 2017, Vol. 63
2017, Vol. 63
文章信息
- 吴红霞, 任延珍, 王丽娜
- WU Hongxia, REN Yanzhen, WANG Lina
- 基于最优脉冲和脉冲相关性的AMR自适应隐写算法
- An Adaptive Steganography Algorithm for AMR Based on the Optimal Pulse and Pulse Correlation
- 武汉大学学报(理学版), 2017, 63(5): 412-420
- Journal of Wuhan University(Natural Science Edition), 2017, 63(5): 412-420
- http://dx.doi.org/10.14188/j.1671-8836.2017.05.005
-
文章历史
- 收稿日期:2017-01-03



引用本文

|



2. 武汉大学 空天信息安全与可信计算教育部重点实验室, 湖北 武汉 430072;
3. 武汉大学 计算机学院, 湖北 武汉 430072
2. Key Laboratory of Aerospace Information Security and Trusted Computing, Ministry of Education, Wuhan 430072, Hubei, China;
3. School of Computer, Wuhan University, Wuhan 430072, Hubei, China
隐写术是一种隐蔽通信技术,它通过在文本、图像、音频和视频中隐藏秘密信息进行信息传输[1~5].隐写分析通过检测秘密信息是否存在来防止隐写术的非法使用[6~10].近年来,随着移动互联网音频应用的快速发展,各种压缩音频文件在互联网上被共享和分发.AMR(adaptive multimedia rate)[11]是3GPP组织指定的语音压缩标准,目前被广泛用于GSM,TDMA,UMTS和VOLTE,同时也被应用在各种移动手机终端系统中,如iPhone,Samsung,Nokia等,一些主流的移动终端通信软件,如QQ,微信都支持AMR语音编码格式.
AMR被广泛采用的同时,也为隐秘通信提供了新的载体空间.目前针对AMR音频压缩编码的隐写算法不断涌现[12~19],这些算法通过在编码过程修改编码参数嵌入秘密信息.AMR编码是基于代数码激励线性预测(ACELP,algebraic coded exited linear prediction)原理,其中有三个可行的嵌入域,包括固定码本(FCB, fixed codebook)[12, 13],线性预测系数(LPC,liner prediction coefficient)[14~16]和基音周期(ACB, adaptive codebook)[17~19].AMR的固定码本结构是基于交错正负脉冲设计的,编码时固定码本搜索是采用不彻底的深度优先树搜索准则,这意味着AMR编码的FCB参数具有一定的冗余,码本参数还存在其他可选空间,因此可以通过秘密信息选择其他次优码本而不降低综合语音质量.现有的AMR固定码本隐写算法[12, 13]就是基于这个思想.Geiser等[12]针对AMR-NB(narrow-band),根据固定码本搜索过程中非零脉冲位置选择所存在的随机性和可修改性,提出基于轨道脉冲位置调制的隐写算法.Miao等[13]针对AMR-WB(wide-band),采用类似于Geiser等[12]的方法,在AMR固定码本搜索过程中,通过调整轨道最后一个脉冲的位置,使其与同轨道其他脉冲位置和秘密信息保持一定的映射关系以嵌入秘密信息.该算法可以达到较好的隐蔽性和较高的隐写容量.文献[14~16]是针对LPC域的隐写,其中Xiao等[14]针对低速率语音编码提出基于改进的量化索引调制(QIM, quantization index modulation)的隐藏方法,采用基于互补邻居节点(CNV, complementary neighbor vertex)算法对量化使用的矢量码本进行优化划分,根据嵌入秘密信息的值修改码字映射实现秘密信息的隐写.Liu等[15]使用矩阵编码在线性预测编码中进行隐写,该算法根据LPC系数向量的最短距离搜索准则构建映射表,并结合秘钥选择嵌入位置和嵌入模板.Liu等[16]基于替换LPC系数量化索引集提出一种新颖的QIM隐写算法,该算法将量化索引集作为量化索引空间中的一个点,隐写在该索引空间中进行.文献[17~19]是针对基音周期域的隐写.Nishimura[17]通过混合自适应基音量化、基音变化点和修改基音延迟的方法调整自适应码本搜索范围嵌入秘密信息.余迟等[18]提出一种针对基音周期的3G信息隐藏方法,在进行自适应码本搜索过程中,对得到的每个子帧的整数基音周期参数检测其与前后相邻的基音周期值是否相等进行秘密信息的嵌入.刘程浩等[19]提出一种针对低比特率语音编码的隐写术,该方法在进行闭环基音周期搜索之前对各个子帧的基音周期搜索范围进行调整实现秘密信息的嵌入.FCB脉冲位置参数是AMR编码的重要组成部分,每个帧中有多于30%的比特用于编码脉冲位置参数,如在12.2 kb/s模式中,固定码本所占比例约为46.9%,因此,它是AMR压缩域中隐蔽空间最大的嵌入域.
