 2017, Vol. 63
2017, Vol. 63
文章信息
- 谢逸, 饶文碧, 段鹏飞, 陈振东
- XIE Yi, RAO Wenbi, DUAN Pengfei, CHEN Zhendong
- 基于CNN和LSTM混合模型的中文词性标注
- A Chinese POS Tagging Approach Using CNN and LSTM-Based Hybrid Model
- 武汉大学学报(理学版), 2017, 63(3): 246-250
- Journal of Wuhan University(Natural Science Edition), 2017, 63(3): 246-250
- http://dx.doi.org/10.14188/j.1671-8836.2017.03.009
-
文章历史
- 收稿日期:2016-08-10



引用本文

|



词性标注(part-of-speech tagging, 简称POS tagging)是自然语言处理里的重要问题,它被广泛地用于机器翻译、文字识别、语音识别、信息检索等相关领域[1].词性标注通过上下文赋予每个词语一个正确的候选词性,从而为自然语言中的词法分析、语法分析和语义分析提供支撑.
词性标注的方法归纳起来,可以分为4类:
1) 基于规则的方法.2008年,王广正等[2]提出了基于规则优先级的词性标注方法.基于规则的方法简单,易于实现,但手工构造规则是一项非常艰难的任务.
2) 基于统计的方法.该方法客观性强,准确性较高,但需要处理兼类词和未登录词的问题.常见的方法有:隐马尔科夫模型(hidden Markov model,简称HMM)、最大熵(maximum entropy,简称ME)、条件随机场(conditional random fields,简称CRF)等.Kupiec等[3]使用隐马尔科夫模型,在50万词的英文语料库上,词性标注准确率达到了95%.
3) 基于规则和统计的方法,充分利用两种方法的各自优势,比单一使用一种的准确性要高[4],但该类方法依赖于建立的规则或人工特征的选取,同时也与任务领域的资源有很大的相关性,一旦领域变化,标注效果就会受较大影响.
4) 基于深度学习的方法.通过对数据多层建模获得数据的特征和分布式表示,避免繁琐的人工特征抽取,具有良好的泛化能力[5].深度学习常见的模型主要有多层感知器(multi-layer perceptron,简称MLP)、自动编码器(AutoEncoder,简称AE)、卷积神经网络(convolutional neural network,简称CNN)和长短期记忆模型(long-short term memory,简称LSTM)等.这些模型中CNN[6]和LSTM[7]应用较为广泛.CNN是目前效果最好的深度学习模型之一,利用滑动窗口,可以很好的解决词的组合特征及一定程度上的依赖问题,表达句子之间的关系较为自然,由于参数共享,因此它的计算量较小,计算速度较快.2011年Collobert等[8]在Word Embedding基础上,设计了一种利用卷积计算和滑动窗口的前向神经网络,并把它应用于英文词性标注和实体识别等任务上.对于词性标注这种标注任务来说,可以把输入的文本看作是线性序列,文本中字或词为序列的一个元素,每个元素的标注很大程度依赖于前面元素的信息.LSTM隶属于循环反馈神经网络,它可以将文本中某一序列元素与某时刻模型的输入对应起来,利用隐层单元的记忆模块,保存长间隔信息,对序列元素逐一标注.2015年,Sundermeyer等[9]利用LSTM进行语言建模,Wang等[10]使用LSTM进行英文词性标注,取得较好的效果.
本文提出了一种基于CNN和LSTM的混合模型来进行中文词性标注的方法,混合模型利用CNN滑动窗口和权值共享[11]来获得局部上下文信息,从而生成词语表示特征并作为下一层的输入,LSTM的时序性非常适合标注这种序列任务[12],将两者结合起来,充分利用两者的各自优势,中文词性标注的性能得到了显著的提升.
1 本文方法 1.1 模型结构以“世界杯跳水赛中国选手再夺两枚金牌”为例,本文设计的基于CNN和LSTM的混合神经网络模型结构如图 1所示.模型分为3个层次:第一层通过使用Word2Vec将文本中的词语转换成为词向量;第二层为CNN层,将第一层所产生的词向量输入到CNN层,利用滑动窗口,计算前后词对当前词的影响,生成词语表示特征;第三层为LSTM层,将CNN层生成的各词的词语表示特征依次输入LSTM各节点,预测最后的词性标注标签.

