 2019, Vol. 65
2019, Vol. 65
文章信息
- 李婷婷, 吕佳
- LI Tingting, LÜ Jia
- 基于加权K最近邻改进朴素贝叶斯自训练算法
- Improved Naive Bayes Self-Training Algorithm Based on Weighted K-Nearest Neighbor
- 武汉大学学报(理学版), 2019, 65(5): 465-471
- Journal of Wuhan University(Natural Science Edition), 2019, 65(5): 465-471
- http://dx.doi.org/10.14188/j.1671-8836.2019.05.007
-
文章历史
- 收稿日期:2018-07-18



引用本文

|



2. 重庆师范大学 重庆市数字农业服务工程技术研究中心,重庆 401331
2. Chongqing Center of Engineering Technology Research on Digital Agricultural Service, Chongqing Normal University, Chongqing 401331, China
由于现实生活中存在大量的无标记样本, 而有标记样本非常有限。因此, 利用少量有标记样本和大量无标记样本共同训练分类器的半监督学习算法应运而生[1, 2]。自训练算法[3, 4]是半监督学习算法中的一种, 它先用少量有标记样本训练分类器, 再选出高质量的无标记样本加入到有标记样本集中, 迭代循环直至算法收敛。自训练算法的简单有效性, 使得该算法广泛应用于文本分类[5]、图像处理[6]、地形识别[7]等多个领域。
自训练过程中, 如何选取高质量样本进行训练, 成为广大学者争相研究的课题。由于朴素贝叶斯算法具有简单、高效和稳定性强等特点, 部分学者将朴素贝叶斯计算得出的后验概率作为置信度选取高质量样本。文献[8]引入一种改进的朴素贝叶斯算法, 该算法通过将集成分类器最大后验概率与朴素贝叶斯后验概率之和作为置信度, 解决了重复出现最大后验概率值的问题, 有利于选取高质量样本。Taheri等[9]提出了一种新的属性加权朴素贝叶斯分类器, 该分类器考虑了条件概率的权重, 其中目标函数是基于朴素贝叶斯分类器的结构和属性权重建立的, 它的最佳权重由局部优化方法确定, 来源于真实世界数据集上的实验结果显示了所提方法的有效性。董立岩等[10]根据类别Ci的后验概率与非Ci类的平均概率之差作为置信度, 选取置信度最大的h个样本加入训练集, 提出了一种基于半监督学习的新型半监督朴素贝叶斯算法, 该方法通过将选出的高质量样本加入训练集进行训练, 提高了分类正确率。张维等[11]首先将朴素贝叶斯分类器作为初始分类器对有标记样本进行分类, 然后对无标记样本使用EM算法, 迭代训练初始分类器, 在Amazon. cn数据集上的实验结果表明, 该方法提升了算法的有效性。
样本的空间结构包含着重要信息, 在利用好这些信息的基础上选取高质量样本能大大提升自训练算法的性能。针对传统朴素贝叶斯自训练方法未能利用样本空间结构所含信息的问题, Gan等[12]提出用半监督模糊C均值聚类(semi-supervised fuzzy C means, SFUC)来改进自训练算法。他们认为无标记样本可能含有数据空间结构的潜在信息, 利用这些信息能更好地辅助自训练。半监督度量的模糊聚类算法(semi-supervised metric-based fuzzy clustering algorithm, SMUC)通过学习马氏距离来取代模糊C均值中的欧式距离, 文献[13]使用SMUC改进自训练, 效果好于SFUC。以上两种方法很好地利用了空间结构所包含的样本信息, 实验结果证实了所提方法的可行性和有效性。Karlos等[14]计算出无标记样本与有标记样本间的距离, 选取离类中心最近的h个样本进行朴素贝叶斯分类。该方法在一定程度上考虑到了整个样本空间结构对分类正确率的影响。
在文献[14]的工作基础上, 本文提出了一种使用加权K-最近邻[15, 16(] K-nearest-neighbor, KNN)改进朴素贝叶斯自训练的算法(improved naive Bayesian self-training algorithm based on weighted K-nearest neighbors, WKNNNBST), 采用加权K-最近邻的方法通过样本间的距离以及加权核函数得出无标记样本的隶属度。该隶属度在一定程度上能反映出样本空间潜在的结构, 在一个较好的空间结构上对未标记样本分类, 能有效提升分类正确率。
1 本文算法 1.1 算法思想在传统的半监督朴素贝叶斯自训练过程中, 使用朴素贝叶斯计算置信度时, 是通过以往的经验和分析得出的先验概率来决定后验概率从而得出样本所属类别置信度[17], 这样会使分类决策存在一定的错误。在自训练过程中, 选择未标记样本时可能会将大量带有错误类标号的样本添加到训练集中, 再一次次地迭代, 降低了分类正确率[18]。但如果未标记样本与已标记样本在空间结构上距离越近, 那么该未标记样本所含的信息也就更准确, 分类时将会得出更高的正确率。但传统朴素贝叶斯在自训练过程中并未考虑到整个样本集的空间结构对分类正确率的影响。
