 2016, Vol. 62
2016, Vol. 62
文章信息
- 彭敏 , 官宸宇 , 朱佳晖 , 谢倩倩 , 黄佳佳 , 黄济民 , 杨绍雄 , 高望 , 应称 . 2016
- PENG Min, GUAN Chenyu, ZHU Jiahui, XIE Qianqian, HUANG Jiajia, HUANG Jimin, YANG Shaoxiong, GAO Wang, YING Chen . 2016
- 面向社交媒体文本的话题检测与追踪技术研究综述
- A Survey on Topic Detection and Tracking in Social Media Text
- 武汉大学学报(理学版), 2016, 62(3): 197-217
- Journal of Wuhan University(Natural Science Edition), 2016, 62(3): 197-217
- http://dx.doi.org/10.14188/j.1671-8836.2016.03.001
-
文章历史
- 收稿日期:2015-12-17



引用本文

|


社交媒体(social media)是指一系列建立在Web 2.0基础上,允许用户创造和交流UGC(user generated content)的互联网应用[1].人们在生活中经常使用的微博、博客、社区网站等都属于典型的社交媒体.借助于这些平台,无论是观点的表达和交换,或是信息的获取和传播,都变得自由、方便和快捷,因此这些社交媒体吸引了大批网络用户,并且用户数量还在不断增长.根据《2015中国社交媒体影响报告》的数据显示,在2014年社交媒体用户规模持续扩大,以极具代表性的新浪微博为例,其月活跃用户数(monthly active users,MAUs)已经达到1.67亿人次,较2013年同期增长36%(http://data.weibo.com/report/reportDetail?id=215);同时遍布全球范围的社交媒体网站Twitter在2015年第一季度的月活跃用户数已达到3.08亿,而竞争对手Facebook的活跃用户更是稳定在10亿人之上.在广泛覆盖互联网用户的同时,社交媒体也给其生活带来了不可低估的影响,最重要的方面在于,通过社交媒体平台,人们可以实时获取新闻资讯和各种对自己有价值的实用信息.
许多已有的商业门户网站都会为用户收集并提供丰富的新闻报道给用户,比如新浪、网易等.然而,报道内容一般由新闻编辑人工编写,带有一定的主观性,且新闻数量非常庞大.如果参考多个门户网站的报道,很难对关心的新闻事件有一个清晰准确的认识.在社交媒体平台上,新闻话题多来源于事件现场的用户实时发布的消息,或者具有较高影响力用户的及时推送,经由多人进行评论和转发分享,相互交换意见,使得该新闻事件得以广泛迅速地传播开来,其发展动态也易于被人们追踪.例如微博,用户在该平台上发布的丰富而又全面的内容不仅创造了人们在社交网络中争相讨论的一个又一个热门话题,更是吸引了众多传统媒体利用微博来对相关事件做进一步的跟进.然而,随着参与用户数量的增加,话题热度飙升的同时,相关的帖子数量也随之猛涨,而用户的精力却十分有限,不可能通过阅读所有帖子来获取相关话题的有用知识.话题检测与追踪技术可以有效解决此类问题.
通过使用话题检测与追踪技术,用户关心的信息可以从海量且杂乱无章的各类信息中被挑选出来,经过严格的过滤和有效的组织,生成简单明了的话题并呈现给用户,使用户能够及时了解自己关注的领域话题以及当前社会上出现的热点事件.对于普通网络用户来说,话题检测的应用能够帮助他们在获得话题知识的过程中节省更多的时间和精力,使他们在无先验知识的情况下,能够了解社会上发生的大大小小的事件,并追踪事件的来龙去脉[2].对于企业而言,用户在社交媒体平台上发表的与之相关的评价,以及关乎同一行业中其他企业的热议话题和突发事件,都是十分宝贵的信息,通过话题发现进行监测,帮助企业及时调整策略,能够使企业稳定发展.对于政府,话题检测与追踪有助于了解社会舆情,聆听人民需求,监督社会秩序.所以,做好话题检测与追踪的研究工作,对社交媒体的参与者具有十分重要的现实意义.
而作为信息处理领域中备受关注的研究热点,话题检测与追踪技术在发展初期将新闻媒体信息流作为研究对象,通过监控新闻描述的话题,发现新的用户感兴趣的信息并追踪下去,最后将涉及某个话题的新闻组织起来以某种方式呈现给用户[3].而后由于计算机技术的飞速发展和互联网的广泛普及,社交媒体逐渐流行起来,于是研究人员将目光投向了彼时具有代表性的博客、邮件、社区和论坛等社交媒体形式.不同于新闻报道的语言规范性和内容有效性,社交媒体文本内容随意性较强,且充斥着大量的无价值信息,文档之间的关联性也较低.这些新出现的特征对传统的话题检测与追踪技术提出了更高的要求.然而随着微博、Twitter等短文本形式的社交媒体的爆炸式增长,基于社交媒体文本的话题检测与追踪工作又遇到了新的难题,尤其是在数据规模较大的情况下如何保证信息处理的实时性.网络社交媒体中的大多数内容都是由用户自发创造的,包括文字、图片、音视频以及表情等多种表现形式.本文所讨论的各种话题检测与追踪方法,主要针对用户创造的文本内容.这些文本内容拥有的多方面特征在帮助社交媒体变得广泛流行的同时,也为研究工作带来了如下的困扰:
1) 当下流行的绝大多数社交媒体(比如微博)文本篇幅短小,内容碎片化严重,同时数据量巨大.因此面临高稀疏性及其导致的高维度问题,且存在很多非话题文档,包含大量冗余特征.
2) 由于用户在创造内容时几乎不受约束,语言组织形式多样化,用语随意不够规范,给识别和理解带来了很大的困难.
3) 庞大的用户群体在各个社交媒体平台上频繁发布广告信息,造成信息质量的良莠不齐,内容噪声大大增加.
4) 与一般纯文本不同,社交媒体内容还包含有地理位置、标签等特殊信息,需要加以关注和分析.
已有的在该领域的相关综述文献或是只总结了针对新闻报道的各类话题检测与追踪技术[4~6],又或是仅仅面向微博、Twitter等单一语料,且只完成了话题检测的综述性工作[7, 8],并未涉及话题追踪的相关工作.本文重点论述了应用于社交媒体大规模文本流的话题检测与追踪技术的研究现状,深入分析了近几年来国内外发表的具有代表性的研究成果.针对上文提到的问题和挑战,本文按照应用场景,分别从离线话题检测、在线话题检测和话题演化追踪这三个方面探讨了当前主要的话题检测与追踪方法,介绍了在该领域实验中被普遍使用的评估方式,最后提出了当下面临的挑战和今后的工作方向.
1 研究现状分析 1.1 离线话题检测话题的检测最初应用在离线静态文本上.离线话题检测方法一般基于LDA(Latent Dirichlet Allocation),主要分为两大类,基于概率主题模型的方法和其他非概率主题模型的方法.概率主题模型方法主要分为基于监督的主题建模、基于短语的主题建模、基于稀疏的主题建模和基于领域知识的主题建模.非概率主题模型方法主要包括基于文档和基于特征两大类.
1.1.1 概率主题模型方法1) 基于监督的主题建模
在一些应用场景中,话题检测不仅需要考虑文本,还需要将除文本外的附加属性共同考虑,以提高检测的准确性.例如在推荐系统中,在根据评论文本进行话题检测来预测用户对某一商品的偏好程度时,也需要结合该商品的类别属性.而有监督的主题模型sLDA(supervised LDA)[9]正是这样一个能够利用文本附加属性的话题检测模型.与一般的LDA建模过程不同,sLDA中的每一个文档都包含一个响应变量,类似于文本的标签.然而,在有些场景下,文本往往不止有一个标签,而是带有多个不同的标签,在这种情况下,如何为文本中的主题或词汇找寻最合适的标签也就成为了一个问题.L-LDA(labeled LDA)[10]是一个建立在多标签文本之上的主题模型,它通过用户有监督的主题和标签的配对来实现标签选择的问题.L-LDA与sLDA最大的不同之处在于,sLDA中的标签来源于主题混和经验分布,而L-LDA中的标签来源于文档本身,因而更具可信度.考虑实际情况中往往仅有一小部分文本带有标签,而针对这种小部分带标签的情况,需要采用半监督的方式.PL-LDA(partially labeled LDA)[11]便是一个半监督方式的主题模型,只依靠少部分带标记的文本,便能进行所有文本的主题标签配对.虽然PL-LDA不能解决同义词问题,但是相比于之前的带标记的主题模型,能够在一定程度上解决一义多词问题.为了进一步探索主题在文档集之间的差异性,Rabinovich等人提出了一个基于逆向回归的主题模型IRTM(inverse regression topic model)[12].在IRTM中,文本的一些元数据或边缘信息充当响应变量,响应变量服从高斯分布,反映主题变化的扭曲参数服从拉普拉斯先验分布.IRTM能够有效地建模主题在词汇表达形式上的差异性,并依据该差异性做出相关反馈.
2) 基于短语或顺序的主题建模
基于传统的LDA的主题探测是将文档视为一个“词袋”,不考虑词汇在文档中的出现顺序.然而词汇出现的顺序在某些应用场景下是不可或缺的,而且考虑这种顺序可以有助于主题推断.基于此,Hanna等人首先提出一种基于二元词组的主题模型BTM(bigram topic model)[13],即以二元词组替换LDA中的词汇的概念,以二元词组为基本单位进行主题建模,并以Gibbs EM替代传统的Collapsed Gibbs算法来进行模型参数的推断.该模型无论是在时间效率上还是主题的语义性方面,均优于LDA.TNG(topic n-gram)[14]同样也使用N元词组来进行主题建模,与BTM不同的是,TNG是依据前后词汇之间的上下文信息来确定是否组成词组.TNG探测出的N元词组虽然能够增强主题的有意义性,但是没有考虑到语义合成性,即并非所有的N元词组均能进行语义结合.因此,Lindsey等人在TNG的基础上提出了PD-LDA(phrase-discovering LDA)模型[15],使主题表达的短语更具合理性.PD-LDA采用层次化的Pitman-Yor过程来表达主题与词汇之间的结合关系,并通过马尔可夫蒙特卡洛采样来估计模型参数.PD-LDA探测出的主题短语在词汇冲突性方面较TNG有明显的优势,在二元词组和三元词组方面准确率均有15%左右的提升.此外,在短文本主题建模方面,Yan等人也从二元词组入手提出BTM-2(biterm topic model)[16].BTM-2与BTM虽然都是基于二元词组,但是有着本质的不同,BTM-2中的二元词组不需要考虑顺序性和连贯性,可以是文档中的任意位置的两个词汇组成的词对.而且BTM-2中二元词组的生成过程是同时进行的.通过这种方式,可以使得短文本中词汇的上下文信息被充分地利用,避免了因词汇共现信息不足而导致主题建模病态.
主题建模往往涉及文档、主题、词汇三个层面的工作,因此,不仅需要将主题表达为有意义的词汇组合,也需要将文档表达为有意义的片段组合.NTSeg[17]是一个多粒度的主题模型,它不仅能像TNG一样能产生短语级别的主题,还能产生文档级别的主题,即将文档表达为若干有意义片段的组合.由于NTSeg能产生多粒度的主题,尤其是能产生文档级别的主题,因此能够被有效地运用在一些文档型任务上,譬如分本分类、文本摘要等.词汇需要考虑顺序,主题有时也需要考虑顺序,特别是在一些领域相关的主题建模场景,譬如百度百科中,关于城市的介绍往往以历史、地理、经济、政治的顺序展开.捕捉这类主题顺序信息有助于快速将文档进行主题划分,同时又能够洞悉该领域文档的组成结构.TMTO(topic model of top-t orderings)[18]是一个专注挖掘主题顺序信息的主题模型,它假设某领域的文档均拥有一个特定的主题顺序,但是允许文档与文档之间存在一定的差异性.通过多阶段的top-t个主题的排序及调整,TMTO能够构建适应多数文档主题顺序的模型.
