 2019, Vol. 65
2019, Vol. 65
文章信息
- 郭天翼, 彭敏, 伊穆兰, 毛文月, 胡星灿, 魏格格
- GUO Tianyi, PENG Min, YI Mulan, MAO Wenyue, HU Xingcan, WEI Gege
- 自然语言处理领域中的自动问答研究进展
- Advances in Question Answering in Natural Language Processing
- 武汉大学学报(理学版), 2019, 65(5): 417-426
- Journal of Wuhan University(Natural Science Edition), 2019, 65(5): 417-426
- http://dx.doi.org/10.14188/j.1671-8836.2019.05.001
-
文章历史
- 收稿日期:2018-09-30



引用本文

|

 ,
, 自动问答(question answering, QA)最初的定义很简单, 是指对于人们用自然语言提出的问题, 计算机能够自动地给出答案或者答案列表。自动问答是计算机科学学科中信息检索与自然语言处理领域的一个重要研究方向, 主要任务是理解并自动回答用户提出的问题, 构建满足用户提出的检索、推理等需求的自动问答系统。本文拟综述近年来自然语言处理领域的自动问答技术的研究与发展。
自动问答不仅要满足用户对自然的信息交互的需求, 也要满足用户通过自动问答获取精确高效的信息的需求。自从深度学习得到广泛应用以来, 自动问答也随之得到了蓬勃的发展, 在各种智能产品上的应用也越来越广泛。
与搜索引擎相比, 自动问答系统为用户提供的答案并非是简单检索排序的文档, 而是更具有语义内涵的自然语言表述。近年来, 随着人工智能的飞速发展, 自动问答已经成为倍受关注且发展前景广阔的研究方向。该研究涉及到信息检索、知识库、深度学习等领域, 对加深自然语言处理的理论与应用研究有着现实意义。
1 自动问答的背景 1.1 自动问答的历史自动问答的研究历史可以追溯到人工智能的诞生。1950年, 阿兰·图灵(Alan M.Turing)[1]提出一种让机器回答问题来验证机器能否进行"思考"的方法, 并在这个想法之上完善, 提出了图灵测试, 用以检验机器是否具有智能。1966年, 具有问答功能的聊天机器人ELIZA诞生于美国麻省理工学院人工智能实验室, 由Weizenbaum创建[2]。ELIZA可以通过脚本理解简单的自然语言, 并模拟出类似人类的互动过程。但是ELIZA的设计机理是一些非常巧妙的语言变换技巧, 而非真正的"自然语言理解"。Parry[3]是继ELIZA之后的又一个著名的聊天机器人, 由Colby于1971年实现。自此之后, 包括ALICE[4]与Jabberwacky[5]在内的各种聊天机器人也被相继创造出来。
现有的基于关键词匹配与浅层语义分析的自动问答已经难以满足用户日益增长的需求。2011年, 以深度问答技术为核心的IBM Watson自动问答机器人在美国智力竞赛节目《Jeopardy》中战胜人类选手, 引起了业内的巨大轰动[6]。随着移动互联网的崛起与发展, 以苹果公司的Siri、谷歌的谷歌助理、亚马逊的Alexa等为代表的移动语音助手纷纷出现。这类问答系统都以自然语言为基本输入方式。各大互联网公司也将这种输入方式当作信息服务的新的表现形式, 并加大投资力度, 试图取得领先地位。
1.2 相关工作进入21世纪, 相继有学者从不同角度对自动问答领域的研究进行综述[7~12], 如文献[9]着重从限定领域自动问答方面进行了总结, 文献[10]综述了基于Web的问答系统, 文献[11]阐述了只能对话系统的相关内容, 而文献[12]给出了知识库问答系统研究进展。近年来, 随着新技术的出现, 自动问答系统得到长足发展, 但近五年在自然语言理解领域尚无较新较全面的自动问答研究概述。对自动问答整体研究状况的梳理, 有助于研究者了解当前自动问答研究的动向, 了解该问题的前沿领域与研究空白。
2 自动问答的类别自动问答技术依据不同的特征, 可以划分为不同的类别。现有的一般分类依据包括数据来源、问答范围、会话管理方式等。本文分别从这几种分类角度来对自动问答进行综述。
2.1 依据数据来源区分根据目标数据源的不同, 已有自动问答技术大致可以分为三类:1)检索式问答; 2)社区问答; 3)知识库问答。
2.1.1 检索式问答检索式问答指利用信息检索领域的技术对问题进行分析、提取特征进行检索得到问题的答案。从特征抽取方式来划分, 可以将检索式问答系统大致划分为基于模式匹配的方法与基于统计文本抽取的方法。由于知识库技术与深度学习技术的广泛应用, 研究者已经不再关注单纯的检索式问答, 大多都转为研究基于检索信息的知识库问答与深度问答。近五年的检索式问答文献显示, 该领域并没有构成一套完整的理论和方法体系。
文献[13]提出了一种基于候选答案相关性的判别的问答系统MCQAS(multiple choice question answering system), 它基于问题关键词与搜索结果片段的词共现信息来估算答案相关性。该方法通过计算每个子片段的权重, 进而计算整体的片段权重, 最终得到答案打分来进行答案的提取。然而该方法存在精度不高、答案必须完全匹配等问题。
Clark等[14]将基于模式匹配、基于统计与基于知识库的推理方法相结合, 首先在语料库上进行检索, 然后在检索到的语料上进行统计, 采用了支持向量机对语义相似度进行评估, 并通过简单的知识推理进行回答。用四年级考试所需的问答进行评估, 该方法与基于马尔科夫逻辑网络的问答系统相比, 语义相似度提高了23.8%。
深度学习对检索式问答系统的发展有着一定帮助, 并主要应用于从文本中提取答案。Azzouni等[15]认为基于匹配与语法分析的传统方法容易受到噪音的影响并且难以进行解析, 因此提出了基于深度神经网络的答案句选择模型, 尽可能减少对语法特征或外部资源的依赖。模型直接在问题与答案的单词序列上进行训练, 实际上并不依赖于句子。
