和欧氏距离相结合的奖励函数,帮助算法尽快收敛并获得一个比较好的推荐策略。
2.1 数据处理在强化学习任务中,学习的目标就是找到能够使长期累积奖励最大化的策略[18]。首先要对历史数据进行处理,将历史评分转换为用户对项目的感兴趣程度。文献[14]将用户对商品(电商)的忽略、点击、购买行为分别转化为0、1、5来表示用户对该商品的感兴趣程度。这种方法并不适合本文,一是因为本文的数据集中只包含用户的评分值记录;二是这种方法忽略了用户评分值的重要性。使用这种方法,一旦用户对一部电影进行评分,用户对该电影的感兴趣程度就为5,忽略了用户对电影评价的高低。本文认为用户对电影的评分值更能体现推荐是否满足用户兴趣需求,所以感兴趣程度的设置应综合考虑用户的评分值。对每一个用户i的评分数据进行均值计算获得userr_meani,对某一电影j在该网站的评分记录进行均值计算获得movier_meanj,用户i对电影j的评分为x,通过
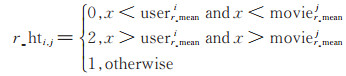
|
(2) |
对数据集的评分数据进行处理,r_hti, j表示用户对该电影的感兴趣程度。
图 2为处理前后的数据。

|
| 图 2 r_hti, j值设置 Fig. 2 The setting of r_hti, j |
Barkan等[17]将Word2vec [19]方法的Skip-gram with negative sampling(SGNS)的思路迁移到基于物品的协同过滤(Item-based CF)上,提出了Item2vec。一个物品集合被看作自然语言中的一个句子,物品集合中的物品等价于句子中的单词,一个商品集合是一个订单中包含的所有商品。以物品的共现性作为自然语言中的上下文关系,构建神经网络来学习物品在空间中的词向量表示。本文将所有用户的历史评分电影记录看作一个语料库,一个用户的评分电影记录看作一个单词集合,通过所有用户的评分记录集合学习每部电影的词向量表示,将离散的电影空间转换为连续的表示。对于用户的评分电影集合W1,W2,…,Wk,目标函数为:
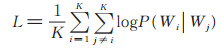
|
(3) |
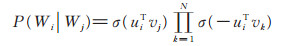
|
(4) |
其中,σ (x)= 1/(1 + exp(-x)),u∈Wi,v∈Wj,N为对于每一个正样本负采样的个数。
2.3 奖励函数设置奖励函数在强化学习中至关重要,奖励函数影响算法的收敛速度和学习效果。本文对用户的历史数据进行处理,将用户的历史评分列表转换为(s_ht,a_ht,r_ht)的形式,并将其存储在M中(算法1)。推荐Agent在t时刻,从M获得一个(s_ht,a_ht,r_ht)元组,令状态st = s_ht = {moviet1,…,movietK },产生一个电影推荐at,通过原数据中的a_ht和r_ht对该电影推荐进行评估并给予一个立即奖励rt(st,at)。现有的研究通常利用两者之间的余弦距离计算奖励值,但实验发现余弦距离更倾向于从方向上区分差异,对距离并不敏感,很容易使算法过早收敛于一个局部最优的策略,产生余弦相似度较高,但欧氏距离很大的推荐结果,无法满足用户的要求。本文对用户短时期内评分的电影进行相似度分析(如表 1所示,表中mi表示电影ID),可以看出用户的电影兴趣在短期内没有太大变化,不同电影间余弦相似度比较高(cosin > 0)且欧氏距离比较小(Ed < 1),因此本文设计了一种余弦相似度和欧氏距离相结合的奖励函数,如下式:
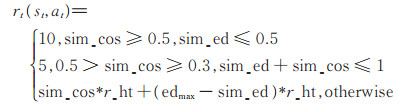
|
(5) |
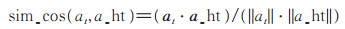
|
(6) |
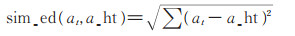
|
(7) |
| Algorithm 1 Recommender Simulator |
| Input: User rating history |
| The length of state K |
| Output:Memory M |
| for user=1…n do |
| for i in len(user rating list) do |
| s_ht={moviei, moviei + 1, …, moviei + K - 1} |
| a_ht=moviei + K |
| r_ht=r_ht of moviei + K |
| if r_ht> 0 then |
| Add(s_ht,a_ht,r_ht) in M |
| end if |
| end for |
| end for |
| Return M |
| (m1, m2, m3, m4) | (m1, m4) | (m2, m4) | (m3, m4) | |||||
| cosin | Ed | cosin | Ed | cosin | Ed | |||
| (31, 1 029, 1 061, 1 129) | 0. 42 | 0. 85 | 0. 71 | 0. 51 | 0. 46 | 0. 67 | ||
| (1 029, 1 061, 1 129, 1 263) | 0. 75 | 0. 42 | 0. 63 | 0. 50 | 0. 81 | 0. 44 | ||
| (5 218, 5 299, 5 377, 5 445) | 0. 80 | 0. 36 | 0. 82 | 0. 35 | 0. 67 | 0. 49 | ||
其中,sim_cos是用户实际观看电影a_ht和推荐电影at间的余弦距离,sim_ed是两部电影间的欧氏距离,edmax是欧氏距离的惩罚因子,当sim_ed > edmax时,edmax - sim_ed < 0会使reward值降低。