3) 基于稀疏的主题建模
为了使得到的主题具有较强的语义性,通常希望每个主题只跟若干个词汇相关,而不是跟整个词汇列表都相关.因此,保证文档-主题和主题-词汇分布的稀疏性有助于增强主题的语义理解性.
稀疏主题的建模可追溯至凝聚主题模型FTM(focused topic model)[19].FTM在LDA的基础上通过印度自助餐厅过程来生成文档-主题稀疏表达模式,并使得每一个文档只跟若干个主题相关.ICD(IBP compound Dirichlet process)[20]则是在HDP(hierarchical Dirichlet process)的基础上融合印度自助餐厅过程的稀疏主题模型.ICD使得主题在主题簇之间的联系与主题在文档内的重要性相分离,从而构建出更符合文本内容本身的,概念表达凝练的主题.STC(sparse topical coding)[21]对主题模型中混合分布(尤其是主题-词汇分布)的正则化约束进行松弛,创造性地将主题表现为词汇的稀疏编码,使得产生的主题模型具有以下两个特点:1)主题-词汇分布具有稀疏性,表意更为明确;2)模型的范式与凸优化问题相结合,能够被应用到一些机器学习学习的场景中.OSTC(online sparse topical coding)[22]是STC的在线改进,以适应大规模文本主题建模的需求.同STC一样,OSTC也涉及正则化约束和稀疏编码,所不同的是,OSTC的梯度优化更新方式更具有可扩展性,收敛速度也更快.
STC和OSTC都只是单稀疏的主题模型,即只有主题-词汇分布是稀疏的.然而在有些情况下,也需要文档-主题分布的稀疏性,尤其是在社交网络短文本情景下,一个短文本由于其信息的简短性,往往只和少部分主题相关.DsparseTM(dual-sparse topic model)[23]是一个双稀疏化的主题模型,不仅主题-词汇分布是稀疏的,文档-主题分布也是稀疏的.一般地,一个分布若是稀疏化,往往平滑性就较差,而DsparseTM通过Spike and Slab先验分布能够将分布的稀疏性和平滑性相分离,从而解决了稀疏性和平滑性无法兼顾的难题.DsparseTM在分类和聚类准确率方面均优于单稀疏的STC,而且产生的主题也具有较强的语义解释性,在短文本主题挖掘方面具有一定的实际效果.
cFTM(contextual focused topic model)[24]是一个无参数的稀疏主题模型.与STC等稀疏主题模型不同的是,cFTM强调了利用上下文的作用,并利用文本的作者和地点信息来辅助主题建模.SACM(sparse aspect coding model)[25]也是一个注重利用边缘信息的稀疏主题模型.与cFTM不同的是,SACM的稀疏性是通过L1正则化约束来实现的.而与STC不同的是,SACM能够充分利用边缘信息派生出用户内在兴趣变量和商品内在质量变量,构建推荐系统场景下的主题模型.同时,SACM挖掘出的稀疏主题能够较好地反映用户或是商品的内在特性,达到更为准确的推荐效果.
4) 基于领域知识的主题建模
在某些主题建模场景下,文本自身往往具有一定的领域知识背景.而将这些领域知识综合运用到主题建模中,往往能够增强主题的语义信息,使挖掘出的主题更具有意义.基于领域知识进行主题建模有两大难点:一是如何有效地进行知识的表达,二是如何挖掘领域知识.
针对领域知识的表达问题,文献[26]提出了Must-Link和Cannot-Link两种词汇表达集合来约束词汇之间的共现情况.所有语义相近的词汇均处于同一个Must-Link集合中,而一般不太可能共同出现的词汇则处于Cannot-Link集合中.这两者统一于Dirichlet森林先验分布之下,并基于此进行参数的推断,构建DF-LDA(Dirichlet forest LDA)模型.通过DF-LDA产生的主题比LDA产生的主题在语义概念上更为清晰,能够将表意相同的词汇较好地归结在同一个主题下.Newman等人[27]基于外部知识构建词汇之间的依赖关系矩阵,将该矩阵正则化主题-词汇分布即可挖掘具有丰富语义信息的主题.词汇之间依赖关系主要借助点对互信息(point-wise mutual information,PMI)来刻画,而正则化的形式主要为二次型正则化或卷积正则化.Kang等人将雅虎、维基百科等带标注的语料库作为先验信息来辅助主题建模,提出了thLDA(transfer hierarchical LDA)模型[28].在thLDA中,首次借助了迁移学习的方式,将其他领域的信息用来指导当前文本集合的主题建模,有效地克服了短文本中词汇共现量不足、上下文信息不丰富的缺陷.由于采用了知识库,thLDA产生的主题具有较强的语义理解性,能够有效地运用在大规模短文本主题建模中.Rajagopal 等人[29]提出了基于常识的主题建模,将常识反映到主题构建的过程中.在该模型中,文档并不是以全部词汇为特征,而是以“语义原子”为特征.此处的语义原子是指关于某一个概念的相关词汇或短语的集合,语义原子的挖掘主要通过语法树解析提取相关名词来实现.为了进一步提纯,所产生的主题还需要再一次经过层次聚类.基于常识构建的主题无需通过额外的语料库训练,且能够较为有效地运用在文本聚类中.Lim 等人[30]提出了TOTM(Twitter opinion topic model)来进行Twitter文本的意见和情感挖掘.在TOTM中,文本标签、表情符号、情感词等信息起到了十分重要的作用.不同于以往的一些基于情感的主题模型,TOTM不需要构建主题关于情感的分布,而是直接构建意见-目标对.此外,为了增强情感分析的能力,TOTM中引入论文情感词典作为情感先验知识,也增强了自适应学习的能力.TOTM的意见和情感的分析功能能够被运用于推荐系统应用之中,以实现用户兴趣挖掘和行为预测.Chen等人在DF-LDA的基础上进行相关改进,提出了一个融合多领域先验知识的主题模型MDK-LDA(LDA with multi-domain knowledge)[31].MDK-LDA同样注重运用领域知识,但是更注重以旧推新,使用s-set来包罗具有相同语义的词汇.与DF-LDA不同的是,MDK-LDA不使用Cannot-Link,只使用Must-Link,并以s-set的形式进行语义关联强化,这样能够避免Must-Link带来的弊病,即相同意思的词汇对之间概率值会趋于相同.MDK-LDA采用广义的玻利亚罐(generalized Pólya urn,GPU)模型建模生成过程,产生的主题比LDA和DF-LDA更具有语义解释性.紧随MDK-LDA的是GK-LDA(general knowledge LDA)[32],它是一个基于广义领域知识的主题模型.GK-LDA中的知识以LR-set的形式体现,构造方法是词典语义关联法,主要是利用同义词、一词多义和形容词.GK-LDA与MDK-LDA的不同之处在于它并不假设所有提供的知识均是正确的,且能够发现和解决错误的知识.模型的参数推断同MDK-LDA一样也是采用GPU,产生的主题在语义理解性方面要优于DF-LDA和MDK-LDA.Chen等人[33]提出的MC-LDA(LDA with m-set and c-set)是又一个采用Must-Link和Cannot-Link词对约束的基于领域知识的主题模型.与MDK-LDA和GK-LDA不同的是,MC-LDA丰富和完善了Cannot-Link集合的内容,提出了领域一致的Cannot-Link和领域不一致的Cannot-Link,并通过扩展的广义玻利亚罐(extended generalized Pólya urn,E-GPU)模拟生成过程进行参数推断.MC-LDA取消了Must-Link的传递性,不仅可以解决一词多义问题,还能依据Cannot-Link集合的划分效果自动地确定主题个数,是一个注重聚类和主题抽取并举的模型.
领域知识并非与生俱来,在某些情况下,尤其是数据规模较大的情况下,领域知识往往无法事先提供,需要进行挖掘整理.针对如何挖掘领域知识的问题,Chen等人提出了基于自动先验知识学习的主题模型AKL(automated prior knowledge learning)[34].它与以往的领域知识主题模型的不同之处在于更专注于对于领域知识的自动挖掘,尤其是在事先没有提供任何知识的情况下.在首次使用时,由于没有任何先验知识,因此模型采用LDA挖掘潜在主题,然后对潜在主题集合进行频繁项集挖掘和聚类来产生一些词汇簇作为知识的表现形式.针对多领域知识的问题,Chen等人[35]又提出了多领域的主题模型LTM(lifelong topic model).LTM是第一个基于生命周期学习的主题模型,能够学习历史数据得到领域信息,用于新一轮主题建模.它与DF-LDA、MDK-LDA、GK-LDA、MC-LDA以及AKL的不同在于能够在没有领域知识提供的基础上自动挖掘多领域的知识.同时,LTM在可操作性方面和主题语义解释性方面具有较为显著的提升,能够以无监督的方式实现有监督的效果.AMC(automatically generated must-links and cannot-links)[36]是Chen等人提出的又一个基于生命周期学习的主题模型.AMC相比于LTM,更强调像人一样学习,强调大数据的应用场景.在AMC中,沿用了Must-Link和Cannot-Link的思想,采用频繁项集挖掘方法分别挖掘这两类知识,然后采用多元广义玻利亚罐模型(multi-generalized Pólya urn,MGPU)进行推断.AMC能够解决一词多义问题,也能够检测错误的领域知识,还能够避免使用Cannot-Link带来的弊端,是领域知识主题模型中的最新代表.本文分别从是否属于自动挖掘、是否涵括多领域、知识表达方式、推断方法以及重要特点等方面对上述部分领域知识主题模型进行了对比分析,结果如表1所示.
| 主题模型 | 是否自动挖掘 | 是否多领域 | 知识表达 | 推断方法 | 特点备注 |
| DF-LDA | 否 | 否 | Must-Link, Cannot-Link | Dirichlet森林 | 扩展Dirichlet分布 |
| MDK-LDA | 否 | 否 | Must-Link | GPU | 解决Must-Link的趋同性 |
| GK-LDA | 否 | 是 | LR-set | GPU | 基于广义领域知识、可容错 |
| MC-LDA | 否 | 否 | Must-Set, Cannot-Set | EGPU | 完善Cannot-Link、自动确定主题个数 |
| AKL | 是 | 否 | 词汇簇 | GPU | 频繁项集挖掘 |
| LTM | 是 | 是 | pk-set | GPU | 生命周期学习、大数据 |
| AMC | 是 | 是 | must-link knowledge, cannot-link knowledge | MGPU | 迁移学习、词汇图、大数据 |
1) 基于文档的方法
基于文档的方法将文档作为主题的基本单元,首先对文档进行解析构造抽象表达,有时也加入外部特征,然后使用距离函数计算与类中心或其他文档的距离,最后进行分类或聚类并进行一定的筛选,输出的类就是主题.例如,文献[37]将主题抽取任务拆分为两步,第一步是训练一个相似度函数,使用之前已标注数据和Twitter文本的全部相关特征训练一个有监督的分类器.分类器将一对文本作为输入,并决定两个文本是否属于同一个主题.第二步则是基于第一步分类器给出的结果使用传统的层次聚类方法聚类得到主题.而文献[38]则在将文本转化到向量空间后,应用潜在语义索引,即对文本-词汇矩阵作奇异值分解使得文本向量被映射为低维特征向量.在得到特征向量后,相对于传统的层次聚类方法,该方法使用了一种两层层次聚类,即文本被划分为批次,每一批次内先进行一次层次聚类,再将得到的类进行一次单遍聚类,最终得到主题.
2) 基于特征的方法
基于特征的方法将主题视为一个由一系列相似度较高的短语组成的集合.这一类方法首先处理文本并经过筛选得到候选短语,之后同样使用相似度函数计算两个短语之间的相似度,并对之进行聚类得到主题.例如,文献[39]解析出现次数超过20次的单个单词,并使用二分k-means算法聚类得到主题.
