
Doctor recommendation approach for online healthcare platforms
-
摘要: 近年来,随着智慧医疗的日益普及,在线医疗平台已逐步发展为满足大众基本医疗需求的重要渠道。为患者推荐合适的医生是在线问诊中的一个重要过程,优化推荐能力不仅可以提高患者的满意度,还能够推动在线医疗平台的发展。与传统推荐系统不同,医生推荐领域受到隐私保护限制,无法查看患者曾经的诊疗历史,因此模型训练时仅能利用每位患者最近一次的就诊记录,面临严峻的数据稀疏问题。同样,模型预测时也仅能根据患者当前的疾病描述文本进行推荐,而由于患者对疾病描述方式的差异性,模型对不同患者的推荐能力也存在差异,这会使部分患者的需求无法得到满足,进而影响模型整体的推荐能力。基于此,本文提出了一种基于数据增强的医生推荐方法(sequential three-way decision with data augmentation, STWD-NA),通过引入不匹配的医患交互信息扩充训练数据,并利用序贯三支决策的思想训练模型。具体来说,该方法由两部分组成:一方面引入了不匹配交互信息的方法,以缓解训练冷启动问题;另一方面,提出了一种基于序贯三支决策的训练算法,以动态调整模型训练时的关注度。最后,通过好大夫平台上的真实数据集验证了本文所提STWD-NA方法的有效性。Abstract: Online healthcare platforms have become increasingly important in meeting the basic medical needs of the public, especially with the growing popularity of smart healthcare. A crucial step in the online consultation process is helping patients find a doctor with relevant expertise, as this not only enhances patient satisfaction but also fosters the development of online healthcare platforms. Unlike traditional recommendation systems, doctor recommendations are subject to privacy protection, and historical records for each patient cannot be accessed. As a result, models can only utilize the most recent consultation records for training, leading to severe data sparsity issues. Similarly, during prediction, recommendations are made solely based on the patient’s current disease description. However, different patients describe their conditions in different ways, which results in varying recommendation effectiveness across patients. This may fail to meet the needs of some, thereby affecting the overall performance of the recommendation system. Along this line, in this paper, we proposed a novel method called Sequential three-way decision with data augmentation (STWD-NA), which combined both matching and mismatched interaction information for doctor recommendation to expand training data. Specifically, this novel method consisted of two parts. On the one hand, it proposed a method to integrate the mismatched interaction information to alleviate the cold-start problem during training. On the other hand, an algorithm was proposed based on the idea of sequential three-way decisions to dynamically adjust the model’s attention during the training process. Evaluation based on real-world dataset haodf.com demonstrates the utility and the effectiveness of the proposed method.
-