2.1.2 社区问答社区问答指用户利用问答社区进行互动, 提出问题或回答问题的问答形式。问答社区是社区问答用户活跃的互联网社区。问答社区用户量巨大, 可提供许多问答数据, 这些问答数据覆盖了用户的各种信息需求。此外, 用户的历史行为信息对社区中的问答分析也有重要帮助。
问答社区为用户提供了一种新兴的、独特的交互模式。提问用户将问题提交到问答社区, 等待其他用户回答问题; 回答用户依据自身的知识水平, 选择合适的问题进行回答。用户还可以评价他人的答案, 并进行打分表示用户对他人的答案的态度。提出问题的用户还可以选取最满意的答案标记为当前问题的最佳答案。
社区问答对用户的行为进行分析, 理解用户的行为模式, 为用户的查询提供高质量的回答。社区问答包含三个核心任务, 分别是专家推荐、相似问题检索与答案质量评估。
1) 专家推荐
专家推荐对问答社区中的用户进行分析与评估, 提取每个高活跃回答用户的擅长领域, 选择与当前问题所属领域相关度较高的专家, 将当前问题通过问答社区推荐给专家, 借以提升问答的准确度与时效性。
专家推荐的主要方法是对用户与用户所回答的问题共同建模, 计算用户的领域专业度, 并通过领域专业度去检索专家。专家推荐任务可以简单表述为:给定用户列表U, 对于问题q与其所属领域dq, 检索可以回答问题q的专家eq:
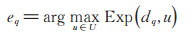
|
其中, Exp为用户的领域专业度。领域专业度的表示方法有多种, 包括主题建模、评分矩阵等。
Yang等[16]提出了一种新颖的联合概率模型CQARank, 对主题信息与专家知识同时建模, 并利用问答社区评论与投票用户的问答历史信息, 找到具有相似的局部偏好和高水平专业知识的专家。同时, 该模型也适用于专家查询、相关答案检索和类似问题推荐等任务。Zhao等[17]提出了基于缺失值估计的专家推荐方法, 构建图正则化矩阵来计算用户的社交网络联系, 判定用户是否是可以回答新问题的专家。该方法在问答社区Quora上收集数据进行实验, 得到了良好的结果。在文献[17]的基础上, Zhao等[18]通过循环神经网络学习问题的语义表示, 依据训练得到的排名度量嵌入对用户进行排名以提取专家信息。
2) 相似问题检索
相似问题检索在问答社区已存在的问题中进行检索, 选择与当前问题相似度最高的问题并提供给用户, 以方便用户获取到与当前问题相关的问答信息。
相似问题检索的一种基本方法是直接进行检索, 通过对问题中的词汇进行检索, 可以得到与问题相似的其他问题。通过词汇检索进行相似问题检索简单明了, 然而这种方法无法判断问题之间的相似程度大小, 因此已很少被使用。
通过文本相似度进行相似问题检索可以有效衡量问题间相似度。它是相似问题检索的最主要的解决方案。文本相似度是衡量文本之间的相似程度最常用的方法。常见的文本相似度包括余弦距离、词移距离等。余弦距离即
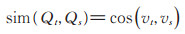
|
其中, Qt与Qs是两个问题, vt与vs是两个问题对应的向量, sim (Qt, Qs)表示两个问题的相似度函数。
Zhou等[19]使用维基百科作为外部知识的扩充, 对问题进行同义词概念扩充, 将检索问题在概念向量空间中进行表示并检索, 解决了问题的单词特征较为稀疏的问题, 改善了问题检索的性能。Wu等[20]提出了一种改进短查询的检索相关性的模型, 通过对社区问答档案中的问题描述、Web查询日志与搜索结果中挖掘搜索意图, 使用语言模型计算查询与候选问题间的相关性, 选择最相关的问题。文献[21]通过将问题表示为一个连续空间中的词向量集合, 利用算法将词向量集合合并成一个定长向量来表示问题, 更适合处理大规模的问题。文献[22]提出了一个全新的社区问答统一模型卷积神经张量网络CNTN, 使用张量层衡量文本的相似度, 学习比传统相似性度量更有效的度量方法。
3) 答案质量评估
答案质量评估是对相关问题的多个答案进行比较与评估, 对答案进行排序, 过滤相关度较低或不相关的答案, 有助于全面提升问答社区的问答质量, 提高用户的问答效率。
答案质量评估可以被解释为一个分类任务。在任务中, 一个问题的所有答案被分为两个类别, 分别是"好"答案与"差"答案。通过丰富的分类算法框架, 可以方便地进行答案质量的评估任务。
Toba等[23]提出了一个新颖的分类器框架, 用于准确有效地预测社区问答质量, 框架性能甚至超越了使用元数据识别问答质量高低的系统。文献[24]提出了基于图形切割的模型, 通过计算答案之间的相似性, 构造一个带权无向图, 在图上应用最大流算法以得到分类边界。文献[25]将答案评估问题作为序列标注任务, 使用卷积神经网络与长短时记忆网络预测答案序列中每个答案的质量(好, 可能好, 坏)。
在专家推荐、相似问题检索与答案质量评估三个核心任务之外, 社区问答也包含问题-评论相似性排名、问题间相似性排名等重要任务。SemEval-2016 Task 3与SemEval-2017 Task 3[26]提出了问题-评论相似性排名、问题间相似性排名等任务, 并公开了数据集用以进行任务。Hsu等[27]与FrancoSalvador[28]在SemEval-2016 Task 3的数据集上进行了问题-评论相似性排名、问题间相似性排名两个任务的评估, 并取得了好的结果。文献[29]的模型同时在SemEval-2015与SemEval-2017两个数据集上进行了实验, 与其他的模型相比, 表现出了好的效果。
社区问答已经成为了一种新兴的问答方式与知识共享模式, 对于社区问答的研究也已经取得了一些很好的成果。然而社区问答仍然存在着一些问题等待解决, 包括个性化搜索与推荐、恶意信息过滤、社区问答商业化等。
2.1.3 知识库问答知识库问答, 或称为面向知识库的问答, 是通过对自然语言问题进行语义理解与解析, 基于知识库进行知识提取获得答案。知识库是一组结构化数据, 包含多个三元组。三元组的结构如下: (E1, R, E2)。其中, E1与E2是三元组的两个实体, R是三元组中两个实体的关系。三元组(E1, R, E2)表明实体E1与E2之间存在关系R。