与之相对的,文献[40]则侧重计算一个集合短语的共现度而不是两个短语之间的相似度.首先通过随机抽取Twitter文本计算一个短语的基础出现概率,并与现实文档库比较得到候选短语;然后对每一个候选短语构建一个主题集合,采用贪婪的方式添加与之相似度最高的短语直到超过设定阈值.最后去除重复的主题集合得到主题.该方法松弛了频繁项集挖掘的限制,并不严格要求集合内的所有短语都在同一文档内出现.类似的利用短语间共现关系的方法还有文献[41],将主题抽取视为在短语共现矩阵上的非负矩阵分解(nonnegative matrix factorization,NMF)问题.在传统应用非负矩阵分解解决主题抽取的方法中,所分解的文档-词汇矩阵在Twitter数据集上非常稀疏,维度也非常大.因此该文献中使用的是将每一个短语表示为由与其他每一个短语的点对互信息构成的向量组成的短语共现矩阵,应用非负矩阵分解得到短语-主题矩阵,最终得到的主题是关于短语的权重向量.
1.2 在线话题检测随着社交媒体的迅猛发展,信息更迭的速度也随之加快,同检索历史事件相比,越来越多的用户更倾向于了解最新发生的热点事件或者人们正在热烈议论的焦点话题,在这种背景下,在线话题检测(online topic detection,OTD)技术应运而生.在线话题检测是话题检测与追踪中的一个重要研究课题,其特点在于系统必须在对所有话题毫不了解的情况下构造话题检测模型,并根据该模型检测陆续到达的数据流,从中识别出最新话题,同时收集已识别话题的相关后续报道[42].该技术可以做到在大规模网络数据流的环境中对话题的实时检测.然而数据流连续、有序、快速到达、动态变化的特点以及在线分析的应用需求,需要话题检测方案能够持续监视数据流,并且只能对数据流进行单遍扫描,因为将全部数据保存起来进行重复处理是不现实的[43].这些限制条件使得传统的离线话题检测方法在应对在线文本数据流时并不适用.许多研究人员在相关离线话题检测经典算法的基础上,针对随着时间变化的在线数据流的特点,提出了一系列有效的解决方案.本文按照应用场景将在线话题检测分为一般话题检测、突发话题检测和实时话题检测,并将在下文中从这三个方面来详细讨论各领域的研究现状.
1.2.1 一般话题检测一般话题检测的任务是在社交媒体数据流中对热点话题进行检测,本节所讨论的研究成果大多致力于提高被检测话题的质量和完整性.
传统的话题检测方法可以简单概括为对数据集进行聚类,得到的每个簇描述一个话题.由于本章讨论的话题检测环境为在线数据流,传统的聚类方法不能有效地发挥其作用,因而许多研究人员在此基础上提出了新的改进方案,例如后来被普遍应用的增量型聚类方法[44].Li等人[45]设计了一个针对Twitter的事件检测系统,首先检测出具有突发性的tweets片段作为事件片段,其次根据它们的频率分布和内容相似性进行聚类,最后利用外部知识(例如维基百科)来识别真实的事件并能够改善用以表示事件的文本片段质量.其中,tweets片段是指大量存在于Twitter数据中的连续词语或短语.对比一元语法模型,作者使用tweets片段明显减少了事件检测过程中的噪声影响,并且使得检测出的事件易于理解.Yin[46]将事件检测过程分为线上和线下两个阶段,线上阶段增量式地检测以形成基本簇,并维持其概括性统计信息,同时线下阶段将相似的基本簇自底向上进行合并,生成基于事件的完整簇.
随着在社交媒体数据中进行话题检测的热度逐渐高涨,很多研究人员都将目光聚集在了以微博为首的社交媒体数据流所具备的特征上面.Lee等人[47]针对短文本数据流的特点,提出了一个改进的基于密度的聚类方法,使用滑动时间窗口技术来处理大量文本流;为了保证检测话题的新颖性对词语赋权值,并利用构建的短文本邻近关系有效解决了增量式聚类算法Incremental DBSCAN[48]存在的文本内容主题不明确等问题,同时在探测到主题之后执行了主题排序算法,用以给用户提供重要的新兴事件.Pervin等人[49]提出在处理高速实时的短文本流时先找到频繁出现的词对,而后运用启发式的关联规则方法将词对扩展为频繁出现的三个或者更多词的组合簇,用以更全面地表示检测到的话题.在聚类步骤之后,文章又计算了各个簇的突发值,来定义各话题的流行性,并且在进一步的筛选后将结果返回给用户.Kumar等人[50]针对Twitter流存在的语言不规范性、数据量庞大以及速率快等问题,使用single-pass聚类和压缩距离的方法加以解决,进而达到从Twitter流中有效检测事件的目的.其中,压缩距离是指由归并两条文本所得的压缩增益而获取的此两条文本之间的距离,相比于需要额外维持词表和数据转换的余弦距离,压缩距离可以直接应用于流动的Twitter文本,从而提高了事件探测的工作效率.除了以上短文本流所具备的基本特征外,Fang等人[51]从话题在时间和空间上的局部性质入手,提出了一个基于多视点聚类的新框架,整合了Twitter文本的语义关系、社群标签关系和时序关系等,并通过聚类之后实施的基于后缀树的关键词提取技术,有效保持了关键词的正确顺序,进而保证了所检测热点话题的质量.在近期的研究成果中,Feng等人[52]设计了一个全新的基于标签聚类的Twitter流事件检测方法,其亮点在于提出了一种新的数据结构STREAMCUBE,对数据立方体结构进行了时间和空间维度上多层次的扩展,使得用户可以获得任意时间段以及地区内的已经发生过的或是正在发生的事件.为了保证高可扩展性,该方法使用分治策略来构建STREAMCUBE结构,该结构能够保证Twitter数据的实时交互性.
由聚类又衍生出了基于图以及网络的话题检测方法.Zhou等人[53]针对危机管理和决策等类似实际应用在Twitter流中进行事件检测,首先提出一个图模型LTT(location-time constrained topic),综合考虑了社交数据的内容、时间和地点信息,将每条消息描述为一组主题上的概率分布,从各个维度着手解决了社交数据的不确定性问题.在此基础上,事件检测过程通过对数据流执行相似性连接来实现,其中两条消息的相似度用它们概率分布的距离来衡量.同时,Zhou等人又提出一个基于维度可变可扩展散列的索引方案,有效加强了相似性连接,即提高了事件检测的速度.Chen等人[54]展示了一个新方法NPHGS(non-parametric heterogeneous graph scan)用来在整个异构网络中检测和提前预测事件.该方法首先将异构网络图模拟为传感器网络,避免了复杂的建模过程.其中,节点之间的相互关系、节点属性,都可以有不同的代表类型.该网络根据感知邻居节点信息环境评估所有节点在当前时间段的异常水平,通过使用一个新型的图扫描算法最大化非参数扫描统计量,由此对其进行聚类,最终可以获得由事件类型、地理位置、时间以及参与者等信息联合表示的事件内容.Zhang等人[55]强调了文本数据中词语之间存在的潜在共现关系,由此可以检测出那些重要却又难以识别的话题,例如动物的非常规行为可以预示地震的发生.他们提出,在提取词语共现关系生成词图后,可将由LDA建立的语义信息图与之相结合,最后利用图分析方法来提取话题.其中,词图和语义信息图的结合充分利用了词语的共现关系和语义关系,使得话题检测更加准确和完整.
另外,主题模型方法也被频繁用于话题检测任务当中.传统LDA以及基于LDA的一系列检测方法都是面向静态数据集的,而Hoffman等人[56]顺应技术发展需要,提出了在线LDA技术(online LDA,OLDA),引入在线式的变分推断方法,利用一种随机的自然梯度算法来判断收敛到目标函数的程度.它可以做到直接对大量在线数据流进行分析处理.Lau等人[57]提出了一个在线更改版的LDA方法,在每个时间窗口中,使用之前生成的模型指导新的模型学习,从而增量式地更新主题模型.每次更新,主题中词的分布也随之变动.当一个事件发生时会引起主题中词分布的突然变化,由此通过使用Jensen-Shannon散度措施来监测主题的变动程度,进而达到检测事件的目的.Zhang等人[22]针对OLDA不能有效控制主题稀疏度的缺点,提出了一个稀疏在线主题模型,通过稀疏诱导正则化(sparsity-inducing regularization)直接控制潜在语义模式的稀疏度,并使用一个在线算法学习局部字典.实验证明该方法比OLDA具有更低的困惑度以及更高的主题稀疏度.Guo等人[58]将在线话题检测作为时间优化问题来解决,基于LDA提出一种新的增量式话题检测方法OTD-TF(online topic detection using tensor factorization).该方法首先在当前时间片应用LDA算法获得主题,并使用主题张量来表示主题之间的联系.在使用张量分解将相似主题合并后,文档被重新分配至相应的主题簇中.反复执行以上步骤后,可以获得检测到的话题和趋势,以及话题间的关系.另一方面,为了解决微博文本信息量较少的问题,Peng等人[59]利用潜在话题的多方面特性,提出一种新型的多视图聚类方法来聚合潜在话题,由此得到面向事件的中心话题并进行话题的预测分析.另外,针对数据流形式和巨大数据量给潜在话题检测任务带来的困难,Jiang等人[60]提出了一个新的概率主题模型WSSM(web search stream model),使用检索会话(search session)来保证信息连续性,构造了包含检索会话、查询词和点击链接在内的三元关系,并引入SPI(stream parameter inference)技术训练WSSM,有效缩短了探测任务的响应时间.
近年来涌现出了一批以小波分析、频繁模式挖掘等为首的新方法.Weng等人[61]针对微博中大量无意义的噪声数据,利用小波分析法过滤琐碎的词,并结合傅里叶变换和香农理论计算小波熵的变动来辨识突发情况,最后利用基于模块的图分割技术,能够更加准确地检测出Twitter中的事件.Cordeiro[62]将Twitter流中标签的出现分布用小波信号表示,利用峰值检测方法和连续小波变换检测标签的突增情况来检测事件,并结合LDA主题模型来更好地描述检测到的事件.Yin等人[63]提出一种新型的基于用户和时间的统一混合模型,用来有针对性地同时检测稳定话题和时序话题,即用户感兴趣的话题和突发性的话题,并对它们加以区分.Guo等人[64]将频繁模式挖掘应用到热门话题检测领域,形成频繁模式流挖掘算法,取得了较为有效的效果.Huang等人[65]进一步对频繁模式挖掘加以利用,提出HUPC(high utility pattern clustering)框架来实现话题检测.在该框架中,挖掘出的频繁模式集合须经过高效用模式挖掘算法进行筛选,仅保留少量的高效用频繁模式进行下一步的聚类工作,有效地减少了冗余信息和处理时间.Hu等人[66]将目标定位于挖掘网络文本流中基于用户的稀有连续主题模式,使用基于模式增长的序列模式挖掘算法和模式稀有性分析策略,高效地实现了检测目的.Huang等人[67]针对微博话题检测中需要解决的高维数据、噪声信息以及话题的快速演化等主要问题,提出了一个微博在线话题检测模型——可区分语言模型(discriminative language model,DLM).该模型首先选择微博数据的可区分特征子空间,接着利用一元语言模型实现微博话题的在线检测.
1.2.2 突发话题检测在社交媒体平台上,每天能够产生海量的文本信息.以微博为首的多种媒体相互关联,通过非常方便的信息发表、评论和转发行为,极大地促进了信息的快速传播,同时也为突发话题检测提供了条件.在社交媒体平台上应用突发话题检测技术,对于最新社会热点发现、网络民意及时感知、舆情检测、应急处置等方面都具有积极的现实意义[68].
