
Application of convolutional neural networks in image super-resolution
-
摘要: 卷积神经网络因强大的学习能力,已成为解决图像超分辨问题的主流方法。然而,用于解决图像超分辨的不同类型深度学习方法存在巨大的差异。目前,仅有少量文献能根据不同缩放方法来总结不同深度学习技术在图像超分辨上的区别和联系。因此,根据设备的负载能力和执行速度等介绍面向图像超分辨方法的卷积神经网络尤为重要。本文首先介绍面向图像超分辨的卷积神经网络基础,随后通过介绍基于双三次插值、最近邻插值、双线性插值、转置卷积、亚像素层、元上采样的卷积神经网络的图像超分辨方法,分析基于插值和模块化的卷积神经网络图像超分辨方法的区别与联系,并通过实验比较这些方法的性能。本文对潜在的研究方向和挑战进行阐述并总结全文,旨在促进基于卷积神经网络的图像超分辨研究的发展。Abstract: Known for their strong learning abilities, convolutional neural networks (CNNs) have become mainstream methods for image super-resolution. However, substantial differences exist among deep learning methods of various types, and there is limited literature to summarize the relations and differences of different methods in image super-resolution. Thus, it is important to summarize such studies according to the loading capacity and the execution speed of devices. This paper first introduces the principles of CNNs in image super-resolution and then introduces CNN-based bicubic interpolation, nearest neighbor interpolation, bilinear interpolation, transposed convolution, subpixel layering, and meta-upsampling for image super-resolution to analyze the differences and relations of different CNN-based interpolations and modules. The performance of these methods is compared through experiments. Finally, this paper presents potential research points and drawbacks and summarizes the whole paper to promote the development of CNNs in image super-resolution.
-
图像超分辨(super-resolution, SR)能通过机器学习方法将低分辨率(low-resolution, LR)图像重建成具有丰富细节信息和清晰纹理的高分辨率(high-resolution, HR)图像[1]。它通过提高图像质量来提高目标检测、图像分类等众多上层计算机视觉任务的性能,为卫星遥感、公共安防[2]和视频感知[3]等领域提供助力。
早期的图像超分辨方法如图像插值方法[4]、基于稀疏表示方法、基于局部嵌入方法、基于退化模型方法[5]等主要通过图像中像素之间的关系,提升图像的质量。其中,基于图像插值方法是简单和容易实现的,但无法很好地恢复高频信息和纹理特征[6]。为了解决此问题,基于稀疏表示方法利用图像集来训练字典,获得高分辨率图像[7]。虽然该方法在一定程度上能恢复图像细节信息,但仍会出现锯齿状问题[8]。为了获得更多图像细节信息,基于局部嵌入方法通过流形学习中局部线性嵌入K近邻算法来提高图像的像素质量。随后,学者通过高分辨率(HR)和低分辨率(LR)图像间的退化关系进行建模,并通过优化目标函数与解函数重建HR图像[8]。例如,迭代反投影法[9]、凸集投影法[10]等方法均从退化模型的角度出发,利用投影获得更准确的参数、恢复更多图像细节和加快恢复高质量图像的速度[11-12]。为了提取更多的LR图像关键信息,优化退化关系,更多机器学习方法被用来学习对应的高频信息[13]。这些图像超分辨方法,结合有限的图像信息,获得高质量图像,不仅推动图像超分辨领域的发展[13],也为智能交通和人脸识别[14]等计算机视觉应用提供有价值的方案。但是这些方法需要手动设置参数和优化方法等,影响图像超分辨任务的效率[15]。
为了解决这些问题,具有强大学习能力的深度学习技术被用来解决图像超分辨。例如:Dong等[16]用端到端结构解决图像超分辨问题。具体为:它通过三层卷积结构把低分辨率图像以像素形式映射到高分辨率图像, 该方法称为超分辨率卷积神经网络(super-resolution convolutional neural network, SRCNN)[16]。虽然SRCNN在图像超分辨性能上明显超过传统的图像超分辨方法,但SRCNN可扩展性差和特征维数过少,导致它没有被推广应用[17]。随后,Dong等[18]提出快速的超分辨率卷积神经网络(fast super-resolution convolutional neural network, FSRCNN)来优化SRCNN模型,加快图像超分辨模型的训练效率。FSRCNN主要通过深层的反卷积操作放大图像来代替图像预处理的双三次插值等操作,降低训练过程的效率。此外,FSRCNN使用更小的卷积核和更多的映射层处理,改变特征维数并获得图像特征,提高图像质量。由于深度网络具有较深的特征提取能力和残差学习操作具有较强的浅层特征传递能力,残差卷积神经网络用来解决图像超分辨。例如:Kim等[17]将残差学习操作用到卷积神经网络的末端构造深度超分辨率卷积神经网络(very deep super-resolution convolutional network, VDSR)提升预测图像的质量。此外递归网络通过递归连接卷积层不仅控制参数量,还能增强网络的表达能力,加快模型训练速度,提高图像重建效果[19-20]。为了增强网络的深度学习特征能力,密集连接融合网络的层次特征,增强模型的信号传播和特征重用能力,获得更多的图像细节信息,提升图像复原的质量[21-22],Zhang等[22]利用当前层与所有后层进行相连,增强深度网络的记忆能力,提高图像超分辨的性能。该方法不仅能防止深度网络的梯度消失或爆炸现象的出现,还能大大地提升获得图像的清晰度。为了提高图像超分辨的速度,注意力机制利用当前层引导之前层来获得显著性特征,加快图像重建效率。例如,Zhang等[23]利用残差网络结构和通道注意力提取丰富的高频和低频信息,这不仅能解决深度网络难训练问题,还能增强图像超分辨的效果。Dai等[24]利用二阶特征统计来自适应地重新缩放通道特征实现二阶注意力网络(second-order attention network, SAN),增强网络的判别能力,提高预测图像的清晰度。为了解决样本不足问题,生成对抗网络利用博弈思想设计生成器和判别器,建立图像超分辨模型。其中,生成器用于生成重建图像,判别器用于判断生成图像与真实图像的差距,通过二者的博弈来提高图像超分辨的性能。例如Ledig等[25]利用感知损失函数来训练生成对抗网络(super-resolution generative adversarial network, SRGAN),获得更多的纹理信息,增强预测图像的质量。为了解决伪影问题,Wang等[26]利用没有批量标准化的残差密集块改进网络,并使用激活前的特征来改进感知损失,从而提高恢复图像的质量。为了同时获得更优的视觉效果,王凡超等[27]组合感知损失和对抗损失来提高特征重构能力。
尽管卷积神经网络在图像超分辨上有很多研究[28],但很少有相关文献系统地阐述图像超分辨领域中不同卷积神经网络的区别与联系。本文首先回顾了图像超分辨从传统方法到深度学习方法的发展历史,搜集整理了多个超分辨技术框架,分析总结了近百种不同角度、不同思路的超分辨方法,并通过系统性的对比研究,展示了它们的性能、优缺点、复杂性、挑战和潜在的研究要点等。具体为:本文首先介绍了图像超分辨技术近年来的发展状况,概述了从传统的图像超分辨方法到基于卷积神经网络的图像超分辨方法的演进过程。第二,本文从技术前身、基本原理与实际效果等角度,完整介绍了基于卷积神经网络图像超分辨率方法的经典网络框架。第三,根据不同的技术原理,本文将面向图像超分辨的卷积神经网络划分为两类,包括基于插值和基于模块化的卷积神经网络图像超分辨方法,并分析了用于非盲图像超分辨与盲超分辨的卷积神经网络的动机、实现、性能与差异。 第四,本文定性和定量分析这些算法在图像超分辨公共数据集上的性能。最后,本文指出了卷积神经网络在图像超分辨领域面临的挑战与未来发展方向。
1. 面向图像超分辨的卷积神经网络的主流框架
尽管传统机器学习的图像处理方法可以利用先验知识提高图像超分辨的处理速度,但仍存在两点不足[29]:1)机器学习方法需要手动设置参数;2)需要通过复杂的优化算法来优化参数[30]。针对上述问题,基于深度学习的图像处理方法被提出。它依靠深度的网络结构,能自动学习图像特征,这不仅能避免手动设置参数和优化参数的使用,而且已广泛应用在图像分类、图像修复和图像超分辨率等图像处理任务中[31]。本文的总体结构如图1所示。
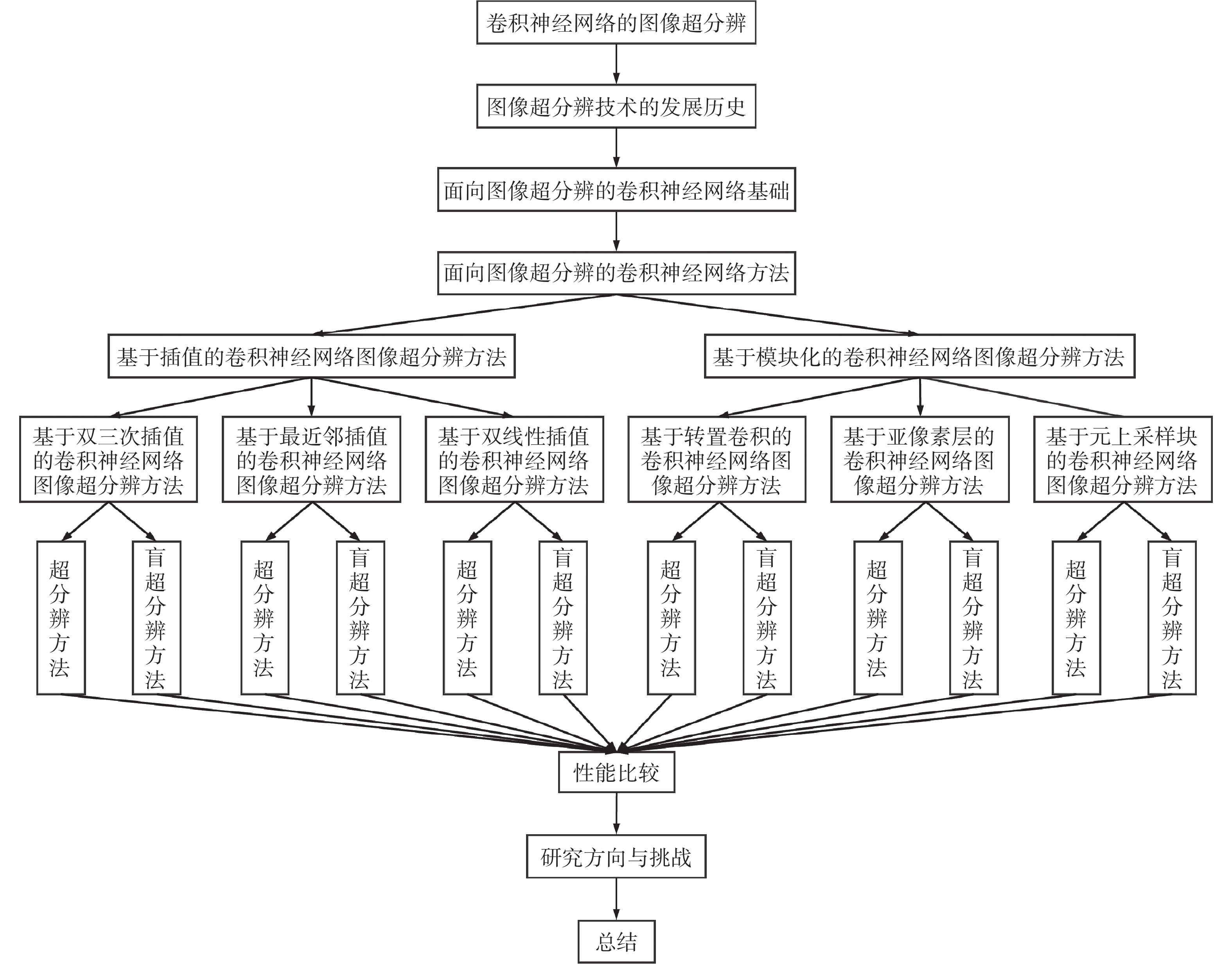 图 1 综述结构Fig. 1 Structure of the review
图 1 综述结构Fig. 1 Structure of the review 下载:
全尺寸图片
下载:
全尺寸图片
本节通过介绍6种图像超分辨领域的经典网络框架:超分辨率卷积神经网络(SRCNN)[16]、极深图像超分辨卷积网络(VDSR)[17]、深度递归卷积网络(deeply-recursive convolutional network, DRCN)[20]、快速超分辨率卷积神经网络(FSRCNN)[18]、 超分辨率密集网络(super-resolution dense network, SRDenseNet)[21]和残差密集网络(residual dense network, RDN)[22]来了解基于深度学习的图像超分辨方面的研究,这是本文针对卷积神经网络的图像超分辨技术进行讨论与研究的基础。
为了提升图像超分辨的效果,Dong等[16]利用3层卷积,提出了端到端的图像超分辨卷积神经网络SRCNN,其网络结构如图2所示。该模型可以直接学习LR和HR之间的端到端映射,并将这种映射表示为以LR图像为输入,HR图像为输出的深度卷积神经网络。与传统方法相比,该模型不仅能自动地学习参数,还使模型具有好的图像超分辨性能。该网络的具体实现为:SRCNN模型包括1个预处理操作和3个卷积层。首先,预处理操作对输入的LR图像进行双三次插值操作,通过上采样获得与目标相同大小的输入图像。其次,第一卷积层从LR图像中提取特征。第二卷积层将这些特征非线性地映射到HR的表示块中,获得高频特征[1]。最后,第三卷积层将获得高频特征图放在一个空间区域中,生成最终的HR图像。轻量化的结构、较高的执行效率、较强的鲁棒性,促使其实际效果优于传统的图像超分辨技术,这不仅是卷积神经网络在图像超分辨领域应用的基石,而且为该领域的不断发展提供了方向和框架[16]。
 图 2 SRCNN的网络结构Fig. 2 Network structure of SRCNN下载:
全尺寸图片
图 2 SRCNN的网络结构Fig. 2 Network structure of SRCNN下载:
全尺寸图片
SRCNN虽然成功地将深度学习技术引入到图像超分辨率上,但该方法存在两方面局限性:1)SRCNN模型训练收敛太慢;2)SRCNN模型只适用于复原固定尺寸的图像[17]。为解决上述缺陷,Kim等[17] 通过使用深度网络结构中的多次级联小滤波器提出了VDSR模型,提升图像超分辨的性能。受VGG[32]的启发,VDSR也采用
$ 3 \times 3 $ 的级联小滤波器来高效地提取图像特征,提高图像的分辨率[1]。为缓解梯度爆炸和梯度消失问题,VDSR使用了梯度剪裁和残差学习操作。20层的VDSR模型恢复高分辨率图像的流程为:首先,VDSR通过双三次插值操作放大输入图像,使其与参考图像相同尺寸;其次,使用19个堆积的卷积层来提取图像特征;最后,通过一层卷积来重建图像,获得高质量图像。其中,所有卷积核为$ 3 \times 3 $ ,第一层的输入通道为3,最后一层的输出通道为3,其余层的输入和输出通道都为64。VDSR的网络结构如图3所示。 图 3 VDSR的网络结构Fig. 3 Network structure of VDSR下载:
全尺寸图片
图 3 VDSR的网络结构Fig. 3 Network structure of VDSR下载:
全尺寸图片
虽然通过增加网络层数能提高图像超分辨的性能,但深度网络中浅层对深层作用会减少,这会导致模型收敛需要更多的训练数据[20]。为了克服这个挑战,Kim等[20]采用递归操作改进VDSR实现DRCN图像超分辨网络,这不仅能降低梯度爆炸和梯度消失的影响,同时还能提升图像超分辨网络的表达能力。此外,将跳跃连接融合到网络中,加强浅层对深层的作用,增强网络的学习能力。例如,DRCN采用感受野为
$ 41 \times 41 $ 的单卷积层作为递归单元,学习更精准的图像特征;并通过将每个递归单元的中间结果输入到重构模块,生成HR特征图来重建高分辨率图像。其中,递归单元后的一层卷积核为$ 9 \times 9 $ ,其余所有卷积核均为$ 3 \times 3 $ ,输入与输出的通道数均与VDSR一致。DRCN的网络结构如图4所示。 图 4 DRCN的网络结构Fig. 4 Network structure of DRCN下载:
全尺寸图片
图 4 DRCN的网络结构Fig. 4 Network structure of DRCN下载:
全尺寸图片
DRCN虽然将多重监督与递归单元结合在一起,在不引入大量参数的情况下,学习到更高层次的图像特征,但模型内部依然存在如下缺陷[18]:1)采用双三次插值对图像预处理时,模型计算复杂度随高分辨率图像的空间大小呈二次增长。2)模型非线性映射时,输入图像块依次被投影到高维的LR与HR特征空间中,该过程计算昂贵且效率低下。为解决上述缺陷,Dong等[18]提出了一种更简洁高效的网络结构FSRCNN。该网络主要从3个方面改进超分辨模型:首先,在网络末端引入反卷积层,避免双三次插值的使用,这能直接从原始LR图像学习到HR图像的映射;其次,通过在映射前缩小输入特征维度,映射后再展开特征的方法来改进映射层,降低计算成本;3)采用更小的过滤器尺寸,提高图像超分辨效率[1],FSRCNN的网络结构如图5所示。
 图 5 FSRCNN的网络结构Fig. 5 Network structure of FSRCNN下载:
全尺寸图片
图 5 FSRCNN的网络结构Fig. 5 Network structure of FSRCNN下载:
全尺寸图片
尽管FSRCNN能降低模型的计算成本并提高了图像超分辨的质量,但在模型训练时,梯度消失与梯度爆炸的问题依然存在。随着卷积神经网络的设计趋于复杂化,模型的训练效率不断降低[21]。针对这一问题,Tong等[21]提出了一种新颖的图像超分辨率方法,使用密集跳跃连接的图像超分辨网络(SRDenseNet)。为了缓解梯度消失与梯度爆炸的问题,SRDenseNet首先采用密集跳跃连接操作嵌入到卷积神经网络中,有效结合低级特征与高级特征,改善网络中的信息流动[1]。为了降低训练复杂度,SRDenseNet在特征提取时,允许模型重用前层特征映射信息,避免重复学习冗余特征,完成高分辨图像的重建。SRDenseNet模型恢复HR图像的流程为:输入图像依次通过卷积层学习低级特征、密集网络块学习高级特征、反卷积层学习上采样滤波器、重构层生成高分辨率的输出图像[22]。SRDenseNet的网络结构如图6所示。
 图 6 SRDenseNet的网络结构Fig. 6 Network structure of SRDenseNet下载:
全尺寸图片
图 6 SRDenseNet的网络结构Fig. 6 Network structure of SRDenseNet下载:
全尺寸图片
随着网络深度的不断增加,SRDenseNet引入的密集块虽然利用了低级和高级特征信息提高模型训练效率,但原始低分辨率图像的分层特征利用率不足,图像重建质量有待提高。为解决这一问题,Zhang等[22]提出了RDN。RDN中的残差密集块(residual dense block, RDB)利用局部密集连接,结合网络所有层的特征信息,有效地提高了图像特征的利用率与图像超分辨效果。RDN模型的图像超分辨流程为:首先,输入图像通过卷积层来获得浅层的特征;随后,输入3个连续的RDB来提取深层特征;其次,利用密集操作融合网络中,结合网络内部所有层获取的特征信息,通过局部特征融合自适应增强特征;最后,使用反卷积和上采样操作得到高分辨率图像。其中,RDN和RDB的网络结构如图7和8所示。
 图 7 RDN的网络结构Fig. 7 Network structure of RDN下载:
全尺寸图片
图 7 RDN的网络结构Fig. 7 Network structure of RDN下载:
全尺寸图片
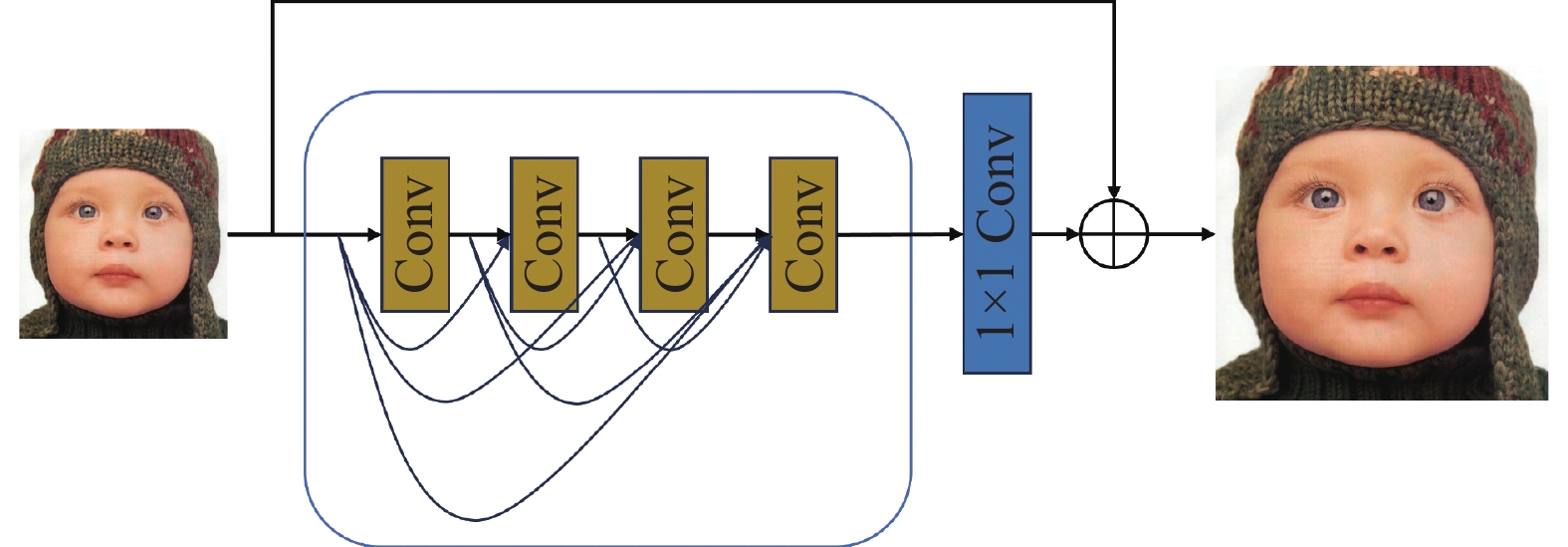 图 8 RDB的网络结构Fig. 8 Network structure of RDB下载:
全尺寸图片
图 8 RDB的网络结构Fig. 8 Network structure of RDB下载:
全尺寸图片
2. 面向图像超分辨的卷积神经网络方法
第1章按照技术演进的历程,已详细地介绍了一些面向图像超分辨的卷积神经网络的主流框架。为进一步了解卷积神经网络在图像超分辨领域的发展与应用,本章将已有方法划分为基于插值方法和基于模块化方法。分类依据为:插值算法是处理图像超分辨方法的经典技术,它能把低频信息转化到高频信息,是恢复高质量图像必不可少的一步。随着端到端的卷积神经网络出现,插值算法已被用在卷积神经网络前(在网络输入前利用插值算法放大低分辨率图像)或网络末端(在网络深层利用插值算法放大低分辨率图像),用于放大获得的低频信息,从而获得高清图像。然而,不同插值方法会影响图像超分辨方法复原高质量图像的性能,因此,本文将插值方法作为一种分类标准,并分为“双三次插值算法”“最近邻插值算法”“双线性插值算法”。由于标题字数关系,本文采用缩写,如“基于双三次插值的卷积神经网络算法”写成“双三次插值算法”、“基于最近邻插值的卷积神经网络算法”写成“最近邻插值算法”、“基于双线性插值的卷积神经网络算法”写成“双线性插值算法”。插值方法在放大图像时容易丢失细节信息,由于卷积神经网络在训练过程中具有动态学习参数的能力,因此,学者们将卷积和插值方法结合,提出了模块化方法以提高图像超分辨的鲁棒性。每种方法包括3种典型计算类型,按照图像退化类型是否已知,从图像超分辨与图像盲超分辨的角度,介绍了多种图像超分辨率经典算法、设计思路和实际应用。本章结构如图1所示。
2.1 基于插值的卷积神经网络图像超分辨方法
随着显示器等硬件设备的迅速发展,一张图像通常需要以不同的尺寸和不同的纵横比显示。插值操作是常见的缩放图像,可以根据待补充像素点的周围信息确定缺失像素。因此,将插值操作应用于神经网络的预上采样中,可以初步补充像素点,扩大待处理图像的分辨率和尺寸,使其与参考的图像具有相同大小。此外,通过修改输入图像的设置,如大小、分辨率及横纵比等,使卷积神经网络更容易建立输入图像与输出图像的映射[33]。因此,卷积神经网络在处理图像超分辨任务时会采用不同的图像插值技术[34],例如双三次插值[35]、最近邻插值[4]和双线性插值[36]等来缩放待处理的图像尺寸,使其与参考的图像具有相同的尺寸,从而利于训练图像超分辨模型。本节将基于插值的卷积神经网络图像超分辨方法,根据插值方法的不同分为3类:双三次插值算法、最近邻插值法和双线性插值法,并分别介绍它们在图像非盲和盲超分辨率任务上的应用,基于插值的卷积神经网络图像超分辨方法分类结构如图9所示。
 图 9 基于插值的卷积神经网络图像超分辨方法分类结构Fig. 9 Classification structure of interpolation-based convolutional neural network methods for image super-resolution下载:
全尺寸图片
图 9 基于插值的卷积神经网络图像超分辨方法分类结构Fig. 9 Classification structure of interpolation-based convolutional neural network methods for image super-resolution下载:
全尺寸图片
2.1.1 双三次插值算法
1) 基于双三次插值的卷积神经网络图像超分辨方法
双三次插值方法主要通过计算未知像素点周围16个像素的加权平均值,作为最终的插值结果。由于周围像素与未知像素的距离各不相同,像素距离越近,权重越高,因此该方法插值效果较好。
基于双三次插值方法原理,卷积神经网络将其用在图像超分辨上。具体流程为:首先利用双三次插值方法将低分辨率图像扩大成与参考的高质量图像相同尺寸大小的图像;其次,将上一步获得的图像输入卷积神经网络以预测对应的高质量图像。例如:Dong等[16]采用双三次插值操作预处理给出的低分辨率图像,并通过三层卷积神经网络以像素点的方式映射得到高质量图像。虽然该方法在图像超分辨上比传统的机器学习方法获得更有效的效果,但该网络可扩展性差,其性能随着网络深度增加而下降。为克服这些缺点,VDSR采用更小的卷积核以堆积的方式增大网络深度,扩大感受野信息,提取更多的上下文信息。并通过残差操作来增强浅层特征的作用,提升图像超分辨的性能[37]。为充分利用网络的结构信息,Ren等[38]通过增加网络宽度扩大感受野,实现了基于上下文网络融合的卷积神经网络图像超分辨方法(context-wise network fusion, CNF),提高恢复图像的质量。其中,CNF通过并行3个不同层数的SRCNN获得3幅不同的高质量图像,融合它们能获得重建图像[39]。为获得互补的信息,Hu等[40]提出级联多尺度交叉卷积神经网络(cascaded multi-scale cross, CMSC)。CMSC采用双三次插值来放大低分辨率图像,使其与参考图像具有相同的大小;随后,采用级联子网络以由粗到细的方式学习精准的高频特征;为了增强网络的表达能力,将残差学习操作融合到CMSC中;最后,采用多尺度交叉模块提取互补的多尺度信息,保证提取特征的鲁棒性,提高图像超分辨率的性能。为降低计算代价,Yamanaka等[41]提出了基于残差学习跳跃连接的深度卷积神经网络(deep CNN with residual net, skip connection and network, DCSCN)。DCSCN将跳连接嵌入到深度网络中,提取局部和全局的图像特征;为减少网络的复杂度,采用两个
$ 1 \times 1 $ 卷积对获得特征进行降维,最后通过一个$ 3 \times 3 $ 的卷积进行重构和获得预测的HR图像。尽管上述模型提高了模型训练效率,但仍然存在如下问题:LR图像的层次特征利用不足、模型过大等。为提高图像特征利用率,RDN利用RDB实现图像局部特征抽取、全局特征融合,充分利用了LR图像的多层次特征。而为了解决上述模型由于层数过多导致的模型过大问题(如过拟合、存储与检索困难等)[42]。DRCN率先将递归神经网络引入图像超分辨领域,通过卷积层间权重共享,在不增加额外参数的条件下,恢复了更多的图像信息,降低了梯度爆炸和梯度消失的影响。为了降低模型参数,提高训练效率,DRRN[43]在DRCN的基础上改进,不同于卷积层间共享权重,DRRN将多个残差单元组成递归块,在递归块间共享权重,显著提高图像复原精度,实现了深度而简洁的网络。同样利用残差学习提高图像质量的超分辨模型还包括增强的深度卷积神经网络(enhanced deep super-resolution network, EDSR)、多尺度深度卷积神经网络(multi-scale deep super-resolution system, MDSR)[44]、基于残差通道注意力的卷积神经网络(residual channel attention network, RCAN)[23]等。
为了解决深度网络容易出现梯度消失或梯度下降的难题,Tai等[39]提出基于记忆网络的卷积神经网络(memory network, MemNet)。MemNet利用连接操作将浅层信息传递到深层,这不仅能缓解深度网络中梯度消失或梯度爆炸问题,还能提高图像超分辨率效果[45]。Tian等[46]提出由粗到细卷积神经网络的图像超分辨方法(coarse-to-fine super-resolution CNN, CFSRCNN)。该方法分别提取低频和高频信息,并将连接和残差学习作用到网络的层次信息上,融合高频和低频信息,解决由深层上采样操作突然放大获得的特征,导致的网络训练困难问题。
为了解决真实世界的图像增强问题,Rad等[47]使用GAN实现了一个真实双三次超分辨率的卷积神经网络(real bicubic super-resolution, RBSR)。具体流程为:首先使用一个基于卷积神经网络的生成器将真实的低分辨率图像转换为类似于双三次下采样的低分辨率图像。随后,通过预训练的EDSR[44]网络作用在获得的低分辨率图像上,预测高质量图像。此外,基于数字高程模型的超分辨率生成对抗网络(digital elevation model-SRGAN, D-SRGAN)[48]和基于高分辨率表征学习的医学图像超分辨率生成对抗网络(GAN-based medical image SR network via HR representation learning, Med-SRNet) [49]能有效地获得图像的细节信息,提高真实图像的分辨率。为了方便读者理解不同超分辨方法的原理和区别,表1通过作者、方法、提出时间、应用和关键字来展示基于双三次插值的卷积神经网络图像超分辨方法。