图 1是一个简单的知识库的示例, 它表示了对"罗纳尔多·路易斯纳·扎里奥·达利马"这个对象的知识的组织结构。其中蕴含的知识有"罗纳尔多的身高是180 cm"、"罗纳尔多的体重是98 kg"、"罗纳尔多的国籍是巴西"等。

|
| 图 1 知识库示例 Fig. 1 An example of knowledge base |
文本知识库将非结构化的文本数据组织成结构化的三元组。目前互联网上已有的大规模文本知识库包括DBpedia[30]、Freebase[31]、YAGO[32]等。利用文本知识库, 问答系统可以使用处理结构化数据的方式来处理文本, 进行知识库问答。
知识库问答的中心问题是如何从知识库中获取与问题相关的信息进行回答。主要包括语义解析、信息抽取、向量建模等方法。
1) 语义解析
语义解析是一种将自然语言解析为机器可以理解的逻辑形式的分析方法。通过逻辑形式从知识库中提取信息进行回答是基于语义解析的知识库问答的主要方式。Berant等[33]采用语义解析的方式, 对依赖于标注逻辑形式的传统语义解析器进行改进, 在无监督的情况下学习大规模断言下的语义解析器将自然语言转化为一系列形式化的逻辑形式, 并在知识库中查询并得到答案。Cai等[34]对文本中提取的关系与知识库关系进行匹配, 在匹配的关系上进行语义解析以进行知识库问答。文献[35]介绍了一种可扩展的开放域本体推理的语义解析方法, 通过构建语言驱动的领域无关的语义表示, 使用学习到的本体匹配模型来转换目标领域的表示, 该方法可以解决本体不匹配问题。
2) 信息抽取
信息抽取与语义解析不同, 它采用相对粗略的检索方式, 从问题中提取实体, 并在知识库中进行查询以获得以该实体为中心的知识库子图, 并在提取到的图上进行进一步的分析与处理, 以得到问题的答案。
Yao等[36]采用信息抽取的方法来进行问答, 对问题进行实体抽取, 并查询该实体在知识库中的位置, 通过图的近邻运算, 进行信息提取并筛选候选答案, 可以得到问题的答案。
3) 向量建模
向量建模方法与信息抽取比较类似。该方法根据问题得到候选答案, 并映射到向量空间中, 分布表达。同时对该表达进行训练以提高问题与正确答案的联合分数。
Bordes等[37]提出使用少量的人工编写的特征, 在更大的主题范围内进行问答。该系统学习词汇与知识库成员的低维向量表示, 这些表示为自然语言问题与候选答案进行打分。Yang等[38]提出了一种新的基于向量的知识库问答方法, 使用简单的向量运算将将自然语言问题映射到实体和谓词以进行结构化查询。Bordes等[39]将问题转换为向量表示, 专注于回答简单事实问题, 提出一种基于向量微调的模型方法, 优化参数化向量空间中的相似性矩阵进而提升性能。
深度学习的出现为知识库问答提供了新的解决方法, 通过深度学习对传统方法进行提升, 可以取得更加好的问答效果。Dai等[40]提出了一种用大规模知识库来回答单事实问题的方法, 使用神经网络的新型条件参数对问题进行全概率处理, 并用聚焦剪枝方法减少推理期间的搜索空间, 同时研究用两种模型的变形改进高度稀疏监督下的数百万实体的表示的泛化。Dong等[41]引入了MCCNNs的多层卷积神经网络模型, 得到问题的分布表示, 同时学习知识库中的实体关系的低维向量形式。该模型结合Yao等[36]的工作, 使用问句中实体的知识库子图来生成候选答案, 与卷积神经网络的输出共同打分。Yih等[42]通过将语义解析问题划分为几个子问题, 分别设计最佳解决方案, 并利用基于卷积网络的语义匹配框架, 使用连续空间表示来构建更好的关系匹配模型。Bordes等[43]使用了基于记忆网络[44]的深度问答系统, 同时构建了基于知识库的问答数据集SimpleQuestions, 在多个数据集上进行了问答的验证, 证明了系统的优越性能, 并在一定程度上进行迁移学习。Zhang等[45]提出了基于注意力的适用于知识库问答的神经网络模型, 考虑到了答案对于问题表示的影响, 利用全局知识库信息更准确地表示答案。
知识库技术的发展同时引导着知识库问答的发展。知识库的结构化特性、可扩充性与高度互连性为知识库问答带来了全新的可能性, 并为自动问答提供了优秀的解决方案。
2.2 依据问答范围区分根据回答范围的不同, 自动问答技术大致可以分为两类:1)开放域问答; 2)垂直域问答。
2.2.1 开放域问答开放域问答指问答不限定于一个特定领域, 可以基于任何领域进行提问回答的问答方式, 它可以使用任何形式的问答系统。由于知识库相关技术的快速发展, 当前的开放域问答以知识库问答为主。
Ryu等[46]使用覆盖广泛、增长快速的半结构化知识来源维基百科作为问答系统的知识来源。文献的评估结果表明, 维基百科的不同知识来源可以为不同的问题类型提供信息。
Fader等[47]提出了一个利用多个大规模的策划与提取的知识库的开放域问答系统, 描述了一个推导高置信度答案的推理算法与一种用于学习评分函数的感知器算法。同时提出了从问题语料库中自动挖掘释义运算符与重写多个知识库的查询运算符的算法。
Sun等[48]分析了基于Web的检索式问答系统与基于知识库的问答系统的不足之处, 同时使用了Web资源与Freebase知识库, 通过选择候选答案、映射到Freebase生成特征并建模, 最后基于特征排序选择最佳答案。
Wang等[49]提出了基于强化学习的开放域问答系统R3。它由Ranker、Reader与Reward三部分组成。Ranker使用基于Match-LSTM的模型进行文章选择, Reader在Ranker选择的文章中进行答案范围的筛选, Reward计算奖励并控制参数。模型在测试的5个数据集中的4个都取得了当时最好的效果。
2.2.2 垂直域问答垂直域问答, 又叫做限定域问答, 表示问答的背景知识在某个限定领域上的问答。近五年的垂直域问答文献表明, 现阶段针对垂直域问答的研究已经基本停止。垂直域问答的特性决定了现有的比较成熟的开放域问答系统面对某些垂直域问答系统会失效。垂直域问答与开放域问答两者采用的技术既有重叠也各有特色[7]。