随着隐写算法的不断发展,目前针对AMR压缩音频的隐写分析算法不断出现[20~25].文献[20, 21]是针对基音周期的隐写分析算法.Burns等[20]发现隐写后stego语音的基音周期将会发生变化,因此Burns等根据语音特征并结合分层聚类算法提出一种隐写分析算法.Wang等[21]发现隐写将改变相邻帧之间的相关性,为了量化这种相关性,Wang等通过使用码本索引分析相邻帧的相关性,提出一种码本相关网络模型.文献[22]是针对LPC的隐写分析算法,李松斌等[22]发现QIM隐写使码流中LPC系数的量化索引发生转移,并导致码字分布特性和相关性发生改变,设计了基于码字分布不均衡性和相关性统计模型的隐写分析算法.文献[23~25]是针对AMR固定码本的隐写分析算法,Ding等[23]基于隐写嵌入所带来的脉冲位置直方图发生的变化,提取脉冲位置参数修正直方图平坦度、特征函数质心和方差,以及码流中0和1出现的概率差(HFCV)作为特征,通过SVM训练分类实现对G.729语音编码的隐写分析.Miao等[24]隐写分析方法提取马尔科夫链转移概率、联合熵和条件熵作为音频特征(MTJCE)来评估相邻脉冲的相互关系,该方法能够很好的区分cover音频与stego音频.Ren等[25]提出的一种基于压缩SPP特征(SPP:same position probability,同一轨道中两个脉冲位置相同的概率)的隐写分析算法,该方法对音频同一轨道中两个脉冲位置相同的概率SPP进行统计分析.
现有的针对AMR固定码本的隐写算法[12, 13]存在两方面的问题.首先,它们没有考虑嵌入所引入的统计特征异常.嵌入将会引起cover和stego间有很大的差异,并且这些差异信息会被隐写分析算法利用.其次,上述两种隐写算法在隐写时没有考虑固定码本的搜索准则,所以隐写将会导致语音质量的下降,在低比特率的情况下,隐写后stego语音质量下降更明显.为了提高隐蔽性和统计安全性,本文提出了一种适用于AMR固定码本的自适应隐写算法(AFAS算法),根据脉冲最优概率和同轨道中脉冲相关性设计代价函数;根据FCB搜索得到的最优脉冲位置的命中函数b(n)设计加性失真函数.
1 AMR固定码本搜索原理AMR是一种基于ACELP技术的混合编码算法.固定码本(FCB)搜索是AMR编码中的关键部分,FCB搜索过程中只有较少部分的非零脉冲位置被选择和编码.AMR中的固定码本结构是基于交错正负脉冲(interleaved single-pulse permutation,ISPP)设计的,不同的编码速率模式具有不同的脉冲分布.以12.2 kb/s编码模式为例,激励码本矢量包含10个非零脉冲,所有脉冲的幅度为+1或-1.子帧中的40个脉冲位置被分为5个轨道,每个轨道中有两个非零脉冲,如表 1[11]所示.
AMR固定码本搜索过程对于每个脉冲位置的选择原则是保证合成语音与原始语音的加权均方误差最小,其搜索的目标就是选择包含最优的N个脉冲的码本矢量.在AMR固定码本搜索过程中非零脉冲的确定顺序为i0到i9,搜索使得(1) 式中Qk最大的矢量Ck, 即为所求的固定码本矢量,为列向量.
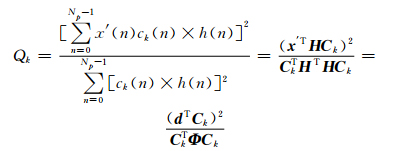
|
(1) |
其中, k=0, …, 9, Np表示每个子帧中的脉冲总数,h(n)是感知加权滤波器的脉冲响应,矩阵H是下三角托普利兹卷积矩阵,其主对角线值为h(0),依次向下的对角线值分别为h(1), h(2), …, h(39),并且h(0)=1,-1 < h(i) < 1,1≤i≤39.d=HTx′为目标信号x′和脉冲响应h(n)的相关信号,Φ=HTH为h(n)的自相关矩阵,并且它是一个对称矩阵.