表 1 基于双三次插值的卷积神经网络图像超分辨方法Table 1 Image super-resolution methods using convolutional neural networks based on bicubic interpolation作者 方法 提出时间 应用 关键字 Dong等 SRCNN[16] 2016年 图像超分辨 基于像素映射的卷积神经网络 Kim等 VDSR[17] 2016年 图像超分辨 深度的卷积神经网络 Ren等 CNF[38] 2017年 图像超分辨 基于上下文网络融合的卷积神经网络 Hu等 CMSC[40] 2018年 图像超分辨 级联多尺度交叉的卷积神经网络 Kim等 DRCN[20] 2016年 图像超分辨 基于深度递归的卷积神经网络 Tai等 DRRN[43] 2017年 图像超分辨 基于深度递归的残差卷积神经网络 Tai等 MemNet[39] 2017年 图像超分辨 基于记忆网络的卷积神经网络 Lim等 EDSR[44] 2017年 图像超分辨 增强的深度卷积神经网络 Lim等 MDSR[44] 2017年 图像超分辨 多尺度深度卷积神经网络 Wang等 ProSR[50] 2018年 图像超分辨 基于逐层上采样的卷积神经网络 Zhang等 RCAN[23] 2018年 图像超分辨 基于残差通道注意力的卷积神经网络 Ni等 CGDMSR[51] 2017年 图像超分辨 基于深色和彩色图像的卷积神经网络 Yamanaka等 DCSCN[41] 2017年 图像超分辨 基于残差学习的深度卷积神经网络 Han等 SSF-CNN[52] 2018年 图像超分辨 基于空间和光谱的卷积神经网络 Ledig等 SRGAN[25] 2017年 图像超分辨 生成对抗的网络 Wang等 LISTA[53] 2015年 图像超分辨 基于稀疏编码的卷积神经网络 Hui等 IDN[54] 2018年 图像超分辨 基于信息蒸馏的卷积神经网络 Tian等 CFSRCNN[46] 2020年 图像超分辨 由粗到细卷积神经网络 Rad等 RBSR[47] 2021年 图像超分辨 基于真实双三次超分辨率的卷积神经网络 Demiray等 D-SRGAN[48] 2021年 图像超分辨 基于数字高程模型的超分辨生成对抗网络 Zhang等 Med-SRNet[49] 2022年 图像超分辨 基于高分辨率表征学习的医学图像超分辨率生成对抗网络 2)基于双三次插值的卷积神经网络图像盲超分辨方法
大多数基于CNN的方法都通过已知先验来建立图像退化模型。然而,当真实捕获到图像的退化类型与预先假设不同时,图像复原方法的性能会降低。例如,为解决盲图像超分辨率中未知模糊核的估计问题,Yuan等[55]提出了基于循环−循环的生成对抗网络(cycle-in-cycle GAN, CinCGAN)。CinCGAN包含两个CycleGAN:第1个CycleGAN将各种降质因素的低分辨图像映射到干净的双三次下采样的低分辨率空间中,实现去噪和去模糊;随后,通过预训练的深度模型将中间结果上采样到所需的高分辨大小图像;最后,通过第2个GAN对第1个CycleGAN进行微调和优化,生成高质量高分辨的图像。为了更好地处理不同模糊核的低分辨图像,Maeda[56]通过改进CycleGAN实现了非成对的图像超分辨率卷积神经网络(unpaired image super-resolution, UISR)。UISR仅使用非配对的核/噪声校正网络来去除噪声和模糊核,生成干净的LR图像。为了重建高分辨率图像,该方法利用伪配对的超分辨率网络学习到从伪干净LR图像到原始高分辨率(HR)图像的映射,实现超分辨率图像重建功能。Zhang等[57]提出了深度即插即用的超分辨卷积神经网络(deep plug-and-play super-resolution, DPSR)。该方法通过设计一个新的图像超分辨率退化模型和利用半二次分裂算法优化能量函数,实现处理任意模糊核的低分辨率图像功能。为了提高模糊核的估计精度,Gu等[58]提出了基于迭代内核校正的卷积神经网络(iterative kernel correction, IKC)。IKC能根据已有的SR结果对估计核进行迭代修正,逐渐恢复逼近真实HR图像以去除因内核不匹配导致的图像伪影。但IKC只关注有限类型的模糊核与噪声,因此,该方法并不是完全意义上的图像盲超分辨率方法。
为了提高真实图像盲超分辨率方法的泛化性和鲁棒性,Zhou等[59]提出了内核建模超分辨率卷积神经网络(kernel modeling super-resolution, KMSR)。KMSR主要分为两个阶段:首先,使用生成对抗网络构建了一组真实的模糊核,随后使用生成的核构建了HR和相应的LR图像。之后,利用它们来训练超分辨率网络,提升了真实照片盲超分辨率方法的性能。为了处理复杂场景下真实图像的盲超分辨率,Kligler 等[60]提出了内核生成对抗网络方法,该方法仅利用LR图像进行训练(代替已知的先验知识),学习其内部的图像块分布来估计出模糊核,实现自适应的下采样操作,提高了盲超分辨模型的鲁棒性。针对真实世界中未知退化的图像超分辨问题,Wang等[61]提出基于退化感知的卷积神经网络超分辨方法(degradation-aware super-resolution, DASR)。DASR从退化表示中预测卷积核和信道级调制系数,增强图像超分辨模型的鲁棒性。为了更有效地处理不同退化情况下的图像超分辨问题,Zhang等[62]引入随机洗牌策略随机学习模糊、下采样和噪声,实现图像盲复原模型。为了提高真实图像的盲超分辨效率,Wang等[45]利用高阶退化引导GAN网络,实现图像盲超分辨模型。表2概述了更多基于双三次插值的卷积神经网络图像盲超分辨率方法。
表 2 基于双三次插值的卷积神经网络图像盲超分辨方法Table 2 Blind image super-resolution methods using convolutional neural networks based on bicubic interpolation作者 方法 提出时间 应用 关键词 Yuan等 CinCGAN[55] 2018年 图像盲超分辨 基于循环中循环的生成对抗网络 Maeda等 UISR[56] 2020年 图像盲超分辨 非成对图像生成对抗网络 Zhang等 DPSR[57] 2019年 图像盲超分辨 深度即插即用超分辨卷积神经网络 Gu等 IKC[58] 2019年 图像盲超分辨 基于迭代内核校正的卷积神经网络 Zhou等 KMSR[59] 2019年 图像盲超分辨 内核建模卷积神经网络 Kligler等 KernelGAN[60] 2019年 图像盲超分辨 内核生成对抗网络 Wang等 DASR[61] 2021年 图像盲超分辨 基于退化感知的超分辨率卷积神经网络 Zhang等 Blind ESRGAN[62] 2021年 图像盲超分辨 增强的盲超分辨卷积神经网络 Wang等 Real ESRGAN[45] 2021年 图像盲超分辨 增强的真实图像超分辨卷积神经网络 Zhang等 CRL-SR[63] 2021年 图像盲超分辨 基于对比表示学习的盲图像超分辨率卷积神经网络 Wu等 CDCN[64] 2022年 图像盲超分辨 基于组件分解与协同优化的卷积神经网络 Cao等 PCNet[65] 2021年 图像盲超分辨 基于先验校正网络的盲超分辨率卷积神经网络 Yamawaki等 BSR-DUL[66] 2021年 图像盲超分辨 基于联合优化策略的盲超分辨率卷积神经网络 Yamawaki等 DIP[67] 2021年 图像盲超分辨 基于可学习退化模型的盲无监督学习卷积神经网络 2.1.2 最近邻插值算法
1)基于最近邻插值的卷积神经网络图像超分辨方法
最近邻插值算法通过直接选择待插入点最近的相邻像素作为插入点的像素值来完成插值操作,完成图像超分辨任务[4]。虽然该方法能在一定程度上提高计算速度,但该过程仅复制已有的像素值,这会导致在放大图像时失真较为严重。该算法与其他插值算法相比,思想最简单,计算速度最快,也更容易实现,因此它已广泛应用于卷积神经网络中解决图像超分辨问题[68]。
早期的卷积神经网络通过反卷积实现把低频特征转为高频特征,从而获得高质量图像。其中,反卷积层是基于最近邻近插值算法实现的[18],例如, FSRCNN利用深层的反卷积层从获得LR特征图转化为SR特征图,重构高质量图像[18]。为了提高图像超分辨模型的适应能力,Zhang等[69]提出超分辨卷积神经网络(unfolding super-resolution network, USRNet)。USRNet通过半二次分裂算法展开MAP推理,得到固定次数的迭代计算,用于交替求解一个数据子问题和一个先验子问题;随后,这两个子问题由神经模块解决,得到一个端到端的迭代网络。为了降低计算成本和模型复杂度, Fan等[70]通过深度约束的残差设计提出基于平衡两阶段残差的卷积神经网络(balanced two-stage residual networks, BT-SRN),在图像超分辨任务中性能与效率均取得好的效果。为了防止峰值信噪比不能全面地衡量图像质量的问题,Sajjadi等[71]提出了增强网络(EnhanceNet),该网络采用对抗训练,并通过结合像素级损失、感知损失和纹理匹配损失生成高质量、具有逼真纹理的超分辨率图像。
为了减少超分辨图像中的伪影以及失真细节,增强型超分辨率生成对抗网络(enhanced super-resolution generative adversarial networks, ESRGAN)[26]引入残差密集块和相对平均鉴别器,并改进感知损失和对抗性训练来改进SRGAN网络,解决图像超分辨问题。其中,残差密集块增加了网络中层次之间的关系,增强深度网络的结构信息;其次,在权重初始化过程中采用了更小的初始化值来提高深度网络训练的稳定性;最后,考虑到当前生成图像的真实度,使用相对均值鉴别器来增加生成图像的更多真实细节信息,这能减少生成图像与平均真实图像之间的相对差异,使其更加符合人类视觉感知。由于不同图像的纹理细节差异较大,图像超分辨率方法很难提取不同图像中的细节信息。为了解决这个问题,Shang等[72]提出了基于感受野块的增强超分辨率生成对抗网络(super resolution network with receptive field block based on Enhanced SRGAN, RFB-ESRGAN)。RFB-ESRGAN利用小卷积核代替大卷积核提取不同尺度的特征信息进而提取更多细节信息,获得更多图像细节,提高图像超分辨性能。最后,该网络交替使用侧重于空间维度的最近邻插值和侧重于深层维度的亚像素卷积执行上采样,实现深层信息和空间信息充分交流,达到生成更多图像细节的效果。为了降低模型复杂度, Zhao等[73]提出了像素注意力卷积神经网络(pixel attention network, PAN)。PAN利用像素级注意力模块对输入特征图以加权的方式来突出关键像素,抑制无关信息,并结合残差块和多尺度特征融合,优化网络结构,在减少计算复杂度的同时提升图像超分辨性能。表3 给出了更多基于最近邻插值的卷积神经网络图像超分辨方法。
表 3 基于最近邻插值的卷积神经网络图像超分辨方法Table 3 Image super-resolution methods using convolutional neural networks based on nearest neighbor interpolation作者 方法 提出时间 应用 关键词 Dong等 FSRCNN[18] 2016年 图像超分辨 快速超分辨卷积神经网络 Zhang等 USRNet[69] 2020年 图像超分辨 展开超分辨率卷积神经网络 Fan等 BT-SRN[70] 2017年 图像超分辨 基于平衡两阶段残差的卷积神经网络 Sajjadi等 EnhanceNet[71] 2017年 图像超分辨 基于感知损失、对抗损失和纹理损失的增强卷积神经网络 Wang等 ESRGAN[26] 2019年 图像超分辨 增强的超分辨率生成对抗网络 Shang等 RFB-ESRGAN[72] 2020年 图像超分辨 基于感受野块的增强超分辨率生成对抗网络 Zhao等 PAN[73] 2020年 图像超分辨 像素注意力卷积神经网络 Huang等 CCNet[74] 2019年 图像超分辨 基于跨尺度通信的卷积神经网络 Jo等 LUT[75] 2021年 图像超分辨 基于查找表的实用图像超分辨率卷积神经网络 2)基于最近邻插值的卷积神经网络图像盲超分辨方法
现有图像盲超分辨方法均基于模糊核具有空间不变性的假设,但由于物体运动和失焦等因素,模糊核通常是空间变化的,这些图像盲超分辨模型在实际应用中性能较差。为解决这个问题,Liang等[76]提出相互仿射的卷积神经网络(mutual affine network, MANet)。MANet引入一种全新的互仿射卷积层,使网络能在不增加感受野、模型大小和计算负担的前提下增强特征表达能力,使得图像超分辨模型在模糊核空间变化中展现了优秀的性能。表4给出了更多的基于最近邻插值的卷积神经网络图像盲超分辨方法。
2.1.3 双线性插值算法
1)基于双线性插值的卷积神经网络图像超分辨方法
双线性插值算法加权平均待插入点的4个邻域像素,计算最终插入值。具体而言,它在水平和垂直两个方向上分别计算插值权重,再结合4个邻域像素的值,从而得到插入点的估计值。最近邻方法没有考虑不同方向的信息,而双线性算法保留水平和垂直的边缘信息,因此使得图像变得更平滑,应用在图像超分辨任务中。例如,Youm等[78]将多通道输入引入卷积神经网络,提出了多通道输入的卷积神经网络(multi-channel-input super-resolution convolutional neural networks, MC-SRCNN),提高了网络的泛化能力和图像超分辨性能。具体为:MC-SRCNN利用双线性插值、双三次插值通道等作为多通道输入,不仅能有效减轻SRCNN中梯度消失和梯度爆炸以提高训练稳定性,还能使网络获得更丰富的信息,从而提高SRCNN性能。为了解决SRCNN恢复高分辨率图像效果不佳问题,Intaniyom等[79] 通过双阶段处理模块来提高在图像超分辨任务放大过程中的预测质量,提出了改进超分辨率卷积神经网络(modified super-resolution CNN, m-SRCNN)。其中,第1阶段通过对图像进行锐化、去噪、缩放和裁剪处理,粗略地获得相对干净的低分辨率图像;第2阶段利用图像增强模块、放大和增强模块、双重增强模块和双重放大模块从不同方面增强图像,提高预测图像的分辨率。为了降低计算成本和减少模型复杂度,学者们提出了很多优化图像超分辨网络的方法。例如,Vu等[80]通过使用通道增加网络深度,称为快速、高效的增强卷积神经网络(fast and efficient quality enhancement, FEQE),这不仅可以减少计算复杂度,还可以提取更多特征信息,提高图像保真度。为提高图像超分辨模型的训练效率,Liu等[81]设计渐进残差块对深度特征逐步下采样,进而提出渐进式残差学习的卷积神经网络(progressive residual learning for single image SR, PRLSR),减少冗余信息,获得更精准的结构信息,从而减少图像的细节损失。此外,可学习权值的残差结构不仅可以提取更多层的特征,还能自适应调整残差映射与恒等映射在残差结构中的影响,加快收敛速度,提高图像超分辨性能。为了克服卷积操作引起的像素偏移问题,Zhang等[82]将可变形卷积引入到深度残差网络中,提出了可变形的残差卷积神经网络(deformable and residual convolutional network, DefRCN),解决图像超分辨问题。DefRCN采用自适应调整采样网络,学习更精准的空间信息,解决了固定卷积核大小对卷积神经网络在图像超分辨性能限制的问题。此外,将改进的残差卷积块融合到卷积神经网络中,不仅能提高训练效率,也能防止深度网络的梯度消失问题。为了解决未知退化问题,Kim等[83]基于CinCCGan[55]提出了循环的生成对抗网络(cycle GAN)。该网络结合像素级损失、感知损失、结构相似损失和区域鉴别器,根据目标区域生成图像,解决未有参考高分辨率图像的图像超分辨问题。表5给出了更多基于双线性插值的卷积神经网络图像超分辨方法。
表 5 基于双线性插值的卷积神经网络图像超分辨方法Table 5 Image super-resolution methods using convolutional neural networks based on bilinear interpolation作者 方法 提出时间 应用 关键词 Youm等 MC-SRCNN[78] 2016年 图像超分辨 多通道输入的卷积神经网络 Intaniyom等 m-SRCNN[79] 2021年 图像超分辨 改进的超分辨率卷积神经网络 Vu等 FEQE[80] 2019年 图像超分辨 快速且高效的增强卷积神经网络 Liu等 PRLSR[81] 2020年 图像超分辨 渐进式残差学习的卷积神经网络 Kim等 cycle GAN[83] 2020年 图像超分辨 循环中循环的生成对抗网络 Fan等 SCN[84] 2020年 图像超分辨 多尺度卷积神经网络 Zhang等 DefRCN[82] 2022年 图像超分辨 可变形与残差卷积神经网络 Suryanarayana等 VDR-net[85] 2021年 图像超分辨 深度残差卷积神经网络 Umer等 SR2GAN[86] 2021年 图像超分辨 深度超分辨率残差生成对抗网络 2)基于双线性插值的卷积神经网络图像盲超分辨方法
为了提高核估计效果, Zhu等[87]提出了基于编码器−解码器的内核估计卷积神经网络(encoder-decoder based kernel estimation, EDKE)。EDKE首先通过编码器网络学习真实图像的退化过程,随后利用解码器将LR图像放大到输入大小,并映射到原始图像本身,解决了核各向异性对核估计在实践中精确值的限制问题,实现了更准确的核估计与图像复原。为了提高真实图像的盲超分辨复原效果,Wei等[88]提出领域距离感知的超分辨率卷积神经网络(domain-distance aware super-resolution, DASR)。该网络采用领域距离感知训练和领域距离加权监督策略,能有效地减少训练数据和测试数据之间的域间差距,使输出图像更自然和真实,提高本方法在真实世界中的实用性。表6概述了上述基于双线性插值的卷积神经网络的图像盲超分辨方法。
2.2 基于模块化的卷积神经网络图像超分辨方法
由于卷积神经网络具有端到端结构,采用软件工程中模块化设计的思想引导卷积神经网络成为解决图像处理任务的主流方法[89]。而在图像超分辨中,用于提高分辨率的转置卷积、亚像素层和元上采样操作也被封装成模块来完成图像超分辨任务。根据不同上采样模块,可以将基于模块化的卷积神经网络图像超分辨方法分为基于转置卷积模块的图像超分辨、基于亚像素层模块的图像超分辨,以及基于元上采样模块的图像超分辨方法,具体如图10所示。
 图 10 基于模块化的卷积神经网络图像超分辨方法分类结构Fig. 10 Classification structure of modular convolutional neural network methods for image super-resolution下载:
全尺寸图片
图 10 基于模块化的卷积神经网络图像超分辨方法分类结构Fig. 10 Classification structure of modular convolutional neural network methods for image super-resolution下载:
全尺寸图片
2.2.1 转置卷积(反卷积)
1)基于转置卷积模块的卷积神经网络图像超分辨方法
转置卷积与插值的上采样方法在图像超分辨中的作用相同,都是将低分辨率图像放大成高分辨率图像。但它们的原理不同,转置卷积先对低分辨率图像进行零填充,也就是在像素之间填充零像素,得到扩大的特征图,后在过大的特征图上进行卷积操作以重构出高分辨率图像。由于转置卷积在卷积核中自动学习权重,不需要预定义的插值权重或插值操作,因此比插值方法的效率更高。例如,Li等[89]整合特征映射的反卷积、多尺度融合和残差学习,实现高效的超分辨网络。为了提高模型训练效率,Mao等[90]提出深度残差的编码器−解码器卷积神经网络(very deep residual encoder-decoder networks, RED-Net)。RED-Net由多层卷积和反卷积算子组成。首先,该网络使用跳跃连接来对称连接卷积层和反卷积层,跳跃连接允许信号反向传播到底层,解决梯度消失的问题,使得训练深度网络更加容易。随后,再次利用跳跃连接将图像细节从卷积层传递到反卷积层,提高图像恢复性能。Lai等[91]提出了拉普拉斯金字塔超分辨率卷积神经网络(Laplacian pyramid super-resolution network, LapSRN)。LapSRN由特征提取分支和图像重构分支组成,并将图像分解成不同分辨率的层级,每个层级包含不同频率的信息,其具体超分辨流程为:首先,网络从LR图像中提取特征;随后,在每个金字塔层级学习当前分辨率图像与HR图像间的差异;最后,将学习到的差异信息添加到上采样后的图像中,生成高分辨率输出图像并作为下一层级的输入。通过这种逐级处理,逐层提高图像的分辨率和细节质量,最终完成超分辨率重建。
为了使深度网络更适用于真实的手机相机的图像复原问题,Hui等[54]提出信息蒸馏的卷积神经网络(information distillation network, IDN)来解决图像超分辨问题。IDN是由特征提取块、信息蒸馏块和重构块来实现轻量级的卷积神经网络,其具体工作原理为:首先,利用特征提取块初步提取图像特征;随后,信息蒸馏块通过增强单元和压缩单元逐层提取和压缩特征信息,将长短路径特征融合以获得更多的有效信息;最后,重建块利用残差学习操作融合不同层获得的特征,提高获得特征的鲁棒性,从而提高图像超分辨性能。同样改进残差学习的超分辨网络还有Shi等[92]提出的具有固定跳跃连接的广泛残差卷积神经网络(wide residual network with a fixed skip connection, FSCWRN)。该网络结合全局残差学习和基于浅层网络的局部残差学习,采用渐进式宽网络代替深层网络,缓解了深度网络存在的退化和特征重用减少的问题。尽管跳跃连接缓解了梯度爆炸和梯度消失问题,但是跳跃连接仍然存在缺陷:模型前层无法从后层访问有效信息。针对这个问题,Li等[93]提出了超分辨率反馈卷积神经网络(super-resolution feedback network, SRFBN)。SRFBN利用带有约束的循环神经网络中的隐藏状态实现反馈机制,通过反馈连接自上而下传输高级信息,低级信息通过高级信息的反馈得到逐步的细化和增强,最终生成高分辨率图像。
为了提高超分辨模型在大幅图像上的运行速度和恢复质量。Zeng等[94]提出了多对多连接的卷积神经网络(many-to-many connection of network, MMCN)。在重构过程中,MMCN采用反卷积层和局部多态并行网络来提高图像恢复质量。为了处理较大比例因子缩放的图像超分辨问题,Haris等[95]提出深度反向投影卷积神经网络(Deep back-projection network, DBPN)。该网络创新性地结合迭代的上采样和下采样层,通过将HR特征投影回LR空间的误差反馈机制来增强特征表示和重建精度,从而提高图像超分辨效果。为了在使用较大比例因子复原图像时,降低视觉伪影,提高图像质量。Yang等[96]提出深度循环融合卷积神经网络(deep recurrent fusion network, DRFN)。DRFN采用转置卷积,避免了预处理伪影问题。采用循环残差块逐步恢复高频信息,并通过多层次特征融合充分利用不同感受野的特征,通过卷积层融合特征图重建高分辨率图像。
为解决超分辨图像过度平滑和纹理细节丢失的问题,Zhong等[97]提出超分辨率团结构网络(super-resolution clique network, SRCliqueNet)。SRCliqueNet结合团块组和团上采样模块从低分辨率图像中提取特征图,并利用预测小波变换粗略地重建高分辨率图像。最后,通过逆离散小波变换生成最终的高分辨率图像,从而增强纹理细节和视觉效果。考虑到超分辨图像的高频细节,Wang等[98]提出端到端的深层和浅层卷积神经网络(end-to-end deep and shallow network, EEDS)。EEDS联合训练一个深层和浅层的网络使得统一到一个框架中,浅层网络负责提取低频信息,深层网络负责捕获高频细节,两个网络相结合能同时使得增强高低频信息关联性,提高恢复图像的质量。表7给出了更多基于转置卷积的卷积神经网络图像超分辨方法。
表 7 基于转置卷积的卷积神经网络图像超分辨方法Table 7 Image single super-resolution methods using convolutional neural networks based on transposed convolution作者 方法 提出时间 应用 关键词 Dong等 FSRCNN[18] 2016年 图像超分辨 快速超分辨卷积神经网络 Li等 CTU[89] 2017年 图像超分辨 采用帧内编码块上采样方法的卷积神经网络 Mao等 RED-NET[90] 2016年 图像超分辨 深度残差的编码器−解码器卷积神经网络 Lai 等 LapSRN[91] 2018年 图像超分辨 拉普拉斯金字塔超分辨率卷积神经网络 Hui等 IDN[54] 2018年 图像超分辨 信息蒸馏的卷积神经网络 Shi等 FSCWRN[92] 2019年 图像超分辨 具有固定跳跃连接的广泛残差卷积神经网络 Li等 SRFBN[93] 2019年 图像超分辨 超分辨率反馈卷积神经网络 Zeng等 MMCN[94] 2019年 图像超分辨 多对多连接的卷积神经网络 Haris等 DBPN[95] 2018年 图像超分辨 深度反向投影卷积神经网络 Yang等 DRFN[96] 2019年 图像超分辨 深度循环融合卷积神经网络 Zhong等 SRCliqueNet[97] 2018年 图像超分辨 超分辨率团结构网络 Wang等 EEDS[98] 2019年 图像超分辨 端到端的深层和浅层卷积神经网络 Tong等 SRDenseNet[21] 2017年 图像超分辨 使用密集跳跃连接的图像超分辨网络 Li等 MSRN[99] 2018年 图像超分辨 多尺度残差的超分辨率卷积神经网络 Tan等 SCFFN[100] 2022年 图像超分辨 基于自校准特征融合的高效超分辨率卷积神经网络 Cheng等 ResLap[101] 2020年 图像超分辨 融合残差密集块的拉普拉斯金字塔超分辨卷积神经网络 Jia等 MA-GAN[102] 2022年 图像超分辨 多头注意力生成对抗网络 Chen等 MFFN[103] 2024年 图像超分辨 基于多级特征融合网络的图像超分辨率卷积神经网络 Zhang等 UMCTN[104] 2024年 遥感图像超分辨 不确定性驱动的混合卷积与Transformer结合的遥感图像超分辨网络 Bai等 BSRN[105] 2024年 图像超分辨 极其轻量级的图像超分辨率卷积神经网络 Dargahi等 CPDSCNN[106] 2023年 图像超分辨 级联并行结构的深浅卷积神经网络 2)基于转置卷积的卷积神经网络图像盲超分辨方法
由于真实场景的复杂性,图像盲超分辨恢复效果不佳。学者们利用生成式网络的博弈原理恢复细节信息,提高图像超分辨效果。例如,Xu等[107]采用生成对抗网络学习特定类别的细节信息,提出了多级生成对抗网络(multi-class GAN, MCGAN)。该网络引入新的训练损失来恢复图像细节信息,并采用转置卷积来重构高质量图像。为了放大未知缩放因子的图像超分辨,Tao等[108]提出频谱到内核的卷积神经网络(spectrum to kernel network, S2K)。S2K充分利用低分辨率图像频谱中的形状结构,并通过可行的隐式跨领域转换直接输出相应的上采样空间核来降低模糊核估计误差,使非盲超分辨方法能在盲超分辨环境下使用。更多的基于转置卷积的卷积神经网络图像盲超分辨方法如表8所示。