传统的突发话题检测研究主要针对网页文档进行处理,随着近几年微博等社交媒体的快速发展,研究对象也逐渐转移到了社交媒体数据.基于社交媒体文本的突发话题检测是话题检测的一个子任务,其基础检测方法包括检测数据中的突发特征,对突发特征聚类,以及建立突发性的主题模型等.两种常用的检测流程如图1所示.本节将具体讨论应用于社交媒体文本的突发话题检测技术,同时也包括新兴话题检测和首事件检测.

|
| 图 1 两种突发话题检测基本框架 Figure 1 Two Basic Frameworks of Emerging Topic Detection |
1) 首事件检测.Petrovic'等人[69]提出利用局部敏感哈希(locality-sensitive hashing,LSH)方法检测Twitter中的首事件,在不失精度的前提下,该方法极大地提升了处理速度.Petrovic'等人在后来的工作中又对该解决方案做了改进,针对其存在的同一主题下词汇的高度多样性问题,提出将片段级别的短语与LSH结合在一起来检测首事件,改善了检测效果[70].Wurzer等人[71]则使用查找表(lookup table)来表达之前到达的Twiiter文本流,避免了新到达文本与历史文本的逐一相似度比较,同样能够在不损失准确度的前提下提高处理速度,使得首事件检测可以在完整的Twiiter流中进行.
2) 突发话题检测.本节将重点探讨针对在线文本流进行的话题新颖性和突发性的检测,并按照检测方式进行分类.
① 字典学习:Kasiviswanathan等人[72]提出首先从文档流中学习得到由词项分布表示的字典,其次将新的文档向量用已有的字典进行稀疏表示,如果其重构误差大于一定阈值,那么当前的向量代表的话题就可能是新话题,表明该文档具备一定的新颖性.在此工作的基础上,Kasiviswanathan等人又根据当时逐渐流行起来的交替方向乘子法(alternating direction method of multipliers,ADMM)[73],凭借其对复杂目标函数的学习问题所具有的广泛适应性,提出了更加高效的在线字典学习算法,大大加快了突发话题的检测速度[74].然而随着社交网络数据流量的激增,该方法中字典的更新受到了限制,导致计算效率低下.为解决此问题,Kasiviswanathan等人又进一步提出利用分布式算法,即通过分布并行计算来更新字典,从而提高处理速度和工作效率[75].
② 主题模型:Cataldi等人[76]认为,如果一个词在当前的时间间隔内频繁出现而在过去的时间段内却很少出现,那么这个词可以被看作是突发词.该文章根据老化理论对每个词建立生命周期模型,使用能量值来衡量词的突发性.若在当前时间间隔的能量值高于阈值,则该词被归类为突发词,最后建立主题图连接突发词汇和相关词汇产生突发话题.之后的突发性研究大都接受并扩展了该文中关于突发词的定义.在进一步研究中,Cataldi等人继续使用词语老化模型(term aging model)计算每个词的突发性,并借助图模型方法进行检索,得到可以代表相应话题的最小词项集合[77].
针对标签数量规模较小,不足以单用标签来充分识别话题的问题,Chu等人[78]首先根据PLDA(partially LDA)模型利用不含话题标签的相关tweets来扩充可用样本容量.随后通过SIR(susceptible-infectious-recovered)模型分析发现,标签话题的传播模式类似于急性传染病的传播模式,由此根据在内外源驱动的双重影响下突发话题的传播潜力,建立了突发传染病模型来监测突发话题.Wu等人[79]利用LDA模型来检测话题,根据话题之间的一致性、共现和语义等关系形成话题之间的复合关系,并结合分割的时间窗口序列来构建话题演化模型,最后由话题的演化类型来识别新兴话题.Qiu等人[80]运用自然语言处理中增大信息熵的方法将相关微博整理成一棵主题树,计算文本中每个词的“贡献度”,提前处理掉干扰信息,排除了垃圾数据对话题检测的影响.然后,该方法利用“贡献度”作为空间向量模型(vector space model,VSM)改进后的参数值计算文档间相似度来提取突发话题,达到提高突发话题检测精准度的目的.He等人[68]针对微博特征空间动态变化、信息噪声大的特点,提出一种基于有意义串动量模型的微博突发话题检测方法.该方法首先提取时间窗口内微博信息流的有意义串作为微博信息的动态特征,并根据动力学原理对特征进行动量建模,进而结合特征能量大小、变化趋势以及二阶变化率检测突发特性有意义串,即突发特征,通过合并突发特征形成突发话题.Yan等人[81]对他们之前提出的针对短文本处理的BTM-2方法[16]做了进一步的延伸,考察当前时间窗口内各词对的突发性并作为先验知识,从而在微博流中检测突发话题.该方法有效解决了针对短文本进行主题建模存在的数据稀疏性问题.
③ 特征聚类:Zhang等人[82]结合突发话题固有的特征(比如突发性和罕见性),为当前微博信息流中的每个候选词赋权值,那些比阈值高的词项便是当前时间窗口内的突发话题关键词.Yu等人[83]使用流特征来构建高维特征空间模型,利用特征关联性和新兴模式预测能力的关系,结合数据流特征选择方法,展开新兴模式的在线实时挖掘.该方法不仅可以有效地应对较大的特征空间,还能够在未知完整特征集合的情况下处理高维数据集.其中,流特征被定义为在样本(示例)空间不变的条件下,问题空间中不断随时间流入的特征[84].Guo等人[85]提出的方法与传统方法相比,综合考虑了用户传播特征和用户行为特征,结合计算得到的用户影响力权重,提出突发词抽取算法,得到的突发词更具实际意义,能够愈加清晰地描述某一事件.Shen等人[86]针对微博消息流的多属性和大规模特点,提出一种无需中文分词的实时突发话题检测框架,可以根据消息流动态调整窗口大小,并借助传播影响力来度量实体的突发权值,针对实体、消息、用户采用高阶联合聚类算法结合聚类分析来检测突发话题.
④ 基于统计信息:Saha等人[87]提出了一种动态的非负矩阵分解方法,通过比较分解得到的矩阵的变化能快速地识别新出现的话题,并能追踪到话题随着时间的变化情况.Xie等人[88]通过将数据流统计信息的导数存储起来并实时更新,作为早期检测过程,之后通过解决最优化问题得到突发话题.另外,该方法使用了基于哈希的降维技术来减少存储容量并增加了可扩展性.Schubert等人[89]将突发话题检测看作离群点检测任务,通过对比词和词对的近期出现频率与动态更新的指数加权滑动平均和方差来判断其突发性,同时利用词和词对分布伴随着的长尾效应,提出使用散列技术来监视它们.由于统计及散列方法的使用,该方法大大降低了存储开销.
⑤ 其他方法及特定条件限制:Chen等人[90]将目标定位于微博平台上,为特定组织检测突发话题,提出使用增量聚类算法,整合了用户、关键词以及时间等多方面特征信息来判断话题的突发性.Unankard等人[91]考虑到微博事件中地点的重要性和实用性,将目标放在带有地点信息的突发事件上,结合用户位置和事件地点的强关联性来检测突发热点事件.Zhao等人[92]以从数据流中抽取的突发词为节点,突发词之间的非对称相似度值(文中使用Tversky指数)作为边的权重构建图结构,而后将其分割为若干强连通子图来生成突发话题.
1.2.3 实时话题检测得益于社交媒体的实时性特征,某些特别的应用领域可以获得及时的反馈信息,比如自然灾害预警、交通事故检测等.对于实时话题的检测,也可以将其看作新兴事件检测,只是将部分重点置于检测的实时性方面.
Sakaki等人[93]针对Twitter的实时性特征,设计了一个概率时空模型来实时监测并快速发现地震、龙卷风等类似事件的相关信息,其关键在于将每个Twitter用户看作一个网络传感器,应用卡尔曼滤波(Kalman filter)和粒子滤波(Particle filter)技术来获取事件发生地点以及扩散轨迹.Hong等人[94]提出了一个有效的实时tweets过滤系统,用来在Twitter流中进行事件追踪.随着新的tweets的实时流入,该系统通过动态更新背景语料库来解决冷启动问题,并且在进行文本扩充和保证tweets质量的基础上构建了内容模型.特别地,该系统使用伪相关反馈方法结合固定时间滑动窗口策略有针对性地解决了话题漂移问题.Wang等人[95]结合多方面技术来检测事件,提出利用高斯混合模型从Twitter数据流中抽取出候选突发关键词,基于HDP模型建立了一个时间依赖的HDP(td-HDP)模型来检测事件,并在其中使用随机条件场算法检测事发地点.该方法可以及时并准确地检测到事件发生的内容、地点以及时间.Feng等人[96]将目标定为及时检测出涉及到现实生活中灾害事件的每条微博,并将其转化为分类问题,结合微博、语言、内容以及事件等特征,使用支持向量机(support vector machine,SVM)判断输入微博是否为检测目标微博.此外,该方法使用了一个时域分析法[76]过滤历史事件,保证了检测到的事件的新颖性.Meladianos等人[97]经过调查发现,子话题的出现会引起一些特定词汇被热烈讨论,由此作者提出不同于以往考察方法的新策略,专门考察这些特定词汇的使用频率及变化情况,据此将实时接收到的一系列tweets构造成带权词图,根据图分割方法来检测子事件.其中,该图分割方法是指将图分解出极大连通子图,满足在该子图中起码有一个顶点度数至少为k的条件.Hayashi等人[98]将检测有效话题和过滤Twitter数据流结合起来,提出在实时监控热门话题的同时,按照一份黑名单对新到达的Twitter数据流进行过滤,以达到减少处理时间和提高检测准确性的目的.该黑名单包含了引发话题劫持(topic hijacking)的大量重复发帖的用户以及无意义的词语组合,并能够进行实时更新.
1.3 话题演化追踪随着以Twitter、微博为首的社交媒体的快速发展,在社交媒体文本内容中进行话题演化追踪成为近年来研究的热点.该领域的研究有助于追踪用户的喜好和话题的发展趋势,因此对用户个性化推荐的生成、观点的总结,以及突发事件应急监测等实际应用都有着重要的指导作用.图2[99]展示了一组从2014年3月4日至3月10日的新浪微博热门话题的演化过程.针对前文中提及的社交媒体文本内容所具有的特点和带来的问题,各种有效的解决方案也不断地被提出.本章按照话题演化追踪研究面临的挑战进行分类,对国内外已有的方法进行了总结.
1)数据的时间结构和特性问题
为了解决数据的时间信息无法被充分利用于话题演化分析的挑战,最初,Mei等人[100]在2005年首次将TTM(temporal text mining)应用于话题演化过程,提出了通用概率模型,以无监督的方式发现话题演化模式.其在已有的研究基础上,应用TTM并结合时间信息,在话题层次上进行聚类,分析了话题演化周期,对话题演化模式进行总结摘要.该文提出的方法能够从时间角度有效地分析和总结话题演化结构,有广泛的应用前景.同样结合了时间信息的主题模型还有Blei等人[101]提出的DTM(dynamic topic models)模型.该模型引入了时间窗口,关注主题词分布和文档主题分布随时间的演化,并利用非参数小波回归和卡尔曼滤波改进变分推断算法.与此同时,Wang等人[102] 提出TOT(topics over time)模型,在LDA模型产生过程的基础上,引入了服从Beta分布的时间变量,能够有效地预测主题分布随时间的演化,主要解决了将时间作为连续变量与主题模型相结合的问题.

|
| 图 2 话题随时间演化样例(2014年3月4日至3月10日) Figure 2 Example of Topics over Time (from Mar.4 to Mar.10,2014) |
此外,社交媒体文本内容的稀疏性、动态性等特征,也是探测社交媒体中话题演化趋势的阻碍之一.Lin等人[103]首次提出了DPRF(dynamic pseudo relevance feedback)模型获得与用户查询有关的内容,将话题演化过程探测问题转化成了图优化问题,并用最小权重支配集和近似有向斯坦纳树算法求解,最后产生时间连续和语义连贯的话题演化摘要.
