 2019, Vol. 65
2019, Vol. 65
文章信息
- 李智, 张娟, 方志军, 黄勃, 姜晓燕, 黄正能
- LI Zhi, ZHANG Juan, FANG Zhijun, HUANG Bo, JIANG Xiaoyan, HWANG Jenq-Neng
- 基于循环生成对抗网络的道路场景语义分割
- Road Scene Semantic Segmentation with Cycle-Consistent Adversarial Networks
- 武汉大学学报(理学版), 2019, 65(3): 303-308
- Journal of Wuhan University(Natural Science Edition), 2019, 65(3): 303-308
- http://dx.doi.org/10.14188/j.1671-8836.2019.03.011
-
文章历史
- 收稿日期:2018-07-04



引用本文

|



2. 华盛顿大学 电气工程系, 华盛顿 西雅图 98195
2. Department of Electrical Engineering, University of Washington, Seattle 98195, Washington, USA
随着无人驾驶汽车技术的快速发展,车道线检测[1]、行人检测[2]、交通标志识别[3]、道路场景语义分割[4]等技术都得到了关注,这些任务有很大的挑战性。道路场景语义分割是对道路场景图像中不同语义,即场景中物体的类别进行分割,它是图像语义分割[5]领域在现实中的应用,受到极大的关注。
近几年深度学习(deep learning)获得了重大进展,特别是卷积神经网络在图像语义分割方面取得了一系列成果[6~9]。然而由于利用卷积神经网络进行图像语义分割方法[10]基于有监督算法,需要大量标记样本,标记样本需要达到像素级标注。根据文献[11],像素级标注图像的耗时相较于图像定位多15倍,这限制了基于卷积神经网络的图像语义分割方法的应用范围。
生成对抗网络[12](generative adversarial networks,GAN),对于半监督学习的发展具有重要意义,在学习过程中不需要数据标签,可以解决一般网络模型过于依赖数据量及标签的缺点。虽然生成对抗网络对半监督学习有一定的启发意义,但是生成对抗网络并不完美,它在解决已有问题的同时也引入了一些新的问题。比如生成对抗网络生成的样本虽然具有多样性,但是存在模式崩溃[13] (mode collapse)问题,即可能生成多样的,但差异不大的样本。
2017年,Zhu等[14]提出了循环生成对抗网络(cycleconsistent adversarial networks,CycleGAN)。这种方法相较于传统生成对抗网络,有两点改进:一是将网络的输入改为给定的图片数据,传统生成对抗网络的输入是随机噪声,因此,传统生成对抗网络只能随机生成图片,无法控制输出图片的质量;二是无需成对数据,传统的生成对抗网络需要成对数据,即每一张图片都有一张对应的真实标注图片,而循环生成对抗网络无需成对数据,因此循环生成对抗网络相较于传统生成对抗网络,应用更广泛,对数据量和标签的要求更低。但该方法的训练过程不稳定,根据文献[13]的研究,使用对抗损失函数(adversarial loss)的生成对抗网络在(近似)最优判别模型下,会导致生成模型梯度(近似)为0,即梯度消失。
本文改进了循环生成对抗网络,将循环生成对抗网络中的目标函数对抗损失函数替换为最小二乘损失函数(least squares loss) [15],增加了训练过程的稳定性,提高了图像分割的质量;并使用L2范数解决了训练过程中出现的模式崩溃问题。
1 本文方法 1.1 循环生成对抗网络原始生成对抗网络的目标是学习噪声向量Z与输出图像Y之间的映射关系[12],即G:Z → Y。而循环生成对抗网络[14]是学习观察图像X与输出图像Y之间的映射关系,即G:X → Y。本文使用的方法相较GAN,无需在训练数据之间建立一对一的映射。
图 1给出了本文方法的整体流程示意。图 1(a)给出了循环生成对抗网络结构,分别有一对生成模型(generator)和一对判别模型(discriminator),生成模型G将源域X中的图片映射到目标域Y中,即G:X → Y;与之相反,生成模型F将目标域Y中的图片映射到源域X中,即F:Y → X。图 1(b)给出了循环生成对抗网络正向训练过程,输入图像x经过生成模型G 生成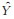
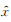
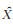
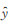