2.4 改进的强化学习算法DDPG传统的强化学习算法常应用于在线游戏的训练,在这种情况下Agent面对任何状态都可以采取相应动作并即时获得奖励和状态的更新。对于推荐系统来说,在算法上线应用之前是无法获得用户真正的反馈的,只能通过模拟的方法来获得每一次推荐带来的奖励。本文通过M和设置的奖励函数获得推荐的模拟奖励值,提出一种改进的DDPG算法。传统DDPG算法在每个episode之前初始化状态,本文令算法在每一个时间步都从推荐模拟存储器M获得一个已知状态(见算法2),这样Agent产生的推荐的奖励值就得以计算。令Q (s,a|θμ)表示Critic网络,θμ为神经网络参数,用于对Actor产生的推荐进行评价,fθρ为Actor网络用来产生推荐,θρ为其对应的神经网络参数。在训练过程中,对于当前状态st,推荐Agent产生一个电影推荐(动作)at,用户通过(5)式计算立即奖励rt(st,at),同时更新状态st + 1。将数据以(st,at,rt,st + 1)的形式存储在存储器D中,算法每次从D中随机采样m个元组进行学习。
Critic网络对状态-动作对的价值函数Q (st,at)进行学习,Critic的损失函数为:
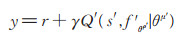
|
(8) |
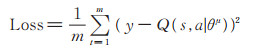
|
(9) |
其中,y为Critic-target网络的值,Q (s,a|θμ)是Critic网络的值,γ ∈ [0, 1]是折扣因子,然后使用梯度下降法对网络进行更新:
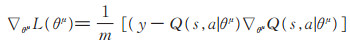
|
(10) |
在Actor-Critic框架中,Actor根据当前状态选择动作,Critic评价该动作的得分,Actor再根据Critic的评分修改该动作被选择的概率。Actor是一种基于策略的学习网络,用策略函数J来评价一个策略的好坏,对策略函数求梯度:
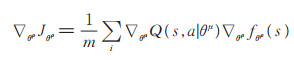
|
(11) |
| Algorithm 2 改进的DDPG算法 |
| Random initialize Critic network Q (s, a|θμ) and Actor fθ ρ with weights |
| Initialize target network Q ′ and f ′with weights θ μ' ← θμ, θρ' ← θρ |
| Initialize the capacity of replay memory D |
| Initialize a Gaussian Noise G |
| for episode = 1…N do |
| for t = 1…T do |
| Select a tuple(s_ht,a_ht,r_ht) from R and st=s_ht |
| at=fθρ (st) + G according to current policy and exploration noise |
| execute at and observe rt according equation (5) observe new state st + 1 |
| Store transition (st, at, rt, st + 1) in D |
| Sample mini-batch of m transitions (s, a, r, s′) from D |
| Set y = r + γQ′(s′, f ′θρ′|θμ′) |
| Update Critic by minimizing the loss :equation (10) |
| Update the Actor using the sampled policy gradient: equation (11) |
| Update the target networks |
| θμ′ ← τθμ +(1 - τ) θμ′, |
| θρ′ ← τθρ +(1 - τ) θρ′ |
| end for |
| end for |
实验硬件环境:PC机一台,8GB内存+256GB硬盘。本文实验平台操作系统为window10,编程语言为python语言,编程在Jupyter Notebook上进行。实验使用movielens数据集(https://grouplens.org/datasets/movielens/),其中ml-latest-small数据集中包括600个用户对9 000部电影的10万条评分记录。设K=3 (状态中包括3部电影),实验在经过Item2vec处理后的连续动作空间上进行,电影的词向量维度分别设置为20,50,70,对比不同词向量维度在相同算法参数设置下,平均奖励的收敛情况和推荐准确性。图 3为在不同词向量维度设置下平均奖励的收敛情况,可以看出该算法在词向量维度为20时,产生的推荐策略获得的平均奖励最大,推荐的电影最符合用户兴趣。本实验选取准确率(Precision)作为推荐策略的评价指标,表 2为算法在不同词向量维度设置下的推荐准确度。
| 词向量维数 | 准确率@5 | 准确率@10 |
| 20 | 0. 271 | 0. 304 |
| 50 | 0. 249 | 0. 255 |
| 70 | 0. 235 | 0. 240 |
冷启动问题是指,推荐系统在用户数据比较少的情况下难以学习用户偏好、产生令用户满意的推荐。实验同时在ml-20m的数据集上进行训练,该数据集包括13万用户对27 000部电影的2×107条评分记录,对比算法在两个数据集上的推荐准确率(表 3)可以发现,ml-20m数据集的评论数是ml-latest-small的2.0×102倍,但两者的推荐准确率@10只有0.007的差距,所以本文提出的算法在一定程度上能够缓解推荐系统中存在的冷启动问题。
| 数据集 | 评论数 | 准确率@10 |
| ml-latest-small | 1. 0×105 | 0. 304 |
| ml-20m | 2. 0×107 | 0. 311 |
本文提出一种Item2vec和改进的DDPG相结合的推荐算法。使用Item2vec将离散的电影项目转化为词向量表示,同时提出了一种余弦距离与欧氏距离相结合的奖励函数,实现了较好的推荐准确度。实验在两个大小不同的数据集上进行,验证了本文提出的算法在缓解冷启动问题上也有很好的表现。本文提出的算法还可以进行扩展,对于状态的设置增加其他因素,如时间、用户当前的搜索关键字等,以进一步提高推荐准确性。
| [1] |
PETER B, ALFRED K, WOLFGANG N. An Adaptive Web[M]. Berlin: Springer, 2007: 291-324.