为了解决传统朴素贝叶斯自训练算法存在的以上问题, 本文提出了基于加权KNN改进朴素贝叶斯自训练的算法。加权KNN计算未标记样本在特征空间中的K个最相似(即特征空间中最邻近)样本的过程中, 会采用距离公式计算未标记样本与每个已标记样本间的距离, 再用第K+1个近邻距离来标准化前K个近邻距离, 然后用加权函数将标准化距离转化为未标记样本与已标记样本的同类概率, 最后根据K个近邻求出未标记样本属于每个类的后验概率, 随即计算出未标记样本属于每个类的隶属度。因此, 隶属度的高低能很好地反映出整个样本集的空间结构, 当某个无标记样本的最大隶属度较高时, 说明该无标记样本在空间结构上离真实样本的类中心越近, 所含的信息也更准确。所以, 在一个较好的空间结构上对未标记样本进行分类, 充分地利用了样本的空间结构信息, 能很好地降低自训练过程中的迭代错误。
基于以上分析, 本文算法首先用加权KNN选出无标记样本中最大隶属度较高的前h个样本, 再用朴素贝叶斯分类器对这h个样本进行分类, 随后选取分类置信度高的前f (f < h)个样本加入到有标记样本中进行下一次训练。这样, 降低了自训练过程的错误累积, 从而提高了算法的分类精度。利用WKNNNBST算法生成数据类标号的过程如图 1所示。其中L表示有类标号的样本集, U表示无类标号的样本集, Top h表示从无类标号样本集中选取隶属度高的h个样本, Top f表示从隶属度高的h个样本集中选取置信度高的f个样本, WKNN(weighted K-nearest neighbors algorithm)表示加权K-最近邻算法, NBC(naive Bayes classifier)表示朴素贝叶斯分类器。

|
| 图 1 WKNNNBST算法生成数据类标号过程 Fig. 1 The process of WKNNNBST algorithm generates data class labeling |
在自训练学习过程中, 如果未标记样本离已标记样本空间距离越近, 那么它的隶属度也相对更大, 标注的隶属度越大的样本, 所得到的类标号与真实的类标号更可能相同, 可以用最大后验概率来代表属于某个类的隶属度。
设有类标号的数据集L={(xi, yi) }, 其中: 
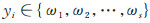
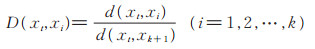
|
(1) |
然后用加权核函数, 将标准化距离转化为xt和xi的同类概率P (xi|xt), 则有
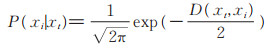
|
(2) |
最后根据xt的k个近邻求出xt属于类ωr(r=1, 2, …, s)的后验概率, 则有
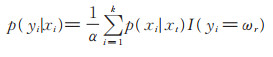
|
(3) |
其中

|
(4) |

|
(5) |
则无标记样本的隶属度可以定义为

|
(6) |
这样便得出了KNN分类器的隶属度[19]。
1.3 WKNNNBST算法流程输入:有类标号的样本集L, 无类标号的样本集U。
输出:测试集Test的预测类别C, 分类正确率R。
步骤:
Step 1 通过样本集L和U训练加权KNN分类器, 从而得出U中所有样本的分类隶属度, 然后选出每个未标记样本所属类别的隶属度的最大值。
Step 2 再将每个未标记样本的最大隶属度按降序排序, 选出U中隶属度高的前h个样本。
Step 3 将选出的h个样本用朴素贝叶斯分类器进行再一次分类, 并将得到的置信度按降序排序。
Step 4 在Step 3中选出置信度高的前f个样本, 其中f小于h。
Step 5 将选出的f个样本以及对应的类标号加入到L集形成更新后的L集。
Step 6 原始U集对应减去挑选出的f个样本集, 形成新的U集。
Step 7 重复Step1到Step 6, 直到U集为空。
Step 8 循环结束, 利用新得到的L集来预测Test中的样本所属类别C, 并计算预测正确率R。
2 仿真实验 2.1 实验算法及说明为了说明本文算法的有效性, 设计了5个对比算法, 在9个数据集上的对比实验。选用的算法如下:
① 朴素贝叶斯算法(Naive Bayes, NB)。
② 朴素贝叶斯自训练算法(Naive Bayes selftraining, NBST)。
③ 基于文献[10]提出的半监督朴素贝叶斯新算法(Novel semi-supervised Naive Bayes, NSNB)。
④ 基于文献[13]提出的半监督基于度量的模糊聚类自训练(semi-supervised metric-based fuzzy clustering self-training, SMUCST)。
⑤ 传统的半监督K最近邻算法结合朴素贝叶斯算法(K-nearest neighbor combined with Naive Bayes, KNNNB)。