为了简化搜索过程,固定码本将脉冲的幅度预先设置为参考信号b(n),根据b(n)绝对值的大小采用深度优先树搜索算法在每个轨道中搜索非零脉冲位置,b(n)的计算公式如下:
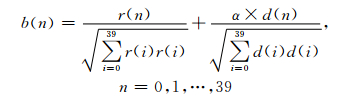
|
(2) |
其中,d(n)表示第n个目标信号与脉冲响应之间的相关性;r(n)表示预测后的第n个残差信号;α为扩展因子,编码速率越高α越小.
AMR固定码本搜索过程采用深度优先树搜索算法,不同编码速率模式的区别仅在于搜索的脉冲数和相应的搜索树的级数不同.以AMR-NB 12.2 kb/s模式为例,搜索树总共5层,每次搜索2个非零脉冲位置,并且这两个脉冲总是出现在连续的轨道上,如图 1[11]所示.

在搜索树的第一层上,首先固定i0的位置,脉冲i0置于该子帧的所有5个轨道中40个采样点参考信号全局最大的位置,脉冲i1置于其余的4个轨道中参考信号局部最大的位置,这一层不需要搜索.第2层,在脉冲i1所在轨道后面的2个相邻轨道中搜索脉冲i2和i3,搜索时,先固定i2的位置,然后在另一个轨道中搜索i3,分别计算Qk,选择使得当前目标信号Qk最大的脉冲i2和i3的位置,搜索组合为8×8.第3、4、5层的搜索过程与第2层完全相同,上述4层搜索形成一次的搜索迭代.每次搜索沿着其中一条深度优先树路径走到底,然后重新选择一条新路径进行搜索.
2 AFAS算法现今,大多数自适应隐写算法是基于最小化加性失真模型[26]进行设计的,该模型先设计每个cover元素的嵌入修改代价函数,再根据嵌入修改代价函数定义加性失真函数,这种思想已经被很好的利用,如HUGO[27],UNIWARD[28].为了利用最小化失真模型,一种有效的编码框架——STC[29](Syndrome-Trellis Codes)常被用于获得平均嵌入失真的理论界限.自适应隐写算法的核心是嵌入修改代价函数和加性失真函数的设计.
为了提高AMR FCB隐写算法的隐蔽性和统计安全性,本文利用嵌入修改代价函数和命中函数设计加性失真函数.图 2显示了AFAS算法的流程.编码时,STC编码通过维特比算法[29]选择一个合适的修改方案使全局嵌入失真接近理论界限值.接收端不需要知道失真函数,只需要知道秘密信息的长度,就可以正确地提取出秘密信息.提取过程相对简单,先逐帧解码AMR音频获得每个子帧中非零脉冲位置,再根据秘密信息长度使用STC解码提取出秘密信息.

|
| 图 2 自适应隐写(AFAS)算法流程 Figure 2 The processing flow of the AFAS algorithm |
根据脉冲位置特征,AFAS算法从两个方面考虑设计嵌入代价函数:脉冲最优概率和同一轨道中两个脉冲位置的相关性.
1) 脉冲最优概率
在FCB搜索过程中,首先,FCB搜索每个子帧中的10个非零脉冲信息sk, 0≤k≤9.对于脉冲i0,计算40个参考信号值b(n), 0≤n≤39,找出全局b(n)绝对值最大的位置s′0,如果s′0=s0则该位置是最优的,最优次数加1.对脉冲ik, 1≤k≤9,计算当前脉冲位置为sk时的Qk,同时计算该脉冲在同一轨道的其他所有可选位置处的Qk局部最大的位置s′k,如果Qk > Q′k,则位置sk是最优的,最优次数加1.最后统计一帧中每个脉冲ik在所有子帧中出现最优次数的概率.非零脉冲最优概率计算如(3) 式所示:
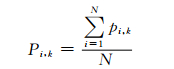
|
(3) |
其中,N表示一帧中的子帧数,i是子帧的索引,k是子帧中非零脉冲索引.若当前子帧脉冲ik为最优,则pi, j=1,否则,pi, k=0.