随着互联网的发展和在线医疗平台在社交媒体上的日益普及,加之网络打破地域壁垒、保护患者隐私等优势,越来越多的人倾向于通过在线咨询专业医生寻求医疗服务。在在线医疗平台上,患者需要先选择一位医生,之后再以聊天的形式向医生阐述病情,并获取诊疗建议。可见,选择合适的医生,是在线问诊中的关键步骤。然而,随着在线问诊平台上医生数量的不断增多,缺乏专业知识的患者想要快速从中寻找符合其实际需求的医生变得愈发困难。在这种情况下,为患者推荐合适的医生对患者和平台都至关重要。一方面,对于患者来说,合适的医生推荐有助于提高线上问诊效率,改善问诊体验[1];另一方面,对于平台而言,能够提高服务质量,并推动平台发展[2]。由于医生推荐对于在线医疗的关键作用,其相关研究一直以来都是国内外学者的一个研究热门话题。
一般而言,医生推荐是通过挖掘患者的问诊需求信息,为其推荐具有相关专长医生的过程。与通过获取目标用户过去的行为(如购买历史)来捕获其潜在需求的传统推荐方法[3]不同,在医生推荐领域,出于隐私保护的要求,患者均会被匿名处理,即对于每位患者,人们仅能获取其与一位医生的一条交互信息,故医生推荐任务面临严峻的交互数据稀疏问题,进而直接影响患者需求挖掘的质量。早期医生推荐研究主要是利用机器学习的方法[2,4-6]挖掘医生和患者特征,并根据相似度实现医生推荐。但由于它们采用的是浅层文本建模技术,往往会存在推荐质量不高的问题。近年来,一些基于深度学习的方法被相继提出,通过引入医患对话[7-8]、使用知识图谱[9-10]等方式丰富了医生和患者的特征信息,并在深层网络的加持下,取得了较好效果。然而,上述方法侧重于增加医生和患者的辅助信息,较少从交互数据稀疏的角度,考虑患者需求难以挖掘的挑战。基于上述分析,本文通过扩充医生和患者的交互信息来挖掘患者需求,提高推荐的准确性。由于在数据集中,除患者实际就诊的医生能够提供匹配信息之外,其余医生也可以为模型提供不匹配的信息。不同于简单告诉模型哪位医生能够治疗该患者,不匹配信息能够告诉模型该患者不具备哪些需求,有时甚至比匹配信息更重要,故引入不匹配的医生信息是一种有效的数据增强方式。因此,本文选择一些患者未就诊的医生纳入模型,从侧面挖掘患者需求,进而提高模型的推荐能力。具体而言,对每位患者,本文将未就诊医生视为其负样本,将实际就诊的医生视为其正样本,通过正反两个角度的学习,挖掘出患者更深的特征与偏好,最终提升医生推荐的准确性。
与此同时,由于模型为患者推荐合适医生时,仅能利用患者提供的疾病描述文本,而不同患者对自身疾病的描述方式有所不同,这可能会使得模型对不同患者的推荐能力存在差异,进而影响整体的推荐准确性。因此,如何尽可能缩减推荐能力的差异,也是医生推荐任务需要考虑的另一问题。合理确定为每位患者提供的负样本数量、调整模型训练时的关注度,是缩减推荐能力差异的一种思路。基于此,本文借鉴三支决策[11]分而治之的思想将患者分配到正域、负域和边界域中,并对不同区域采取不同策略以确定负样本数量,进而改善负样本的数量分配。进一步地,由于模型的推荐能力会随训练过程而变化,故本文借助序贯三支决策[12]中的粒计算思想,根据当前模型的推荐结果迭代地选择负样本,动态地确定负样本数量,通过使用更有针对性的训练数据高效训练模型,用以提升模型的推荐能力。
基于上述分析,本文从扩充训练数据的角度出发,以提高推荐准确度并同时控制训练成本为目标,提出了一种数据增强的医生推荐方法 (sequential three-way decision with data augmentation, STWD-DA)。首先,针对医生推荐任务因少量交互数据而产生的数据稀疏问题,引入患者未就诊的医生作为负样本增强交互数据,进而挖掘患者更全面的需求,提高推荐准确度。其次,考虑到训练成本,本文使用三支决策思想,合理分配负样本数量,在保证模型效果的同时,最大程度降低训练成本。最后,利用序贯三支决策中多粒度的思想来训练模型,以提高模型的推荐能力。
1. 相关研究
1.1 在线医生推荐
与传统推荐方法相比,医生推荐领域的数据稀疏问题显得更加突出。目前,解决医生推荐问题的相关研究主要聚焦于增强医生特征表示和改进推荐策略两方面。Che等[13]通过整合不同医疗平台上的多源异构数据,获得医生的综合推荐排名;梁建树等[14]考虑了咨询文本、医生评论和用户简介3种信息源,以提高医生推荐的覆盖率;Singh等[15]得到与医生和患者相关的8个不同特征,应用KNN(k-nearest neighbor)算法为每个特征分配权重,最后根据相似度得分和医生技能得分进行推荐;Yi等[16]利用医生属性、患者咨询文本和医生回复文本,构建组合推荐模型;Lu等[8]将医患对话作为补充信息,并结合多头注意力机制自动配对医生与患者;聂卉等[17]采用层次注意力网络和注意力机制,通过加强医患向量间的交互,改进推荐策略。综上所述,医生推荐领域虽然已取得较多的研究成果,但仍存在一定局限性。一方面,现有文献大多只利用患者与实际就诊医生的交互信息进行特征提取,忽视了大量未就诊医生所带来的信息。另一方面,现有文献针对模型对不同患者推荐能力的研究也较少。因此,本文通过引入未就诊的医生信息扩充交互数据,并利用序贯三支决策思想动态地确定引入数量与质量,以提高模型的整体推荐准确度。
1.2 序贯三支决策
三支决策[11](three-way decision, 3WD)是近十年来发展起来的一种处理不确定性决策的粒计算方法,是从决策粗糙集理论逐渐演变成的一种符合人类认知的三分而治(trisecting and acting)模型。三支决策的核心思想是将一个统一集划分为3个互不相交的成对区域,对每一个区域制定相应的决策策略。事实证明,使用三分而治的思想处理问题卓有成效。Liang[18]利用三支决策对样本区域进行划分,使用不同的smote方法对不同区域中少数类样本的数量进行增强;Shen[19]将三支决策应用于信用评分,筛选出和接受样本分布更相近的拒绝样本;Zhou[20]使用三支决策来提高产品设计的成功率,以避免风险损失。