实验的数据来源于UCI以及Kaggle数据集, 共9个(如表 1)。对数据集Lonosphere和Image Segmentation做预处理, 删除其中的离散属性列。
| Dataset | Size | Attributes | Class |
| Seeds | 210 | 7 | 3 |
| Iris | 150 | 4 | 3 |
| User knowledge modeling | 258 | 5 | 4 |
| Wine | 178 | 13 | 2 |
| Pima | 768 | 8 | 2 |
| Lonosphere | 351 | 32 | 2 |
| Abalone | 4177 | 8 | 3 |
| Breast cancer coimbra | 116 | 9 | 2 |
| Image segmentation | 2310 | 14 | 7 |
实验中, 把每组数据随机分成训练集和测试集, 其中训练集占80%, 测试集占20%。再在训练集中随机选取10%做初始化有标记样本, 其余样本除去类标签后作为无标记样本。所有算法进行十折交叉验证, 取10次平均分类正确率。
算法NBST、NSNB、SMUCST以及本文算法在自训练迭代过程中所涉及的参数h的取值为无标记样本数量的20%。本文算法所涉及的另一参数f的取值及对应的正确率±标准差见表 2。从表 2可以看出, 在初始有标记样本数量为30%的情况下, f取不同的值对分类正确率的影响。当f=50%×h时, 本文算法整体上效果更好。因此, 在2.2节中, 取f=50%×h进行实验说明。
| % | |||||
| Dataset | f=30%×h | f=40%×h | f=50%×h | f=60%×h | f=70%×h |
| Seeds | 83. 809 5±3. 809 5 | 89. 523 8±3. 563 5 | 90. 952 4±5. 909 4 | 89. 523 8±2. 857 1 | 86. 666 7±3. 563 5 |
| Iris | 96. 000 0±3. 887 3 | 92. 666 7±3. 887 3 | 96. 666 7±2. 108 2 | 96. 000 0±1. 333 3 | 91. 333 3±3. 399 3 |
| User knowledge modeling | 83. 076 9±5. 493 4 | 84. 615 3±3. 217 9 | 85. 769 2±5. 652 7 | 80. 000 0±5. 908 6 | 82. 692 3±6. 435 8 |
| Wine | 92. 777 8±4. 154 7 | 95. 555 6±2. 832 8 | 96. 666 7±2. 078 7 | 94. 444 4±3. 928 4 | 96. 111 1±3. 768 0 |
| Pima | 67. 532 5±4. 928 2 | 68. 441 6±3. 952 0 | 72. 510 8±1. 673 2 | 70. 259 7±3. 421 3 | 69. 480 5±2. 845 3 |
| Lonosphere | 72. 857 1±6. 172 1 | 85. 714 3±4. 856 2 | 87. 142 9±4. 917 2 | 82. 857 1±7. 095 1 | 82. 857 1±4. 714 0 |
| Abalone | 51. 568 9±0. 724 9 | 50. 586 8±2. 026 2 | 52. 047 9±2. 102 6 | 51. 185 6±2. 199 9 | 53. 077 8±1. 427 9 |
| Breast cancer coimbra | 68. 115 9±5. 422 7 | 65. 217 4±7. 100 0 | 66. 521 7±8. 198 3 | 62. 318 8±10. 845 4 | 50. 724 6±7. 389 9 |
| Image segmentation | 66. 428 6±2. 471 1 | 69. 285 7±2. 953 8 | 70. 476 2±2. 146 4 | 65. 555 6±2. 319 3 | 62. 539 7±4. 683 2 |
| 注:加粗部分表示实验效果最好 | |||||
训练集中随机选取10%做初始化有标记样本, 取10次平均分类正确率±标准差, 如表 3所示, 其中加粗的数据说明在该算法上分类效果最好。本文所提算法与5个对比算法的正确率提升效果如表 4所示。
| % | ||||||
| Dataset | WKNNNBST | NB | SNBST | NSNB | SMUCST | KNNNB |
| Seeds | 87.62±1.78 | 83.33±10.38 | 80.71±13.19 | 87.14±3.23 | 86.67±7.47 | 76.07±9.62 |
| Iris | 87.33±5.73 | 83.33±18.62 | 81.67±17.14 | 84.33±12.65 | 62.67±17.88 | 70.83±16.89 |