2) 脉冲相关性
本文利用同轨道中脉冲对的概率分布表示两个脉冲位置的相关性.脉冲对的概率计算如下式,
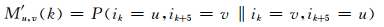
|
(4) |
每个子帧中同轨道的两个脉冲位置的相关性的统计结果计算如下:
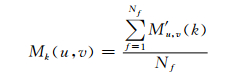
|
(5) |
其中,k=0, 1, …, 4为子帧中的轨道数(12.2 kb/s模式),u, v, 0≤u, v≤39为轨道中可选脉冲位置,Nf为AMR音频帧中包含的子帧数.f为子帧序号,1≤f≤Nf.如果第一个脉冲位置ik=u(或ik=v),第二个脉冲位置ik+5=v(或ik+5=u),则P(ik=u, ik+5=v‖ik=v, ik+5=u)=1,否则,P(ik=u, ik+5=v‖ik=v, ik+5=u)=0.
图 3显示了第0轨道中脉冲对的概率分布结果,图 3结果表明,Geiser等[12]和Miao等[13]隐写方案隐写后很明显地改变了脉冲对的概率分布,因此,同轨道中脉冲对的概率分布是影响隐写算法统计安全性的重要因素.

|
| 图 3 隐写前后轨道0中两个脉冲位置的概率分布 Figure 3 The histogram for probability distributions of pulse pairs in the 0-th track |
脉冲的最优概率和同轨道中脉冲对的相关性可以很好地反映非零脉冲的分布,因此,本文利用脉冲最优概率和同轨道中脉冲对的相关性定义每个非零脉冲的嵌入适用性.嵌入适用性的定义如下式
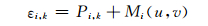
|
(6) |
修改代价函数可以根据非零脉冲的嵌入适用性定义,如(7) 式所示:
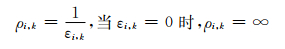
|
(7) |
FCB搜索限制在每个轨道中选取2个非零脉冲,每个非零脉冲位置在8个不同位置中选择,每个子帧中共有10个非零脉冲位置.假设Xi和Yi分别为cover音频和相应的stego音频中非零脉冲位置,
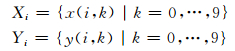
|
其中i=1,…,N,N为音频中子帧的总数.
以第0个轨道为例,y(i, k)∈I(i, k),
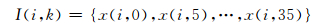
|
为了评估嵌入影响,定义将非零脉冲位置x(i, k)修改为y(i, k)的代价函数ρi, k(X, y(i, k)).若y(i, k)=x(i, k),则ρi, k(X, y(i, k))=0,否则,ρi, k(X, y(i, k))=ρi, k∈[0, ∞).全局加性失真函数的设计如(8) 式所示,
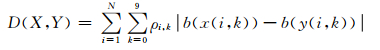
|
(8) |
b(x(i, k)), b(y(i, k))分别表示cover和stego中第i个子帧中第k个非零脉冲位置的命中函数值.
3 实验评估为了评估AFAS算法的性能,本文从三方面进行实验分析,包括隐蔽性分析、统计安全性分析和隐藏容量分析.
1) 隐蔽性分析:为了分析AFAS算法的听觉隐蔽性,实验使用主观语音质量评估(PESQ)[30]工具评估该算法的隐蔽性能.
2) 统计安全性分析:统计安全性反映了对抗隐写分析算法的能力,评价指标为TER(检测错误率)[31].实验评估使用隐写分析算法[23~25]检测AFAS算法的统计安全性,TER计算方法如下:
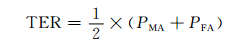
|
(9) |
其中PMA和PFA分别代表漏警率和误警率.TER越大,隐写算法的统计安全性越高.
3) 隐藏容量分析:为了分析AFAS的隐藏能力,实验中使用每秒音频中最大能嵌入的秘密信息比特数(Cap)作为评价指标,Cap越大,隐藏容量越高.
3.1 实验设置本次实验采用2 305段WAV音频,所有音频样本段的时长30 s左右,单声道,8 kHz,16 bit采样率,包括数字语音和不同的音乐.4种AMR音频数据样本库分别为:
1) 一个Cover音频样本库CDB:对每段WAV采用3GPP公开的AMR编码器进行编码,编码速率模式为12.2 kb/s和10.2 kb/s,总共有2 305段cover音频.
2) 三个stego音频样本库:在AMR12.2 kb/s编码模式下,分别用AFAS算法,文献[12]和文献[13]算法对2 305段WAV样本在绝对嵌入率(ABR)为2.53%、5.07%、7.6%、10.13%和12.66%时,生成SDB1,SDB2,SDB3样本库,每个样本库中有2 305×5=11 525段stego样本.