在关注数据质量和用户影响力的同时,缺少与特定用户相关的社交媒体文本内容是话题演化追踪的另一挑战.Qi等人[104]发现有些企业为了盈利,通常需要比普通用户更早知道利益相关话题的演化趋势以做出应对,因此提出了一种规则驱动模型.该模型列出了四种话题演化规则,再将用户分为三类,考虑话题对企业的影响,之后通过聚类建立话题演化的平均场(mean field)方程模型,讨论话题演化的特征和趋势.
另外,社交媒体文本内容的时间动态性也非常复杂,使得在线文本内容的时间演化模式发现过程尤其困难.Yang等人[105]提出使用时间序列形状作为相似性衡量标准的K-SC(K-spectral centroid)时间序列聚类算法来发现时间演化模式,K-SC算法比K-means聚类算法更适用于多种时间演化模式的发现.此外还提出了基于小波变换的增量自适应聚类算法,该算法可较好地运用于大规模数据集.
然而,前面提到的结合时间信息的许多话题模型通常受时间变化形式的限制,或者推断过程消耗较高.Dubey等人[106]进一步对TOT模型进行改进,提出了npTOT(nonparametric topics over time)话题模型,该模型无需事先定义话题个数,提高了推断效率,同时引入了时间变化和话题流行度之间的关系,使得相关话题的演化分析方法类似.
2) 过拟合问题
LDA模型也同样广泛应用于话题演化追踪领域.在LDA中,同一文档的主题先验参数的不同,会产生共现矩阵的过拟合问题.Masada等人[107]在LDA模型的基础上提出了LYNDA(latent dynamically-parameterized Dirichlet allocation)模型,认为LDA模型中的主题的狄利克雷先验参数是文档时间标记的平滑性函数.LYNDA模型比DTM和cDTM的推断过程简单,且能够解决TOT模型无法解决的平滑性问题.
3) 数据流问题
大部分话题演化探测方法,都将文档集作为有限序列来处理.而无限数据流的话题演化探测则需要关注数据分布和特征空间的动态性,比静态数据流的处理更加困难.因此,出现了许多基于概率或者非概率基本模型的在线优化模型.首先是由AlSumait等人[108]提出使用OLDA模型检测突发话题和话题演化.OLDA作为LDA模型的在线改进,主要思想是利用历史数据的模型参数来获取最新文档的分布和话题的演化矩阵.之后,Gohr等人[109]提出了“Topic Monitor”模型,用于追踪无限文档流中话题和词的演化,在使用PLSA作为主题模型的同时,提出了一种主题适应机制.该方法可以快速探测话题演化,减少噪声的干扰.此外,Wang等人[110]提出的TM-LDA(temporal-LDA)主题模型,结合了数据集的时间动态性,能够从历史数据中学习主题参数的变化,预测未来数据的主题分布,从而有效地分析潜在主题演化的过程.Saha等人[87]基于NMF引入时间正则化,能够极大地提高话题发现的效率,同时构建了动态NMF模型,可以快速预测大规模文本流的话题演化趋势.
4) “memes”追踪问题
“memes”是一种在互联网广泛传播的短文本.由于其传播广泛、消退时间快、数据集规模大、特征变化不明显等特性,现有的用于处理长时间演化的方法不适用于“memes”追踪.Leskovec等人[111]提出了一种可扩展的聚类算法,先通过聚类搜集传播广泛的语句以扩展至可观的数据规模,之后运用这些数据进行首次演化定量分析,并针对“memes”演化分析提供连贯性的表示.该方法首次解决了长久以来无法对“memes”进行话题演化追踪的挑战.Suen等人[112]提出了NIFTY(News Information Flow Tracking,Yay!)模型,使用一个新型的具有高可扩展性的增量式聚类算法来有效识别“memes”的突发变动情况,认为每个聚类簇是一个meme,并构建有向图模型,能够方便保存历史信息,有利于提高聚类质量和效率.
5) 现实任务问题
针对应用在现实中的数据挖掘任务提出相应的话题演化模型,是目前存在的另一个挑战.Hong等人[113]提出了一种有监督的模型,将时间主题模型和词汇流量指标结合,并对词汇流量进行优化,能够有效预测词汇在将来的流量,同时得到话题的流量,从而追踪词汇演化过程.Chu等人[114]提出了一种用于探测新闻话题演化的模型.该模型使用基本的LDA进行话题数目自适应的话题抽取,有利于提高话题提取的质量,通过计算相邻时间段内两个话题的分布距离实现话题关联,能够很好地描述新闻话题的演化过程.Hu等人[115]提出的新闻话题建模方法,同样可以自适应地获得每个时间段内的主题个数.和Chu等人的方法不同的是,该文使用OLDA模型检测主题,并采用Gibbs采样方法推断模型,进而通过计算子话题的语义相似度和时序关系来建立关联.
数据流的特征空间具有动态性,因此针对数据流的分类任务也变得更加困难.Nishida等人[116]发现,交替估计历史数据的词概率分布和最新数据的词概率分布,能够实现对突发词汇的快速响应,并准确分析数据流的各种变化,提高数据流分类的准确性.
6) 提高话题演化追踪的效率和准确性问题
社交媒体的快速发展,伴随着数据集的激增,话题演化追踪的效率和速度迫切需要得到提高.Yang等人[117]提出了话题个数自适应的LDA模型,并且首次提出了话题过滤以及垃圾模板话题的概念来对噪声进行过滤,进而提高话题的质量及其演化精度.对于层次话题的检测和演化分析,有基于二叉树组织层次话题的方法.但二叉树建模方法对话题关系的描述不够准确,由此,Wang等人[118]提出了一种演化多叉树聚类方法——EvoBRT,使用贝叶斯玫瑰树构建多叉树,利用在线贝叶斯过滤框架来描述文本内容的演化聚类问题.该方法比之前的基于二叉树聚类算法具有更优的效果.而Zhu等人[99]在提出的新模型CTH(coherent topic hierarchy)中,并没有直接使用贝叶斯玫瑰树,而是基于主题分布的特点,采用了分布相似度增强的贝叶斯玫瑰树,更能反映文本数据之间的真实关联关系.该模型基于BTM来抽取主题,并进行了稀疏化处理以增强主题的语义理解性.同时在时间序列建模方面,采用树间随机游走模型构建相邻时刻下树状结构之间的关联关系,避免了关系枚举及量化的复杂性.Chen等人[119]基于SVD(singular value decomposition)算法,提出了LWI-SVD模型,使用高效且准确的低秩近似对SVD加速,将多个维数的更新结果聚集成一个维度,以降低在线更新的空间消耗.
2 评估方式本章将对话题检测、主题模型及话题演化相关实验的评估方法作简要的总结.
对于话题检测,大部分实验使用准确率(precision)、召回率(recall)、F值(F-measure)来评价话题检测的正确性.准确率和召回率是广泛用于信息检索和统计学领域的两个关键指标.在话题检测中,准确率描述了检测结果中正确的话题数量与检测结果的总话题数量的比率,可衡量检测结果的查准率,即检测结果中有多少是正确的话题.召回率描述了检测结果中正确的话题数量与被测试集中应有的话题数量的比率,可衡量结果的查全率,即有多少正确的话题被检测出来了.正常情况下准确率和召回率都是越高越好,然而事实上这两者存在矛盾.例如,只检测出一个话题且是正确的话题,那么准确率达到了100%而召回率就很低.或者是检测出了大量的话题,其中包括了所有正确的话题和大量不正确的话题,那么召回率可以达到100%而准确率就会很低.因此在做实验研究时,准确率—召回率曲线就可以帮助分析实验结果.而常见的综合考虑准确率和召回率的方法就是F值.F值是准确率和召回率的调和平均.其他很多参数都是准确率和召回率的变体,譬如误报率(false alarm rate),漏查率(missed detection rate)等,也有很多实验采用对这些指标组合的方式构建最适合于自身实验评价的指标,但它们的本质还是准确率和召回率.与此同时,时间复杂度、运行时间以及人工评估方法也是广泛用于评价话题检测结果的指标.以上评估指标的计算公式详见表2,其中,A和B分别代表检测结果中正确的话题数量和错误的话题数量,C和D分别为没有被检测出来的正确的话题数量和错误的话题数量.
| 准确率 | precision=$\frac{A}{A+B}$ |
| 召回率 | recall=$\frac{A}{A+C}$ |
| F | F=2×$\frac{precision\times recall}{precision+recall}$ |
| 误报率 | FAR=$\frac{B}{A+B}$ |
| 漏查率 | MDR=$\frac{C}{A+C}$ |
对于主题模型,其评价涉及模型整体的评价和产生的主题的评价.模型整体的评价包括对主题模型泛化能力的评价以及第三方应用效果的评价;主题的评价则是对模型所产生的主题是否具有语义上的可读性和可理解性的评价.模型泛化能力的评价一般采用困惑度(perplexity)[120]或留存数据似然概率(held-out likelihood)[121].这两者虽然表达形式不同,但原理相通.假设有一包含M个文档的测试文档集,则其困惑度定义为:
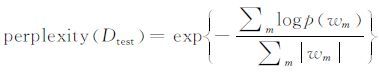
|
其中wm为每一个文档中的词汇总数,pw表示整个测试文档集下所有词汇的联合概率,其计算公式如下:
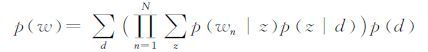
|
由公式可以看出,对于困惑度,通常是越低则模型的泛化能力越强.与之相反,对于留存数据的预测似然概率,则是越高越好.从留存数据似然概率这个指标又可以衍生出一系列与之相关的指标,譬如退火重要性采样(annealed importance sampling)[122]、调和平均方法(harmonic mean method)[123]、“从左往右”评价(left-to-right evaluation)[124]、Chib-style估计[125]等.相关的一些研究工作表明,在这些衍生指标中,“从左往右”评价和Chib-style估计相对来说更具有评价可靠性.第三方应用效果的评价指的是将主题模型运用到文本分类、信息检索等场合时的相关指标的评价.譬如通过文本分类效果来间接评价模型的优缺点,或通过信息检索来评价模型的优缺点.主题语义性评价可分为人工评价和自动评价两大类.人工评价是一种比较可靠的评价主题是否具有意义的方法,而且比较适用于来源复杂,没有标注的文本.自动评价是通过预先设定的评价指标让机器自动判别主题的语义性.自动评价往往需要借助相关的语料库,譬如Word-Net、Wikipedia、Google搜索引擎等,涉及的指标往往也纷繁庞杂.但是在众多的自动评价指标中,点对互信息是最为常用最为权威的一个[126],通常被用于衡量两个词之间的内在关联性.词对wi,wj的点对互信息定义如下:
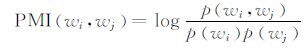
|
标准化的点对互信息(normalized point-wise mutual information,NPMI)[127]是点对互信息的条件概率标准化形式,也是评价主题语义性的主要指标之一.此外还有对数条件概率(log conditional probability,LCP)[128]、分布相似度(distributional similarity,DS)[129]等,都是PMI的变体.基于PMI及其变体的自动评价指标往往与人工评价的结果高度契合,能够较好地反映出主题的语义信息强弱,因此可作为主题语义评价的首选.
对于话题演化方面的评估,主要分为话题内容和话题强度的演化评估[130].在话题内容的演化评估上,可使用话题在每个时间点上的绝对长度(absolute strength)和正则化长度(normalized strength)来评测话题内容随时间的演化[100],或者将关键词在一个时间段内出现的次数作为演化评估标准.在话题强度的演化评估上,可使用话题的平均得分(average score)和累积得分(cumulative score)来评测话题和子话题的强度随时间的变化[131].也有使用话题在某一时间间隔中所占的比重作为衡量标准,来衡量话题强度的演化.抑或使用平均相关重构误差(average relative reconstruction error)、绝对运行时间(absolute execution time)和时间增益(time gain)作为演化的评估指标[119].