文献[50]提到了将开放域问答系统直接推广到垂直域问答系统可能导致的问题。结合运营中的航空航天工程问答系统的用户所确定的评估标准, 该文献认为对于垂直域问答系统的评估相比于开放域问答, 应该采用更具有情境性的评价方式。
由于知识库技术与实体关系提取的广泛应用, 对开放域知识的获取正变得越来越简单。许多特定领域的知识纷纷被知识库所包含。因此, 开放域问答正逐渐取代垂直域问答成为自动问答的主流模式。
2.3 依据会话管理方式区分根据问答的会话管理方式来划分, 自动问答可以划分为两类:单轮问答和多轮问答(多轮对话)。用户的一次提问与问答系统的一次针对性的回答构成了一轮问答。单轮问答的每轮问答之间相互独立, 不存在关联, 多轮问答的每轮问答之间存在一定的关联性。多轮问答对问答上下文进行建模, 增加了问答上下文的管理模块, 因此具有更高的难度与研究价值。多轮问答是单轮问答的功能性扩展, 因此单轮问答的所有功能均包含于多轮问答中。
多轮问答是自动问答发展的一个趋势, 正在慢慢地成为自动问答的主流。相比于单轮问答, 多轮问答存在问答之间的交互与依赖, 能够构造用户与对话系统间更为上下文相关的会话过程。问答间的交互使得问答系统可以利用当前会话过程的问答信息, 避免了用户重复输入信息, 使问答更加人性化。多轮问答区别于单轮问答的一个最重要的模块叫做对话管理模块。它用来管理问答过程中的交互依赖与时效问题。对话管理模块的实现方式较多, 传统的对话管理模块实现方式包含简单的语义槽填充、有限状态机、较为复杂的基于日程的管理模块等。由于循环神经网络对于序列型数据的建模有着优势, 因此基于深度学习的对话管理常使用基于循环神经网络的对话状态跟踪策略。
Henderson等[51~53]提出了一种基于递归神经网络的置信跟踪方法。该方法直接从自动语音识别(automatic speech recognition, ASR)输出映射到置信状态更新, 避免使用复杂的语义解码器, 同时仍然获得优秀的性能。Mrkšić等[54]基于Henderson等人提出的置信跟踪方法, 在通用的对话模型上进一步训练, 学习特定域的问答行为并保留通用对话模型的跨域对话模式。在文献[55]中, Mrkšić等提出了神经置信跟踪模型, 该模型结合了口语理解与对话状态跟踪, 可以有效地处理不同的对话类型而不需要任何人工编写。文献[56]提出了一种基于注意力机制的神经网络模型, 用以进行联合的意图检测和槽填充策略。该模型结合了对齐信息与注意力机制, 为多意图分类和时隙标签预测提供了附加信息。文献[57]研究了强化学习在对话状态跟踪上的应用, 提出了基于深度循环Q网络(deep recurrent Q-networks, DRQN)的端到端多轮问答框架, 并提出了一种混合算法, 结合了强化学习与有监督学习, 实现了更快的学习速度。
在基于循环神经网络的对话状态跟踪之外, 也有学者对其他对话管理方法进行了研究。Shi等[58]提出了一种基于卷积神经网络的对话状态跟踪方法。通过使用包含一般与特定主题过滤器的卷积层, 该方法实现了多主体对话状态跟踪的性能改进。文献[59]介绍了一种基于机器阅读的一般范式的对话状态跟踪的新方法, 并使用了端到端的内存网络实现了会话管理功能。
除了对话管理模块, 多轮问答也包含了其他的功能模块, 如自然语言理解与自然语言生成等模块。其中对话管理模块的质量是决定一个多轮问答的优秀程度的关键, 并且也是决定用户体验的关键。针对多轮问答, 业界有着独特的评价指标, 包含任务完成率与平均对话轮数等。
3 基于深度学习的问答系统自从深度学习在2006年由Hinton等[60]提出, 到现在, 深度学习有了长足的发展。深度学习为问答系统提供了一个简单高效的解决方案, 将复杂的文本语义信息(词、短语、句子、段落以及篇章等)投射到低维的语义空间中, 通过使用低维空间中的向量数值计算来解决传统问答系统难以解决的问题。
基于相似性匹配的深度学习方法是深度学习问答系统的一个重要方法。它的核心思想是从观测数据中学习问题与知识的语义表示, 使得正确的回答依据在学到的向量空间中是和问题的最接近的向量。Yih等[61]提出了一个针对单关系的基于语义相似性的的语义解析框架, 并使用基于卷积神经网络的新型语义相似性模型作为核心。该框架同时训练了两个语义相似性模型:一个将问题的表述链接到知识库中的实体, 另一个将关系模式映射到关系。最后框架在知识库中找到实体关系三元组, 将问题中未提及的实体作为问题的答案返回。
无论是检索式问答、社区问答还是知识库问答, 深度学习都难以应用到对数据来源的检索中, 因此深度学习问答系统主要研究的方向是, 在提供了数据来源的基础上, 使用深度学习来对用户的提问进行回答。自动问答的这个子任务被称为阅读理解。阅读理解对问答的数据来源要求不高, 既可以使用用户提供的数据进行回答, 也可以与外部知识相结合共同进行回答。然而阅读理解对数据分析与推理功能的要求较高, 因此传统的机器学习方法难以取得优良的结果, 业界普遍采用深度学习方法进行阅读理解。
阅读理解的一般任务形式为:给定一段或多段文本作为数据来源, 输入问题, 经过处理后输出一段文本作为问题的答案。依据答案是否直接来自文本, 可将阅读理解划分为抽取式阅读理解与生成式阅读理解。
1) 抽取式阅读理解
抽取式阅读理解常用的技术是循环神经网络与指针网络(pointer network)[62]。循环神经网络是建模序列型数据的强大工具。指针网络的输出是指向输入的一系列指针, 通过输入文本, 指针网络可以输出预测的答案起始位置与结束位置, 起始位置与结束位置之间的文本作为抽取到的答案。
Seo等[63]介绍了双向注意力流网络(bi-directional attention flow, BiDAF)。网络采用分层多阶段架构, 对不同力度的上下文段落表示进行建模。网络使用了字符级、词汇级与上下文级向量, 并通过文本-问题与问题-文本双向注意力流来获得查询的上下文表示。