实验中所使用的绝对嵌入率ABR是根据AFAS算法的相对嵌入率计算得出的,上述5个绝对嵌入率分别对应AFAS算法的相对嵌入率为20%、40%、60%、80%和100%.
实验所使用的3种隐写分析算法分别为Ding等[23]针对ABS压缩域提出基于脉冲位置变化直方图的隐写分析算法; Miao等[24]提取马尔科夫转移概率、联合熵和条件熵作为音频分析特征(MTJCE)进行隐写分析; Ren等[25]针对AMR固定码本隐写算法提出基于同轨道脉冲位置相同概率(SPP)的隐写分析算法.
3.2 实验结果和性能分析 3.2.1 隐蔽性分析以12.2 kb/s编码模式为例,实验对比了100段语音样本在3种隐写方法隐写前后对应的PESQ值,图 4为对比结果.由图 4可知,采用AFAS算法隐写对语音质量改变较小,隐蔽性会更好.原因是AFAS方法结合最小化嵌入影响的失真函数,根据嵌入失真最小的原则选择同轨道中第二个非零脉冲位置,即嵌入后对音频质量改变最小.

|
| 图 4 使用3种隐写方法进行隐写前后的PESQ对比结果 Figure 4 PESQ for cover audios and stego audios of three methods |
实验中计算500段不同音频隐写前后的PESQ平均值和方差.表 2是分别采用3种隐写方法进行隐写前后的语音PESQ的平均值、最大值和最小值,表 3是分别采用3种隐写方法进行隐写后的PESQ较cover语音PESQ的变化的平均值与方差.对比实验结果表明采用AFAS方法进行隐写对语音质量改变的较小,说明AFAS算法具有较好的隐蔽性.
| ABR/% | 平均值 | 最大值 | 最小值 | ||||||||
| AFAS算法 | Geiser[12] | Miao[13] | AFAS算法 | Geiser[12] | Miao[13] | AFAS算法 | Geiser[12] | Miao[13] | |||
| 0 | 3.842 | 3.842 | 3.842 | 4.650 | 4.650 | 4.650 | 3.118 | 3.118 | 3.118 | ||
| 2.53 | 3.812 | 3.489 | 3.600 | 4.487 | 4.100 | 4.230 | 2.892 | 2.768 | 2.750 | ||
| 5.07 | 3.790 | 3.415 | 3.579 | 4.362 | 3.984 | 4.176 | 2.851 | 2.743 | 2.739 | ||
| 7.6 | 3.764 | 3.397 | 3.520 | 4.320 | 3.978 | 3.968 | 2.763 | 2.521 | 2.597 | ||
| 10.13 | 3.739 | 3.364 | 3.432 | 4.289 | 3.952 | 3.950 | 2.700 | 2.469 | 2.386 | ||
| 12.66 | 3.728 | 3.257 | 3.324 | 4.250 | 3.923 | 3.926 | 2.695 | 2.328 | 2.259 | ||
| ABR/% | 平均值 | 方差 | |||||
| AFAS算法 | Geiser[12] | Miao[13] | AFAS算法 | Geiser[12] | Miao[13] | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 2.53 | 0.152 9 | 0.498 6 | 0.498 6 | 1.439 6 | 12.659 7 | 12.439 5 | |
| 5.07 | 0.219 0 | 0.513 0 | 0.502 9 | 2.548 2 | 13.381 9 | 13.861 2 | |
| 7.6 | 0.221 5 | 0.537 0 | 0.516 2 | 2.719 8 | 15.564 7 | 14.583 2 | |
| 10.13 | 0.235 1 | 0.542 9 | 0.543 1 | 2.746 0 | 15.932 8 | 15.961 2 | |
| 12.66 | 0.239 0 | 0.578 3 | 0.560 0 | 2.839 5 | 16.486 3 | 16.539 1 | |
图 5显示了使用AFAS算法隐写前后每一子帧中非零脉冲位置的分布直方图(12.2 kb/s编码码式),实验中,音频样本相对嵌入率为100%.分别计算cover和stego中每个子帧中非零脉冲位置出现的次数.图 5中的结果表明,使用AFAS算法隐写后AMR FCB每个子帧中非零脉冲位置分布变化不大.