3 面临的挑战和未来工作方向语义理解困难和模型创新是文本挖掘领域研究存在的两大瓶颈问题,针对社交媒体研究对象,则又增加了内容短文本和数据海量性两个问题.因此,在社交媒体平台上开展话题检测与追踪工作难度更大.上面提到的解决方法已经克服了一些存在的困难,例如使用滑动窗口技术处理在线数据流,然而,话题检测与追踪研究还处于不断发展阶段,仍有许多问题和挑战亟待解决.
首先,随着社交媒体平台的用户规模和信息量的迅速增长,快速且准确地处理海量数据集以及实时变化的在线数据流这一目标仍旧没能很好地实现.尤其是随之大范围出现的多样化发展的噪声数据,为文本挖掘工作带来了极大的困扰.因此,需要更进一步地研究社交媒体中垃圾内容的发现与过滤技术.
其次,我们研究的社交媒体文本对象多数为用户生成的内容,其时间空间动态性非常复杂,且由短文本特征导致的稀疏性问题也一直存在.针对这方面的挑战,需要结合社交媒体中的实际数据,充分挖掘短文本特征更多的内在关联信息,用以进行特征选择,实现个性化的特征扩展,提高待处理短文本的质量和处理效率.
另外,现有的大部分研究都是针对单源数据源检测话题,比如Twitter,话题形成的来源过于单一.现阶段网络中各社交媒体相互紧密关联(比如可以将豆瓣中的帖子分享至微博),话题的传播方式和途径也覆盖了多种社交媒体平台.因此,可以考虑在话题检测过程中增加更多的话题来源网站,以便全面反映网络中存在的话题以及热点话题,进一步改进面向用户查询的话题反馈.
针对热门话题的检测,不仅要考虑文本信息对检测结果的影响,还需考虑非文本信息对热门话题检测的贡献.近几年的研究中时序特征和用户特征等非文本信息已经被广泛地用于构建话题检测模型,然而在用户特征方面,大多数研究只是利用了用户影响力和评论转发数量等简单的用户行为特征.事实上,包括用户属性信息、用户的参与行为以及用户角色分类信息在内的诸多其他用户特征,均可以被引入到热门话题检测和话题热度评估的过程中去,用以改善检测结果.
由于在广泛应用的主题模型方法中,向量空间模型和LDA 模型在考虑语义方面存在一定的局限性,检测出的话题一般用无序的词语或短语表示,语义理解性较差.由此,提供语义清晰、解释性好的高质量话题表示这一用户需求近来备受关注.可以考虑结合领域词汇集或者外部知识库对抽取出的主题词进行扩充,抑或是利用可视化技术,实现将检测到的话题直观地呈现给用户.
最后,在话题检测与追踪研究的实验部分,准确率、召回率和F值等作为最频繁使用的评估指标,虽然可以有效地反映系统的准确性,但是避免不了自身存在的局限性.针对不同的话题检测与追踪任务,相应地也涌现出了各式各样的评估方法和指标,但是还没有一个可以普遍适用的成熟且完整的评估系统.
| [1] | KAPLAN A M, HAENLEIN M. Users of the world, unite! The challenges and opportunities of Social Media[J]. Business Horizons, 2010, 53 (1) : 59 –68. |
| [2] | 刘玉新. Web 2.0 互联网在线话题发现和热度评估[D]. 广州: 华南理工大学, 2013. LIU Y X. Web 2.0 Internet Online Topic Discovery and Hotness Evaluation[D]. Guangzhou: South China University of Technology, 2013(Ch). |
| [3] | ALLAN J. Topic Detection and Tracking: Event-Based Information Organization. Norwell: Kluwer Academic Publishers.[M] 2002 . |
| [4] | 张晓艳, 王挺. 话题发现与追踪技术研究[J]. 计算机科学与探索, 2009 ,3 (4) : 347 –357. ZHANG X Y, WANG T. Research of technologies on topic detection and tracking[J]. Journal of Frontiers of Computer Science and Technology, 2009, 3 (4) : 347 –357. |
| [5] | 洪宇, 张宇, 刘挺, 等. 话题检测与跟踪的评测及研究综述[J]. 中文信息学报, 2007 ,6 (6) : 71 –87. HONG Y, ZHANG Y, LIU T, et al. Topic detection and tracking review[J]. Journal of Chinese Information Processing, 2007, 6 (6) : 71 –87. |
| [6] | 王卫姣. 话题追踪技术研究综述[J]. 软件导刊, 2013 ,20 (4) : 147 –149. WANG W J. Research status of topic tracking technology[J]. Software Guide, 2013, 20 (4) : 147 –149. |
| [7] | 孙国梓, 黄斯琪, 张禹森, 等. 基于数据挖掘的微博话题检测方法研究进展[J]. 金陵科技学院学报, 2014 ,30 (1) : 15 –20. SUN G Z, HUANG S Q, ZHANG Yusen, et al. Research on microblog’s topic detection based on data mining[J]. Journal of Jinling Institute of Technology, 2014, 30 (1) : 15 –20. |
| [8] | ATEFEH F, KHREICH W. A survey of techniques for event detection in Twitter[J]. Computational Intelligence, 2015, 31 (1) : 132 –164. |
| [9] | MCAULIFFE J D, BLEI D M. Supervised topic models[DB/OL] [2015-01-03]. http://dl.acm.org/citation.cfm?doid=1553374.1553535. DOI: 10.1145/1553374.1553535. |
| [10] | RAMAGE D, HALL D, NALLAPATI R, et al. Labeled LDA: A supervised topic model for credit attribution in multi-labeled corpora[DB/OL] [2015-01-03]. http://dl.acm.org/citation.cfm?doid=1699510.1699543. DOI: 10.3115/1699510.1699543. |
| [11] | RAMAGE D, MANNING C D, DUMAIS S. Partially labeled topic models for interpretable text mining[C]//Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2011: 457-465. DOI: 10.1145/2020408.2020481. |
| [12] | RABINOVICH M, BLEI D. The inverse regression topic model[DB/OL].[2015-06-03]. http://jmlr.org/proceedings/papers/v32/rabinovich14.html. |
| [13] | WALLACH H M. Topic modeling: Beyond bag-of-words[C]//Proceedings of the 23rd International Conference on Machine Learning. New York: ACM, 2006: 977-984. DOI: 10.1145/1143844.1143967. |
| [14] | WANG X, MCCALLUM A, WEI X. Topical n-grams: Phrase and topic discovery, with an application to information retrieval[C]// Seventh IEEE International Conference on Data Mining( ICDM 2007). Piscataway: IEEE, 2007: 697-702. DOI: 10.1109/ICDM.2007.86. |
| [15] | LINDSEY R V, HEADDEN III W P, STIPICEVIC M J. A phrase-discovering topic model using hierarchical pitman-yor processes[DB/OL].[2015-06-04]. http://dl.acm.org/citation.cfm?id=2390975. |
| [16] | YAN X, GUO J, LAN Y, et al. A biterm topic model for short texts[DB/OL].[2015-12-09]. http://dl.acm.org/citation.cfm?doid=2488388.2488514. DOI: 10.1145/2488388.2488514. |
| [17] | JAMEEL S, LAM W. An unsupervised topic segmentation model incorporating word order[C]//Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2013: 203-212. DOI: 10.1145/2484028.2484062. |
| [18] | DU L, PATE J K, JOHNSON M. Topic models with topic ordering regularities for topic segmentation[C]//Data Mining (ICDM), 2014 IEEE International Conference on. Piscataway: IEEE, 2014: 803-808. DOI: 10.1109/ICDM.2014.49. |
| [19] | WILLIAMSON S, WANG C, HELLER K, et al. Focused topic models[DB/OL].[2015-06-12]. http://www.cs.cmu.edu/~sinead/WilliamsonWangHellerBlei09.pdf. |
| [20] | WILLIAMSON S, WANG C, HELLER K A, et al. The IBP compound Dirichlet process and its application to focused topic modeling[DB/OL].[2015-06-18]. http://machinelearning.wustl.edu/mlpapers/paper_files/icml2010_WilliamsonWHB10.pdf. |
| [21] | ZHU J, XING E P. Sparse topical coding[DB/OL].[2015-06-16]. http://repository.cmu.edu/machine_learning/203/. |
| [22] | ZHANG A, ZHU J, ZHANG B. Sparse online topic models[C]//Proceedings of the 22nd International Conference on World Wide Web. New York: ACM, 2013: 1489-1500. DOI: 10.1145/2488388.2488518. |
| [23] | LIN T, TIAN W, MEI Q, et al. The dual-sparse topic model: Mining focused topics and focused terms in short text[C]//Proceedings of the 23rd International Conference on World Wide Web. New York: ACM, 2014: 539-550. DOI: 10.1145/2566486.2567980. |
| [24] | CHEN X, ZHOU M, CARIN L. The contextual focused topic model[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2012: 96-104. DOI: 10.1145/2339530.2339549. |
| [25] | XU Y, LIN T, LAM W, et al. Latent aspect mining via exploring sparsity and intrinsic information[C]//Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management. New York: ACM, 2014: 879-888. DOI: 10.1145/2661829.2662062. |
| [26] | ANDRZEJEWSKI D, ZHU X, CRAVEN M. Incorporating domain knowledge into topic modeling via Dirichlet forest priors[C]//Proceedings of the 26th Annual International Conference on Machine Learning. New York: ACM, 2009: 25-32. DOI: 10.1145/1553374.1553378. |
| [27] | NEWMAN D, BONILLA E V, BUNTINE W. Improving topic coherence with regularized topic models[DB/OL].[2015-06-15]. http://papers.nips.cc/paper/4291-improving-topic-coherence-with-regularized-topic-models. |
| [28] | KANG J H, MA J, LIU Y. Transfer Topic Modeling with Ease and Scalability[DB/OL]. [2015-11-25]. http://epubs.siam.org/doi/abs/10.1137/1.9781611972825.49. |
| [29] | RAJAGOPAL D, OLSHER D, CAMBRIA E, et al. Commonsense-based topic modeling[C]//Proceedings of the Second International Workshop on Issues of Sentiment Discovery and Opinion Mining. New York: ACM, 2013: Article No.6.DOI:10.1145/2502069.2502075. |
| [30] | LIM K W, BUNTINE W. Twitter opinion topic model: extracting product opinions from tweets by leveraging hashtags and sentiment lexicon[C]//Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management. New York: ACM, 2014: 1319-1328. DOI: 10.1145/2661829.2662005. |
| [31] | CHEN Z, MUKHERJEE A, LIU B, et al. Leveraging multi-domain prior knowledge in topic models[C]//Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence. Menlo Park: AAAI Press, 2013: 2071-2077. |
| [32] | CHEN Z, MUKHERJEE A, LIU B, et al. Discovering coherent topics using general knowledge[C]//Proceedings of the 22nd ACM International Conference on Conference on Information & knowledge management. New York: ACM, 2013: 209-218. DOI: 10.1145/2505515.2505519. |
| [33] | CHEN Z, MUKHERJEE A, LIU B, et al. Exploiting Domain Knowledge in Aspect Extraction[DB/OL]. [2015-11-25]. https://www.researchgate.net/profile/Zhiyuan_Chen6/publication/268037012_Exploiting_Domain_Knowledge_in_Aspect_Extraction/links/54602ee00cf295b56161d020.pdf. |
| [34] | CHEN Z, MUKHERJEE A, LIU B. Aspect extraction with automated prior knowledge learning[DB/OL]. [2015-10-05]. http://aclweb.org/anthology/P14-1033. DOI: 10.3115/v1/p14-1033. |
| [35] | CHEN Z, LIU B. Topic modeling using topics from many domains, lifelong learning and big data[DB/OL]. [2015-10-25]. http://machinelearning.wustl.edu/mlpapers/papers/icml2014c2_chenf14. |
| [36] | CHEN Z, LIU B. Mining topics in documents: standing on the shoulders of big data[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014: 1116-1125. DOI: 10.1145/2623330.2623622. |
| [37] | SPINA D, GONZALO J, AMIGE. Learning similarity functions for topic detection in online reputation monitoring[C]//Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval. New York: ACM, 2014: 527-536. DOI: 10.1145/2600428.2609621. |
| [38] | YANG C, YANG J, DING H, et al. A hot topic detection approach on Chinese microblogging[DB/OL]. [2015-12-12]. http://link.springer.com/chapter/10.1007%2F978-1-4471-4853-1_52. DOI: 10.1007/978-1-4471-4853-1_52. |
| [39] | RAFEA A, MOSTAFA N. Topic extraction in social media[C]//Collaboration Technologies and Systems (CTS), 2013 International Conference on. Piscataway: IEEE, 2013: 94-98. DOI: 10.1109/cts.2013.6567212. |
| [40] | PETKOS G, PAPADOPOULOS S, AIELLO L, et al. A soft frequent pattern mining approach for textual topic detection[C]//Proceedings of the 4th International Conference on Web Intelligence, Mining and Semantics (WIMS14). New York: ACM, 2014: 25. DOI: 10.1145/2611040.2611068. |
| [41] | YAN X, GUO J, LIU S, et al. Learning topics in short texts by non-negative matrix factorization on term correlation matrix[DB/OL]. [2015-12-22]. http://epubs.siam.org/doi/abs/10.1137/1.9781611972832.83. DOI: 10.1137/1.9781611972832.83. |