|
| 图 1 循环生成对抗网络 Fig. 1 The cycle-consistent adversarial networks |
本文使用最小二乘损失[15]改进循环生成对抗网络中出现的训练不稳定问题。对于生成模型G以及它对应的判别模型DY,损失函数定义如下:
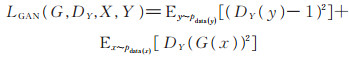
|
(1) |
对于生成模型F以及它对应的判别模型DX,损失函数定义如下:
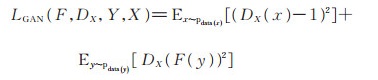
|
(2) |
为了解决生成对抗网络训练过程中出现的模式崩溃问题,本文引入L2范数[16]解决。根据
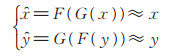
|
(3) |
L2范数损失函数定义为:
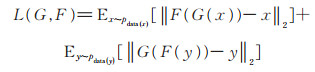
|
(4) |
本文最终的目标函数定义如下:
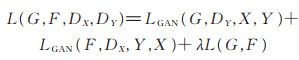
|
(5) |
其中,生成模型G,F与判别模型DX,DY目标如下:
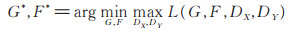
|
(6) |
生成模型由三个部分组成:编码器、转换器和解码器[17]。参考文献[14],输入图像大小固定为256× 256× 3。图像经过编码器之后,输出尺寸为64× 64× 256。之后使用6层Resnet [18]模块实现转换器的功能。解码器与编码器的作用完全相反,使用3层反卷积层实现,最终得到一个大小为256× 256×3的生成图。生成模型的结构如图 2所示。

|
| 图 2 生成模型网络结构 Fig. 2 Generator network structure |
判别模型的作用是预测生成模型的输出结果为原始图像还是生成模型的输入图像。判别模型的网络结构只由编码器组成,本文使用5层卷积层实现;最后一层产生1维输出的卷积层确定这些特征是否属于特定类别。判别模型的结构如图 3所示。

|
| 图 3 判别模型网络结构 Fig. 3 Discriminator network structure |
本文实验操作系统为64位Windows 10。算法基于TensorFlow框架,版本为1.8.0,编程语言为Python 3.5。本文所有的实验均在显卡GTX1080Ti下进行。
实验分为3组:1)本文算法收敛实验;2)对不同测试图像运用本文算法生成图像;3)本文算法与其他算法对比,本组的测试样本数量为500。
2.2 数据集实验使用数据集Cityscapes [19]。Cityscapes是图像语义分割领域的基准数据集,包括50个城市的街道图像,共计20 000幅粗略标注图像,5 000幅精细标注图像;为了测试本文方法的有效性,随机选取其中200幅原始图像以及200幅精细标注图像进行训练。
2.3 算法收敛实验图 4所示为生成模型根据街道图像生成的一些街道语义分割图像,测试图像包括非结构化道路、高速公路、十字路口等多种场景的道路。可以看出,随着训练轮数的增加,生成器生成的街道语义分割效果会更好。

|
| 图 4 不同迭代次数后生成模型的生成效果 Fig. 4 Generating effect of generator after different iteration times |
本组实验选取了2 475张图像训练,500张图像用于测试,测试图片包含弯道、狭窄小路、双向车道等。开始实验之前先将图像压缩到256×256,之后经过生成器输出生成图片,然后判别器判别生成图片是否为生成的,之后利用生成器与判别器的输出结果计算生成损失与判别损失。随机抽取5组输出,如图 5所示。实验结果表明对于各种道路场景,生成效果明显。