斯坦福大学和Facebook人工智能研究所联合提出了DrQA深度开放域问答系统[64], 该系统使用基于TF-IDF的检索策略从维基百科中检索与问题最相关的五篇文章, 并使用双向LSTM(long shortterm memory)对文章与问题进行编码, 共同进行运算输出问题的答案。
文献[65]提出了一种阅读理解端到端神经网络模型。通过循环神经网络匹配问题与文本, 并使用自注意力机制来匹配文本自身以改进文本表示, 从而有效地编码整个文本信息。
Yu等[66]则认为, 基于循环神经网络的阅读理解模型存在模型复杂、训练过于缓慢等问题, 因此提出了基于卷积神经网络与自注意力机制的阅读理解模型QANet。该模型通过卷积操作捕获文本的局部结构, 利用自注意力机制学习词与词之间的全局交互信息。
2) 生成式阅读理解
抽取式阅读理解简单明了, 实现较为容易, 然而答案只能是文本中的文字, 难以实现灵活与人性化的问答。生成式阅读理解研究的是如何生成更加符合自然语言特性的答案。
Sequence to Sequence(Seq2Seq)[67]是生成式阅读理解中的常用技术。Seq2Seq的模型包含两个主要模块, 分别是编码器Encoder与解码器Decoder。Encoder通过对输入序列进行编码得到一个固定长度的向量表达, Decoder通过解码过程将向量转化为输出序列。在阅读理解中, 较为常见的生成式阅读理解方法是先使用抽取式阅读理解抽取问题对应答案的依据片段, 将依据片段输入Seq2Seq模型, 可以得到一个符合自然语言习惯的合格的答案。
文献[68]基于文献[65]的工作, 将生成式阅读理解任务划分为"提取-合成"两阶段。"提取"阶段通过提取式模型提取出文本的多个子片段作为生成答案所需的证据; "合成"阶段通过Seq2Seq模型以证据为特征生成答案。
文献[69]使用边界预测、内容建模和答案验证三阶段模型进行阅读理解。边界预测模块使用抽取式模型获得候选答案; 内容建模模块对候选答案进行处理, 依次判断每个词汇是否应当出现在最终答案中; 答案验证通过比对多个候选答案的信息, 进行候选答案间的交叉验证并从中选择表现最好的作为最终答案。
阅读理解子任务上出现了许多评测与数据集, 包括SQuAD[70]、CoQA[71]、DuReader[72]等。在这些数据集的评测过程中涌现了大量优秀的阅读理解论文与模型。阅读理解仍有着光明的发展前景, 吸引着许多学者投入研究。
4 自动问答领域的问题与挑战自动问答领域仍然存在着一些难以解决的问题。这些问题包括复杂推理问题、对话系统的长时对话管理问题和多用户问答管理问题等。
4.1 复杂推理问题现有的问答系统对于简单的事实类问答的效果较好, 而对于需要复杂推理的事实类问答、描述类问答与观点类问答的效果较差, 一个重要原因是没有解决复杂问题中的逻辑推理问题。使用信息抽取与检索方法的问答系统中的推理形式一般较为简单, 仅能通过词汇与语句间的相似度计算进行简单的推理工作; 使用模式匹配方法的问答系统能够根据推理模式来进行简单与复杂推理, 然而推理模式的编写需要大量的人工工作; 使用机器学习方法的问答系统可以通过具有一定智能的机器学习方法进行推理, 相比于前两种问答系统具有明显优势, 但是需要很多语料对它进行训练与特征分析。
4.2 长时对话管理问题自动问答中对话系统的一个挑战是如何进行时间跨度较长的对话流程。该流程中有两个方面问题需要解决:如何确定对话过程中的哪些信息较为重要, 需要保存在对话系统的记忆中; 如何确定哪些信息已经过时, 需要从记忆中去除。现阶段的一些对话系统已经可以做到在一次会话过程中进行多轮对话, 一个较为简单的解决方法是在会话结束时将会话信息暂时存储下来, 下次会话开始时再进行恢复。然而要实现真正的长时对话管理, 还有许多问题需要解决。
4.3 多用户问答管理问题自动问答中对话系统面临的另一个复杂问题是多用户问答中的交互与管理问题。针对每个用户分别进行对话, 相互隔离是较为容易实现的, 然而对于"上一个和你对话的用户说了什么内容"这样在一个用户的对话流程中引入了另一个用户的对话内容的问题, 涉及到用户之间的信息交换, 大部分对话系统仍然无法解决。为了解决长时对话管理与多用户问答问题, 对话系统的对话管理模块必须具有相当水平的智能。
5 结语自从人工智能出现以来, 自动问答技术便是领域中一个重要的研究分支。人工智能领域的专家对自动问答的研究一直没有停止。随着互联网的不断发展, 网络上的知识不断增加, 用户对自动问答的要求也越来越高。现阶段自动问答技术还处在较为原始的地步, 几乎所有的问答系统都仅仅具备最基本的智能与推理能力, 只能做到从知识库等来源进行搜索, 并且准确率一般都比较低, 不能令人满意。
虽然自动问答技术的表现离理想目标还有较大的距离, 但是它发展迅猛。现阶段, 工业领域已经有许多表现较为优秀的问答系统被投入使用。相信在不久的将来, 问答系统的发展将会出现重大突破。
| [1] |
TURING A M. Computing Machinery and Intelligence[J]. Mind, 1950, 59(236): 433-460. |
| [2] |
WEIZENBAUM J. ELIZA-A computer program for the study of natural language communication between man and machine[J]. Communications of the ACM, 1966, 9(1): 36-45. |
| [3] |
COLBY K M, WEBER S, HILF F D. Artificial paranoia[J]. Artificial Intelligence, 1971, 2(1): 1-25. |
| [4] |
WALLACE R S.The anatomy of ALICE[C].Parsing the Turing Test, Berlin: Springer, 2009: 181-210.