| [42] | 程葳, 龙志祎. 面向互联网新闻的在线话题检测算法[J]. 计算机工程, 2009 ,35 (18) : 28 –30. CHENG W, LONG Z Y. Online topic detection algorithm for internet news[J]. Computer Engineering, 2009, 35 (18) : 28 –30. |
| [43] | AGGARWALC C, SUBBIAN K. Event detection in social streams[DB/OL]. [2015-11-10]. http://epubs.siam.org/doi/abs/10.1137/1.9781611972825.54. DOI: 10.1137/1.9781611972825.54. |
| [44] | 张小明, 李舟军, 巢文涵. 基于增量型聚类的自动话题检测研究[J]. 软件学报, 2012 ,23 (6) : 1578 –1587. ZHANGX M, LI Z J, CHAO W H. Research of automatic topic detection based on incremental clustering[J]. Journal of Software, 2012, 23 (6) : 1578 –1587. |
| [45] | LI C, SUN A, DATTA A. Twevent: segment-based event detection from tweets[C]//Proceedings of the 21st ACM International Conference on Information and Knowledge Management. New York: ACM, 2012: 155-164. DOI: 10.1145/2396761.2396785. |
| [46] | YIN J. Clustering microtext streams for event identification[DB/OL].[2015-09-02]. http://www.aclweb.org/anthology/I13-1085. |
| [47] | LEE C H, CHIEN T F. Leveraging microblogging big data with a modified density-based clustering approach for event awareness and topic ranking[J]. Journal of Information Science, 2013, 39 (4) : 523 –543. |
| [48] | ESTER M, KRIEGEL H P, SANDER J, et al. Incremental clustering for mining in a data warehousing environment[C]//Proceedings of the 24th International Conference on Very Large Data Bases(VLDB’98). San Francisco: Morgan Kaufmann Publishers Inc, 1998: 323-333. |
| [49] | PERVIN N, FANG F, DATTA A, et al. Fast, scalable, and context-sensitive detection of trending topics in microblog post streams[J]. ACM Transactions on Management Information Systems (TMIS), 2013, 3 (4) . |
| [50] | KUMAR S, LIU H, MEHTA S, et al. From Tweets to Events: Exploring a Scalable Solution for Twitter Streams[DB/OL]. [2015-09-02]. http://arxiv.org/abs/1405.1392. |
| [51] | FANG Y, ZHANG H, YE Y, et al. Detecting hot topics from Twitter: A multiview approach[J]. Journal of Information Science, 2014, 40 (5) : 578 –593. |
| [52] | FENG W, HAN J, WANG J, et al. STREAMCUBE: Hierarchical spatio-temporal hashtag clustering for event exploration over the Twitter stream[DB/OL]. [2015-12-02]. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7113425. DOI: 10.1109/icde.2015.7113425. |
| [53] | ZHOU X, CHEN L. Event detection over twitter social media streams[J]. The VLDB Journal—The International Journal on Very Large Data Bases, 2014, 23 (3) : 381 –400. |
| [54] | CHEN F, NEILL D B. Non-parametric scan statistics for event detection and forecasting in heterogeneous social media graphs[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014: 1166-1175. DOI: 10.1145/2623330.2623619. |
| [55] | ZHANG C, WANG H, CAO L, et al. A hybrid term-term relations analysis approach for topic detection[J]. Knowledge-Based Systems, 2016, 93 : 109 –120. |
| [56] | HOFFMAN M, BACH F R, BLEI D M. Online learning for latent Dirichlet allocation[DB/OL]. [2015-09-03]. http://papers.nips.cc/paper/3902-online-learning-for-latentdirichlet-allocation!. |
| [57] | LAU J H, COLLIER N, BALDWIN T. On-line trend analysis with topic models:#Twitter trends detection topic model online[DB/OL]. [2015-09-02]. http://www.aclweb.org/anthology/C12-1093?Q6uDV-ZCFE6L3mQWCsrCoDA&ved=0CDIQFjAE&usg=AFQjCNGSq0fKLBTgVJhZhwak0fFPiJHT2w. |
| [58] | GUO X, XIANG Y, CHEN Q, et al. LDA-based online topic detection using tensor factorization[J]. Journal of Information Science, 2013, 39 (4) : 459 –469. |
| [59] | PENG M, ZHU J, LI X, et al. Central topic model for event-oriented topics mining in microblog stream[C]//Proceedings of the 24th ACM International on Conference on Information and Knowledge Management. New York: ACM, 2015: 1611-1620. DOI: 10.1145/2806416.2806561. |
| [60] | JIANG D, LEUNG K W T, NG W. Fast topic discovery from web search streams[C]//Proceedings of the 23rd International Conference on World Wide Web. New York: ACM, 2014: 949-960. DOI: 10.1145/2566486.2567965. |
| [61] | WENG J, LEE B S. Event detection in Twitter[J]. ICWSM, 2011, 11 : 401 –408. |
| [62] | CORDEIRO M. Twitter event detection: Combining wavelet analysis and topic inference summarization[DB/OL]. [2015-09-02]. http://paginas.fe.up.pt/~prodei/dsie12/papers/paper_14.pdf. |
| [63] | YIN H, CUI B, LU H, et al. A unified model for stable and temporal topic detection from social media data[C]//Data Engineering (ICDE), 2013 IEEE 29th International Conference on. Piscataway: IEEE, 2013: 661-672. DOI: 10.1109/icde.2013.6544864. |
| [64] | GUO J, ZHANG P, GUO L. Mining hot topics from Twitter streams[J]. Procedia Computer Science, 2012, 9 : 2008 –2011. |
| [65] | HUANG J, PENG M, WANG H. Topic detection from large scale of microblog stream with high utility pattern clustering[C]//Proceedings of the 8th Workshop on Ph. D. Workshop in Information and Knowledge Management. New York: ACM, 2015: 3-10. DOI: 10.1145/2809890.2809894. |
| [66] | HU Z Y, WANG H A, ZHU J Q, et al. Discovery of rare sequential topic patterns in document stream[DB/OL].[2015-09-07]. http://epubs.siam.org/doi/pdf/10.1137/1.9781611973440.61. DOI: 10.1137/1.9781611973440.61. |
| [67] | 黄云, 张彬连, 颜一鸣. 基于可区分语言模型的微博在线话题检测[J]. 计算机应用研究, 2014 ,31 (12) : 3539 –3542. HUANG Y, ZHANG B L, YAN Y M. Online topic detection in microblogs based on discriminative language model[J]. Application Research of Computers, 2014, 31 (12) : 3539 –3542. |
| [68] | 贺敏, 杜攀, 张瑾, 等. 基于动量模型的微博突发话题检测方法[J]. 计算机研究与发展, 2015 ,52 (5) : 1022 –1028. HE M, DU P, ZHANG J, et al. Microblog bursty topic detection method based on momentum model[J]. Journal of Computer Research and Development, 2015, 52 (5) : 1022 –1028. |
| [69] | PETROVIĆ S, OSBORNE M, LAVRENKO V. Streaming first story detection with application to twitter[DB/OL]. [2015-09-06]. http://dl.acm.org/citation.cfm?id=185802. |
| [70] | PETROVIĆ S, OSBORNE M, LAVRENKO V. Using paraphrases for improving first story detection in news and Twitter[DB/OL]. [2015-09-05]. http://dl.acm.org/citation.cfm?id=2382072. |
| [71] | WURZER D, LAVRENKO V, OSBORNE M. Twitter-scale new event detection via k-term hashing[DB/OL]. [2016-01-12]. http://aclweb.org/anthology/D15-1310. DOI: 10.18653/v1/d15-1310. |
| [72] | KASIVISWANATHAN S P, MELVILLE P, BANERJEE A, et al. Emerging topic detection using dictionary learning[C]//Proceedings of the 20th ACM International Conference on Information and Knowledge Management. New York: ACM, 2011: 745-754. DOI: 10.1145/2063576.2063686. |
| [73] | BOYD S, PARIKH N, CHU E, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers[J]. Foundations & Trends in Machine Learning, 2011, 3 (1) : 1 –122. |
| [74] | KASIVISWANATHAN S P, WANG H, BANERJEE A, et al. Online L1-dictionary learning with application to novel document detection[DB/OL]. [2015-09-09]. http://papers.nips.cc/paper/4571-online-L1-dictionary- learning-with-application-to-novel-document-detection. |
| [75] | KASIVISWANATHAN S P, CONG G, MELVILLE P, et al. Novel document detection for massive data streams using distributed dictionary learning[J]. IBM Journal of Research and Development, 2013, 57 (3-4) . |
| [76] | CATALDI M, CARO L D, SCHIFANELLA C. Emerging topic detection on twitter based on temporal and social terms evaluation[C]//Proceedings of the Tenth International Workshop on Multimedia Data Mining. New York: ACM, 2010: 4. DOI: 10.1145/1814245.1814249. |
| [77] | CATALDI M, CARO L D, SCHIFANELLA C. Personalized emerging topic detection based on a term aging model[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2013, 5 (1) . |
| [78] | CHU V W, WONG R K K, CHEN F, et al. Microblog topic contagiousness measurement and emerging outbreak monitoring[C]//Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management. New York: ACM, 2014: 1099-1108. DOI: 10.1145/2661829.2662014. |
| [79] | WU Q Q, ZHENG Y, YINGYING S, et al. Emerging topic detection model based on LDA and its application in stem cell field[DB/OL]. [2015-11-26]. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7023867. DOI: 10.1109/cse.2014.355. |
| [80] | 邱云飞, 郭弥纶, 邵良杉. 基于主题树的微博突发话题检测[J]. 计算机应用, 2014 ,34 (8) : 2332 –2335. QIU Y Fi, GUO M L, SHAO L S. Microblog bursty topic detection based on topic tree[J]. Journal of Computer Applications, 2014, 34 (8) : 2332 –2335. |
| [81] | YAN X, GUO J, LAN Y, et al. A probabilistic model for bursty topic discovery in microblogs[DB/OL]. [2015-07-26]. http://www.shortext.org/paper/BBTM-AAAI15.pdf. |
| [82] | ZHANG Z, XU M, ZHENG N. Mining burst topical keywords from microblog stream[DB/OL]. [2015-12-06]. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=6526261. DOI: 10.1109/iccsnt.2012.6526261 |
| [83] | YU K, DING W, SIMOVICI D A, et al. Mining emerging patterns by streaming feature selection[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2012: 60-68. DOI: 10.1145/2339530.2339544. |
| [84] | 俞奎. 流特征下的在线知识发现研究[D]. 合肥: 合肥工业大学, 2013. U K. Online Knowledge Discovery with Streaming Features[D]. Hefei: Hefei University of Technology, 2013(Ch). |
| [85] | 郭跇秀, 吕学强, 李卓. 基于突发词聚类的微博突发事件检测方法[J]. 计算机应用, 2014 ,34 (2) : 486 –490. GUO Y X, LV X Q, LI Z. Bursty topics detection approach on Chinese microblog based on burst words clustering[J]. Journal of Computer Applications, 2014, 34 (2) : 486 –490. |
| [86] | 申国伟, 杨武, 王巍, 等. 面向大规模微博消息流的突发话题检测[J]. 计算机研究与发展, 2015 ,52 (2) : 512 –521. SHEN G W, YANG W, WANG W, et al. Burst topic detection oriented large-scale microblogs streams[J]. Journal of Computer Research and Development, 2015, 52 (2) : 512 –521. |