|
| 图 5 cover和stego中每一子帧中非零脉冲位置分布 Figure 5 The distribution of non-zero pulse position for cover and stego |
表 4,5显示了12.2 kb/s和10.2 kb/s编码模式下的实验结果.由表 4,5可知,在相同的绝对嵌入率情况下,对每种隐写分析方案,AFAS算法的检测错误率都高于文献[12, 13]提出的隐写方案,这表明AFAS算法较现有的隐写算法具有较高的统计安全性.
| ABR/% | HFVC[23]隐写分析方案 | MTJCE[24]隐写分析方案 | SPP[25]隐写分析方案 | ||||||||
| AFAS算法 | Geiser[12] | Miao[13] | AFAS算法 | Geiser[12] | Miao[13] | AFAS算法 | Geiser[12] | Miao[13] | |||
| 0 | 0.024 6 | 0 | 0.006 6 | 0.075 2 | 0 | 0 | 0.034 6 | 0 | 0.004 4 | ||
| 2.53 | 0.506 0 | 0.345 5 | 0.312 9 | 0.450 6 | 0.371 4 | 0.376 5 | 0.436 0 | 0.269 0 | 0.263 5 | ||
| 5.07 | 0.254 2 | 0.132 2 | 0.195 5 | 0.234 2 | 0.086 6 | 0.102 6 | 0.284 2 | 0.046 6 | 0.104 2 | ||
| 7.60 | 0.203 7 | 0.034 6 | 0.088 0 | 0.187 9 | 0.053 4 | 0.097 4 | 0.192 6 | 0.011 8 | 0.114 4 | ||
| 10.13 | 0.116 9 | 0.017 1 | 0.031 3 | 0.141 0 | 0.013 9 | 0.056 5 | 0.153 3 | 0.011 3 | 0.068 3 | ||
| 12.66 | 0.075 7 | 0 | 0.001 | 0.098 7 | 0 | 0 | 0.086 1 | 0 | 0.012 2 | ||
| ABR/% | HFVC[23]隐写分析方案 | MTJCE[24]隐写分析方案 | SPP[25]隐写分析方案 | ||||||||
| AFAS算法 | Geiser[12] | Miao[13] | AFAS算法 | Geiser[12] | Miao[13] | AFAS算法 | Geiser[12] | Miao[13] | |||
| 0 | 0.024 6 | 0 | 0.006 6 | 0.012 8 | 0 | 0 | 0 | 0 | 0 | ||
| 2.53 | 0.530 6 | 0.282 6 | 0.248 8 | 0.310 8 | 0.282 7 | 0.300 9 | 0.407 5 | 0.326 3 | 0.338 6 | ||
| 5.07 | 0.313 9 | 0.205 2 | 0.213 9 | 0.252 1 | 0.197 8 | 0.205 6 | 0.296 2 | 0.225 9 | 0.191 6 | ||
| 7.60 | 0.169 5 | 0.096 9 | 0.126 9 | 0.172 1 | 0.123 0 | 0.128 5 | 0.171 3 | 0.109 9 | 0.140 0 | ||
| 10.13 | 0.105 2 | 0.011 7 | 0.024 3 | 0.130 4 | 0.115 2 | 0.101 3 | 0.094 8 | 0.050 9 | 0.073 5 | ||
| 12.66 | 0.042 6 | 0.012 6 | 0.004 8 | 0 | 0.004 8 | 0 | 0.011 3 | 0.0109 | 0.010 6 | ||
在AFAS算法中,在每个轨道中嵌入1比特秘密信息.以12.2 kb/s为例,8kHz采样率,每帧20ms,每一帧被分为4个子帧,每个子帧有5个轨道,所以嵌入容量Cap为1 kb/s文献[12, 13]提出的隐写方法的Cap最大分别能达到2 kb/s和3 kb/s.AFAS算法的隐藏容量Cap低于文献[12, 13]所提方案.
4 结论为了提高隐蔽性和统计安全性,本文提出一种AMR固定码本的自适应隐写算法(AFAS算法),基于固定码本的特征和FCB最优搜索的原理,分别设计了嵌入代价函数和加性失真函数.AFAS算法结合脉冲最优概率和同一轨道中两个脉冲位置的相关性设计嵌入代价函数.在设计加性失真函数时引入命中函数值b(n)来提高算法的隐蔽性.实验结果表明,AFAS算法较文献[12, 13]的隐写算法具有较好的隐蔽性和统计安全性.AMR是基于CELP技术的混合编码算法,现在主流的语音编码G.729和G722.1也是基于CELP技术进行编码,AFAS算法原理上适用于G.729和G722.1编码标准.在下一步的工作中,我们将进一步分析AMR FCB的分布特性,提高算法的隐藏容量.