|
| 图 5 不同测试样本生成效果对比 Fig. 5 Comparison of different test sample generation effects |
为验证本文使用的改进循环生成对抗网络方法的有效性,选择3个常用的性能指标[5]度量:像素准确率(pixel accuracy,PA)、平均准确率(mean accuracy,MA)与平均IU(mean intersection over union,mean IU)。分别定义如下:
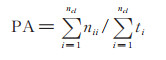
|
(7) |
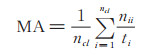
|
(8) |
|
(9) |
其中,nij为分类i的像素被预测为属于分类j的像素数量,ncl为类别的数量,
表 1所示为不同方法在数据集上的性能对比,其中与本文做对比的算法的分割精确度均由文献[14]提供。
CoGAN [20]有两个相互独立的生成对抗网络模型,在训练过程中生成模型和判别模型共享参数。BiGAN [21]的生成器由两个网络模型组成:编码器和解码器。它们同时被训练用于和判别器形成对抗关系。文献[22]提出“模拟+无监督学习”的方法(SimGAN),可以使用合成和未标记的数据训练网络。
在相同数据集以及同数量的训练/测试样本前提下,本文算法的像素准确率、平均准确率、meanIU比CoGAN、BiGAN、SimGAN的提高了30%以上;同时,比CycleGAN的像素准确率和meanIU也有一定的提高,说明使用最小二乘损失对提高生成对抗网络生成图片质量有明显帮助。
从图 6可看出,本文算法的效果明显比CoGAN、BiGAN、SimGAN的好。图 6中第一行,CoGAN对车的识别效果很差。图 6中第二行展示了较为复杂场景下的识别效果,CoGAN,BiGAN,SimGAN以及CycleGAN均出现了识别错误以及图片模糊的情况。本文算法也存在一些问题,如在图 6第三行中,街道拐角的轮廓并不光滑。但从整体效果来看,本文算法相较于其他算法取得了更好的分割结果。