| [87] | SAHA A, SINDHWANI V. Learning evolving and emerging topics in social media: A dynamic NMF approach with temporal regularization[C]//Proceedings of the fifth ACM International Conference on Web Search and Data Mining. New York: ACM, 2012: 693-702. DOI: 10.1145/2124295.2124376. |
| [88] | XIE W, ZHU F, JIANG J, et al. Topic Sketch: Real-time bursty topic detection from Twitter[C]//Data Mining (ICDM), 2013 IEEE 13th International Conference on. Piscataway: IEEE, 2013: 837-846. DOI: 10.1109/ICDM.2013.86.. |
| [89] | SCHUBERT E, WEILER M, KRIEGEL H P. SigniTrend: scalable detection of emerging topics in textual streams by hashed significance thresholds[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014: 871-880. DOI: 10.1145/2623330.2623740. |
| [90] | CHEN Y, AMIRI H, LI Z, et al. Emerging topic detection for organizations from microblogs[C]//Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2013: 43-52. DOI: 10.1145/2484028.2484057. |
| [91] | UNANKARD S, LI X, SHARAF M A. Emerging event detection in social networks with location sensitivity[J]. World Wide Web, 2015, 18 (5) : 1393 –1417. |
| [92] | ZHAO L, LI Y, LIU X, et al. A graph-based bursty topic detection approach in user-generated texts[C]//Web Information System and Application Conference (WISA), 2014 11th. Piscataway: IEEE, 2014: 273-278. DOI: 10.1109/WISA.2014.57. |
| [93] | SAKAKI T, OKAZAKI M, MATSUO Y. Earthquake shakes Twitter users: Real-time event detection by social sensors[C]//Proceedings of the 19th International Conference on World Wide Web. New York: ACM, 2010: 851-860. DOI: 10.1145/1772690.1772777. |
| [94] | HONG Y, FEI Y, YANG J. Exploiting topic tracking in real-time tweet streams[C]//Proceedings of the 2013 International Workshop on Mining Unstructured Big Data Using Natural Language Processing. New York: ACM, 2013: 31-38. DOI: 10.1145/2513549.2513555. |
| [95] | WANG X, ZHU F, JIANG J, et al. Real Time Event Detection in Twitter[M/OL]. [2015-10-15]. http://link.springer.com/chapter/10.1007/978-3-642-385-62-9_51. |
| [96] | FENG X, ZHANG S, LIANG W, et al. Real-Time Event Detection Based on Geo Extraction and Temporal Analysis[M/OL]. [2015-11-23]. http://link.springer.com/chapter/10.1007/978-3-319-14717-8_11. |
| [97] | MELADIANOS P, NIKOLENTZOS G, ROUSSEAU F, et al. Degeneracy-based real-time sub-event detection in twitter stream[DB/OL]. [2015-11-23]. http://www.aaai.org/ocs/index.php/ICWSM/ICWSM15/paper/view/10502. |
| [98] | HAYASHI K, MAEHARA T, TOYODA M, et al. Real-time top-R topic detection on twitter with topic hijack filtering[C]//Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2015: 417-426. DOI: 10.1145/2783258.2783402. |
| [99] | ZHU J, LI X, PENG M, et al. Coherent Topic Hierarchy: A Strategy for Topic Evolutionary Analysis on Microblog Feeds[M/OL]. [2016-01-19]. http://link.springer.com/chapter/10.1007/978-3-319-21042-1_6. |
| [100] | MEI Q, ZHAI C X. Discovering evolutionary theme patterns from text: An exploration of temporal text mining[C]//Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining. New York: ACM, 2005: 198-207. DOI: 10.1145/1081870.1081895. |
| [101] | BLEI D M, LAFFERTY J D. Dynamic topic models[C]//Proceedings of the 23rd International Conference on Machine Learning. New York: ACM, 2006: 113-120. DOI: 10.1145/1143844.1143859. |
| [102] | WANG X, MCCALLUM A. Topics over time: A non-Markov continuous-time model of topical trends[C]//Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2006: 424-433. DOI: 10.1145/1150402.1150450. |
| [103] | LIN C, LIN C, LI J, et al. Generating event storylines from microblogs[C]//Proceedings of the 21st ACM International Conference on Information and Knowledge Management. New York: ACM, 2012: 175-184. DOI: 10.1145/2396761.2396787. |
| [104] | QI J, QU Q, TAN Y. Topic evolution prediction of user generated contents considering enterprise generated contents[C]//Proceedings of the First ACM International Workshop on Hot Topics on Interdisciplinary Social Networks Research. New York: ACM, 2012: 73-76. DOI: 10.1145/2392622.2392635. |
| [105] | YANG J, LESKOVEC J. Patterns of temporal variation in online media[C]//Proceedings of the fourth ACM International Conference on Web Search and Data Mining. New York: ACM, 2011: 177-186. DOI: 10.1145/1935826.1935863. |
| [106] | DUBEY A, HEFNY A, WILLIAMSON S, et al. A nonparametric mixture model for topic modeling over time[DB/OL]. [2015-11-17]. http://epubs.siam.org/doi/abs/10.1137/1.9781611972832.59. DOI: 10.1137/1.9781611972832.59. |
| [107] | MASADA T, FUKAGAWA D, TAKASU A, et al. Dynamic hyperparameter optimization for Bayesian topical trend analysis[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management. New York: ACM, 2009: 1831-1834. DOI: 10.1145/1645953.1646242. |
| [108] | ALSUMAIT L, BARBAR D, DOMENICONI C. On-line LDA: Adaptive topic models for mining text streams with applications to topic detection and tracking[DB/OL]. [2015-12-21]. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=4781095. DOI: 10.1109/ICDM.2008.140. |
| [109] | GOHR A, HINNEBURG A, SCHULT R, et al. Topic evolution in a stream of documents[C]//Proceedings of the 2009 SIAM International Conference on Data Mining, 2009, 9: 859-872. DOI: 10.1137/1.9781611972795.74. |
| [110] | WANG Y, AGICHTEIN E, BENZI M. TM-LDA: Efficient online modeling of latent topic transitions in social media[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2012: 123-131. DOI: 10.1145/2339530.2339552. |
| [111] | LESKOVEC J, BACKSTROM L, KLEINBERG J. Meme-tracking and the dynamics of the news cycle[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2009: 497-506. DOI: 10.1145/1557019.1557077. |
| [112] | SUEN C, HUANG S, EKSOMBATCHAI C, et al. NIFTY: A system for large scale information flow tracking and clustering[DB/OL]. [2015-12-18]. http://dl.acm.org/citation.cfm?doid=2488388.2488496. DOI: 10.1145/2488388.2488496. |
| [113] | HONG L, YIN D, GUO J, et al. Tracking trends: Incorporating term volume into temporal topic models[C]//Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2011: 484-492. DOI: 10.1145/2020408.2020485. |
| [114] | 楚克明, 李芳. 基于 LDA 模型的新闻话题的演化[J]. 计算机应用与软件, 2011 ,28 (4) : 4 –7. CHU K M, LI F. LDA model-based news topic evolution[J]. Computer Applications and Software, 2011, 28 (4) : 4 –7. |
| [115] | 胡艳丽, 白亮, 张维明. 一种话题演化建模与分析方法[J]. 自动化学报, 2012 ,38 (10) : 1690 –1697. HU Y L, BAI L, ZHANG W M. Modeling and analyzing topic evolution[J]. Acta Automatica Sinica, 2012, 38 (10) : 1690 –1697. |
| [116] | NISHIDA K, HOSHIDE T, FUJIMURA K. Improving tweet stream classification by detecting changes in word probability[C]//Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2012: 971-980. DOI: 10.1145/2348283.2348412. |
| [117] | 杨星. 基于 LDA 的话题获取与演化研究[D]. 郑州: 河南工业大学, 2013. YANG X. The Research on Topic Access and Evolution with LDA[D]. Zhengzhou: Henan University of Technology, 2013(Ch). |
| [118] | WANG X, LIU S, SONG Y, et al. Mining evolutionary multi-branch trees from text streams[C]//Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2013: 722-730. DOI: 10.1145/2487575.2487603. |
| [119] | CHEN X, CANDAN K S. LWI-SVD: Low-rank, windowed, incremental singular value decompositions on time-evolving data sets[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014: 987-996. DOI: 10.1145/2623330.2623 671. |
| [120] | BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation[J]. The Journal of machine Learning research, 2003, 3 : 993 –1022. |
| [121] | BLEI D M, LAFFERTY J D. Correlated topic models[C]//Advances in Neural Information Processing Systems 18. Cambridge: MIT Press, 2006: 147-154. |
| [122] | LI W, MCCALLUM A. Pachinko allocation: DAG-structured mixture models of topic correlations[C]//Proceedings of the 23rd International Conference on Machine Learning. New York: ACM, 2006: 577-584. DOI: 10.1145/1143844.1143917. |
| [123] | NEWTONM A, RAFTERY A E. Approximate Bayesian inference with the weighted likelihood bootstrap[J]. Journal of the Royal Statistical Society. Series B (Methodological), 1994, 56 : 13 –48. |
| [124] | WALLACHH M. Structured Topic Models for Language[D]. Cambridge: University of Cambridge, 2008. |
| [125] | MURRAYI, SALAKHUTDINOV R R. Evaluating probabilities under high-dimensional latent variable models[DB/OL].[2015-06-01]. http://papers.nips.cc/paper/3584-evaluating-probabilities-under-high-dimensional-latent-variable-models. |
| [126] | NEWMAN D, LAU J H, GRIESER K, et al. Automatic evaluation of topic coherence[DB/OL].[2015-12-14]. http://dl.acm.org/citation.cfm?id=1858011. |
| [127] | BOUMA G. Normalized (pointwise) mutual information in collocation extraction[J]. Proceedings of GSCL, 2009 : 31 –40. |
| [128] | MIMNO D, WALLACH H M, TALLEY E, et al. Optimizing semantic coherence in topic models[DB/OL].[2015-12-15]. http://dl.acm.org/citation.cfm?id=2145462. |
| [129] | ALETRAS N, STEVENSON M. Evaluating topic coherence using distributional semantics[DB/OL].[2015-06-03]. https://www.researchgate.net/profile/Nikolaos_Aletras/publication/235974307_Evaluating_Topic_Coherence_Using_Distributional_Semantics/links/00b7d5151a903889ecwhdxxblxb-62-03-1970.pdf. |
| [130] | 单斌, 李芳. 基于LDA话题演化研究方法综述[J]. 中文信息学报, 2010 ,24 (6) : 43 –49. SHAN B, LI F. A survey of topic evolution based on LDA[J]. Journal of Chinese Information Processing, 2010, 24 (6) : 43 –49. |
| [131] | SHUBHANKAR K, SINGH A P, PUDI V. An efficient algorithm for topic ranking and modeling topic evolution[DB/OL]. [2015-12-17]. http://link.springer.com/chapter/10.1007%2F978-3-642-23088-2_23. DOI: 10.1007/978-3-642-23088-2_23. |