| User knowledge modeling | 60.19±19.44 | 68.27±22.27 | 60.58±27.44 | 71.15±15.76 | 48.46±10.24 | 35.19±15.07 |
| Wine | 91.11±3.24 | 71.94±14.24 | 85.00±12.98 | 85.56±11.24 | 75.00±8.78 | 58.33±6.46 |
| Pima | 72.41+1.62 | 70.35±4.01 | 68.83±1.40 | 66.88±1.40 | 71.21±3.61 | 65.39±2.25 |
| Lonosphere | 80.29±3.71 | 78.86±4.86 | 77.33±9.00 | 72.29±7.65 | 63.57±2.14 | 72.00±5.58 |
| Abalone | 51.74±0.99 | 51.10±0.67 | 51.38±1.20 | 50.97±1.09 | 49.22±1.46 | 50.13±2.21 |
| Breast cancer coimbra | 57.83±11.18 | 57.39±6.96 | 56.96±13.81 | 52.17±11.50 | 51.30±13.16 | 56.52±9.25 |
| Image segmentation | 69.52±2.75 | 67.89±3.46 | 68.21±2.76 | 55.22±6.86 | 58.10±6.76 | 64.98±3.85 |
| 注:加粗部分表示实验效果最好 | ||||||
| % | |||||
| Dataset | NB | SNBST | NSNB | SMUCST | KNNNB |
| Seeds | 4.285 7 | 6.904 7 | 0.476 1 | 0.952 3 | 11.547 6 |
| Iris | 4.000 0 | 5.666 6 | 3.000 0 | 24.666 6 | 16.500 0 |
| User knowledge modeling | -8.076 9 | -0.384 6 | -10.961 5 | 11.730 8 | 25.000 0 |
| Wine | 19.166 7 | 6.111 1 | 5.555 5 | 16.111 1 | 32.777 8 |
| Pima | 2.056 3 | 3.571 5 | 5.519 5 | 1.190 5 | 7.013 0 |
| Lonosphere | 1.428 6 | 2.952 4 | 8.000 0 | 16.714 3 | 8.285 7 |
| Abalone | 0.638 7 | 0.359 3 | 0.766 4 | 2.516 5 | 1.604 8 |
| Breast cancer coimbra | 0.434 8 | 0.869 6 | 5.652 2 | 6.521 8 | 1.304 4 |
| Image segmentation | 1.634 9 | 1.317 5 | 14.301 6 | 11.428 6 | 4.547 6 |
如表 3所示, 当有标记样本比例为10%时, WKNNNBST算法性能整体上优于对比算法, WKNNSNBST算法在数据集Seeds、Iris、User knowledge modeling、Wine、Abalone、Breast cancer coimbra以及Image segmentation上的正确率均高于其余算法。但在数据集User knowledge modeling上, 本文算法相对与对比算法表现较差, 这主要是因为该数据集自身性质所决定的, 其属性值本身很小, 且属性值之间的差距不大, 当WKNN在计算已标记样本与未标记样本之间的欧氏距离差值过小, 导致类别之间的区分度不大, 影响了最后的分类正确率。
如表 4所示, 当有标记样本比例为10%时, WKNNNBST算法的正确率较其他5个算法整体有提升。可在数据集User knowledge modeling上, 本文算法的正确率却不如NB、SNBST以及NSNB, 这主要是因为属性值过小, 导致WKNN计算属性值之间距离时区分不明显, 使得WKNN很难有效的辅助朴素贝叶斯自训练, 从而降低了算法性能。
为了说明初始有标记样本数对算法的影响, 图 2给出了当初始化有标记样本比例分别为10%、20%、30%、40%以及50%的时候, 做十折交叉验证, 6个算法在9个数据集上的平均分类正确率。