|
| 图 6 本文算法与其他算法在Cityscapes上分割效果对比 Fig. 6 Comparison of the segmentation results between the proposed algorithm and other algorithms in Cityscapes |
本文使用循环生成对抗网络将街道图片转换成街道场景语义分割图片。该方法与传统生成对抗网络方法有所不同,但生成结果相较于基准方法有提升。未来工作在于改进循环生成对抗网络的网络结构,加快网络收敛速度,提高图片分割质量。
| [1] |
刘富强, 张姗姗, 朱文红, 等. 一种基于视觉的车道线检测与跟踪算法[J]. 同济大学学报(自然科学版), 2010, 38(2): 223-229. LIU F Q, ZHANG S S, ZHU W H, et al. A visionbased lane detection and tracking algorithm[J]. Journal of Tongji University(Natural Science), 2010, 38(2): 223-229. DOI:10.3969/j.issn.0253-374x.2010.02.013 (Ch). |
| [2] |
施培蓓, 刘贵全, 汪中. 基于快速增量学习的行人检测方法[J]. 小型微型计算机系统, 2015, 36(8): 1837-1841. SHI P B, LIU G Q, WANG Z. Fast incremental learning method for pedestrian detection[J]. Journal of Chinese Computer Systems, 2015, 36(8): 1837-1841. DOI:10.3969/j.issn.1000-1220.2015.08.034 (Ch). |
| [3] |
徐岩, 王权威, 韦镇余. 一种融合加权ELM和AdaBoost的交通标志识别算法[J]. 小型微型计算机系统, 2017, 38(9): 2028-2032. XU Y, WANG Q W, WEI Z Y. Traffic sign recognition algorithm combining weighted ELM and AdaBoost[J]. Journal of Chinese Computer Systems, 2017, 38(9): 2028-2032. DOI:10.3969/j.issn.1000-1220.2017.09.021 (Ch). |
| [4] |
魏云超, 赵耀. 基于DCNN的图像语义分割综述[J]. 北京交通大学学报, 2016, 40(4): 82-91. WEI Y C, ZHAO Y. A review on image semantic segmentation based on DCNN[J]. Journal of Beijing Jiaotong University, 2016, 40(4): 82-91. DOI:10.11860/j.j.issn.1673-0291.2016.04.013 (Ch). |
| [5] |
姜枫, 顾庆, 郝慧珍, 等. 基于内容的图像分割方法综述[J]. 软件学报, 2017, 28(1): 160-183. JIANG F, GU Q, HAO H Z, et al. Survey on contentbased image segmentation methods[J]. Journal of Software, 2017, 28(1): 160-183. DOI:10.13328/j.cnki.j0s.005136 (Ch). |
| [6] |
LONG J, SHELHAMER E, DARRELL T.Fully convolutional networks for semantic segmentation[C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE, 2015: 3431-3440.
|
| [7] |
CHEN L C, PAPANDREOU G, et al. Deeplab:Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. DOI:10.1109/TPAMI.2017.2699184 |
| [8] |
ZHENG S, JAYASUMANA S, ROMERA-PAREDES B, et al.Conditional random fields as recurrent neural networks[C] // Proceedings of the IEEE International Conference on Computer Vision.Piscataway: IEEE, 2015: 1529-1537.DOI: 10.1109/ICCV.2015.179.
|
| [9] |
CHEN L C, YANG Y, WANG J, et al.Attention to scale: Scale-aware semantic image segmentation[C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE, 2016: 3640-3649.
|
| [10] |
LIN G, SHEN C, VAN DEN HENGEL A, et al.Efficient piecewise training of deep structured models for semantic segmentation[C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE, 2016: 3194-3203.
|
| [11] |
LIN T Y, MAIRE M, BELONGIE S, et al.Microsoft coco: Common objects in context[C] // Proceedings of the European Conference on Computer Vision.Berlin: Springer, 2014: 740-755.
|
| [12] |
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al.Generative adversarial nets[C] // Proceedings of the Advances in Neural Information Processing Systems.Massachusetts: MIT Press, 2014: 2672-2680.
|
| [13] |
ARJOVSKY M, CHINTALA S, BOTTOU L.Wasserstein GAN[EB /OL].[2017-01-26].https://arxiv.org/pdf/1701.07875.pdf.
|
| [14] |
ZHU J Y, PARK T, ISOLA P, et al.Unpaired Imageto-image Translation Using Cycle-Consistent Adversarial Networks[EB / OL].[2017-03-30].https://arxiv.org/pdf/1703.10593.pdf.
|
| [15] |
MAO X D, LI Q, XIE H R, et al.Least squares generative adversarial networks[C] // Proceedings of the IEEE International Conference on Computer Vision.Piscataway: IEEE, 2017: 2813-2821.
|
| [16] |
PATHAK D, KRAHENBUHL P, DONAHUE J, et al.Context encoders: Feature learning by inpainting[C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE, 2016: 2536-2544.
|
| [17] |
BADRINARAYANAN V, KENDALL A, CIPOLLA R. Segnet:A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495. DOI:10.1109/TPAMI.2016.2644615 |
| [18] |
HE K, ZHANG X, REN S, et al.Identity mappings in deep residual networks[C] // Proceedings of the European Conference on Computer Vision.Berlin: Springer, 2016: 630-645.
|
| [19] |
CORDTS M, OMRAN M, RAMOS S, et al.The cityscapes dataset for semantic urban scene understanding [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE, 2016: 3213-3223.
|
| [20] |
LIU M Y, TUZEL O.Coupled generative adversarial networks[C] // Proceedings of the Advances in Neural Information Processing Systems.Massachusetts: MIT Press, 2016: 469-477.
|
| [21] |
DUMOULIN V, BELGHAZI I, POOLE B, et al.Adversarially Learned Inference[EB / OL].[2017-01-26].https://arxiv.org/pdf/1701.07875.pdf.
|
| [22] |
SHRIVASTAVA A, PFISTER T, TUZEL O, et al.Learning from simulated and unsupervised images through adversarial training[C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway: IEEE, 2017: 2107-2116.
|