|
| [2] |
RICCI F, ROKACH L, SHAPIRA B, et al. Recommender Systems Handbook[M]. Boston: Springer, 2011: 145-186.
|
| [3] |
OKURA S, TAGAMI Y, ONO S, et al.Embedding-based news recommendation for millions of users[C] // Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York: ACM, 2017: 1933-1942.DOI: 10.1145/3097983.3098108.
|
| [4] |
COVINGTON P, ADAMS J, SARGIN E.Deep neural networks for YouTube recommendations[C] //ACM Conference on Recommender Systems.New York: ACM, 2016: 191-198.
|
| [5] |
AMATRIAIN X.The recommender problem revisited [C] // Proceedings of the 8th ACM Conference on Recommender Systems.New York: ACM, 2014: 397-398.
|
| [6] |
SUTTON R, BARTO A. Reinforcement learning: An introduction[J]. IEEE Transactions on Neural Networks, 1998, 9(5): 1054-1054. DOI:10.1109/tnn.1998.712192 |
| [7] |
SHANI G, HECKERMAN D, BRAFMAN R I. An MDP-based recommender system[J]. Journal of Machine Learning Research, 2005, 6(1): 1265-1295. DOI:10.1007/s10846-005-9023-3 |
| [8] |
TAGHIPOUR N, KARDAN A.A hybrid web recom mender system based on Q-learning[C] // ACM Symposium on Applied Computing.New York: ACM, 2008: 1164-1168.DOI: 10.1109/GrC.2010.153.
|
| [9] |
CHOI S, HA H, HWANG U, et al.Reinforcement learning based recommender system using bi-clustering technique[DB/OL].[2018-10-02].https://arxiv.org/pdf/1801.05532.pdf.
|
| [10] |
MNIH V, KAVUKCUGLU K, SILVER D, et al.Playing Atari with deep reinforcement learning[DB/OL].[2018-10-02].https://arxiv.org/pdf/1312.5602v1.pdf.
|
| [11] |
MNIH V, KAVUKCUGLU K, SILVER D, et al. Humanlevel control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. DOI:10.1038/nature14236 |
| [12] |
SILVER D, LEVER G, HEESS N, et al.Deterministic Policy Gradient Algorithms[DB/OL].[2018-12-12].http://www0.cs.ucl.ac.uk/staff/d.silver/web/Publications_files/deterministic-policy-gradients.pdf.
|
| [13] |
LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[J]. Computer Science, 2015, 6: A187. |
| [14] |
ZHAO X Y, ZHANG L, DING Z, et al.Deep reinforcement learning for list -wise recommendations[J].Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.New York: ACM, 2018: 95-103.DOI: 10.1145/3240323.3240374.
|
| [15] |
ZHAO X Y, ZHANG L, DING Z, et al.Recommendations with negative feedback via pairwise deep reinforcement learning[C] // Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.New York: ACM, 2018: 1040-1048, DOI: 10.1145/3219819.3219886.
|
| [16] |
MUNEMASA I, TOMOMATSU Y, HAYASHI K, et al.Deep reinforcement learning for recommender systems[C] //International Conference on Information & Communications Technology.New York: IEEE, 2018: 226-233.
|
| [17] |
BARKAN O, KOENIGSTEIN N.Item2Vec: Neural Item Embedding for Collaborative Filtering[C] // 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing(MLSP).New York: IEEE, 2016: 1-6.DOI: 10.1109/MLSP.2016.7738886.
|
| [18] |
周志华. 机器学习[M]. 北京: 清华大学出版社, 2016: 371-397. ZHOU Z H. Machine Learning[M]. Beijing: Tsinghua University Press, 2016: 371-397. (Ch). |
| [19] |
MIKOLOV T, CHEN K, CORRADO G, et al.Efficient Estimation of Word Representations in Vector Space[DB/ OL].[2018-12-20].https://www.researchgate.net/publication/234131319_Efficient_Estimation_of_Word_Representations_in_Vector_Space.
|