从图 2可以看出, 本文算法在9个数据集上整体优于对比算法, 尤其是在Iris、Wine、Pima、Lono- sphere以及Image segmentation这5个数据集上, 该算法在有标记样本比例极少的情况下正确率较高于其他算法。这是因为本文算法在选择未标记样本时先用加权KNN选出了空间结构上离有标记样本更近的数据, 在此基础上用朴素贝叶斯分类器选取更高置信度的可靠样本加入训练集, 解决了部分样本被误标记的问题, 从而提高了分类正确率。但随着有标记样本比例的增加, 本文算法与对比算法正确率整体趋于稳定, 可以看出在有标记样本足够多的情况下, 样本所含信息量越大, 算法的性能相对也更好。但算法SMUCST在数据集Iris、User knowledge modeling、Wine以及Lonosphere上正确率相对较低, 这可能因为这些数据属性之间相关性较弱, 导致正确率降低。而算法NB、NBST、NSNB、KNNNB以及WKNNNBST都有涉及到朴素贝叶斯分类器, 该分类器对样本属性之间关联不强的数据集有更好的表现力。从图 2中还可以看出在数据集Iris、User knowledge modeling以及Pima上用半监督KNNNB算法计算得出的正确率相对较低, 这不仅与数据集本身的特点有关, 也与KNN算法的特性有关的, 该算法只计算"最近的"邻居样本, 某一类的样本数量很大时, 输入新样本邻居中大容量类的样本占多数, 这就容易导致最终分类出错。因此, 本文选取不易受不平衡样本影响的加权KNN进行实验。观察图 2可发现, 在初始有标记样本占比逐渐增加时本文算法与对比算法的准确度整体上越来越接近, 这是因为当有标记样本数量足够的情况下, 以上所有算法的准确度会逐渐趋于稳定。本文算法主要运用于半监督学习, 半监督学习是基于有标记样本缺失较多的情况下提出的。因此, 本文算法更利于在有标记样本极其缺失的环境中进行分类, 对比实验证实了本文提出的分类算法在各个数据集上均占有一定优势。

|
| 图 2 平均分类正确率与有标记样本比例的关系 Fig. 2 The relationship between the average classification accuracy and the proportion of labeled samples |
传统朴素贝叶斯自训练算法是根据以往的经验和分析得出的先验概率来决定后验的概率, 从而得到样本所属类别置信度, 这就容易导致分类决策存在一定的错误, 且整个过程并未利用到训练样本空间结构所包含的信息。针对以上问题, 本文提出了基于加权KNN改进朴素贝叶斯自训练的算法。该算法充分地利用了样本的空间结构信息, 使传统朴素贝叶斯分类器在一个较好的空间结构上对未标记样本进行分类, 确保了每次添加的都为更高质量的样本, 减少迭代过程中的错误累积。在UCI及Kaggle数据集上的对比实验证实了本文提出的算法性能优于其他对比算法。在后续工作中, 将讨论如何通过多个分类器共同对未标记样本分类, 从而选取分类都正确的样本来扩充训练集的问题, 以及如何对大量数据更多分类的样本进行准确分类的问题。
| [1] |
HADY M F A, SCHWENKER F. Semi-supervised learning[J]. Journal of the Royal Statistical Society, 2013, 172(2): 219-235. DOI:10.1007/978-3-642-36657-4_7 |
| [2] |
RASMUS A, VALPOLA H, HONKALA M, et al. Semi-supervised learning with ladder networks[J]. Computer Science, 2015, 9(Suppl 1): 1-9. |
| [3] |
PIROONSUP N, SINTHUPINYO S. Analysis of training data using clustering to improve semi-supervised self-training[J]. Knowledge-Based Systems, 2018, 143(2): 65-80. |
| [4] |
TRIGUERO I, EZ J, LUENGO J, et al. On the charac-terization of noise filters for self-training semi-supervised in nearest neighbor classification[J]. Neurocomputing, 2014, 132(13): 30-41. |
| [5] |
GARLA V, TAYLOR C, BRANDT C. Semi-supervised clinical text classification with Laplacian SVMs:An application to cancer case management[J]. Journal of Biomedical Informatics, 2013, 46(5): 869. DOI:10.1016/j.jbi.2013.06.014 |
| [6] |
PROKOPIOU K, KAVALLIERATOU E, STAMATATOS E.An image processing self-training system for ruling line re-moval algorithms[C]//2013 18th International Conference on Digital Signal Processing (DSP).Washington: IEEE, 2014: 1-6.DOI: 10.1109/ICDSP.2013.6622767.