表 8 基于转置卷积的卷积神经网络图像盲超分辨方法Table 8 Blind image super-resolution methods using convolutional neural networks based on transposed convolution2.2.2 亚像素层
1)基于亚像素层的卷积神经网络图像超分辨方法
亚像素的核心思想是利用卷积层获得多通道数的特征图,并利用子像素卷积或其他重排列方式将多个通道的特征图在像素级上重新排列成预定尺度的高分辨率图像。由于神经网络通过卷积层可以利用更多的全局信息和上下文信息,比插值方法获得更丰富的细节信息,还原更逼真的图像信息。此外,不同于其他模块化的方法,该方法仅利用卷积和重排列操作,因此计算量小于反卷积、反池化操作,这可以大幅度提升神经网络的运行速度。基于亚像素层的上述特性, Shi等[111]提出了高效亚像素卷积网络解决图像超分辨问题(efficient sub-pixel convolutional neural network, ESPCN)。ESPCN在低分辨率空间中提取低分辨率特征映射,并使用亚像素层代替双三次插值操作把获得特征放大成高分辨率特征,这会降低计算成本,提高图像超分辨效率。为了进一步提高图像超分辨性能,RFB-ESRGAN[72]交替使用最近邻插值和亚像素卷积操作来充分利用输入图像的深度信息和空间信息,获得更多的细节信息,提高图像超分辨效果。为了减少图像重建过程中细节信息的丢失,Song等[112]提出了增强深度残差的超分辨率卷积神经网络(gradual deep residual network for super-resolution, GDSR)。GDSR使用残差块提取图像的深度特征,并将特征信息通过亚像素卷积层上采样到高分辨率空间。最后,通过多个子网络逐步重构出高质量高分辨率图像,这能有效减少细节信息的丢失,提高图像超分辨性能。为了降低图像超分辨网络的计算复杂度,Jiang等[113]提出增强亚像素卷积神经网络(improved sub-pixel convolutional neural network, ISCNN)。该网络首先利用较小的卷积核初步地提取图像低频特征。随后,通过亚像素层上采样放大图像特征,最后利用卷积运算二次提取高频特征,以上两步操作提高了图像质量。
随着超分辨技术不断进步,对图像细节的修复提出了更高的要求。为了有效地加强模型不同层间的信息特征相关性,Niu等[114]提出了整体注意力卷积神经网络(holistic attention network, HAN)。该网络由层注意模块和通道−空间注意力模块组成,并通过加强模型层、通道和位置之间的整体相互依赖关系来建模,提取层次中丰富的特征,提高图像超分辨性能。为了降低计算复杂度,Jiang等[115]提出分层密集连接的卷积神经网络(hierarchical dense connection network, HDN)。HDN构造了分层密集残差块,并以共享的方式互相连接,允许网络在不同阶段融合特征。同时,利用分层矩阵结构提高特征表示能力,可以为信息融合和梯度优化提供额外的交错路径,但网络层数相对较少,减少了计算代价。
尽管基于深度网络的SISR在传统的误差度量和感知质量方面都取得了较好的效果,然而当上采样因子较大时,这些方法仍具有挑战性。针对这一问题,Wang等[50]提出渐进的超分辨率卷积神经网络(progressive super-resolution, ProSR)。ProSR采用逐渐多次执行上采样操作,逐步地重建高分辨率图像。与已有的渐进式超分辨模型相比,ProSR简化了网络内的信息传播,在上采样因子较高时保证了图像复原质量。为了解决SISR中任意超分辨尺度因子的问题,Hui等[116]利用蒸馏和选择性融合的级联信息多重蒸馏块提出信息多重蒸馏卷积神经网络(information multi-distillation network, IMDN)。其中,蒸馏模块逐步提取层次特征,融合模块根据候选特征的重要性进行聚合。最终,利用自适应剪裁策略实现任意比例因子的图像复原功能。为了降低模型的计算负担,Wu等[117]提出了基于位移卷积的网络(shift-conv-based network, SCNet)。该网络全部采用1×1卷积提取图像特征来降低计算量,并通过空间位移操作扩大其感受野,在保持了超分辨性能的同时显著提高了计算效率。
然而,尽管堆叠深度小核卷积能够提高模型性能,但其仍然无法有效扩大感受野[118]。为了解决这个问题,Wang等[119]提出了多尺度注意力网络(multi-scale attention network, MAN),MAN首先将图像特征通道划分为3组,并在每组通道上使用不同尺寸的大核深度卷积提取多尺度特征;随后,通过结合空间注意力和门控机制调节融合的特征权重。最后,通过亚像素层上采样放大图像,实现图像的超分辨率。表9给出了更多基于亚像素层的卷积神经网络图像超分辨方法。
表 9 基于亚像素层的卷积神经网络图像超分辨方法Table 9 Image super-resolution methods using convolutional neural networks based on the sub-pixel layer作者 方法 提出时间 应用 关键词 Shi等 ESPCN[111] 2016年 图像超分辨 高效亚像素卷积神经网络 Shang等 RFB-ESRGAN[72] 2020年 图像超分辨 基于感受野块的增强超分辨率卷积神经网络 Zhao等 MSCNNS[120] 2019年 图像超分辨 多尺度亚像素卷积神经网络 Song等 GDSR[112] 2021年 图像超分辨 增强深度残差的超分辨率卷积神经网络 Vu等 FEQE[80] 2019年 图像超分辨 快速且高效的增强卷积神经网络 Tian等 CFSRCNN[46] 2020年 图像超分辨 由粗到细卷积神经网络 Jiang等 ISCNN[113] 2021年 图像超分辨 增强亚像素卷积神经网络 Niu等 HAN[114] 2020年 图像超分辨 整体注意力卷积神经网络 Jiang等 HDN[115] 2020年 图像超分辨 分层密集连接的卷积神经网络 Wang等 ProSR[50] 2018年 图像超分辨 渐进结构和训练的超分辨率卷积神经网络 Hui等 IMDN[116] 2019年 图像超分辨 信息多重蒸馏卷积神经网络 Ruan等 ESCNN[121] 2022年 图像超分辨 高效亚像素卷积神经网络 Xie等 LKDN[122] 2023年 图像超分辨 大核蒸馏卷积神经网络 Fang等 HNCT[123] 2022年 图像超分辨 卷积与注意力融合网络 Kong等 RLFN[124] 2022年 图像超分辨 残差局部特征卷积神经网络 Tian等 DSRNet[125] 2024年 图像超分辨 动态的超分辨率卷积神经网络 2)基于亚像素层的卷积神经网络图像盲超分辨方法
基于核估计的盲超分辨率方法,在复杂的退化情况下难以准确估计核,导致超分辨效果不佳。为了提高核估计精准性,Xiao等[126]提出了渐进式盲超分辨率卷积神经网络(progressive CNN model for blind super-resolution, PCSR)。PCSR直接从概率图模型的角度出发,使用密集连接和渐进策略有效地利用跨尺度的图像先验信息,重建高质量图像。由于真实图像往往存在随机模糊和噪声,这增加了图像超分辨难度。为解决这一问题,Huo等[127]提出空间上下文幻觉的卷积神经网络(spatial context hallucination network, SCHN),它能将去噪、去模糊和超分辨集成到一个框架中。SCHN利用可变形卷积纠正由于卷积操作引起的图像像素偏移问题,并利用像素重组卷积扩大空间维度,避免在模糊核未知时积累的误差影响图像去模糊和超分辨率效果,从而降低复原图像的质量。为了解决上述问题,Dong等[128]提出基于模糊核预测方法的卷积神经网络(super-resolution method with blur kernel prediction, BKPSR)。BKPSR使用轻量级的卷积神经网络和变分自编码器来预测模糊核代码,随后利用预测的模糊核代码辅助图像超分辨,取得了很好的效果。表10给出了更多基于亚像素层的卷积神经网络图像盲超分辨方法。
2.2.3 元上采样模块
1)基于元上采样模块的卷积神经网络图像超分辨方法
在真实世界中,退化的分辨率未知,因此可根据使用者的需求实现任意倍数的图像分辨率恢复尤为重要[129]。传统的机器学习方法针对不同因子训练多个上采样模块以预定义缩放因子,效率较低。而基于元上采样模块的方法则是基于元学习的思想,其特点在于不再局限于固定的放大倍数,而是通过一个灵活的模块动态生成适配于特定倍数的滤波器参数,从而提升了在任意放大倍数下的适用性。具体而言,这类方法通过网络预测滤波器参数,使模型能够在不同上采样因子条件下对图像进行有效的超分辨处理,从而提高了计算效率和适应性。不同于之前需要根据不同放大倍数设计不同插值参数和模型结构的方法,这种基于预测的参数生成方式可以在不牺牲性能的情况下简化模型结构,使得不同的放大倍数可使用相同的模型结构。Hu等[129]首次利用单一模型求解任意尺度因子的图像超分辨率,并提出了元超分辨率卷积神经网络(meta-super resolution, Meta-SR)。对于不同缩放因子,Meta-SR使用元上采样模块代替传统模块;该模块动态预测上采样过滤器权重,使其能够在不同尺度因子下工作,通过特征图与过滤器间的卷积计算,生成任意大小的高分辨率图像。由于多数超分辨网络仅关注固定整数尺度因子的图像SR,且仅能在单一模型中处理如采样因子、模糊核和噪声水平中的一种退化参数,因此实际使用效率不高。
为解决上述问题,Hu等[130]基于Meta-SR的基础上,提出了元统一超分辨率卷积神经网络(meta-unified super-resolution network, Meta-USR)。该网络能利用元修复块增强传统的上采样模块,自适应预测各种退化参数组合的卷积滤波器权值,解决复杂的退化参数的图像超分辨问题。为了实现精确、灵活的任意尺度因子SISR,Fu等[131]提出残差尺度注意力卷积网络(residual scale attention network, RSAN)。RSAN将尺度因子作为先验知识引入深度网络模型,学习低分辨率图像的判别特征,并利用坐标信息和尺度因子的二次多项式预测像素级重建核,实现任意尺度因子的图像超分辨率。为了充分利用图像潜在的多尺度特征,Li等[99]提出多尺度跳跃连接的卷积神经网络(multi-scale skip-connection network, MSN)。MSN首先利用不同大小的卷积核从低分辨率图像中提取多尺度特征。然后,将这些特征输入多尺度混合组以充分提取图像细节信息。随后,通过混合卷积层训练来自前一尺度和当前尺度的图像细节信息,每层输出通过跳跃连接传递到后续混合卷积层,形成密集连接;最后,通过充分利用图像的潜在多尺度特征,采用元上采样模块实现任意比例因子的特征图放大,从而重建高分辨率图像。
由于元上采样模块在图像处理方面的优越性,不同应用领域纷纷使用该模块以提高图像超分质量与灵活性,例如,在光图像融合领域,Li等[132]提出基于元学习的红外与可见光图像融合深度框架。在该框架中,首先通过卷积神经网络提取源图像特征,并根据使用者的需求,使用任意比例因子的元上采样模块得到高分辨率图像特征;随后,将特征输入基于双重注意力机制的特征融合模块,实现不同源图像的特征融合;最后,在框架中迭代使用残差补偿模块,增强网络的细节提取能力,从而提高光图像融合效果。在医学成像领域,Tan等[133]提出元超分辨生成对抗网络(Meta-SRGAN),该网络在SRGAN的基础上,利用元上采样模块实现任意尺度、高保真的大脑核磁共振图像超分辨率,以辅助医疗诊断。Zhu等[134]提出任意尺度医学图像超分辨率卷积神经网络(medical image arbitrary scale super-resolution, MIASSR),该方法将元学习与生成对抗网络相结合,并利用迁移学习实现全新医疗模式的超分辨任务,如心脏磁共振图像和胸部计算机断层扫描图像超分辨任务。表11概括了更多的基于元上采样模块的卷积神经网络图像超分辨方法。
表 11 基于元上采样模块的卷积神经网络图像超分辨方法Table 11 Image super-resolution methods using convolutional neural networks based on the meta-upsampling module作者 方法 提出时间 应用 关键词 Hu等 Meta-SR[129] 2019年 图像超分辨 元超分辨率卷积神经网络 Hu等 Meta-USR[130] 2021年 图像超分辨 元统一超分辨率卷积神经网络 Fu等 RSAN[131] 2021年 图像超分辨 残差尺度注意力卷积网络 Tan等 Meta-SRGAN[133] 2020年 图像超分辨 元超分辨生成对抗网络 Zhu等 MIASSR[134] 2021年 图像超分辨 任意尺度医学图像超分辨率卷积神经网络 Li等 MSN[99] 2018年 图像超分辨 多尺度跳跃连接的卷积神经网络 Hong等 DC-Net[135] 2023年 图像超分辨 解耦与耦合的卷积神经网络 2)基于元上采样模块的卷积神经网络图像盲超分辨方法
为提高真实图像的盲超分辨效果,一些方法试图用多种退化因子的复杂组合训练超分辨网络,以覆盖真实的退化空间。但由于运动物体和失焦等因素,模糊核的估计误差会导致图像超分辨失效。针对这一问题,Xia等[136]提出基于元学习的区域退化感知超分辨率卷积神经网络(meta-learning based region degradation aware SR Network, MRDA)。MRDA包括3种不同网络类型:元学习网络、退化提取网络和区域退化感知超分辨网络。首先,轻量级元学习网络采用元学习算法学习退化过程;随后,退化提取网络通过多次迭代,快速适应特定的复杂退化,并隐式提取退化信息;最后,区域退化感知超分辨网络利用空间调制系数,自适应调整显式退化表示的影响,从而提高图像盲超分辨率性能。
3. 性能比较
为了使读者更方便地了解更多面向图像超分辨的卷积神经网络方法,本章首先介绍不同方法的常用数据集、常用评价指标和实验设置,然后将从定量比较和可视化分析两个方面对不同图像超分辨方法的性能与表现进行对比。
3.1 数据集
本节对上述的图像超分辨模型划分为两类:非盲图像超分辨率卷积神经网络与盲图像超分辨率卷积神经网络。数据集通常分为训练数据集和测试数据集,分别用于模型的训练与评估。此外,验证数据集通常包含在训练数据集中,用于训练过程中检测图像超分辨模型效果,它通常由与测试集具有相同分布的图像组成。不同模型的更多细节内容如下所示:
1)图像超分辨率卷积神经网络
训练数据集 ImageNet[137]、91-images[7]、BSD[138]、DIV2K[139]、Harvard[140]、General-100[141]、Flickr2K[139]、MSCOCO[142]、OST[143]、DIV8K[144]、SRResNet[25]、WED[145]、FFHQ[146]、Nico-illust[147]、 NYU Depth[148]、Make3D[149]、T91[7]、OASIS[150]、BraTS[151]、ACDC[152]、COVID-CT[153]、ILSVRC 2012[137]、UCID[154]。
测试数据集 Set5[155]、Set14[156]、BSD、Urban100[141]、Manga109[157]、DIV2K[139]、CAVE[158]、Harvard、720p[159]、PIRM[160]、DIV8K、Nico-illust、SRResNet、DIV2K4D[161]、Set12[162]、UCID、SuperTexture[163]、NYU Depth、Make3D、ImageNet400[137]、OASIS、BraTS、ACDC、COVID-CT。
2)图像盲超分辨率卷积神经网络
训练数据集 DIV2K、Flickr2K、WED、FFHQ、OutdoorSceneTraining[143]、DIV2KRK[60]、CelebA[164]、VOC2012[165]。
测试数据集 NTIRE2018[166]、Set5、Set14、BSD、DIV2K、Urban100、RealSRSet[161]、OST、DPED[167]、ADE20K[168]、RealSR[169]、DRealSR[170]、 CelebA、Manga109。
为了使读者更方便地了解相关图像超分辨模型的数据集信息,表12概括了上述不同的图像超分辨率和盲超分辨率方法的训练数据集和测试数据集。
表 12 图像超分辨率与盲超分辨率的训练与测试数据集Table 12 Training and testing datasets for single image super-resolution and blind super-resolution方法分类 图像超分辨方法 训练数据集 测试数据集 图像超
分辨率SRCNN[16] ImageNet Set5、Set14 VDSR[17] T91、BSD Set5、Set14、BSD100、Urban100 CMSC[40] T91、BSD300 Set5、Set14、BSD100、Urban100 DRCN[20] T91 Set5、Set14、BSD100、Urban100 DRRN[43] T91、BSD Set5、Set14、BSD100、Urban100 MemNet[39] BSD Set5、Set14、BSD100、Urban100 EDSR[44] DIV2K Set5、Set14、BSD100、Urban100、DIV2K MDSR[44] DIV2K Set5、Set14、BSD100、Urban100、DIV2K ProSR[50] DIV2K Set5、Set14、BSD100、Urban100、DIV2K RCAN[23] DIV2K Set5、Set14、BSD100、Urban100、Manga109 DCSCN[41] T91、BSD Set5、Set14、BSD100 SSF-CNN[52] Harvard CAVE、Harvard LISTA[53] T91 Set5、Set14、BSD100 图像超
分辨率IDN[54] T91、BSD Set5、Set14、BSD100、Urban100 CFSRCNN[46] DIV2K Set5、Set14、BSD100、Urban100、720p FSRCNN[18] T91、General-100 Set5、Set14、BSD100 USRNet[69] DIV2K、Flickr2K BSD68 BT-SRN[70] DIV2K DIV2K EnhanceNet[70] MSCOCO Set5、Set14、BSD100、Urban100 ESRGAN[26] DIV2K、Flickr2K、OST Set5、Set14、BSD100、Urban100、PIRM RFB-ESRGAN[72] DIV8K、DIV2K、Flickr2K、OST DIV8K PAN[73] DIV2K、Flickr2K Set5、Set14、BSD100、Urban100、Manga109 CCNet[74] SRResNet SRResNet Blind ESRGAN[62] DIV2K、Flickr2K、WED、FFHQ DIV2K4D、RealSRSet MANet[76] DIV2K Set5、Set14、BSD100、Urban100 MC-SRCNN[78] T91 Set5、Set14 m-SRCNN[79] Nico-illust Nico-illust FEQE[80] DIV2K Set5、Set14、BSD100、Urban100 PRLSR[81] DIV2K Set5、Set14、BSD100、Urban100 SCN[84] T91 Set12、BSD64、Urban100 DefRCN[82] DIV2K Set5、Set14、BSD100、Urban100 CTU[89] UCID UCID RED-NET[90] BSD BSD200 LapSRN[91] T91、BSD200 Set5、Set14 IDN[54] T91、BSD200 Set5、Set14、BSD100、Urban100 SRFBN[93] DIV2K、Flickr2K Set5、Set14、BSD100、Urban100、Manga109 MMCN[94] T91 Set5、Set14、BSD100、Urban100 DBPN[95] DIV2K、Flickr2K、ImageNet Set5、Set14、BSD100、Urban100、Manga109 DRFN[96] T91、BSD200 Set5、Set14、BSD100、Urban100、ImageNet400 SRCliqueNet[97] DIV2K Set14、BSD100、Urban100 EEDS[98] T91 Set5、Set14、BSD100 SRDenseNet[21] ImageNet Set5、Set14、BSD100、Urban100 MSRN[99] DIV2K Set5、Set14、BSD100、Urban100、Manga109 ESPCN[111] ImageNet Set5、Set14、BSD300、BSD500、SuperTexture MSCNNS[120] NYU Depth、Make3D NYU Depth、Make3D GDSR[112] T91、BSD200 Set5、Set14、BSD100、Urban100 ISCNN[113] BSD300 BSD300、BSD500 HAN[114] DIV2K Set5、Set14、BSD100、Urban100、Manga109 HDN[115] DIV2K Set5、Set14、BSD100、Urban100、Manga109 IMDN[116] DIV2K Set5、Set14、BSD100、Urban100、Manga109 Meta-RDN[129] DIV2K Set14、BSD100、Manga109、DIV2K Meta-USR[130] DIV2K DIV2K、Set5、Set14、BSD100、Urban100、Manga109 RSAN[131] DIV2K Set5、Set14、BSD100、Urban100 Meta-SRGAN[133] DIV2K、BraTS BraTS MIASSR[134] OASIS、BraTS、ACDC、COVID-CT OASIS、BraTS、ACDC、COVID-CT MSN[99] ILSVRC 2012、DIV2K DIV2K、Set5、Set14、BSD100、Urban100、Manga109 图像盲超分辨率 CinCGAN[55] DIV2K NTIRE2018 UISR[56] DIV2K NTIRE2018 IKC[58] DIV2K、Flickr2K Set5、Set14、BSD100 KMSR[59] DIV2K DIV2K KernelGAN[60] — NTIRE2018 DASR[61] DIV2K、Flickr2K Set5、Set14、BSD100、Urban100 BlindESRGAN[62] DIV2K、Flickr2K、WED、FFHQ DIV2K、RealSRSet RealESRGAN[45] DIV2K、Flickr2K、OutdoorSceneTraining RealSR、DRealSR、OST300、DPED、ADE20K EDKE[87] DIV2KRK RealSR MCGAN[107] CelebA CelebA MANet[76] DIV2K BSD100 S2K[108] DIV2K DIV2K、Flickr2K PCSR[126] DIV2K、VOC2012 Set5、Set14 SCHN[127] DIV2K、Flickr2K Set5、Set14 MRDA[136] DIV2K、Flickr2K Set5、Set14、BSD100、Urban100、Manga109 3.2 评价指标
为定量描述不同方法的性能差异,本节将介绍常用于图像超分辨的评价指标,包括峰值信噪比(peak signal-to-noise ratio, PSNR)[171]、结构相似性(structural similarity, SSIM)[172]、模型参数量以及运行时间。
峰值信噪比(PSNR)和结构相似性(SSIM)是两个著名的客观图像质量评价指标[171]。PSNR用于衡量重建图像与参考图像之间的相似度,通过计算图像之间像素的均方误差(mean square error, MSE)获得。PSNR的计算公式为
$$ {M_{{\mathrm{PSNR}}}} = 10 \cdot {\mathrm{lo}}{{\mathrm{g}}_{10}}{\left(\frac{{{P_{{\mathrm{MAX}}}}}}{{{M_{{\mathrm{MSE}}}}}}\right)^2} $$ (1) 式中:
${M_{{\mathrm{PSNR}}}}$ 表示计算得到峰值信噪比的值;${P_{{\mathrm{MAX}}}}$ 表示图像中可取最大的像素值,一般为255;${M_{{\mathrm{MSE}}}}$ 表示重建图像与参考图像之间像素值的均方误差,计算公式为$$ {M_{{\mathrm{MSE}}}} = \frac{1}{{m{{ \times }}n}}\sum\limits_{i = 1}^m {\sum\limits_{j = 1}^n {{{(I_{{\mathrm{SR}}}^{i,j} - I_{{\mathrm{HR}}}^{i,j})}^2}} } $$ (2) 式中:
$ I_{{\mathrm{SR}}}^{i,j} $ 为重建图片的第$i$ 行第$j$ 列的像素值,$ I_{{\mathrm{HR}}}^{i,j} $ 为参考图片的第$i$ 行第$j$ 列的像素值,$m$ 和$n$ 分别表示图像的行和列大小。SSIM用于模拟人类视觉对图像结构信息的感知[172]。与PSNR相比,SSIM更加关注图像之间亮度、对比度和结构等信息的相似性。SSIM的计算公式为
$$ {M_{{\mathrm{SSIM}}}} = \frac{{(2{u_{{\mathrm{SR}}}}{u_{{\mathrm{HR}}}} + {\varepsilon _1})(2{v_{{\mathrm{SR}},{\mathrm{HR}}}} + {\varepsilon _2})}}{{(u_{{\mathrm{SR}}}^2 + u_{{\mathrm{HR}}}^2 + {\varepsilon _1})(v_{{\mathrm{SR}}}^2 + v_{{\mathrm{HR}}}^2 + {\varepsilon _2})}} $$ (3) 式中:
$ {M_{{\mathrm{SSIM}}}} $ 表示计算得到结构相似性的值;$ {u_{{\mathrm{SR}}}} $ 和$ {u_{{\mathrm{HR}}}} $ 分别表示重建图像和参考图像的平均亮度;$ {v_{{\mathrm{SR}}}} $ 和$ {v_{{\mathrm{HR}}}} $ 分别表示重建图像和参考图像的亮度方差;$ {v_{{\mathrm{SR}},{\mathrm{HR}}}} $ 是两张图像的协方差;$ {\varepsilon _1} $ 和$ {\varepsilon _2} $ 是一个极小的常数。模型参数量和运行时间是评估模型性能和效率的两个重要指标。模型参数量用于评价模型的复杂度和内存占用,通过计算各层权重矩阵的大小并求和得到。运行时间用于评价模型在推理阶段对图片执行运算的快慢,通过计算在相同硬件条件下对相同图片完成推理过程所需的平均时间来衡量。
3.3 实验设置
在图像超分辨领域,为了保持公平,测试时用Y通道测试[16,18]。由于不同方法的实验设备、配置及实验设置不同,通常选择PSNR和SSIM以及可视化图像的细节比较来验证图像超分辨模型的性能。每种方法的实验设置可参考具体方法论文中的参数设置。此外,待恢复倍数代表将低分辨率图像放大到几倍高清图像。
3.4 定量比较
为验证第3章中提到的图像超分辨方法性能,本节将比较非盲超分辨率与盲超分辨率两类方法在公开数据集上的表现,通过测试这些方法的峰值信噪比、结构相似性、模型参数量以及运行时间,对这些方法进行定量分析。
1)图像超分辨模型的定量分析
本次测试了VDSR、CMSC、DRCN、DRRN、MemNet、EDSR、MDSR、RCAN、LISTA、IDN、CFSRCNN、FSRCNN、LapSRN、MANet、CNF、DefRCN、SRFBN、MSRN、HAN、RDN等方法在Set5、Set14、BSD100、Urban100等公共数据集上不同倍数的图像超分辨性能。表13中,在Set5数据集上放大倍数为2时,RDN的性能表现最好;表14中放大倍数为3和表15中放大倍数为4时,RCAN的性能表现最好。此外,本实验选取部分超分辨模型在不同大小的图像上实际运行,比较不同模型在放大倍数为2时的处理时间。在表16列举出的多种模型当中,CFSRCNN的模型处理速度最快。最后,本实验比较了几种经典图像超分辨模型的参数大小与计算速度,如表17所示,CARN-M[173]的参数规模最小、运算速度最快、模型复杂度最小。
表 13 图像超分辨模型在Set5、Set14、BSD100、Urban100上放大倍数为2时PSNR与SSIMTable 13 Evaluation of PSNR and SSIM results for scale factor 2 in image super-resolution on Set5, Set14, BSD100, and Urban100方法 Set5 Set14 BSD100 Urban100 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM VDSR[17] 35.53 0.9587 33.03 0.9124 31.90 0.8960 30.76 0.9140 CMSC[40] 37.89 0.9605 33.41 0.9153 32.15 0.8992 31.47 0.9220 DRCN[20] 37.63 0.8588 33.06 0.9121 31.85 0.8942 30.76 0.9133 DRRN[43] 37.74 0.9591 33.23 0.9136 32.05 0.8973 31.23 0.9188 MemNet[39] 37.68 0.9597 33.28 0.9142 32.08 0.8987 31.31 0.9195 EDSR[44] 38.02 0.9606 34.02 0.92.4 32.37 0.9018 33.10 0.9363 MDSR[44] 38.17 0.9605 33.92 0.9203 32.34 0.9014 33.03 0.9362 RCAN[23] 38.33 0.9617 34.23 0.9225 32.46 0.9031 33.54 0.9399 LISTA[53] 37.41 0.9567 32.71 0.9095 31.54 0.8908 — — IDN[54] 37.83 0.9600 33.30 0.9148 32.08 0.8985 31.27 0.9196 CFSRCNN[46] 37.79 0.9591 33.51 0.9165 32.11 0.8988 32.07 0.9273 FSRCNN[18] 36.98 0.9556 32.62 0.9087 31.50 0.8904 29.85 0.9009 LapSRN[91] 37.52 0.9591 33.08 0.9130 31.08 0.8950 30.41 0.9101 MANet[76] 35.98 0.9420 31.95 0.8845 30.97 0.8650 29.87 0.8877 CNF[38] 37.66 0.9690 33.08 0.9136 31.91 0.8962 — — DefRCN[82] 38.02 0.9596 33.58 0.9151 32.21 0.8998 32.20 0.9286 SRFBN[93] 38.11 0.9609 33.82 0.9196 32.29 0.9010 32.62 0.9328 MSRN[99] 38.08 0.9605 33.74 0.9170 32.23 0.9013 32.22 0.9326 HAN[114] 26.83 0.7919 23.21 0.6888 25.11 0.6613 22.42 0.6571 RDN[22] 38.24 0.9614 34.01 0.9212 32.34 0.9017 32.89 0.9353 表 14 图像超分辨模型在Set5、Set14、BSD100、Urban100上放大倍数为3时PSNR与SSIMTable 14 Evaluation of PSNR and SSIM results for scale factor 3 in image super-resolution on Set5, Set14, BSD100, and Urban100方法 Set5 Set14 BSD100 Urban100 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM VDSR[17] 33.66 0.9213 29.77 0.8314 28.82 0.7976 27.14 0.8279 CMSC[40] 34.24 0.9266 30.09 0.8371 29.01 0.8024 27.69 0.8411 DRCN[20] 33.82 0.9226 29.77 0.8314 28.80 0.7963 27.15 0.8277 DRRN[43] 34.03 0.9244 29.96 0.8349 28.95 0.8004 27.53 0.8377 MemNet[39] 34.09 0.9248 30.00 0.8350 28.96 0.8001 27.56 0.8376 EDSR[44] 34.76 0.9290 30.66 0.8481 29.32 0.8104 29.02 0.8685 MDSR[44] 34.77 0.9288 30.53 0.8465 29.30 0.8101 28.99 0.8683 RCAN[23] 34.85 0.9305 30.76 0.8494 29.39 0.8122 29.31 0.8736 LISTA[53] 33.26 0.9167 29.55 0.8271 28.58 0.7910 — — CFSRCNN[46] 34.24 0.9256 30.27 0.8410 29.03 0.8035 28.04 0.8496 FSRCNN[18] 33.16 0.9140 29.42 0.8242 28.52 0.7893 26.41 0.8064 LapSRN[91] 33.82 0.9227 29.87 0.8320 28.82 0.7980 27.07 0.8280 MANet[76] 33.69 0.9184 29.81 0.8270 28.80 0.7931 27.39 0.8331 CNF[38] 33.74 0.9226 29.90 0.8322 28.82 0.7980 — — DefRCN[82] 34.41 0.9263 30.34 0.8388 29.01 0.8044 28.16 0.8519 SRFBN[93] 34.70 0.9292 30.51 0.8461 29.24 0.8084 28.73 0.8641 MSRN[99] 34.38 0.9262 30.34 0.8395 29.08 0.8041 28.08 0.8554 HAN[114] 23.71 0.6171 22.31 0.5878 23.21 0.5653 20.34 0.5311 RDN[22] 34.71 0.9296 30.57 0.8468 29.26 0.8093 28.80 0.8653 IDN[54] 34.11 0.9253 29.99 0.8354 28.95 0.8013 27.42 0.8359 表 15 图像超分辨模型在Set5、Set14、BSD100、Urban100上放大倍数为4时PSNR与SSIMTable 15 Evaluation of PSNR and SSIM results for scale factor 4 in image super-resolution on Set5, Set14, BSD100, and Urban100方法 Set5 Set14 BSD100 Urban100 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM VDSR[17] 31.35 0.8838 28.01 0.7674 27.29 0.7251 25.18 0.7524 CMSC[40] 31.91 0.8923 28.35 0.7751 27.46 0.7308 25.64 0.7692 DRCN[20] 31.53 0.8854 28.03 0.7673 27.14 0.7233 25.14 0.7511 DRRN[43] 31.68 0.8888 28.21 0.7720 27.38 0.7284 25.44 0.7638 MemNet[39] 31.74 0.8893 28.26 0.7723 27.40 0.7281 25.50 0.7630 EDSR[44] 32.62 0.8984 28.94 0.7901 27.79 0.7437 26.86 0.8080 MDSR[44] 32.60 0.8982 28.82 0.7876 27.78 0.7425 26.86 0.8082 RCAN[23] 32.73 0.9013 28.98 0.7910 27.85 0.7455 27.10 0.8142 LISTA[53] 31.04 0.8775 27.76 0.7620 27.11 0.7191 — — CFSRCNN[46] 32.06 0.8920 28.57 0.7800 27.53 0.7333 26.03 0.7824 FSRCNN[18] 30.70 0.8657 27.59 0.7535 26.96 0.7128 24.60 0.7258 LapSRN[91] 31.54 0.8850 28.19 0.7720 27.32 0.7270 25.21 0.7560 MANet[76] 31.54 0.8876 28.28 0.7727 27.35 0.7305 25.66 0.7759 CNF[38] 31.55 0.8856 28.15 0.7680 27.32 0.7253 — — DefRCN[82] 32.21 0.8936 28.59 0.7810 27.57 0.7356 26.04 0.7841 SRFBN[93] 32.47 0.8983 28.81 0.7868 27.72 0.7409 26.60 0.8015 MSRN[99] 32.07 0.8903 28.60 0.7751 27.52 0.7273 26.04 0.7896 HAN[114] 21.71 0.5941 20.42 0.4937 21.48 0.4901 19.01 0.4676 RDN[22] 32.47 0.8990 28.81 0.7871 27.72 0.7419 26.61 0.8028 IDN[54] 31.82 0.8903 28.25 0.7730 27.41 0.7297 25.41 0.7632 表 16 图像超分辨模型在256×256、512×512和1024 ×1024 大小的图像和放大倍数为2时的运行时间Table 16 Runtime for image super-resolution models on images of size 256×256, 512×512, and1024 ×1024 with scale factor of 2s 2)图像盲超分辨模型定量分析
对于众多盲超分辨率模型,本实验同样选取了Set5和Set14公共数据集进行实验。表18列举了经典图像盲超分辨模型在常见数据集、不同倍率时的性能表现。如表18所示,在Set5数据集上且倍数为2和4时,DASR的性能表现最好。
表 18 图像盲超分辨模型在Set5、Set14数据集上放大倍数为2、3和4时PSNR与SSIMTable 18 PSNR and SSIM for blind super-resolution models on Set5 and Set14 datasets at ×2, ×3, and ×4 magnifications方法 指标 放大倍数为2 放大倍数为3 放大倍数为4 Set5 Set14 Set5 Set14 Set5 Set14 IKC[48] PSNR/dB 36.62 32.82 32.16 29.46 31.52 28.26 SSIM 0.9658 0.8999 0.9420 0.8229 0.9278 0.7688 DASR[61] PSNR/dB 37.87 33.34 34.11 30.13 31.99 28.50 SSIM — — — — — — PCSR[126] PSNR/dB 31.49 29.88 — — 29.20 26.82 SSIM 0.909 0.856 — — 0.807 0.694 SCHN[127] PSNR/dB 33.70 29.64 — — 27.81 24.70 SSIM 0.9310 0.8689 — — 0.8339 0.7056 3.5 可视化图像
为了使读者更方便地了解不同图像非盲超分辨和盲超分辨方法的可视化效果,本节将展示部分超分辨模型的人眼观察到的结果,即不同超分辨方法的效果对比图。图11~14中(a)~(h)分别为高清原始图像、传统双三次插值后的图像、SRCNN处理图像、VDSR处理图像、DRCN处理图像、CARN-M处理图像、LESRCNN[174]处理图像、CFSRCNN处理图像。从图11中可以看到,在BSD100数据集上,放大倍数为3时,CFSRCNN方法效果最好。对比其他方法,CFSRCNN方法恢复图像的窗户框更平直,并且能恢复部分小窗户框。图12中,在BSD100数据集上,放大倍数为4时,CFSRCNN方法表现最为优异,大多数方法无法恢复出游艇上最右侧的竖杆,而CFSRCNN方法可以看清有竖杆。图13中,在Urban100数据集上,放大倍数为3时,CFSRCNN方法再次展示出色性能,在更高楼层仍然保持清晰的横向玻璃框,而其他方法则会变得模糊或者错误地变成竖向玻璃框。在图14中可以看出,在Urban100数据集上,放大倍数为4时,CFSRCNN方法同样表现突出,能够清晰地恢复出第3条柱子,而其他方法会模糊或者缺失第3根柱子。综合来看,CFSRCNN方法在不同数据集和放大倍数下普遍表现优越,显示出其在多种场景中卓越的图像超分辨率能力。
 图 11 不同图像超分辨方法在BSD100数据集上当倍数为3时的可视化效果Fig. 11 Visualization effects of different image super-resolution methods on the BSD100 dataset at multiples of 3下载:
全尺寸图片
图 11 不同图像超分辨方法在BSD100数据集上当倍数为3时的可视化效果Fig. 11 Visualization effects of different image super-resolution methods on the BSD100 dataset at multiples of 3下载:
全尺寸图片
 图 12 不同图像超分辨方法在BSD100数据集上当倍数为4时的可视化效果Fig. 12 Visualization effects of different image super-resolution methods on the BSD100 dataset at multiples of 4下载:
全尺寸图片
图 12 不同图像超分辨方法在BSD100数据集上当倍数为4时的可视化效果Fig. 12 Visualization effects of different image super-resolution methods on the BSD100 dataset at multiples of 4下载:
全尺寸图片
 图 13 不同图像超分辨方法在Urban100数据集上当倍数为3时的可视化效果Fig. 13 Visualization effects of different image super-resolution methods on the Urban100 dataset at multiples of 3下载:
全尺寸图片
图 13 不同图像超分辨方法在Urban100数据集上当倍数为3时的可视化效果Fig. 13 Visualization effects of different image super-resolution methods on the Urban100 dataset at multiples of 3下载:
全尺寸图片
 图 14 不同图像超分辨方法在Urban100数据集上当倍数为4时的可视化效果Fig. 14 Visualization effects of different image super-resolution methods on the Urban100 dataset at multiples of 4下载:
全尺寸图片
图 14 不同图像超分辨方法在Urban100数据集上当倍数为4时的可视化效果Fig. 14 Visualization effects of different image super-resolution methods on the Urban100 dataset at multiples of 4下载:
全尺寸图片
4. 潜在的研究点与挑战
本文介绍了图像超分辨技术的发展现状,并深度解析了基于插值的卷积神经网络图像超分辨方法和基于模块化的卷积神经网络,为读者深入理解图像超分辨方法提供参考。本章给出了深度学习在图像超分辨率领域的潜在方向,并指出了一些尚未解决的问题。
4.1 潜在研究点
1)超分辨质量的衡量尺度:现有的超分辨方法主要采取像素级误差度量,例如两像素间距离或者两者组合。然而这些方法只封装了局部像素级信息,因此评价结果并不一定是感知上的可靠结果。例如,高PSNR和SSIM值的图像往往过于平滑,其直观上的超分辨效果并不一定好。目前没有一种通用的感知度量尺度,可以在所有条件下很好地度量图像超分辨效果,因此,新的衡量尺度是一个重要的潜在研究点。
2)统一架构的图像超分辨模型:在真实世界中,两个及两个以上的图像退化因素通常会同时出现并降低图像的质量。因此,如何能获得一个鲁棒性模型以解决复杂场景下的图像超分辨问题是一个重要的研究方向。
3)自监督图像超分辨:真实场景下的参考高清图像难以获取,使得已有的图像超分辨方法在真实世界中实用性降低,因此,根据图像的属性,以自监督方式开发出适合真实场景的图像超分辨方法是非常必要的。
4)大模型图像超分辨率:利用像素之间的关联性能促进更多互补信息的利用,提升图像超分辨性能。因此,通过大模型技术引导深度网络,结合结构信息和像素信息,可以提高图像超分辨性能。
5)多模态图像超分辨率:由于复杂的拍摄场景、运动的拍摄设备以及运动的目标,导致基于单源图像的引导式深度网络所获得的图像超分辨模型在真实场景中的应用受限。因此,多模态的图像超分辨方法具有重要的研究价值和应用前景。
6)轻量级网络:移动设备的普及和算力受限的情况,使得高效、低功耗的图像处理算法需求增加。轻量级网络通过减少参数和计算量,实现高效的图像超分辨率,同时保持较高的图像质量。其优势在于能在低功耗设备上实时运行,适用于智能手机、无人机和边缘计算等应用场景。因此,轻量级网络的图像超分辨研究非常有必要。
4.2 研究挑战
1)多种破坏因子的图像超分辨问题:在真实世界中,由于相机抖动、运动的拍摄物体和相机以及复杂的拍摄背景等,会出现噪声、分辨率低等多种破坏因子,导致捕获的图像受损严重。因此,针对多种破坏因子的图像超分辨问题是有待解决的。
2)鲁棒的图像超分辨衡量指标:已有的图像超分辨方法通常采用PSNR和SSIM作为衡量指标,但有时获得的可视化图像直观效果好,而对应方法的PSNR和SSIM结果却较低。因此,制定鲁棒的图像超分辨衡量指标迫在眉睫。
3)更大的超分辨放大倍率:目前,已有的超分辨模型基本无法解决超大的图像超分辨率问题,这限制了图像超分辨算法在特定场景(如人群场景中人脸超分辨)中的使用。因此,研究更大倍数的图像超分辨方法迫在眉睫。
4)真实图像超分辨任务:已有的大部分图像超分辨方法都通过有参考的干净图像等有监督的方式获得图像超分辨模型,而在真实世界中,由于抖动的相机、运动物体以及拍摄的背景等导致已有图像超分辨模型不适用于真实的图像超分辨任务。因此,研究真实场景下图像超分辨方法是必要的。
5)无监督的图像超分辨:已有的无监督图像超分辨方法过分依赖于无标签的数据,如何获得高质量、多样化的数据是一个关键问题。在真实世界中,低分辨率图像的退化过程往往复杂多变,如何在无监督学习框架下有效地建模和处理这些复杂的退化过程,也是一个亟待解决的难点。
6)大模型的图像超分辨:大模型通常需要大量的计算资源和存储空间。此外,训练大模型还需要高质量和多样性的海量数据,获取和处理这些数据既耗时又复杂。其次,大模型的推理速度和能效需要优化,以便在实际应用中能够高效运行。因此,大模型在图像超分辨率的应用仍然具有很大的挑战性。
7)硬件资源受限平台的图像超分辨率:移动设备和嵌入式系统等资源受限平台通常无法提供足够的计算资源和内存,而图像超分辨率算法通常需要大量的计算能力以及功耗。同时,如何在硬件资源有限的情况下保证处理速度和图像质量也是一个难点。因此,在硬件资源受限平台应用图像超分辨仍面临严峻挑战。
5. 结束语
本文比较和总结不同的卷积神经网络在图像超分辨上的应用,并给出了它们之间的联系与区别。首先,本文介绍了图像超分辨方法的发展状况。其次,本文根据图像属性和设备的要求,介绍了主流的图像超分辨卷积神经网络框架。随后,根据线性和非线性的缩放图像方式给出了基于插值的卷积神经网络图像超分辨方法(双三次插值算法、最近邻插值法、双线性插值算法)和基于模块化的卷积神经网络超分辨方法(转置卷积、亚像素层和元上采样模块),并分析这些方法在非盲图像超分辨和盲图像超分辨问题上的动机、原理、区别和性能。最后,本文给出卷积神经网络在图像超分辨的未来研究方向、面临挑战并对全文进行了总结。
-
图 1 综述结构
Fig. 1 Structure of the review
下载:
全尺寸图片
图 2 SRCNN的网络结构
Fig. 2 Network structure of SRCNN
下载:
全尺寸图片
图 3 VDSR的网络结构
Fig. 3 Network structure of VDSR
下载:
全尺寸图片
图 4 DRCN的网络结构
Fig. 4 Network structure of DRCN
下载:
全尺寸图片
图 5 FSRCNN的网络结构
Fig. 5 Network structure of FSRCNN
下载:
全尺寸图片
图 6 SRDenseNet的网络结构
Fig. 6 Network structure of SRDenseNet
下载:
全尺寸图片
图 7 RDN的网络结构
Fig. 7 Network structure of RDN
下载:
全尺寸图片
图 8 RDB的网络结构
Fig. 8 Network structure of RDB
下载:
全尺寸图片
图 9 基于插值的卷积神经网络图像超分辨方法分类结构
Fig. 9 Classification structure of interpolation-based convolutional neural network methods for image super-resolution
下载:
全尺寸图片
图 10 基于模块化的卷积神经网络图像超分辨方法分类结构
Fig. 10 Classification structure of modular convolutional neural network methods for image super-resolution
下载:
全尺寸图片
图 11 不同图像超分辨方法在BSD100数据集上当倍数为3时的可视化效果
Fig. 11 Visualization effects of different image super-resolution methods on the BSD100 dataset at multiples of 3
下载:
全尺寸图片
图 12 不同图像超分辨方法在BSD100数据集上当倍数为4时的可视化效果
Fig. 12 Visualization effects of different image super-resolution methods on the BSD100 dataset at multiples of 4
下载:
全尺寸图片
图 13 不同图像超分辨方法在Urban100数据集上当倍数为3时的可视化效果
Fig. 13 Visualization effects of different image super-resolution methods on the Urban100 dataset at multiples of 3
下载:
全尺寸图片
图 14 不同图像超分辨方法在Urban100数据集上当倍数为4时的可视化效果
Fig. 14 Visualization effects of different image super-resolution methods on the Urban100 dataset at multiples of 4
下载:
全尺寸图片
表 1 基于双三次插值的卷积神经网络图像超分辨方法
Table 1 Image super-resolution methods using convolutional neural networks based on bicubic interpolation