|
| [5] |
CARPENTER R.Jabberwacky[EB/OL].[2019-05-16].http://www.jabberwacky.com/.
|
| [6] |
FERRUCCI D, LEVAS A, BAGCHI S, et al. Watson: Beyond Jeopardy![J]. Artificial Intelligence, 2013, 199(3): 93-105. |
| [7] |
郑实福, 刘挺, 秦兵, 等. 自动问答综述[J]. 中文信息学报, 2002, 16(6): 47-53. ZHENG S F, LIU T, QIN B, et al. Overview of question-answering[J]. Journal of Chinese Information Processing, 2002, 16(6): 47-53. (Ch). |
| [8] |
何靖, 陈翀, 闫宏飞.开放域问答系统研究综述[C]//第六届全国信息检索学术会议论文集.牡丹江, 2010: 121-128. HE J, CHEN C, YAN H F.A Survey: Open-domain question answering system[C]// Proceedings of the 6th China National Conference on Information Retrieval.Mudanjiang, 2010: 121-128(Ch). |
| [9] |
王东升, 王卫民, 王石, 等. 面向限定领域问答系统的自然语言理解方法综述[J]. 计算机科学, 2017, 44(8): 1-8. WANG D S, WANG W M, WANG S, et al. Research on domain-specific question answering system oriented natural language understanding:A survey[J]. Computer Science, 2017, 44(8): 1-8. (Ch). |
| [10] |
李舟军, 李水华. 基于Web的问答系统综述[J]. 计算机科学, 2017, 44(6): 1-7. LI Z J, LI S H. Survey on web-based question answering[J]. Computer Science, 2017, 44(6): 1-7. (Ch). |
| [11] |
贾熹滨, 李让, 胡长建, 等. 智能对话系统研究综述[J]. 北京工业大学学报, 2017, 43(9): 1344-1356. JIA X B, LI R, HU C J, et al. Review of intelligent dialogue system[J]. Journal of Beijing University of Technology, 2017, 43(9): 1344-1356. (Ch). |
| [12] |
DIEFENBACH D, LOPEZ V, SINGH K, et al. Core techniques of question answering systems over knowledge bases:A survey[J]. Knowledge and Information Systems, 2017, 55(3): 529-569. |
| [13] |
AWADALLAH R. Judging relevance of candidate answers in question answering system[J]. International Journal of Computer Science and Mobile Computing, 2013, 2(5): 2728-2731. |
| [14] |
CLARK P, ETZIONI O, KHOT T, et al.Combining retrieval, statistics, and inference to answer elementary science questions[C]//13th AAAI Conference on Artificial Intelligence.Arizona: AAAI, 2016: 2580-2586.
|
| [15] |
AZZOUNI A, PUJOLLE G.A Long Short-Term Memory Recurrent Neural Network Framework for Network Traffic Matrix Prediction[DB/OL].[2018-08-09].https://www.researchgate.net/publication/316985409_A_Long_Short-Term_Memory_Recurrent_Neural_Network_Framework_for_Network_Traffic_Matrix_Prediction.
|
| [16] |
YANG L, QIU M H, GOTTIPATI S, et al.CQArank: Jointly model topics and expertise in community question answering[C]// ACM International Conference on Information & Knowledge Management.New York: ACM, 2013: 99-108.DOI: 10.1145/2505515.2505720.
|
| [17] |
ZHAO Z, ZHANG L J, HE X F, et al. Expert finding for question answering via graph regularized matrix completion[J]. IEEE Transactions on Knowledge and Data Engineering, 2015, 27(4): 993-1004. DOI:10.1109/TKDE.2014.2356461 |
| [18] |
ZHAO Z, YANG Q F, CAI D, et al.Expert finding for community-based question answering via ranking metric network learning[C]//25th International Joint Conference on Artificial Intelligence.New York: AAAI Press, 2016: 3000-3006.
|
| [19] |
ZHOU G Y, LIU Y, LIU F, et al.Improving question retrieval in community question answering using world knowledge[C]//23rd International Joint Conference on Artificial Intelligence.New York: AAAI Press, 2013: 2239-2245.
|
| [20] |
WU H C, WU W, ZHOU M, et al.Improving search relevance for short queries in community question answering [C]//Proceedings of the 7th ACM International Conference on Web Search and Data Mining.New York: ACM, 2014: 43-52.DOI: 10.1145/2556195.2556239.
|
| [21] |
ZHOU G Y, HE T T, ZHAO J, et al.Learning Continuous Word Embedding with Metadata for Question Retrieval in Community Question Answering[DB/OL].[2018-06-09].https://pdfs.semanticscholar.org/f0ec/25cb2e7a17fed5eae185a5b779c1c0704719.pdf.
|
| [22] |
QIU X P, HUANG X J.Convolutional neural tensor network architecture for community-based question answering [C]//24th International Joint Conference on Artificial Intelligence.Buenos Aires: AAAI Press, 2015: 1305-1311.