|
| 图 1 面向词性标注的CNN和LSTM混合模型 Figure 1 Hybrid model using CNN and LSTM |
自然语言理解的问题要转化为机器能够处理的问题,第一步就必须将这些符号数字化,即将文本的表达映射到k维的向量空间里去.本文用2013年Google开发的Word2Vec将已分词的语料库中的中文词语转换为词向量.经过Word2Vec训练的词向量如下
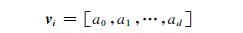
|
(1) |
(1) 式中,d为词向量的维度,模型初始化时设置.
1.1.2 卷积神经网络处理层(CNN层)使用卷积神经网络来提取词语的上下文信息,生成词语的表示特征,其结构如图 2所示.

|
| 图 2 卷积神经网络处理层结构图 Figure 2 Architecture for CNN processing layer |
令vi为第i个词的词向量,vi的维度为d维,当句子词语数为L,卷积神经网络的滑动窗口大小为k时,落入第j个(j≤L-1) 滑动窗口中的词向量依次为vj, vj+1, …, vj+k-1,可以将它们表达为窗口向量,如下
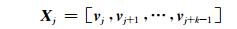
|
(2) |
与当前词vj有关的窗口向量依次为:Xj-k+1, Xj-k+2, …, Xj.对于每个窗口向量Xj,用卷积核W进行卷积运算得到当前窗口特征,
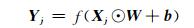
|
(3) |
(3) 式中⊙是卷积乘,b是偏置,f是非线性激活函数,可以是sigmoid函数、tanh函数或者ReLU函数,鉴于ReLU收敛速度快的特性,本文采用ReLU激活函数,ReLU激活函数形式如下
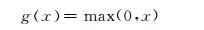
|
(4) |
最大池化(max pooling)会有效的减少特征和参数,降低计算的复杂度,因此,在完成卷积运算后采用最大池化的方法来最大化词语特征表示.窗口向量Yj-k+1,Yj-k+2, …,Yj组成窗口向量特征矩阵,对矩阵的每一行做Max操作,获得每一维的最大特征值,从而最大化词语的表示特征.
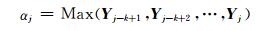
|
(5) |
LSTM是一种特殊的RNN(recurrent neural network).一个LSTM单元是由一个cell和三个门(输入input、输出output和遗忘forget)组成,正是通过这种特殊的结构,LSTM才能选择哪些信息被遗忘,哪些信息被记住.某时刻t,LSTM单元各组成部分做如下更新:
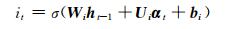
|
(6) |
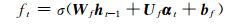
|
(7) |
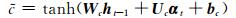
|
(8) |
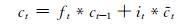
|
(9) |
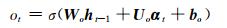
|
(10) |
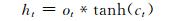
|
(11) |
其中,σ表示sigmoid激活函数,*是元素乘,αt为t时刻的输入向量,ht代表隐藏状态,Ui,Uf,Uc,Uo分别为xt不同门的权值矩阵,而Wi,Wf,Wc,Wo则为ht不同门的权值矩阵,bi,bf,bc,bo为各门的偏置.it, ft, ct和ot分别代表了输入门、遗忘门、记忆单元状态和输出门.
LSTM层的输入为CNN层的输出词向量αj (j≤L),CNN层的一个αj输出对应于一个时刻t的LSTM输入.LSTM层的输出送入Softmax分类器进行分类,计算每个词对应的标注标签最大的概率,从而获得词语的词性标注标签,Softmax公式如下:
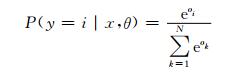
|
(12) |
其中,P(y=i|x, θ)为样本x属于i类的概率.