| [1] |
PETITCOLAS F A P, ROSS J, ANDERSON R J, et al. Information Hiding Survey-A Survey[J/OL].[2016-03-10]. http://gray-world.net/it/papers/pet-itcolas99information.pdf.
|
| [2] |
SEDIGHI V, COGRANNE R, FRIDRICH J. Content-adaptive steganography by minimizing statistical detectability[J]. IEEE Transactions on Information Forensics and Security, 2016, 11(2): 221-234. DOI:10.1109/TIFS.2015.2486744 |
| [3] |
WILSON A, KER A D. Avoiding Detection on Twitter:Embedding Strategies for Linguistic Steganography[J/OL].[2016-03-13]. http://www.cs.ox.ac.uk/andrew.ker/docs/ADK68B.pdf.
|
| [4] |
SADEK M M, KHALIFA A S, MOSTAFA G M. Video steganography:A comprehensive review[J]. Multimedia Tools and Applications, 2015, 74(17): 7063-7094. DOI:10.1007/s11042-014-1952-z |
| [5] |
BILAL I, KUMAR R, ROJ M S, et al. Recent advancement in audio steganography[C]//Distributed and Grid Computing (PDGC). New York:IEEE Press, 2014:402-405. DOI:10.1109/pdgc.2014.7030779.
|
| [6] |
DENEMARK T, BOROUMAND M, FRIDRICH J. Steganalysis features for content-adaptive JPEG steganography[J]. IEEE Transactions on Information Forensics and Security, 2016, 11(8): 1736-1746. DOI:10.1109/tifs.2016.2555281 |
| [7] |
AHITAKER J M, KER A D. Steganalysis of Overlapping Images[C/OL].[2016-05-05].http://www.cs.ox.ac.uk/andrew.ker/docs/ADK64B.pdf.
|
| [8] |
WANG K, ZHAO H, WANG H X. Video steganalysis against motion vector-based steganography by adding or subtracting one motion vector value[J]. IEEE Transactions on Information Forensics and Security, 2014, 9(5): 741-751. DOI:10.1109/tifs.2014.2308633 |
| [9] |
PAULIN C, SELOUANI S A, HERVET E. Audio steganalysis using deep belief networks[J]. International Journal of Speech Technology, 2016, 19(3): 585-591. DOI:10.1007/s10772-016-9352-6 |
| [10] |
XIA Z, WANG X, SUN X, et al. Steganalysis of least significant bit matching using multi-order differences[J]. Security and Communication Networks, 2014, 7(8): 1283-1291. DOI:10.1002/sec.864 |
| [11] |
BESSETTE B, SALAMI R, LEFEBVRE R, et al. The adaptive multi-rate wideband speech codec (AMR-WB)[J]. IEEE Transactions on Speech and Audio Processing, 2002, 10(8): 620-636. DOI:10.1109/tsa.2002.804299 |
| [12] |
GEISER B, VARY P. High Rate Data Hiding in ACELP Speech Codecs[C/OL].[2016-06-05].http://ieeexplore.ieee.org/document/4518532/.
|
| [13] |
MIAO H, HUANG L, CHEN Z, et al. A new scheme for covert communication via 3G encoded speech[J]. Computers & Electrical Engineering, 2012, 38(6): 1490-1501. DOI:10.1016/j.compeleceng.2012.05.003 |
| [14] |
XIAO B, HUANG Y, TANG S. An approach to information hiding in low bit-rate speech stream[C]//IEEE Global Telecommunications Conference. New York:IEEE Press, 2008:1-5. DOI:10.1109/glocom.2008.ecp.375.
|
| [15] |
LIU P, LI S B, WANG H Q. Steganography integrated into linear predictive coding for low bit-rate speech codec[J]. Multimedia Tools and Applications, 2017, 76(2): 2837-2859. DOI:10.1007/s11042-016-3257-x |
| [16] |
LIU P, LI S B, WANG H Q. Steganography in vector quantization process of linear predictive coding for low-bit-rate speech codec[J/OL].[2016-05-23].https://link.springer.com/article/10.1007/s00530-015-0500-7.
|
| [17] |
NISHIMURA A. Data hiding in pitch delay data of the adaptive multi-rate narrow-band speech codec[C]//Intelligent Information Hiding and Multimedia Signal Processing of the 5th IEEE. New York:IEEE, 2009:483-486. DOI:10.1109/ⅡH-MSP.2009.83.