作者 方法 提出时间 应用 关键字 Dong等 SRCNN[16] 2016年 图像超分辨 基于像素映射的卷积神经网络 Kim等 VDSR[17] 2016年 图像超分辨 深度的卷积神经网络 Ren等 CNF[38] 2017年 图像超分辨 基于上下文网络融合的卷积神经网络 Hu等 CMSC[40] 2018年 图像超分辨 级联多尺度交叉的卷积神经网络 Kim等 DRCN[20] 2016年 图像超分辨 基于深度递归的卷积神经网络 Tai等 DRRN[43] 2017年 图像超分辨 基于深度递归的残差卷积神经网络 Tai等 MemNet[39] 2017年 图像超分辨 基于记忆网络的卷积神经网络 Lim等 EDSR[44] 2017年 图像超分辨 增强的深度卷积神经网络 Lim等 MDSR[44] 2017年 图像超分辨 多尺度深度卷积神经网络 Wang等 ProSR[50] 2018年 图像超分辨 基于逐层上采样的卷积神经网络 Zhang等 RCAN[23] 2018年 图像超分辨 基于残差通道注意力的卷积神经网络 Ni等 CGDMSR[51] 2017年 图像超分辨 基于深色和彩色图像的卷积神经网络 Yamanaka等 DCSCN[41] 2017年 图像超分辨 基于残差学习的深度卷积神经网络 Han等 SSF-CNN[52] 2018年 图像超分辨 基于空间和光谱的卷积神经网络 Ledig等 SRGAN[25] 2017年 图像超分辨 生成对抗的网络 Wang等 LISTA[53] 2015年 图像超分辨 基于稀疏编码的卷积神经网络 Hui等 IDN[54] 2018年 图像超分辨 基于信息蒸馏的卷积神经网络 Tian等 CFSRCNN[46] 2020年 图像超分辨 由粗到细卷积神经网络 Rad等 RBSR[47] 2021年 图像超分辨 基于真实双三次超分辨率的卷积神经网络 Demiray等 D-SRGAN[48] 2021年 图像超分辨 基于数字高程模型的超分辨生成对抗网络 Zhang等 Med-SRNet[49] 2022年 图像超分辨 基于高分辨率表征学习的医学图像超分辨率生成对抗网络 表 2 基于双三次插值的卷积神经网络图像盲超分辨方法
Table 2 Blind image super-resolution methods using convolutional neural networks based on bicubic interpolation
作者 方法 提出时间 应用 关键词 Yuan等 CinCGAN[55] 2018年 图像盲超分辨 基于循环中循环的生成对抗网络 Maeda等 UISR[56] 2020年 图像盲超分辨 非成对图像生成对抗网络 Zhang等 DPSR[57] 2019年 图像盲超分辨 深度即插即用超分辨卷积神经网络 Gu等 IKC[58] 2019年 图像盲超分辨 基于迭代内核校正的卷积神经网络 Zhou等 KMSR[59] 2019年 图像盲超分辨 内核建模卷积神经网络 Kligler等 KernelGAN[60] 2019年 图像盲超分辨 内核生成对抗网络 Wang等 DASR[61] 2021年 图像盲超分辨 基于退化感知的超分辨率卷积神经网络 Zhang等 Blind ESRGAN[62] 2021年 图像盲超分辨 增强的盲超分辨卷积神经网络 Wang等 Real ESRGAN[45] 2021年 图像盲超分辨 增强的真实图像超分辨卷积神经网络 Zhang等 CRL-SR[63] 2021年 图像盲超分辨 基于对比表示学习的盲图像超分辨率卷积神经网络 Wu等 CDCN[64] 2022年 图像盲超分辨 基于组件分解与协同优化的卷积神经网络 Cao等 PCNet[65] 2021年 图像盲超分辨 基于先验校正网络的盲超分辨率卷积神经网络 Yamawaki等 BSR-DUL[66] 2021年 图像盲超分辨 基于联合优化策略的盲超分辨率卷积神经网络 Yamawaki等 DIP[67] 2021年 图像盲超分辨 基于可学习退化模型的盲无监督学习卷积神经网络 表 3 基于最近邻插值的卷积神经网络图像超分辨方法
Table 3 Image super-resolution methods using convolutional neural networks based on nearest neighbor interpolation
作者 方法 提出时间 应用 关键词 Dong等 FSRCNN[18] 2016年 图像超分辨 快速超分辨卷积神经网络 Zhang等 USRNet[69] 2020年 图像超分辨 展开超分辨率卷积神经网络 Fan等 BT-SRN[70] 2017年 图像超分辨 基于平衡两阶段残差的卷积神经网络 Sajjadi等 EnhanceNet[71] 2017年 图像超分辨 基于感知损失、对抗损失和纹理损失的增强卷积神经网络 Wang等 ESRGAN[26] 2019年 图像超分辨 增强的超分辨率生成对抗网络 Shang等 RFB-ESRGAN[72] 2020年 图像超分辨 基于感受野块的增强超分辨率生成对抗网络 Zhao等 PAN[73] 2020年 图像超分辨 像素注意力卷积神经网络 Huang等 CCNet[74] 2019年 图像超分辨 基于跨尺度通信的卷积神经网络 Jo等 LUT[75] 2021年 图像超分辨 基于查找表的实用图像超分辨率卷积神经网络 表 4 基于最近邻插值卷积神经网络的图像盲超分辨方法
Table 4 Blind image super-resolution methods using convolutional neural networks based on nearest neighbor interpolation
表 5 基于双线性插值的卷积神经网络图像超分辨方法
Table 5 Image super-resolution methods using convolutional neural networks based on bilinear interpolation
作者 方法 提出时间 应用 关键词 Youm等 MC-SRCNN[78] 2016年 图像超分辨 多通道输入的卷积神经网络 Intaniyom等 m-SRCNN[79] 2021年 图像超分辨 改进的超分辨率卷积神经网络 Vu等 FEQE[80] 2019年 图像超分辨 快速且高效的增强卷积神经网络 Liu等 PRLSR[81] 2020年 图像超分辨 渐进式残差学习的卷积神经网络 Kim等 cycle GAN[83] 2020年 图像超分辨 循环中循环的生成对抗网络 Fan等 SCN[84] 2020年 图像超分辨 多尺度卷积神经网络 Zhang等 DefRCN[82] 2022年 图像超分辨 可变形与残差卷积神经网络 Suryanarayana等 VDR-net[85] 2021年 图像超分辨 深度残差卷积神经网络 Umer等 SR2GAN[86] 2021年 图像超分辨 深度超分辨率残差生成对抗网络 表 6 基于双线性插值的卷积神经网络图像盲超分辨方法
Table 6 Blind image super-resolution methods using convolutional neural networks based on bilinear interpolation
表 7 基于转置卷积的卷积神经网络图像超分辨方法
Table 7 Image single super-resolution methods using convolutional neural networks based on transposed convolution
作者 方法 提出时间 应用 关键词 Dong等 FSRCNN[18] 2016年 图像超分辨 快速超分辨卷积神经网络 Li等 CTU[89] 2017年 图像超分辨 采用帧内编码块上采样方法的卷积神经网络 Mao等 RED-NET[90] 2016年 图像超分辨 深度残差的编码器−解码器卷积神经网络 Lai 等 LapSRN[91] 2018年 图像超分辨 拉普拉斯金字塔超分辨率卷积神经网络 Hui等 IDN[54] 2018年 图像超分辨 信息蒸馏的卷积神经网络 Shi等 FSCWRN[92] 2019年 图像超分辨 具有固定跳跃连接的广泛残差卷积神经网络 Li等 SRFBN[93] 2019年 图像超分辨 超分辨率反馈卷积神经网络 Zeng等 MMCN[94] 2019年 图像超分辨 多对多连接的卷积神经网络 Haris等 DBPN[95] 2018年 图像超分辨 深度反向投影卷积神经网络 Yang等 DRFN[96] 2019年 图像超分辨 深度循环融合卷积神经网络 Zhong等 SRCliqueNet[97] 2018年 图像超分辨 超分辨率团结构网络 Wang等 EEDS[98] 2019年 图像超分辨 端到端的深层和浅层卷积神经网络 Tong等 SRDenseNet[21] 2017年 图像超分辨 使用密集跳跃连接的图像超分辨网络 Li等 MSRN[99] 2018年 图像超分辨 多尺度残差的超分辨率卷积神经网络 Tan等 SCFFN[100] 2022年 图像超分辨 基于自校准特征融合的高效超分辨率卷积神经网络 Cheng等 ResLap[101] 2020年 图像超分辨 融合残差密集块的拉普拉斯金字塔超分辨卷积神经网络 Jia等 MA-GAN[102] 2022年 图像超分辨 多头注意力生成对抗网络 Chen等 MFFN[103] 2024年 图像超分辨 基于多级特征融合网络的图像超分辨率卷积神经网络 Zhang等 UMCTN[104] 2024年 遥感图像超分辨 不确定性驱动的混合卷积与Transformer结合的遥感图像超分辨网络 Bai等 BSRN[105] 2024年 图像超分辨 极其轻量级的图像超分辨率卷积神经网络 Dargahi等 CPDSCNN[106] 2023年 图像超分辨 级联并行结构的深浅卷积神经网络 表 8 基于转置卷积的卷积神经网络图像盲超分辨方法
Table 8 Blind image super-resolution methods using convolutional neural networks based on transposed convolution
表 9 基于亚像素层的卷积神经网络图像超分辨方法
Table 9 Image super-resolution methods using convolutional neural networks based on the sub-pixel layer
作者 方法 提出时间 应用 关键词 Shi等 ESPCN[111] 2016年 图像超分辨 高效亚像素卷积神经网络 Shang等 RFB-ESRGAN[72] 2020年 图像超分辨 基于感受野块的增强超分辨率卷积神经网络 Zhao等 MSCNNS[120] 2019年 图像超分辨 多尺度亚像素卷积神经网络 Song等 GDSR[112] 2021年 图像超分辨 增强深度残差的超分辨率卷积神经网络 Vu等 FEQE[80] 2019年 图像超分辨 快速且高效的增强卷积神经网络 Tian等 CFSRCNN[46] 2020年 图像超分辨 由粗到细卷积神经网络 Jiang等 ISCNN[113] 2021年 图像超分辨 增强亚像素卷积神经网络 Niu等 HAN[114] 2020年 图像超分辨 整体注意力卷积神经网络 Jiang等 HDN[115] 2020年 图像超分辨 分层密集连接的卷积神经网络 Wang等 ProSR[50] 2018年 图像超分辨 渐进结构和训练的超分辨率卷积神经网络 Hui等 IMDN[116] 2019年 图像超分辨 信息多重蒸馏卷积神经网络 Ruan等 ESCNN[121] 2022年 图像超分辨 高效亚像素卷积神经网络 Xie等 LKDN[122] 2023年 图像超分辨 大核蒸馏卷积神经网络 Fang等 HNCT[123] 2022年 图像超分辨 卷积与注意力融合网络 Kong等 RLFN[124] 2022年 图像超分辨 残差局部特征卷积神经网络 Tian等 DSRNet[125] 2024年 图像超分辨 动态的超分辨率卷积神经网络 表 10 基于亚像素层的卷积神经网络图像盲超分辨方法
Table 10 Blind image super-resolution method using convolutional neural networks based on the sub-pixel layer
表 11 基于元上采样模块的卷积神经网络图像超分辨方法
Table 11 Image super-resolution methods using convolutional neural networks based on the meta-upsampling module
作者 方法 提出时间 应用 关键词 Hu等 Meta-SR[129] 2019年 图像超分辨 元超分辨率卷积神经网络 Hu等 Meta-USR[130] 2021年 图像超分辨 元统一超分辨率卷积神经网络 Fu等 RSAN[131] 2021年 图像超分辨 残差尺度注意力卷积网络 Tan等 Meta-SRGAN[133] 2020年 图像超分辨 元超分辨生成对抗网络 Zhu等 MIASSR[134] 2021年 图像超分辨 任意尺度医学图像超分辨率卷积神经网络 Li等 MSN[99] 2018年 图像超分辨 多尺度跳跃连接的卷积神经网络 Hong等 DC-Net[135] 2023年 图像超分辨 解耦与耦合的卷积神经网络 表 12 图像超分辨率与盲超分辨率的训练与测试数据集
Table 12 Training and testing datasets for single image super-resolution and blind super-resolution
方法分类 图像超分辨方法 训练数据集 测试数据集 图像超
分辨率SRCNN[16] ImageNet Set5、Set14 VDSR[17] T91、BSD Set5、Set14、BSD100、Urban100 CMSC[40] T91、BSD300 Set5、Set14、BSD100、Urban100 DRCN[20] T91 Set5、Set14、BSD100、Urban100 DRRN[43] T91、BSD Set5、Set14、BSD100、Urban100 MemNet[39] BSD Set5、Set14、BSD100、Urban100 EDSR[44] DIV2K Set5、Set14、BSD100、Urban100、DIV2K MDSR[44] DIV2K Set5、Set14、BSD100、Urban100、DIV2K ProSR[50] DIV2K Set5、Set14、BSD100、Urban100、DIV2K RCAN[23] DIV2K Set5、Set14、BSD100、Urban100、Manga109 DCSCN[41] T91、BSD Set5、Set14、BSD100 SSF-CNN[52] Harvard CAVE、Harvard LISTA[53] T91 Set5、Set14、BSD100 图像超
分辨率IDN[54] T91、BSD Set5、Set14、BSD100、Urban100 CFSRCNN[46] DIV2K Set5、Set14、BSD100、Urban100、720p FSRCNN[18] T91、General-100 Set5、Set14、BSD100 USRNet[69] DIV2K、Flickr2K BSD68 BT-SRN[70] DIV2K DIV2K EnhanceNet[70] MSCOCO Set5、Set14、BSD100、Urban100 ESRGAN[26] DIV2K、Flickr2K、OST Set5、Set14、BSD100、Urban100、PIRM RFB-ESRGAN[72] DIV8K、DIV2K、Flickr2K、OST DIV8K PAN[73] DIV2K、Flickr2K Set5、Set14、BSD100、Urban100、Manga109 CCNet[74] SRResNet SRResNet Blind ESRGAN[62] DIV2K、Flickr2K、WED、FFHQ DIV2K4D、RealSRSet MANet[76] DIV2K Set5、Set14、BSD100、Urban100 MC-SRCNN[78] T91 Set5、Set14 m-SRCNN[79] Nico-illust Nico-illust FEQE[80] DIV2K Set5、Set14、BSD100、Urban100 PRLSR[81] DIV2K Set5、Set14、BSD100、Urban100 SCN[84] T91 Set12、BSD64、Urban100 DefRCN[82] DIV2K Set5、Set14、BSD100、Urban100 CTU[89] UCID UCID RED-NET[90] BSD BSD200 LapSRN[91] T91、BSD200 Set5、Set14 IDN[54] T91、BSD200 Set5、Set14、BSD100、Urban100 SRFBN[93] DIV2K、Flickr2K Set5、Set14、BSD100、Urban100、Manga109 MMCN[94] T91 Set5、Set14、BSD100、Urban100 DBPN[95] DIV2K、Flickr2K、ImageNet Set5、Set14、BSD100、Urban100、Manga109 DRFN[96] T91、BSD200 Set5、Set14、BSD100、Urban100、ImageNet400 SRCliqueNet[97] DIV2K Set14、BSD100、Urban100 EEDS[98] T91 Set5、Set14、BSD100 SRDenseNet[21] ImageNet Set5、Set14、BSD100、Urban100 MSRN[99] DIV2K Set5、Set14、BSD100、Urban100、Manga109 ESPCN[111] ImageNet Set5、Set14、BSD300、BSD500、SuperTexture MSCNNS[120] NYU Depth、Make3D NYU Depth、Make3D GDSR[112] T91、BSD200 Set5、Set14、BSD100、Urban100 ISCNN[113] BSD300 BSD300、BSD500 HAN[114] DIV2K Set5、Set14、BSD100、Urban100、Manga109 HDN[115] DIV2K Set5、Set14、BSD100、Urban100、Manga109 IMDN[116] DIV2K Set5、Set14、BSD100、Urban100、Manga109 Meta-RDN[129] DIV2K Set14、BSD100、Manga109、DIV2K Meta-USR[130] DIV2K DIV2K、Set5、Set14、BSD100、Urban100、Manga109 RSAN[131] DIV2K Set5、Set14、BSD100、Urban100 Meta-SRGAN[133] DIV2K、BraTS BraTS MIASSR[134] OASIS、BraTS、ACDC、COVID-CT OASIS、BraTS、ACDC、COVID-CT MSN[99] ILSVRC 2012、DIV2K DIV2K、Set5、Set14、BSD100、Urban100、Manga109 图像盲超分辨率 CinCGAN[55] DIV2K NTIRE2018 UISR[56] DIV2K NTIRE2018 IKC[58] DIV2K、Flickr2K Set5、Set14、BSD100 KMSR[59] DIV2K DIV2K KernelGAN[60] — NTIRE2018 DASR[61] DIV2K、Flickr2K Set5、Set14、BSD100、Urban100 BlindESRGAN[62] DIV2K、Flickr2K、WED、FFHQ DIV2K、RealSRSet RealESRGAN[45] DIV2K、Flickr2K、OutdoorSceneTraining RealSR、DRealSR、OST300、DPED、ADE20K EDKE[87] DIV2KRK RealSR MCGAN[107] CelebA CelebA MANet[76] DIV2K BSD100 S2K[108] DIV2K DIV2K、Flickr2K PCSR[126] DIV2K、VOC2012 Set5、Set14 SCHN[127] DIV2K、Flickr2K Set5、Set14 MRDA[136] DIV2K、Flickr2K Set5、Set14、BSD100、Urban100、Manga109 表 13 图像超分辨模型在Set5、Set14、BSD100、Urban100上放大倍数为2时PSNR与SSIM
Table 13 Evaluation of PSNR and SSIM results for scale factor 2 in image super-resolution on Set5, Set14, BSD100, and Urban100
方法 Set5 Set14 BSD100 Urban100 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM VDSR[17] 35.53 0.9587 33.03 0.9124 31.90 0.8960 30.76 0.9140 CMSC[40] 37.89 0.9605 33.41 0.9153 32.15 0.8992 31.47 0.9220 DRCN[20] 37.63 0.8588 33.06 0.9121 31.85 0.8942 30.76 0.9133 DRRN[43] 37.74 0.9591 33.23 0.9136 32.05 0.8973 31.23 0.9188 MemNet[39] 37.68 0.9597 33.28 0.9142 32.08 0.8987 31.31 0.9195 EDSR[44] 38.02 0.9606 34.02 0.92.4 32.37 0.9018 33.10 0.9363 MDSR[44] 38.17 0.9605 33.92 0.9203 32.34 0.9014 33.03 0.9362 RCAN[23] 38.33 0.9617 34.23 0.9225 32.46 0.9031 33.54 0.9399 LISTA[53] 37.41 0.9567 32.71 0.9095 31.54 0.8908 — — IDN[54] 37.83 0.9600 33.30 0.9148 32.08 0.8985 31.27 0.9196 CFSRCNN[46] 37.79 0.9591 33.51 0.9165 32.11 0.8988 32.07 0.9273 FSRCNN[18] 36.98 0.9556 32.62 0.9087 31.50 0.8904 29.85 0.9009 LapSRN[91] 37.52 0.9591 33.08 0.9130 31.08 0.8950 30.41 0.9101 MANet[76] 35.98 0.9420 31.95 0.8845 30.97 0.8650 29.87 0.8877 CNF[38] 37.66 0.9690 33.08 0.9136 31.91 0.8962 — — DefRCN[82] 38.02 0.9596 33.58 0.9151 32.21 0.8998 32.20 0.9286 SRFBN[93] 38.11 0.9609 33.82 0.9196 32.29 0.9010 32.62 0.9328 MSRN[99] 38.08 0.9605 33.74 0.9170 32.23 0.9013 32.22 0.9326 HAN[114] 26.83 0.7919 23.21 0.6888 25.11 0.6613 22.42 0.6571 RDN[22] 38.24 0.9614 34.01 0.9212 32.34 0.9017 32.89 0.9353 表 14 图像超分辨模型在Set5、Set14、BSD100、Urban100上放大倍数为3时PSNR与SSIM
Table 14 Evaluation of PSNR and SSIM results for scale factor 3 in image super-resolution on Set5, Set14, BSD100, and Urban100
方法 Set5 Set14 BSD100 Urban100 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM VDSR[17] 33.66 0.9213 29.77 0.8314 28.82 0.7976 27.14 0.8279 CMSC[40] 34.24 0.9266 30.09 0.8371 29.01 0.8024 27.69 0.8411 DRCN[20] 33.82 0.9226 29.77 0.8314 28.80 0.7963 27.15 0.8277 DRRN[43] 34.03 0.9244 29.96 0.8349 28.95 0.8004 27.53 0.8377 MemNet[39] 34.09 0.9248 30.00 0.8350 28.96 0.8001 27.56 0.8376 EDSR[44] 34.76 0.9290 30.66 0.8481 29.32 0.8104 29.02 0.8685 MDSR[44] 34.77 0.9288 30.53 0.8465 29.30 0.8101 28.99 0.8683 RCAN[23] 34.85 0.9305 30.76 0.8494 29.39 0.8122 29.31 0.8736 LISTA[53] 33.26 0.9167 29.55 0.8271 28.58 0.7910 — — CFSRCNN[46] 34.24 0.9256 30.27 0.8410 29.03 0.8035 28.04 0.8496 FSRCNN[18] 33.16 0.9140 29.42 0.8242 28.52 0.7893 26.41 0.8064 LapSRN[91] 33.82 0.9227 29.87 0.8320 28.82 0.7980 27.07 0.8280 MANet[76] 33.69 0.9184 29.81 0.8270 28.80 0.7931 27.39 0.8331 CNF[38] 33.74 0.9226 29.90 0.8322 28.82 0.7980 — — DefRCN[82] 34.41 0.9263 30.34 0.8388 29.01 0.8044 28.16 0.8519 SRFBN[93] 34.70 0.9292 30.51 0.8461 29.24 0.8084 28.73 0.8641 MSRN[99] 34.38 0.9262 30.34 0.8395 29.08 0.8041 28.08 0.8554 HAN[114] 23.71 0.6171 22.31 0.5878 23.21 0.5653 20.34 0.5311 RDN[22] 34.71 0.9296 30.57 0.8468 29.26 0.8093 28.80 0.8653 IDN[54] 34.11 0.9253 29.99 0.8354 28.95 0.8013 27.42 0.8359 表 15 图像超分辨模型在Set5、Set14、BSD100、Urban100上放大倍数为4时PSNR与SSIM