1.2 标注算法利用以上的中文词性标注混合模型,我们设计了模型训练的算法(算法1),描述如下:
| 算法1模型训练算法 |
| 输入:训练集D |
| 初始化参数:词数L,词向量维度d,滑动窗口大小k,隐层节点数n,迭代次数epochNum |
| 训练过程: |
| Word2Vec训练获得词向量vi; |
| While误差>阈值or迭代次数<epochNum |
| for t=1…L |
| · 使用滑动窗口,获得窗口向量Xj(公式(2)),卷积并最大池化,产生词语表示特征αj |
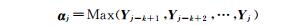 |
| · 一个αj对应于一个时刻t,输入LSTM,产生概率向量 |
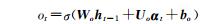 |
| · LSTM输出送入Softmax分类器,产生每个词语的分类标签 |
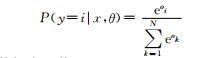 |
| · 计算对数损失函数L: |
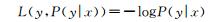 |
| 输出:权值确定的多层模型 |
本文采用PFR《人民日报》1998年1月份的语料库(http://www.icl.pku.edu.cn/icl_res/)、CoNLL09(h http://ufal.mff.cuni.cz/conll2009-st/index.html)和CTB7.0(https://catalog.ldc.upenn.edu/LDC2010T07)作为实验数据.PFR《人民日报》语料库是由北京大学计算语言学研究所与富士通研究开发中心有限公司共同制作.各语料库规模如表 1所示.
| 语料库 | 句子数 | 总词数 |
| PFR | 31 668 | 776 817 |
| CTB7.0 | 2 796 | 59 955 |
| CoNLL09 | 2 577 | 73 154 |
实验中,语料库将分割为3部分:训练集、开发集和测试集.PFR语料库的训练集、开发集和测试集的比例为7:1:2.在进行词性标注时,根据现代汉语语料库加工规范,PFR语料库有39种不同的标注[13].CoNLL09和CTB7.0按照各自官方文档提供的划分方法进行训练集、开发集和测试集的划分.
2.2 实验参数设置要获得一个较优的深度模型,模型里参数的设置是否恰当是关键因素.CNN层主要涉及的参数有:词向量维度、滑动窗口大小、卷积核数和激活函数;LSTM层主要涉及的参数有:节点数、Dropout值、优化方法及学习率.本文选择了词向量维度(取值:50, 100, 200, 300, 400)、滑动窗口大小(取值:3, 5, 7, 9)、节点数(取值:100, 200, 300)、学习率(取值:0.001, 0.005, 0.01, 0.015) 进行实验来取优,其余参数为默认值,实验结果见图 3.

|
| 图 3 各参数对实验效果的影响 Figure 3 Effects of different parameters |
通过实验对比,从图 3中可知,模型中CNN层和LSTM层的参数分别设置如表 2和表 3所示,模型性能达到最佳.
为了验证混合模型的有效性,本文在未加入任何人工特征的前提条件下,在相同的语料库上分别采用HMM、MLP、CNN、LSTM以及本文提出的混合模型进行词性标注,HMM采用一阶马尔科夫模型,对出现兼类词(即一词多性)的情况不做特殊处理.实验从准确率和模型标注速度两方面对模型进行评价,准确率和模型标注速度的实验结果如表 4和表 5所示.实验使用的机器配置为:Intel(R) Xeon E5-2620@2.0GHz,24GB RAM,GPU Quadro k2000.
| 模型 | PFR | CTB7.0 | CoNLL09 |
| HMM | 0.910 3 | 0.912 2 | 0.909 6 |
| MLP | 0.908 8 | 0.908 3 | 0.902 5 |
| CNN | 0.904 7 | 0.903 2 | 0.899 4 |
| LSTM | 0.905 8 | 0.906 7 | 0.902 2 |
| CNN+LSTM | 0.918 0 | 0.915 2 | 0.916 8 |
| 模型 | 标注速度/KB·s-1 |
| CNN | 1.323 8 |
| LSTM | 1.355 9 |
| CNN+LSTM | 1.233 4 |
从表 4可以看出,在未加入任何人工特征的条件下,对PFR语料库进行39种词性标注的准确率按高到低的顺序依次为:CNN+LSTM、HMM、MLP、LSTM、CNN.CNN+LSTM混合模型的准确率比隐马尔科夫(HMM)高0.77个百分点,比LSTM高1.22个百分点,比CNN高1.33个百分点,这得益于混合模型有效的利用了CNN的滑动窗口的特性来获取上下文相关信息产生词语表示特征,LSTM的时序性来产生标注的序列标签.相同的情况也出现在CTB7.0和CoNLL09语料库上.
表 5中的数据是给定560KB的文本,让三种模型对其进行标注而计算得出的.实验表明,混合模型标注的速度较CNN或LSTM的标注速度略低,分析其原因,是因为混合模型在层次上比CNN或LSTM有所增加,计算复杂度有所增加,标注速度就略有降低.