在现实问题求解中,决策过程通常是多步骤的而非单步骤的。因此,为了获得更好的决策效果,Yao等[12]针对延迟决策问题,将静态三支决策推广到动态多阶段决策过程,并采用粒计算的思想提出了一种序贯三支决策模型;Liu等[21]通过考虑误分类成本与信息获取成本,使用3种矩阵分解方法构建多层次粒结构,提出基于序贯三支决策的动态推荐过程;Ye等[22]将用户偏好的动态性和系统的时间性纳入考虑,从时空维度出发,构建多层次推荐信息的多步骤推荐模型;Li等[23]利用序贯三支决策进行人脸识别,来最小化错误分类成本;Yang等[24]使用序贯三支决策融合历史价格和流文本数据,持续预测股票价格;Liang等[25]提出政务文本意图识别方法,利用序贯三支决策动态调整对难识别意图的关注度。基于上述分析,序贯三支决策通过引入延迟决策策略,可以在提供进一步信息时将对象分配到正确区域,从而降低误分类率。对于医生推荐问题而言,可以将当前粒度中没有足够推荐信心的样本转移到下一个粒度,并在进一步学习后对其进行处理。
2. 基于数据增强的医生推荐方法
在医生推荐场景下,为了保护患者隐私,人们一般仅能获取每位患者的一条就诊记录,这造成了训练数据稀疏的问题,进而影响推荐准确度。为解决这一问题,本文提出了一种数据增强方法(STWD-NA),通过引入患者未就诊过的医生作为负样本来扩充训练集,从而提升医生推荐准确率。STWD-NA由数据增强和模型训练两部分构成。首先,给出一种负样本选择与数量确定的方法;其次,提出一种高效的模型训练算法。
2.1 负样本的选择与数量确定
为了缓解医生推荐领域中的数据稀疏问题,本文将未与患者发生交互记录的医生作为负样本纳入模型训练中。本节将从如何选择能为模型训练带来更大信息量的负样本,如何确定负样本数量两个角度,介绍负样本的引入。
2.1.1 负样本的选择
由于不同负样本所提供的信息量不同,故对每位患者而言,不同的未就诊医生带来的影响也不相同。Robinson等[26]的研究表明:与已经明确判断出无法治疗该患者的医生相比,那些不确定能否医治患者的医生可以为模型优化带来更大的梯度贡献并加速收敛。因此,本文利用模型对每个未就诊医生的预测得分进行负样本选择,即未就诊医生被选为负样本的概率和模型对其的打分具有比例关系。具体来说,对于每位患者u,可以将当前模型对所有医生的推荐得分视作概率分布,并据此抽样选择k位医生作为负样本用于模型训练,其具体计算过程为
$$ p_j^u=\dfrac{\mathrm{e}^{s_j^u}}{\displaystyle\sum\limits_{m=1}^M\mathrm{e}^{s_m^u}} $$ $$ {{\boldsymbol{p}}^u} = [p_1^u\;p_2^u\; \cdots \;p_j^u\; \cdots \;p_M^u] $$ (1) $$ {N^u}\sim {\text{multinomial}}({{\boldsymbol{p}}^u},{k_u}) $$ (2) 式中:Nu为给患者u采集的ku个负样本集合;pu表示对于患者u,所有医生被推荐的概率分布;
$p_j^u$ 是第j位医生被推荐给患者u的概率;$s_j^u$ 表示对于患者u,第j位医生的推荐得分;M为所有医生总数。2.1.2 基于三支决策的患者分类方法
对于某些症状单一且描述精确的患者,模型能够较容易地得到其精准特征,进而仅需要少量负样本便能为其推荐合适的医生。然而,对于某些症状较多或描述不太清晰的患者,模型可能较难提取到该患者特征,也因此需要更多负样本才能为其进行精准推荐。基于此,本文根据对负样本的需求对患者进行分类,通过调整数量分配,控制模型训练成本。一般而言,传统分类方法大多考虑“非黑即白”的二支决策情形,但这会导致误分类风险。为避免这一问题,合理分配负样本数量,本文提出了一种基于三支决策的患者分类方法。其主要思想为将容易推荐的患者和难推荐的患者分别划入正域和负域中,不确定类别的患者则被划分至边界域,以延迟对此类患者的判断,进而降低由于仓促决策造成的错误分类成本。
具体而言,本方法通过计算患者u和所有医生的相似度,可得到与患者u最相似的医生,继而实现医生推荐。对于一些患者,模型为其推荐的第1位医生和第2位医生的相似度差值较小,这种情况被定义为推荐信心不足[27]。推荐信心的计算公式为
$$ {F_u} = s_u^{1{\text{st}}} - s_u^{2{\text{st}}} $$ (3) 式中
${\text{s}}_u^{1{\text{st}}}$ 和${\text{s}}_u^{{\text{2st}}}$ 表示医生与患者u的最大相似度和次大相似度。根据Liang等[25]的研究结果,Fu越高,模型对输入对象的判断就越有信心;Fu越低,模型对输入对象的判断就越困难。进一步地,基于式(3)和三支决策分而治之的思想,可将每位患者划分到不同的区域。具体地,划分及处理规则有3条。1) 正域(POS):推荐正确且Fu≥δ。表示模型能够以高推荐信心为患者u正确推荐医生,即模型对该患者有较好的推荐能力,进而可减少为该患者提供的负样本数量,以降低模型的训练成本。2) 负域(NEG):推荐错误。说明模型不能为患者u推荐正确的医生,故应增加此类患者的负样本数量,以帮助模型提高对此类患者的推荐能力。3) 边界域(BND):推荐正确但Fu < δ。这意味着虽然模型可以为患者u推荐正确的医生,但推荐信心不足,还需要一定的信息来充分挖掘该患者特征,故为该患者提供的负样本数量保持不变。2.1.3 负样本数量的确定
为精准刻画模型对每位患者推荐难度不同的问题,本研究根据推荐难度,确定非边界域中每位患者的负样本数量,以合理资源分配,控制训练成本。基于此,本方法引入了一个推荐难度指标(recommendation difficulty, RD),符号为