Table 15 Evaluation of PSNR and SSIM results for scale factor 4 in image super-resolution on Set5, Set14, BSD100, and Urban100
方法 Set5 Set14 BSD100 Urban100 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM VDSR[17] 31.35 0.8838 28.01 0.7674 27.29 0.7251 25.18 0.7524 CMSC[40] 31.91 0.8923 28.35 0.7751 27.46 0.7308 25.64 0.7692 DRCN[20] 31.53 0.8854 28.03 0.7673 27.14 0.7233 25.14 0.7511 DRRN[43] 31.68 0.8888 28.21 0.7720 27.38 0.7284 25.44 0.7638 MemNet[39] 31.74 0.8893 28.26 0.7723 27.40 0.7281 25.50 0.7630 EDSR[44] 32.62 0.8984 28.94 0.7901 27.79 0.7437 26.86 0.8080 MDSR[44] 32.60 0.8982 28.82 0.7876 27.78 0.7425 26.86 0.8082 RCAN[23] 32.73 0.9013 28.98 0.7910 27.85 0.7455 27.10 0.8142 LISTA[53] 31.04 0.8775 27.76 0.7620 27.11 0.7191 — — CFSRCNN[46] 32.06 0.8920 28.57 0.7800 27.53 0.7333 26.03 0.7824 FSRCNN[18] 30.70 0.8657 27.59 0.7535 26.96 0.7128 24.60 0.7258 LapSRN[91] 31.54 0.8850 28.19 0.7720 27.32 0.7270 25.21 0.7560 MANet[76] 31.54 0.8876 28.28 0.7727 27.35 0.7305 25.66 0.7759 CNF[38] 31.55 0.8856 28.15 0.7680 27.32 0.7253 — — DefRCN[82] 32.21 0.8936 28.59 0.7810 27.57 0.7356 26.04 0.7841 SRFBN[93] 32.47 0.8983 28.81 0.7868 27.72 0.7409 26.60 0.8015 MSRN[99] 32.07 0.8903 28.60 0.7751 27.52 0.7273 26.04 0.7896 HAN[114] 21.71 0.5941 20.42 0.4937 21.48 0.4901 19.01 0.4676 RDN[22] 32.47 0.8990 28.81 0.7871 27.72 0.7419 26.61 0.8028 IDN[54] 31.82 0.8903 28.25 0.7730 27.41 0.7297 25.41 0.7632 表 16 图像超分辨模型在256×256、512×512和
1024 ×1024 大小的图像和放大倍数为2时的运行时间Table 16 Runtime for image super-resolution models on images of size 256×256, 512×512, and
1024 ×1024 with scale factor of 2s 表 17 图像超分辨模型的复杂度
Table 17 Complexity of image super-resolution models
表 18 图像盲超分辨模型在Set5、Set14数据集上放大倍数为2、3和4时PSNR与SSIM
Table 18 PSNR and SSIM for blind super-resolution models on Set5 and Set14 datasets at ×2, ×3, and ×4 magnifications
方法 指标 放大倍数为2 放大倍数为3 放大倍数为4 Set5 Set14 Set5 Set14 Set5 Set14 IKC[48] PSNR/dB 36.62 32.82 32.16 29.46 31.52 28.26 SSIM 0.9658 0.8999 0.9420 0.8229 0.9278 0.7688 DASR[61] PSNR/dB 37.87 33.34 34.11 30.13 31.99 28.50 SSIM — — — — — — PCSR[126] PSNR/dB 31.49 29.88 — — 29.20 26.82 SSIM 0.909 0.856 — — 0.807 0.694 SCHN[127] PSNR/dB 33.70 29.64 — — 27.81 24.70 SSIM 0.9310 0.8689 — — 0.8339 0.7056 -
[1] 史振威, 雷森. 图像超分辨重建算法综述[J]. 数据采集与处理, 2020, 35(1): 1−20. SHI Zhenwei, LEI Sen. Review of image super-resolution reconstruction[J]. Journal of data acquisition and processing, 2020, 35(1): 1−20. [2] ZHANG Liangpei, ZHANG Hongyan, SHEN Huanfeng, et al. A super-resolution reconstruction algorithm for surveillance images[J]. Signal processing, 2010, 90(3): 848−859. doi: 10.1016/j.sigpro.2009.09.002 [3] CHAN K C K, ZHOU Shangchen, XU Xiangyu, et al. BasicVSR: improving video super-resolution with enhanced propagation and alignment[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans: IEEE, 2022: 5962−5971. [4] RUKUNDO O, CAO Hanqiang. Nearest neighbor value interpolation[EB/OL]. (2012−11−08)[2024−01−01]. https://arxiv.org/abs/1211.1768v2. [5] ELAD M, FEUER A. Restoration of a single superresolution image from several blurred, noisy, and undersampled measured images[J]. IEEE transactions on image processing, 1997, 6(12): 1646−1658. doi: 10.1109/83.650118 [6] PRAJAPATI A, NAIK S, MEHTA S. Evaluation of different image interpolation algorithms[J]. International journal of computer applications, 2012, 58(12): 6−12. doi: 10.5120/9332-3638 [7] YANG Jianchao, WRIGHT J, HUANG T S, et al. Image super-resolution via sparse representation[J]. IEEE transactions on image processing, 2010, 19(11): 2861−2873. doi: 10.1109/TIP.2010.2050625 [8] CHEESEMAN P, KANEFSKY B, KRAFT R, et al. Super-resolved surface reconstruction from multiple images[M]//Maximum Entropy and Bayesian Methods. Dordrecht: Springer Netherlands, 1996: 293−308. [9] IRANI M, PELEG S. Super resolution from image sequences[C]// Proceedings 10th International Conference on Pattern Recognition. Atlantic City: IEEE, 1990: 115−120. [10] KOMATSU T, IGARASHI T, AIZAWA K, et al. Very high resolution imaging scheme with multiple different-aperture cameras[J]. Signal processing: image communication, 1993, 5(5/6): 511−526. [11] AGUENA M, MASCARENHAS N. Generalization of iterative restoration techniques for super-resolution[C]//2011 24th SIBGRAPI Conference on Graphics, Patterns and Images. Alagoas: IEEE, 2011: 258−265. [12] GAO Xinbo, ZHANG Kaibing, TAO Dacheng, et al. Image super-resolution with sparse neighbor embedding[J]. IEEE transactions on image processing, 2012, 21(7): 3194−3205. doi: 10.1109/TIP.2012.2190080 [13] VAN OUWERKERK J D. Image super-resolution survey[J]. Image and vision computing, 2006, 24(10): 1039−1052. doi: 10.1016/j.imavis.2006.02.026 [14] YU Hong, XIANG Ma, HUA Huang, et al. Face image super-resolution through POCS and residue compensation[C]//2008 5th International Conference on Visual Information Engineering (VIE 2008). Xi’an: IET, 2008: 494−497. [15] TIAN Chunwei, ZHANG Xuanyu, ZHU Qi, et al. Generative adversarial networks for image super-resolution: a survey[EB/OL]. (2022−04−28)[2024−01−01]. https://arxiv.org/abs/2204.13620v4. [16] DONG Chao, LOY C C, HE Kaiming, et al. Image super-resolution using deep convolutional networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 38(2): 295−307. doi: 10.1109/TPAMI.2015.2439281 [17] KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1646−1654. [18] DONG Chao, LOY C C, TANG Xiaoou. Accelerating the super-resolution convolutional neural network[C]//Computer Vision–ECCV 2016. Amsterdam: Springer International Publishing, 2016: 391−407. [19] CHOI J S, KIM M. A deep convolutional neural network with selection units for super-resolution[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu: IEEE, 2017: 1150−1156. [20] KIM J, LEE J K, LEE K M. Deeply-recursive convolutional network for image super-resolution[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1637−1645. [21] TONG Tong, LI Gen, LIU Xiejie, et al. Image super-resolution using dense skip connections[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 4809−4817. [22] ZHANG Yulun, TIAN Yapeng, KONG Yu, et al. Residual dense network for image super-resolution[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 2472−2481. [23] ZHANG Yulun, LI Kunpeng, LI Kai, et al. Image super-resolution using very deep residual channel attention networks[C]//Computer Vision–ECCV 2018. Cham: Springer International Publishing, 2018: 294−310. [24] DAI Tao, CAI Jianrui, ZHANG Yongbing, et al. Second-order attention network for single image super-resolution[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 11057−11066. [25] LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 105−114. [26] WANG Xintao, YU Ke, WU Shixiang, et al. ESRGAN: enhanced super-resolution generative adversarial networks[C]//Computer Vision– ECCV 2018 Workshops. Cham: Springer International Publishing, 2019: 63−79. [27] 王凡超, 丁世飞. 基于广泛激活深度残差网络的图像超分辨率重建[J]. 智能系统学报, 2022, 17(2): 440−446. doi: 10.11992/tis.202106023 WANG Fanchao, DING Shifei. Image super-resolution reconstruction based on widely activated deep residual networks[J]. CAAI transactions on intelligent systems, 2022, 17(2): 440−446. doi: 10.11992/tis.202106023 [28] 刘玉铠, 周登文. 基于多路特征渐进融合和注意力机制的轻量级图像超分辨率重建[J]. 智能系统学报, 2024, 19(4): 863−873. doi: 10.11992/tis.202209045 LIU Yukai, ZHOU Dengwen. Lightweight super-resolution reconstruction via progressive multi-path feature fusion and attention mechanism[J]. CAAI transactions on intelligent systems, 2024, 19(4): 863−873. doi: 10.11992/tis.202209045 [29] YANG Wenming, ZHANG Xuechen, TIAN Yapeng, et al. Deep learning for single image super-resolution: a brief review[J]. IEEE transactions on multimedia, 2019, 21(12): 3106−3121. doi: 10.1109/TMM.2019.2919431 [30] SUN Jian, SUN Jian, XU Zongben, et al. Gradient profile prior and its applications in image super-resolution and enhancement[J]. IEEE transactions on image processing, 2011, 20(6): 1529−1542. doi: 10.1109/TIP.2010.2095871 [31] WANG Zhihao, CHEN Jian, HOI S C H. Deep learning for image super-resolution: a survey[J]. IEEE transactions on pattern analysis and machine intelligence, 2021, 43(10): 3365−3387. doi: 10.1109/TPAMI.2020.2982166 [32] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2014−12−23)[2024−01−01]. https://arxiv.org/abs/1409.1556v6. [33] CHEN Jin, ZHU Xiaolin, VOGELMANN J E, et al. A simple and effective method for filling gaps in Landsat ETM+ SLC-off images[J]. Remote sensing of environment, 2011, 115(4): 1053−1064. doi: 10.1016/j.rse.2010.12.010 [34] PARK S C, PARK M K, KANG M G. Super-resolution image reconstruction: a technical overview[J]. IEEE signal processing magazine, 2003, 20(3): 21−36. doi: 10.1109/MSP.2003.1203207 [35] KEYS R. Cubic convolution interpolation for digital image processing[J]. IEEE transactions on acoustics, speech, and signal processing, 1981, 29(6): 1153−1160. doi: 10.1109/TASSP.1981.1163711 [36] KIRKLAND E J. Advanced computing in electron microscopy[M]. Boston: Springer US, 1998. [37] 周登文, 赵丽娟, 段然, 等. 基于递归残差网络的图像超分辨率重建[J]. 自动化学报, 2019, 45(6): 1157−1165. doi: 10.16383/j.aas.c180334 ZHOU Dengwen, ZHAO Lijuan, DUAN Ran, et al. Image super-resolution based on recursive residual networks[J]. ACTA AUTOMATICA SINICA, 2019, 45(6): 1157−1165. doi: 10.16383/j.aas.c180334 [38] REN Haoyu, EL-KHAMY M, LEE J. Image super resolution based on fusing multiple convolution neural networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu: IEEE, 2017: 1050−1057. [39] TAI Ying, YANG Jian, LIU Xiaoming, et al. MemNet: a persistent memory network for image restoration[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 4549−4557. [40] HU Yanting, GAO Xinbo, LI Jie, et al. Single image super-resolution via cascaded multi-scale cross network[EB/OL]. (2018−02−24)[2024−01−01]. https://arxiv.org/abs/1802.08808v1. [41] YAMANAKA J, KUWASHIMA S, KURITA T. Fast and accurate image super resolution by deep CNN with skip connection and network in network[EB/OL].(2017−07−18)[2024−01−01]. https://arxiv.org/abs/1707.05425. [42] 陈子涵, 吴浩博, 裴浩东, 等. 基于自注意力深度网络的图像超分辨率重建方法[J]. 激光与光电子学进展, 2021, 58(4): 0410013. CHEN Zihan, WU Haobo, PEI Haodong, et al. Image super-resolution reconstruction method based on self-attention deep network[J]. Laser & optoelectronics progress, 2021, 58(4): 0410013. [43] TAI Ying, YANG Jian, LIU Xiaoming. Image super-resolution via deep recursive residual network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2790−2798. [44] LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu: IEEE, 2017: 1132−1140. [45] WANG Xintao, XIE Liangbin, DONG Chao, et al. Real-ESRGAN: training real-world blind super-resolution with pure synthetic data[C]//2021 IEEE/CVF International Conference on Computer Vision Workshops. Montreal: IEEE, 2021: 1905−1914. [46] TIAN Chunwei, XU Yong, ZUO Wangmeng, et al. Coarse-to-fine CNN for image super-resolution[J]. IEEE transactions on multimedia, 2020, 23: 1489−1502. [47] RAD M S, YU T, MUSAT C, et al. Benefiting from bicubically down-sampled images for learning real-world image super-resolution[C]//2021 IEEE Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2021: 1590−1599. [48] DEMIRAY B Z, SIT M, DEMIR I. D-SRGAN: DEM super-resolutionwith generative adversarial networks[J]. SN computer science, 2021, 2(1): 48. doi: 10.1007/s42979-020-00442-2 [49] ZHANG Lina, DAI Haidong, SANG Yu. Med-SRNet: GAN-based medical image super-resolution via high-resolution representation learning[J]. Computational intelligence and neuroscience, 2022, 2022(1): 1744969. [50] WANG Yifan, PERAZZI F, MCWILLIAMS B, et al. A fully progressive approach to single-image super-resolution[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City: IEEE, 2018: 97701−97709. [51] NI Min, LEI Jianjun, CONG Runmin, et al. Color-guided depth map super resolution using convolutional neural network[J]. IEEE access, 2017, 5: 26666−26672. doi: 10.1109/ACCESS.2017.2773141 [52] HAN Xianhua, SHI Boxin, ZHENG Yinqiang. SSF-CNN: spatial and spectral fusion with CNN for hyperspectral image super-resolution[C]//2018 25th IEEE International Conference on Image Processing. Athens: IEEE, 2018: 2506−2510. [53] WANG Zhaowen, LIU Ding, YANG Jianchao, et al. Deep networks for image super-resolution with sparse prior[C]//2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 370−378. [54] HUI Zheng, WANG Xiumei, GAO Xinbo. Fast and accurate single image super-resolution via information distillation network[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 723−731. [55] YUAN Yuan, LIU Siyuan, ZHANG Jiawei, et al. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City: IEEE, 2018: 81401−81409. [56] MAEDA S. Unpaired image super-resolution using pseudo-supervision[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 291−300. [57] ZHANG Kai, ZUO Wangmeng, ZHANG Lei. Deep plug-and-play super-resolution for arbitrary blur kernels[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 1671−1681. [58] GU Jinjin, LU Hannan, ZUO Wangmeng, et al. Blind super-resolution with iterative kernel correction[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 1604−1613. [59] ZHOU Ruofan, SUSSTRUNK S. Kernel modeling super-resolution on real low-resolution images[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 2433−2443. [60] KLIGLER S B, SHOCHER A, IRANI M. Blind super-resolution kernel estimation using an internal-GAN[EB/OL]. (2019−09−14)[2024−01−01]. https://arxiv.arg.org/abs/1909.06581. [61] WANG Longguang, WANG Yingqian, DONG Xiaoyu, et al. Unsupervised degradation representation learning for blind super-resolution[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 10581−10590. [62] ZHANG Kai, LIANG Jingyun, VAN GOOL L, et al. Designing a practical degradation model for deep blind image super-resolution[C]//2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 4771−4780. [63] ZHANG Jiahui, LU Shijian, ZHAN Fangneng, et al. Blind image super-resolution via contrastive representation learning[EB/OL]. (2021−07−01)[2024−01−01]. https://arxiv.org/abs/2107.00708v1. [64] WU Yixuan, LI Feng, BAI Huihui, et al. Bridging component learning with degradation modelling for blind image super-resolution[J]. IEEE transactions on multimedia, 2022(99): 1−16. [65] CAO Xiang, LUO Yihao, XIAO Yi, et al. Blind image super-resolution based on prior correction network[J]. Neurocomputing, 2021, 463: 525−534. doi: 10.1016/j.neucom.2021.07.070 [66] YAMAWAKI K, SUN Yongqing, HAN Xianhua. Blind image super resolution using deep unsupervised learning[J]. Electronics, 2021, 10(21): 2591. doi: 10.3390/electronics10212591 [67] YAMAWAKI K, HAN Xianhua. Deep blind un-supervised learning network for single image super resolution[C]//2021 IEEE International Conference on Image Processing. Anchorage: IEEE, 2021: 1789−1793. [68] 丁宇胜. 数字图像处理中的插值算法研究[J]. 电脑知识与技术, 2010, 6(16): 4502−4503,4506. doi: 10.3969/j.issn.1009-3044.2010.16.075 DING Yusheng. Interpolated algorithm research in digital image processing[J]. Computer knowledge and technology, 2010, 6(16): 4502−4503,4506. doi: 10.3969/j.issn.1009-3044.2010.16.075 [69] ZHANG Kai, VAN GOOL L, TIMOFTE R. Deep unfolding network for image super-resolution[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 3217−3226. [70] FAN Yuchen, SHI Honghui, YU Jiahui, et al. Balanced two-stage residual networks for image super-resolution[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu: IEEE, 2017: 1157−1164. [71] SAJJADI M S M, SCHÖLKOPF B, HIRSCH M. EnhanceNet: single image super-resolution through automated texture synthesis[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 4501−4510. [72] SHANG Taizhang, DAI Qiuju, ZHU Shengchen, et al. Perceptual extreme super resolution network with receptive field block[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: IEEE, 2020: 440−441. [73] ZHAO Hengyuan, KONG Xiangtao, HE Jingwen, et al. Efficient image super-resolution using pixel attention[EB/OL]. (2020−10−02)[2024−01−01]. https://arxiv.arg.org/abs/2010.01073. [74] HUANG Zilong, WANG Xinggang, HUANG Lichao, et al. CCNet: criss-cross attention for semantic segmentation[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 603−612. [75] JO Y, KIM S J. Practical single-image super-resolution using look-up table[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 691−700. [76] LIANG Jingyun, SUN Guolei, ZHANG Kai, et al. Mutual affine network for spatially variant kernel estimation in blind image super-resolution[C]//2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 4076−4085. [77] HE Zongyao, JIN Zhi, ZHAO Yao. SRDRL: a blind super-resolution framework with degradation reconstruction loss[J]. IEEE transactions on multimedia, 2021, 24: 2877−2889. [78] YOUM G Y, BAE S H, KIM M. Image super-resolution based on convolution neural networks using multi-channel input[C]//2016 IEEE 12th Image, Video, and Multidimensional Signal Processing Workshop. Bordeaux: IEEE, 2016: 1−5. [79] INTANIYOM T, THANANPORN W, WORARATPANYA K. Enhancement of anime imaging enlargement using modified super-resolution CNN[C]//2021 13th International Conference on Information Technology and Electrical Engineering. Chiang Mai: IEEE, 2021: 226−231. [80] VU T, NGUYEN C V, PHAM T X, et al. Fast and efficient image quality enhancement via desubpixel convolutional neural networks[C]//ECCV 2018. Munich: Springer International Publishing, 2019: 243−259. [81] LIU Hong, LU Zhisheng, SHI Wei, et al. A fast and accurate super-resolution network using progressive residual learning[C]//2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Barcelona: IEEE, 2020: 1818−1822. [82] ZHANG Yan, SUN Yemei, LIU Shudong. Deformable and residual convolutional network for image super-resolution[J]. Applied intelligence, 2022, 52(1): 295−304. doi: 10.1007/s10489-021-02246-0 [83] KIM G, PARK J, LEE K, et al. Unsupervised real-world super resolution with cycle generative adversarial network and domain discriminator[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: IEEE, 2020: 1862−1871. [84] FAN Yuchen, YU Jiahui, LIU Ding, et al. Scale-wise convolution for image restoration[EB/OL]. (2019−12−19)[2024−01−01]. https://arxiv.org/abs/1912.09028. [85] SURYANARAYANA G, CHANDRAN K, KHALAF O I, et al. Accurate magnetic resonance image super-resolution using deep networks and Gaussian filtering in the stationary wavelet domain[J]. IEEE access, 2021, 9: 71406−71417. doi: 10.1109/ACCESS.2021.3077611 [86] UMER R M, MUNIR A, MICHELONI C. A deep residual star generative adversarial network for multi-domain image super-resolution[C]//2021 6th International Conference on Smart and Sustainable Technologies. Bol and Split: IEEE, 2021: 1−5. [87] ZHU Mingyan, DAI Tao, XIA Shutao, et al. EDKE: encoder-decoder based kernel estimation for blind image super-resolution[C]//2021 International Joint Conference on Neural Networks. Shenzhen: IEEE, 2021: 1−7. [88] WEI Yunxuan, GU Shuhang, LI Yawei, et al. Unsupervised real-world image super resolution via domain-distance aware training[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 13385−13394. [89] LI Yue, LIU Dong, LI Houqiang, et al. Convolutional neural network-based block up-sampling for intra frame coding[J]. IEEE transactions on circuits and systems for video technology, 2018, 28(9): 2316−2330. doi: 10.1109/TCSVT.2017.2727682 [90] MAO X, SHEN C, YANG Y B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections[J]. Advances in neural information processing systems, 2016, 29. [91] LAI Weisheng, HUANG Jiabin, AHUJA N, et al. Fast and accurate image super-resolution with deep Laplacian pyramid networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2019, 41(11): 2599−2613. doi: 10.1109/TPAMI.2018.2865304 [92] SHI Jun, LI Zheng, YING Shihui, et al. MR image super-resolution via wide residual networks with fixed skip connection[J]. IEEE journal of biomedical and health informatics, 2019, 23(3): 1129−1140. doi: 10.1109/JBHI.2018.2843819 [93] LI Zhen, YANG Jinglei, LIU Zheng, et al. Feedback network for image super-resolution[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 3862−3871. [94] ZENG Kai, DING Shifei, JIA Weikuan. Single image super-resolution using a polymorphic parallel CNN[J]. Applied intelligence, 2019, 49(1): 292−300. doi: 10.1007/s10489-018-1270-7 [95] HARIS M, SHAKHNAROVICH G, UKITA N. Deep back-projection networks for super-resolution[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 1664−1673. [96] YANG Xin, MEI Haiyang, ZHANG Jiqing, et al. DRFN: deep recurrent fusion network for single-image super-resolution with large factors[J]. IEEE transactions on multimedia, 2019, 21(2): 328−337. doi: 10.1109/TMM.2018.2863602 [97] ZHONG Zhisheng, SHEN Tiancheng, YANG Yibo, et al. Joint sub-bands learning with clique structures for wavelet domain super-resolution[EB/OL]. (2018−10−25)[2024−01−01]. https://arxiv.org/abs/1809.04508v3. [98] WANG Yifan, WANG Lijun, WANG Hongyu, et al. End-to-end image super-resolution via deep and shallow convolutional networks[J]. IEEE access, 2019, 7: 31959−31970. doi: 10.1109/ACCESS.2019.2903582 [99] LI Juncheng, FANG Faming, MEI Kangfu, et al. Multi-scale residual network for image super-resolution[C]// Computer Vision-ECCV 2018. Cham: Springer International Publishing, 2018: 527−542. [100] TAN Congming, CHENG Shuli, WANG Liejun. Efficient image super-resolution via self-calibrated feature fuse[J]. Sensors, 2022, 22(1): 329. doi: 10.3390/s22010329 [101] CHENG Jianxin, KUANG Qiuming, SHEN Chenkai, et al. ResLap: generating high-resolution climate prediction through image super-resolution[J]. IEEE access, 2020, 8: 39623−39634. doi: 10.1109/ACCESS.2020.2974785 [102] JIA Sen, WANG Zhihao, LI Qingquan, et al. Multiattention generative adversarial network for remote sensing image super-resolution[J]. IEEE transactions on geoscience and remote sensing, 2022, 60: 5624715. [103] CHEN Yuantao, XIA Runlong, YANG Kai, et al. MFFN: image super-resolution via multi-level features fusion network[J]. The visual computer, 2024, 40(2): 489−504. doi: 10.1007/s00371-023-02795-0 [104] ZHANG Xiaomin. Uncertainty-driven mixture convolution and transformer network for remote sensing image super-resolution[J]. Scientific reports, 2024, 14: 9435. doi: 10.1038/s41598-024-59384-x [105] BAI Haomou, LIANG Xiao. A very lightweight image super-resolution network[J]. Scientific reports, 2024, 14(1): 13850. doi: 10.1038/s41598-024-64724-y [106] DARGAHI S, AGHAGOLZADEH A, EZOJI M. Single image super-resolution by cascading parallel-structure units through a deep-shallow CNN[J]. Optik, 2023, 286: 171001. doi: 10.1016/j.ijleo.2023.171001 [107] XU Xiangyu, SUN Deqing, PAN Jinshan, et al. Learning to super-resolve blurry face and text images[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 251−260. [108] TAO G, JI X, WANG W, et al. Spectrum-to-kernel translation for accurate blind image super-resolution[J]. Advances in neural information processing systems, 2021, 34: 22643−22654. [109] FANG Zhenxuan, DONG Weisheng, LI Xin, et al. Uncertainty learning in kernel estimation for multi-stage blind image super-resolution[C]//ECCV 2022. Tel Aviv: Springer Nature Switzerland, 2022: 144−161. [110] DU Yanbin, JIA Ruisheng, CUI Zhe, et al. X-ray image super-resolution reconstruction based on a multiple distillation feedback network[J]. Applied intelligence, 2021, 51(7): 5081−5094. doi: 10.1007/s10489-020-02123-2 [111] SHI Wenzhe, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1874−1883. [112] SONG Zhaoyang, ZHAO Xiaoqiang, JIANG Hongmei. Gradual deep residual network for super-resolution[J]. Multimedia tools and applications, 2021, 80(7): 9765−9778. doi: 10.1007/s11042-020-10152-9 [113] JIANG Pengfei, LIN Weiguo, SHANG