|
| [18] |
余迟, 黄刘生, 杨威, 等. 一种针对基音周期的3G信息隐藏方法[J]. 小型微型计算机系统, 2012, 33(7): 1445-1449. YU C, HUANG L S, YANG W, et al. A 3G speech data hiding method based on pitch period[J]. Journal of Chinese Computer Systems, 2012, 33(7): 1445-1449. DOI:10.3969/j.issn.1000-1220.2012.07.011 |
| [19] |
刘程浩, 柏森, 黄永峰, 等. 一种基于基音预测的信息隐藏算法[J]. 计算机工程, 2013, 39(2): 137-140. LIU C H, BAI S, HUANG Y F, et al. An information hiding algorithm based on pitch prediction[J]. Computer Engineering, 2013, 39(2): 137-140. DOI:10.3969/j.issn.1000-3428.2013.02.027 |
| [20] |
BURNS E M, VIEMEISTER N F. Played-again SAM:Further observations on the pitch of amplitude-modulated noise[J]. The Journal of the Acoustical Society of America, 1981, 70(6): 1655-1660. DOI:10.1121/1.387220 |
| [21] |
WANG C Y, WU Q. Information Hiding in Real-Time VoIP Streams[C/OL].[2016-5-30].http://jozjan.s.cnl.sk/dwl/voip/Remote%20Publications/Information%20Hiding%20in%20Real-Time%20VoIP%20Streams.pdf.
|
| [22] |
李松斌, 孙东红, 袁键, 等. 一种基于码字分布特性G.729A压缩语音流隐写分析方法[J]. 电子学报, 2012, 40(4): 842-846. LI S B, SUN D H, YUAN J, et al. A steganalysis method for G. 729A compressed speech stream based on codeword distribution characteristics[J]. Acta Electronica Sinica, 2012, 40(4): 842-846. DOI:10.3969/j.issn.0372-2112.2012.04.036 |
| [23] |
DING Q, PING X J. Steganalysis of compressed speech based on histogram features[C]//Wireless Communications Networking and Mobile Computing (WiCOM) of the 6th IEEE. New York:IEEE Press. 2010:1-4. DOI:10.1109/WICOM.2010.5600125.
|
| [24] |
MIAO H B, HUANG L S, SHEN Y, et al. Steganalysis of compressed speech based on Markov and entropy[C]//International Workshop on Digital Watermarking. Berlin Heidelberg:Springer-verlag, 2013:63-76. DOI:10.1007/978-3-662-43886-2_5.
|
| [25] |
REN Y Z, CAI T T, TANG M, et al. AMR steganalysis based on the probability of same pulse position[J]. IEEE Transactions on Information Forensics and Security, 2015, 10(9): 1801-1811. DOI:10.1109/TIFS.2015.2421322 |
| [26] |
HOLUB V, FRIDRICH J. Designing steganographic distortion using directional filters[C]//Information Forensics and Security (WIFS). New York:IEEE Press, 2012:234-239. DOI:10.1109/WIFS.2012.6412655.
|
| [27] |
PEVNY T, FILLER T, BAS P. Using high-dimensional image models to perform highly undetectable steganography[C]//International Workshop on Information Hiding (LNCS 6387). Berlin Heidelberg:Springer, 2010:161-177. DOI:10.1007/978-3-642-16435-4_13.
|
| [28] |
HOLUB V, FRIDRICH J. Digital image steganography using universal distortion[C]//Proceedings of the First ACM Workshop on Information Hiding and Multimedia Security. New York:ACM, 2013:59-68. DOI:10.1145/2482513.2482514.
|
| [29] |
FILLER T, JUDAS J, FRIDRICH J. Minimizing Embedding Impact in Steganography Using Trellis-Coded Quantization[C/OL].[2016-05-20]. http://pdfs.semanticscholar.org/9c2d/eded0418cbc0dadc0964be40bb681f02daeb.pdf.
|
| [30] |
RIX A W, BEERENDS J G, HOLLIER M P, et al. Perceptual evaluation of speech quality (PESQ)-A new method for speech quality assessment of telephone networks and codecs[C]//Acoustics, Speech, and Signal Processing of IEEE International Conference. New York:IEEE Press, 2001, 2:749-752. DOI:10.1109/ICASSP.2001.941023.
|
| [31] |
ZHANG W, ZHANG Z, ZHANG L, et al. Decomposing Joint Distortion for Adaptive Steganography[DB/OL].[2016-04-01]. http://staff.ustc.edu.cn/~zhangwm/Paper/2016_13.pdf.
|