$ {R_u} $ ,用于衡量模型对非边界域中每位患者的推荐难度。$$ I(u)=-\text{log}(p(d_{\mathrm{t}}^u)) $$ (4) $$ R_u=I(u)+D(d_{\mathrm{f}}^u,d_{\mathrm{t}}^u) $$ 式中:I(u)表示模型推荐成功的不确定性,即对于患者u而言,推荐成功的信息量;
$ p(d_{\mathrm{t}}^u) $ 表示模型将正样本(实际就诊医生)推荐给对应患者的概率,即推荐正确的概率,一般而言,信息量越大,代表不确定性越高,即推荐难度越大。此外,推荐难度还与推荐列表中的其他医生有关。
$ D(d_{\mathrm{f}}^u,d_{\mathrm{t}}^u) $ 定义为患者u离推荐成功的距离,用于表示患者u的推荐列表中第一位医生$ d_{\mathrm{f}}^u $ 的推荐得分和正样本$ d_{\mathrm{t}}^u $ 的推荐得分的差值。差值越大,与推荐成功的距离越远,推荐难度越大。其具体计算方法为$$ D(x,y) = s(x) - s(y) $$ 推荐难度指标
$ {R_u} $ ,可以完整反映模型推荐能力的不平衡特性。由于模型的推荐难度因患者而异,本方法根据该指标确定每位患者的负样本数量,这既能够给难推荐患者更多的关注,提高模型对他们的推荐能力,又可以减轻三支决策中超参数的训练负担。对于正域中的患者,模型可以较容易地对其进行推荐,故应减少此类患者的负样本数量,以降低训练成本。因此,取[α/Ru]作为患者u的负样本减少量。其中,α为超参数,[ ]为取整符号。对于负域中的患者,模型较难对其进行推荐,故应增加此类患者的负样本,使模型更好地捕捉该类患者特征,进而改善模型推荐效果。因此,取f (Ru)作为患者u的负样本增加量。对于每位患者u,其负样本的数量确定方式为
$$ {k_u} = \left\{ {\begin{array}{*{20}{l}} {k - \left[ {\alpha \dfrac{1}{{{R_u}}}} \right],\quad u \in U_{\text{POS}}} \\ {k,\quad u \in U_{\text{BND}}} \\ {k + f({R_u}),\quad u \in U_{\text{NEG}}} \end{array} } \right. $$ (5) 式中:UPOS、UNEG和UBND分别为落入正域、负域和边界域的所有患者;ku表示在当前的训练轮次下,应为患者u提供的负样本数量;k为模型为所有患者提供的初始负样本数量;f(Ru)为确定负域中样本增加量的函数,其作用是保证正域中所有负样本的减少量等于负域中所有负样本的增加量,目的在于保持负样本的总数恒定,用于合理化训练资源分配,进而提高负样本的整体利用效率。f (Ru)的计算方式为
$$ f({R_u}) = \left[ \begin{split} {\dfrac{{{R_u}}}{{\displaystyle\sum\limits_u^{{U_{{\text{NEG}}}}} {{R_u}} }}T} \end{split}\right] $$ 式中T为正域中所有负样本的减少量,计算公式为
$$ T = \displaystyle\sum\limits_u^{{U_{{\text{POS}}}}} {\alpha \dfrac{1}{{{R_u}}}} $$ 2.2 基于序贯三支决策的医生推荐模型训练
2.2.1 基于Sentence-BERT的医生推荐模型
作为基于Transformer架构的预训练语言模型,BERT(bidirectional encoder representations from transformers)[28]在句子分类与句子对回归任务上均取得显著效果,其采用交叉编码器结构,通过将两个句子共同传递到Transformer网络中得到预测目标值。然而,由于可能的组合太多,这种设置不适合医生推荐任务。在医生推荐领域中,需要计算每位患者和所有医生之间的推荐得分,进而选取最合适的医生。如果候选集中有200位医生,则对于每位患者,BERT都需要进行200次推理计算,这会造成大量的计算开销。一种常见的解决方案是将单个患者/医生输入到BERT模型中,得到其固定的特征表示,但这种做法得到的特征表示质量不佳[29],从而影响推荐准确性。为解决上述问题,本文选用Sentence-BERT[29]模型作为基础的医生推荐模型。Sentence-BERT模型通过孪生网络和三胞胎网络对BERT进行改进,可以在保证推荐准确性的同时大幅提高计算效率。
具体而言,本文首先将患者的咨询文本和医生的个人简历文本分别输入Sentence-BERT模型,并采用平均池化策略(对每个词的向量进行逐元素平均)得到初始句向量。接着,通过优化损失函数,逐步优化句向量,最后得到两类文本的最终表征q和p。在得到最终表征后,通过计算文本之间的余弦相似度,将与患者描述最相似的医生推荐给患者,从而完成医生推荐。具体的操作方式如图1所示。
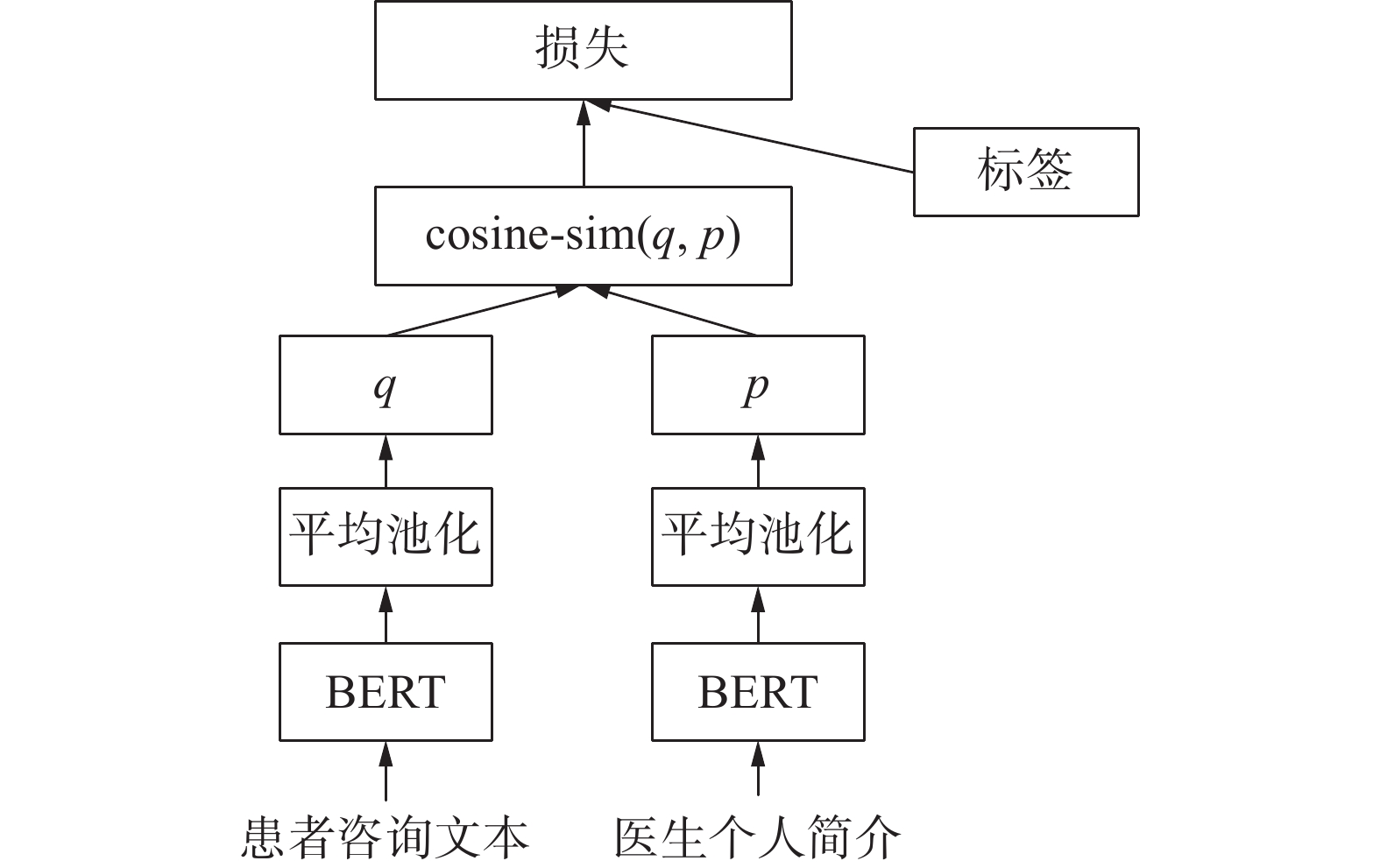 图 1 Sentence-BERT模型结构Fig. 1 Sentence-BERT model architecture
图 1 Sentence-BERT模型结构Fig. 1 Sentence-BERT model architecture 下载:
全尺寸图片
下载:
全尺寸图片
在模型选择之外,目标函数也对模型训练起到重要作用。本文使用对比损失函数[30]对模型进行优化。根据文献[30],对比损失函数表达式为