由于汉语语料库加工规范规定的词性标签较多,词性标注的问题最终仍然是分类的问题,所以标签的个数直接影响到最后的标注准确率.标签越多,准确率就会下降,标签越少,准确率就会越高.如果在充分研究中文词性标注的语言特点之上,人工加入某些特征,那么CNN+LSTM模型对中文词性标注的准确率将会有很大的提升空间.
3 结论本文设计了一种用于中文词性标注的CNN和LSTM混合模型,在未使用任何人工特征的条件下,对中文词语进行词性标注.模型有效的利用CNN滑动窗口以及LSTM时序性的特性.实验结果表明,使用基于CNN和LSTM的混合模型的中文词性标注方法在不加入任何其他人工特征的基础上能够取得很好的标注效果.在同样的实验条件下,混合模型的标注效果要优于HMM、MLP、CNN以及LSTM.今后将针对未登录词和兼类词,研究其对词性标注的影响,使用更多的特征,提高标注的准确率;在进行中文词性标注时,将加入某些特定的中文语言特征,使得准确率进一步提升.
| [1] |
王丽杰, 车万翔, 刘挺. 基于SVMTool的中文词性标注[J]. 中文信息学报, 2009, 23(4): 16-21. WANG L J, CHE W X, LIU T. An SVMtool-based Chinese POS tagger[J]. Journal of Chinese Information Processing, 2009, 23(4): 16-21. |
| [2] |
王广正, 王喜凤. 一种基于规则优先级的词性标注方法[J]. 安徽工业大学学报(自然科学版), 2008, 25(4): 426-429. WANG G Z, WANG X F. A method of POS tagging based on priority of rules[J]. Journal of Anhui University of Technology (Natural Science), 2008, 25(4): 426-429. |
| [3] |
KUPIEC J. Robust part-of-speech tagging using a hidden Markov model[J]. Computer Speech & Language, 1992, 6(3): 225-242. |
| [4] |
王素格, 张永奎. 汉语词性自动标注系统的设计与实现[J]. 计算机工程, 2001, 27(3): 7-8. WANG S G, ZHANG Y K. The design and implementation of the Chinese part-of-speech automatic tagging system[J]. Computer Engineering, 2001, 27(3): 7-8. |
| [5] |
ZHENG X, CHEN H, XU T. Deep learning for Chinese word segmentation and POS tagging[C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: The Association for Computational Linguistics, 2013: 647-657.
|
| [6] |
BOUVRIE J. Notes on convolutional neural networks[R]. Cambridge: MIT, 2006.
|
| [7] |
SEPP H, JURGEN S. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. DOI:10.1162/neco.1997.9.8.1735 |
| [8] |
COLLOBERT R, WESTON J, BOTTOU, et al. Natural language processing (Almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12(1): 2493-2537. |
| [9] |
SUNDERMEYER M, NEY H, SCHLUTER R. From feedforward to recurrent LSTM neural networks for language modeling[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2015, 23(3): 517-529. |
| [10] |
WANG L, TIAGO L, LUIS M, et al. Finding function in form: Compositional character models for open vocabulary word representation[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: The Association for Computational Linguistics, 2015:1520-1530.
|
| [11] |
MA X, HOVY E. End-to-end sequence labeling via Bi-directional LSTM-CNNs-CRF[C]//Proceedings of the 54th Annual Meeting of Association for Computational Linguistics. Stroudsburg: The Association for Computational Linguistics, 2016:1064-1074.
|
| [12] |
PLANK B, SOGGARD A, GOLDBEERG Y. Multilingual part-of-speech tagging with bidirectional long short-term memory models and auxiliary loss[C]//Proceedings of the 54th Annual Meeting of Association for Computational Linguistics. Stroudsburg: The Association for Computational Linguistics, 2016: 412-418.
|
| [13] |
俞士汶, 段慧明, 朱学锋, 等. 北京大学现代汉语语料库基本加工规范(续)[J]. 中文信息学报, 2002, 16(6): 49-64. YU S W, DUAN H M, ZHU X F, et al. The basic processing of contemporary Chinese corpus at Peking University specification[J]. Journal of Chinese Information Processing, 2002, 16(6): 49-64. |