|
| [23] |
TOBA H, MING Z Y, ADRIANI M, et al. Discovering high quality answers in community question answering archives using a hierarchy of classifiers[J]. Information Sciences, 2014, 261(5): 101-115. DOI:10.1016/j.ins.2013.10.030 |
| [24] |
JOTY S, BARRÓ N-CEDENO A, DA SAN MARTINO G, et al.Global Thread-level Inference for Comment Classification in Community Question Answering[DB/ OL].[2018-09-09].https://www.researchgate.net/publication/282132622_Global_Thread-Level_Inference_for_Comment_Classification_in_Community_Question_Answering.DOI:10.18653/v1/D15-1068.
|
| [25] |
ZHOU X Q, HU B T, CHEN Q C, et al.Answer Sequence Learning with Neural Networks for Answer Selection in Community Question Answering[DB/OL].[2018-09-10].https://arxiv.org/pdf/1506.06490v1.pdf.
|
| [26] |
NAKOV P, HOOGEVEEN D, MÀ RQUEZ L, et al.SemEval-2017 Task 3: Community Question Answering [DB/OL].[2018-09-04].http://alt.qcri.org/semeval2017/task3/.
|
| [27] |
HSU W N, ZHANG Y, GLASS J.Recurrent Neural Network Encoder with Attention for Community Question Answering[DB/OL].[2018-09-04].https://arxiv.org/pdf/1603.07044.pdf.
|
| [28] |
FRANCO-SALVADOR M, KAR S, SOLORIO T, et al.UH-PRHLT at SemEval-2016 Task 3: Combining Lexical and Semantic-Based Features for Community Question Answering[DB/OL].[2018-09-04].https://www.aclweb.org/anthology/S16-1126.DOI:10.18653/v1/S16-1126.
|
| [29] |
WU W, S U N X, WANG H F.Question Condensing Networks for Answer Selection in Community Question Answering[DB/OL].[2018-09-04].https://www.aclweb.org/anthology/P18-1162.
|
| [30] |
AUER S, BIZER C, KOBILAROV G, et al.DBpedia: A nucleus for a web of open data[C]//The Semantic Web(International Semantic Web Conference, Asian Semantic Web Conference, 2007)(LNCS4825).Heidelberg : Springer, 2007: 722-735.
|
| [31] |
BOLLACKER K, EVANS C, PARITOSH P, et al.Freebase: A collaboratively created graph database for structuring human knowledge[C]//Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data.New York: ACM, 2008: 1247-1250.DOI: 10.1145/1376616.1376746.
|
| [32] |
SUCHANEK F M, KASNECI G, WEIKUM G.Yago: A core of semantic knowledge[C]//WWW'07 Proceedings of the 16th International Conference on World Wide Web.New York: ACM, 2007: 697-706.DOI: 10.1145/1242572.1242667.
|
| [33] |
BERANT J, CHOU A, FROSTIG R, et al.Semantic Parsing on Freebase from Question-Answer Pairs[DB/ OL].[2018-09-04].https://cs.stanford.edu/~pliang/papers/freebase-emnlp2013.pdf.
|
| [34] |
CAI Q Q, YATES A.Large-scale Semantic Parsing via Schema Matching and Lexicon Extension[DB/OL].[2018-10-04].https://www.aclweb.org/anthology/P13-1042.
|
| [35] |
KWIATKOWSKI T, CHOI E, ARTZI Y, et al.Scaling Semantic Parsers with On-the-Fly Ontology Matching [DB/OL].[2018-05-04].https://www.aclweb.org/anthology/D13-1161.
|
| [36] |
YAO X C, VAN DURME B.Information Extraction over Structured Data: Question Answering with Freebase [DB/OL].[2018-05-04].http://cs.jhu.edu/~xuchen/paper/yao-jacana-freebase-acl2014.pdf.
|
| [37] |
BORDES A, CHOPRA S, WESTON J.Question Answering with Subgraph Embeddings[DB/OL].[2018-03-04].https://www.aclweb.org/anthology/D14-1067.DOI:10.3115/v1/D14-1067.
|
| [38] |
YANG M C, DUAN N, ZHOU M, et al.Joint Relational Embeddings for Knowledge-based Question Answering[DB/ OL].[2018-05-04].http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.655.9380&rep=rep1 &type=pdf.DOI:10.3115/v1/D14-1071.
|
| [39] |
BORDES A, WESTON J, USUNIER N.Open Question Answering with Weakly Supervised Embedding Models[DB/ OL].[2018-03-04].https://arxiv.org/pdf/1404.4326.pdf.
|
| [40] |
DAI Z H, LI L, XU W.CFO: Conditional Focused Neural Question Answering with Large-Scale Knowledge Bases[DB/OL].[2018-04-05].https://www.aclweb.org/anthology/P16-1076.
|
| [41] |
DONG L, WEI F, ZHOU M, et al.Question Answering over Freebase with Multi-Column Convolutional Neural Networks[DB/OL].[2018-04-05].https://www.aclweb.org/anthology/P15-1026.DOI: 10.3115/v1/P15-1026.
|
| [42] |
YIH W T, CHANG M W, HE X D, et al.Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base[DB/OL].[2018-04-05].https://www.aclweb.org/anthology/P15-1128.
|
| [43] |
BORDES A, USUNIER N, CHOPRA S, et al.LargeScale Simple Question Answering with Memory Networks [DB/OL].[2018-06-05].https://arxiv.org/pdf/1506.02075.pdf.
|
| [44] |
WESTON J, CHOPRA S, BORDES A.Memory Networks[DB/OL].[2018-06-05].https://arxiv.org/pdf/ 1410.3916.pdf.
|
| [45] |
ZHANG Y Z, LIU K, HE S Z, et al.Question answering over knowledge base with neural attention combining global knowledge information[DB/OL].[2018-06-05].https://arxiv.org/pdf/1606.00979.pdf.
|
| [46] |
RYU P M, JANG M G, KIM H K. Open domain question answering using Wikipedia-based knowledge model[J]. Information Processing & Management, 2014, 50(5): 683-692. |
| [47] |
FADER A, ZETTLEMOYER L, ETZIONI O.Open Question Answering over Curated and Extracted Knowledge Bases[DB/OL].[2018-07-05].https://homes.cs.washington.edu/~lsz/papers/fze-kdd14.pdf.