$$ {l_{{\text{oss}}}} = \dfrac{1}{2}(y{d^2} + (1 - y){\text{max}}{(0,m - d)^2}) $$ (6) 式中:y为医生与患者是否匹配的标签,如果是患者与其正样本,其值为1;如果是患者与其负样本,则值为0;d是患者与医生之间的余弦相似度;m为阈值,表示只考虑与患者距离在0到m之间的负样本。
2.2.2 基于序贯三支决策的模型训练方法
在医生推荐过程中,推荐模型的准确度会随着训练轮次的迭代而逐渐提高,这意味着模型在时间维度上迭代轮次的增加会带来模型在空间维度上粒度的变化。基于此,本文借鉴文献[31]的粒化方法,通过模型多轮训练来构造多粒度结构。随着训练轮次的增加,模型对患者的推荐能力也会发生变化,继而为患者提供的负样本以及负样本数量也会随之改变。因此,为更精准地获得高质量负样本并确定负样本数量,提高模型训练效率,本文提出了一种基于序贯三支决策的模型训练方法。具体而言,对于给定粒层,在该粒层下落入负域的患者,下一粒层应为其提供更多的负样本进行训练,以提高模型对此类患者的推荐能力;在该粒层处于正域的患者,下一粒层应减少参与训练的负样本数量,进而降低模型对此类患者的训练成本;在该粒层处于边界域的患者,则不改变其负样本数量。另外,随着训练的迭代,能为模型带来高信息量的负样本也在发生变化,故负样本的选择也应随着粒度的转化而不断更新。图2给出了详细的模型训练方法。
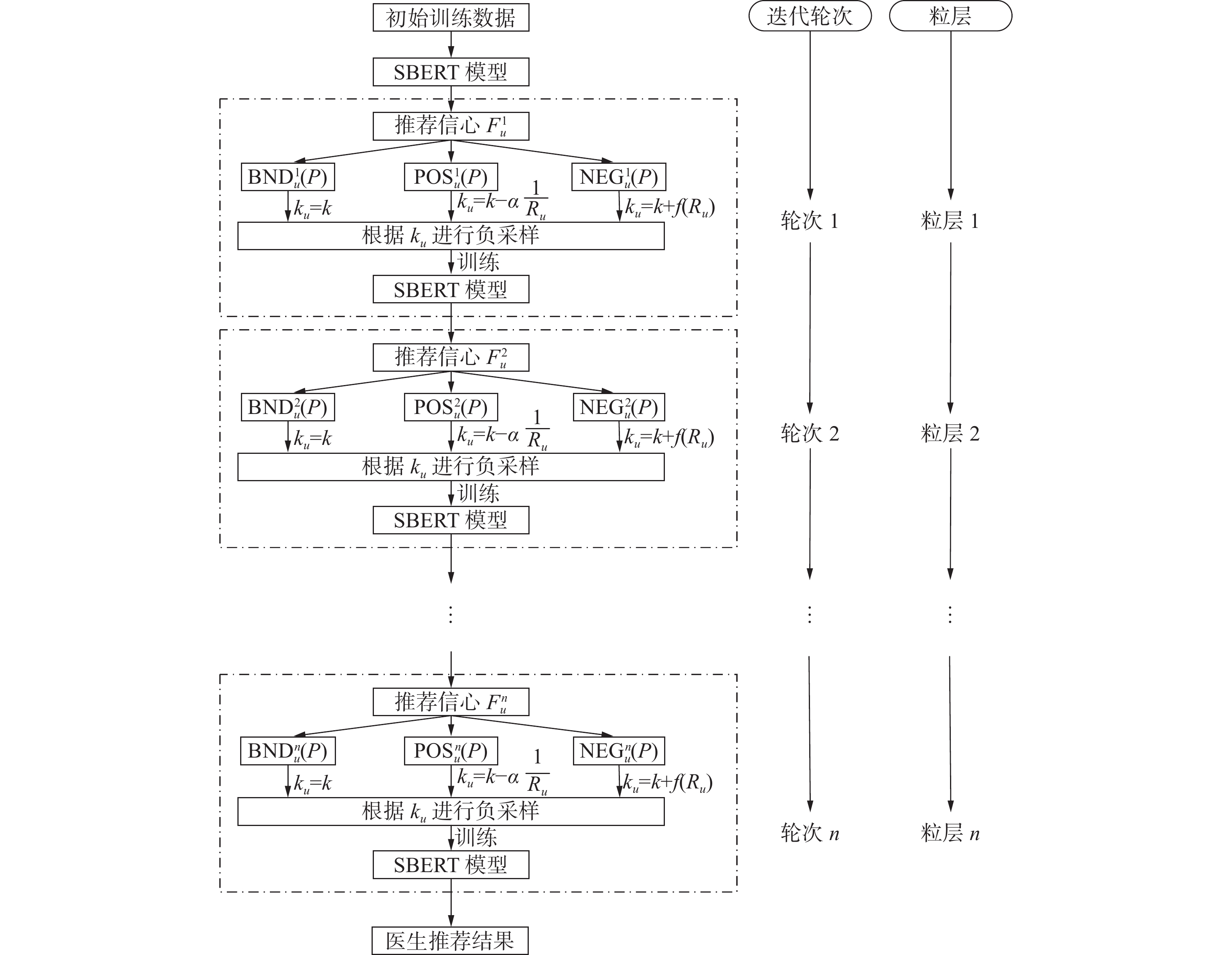 图 2 基于序贯三支决策医生推荐模型训练方法Fig. 2 Model training method based on STWD下载:
全尺寸图片
图 2 基于序贯三支决策医生推荐模型训练方法Fig. 2 Model training method based on STWD下载:
全尺寸图片
在图2中的初始阶段,为确保每位患者都有足够的负样本用于模型训练,本文为所有患者提供了k个相同数量的负样本,将这些负样本与正样本一起放入Sentence-BERT模型中进行训练,以获得模型对每位患者的推荐难度
$ {R_u} $ 。接着,根据式(3)的划分准则,将所有患者分到正域、负域、边界域中,并根据式(2)和(5),确定在下一轮迭代时使用的负样本。之后,利用实际就诊医生和新的负样本继续训练Sentence-BERT模型,并更新模型对每位患者的推荐信心与推荐难度。该过程持续进行,直至模型推荐精度的降幅大于阈值θ为止。基于上述分析,本文所提出的基于数据增强的医生推荐方法STWD-DA由数据增强和模型训练两部分构成,相应的算法流程见算法1。
算法1 基于数据增强的医生推荐方法。
输入 患者u(u=1, 2,…,M),正样本
$d_t^u$ 。输出 推荐的医生
$d_f^u$ (u=1,2,···,M)。1) 为每位患者随机抽取k个负样本,与正样本一起,送入Sentence-BERT模型;
2) 根据式(6),训练Sentence-BERT模型;
3) 基于式(1),计算对于患者u,所有医生被推荐的概率分布;
4) 基于式(4),得到患者u的推荐难度Ru;
5) 依据式(3),得到患者u的推荐信心Fu;
6) if
$d_t^u$ =$d_f^u$ and Fu≥δ then7) 将患者u划分到正域,下一阶段减少其负样本数量;
8) else if
$d_t^u$ =$d_f^u$ and Fu<δ then9) 将u划分到边界域,下一阶段不改变其负样本数量;
10) else
11) 将u划分到负域,下一阶段增加其负样本数量;
12) 根据式(2)和(5),确定每位患者在下一阶段的负样本;
13) 将正负样本一起送入模型中,根据式(6)训练模型;
14) if Accuracy@1 减少量小于θ then
15) 返回步骤3);
16) else
17) 取相似度最大的医生作为患者u的推荐医生
$ d_{f}^{u} $ ;18)return
$ d_{f}^{u} $ 。3. 实验结果及分析
本小节首先介绍实验所用的数据集、模型设置、评价指标等相关实验设置;然后,从对比实验、消融实验、鲁棒性分析、灵敏度分析4个角度,共同验证本文所提方法的有效性。
3.1 实验设置
3.1.1 数据集
本研究选取我国最大的医疗在线平台好大夫在线网站(haodf.com)上2016—2023年的用户咨询文本和医生简历等作为原始数据。研究数据覆盖了骨科、内科、外科和皮肤性病科4个大类下的24个具体科室,其相关的基本统计信息如表1所示。在实验部分,对于每位医生,随机选择其80%的问诊记录作为训练集,剩下的20%用于验证和测试。进一步地,图3给出了患者咨询文本和医生简历文本的长度分布。
表 1 数据集描述Table 1 Data statistics统计信息 数值 医生数 237 患者数 22 429 科室数 24 每个科室下平均患者数 935 每个科室下平均医生数 10 每位医生平均治疗的患者数 95 患者咨询文本的平均长度 188 医生个人简历的平均长度 106 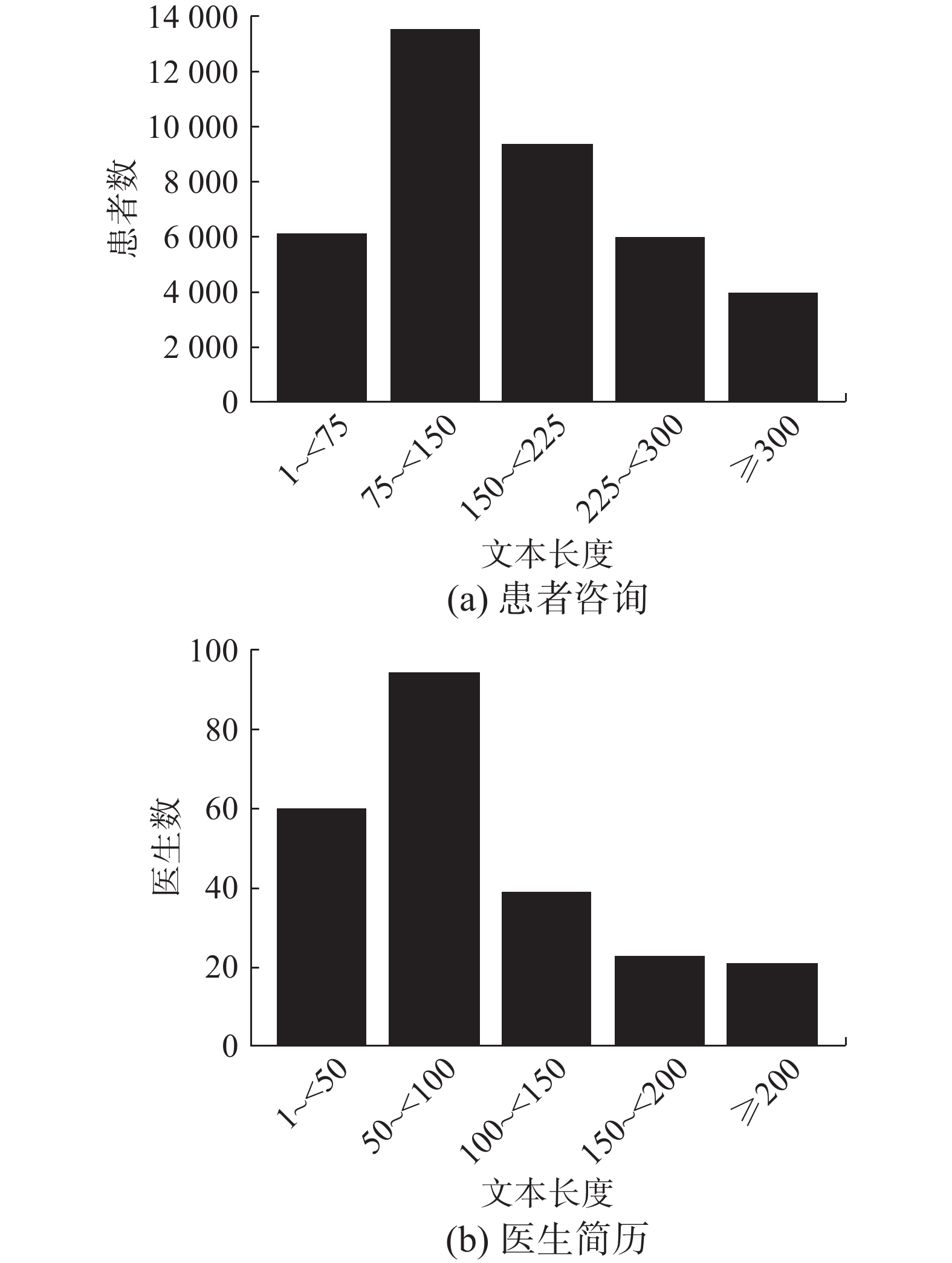 图 3 文本长度分布Fig. 3 Dataset descriptive statistics下载:
全尺寸图片
图 3 文本长度分布Fig. 3 Dataset descriptive statistics下载:
全尺寸图片
3.1.2 模型设置
对于Sentence-BERT模型中的编码部分,本文使用医疗的预训练模型MC-BERT[32],其最大输入长度为512,输出的所有文本嵌入的维度为768。在训练过程中,采用Adam作为优化器,初始学习率为0.008,批量大小为16。超参数设置方面,将初始为每位患者提供的负样本数量k设置为10[8];将推荐信心的阈值δ设置为0.1[25],将算法停止条件的阈值θ设为0.05[25]。
3.1.3 评价指标