|
| [7] |
OTSU K, ONO M, FUCHS T J, et al. Autonomous terrain classification with co-and self-training approach[J]. IEEE Robotics & Automation Letters, 2016, 1(2): 814-819. |
| [8] |
WANG S, WU L S, JIAO L C, et al. Improve the performance of cotraining by committee with refinement of class probability estimations[J]. Neurocomputing, 2014, 136(8): 30-40. |
| [9] |
TAHERI S, YEARWOOD J, MAMMADOV M, et al. Attribute weighted naive Bayes classifier using a local optimization[J]. Neural Computing & Applications, 2014, 24(5): 995-1002. |
| [10] |
董立岩, 隋鹏, 孙鹏, 等. 基于半监督学习的朴素贝叶斯分类新算法[J]. 吉林大学学报(工学版), 2016, 46(3): 884-889. DONG L Y, SUI P, SUN P, et al. A new naive Bayes classification algorithm based on semi-supervised learning[J]. Journal of Jilin University(Engineering Edition), 2016, 46(3): 884-889. DOI:10.13229/j.cnki.jdxb-gxb201603031(Ch) (Ch). |
| [11] |
张维, 苗夺谦, 李峰, 等. WilsonTh数据剪辑在邻域粗糙协同分类中的应用[J]. 计算机科学与探索, 2014, 8(9): 1092-1100. ZHANG W, MIAO D Q, LI F, et al. Application of WilsonTh data clip in neighborhood rough collaborative classification[J]. Computer Engineering and Applications, 2014, 8(9): 1092-1100. DOI:10.3778/j.issn.1673-9418.1406026(Ch) (Ch). |
| [12] |
GAN H T, SANG N, HUANG R, et al. Using clustering analysis to improve semi-supervised classification[J]. Neurocomputing, 2013, 101(3): 290-298. |
| [13] |
吕佳, 黎隽男. 结合半监督聚类和数据剪辑的自训练方法[J]. 计算机应用, 2018, 38(1): 110-115. LÜ J, LI J N. Self-training method combining semisupervised clustering and data editing[J]. Computer Application, 2018, 38(1): 110-115. DOI:10.11772/j.issn.1001-9081.2017071721 (Ch). |
| [14] |
KARLOS S, FAZAKIS N, PANAGOPOULOU A P, et al. Locally application of naive Bayes for self-training[J]. Evolving Systems, 2016, 8(1): 1-16. DOI:10.1007/s12530-016-9159-3 |
| [15] |
BIAU G, CHAZAL F, Cohen-Steiner D, et al. A weighted K-nearest neighbor density estimate for geometric inference[J]. Electronic Journal of Statistics, 2014, 5(2): 204-237. |
| [16] |
YAN X. Weighted K-nearest neighbor classification algorithm based on genetic algorithm[J]. Telkomnika Indonesian Journal of Electrical Engineering, 2013, 11(10): 6173-6178. |
| [17] |
HUAI M, HUANG L S, YANG W, et al.Privacy-preserving naive Bayes classification[C]//International Conference on Knowledge Science, Engineering and Management (LNCS 9403).Cham: Springer, 2015: 627-638.DOI: 10.1007/s00778-006-0041-y.
|
| [18] |
TANHA J, SOMEREN M V, AFSARMANESH H. Semisupervised self-training for decision tree classifiers[J]. International Journal of Machine Learning & Cybernetics, 2017, 8(1): 355-370. DOI:10.1007/s13042-015-0328-7 |
| [19] |
陈日新, 朱明旱. 半监督K近邻分类方法[J]. 中国图象图形学报, 2013, 18(2): 195-200. CHEN R X, ZHU M H. Semi-supervised K-nearest neighbor classification method[J]. Chinese Journal of Image and Graphics, 2013, 18(2): 195-200. (Ch). |