|
| [48] |
SUN H, MA H, YIH W T, et al.Open domain question answering via semantic enrichment[DB/OL].[2018-07-05].http://www.www2015.it/documents/proceedings/proceedings/p1045.pdf.
|
| [49] |
WANG S H, YU M, GUO X X, et al.R3: Reinforced Reader-Ranker for Open-Domain Question Answering [DB/OL].[2018-07-05].https://arxiv.org/pdf/1709.00023v2.pdf.
|
| [50] |
DIEKEMA A R, YILMAZEL O, LIDDY E D.Evaluation of Restricted Domain Question-answering Systems [DB/OL].[2018-07-05].https://www.aclweb.org/anthology/W04-0502.
|
| [51] |
HENDERSON M, THOMSON B, YOUNG S.Deep Neural Network Approach for the Dialog State Tracking Challenge[DB/OL].[2018-07-05].<i>https://aclweb.org/anthology/W13-4073.
|
| [52] |
HENDERSON M, THOMSON B, YOUNG S.Robust Dialog State Tracking Using Delexicalised Recurrent Neural Networks And Unsupervised Adaptation[C]//2014 IEEE Spoken Language Technology Workshop(SLT).Washington D C: IEEE, 2014: 360-365.DOI: 10.1109/SLT.2014.7078601.
|
| [53] |
HENDERSON M, THOMSON B, YOUNG S.Wordbased Dialog State Tracking with Recurrent Neural Networks[DB/OL].[2018-07-05].https://www.aclweb.org/anthology/W14-4340.
|
| [54] |
MRKŠIĆ N, SÉ AGHDHA D O, THOMSON B, et al.Multi-Domain Dialog State Tracking Using Recurrent Neural Networks[DB/OL].[2018-07-05].http://svrwww.eng.cam.ac.uk/~sjy/papers/mstg15.pdf.
|
| [55] |
MRKŠIĆ N, SÉAGHDHA D O, WEN T H, et al.Neural Belief Tracker: Data-Driven Dialogue State Tracking[DB/ OL].[2018-07-05].https://arxiv.org/pdf/1606.03777.pdf.
|
| [56] |
LIU B, LANE I.Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling[DB/ OL].[2018-07-05].https://arxiv.org/pdf/1609.01454.pdf.
|
| [57] |
ZHAO T C, ESKENAZI M.Towards End-to-End Learning for Dialog State Tracking And Management Using Deep Reinforcement Learning[DB/OL].[2018-07-05].https://www.aclweb.org/anthology/W16-3601.
|
| [58] |
SHI H, USHIO T, ENDO M, et al.Convolutional Neural Networks for Multi-Topic Dialog State Tracking[DB/OL].[2018-07-05].https://link.springer.com/chapter/10.1007/978-981-10-2585-3_37. DOI:10.1007/978-981-10-2585-3_37.
|
| [59] |
PEREZ J, LIU F.Dialog State Tracking, a Machine Reading Approach Using Memory Network[DB/OL].[2018-07-05].https://arxiv.org/pdf/1606.04052.pdf.
|
| [60] |
HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507. DOI:10.1126/science.1127647 |
| [61] |
YIH W, HE X, MEEK C.Semantic Parsing for Singlerelation Question Answering[DB/OL].[2018-07-05].http://acl2014.org/acl2014/P14-2/pdf/P14-2105.pdf.
|
| [62] |
VINYALS O, FORTUNATO M, JAITLY N.Pointer Networks[DB/OL].[2018-07-05].https://arxiv.org/ pdf/1506.03134.pdf.
|
| [63] |
SEO M, KEMBHAVI A, FARHADI A, et al.Bi-directional Attention Flow for Machine Comprehension[DB/OL].[2018-07-05].https://arxiv.org/pdf/1611.01603.pdf.
|
| [64] |
CHEN D Q, FISCH A, WESTON J, et al.Reading Wikipedia to Answer Open-Domain Questions[DB/ OL].[2018-07-05].https://arxiv.org/pdf/1704.00051.pdf.DOI:10.18653/v1/P17-1171.
|
| [65] |
Natural Language Computing Group, Microsoft Research Asia.R-NET: Machine Reading Comprehension with SelfMatching Networks[DB/OL].[2018-07-05].https:// www.microsoft.com/en-us/research/wp-content/uploads/ 2017/05/r-net.pdf.
|
| [66] |
YU A W, DOHAN D, LUONG M T, et al.Qanet: Combining Local Convolution with Global Self-Attention for Reading Comprehension[DB/OL].[2018-07-05].https://arxiv.org/pdf/1804.09541.pdf.
|
| [67] |
SUTSKEVER I, VINYALS O, LE Q V.Sequence to Sequence Learning with Neural Networks[DB/OL].[2018-07-05].https://arxiv.org/pdf/1409.3215.pdf.
|
| [68] |
TAN C, WEI F, YANG N, et al.S-Net: From Answer Extraction to Answer Generation for Machine Reading Comprehension[DB/OL].[2018-07-05].https://arxiv.org/pdf/1706.04815.pdf.
|
| [69] |
WANG Y Z, LIU K, LIU J, et al.Multi-Passage Machine Reading Comprehension with Cross-Passage Answer Verification[DB/OL].[2018-09-05].https://arxiv.org/pdf/1805.02220.pdf.
|
| [70] |
RAJPURKAR P, ZHANG J, LOPYREV K, et al.SQuaD: 100, 000+ Questions for Machine Comprehension of Text[DB/OL].[2018-09-05].https://arxiv.org/pdf/1606.05250.pdf.DOI:10.18653/v1/D16-1264.
|
| [71] |
REDDY S, CHEN D, MANNING C D.CoQA: A Conversational Question Answering Challenge[DB/OL].[2018-09-05].https://arxiv.org/pdf/1808.07042v1.pdf.
|
| [72] |
HE W, LIU K, LYU Y J, et al.DuReader: A Chinese Machine Reading Comprehension Dataset from Real-world Applications[DB/OL].[2018-09-05].https://arxiv.org/pdf/1711.05073.pdf.
|