为了方便起见,本实验选取Accuracy@1、MRR@10、MAP@100、NDCG@10作为评估指标,其具体含义如下。
1) Accuracy (精度):它用于衡量模型在给定样本中,预测结果与真实标签匹配的比例。特别地,Accuracy@1表示模型在所有患者中,推荐的医生(即排名第1的医生)与实际就诊医生相同的患者数量占总患者数量的比例。Accuracy计算公式为
$$ A = \dfrac{1}{{\left| U \right|}}\displaystyle\sum\limits_{u = 1}^{\left| U \right|} {\left| {d_f^u = d_t^u} \right|} $$ 式中:|U|表示所有的患者集合,
$d_f^u$ 和$d_t^u$ 分别表示患者u的推荐列表中第1位医生与实际就诊医生。2) MRR (mean reciprocal rank):表示平均倒数排名。该指标关注推荐排序中真实医生所处的位置,位置越靠前则MRR就越大。MRR@10表示推荐系统返回的前10个结果中的第1个推荐正确医生的平均倒数排名。MRR计算公式为
$$ M = \dfrac{1}{{\left| U \right|}}\displaystyle\sum\limits_{u = 1}^{\left| U \right|} {\dfrac{1}{{{r_u}}}} $$ 式中ru代表在为患者u推荐的医生列表中,真实医生的位置排名。
3) MAP (mean average precision):表示平均精度均值。通过将所有查询的平均准确率再求平均得到,能够全面体现模型对患者的推荐能力,平均精度均值越高,最终匹配的医生列表中准确医生的排名也就越靠前。MAP@100表示推荐系统返回的前100个结果的平均精确度,其计算公式为
$$ {P_{\text{A}}}(u) = \dfrac{1}{{\left| M \right|}}\displaystyle\sum\limits_{m = 1}^{\left| M \right|} {\dfrac{m}{{{r_u}}}} $$ $$ {P_{{\text{MA}}}} = \dfrac{{\displaystyle\sum\limits_{u = 1}^{\left| U \right|} {{P_{\text{A}}}(u)} }}{{\left| U \right|}} $$ 式中|M|表示患者实际就诊医生的总数,在医生推荐场景下,令|M|=1。
4) NDCG (normalized discounted cumulative gain):表示归一化折损累计增益。该指标考虑了推荐结果所在位置的影响,真实医生的排序越靠前,其推荐效果越好得分越高。NDCG@10用于衡量模型在返回前10位医生中的相关性排序方面的性能。其计算公式为
$$ {G_p} = \dfrac{1}{{\left| U \right|}}\displaystyle\sum\limits_{u = 1}^{\left| U \right|} {\dfrac{{\displaystyle\sum\limits_{i = 1}^p {\dfrac{{{2^{{r_{{\text{el}}}}_i}} - 1}}{{{{\log }_2}(i + 1)}}} }}{{\displaystyle\sum\limits_{i = 1}^{\left| {{R_{{\text{EL}}}}} \right|} {\dfrac{{{2^{{r_{{\text{el}}}}_i}} - 1}}{{{{\log }_2}(i + 1)}}} }}} $$ 式中:p表示返回的医生个数,本研究中其取值设定为10;reli={0,1},表示第i个位置上的医生是否为正确医生;|REL|为结果按照相关性从大到小的顺序排序,取前p个结果组成的集合,即按照最优的方式对结果进行排序。
3.2 实验结果分析
3.2.1 对比实验
在实验部分,利用本文提出的STWD-DA方法进行推荐,即训练Sentence-BERT模型时,每轮迭代都重新根据上一轮模型的推荐结果选择负样本,且非边界域中每位患者的负样本数量由式(5)确定。进一步地,为验证本文方法的有效性,将以下4个传统学习方法和3个深度学习方法作为基准方法,进行实验分析。
1) 传统学习方法
① Random方法:随机对医生进行排名。
② Frequency方法:根据训练集中医生的受欢迎程度进行推荐。
③ BERT-SIM方法:利用预训练后的MC-BERT模型对患者咨询文本和医生个人简介进行编码,并利用余弦相似度进行推荐。
④ KNN方法:参考与待推荐患者距离最近的K位患者的就诊医生得到推荐结果,K值取20。
2) 深度学习方法
① BERT-MLP (multilayer perceptron)[8]方法:利用MLP对经MC-BERT模型编码后的患者咨询文本和医生个人简介进行匹配推荐。
② DSSM (deep structured semantic models)[33]方法:利用DSSM进行推荐。本文使用BERT替代原始的编码词袋模块,使用TextCNN (convolutional neural network)进行特征提取。
③ SBERT (Sentence-BERT)[29]方法:利用Sentence-BERT进行推荐,训练Sentence-BERT模型时,提供的负样本保持不变。
相应实验结果如表2所示。