Wenqian. Single image super-resolution model based on improved sub-pixel convolutional neural network[C]//2021 IEEE International Conference on Power Electronics, Computer Applications. Shenyang: IEEE, 2021: 132−136. [114] NIU Ben, WEN Weilei, REN Wenqi, et al. Single image super-resolution via a holistic attention network[C]//ECCV 2020. Glasgow: Springer International Publishing, 2020: 191−207. [115] JIANG Kui, WANG Zhongyuan, YI Peng, et al. Hierarchical dense recursive network for image super-resolution[J]. Pattern recognition, 2020, 107: 107475. doi: 10.1016/j.patcog.2020.107475 [116] HUI Zheng, GAO Xinbo, YANG Yunchu, et al. Lightweight image super-resolution with information multi-distillation network[C]//Proceedings of the 27th ACM International Conference on Multimedia. Nice: ACM, 2019: 2024−2032. [117] WU Gang, JIANG Junjun, JIANG Kui, et al. Fully 1×1 convolutional network for lightweight image super-resolution[EB/OL]. (2023−07−30)[2024−01−01]. https://arxiv.org/abs/2307.16140v2. [118] DING Xiaohan, ZHANG X, ZHOU Yizhuang, et al. Scaling up your kernels to 31 × 31: revisiting large kernel design in CNNs[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. New Orleans: IEEE. 2022: 11963−11975. [119] WANG Yan, LI Yusen, WANG Gang, et al. Multi-scale attention network for single image super-resolution[C]//2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: IEEE, 2024: 5950−5960. [120] ZHAO Shiyu, ZHANG Lin, SHEN Ying, et al. Super-resolution for monocular depth estimation with multi-scale sub-pixel convolutions and a smoothness constraint[J]. IEEE access, 2019, 7: 16323−16335. doi: 10.1109/ACCESS.2019.2894651 [121] RUAN Haihang, TAN Zhiyong, CHEN Liangtao, et al. Efficient sub-pixel convolutional neural network for terahertz image super-resolution[J]. Optics letters, 2022, 47(12): 3115−3118. doi: 10.1364/OL.454267 [122] XIE Chengxing, ZHANG Xiaoming, LI Linze, et al. Large kernel distillation network for efficient single image super-resolution[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Vancouver: IEEE, 2023: 1283−1292. [123] FANG Jinsheng, LIN Hanjiang, CHEN Xinyu, et al. A hybrid network of CNN and transformer for lightweight image super-resolution[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New Orleans: IEEE, 2022: 1102−1111. [124] KONG Fangyuan, LI Mingxi, LIU Songwei, et al. Residual local feature network for efficient super-resolution[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New Orleans: IEEE, 2022: 765−775. [125] TIAN Chunwei, ZHANG Xuanyu, ZHANG Qi, et al. Image super-resolution via dynamic network[J]. CAAI transactions on intelligence technology, 2024, 9(4): 837−849. doi: 10.1049/cit2.12297 [126] XIAO Jun, ZHAO Rui, LAI S C, et al. Deep progressive convolutional neural network for blind super-resolution with multiple degradations[C]//2019 IEEE International Conference on Image Processing. Taipei: IEEE, 2019: 2856−2860. [127] HUO Dong, YANG Y H. Blind image super-resolution with spatial context hallucination[EB/OL]. (2020−09−25)[2024−01−01]. https://arxiv.org/abs/2009.12461v1. [128] DONG Runmin, ZHANG Lixian, FU Haohuan. Blind super-resolution on remote sensing images with blur kernel prediction[C]//2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS. Brussels: IEEE, 2021: 2879−2882. [129] HU Xuecai, MU Haoyuan, ZHANG Xiangyu, et al. Meta-SR: a magnification-arbitrary network for super-resolution[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 1575−1584. [130] HU Xuecai, ZHANG Zhang, SHAN Caifeng, et al. Meta-USR: a unified super-resolution network for multiple degradation parameters[J]. IEEE transactions on neural networks and learning systems, 2021, 32(9): 4151−4165. doi: 10.1109/TNNLS.2020.3016974 [131] FU Ying, CHEN Jian, ZHANG Tao, et al. Residual scale attention network for arbitrary scale image super-resolution[J]. Neurocomputing, 2021, 427: 201−211. doi: 10.1016/j.neucom.2020.11.010 [132] LI Huafeng, CEN Yueliang, LIU Yu, et al. Different input resolutions and arbitrary output resolution: a meta learning-based deep framework for infrared and visible image fusion[J]. IEEE transactions on image processing, 2021, 30: 4070−4083. doi: 10.1109/TIP.2021.3069339 [133] TAN Chuan, ZHU Jin, LIO’ P. Arbitrary scale super-resolution for brain MRI images[M]//Artificial Intelligence Applications and Innovations. Cham: Springer International Publishing, 2020: 165−176. [134] ZHU Jin, TAN Chuan, YANG Junwei, et al. MIASSR: an approach for medical image arbitrary scale super-resolution[EB/OL]. (2021−05−22)[2024−01−01]. https://arxiv.org/abs/2105.10738v1. [135] HONG Danfeng, YAO Jing, LI Chenyu, et al. Decoupled-and-coupled networks: self-supervised hyperspectral image super-resolution with subpixel fusion[J]. IEEE transactions on geoscience and remote sensing, 2023, 61: 5527812. [136] XIA Bin, TIAN Yapeng, ZHANG Yulun, et al. Meta-learning-based degradation representation for blind super-resolution[J]. IEEE transactions on image processing, 2023, 32: 3383−3396. doi: 10.1109/TIP.2023.3283922 [137] DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami: IEEE, 2009: 248−255. [138] ARBELÁEZ P, MAIRE M, FOWLKES C, et al. Contour detection and hierarchical image segmentation[J]. IEEE transactions on pattern analysis and machine intelligence, 2011, 33(5): 898−916. doi: 10.1109/TPAMI.2010.161 [139] TIMOFTE R, AGUSTSSON E, GOOL L V, et al. NTIRE 2017 challenge on single image super-resolution: methods and results[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu: IEEE, 2017: 1110−1121. [140] CHAKRABARTI A, ZICKLER T. Statistics of real-world hyperspectral images[C]//CVPR 2011. Colorado: IEEE, 2011: 193−200. [141] HUANG Jiabin, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 5197−5206. [142] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[C]//ECCV 2014. Zurich: Springer International Publishing, 2014: 740−755. [143] WANG Xintao, YU Ke, DONG Chao, et al. Recovering realistic texture in image super-resolution by deep spatial feature transform[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 606−615. [144] GU Shuhang, LUGMAYR A, DANELLJAN M, et al. DIV8K: DIVerse 8K resolution image dataset[C]//2019 IEEE/CVF International Conference on Computer Vision Workshop. Seoul: IEEE, 2019: 3512−3516. [145] MA Kede, DUANMU Zhengfang, WU Qingbo, et al. Waterloo exploration database: new challenges for image quality assessment models[J]. IEEE transactions on image processing, 2017, 26(2): 1004−1016. doi: 10.1109/TIP.2016.2631888 [146] KARRAS T, LAINE S, AILA Timo. A style-based generator architecture for generative adversarial networks[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 4401−4410. [147] IKUTA H, OGAKI K, ODAGIRI Y. Blending texture features from multiple reference images for style transfer[C]//SIGGRAPH ASIA 2016 Technical Briefs. Macau: ACM, 2016: 1−4. [148] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from RGBD images[C]//ECCV 2012. Florence: Springer Berlin Heidelberg, 2012: 746−760. [149] SAXENA A, SUN Min, NG A Y. Learning 3-D scene structure from a single still image[C]//2007 IEEE 11th International Conference on Computer Vision. Rio de Janeiro: IEEE, 2007: 1−8. [150] MARCUS D S, WANG T H, PARKER J, et al. Open access series of imaging studies (OASIS): cross-sectional MRI data in young, middle aged, nondemented, and demented older adults[J]. Journal of cognitive neuroscience, 2007, 19(9): 1498−1507. doi: 10.1162/jocn.2007.19.9.1498 [151] MENZE B H, JAKAB A, BAUER S, et al. The multimodal brain tumor image segmentation benchmark (BRATS)[J]. IEEE transactions on medical imaging, 2015, 34(10): 1993−2024. doi: 10.1109/TMI.2014.2377694 [152] BERNARD O, LALANDE A, ZOTTI C, et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: is the problem solved?[J]. IEEE transactions on medical imaging, 2018, 37(11): 2514−2525. doi: 10.1109/TMI.2018.2837502 [153] AN P, XU S, HARMON S A, et al. CT images in COVID-19 [data set][J]. The cancer imaging archive, 2020, 10: 32. [154] SCHAEFER G, STICH M. UCID: an uncompressed color image database[C]//Storage and Retrieval Methods and Applications for Multimedia 2004. San Jose: SPIE, 2003: 472−480. [155] BEVILACQUA M, ROUMY A, GUILLEMOT C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding[C]//Proceedings ofthe British Machine Vision Conference. Surrey: British Machine Vision Association, 2012. [156] ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations[C]//Curves and Surfaces. Berlin: Springer Berlin Heidelberg, 2012: 711−730. [157] MATSUI Y, ITO K, ARAMAKI Y, et al. Sketch-based manga retrieval using manga109 dataset[J]. Multimedia tools and applications, 2017, 76(20): 21811−21838. doi: 10.1007/s11042-016-4020-z [158] YASUMA F, MITSUNAGA T, ISO D, et al. Generalized assorted pixel camera: postcapture control of resolution, dynamic range, and spectrum[J]. 2010, 19(9): 2241−2253. [159] XU Jun, LI Hui, LIANG Zhetong, et al. Real-world noisy image denoising: a new benchmark[EB/OL]. (2018−04−07)[2024−01−01]. https://arxiv.org/abs/1804.02603v1. [160] BLAU Y, MECHREZ R, TIMOFTE R, et al. The 2018 PIRM challenge on perceptual image super-resolution[C]// Computer Vision-ECCV 2018 Workshops. Cham: Springer International Publishing, 2019: 334−355. [161] MARTIN D, FOWLKES C, TAL D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]//Proceedings Eighth IEEE International Conference on Computer Vision. Vancouver: IEEE, 2001: 416−423. [162] IWANIEC T, MARTIN G. Geometric function theory and nonlinear analysis[M]. Oxford: Oxford University Press, 2001. [163] DAI D, TIMOFTE R, VAN GOOL L. Jointly optimized regressors for image super-resolution[J]. Computer graphics forum, 2015, 34(2): 95−104. doi: 10.1111/cgf.12544 [164] LIU Ziwei, LUO Ping, WANG Xiaogang, et al. Deep learning face attributes in the wild[C]//2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 3730−3738. [165] EVERINGHAM M, ALI ESLAMI S M, VAN GOOL L, et al. The pascal visual object classes challenge: a retrospective[J]. International journal of computer vision, 2015, 111(1): 98−136. doi: 10.1007/s11263-014-0733-5 [166] TIMOFTE R, GU Shuhang, WU Jiqing, et al. Ntire 2018 challenge on single image super-resolution: Methods and results[C]//Proceedings of the IEEE conference on computer vision and pattern recognition workshops. Salt Lake City: IEEE, 2018: 852−863. [167] IGNATOV A, KOBYSHEV N, TIMOFTE R, et al. DSLR-quality photos on mobile devices with deep convolutional networks[C]//2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 3297−3305. [168] ZHOU Bolei, ZHAO Hang, PUIG X, et al. Semantic understanding of scenes through the ADE20K dataset[J]. International journal of computer vision, 2019, 127(3): 302−321. doi: 10.1007/s11263-018-1140-0 [169] CAI Jianrui, ZENG Hui, YONG Hongwei, et al. Toward real-world single image super-resolution: a new benchmark and a new model[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 3086−3095. [170] WEI Pengxu, XIE Ziwei, LU Hannan, et al. Component divide-and-conquer for real-world image super-resolution[C]//ECCV 2020. Glasgow: Springer International Publishing, 2020: 101−117. [171] HORÉ A, ZIOU D. Image quality metrics: PSNR vs. SSIM[C]//2010 20th International Conference on Pattern Recognition. Istanbul: IEEE, 2010: 2366−2369. [172] WANG Zhou, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE transactions on image processing, 2004, 13(4): 600−612. doi: 10.1109/TIP.2003.819861 [173] AHN N, KANG B, SOHN K A. Fast, accurate, and lightweight super-resolution with cascading residual network[C]//Computer Vision–ECCV 2018. Cham: Springer International Publishing, 2018: 256−272. [174] TIAN Chunwei, ZHUGE Ruibin, WU Zhihao, et al. Lightweight image super-resolution with enhanced CNN[J]. Knowledge-based systems, 2020, 205: 106235. doi: 10.1016/j.knosys.2020.106235





