表 2 不同模型在4个评价指标上的实验结果Table 2 Experimental results of different methods on four evaluation metrics方法 Accuracy@1 MRR@10 MAP@100 NDCG@10 Random 0.0042 0.0102 0.0203 0.0166 Frequency 0.0011 0.0050 0.0118 0.0093 BERT-SIM 0.0832 0.0913 0.1072 0.1460 KNN 0.1230 0.2387 0.2037 0.3219 BERT-MLP 0.3053 0.3194 0.3516 0.4050 DSSM 0.3860 0.4276 0.4664 0.4319 SBERT 0.4108 0.5598 0.5671 0.6335 STWD-DA 0.5154 0.6617 0.6667 0.7219 通过表2可以发现,在传统学习方法中,随机推荐方法(Random方法)和基于频率的启发式推荐(Frequency方法)的表现较差,在4项指标上的得分均显著低于其他方法,这凸显了医生推荐问题的复杂性,强调了研究医生推荐方法的必要性。基于深度网络的推荐方法在医生推荐领域展现了良好的性能,其中的DSSM和SBERT使用双塔架构,通过在训练中不断调整患者和医生的特征表示,提升推荐性能。两者的差异可能是因为BERT相较于TextCNN可以更好地利用上下文信息,进而能够得到较高质量的语义表示。进一步地,使用BERT-MLP推荐的效果要远好于BERT-SIM方法,这是因为BERT模型得到的句向量存在非光滑各向异性的问题。该问题会导致句向量在向量空间中占据一个狭窄的圆锥体形[34],而非均匀地分布在向量空间上,使得彼此之间的余弦相似度都很高,无法通过相似度得到满意的结果。因此,如果用BERT作为相似性任务的编码器,还需进一步训练。因此,利用对BERT进行相似性训练后的Sentence-BERT模型,推荐效果就有明显改善。相较于基线中最好的SBERT方法,本文所提的STWD-DA方法在4项指标上分别提高了0.104 6、0.101 9、0.099 6、0.088 4。其原因是STWD-DA通过选择高质量负样本进入模型,让模型学习到更多更有用的信息,进而提升了推荐能力。
3.2.2 消融实验
为了证明本文所提方法中各组成成分的有效性,本文进行了3组消融实验,并对实验结果进行分析。首先,验证动态引入负样本的有效性;其次,验证高质量负样本的有效性;最后,验证差异化确定负样本数量的有效性。不同于SBERT训练时使用固定的负样本,SBERT-random在训练Sentence-BERT模型时,每轮迭代都重新随机选择负样本,保持每位患者的负样本数量统一;SBERT-DNS在训练Sentence-BERT模型时,每轮迭代都重新根据上一轮模型的推荐结果选择负样本,保持每位患者的负样本数量统一;本文方法STWD-DA在训练Sentence-BERT模型时,每轮迭代都重新根据上一轮模型的推荐结果选择负样本并差异化确定每位患者的负样本数量,但保持负样本总数与之前的方法一致。消融实验的相关结果如表3所示。
表 3 消融实验结果Table 3 Experimental results of ablation experiments方法 Accuracy@1 MRR@10 MAP@100 NDCG@10 SBERT 0.4108 0.5598 0.5671 0.6335 SBERT-random 0.4411 0.5895 0.5960 0.6587 SBERT-DNS 0.4879 0.6306 0.6367 0.6900 STWD-DA 0.5154 0.6617 0.6667 0.7219 通过表3可以看到,每轮迭代都重新选择负样本可以有效提升模型推荐能力。这是因为在不断更换负样本的过程中,模型融合了更多的数据,学习到了更多的知识,这也再次验证了引入负样本对提高推荐能力的作用。进一步地,与随机选择负样本相比,优先选取上一轮迭代中推荐分数较高的负样本可以提升模型性能。这是因为相对于随机负样本,强负样本能够为模型训练提供更大的梯度,有助于模型更好地挖掘患者特征。此外,相较于为所有患者提供同等数量的负样本,根据患者的差异调整负样本数量,可以获得更好的模型性能。这说明了模型对不同患者推荐能力上具有差异,并进一步验证了多粒度训练模型的必要性,也体现了差异化确定负样本数量对提高模型准确性的作用。另外,由于在保持负样本总数恒定的情况下,选择强负样本和差异化确定每位患者的负样本数量后,推荐结果都较之前有所提高,故可验证本文所提方法有助于降低训练成本。
3.2.3 鲁棒性分析
为了验证本文所提的数据增强方法的鲁棒性,除采用Sentence-BERT模型之外,将本文提出的数据增强方法应用于BERT-MLP和DSSM等其他深度模型,比较了未经数据增强和经过数据增强的模型推荐性能,相关实验结果如图4所示。
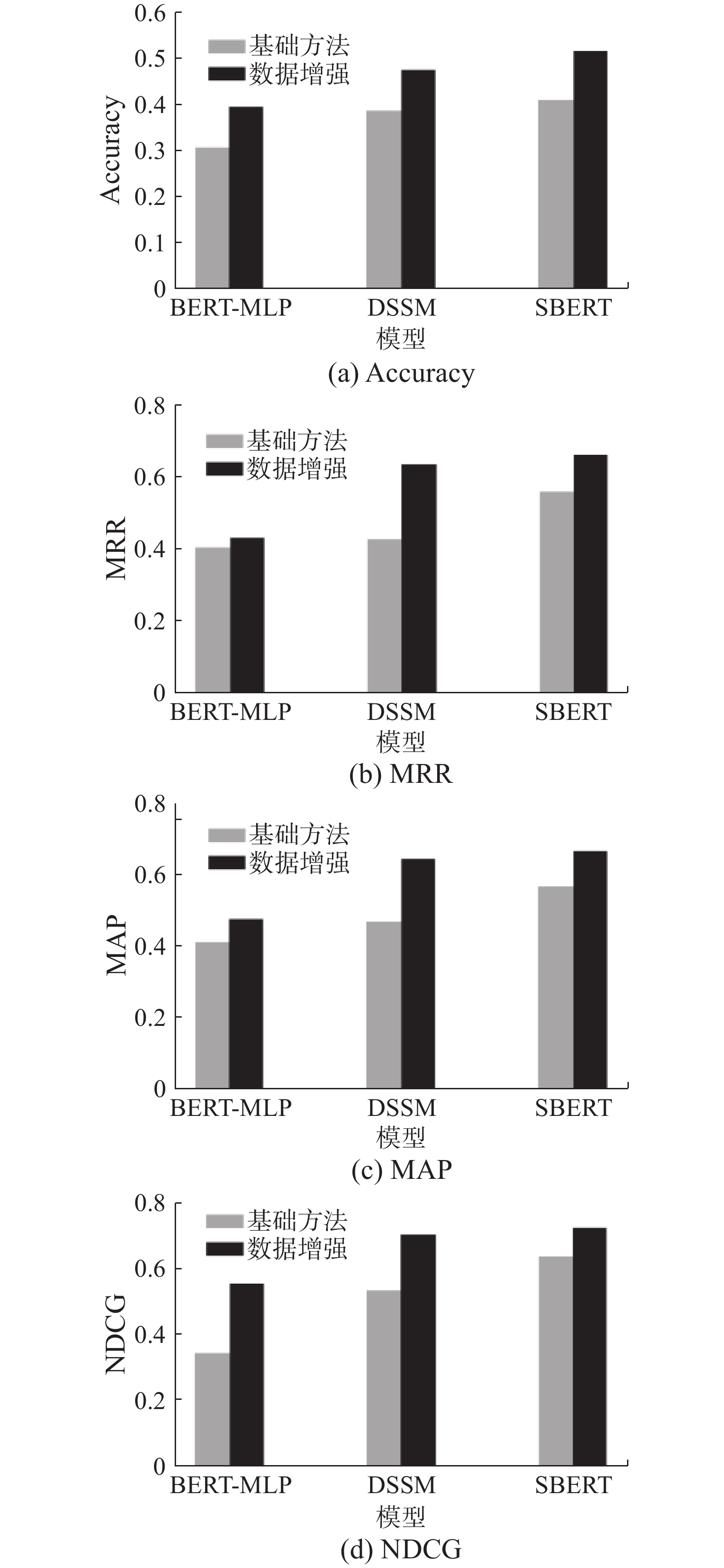 图 4 鲁棒性分析Fig. 4 Robustness analysis下载:
全尺寸图片
图 4 鲁棒性分析Fig. 4 Robustness analysis下载:
全尺寸图片
由图4可知,在使用本文所提的数据增强方法对模型训练后,3种方法在4项评价指标上的表现均优于不使用数据增强方法。故本文方法具有较强的鲁棒性。
3.2.4 特征灵敏性分析
为了进一步验证本研究方法在不同情境下的性能表现,针对患者咨询文本长度、医生个人简历长度以及不同科室的灵敏度进行实验,相关实验结果如图5~7所示。
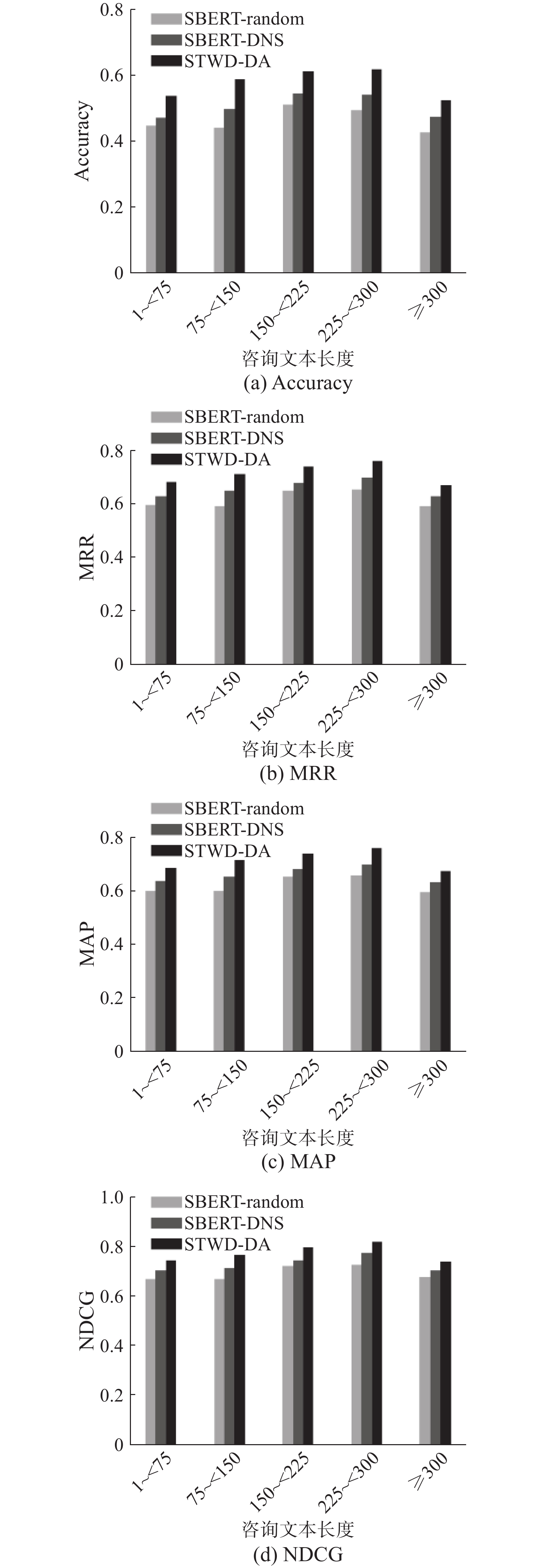 图 5 针对不同长度咨询文本的STWD-DA灵敏度Fig. 5 Sensitivity of STWD-DA to queries length下载:
全尺寸图片
图 5 针对不同长度咨询文本的STWD-DA灵敏度Fig. 5 Sensitivity of STWD-DA to queries length下载:
全尺寸图片
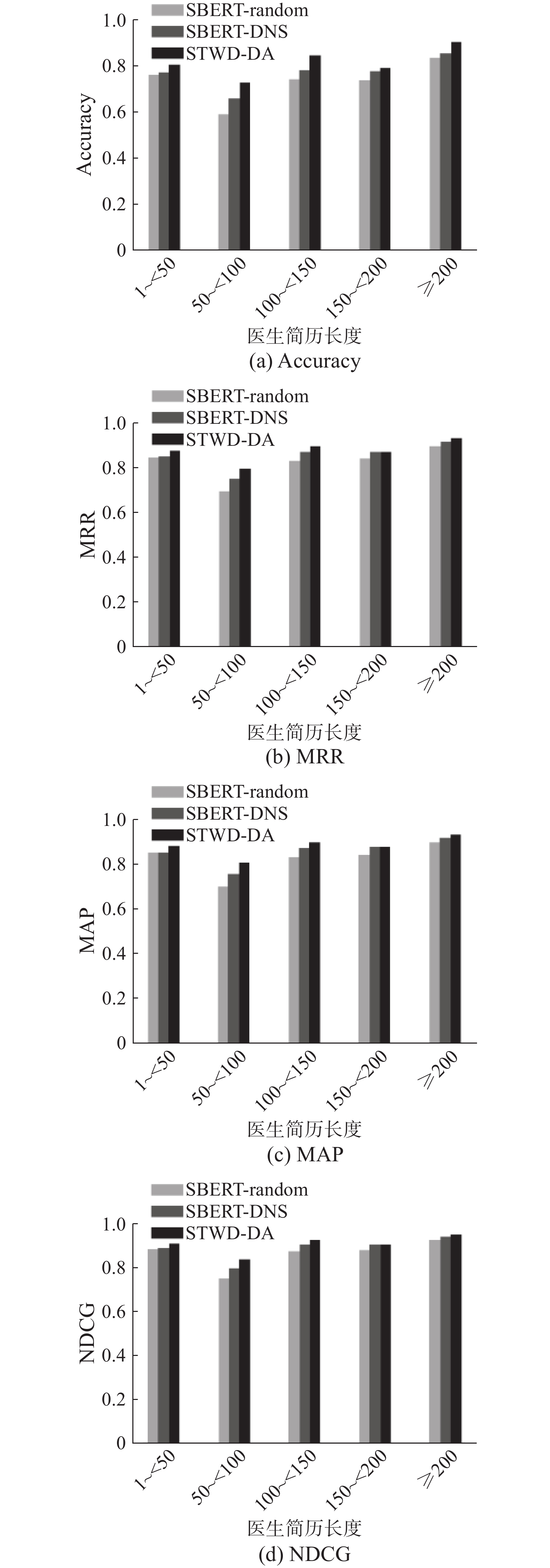 图 6 针对不同长度医生简历的STWD-DA灵敏度Fig. 6 Sensitivity of STWD-DA to profiles length下载:
全尺寸图片
图 6 针对不同长度医生简历的STWD-DA灵敏度Fig. 6 Sensitivity of STWD-DA to profiles length下载:
全尺寸图片
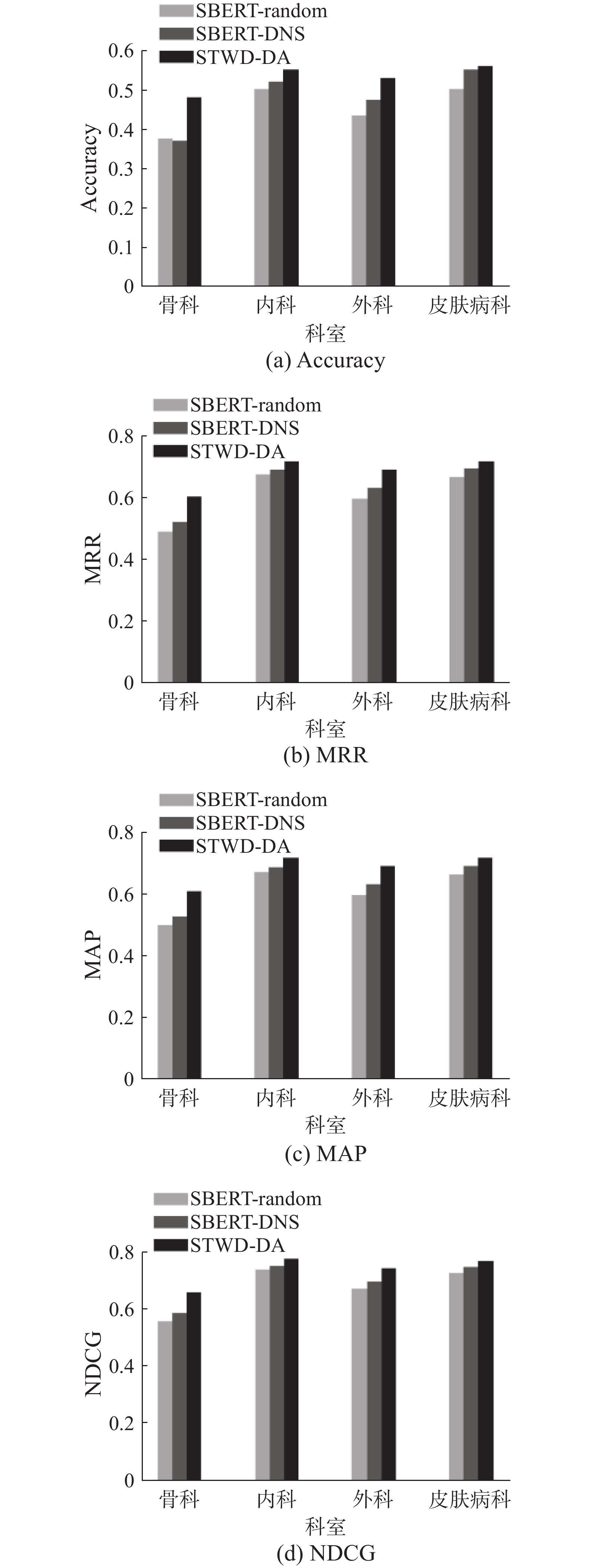 图 7 针对不同科室的STWD-DA灵敏度Fig. 7 Sensitivity of STWD-DA to medical departments下载:
全尺寸图片
图 7 针对不同科室的STWD-DA灵敏度Fig. 7 Sensitivity of STWD-DA to medical departments下载:
全尺寸图片
根据图5可以看出,咨询文本长度在150~<300的患者更容易获得良好的推荐,其原因是太短的咨询文本无法提供全面的疾病信息,而过长的咨询文本又会产生表述冗余。
图6的结果显示,不同长度的医生简历对模型性能影响不大。这是由于医生的简历文本都经过专业化提炼,无论长度长短,都能很好地体现出医生的擅长方向。另外,与SBERT-random相比,STWD-DA受医生简历长度的影响较小。这是因为SBERT-random是随机考虑的不匹配交互信息,缺乏相关性;而STWD-DA则通过更有目的地选择负样本,使不匹配交互信息的使用更高效。该实验结果体现了STWD-DA的另一个优势,即它受医生简历长度等文本特征的影响较小。
在现实生活中,患者可能知道自己的症状属于哪个科室。为了验证模型在这种场景下的性能,本文提供了模型在不同科室的比较分析结果。根据图7的实验结果,本文方法在4个科室中均展示出最佳性能。此外,模型对不同科室的推荐能力不同。在4类科室中,模型对骨科的推荐能力最差,对内科和皮肤病科的推荐能力最佳。这可能是由于骨科医生在专业领域之间的区分度较小,例如治疗腰椎问题的医生也可以治疗颈椎和脊柱问题,因此可能出现患有腰椎问题的患者实际就诊于治疗颈部的医生,从而导致推荐错误。相比之下,内科与皮肤病科的专业领域区分度较高,因此模型在该领域的推荐也更为准确。
在上述灵敏度实验中,STWD-DA方法的均优于其他方法,从而验证了本文方法的有效性。
3.2.5 参数灵敏性分析
在STWD-DA中,α是一个超参数,表示正域中负样本的减少率。α越大,正域中的负样本减少的越多,负域中的负样本也增加的越多。为研究其对模型推荐效果的影响,本实验取α的值为0.1、0.3、0.5、0.7、0.9,并验证不同α值对推荐效果的影响,实验结果如表4所示。
表 4 针对不同α值的模型性能比较分析Table 4 Comparison analysis of model performance for different α valuesα Accuracy@1 MRR@10 MAP@100 NDCG@10 0.1 0.5092 0.6575 0.6628 0.7179 0.3 0.5143 0.6605 0.6657 0.7205 0.5 0.5137 0.6601 0.6653 0.7200 0.7 0.5154 0.6617 0.6667 0.7219 0.9 0.5126 0.6594 0.6647 0.7194 如表4所示可知,当α=0.7时模型表现最佳。α值较低表示正(负)域中的负样本减少(增加)量越少。当α=0时,该方法与SBERT-DNS等效;相反,当α值非常高(例如0.9)时,则会导致正域中的患者丢失更多负样本,从而导致结果较差。根据实验结果,当α=0.7时模型表现更为优秀,因此,本文取α=0.7。此外,这个实验也验证了差异化确定负样本数量的有效性。
4. 结束语
为降低医患交互信息稀疏而对推荐结果造成的影响,本文将未就诊医生所带来的不匹配信息引入模型,并通过合理确定负样本数量,尽可能消减因患者表述不同而造成的推荐能力不同的问题,进而提出了基于数据增强的医生推荐方法(STWD-DA)。具体而言,本文首先利用随机抽取的正负样本训练初始推荐模型;接着,基于粒计算的思想,根据较粗粒度下得到的模型推荐结果,对患者进行分域,调整参与细粒度训练的负样本,在多个粒层逐步训练推荐模型。最后,利用好大夫在线中24个科室的真实数据,从推荐精度、平均倒数均值、平均准确率和归一化折损累计增益4个指标对本文所提方法进行了对比实验、消融实验、鲁棒性分析和灵敏度分析,从而验证了本文方法的有效性。考虑到医生推荐的难点之一在于缺乏患者先前的历史问诊记录,导致数据集中只有一位医生可以作为患者的正样本。相比于海量的负样本来说,一位医生所能提供的信息有限,故未来的研究中,可以考虑利用迁移学习技术,将其他同类型的医生信息作为患者正样本的补充,用以增加模型所能获取的信息量,并进一步优化模型。
-
图 1 Sentence-BERT模型结构
Fig. 1 Sentence-BERT model architecture
下载:
全尺寸图片
图 2 基于序贯三支决策医生推荐模型训练方法
Fig. 2 Model training method based on STWD
下载:
全尺寸图片
图 3 文本长度分布
Fig. 3 Dataset descriptive statistics
下载:
全尺寸图片
图 4 鲁棒性分析
Fig. 4 Robustness analysis
下载:
全尺寸图片
图 5 针对不同长度咨询文本的STWD-DA灵敏度
Fig. 5 Sensitivity of STWD-DA to queries length
下载:
全尺寸图片
图 6 针对不同长度医生简历的STWD-DA灵敏度
Fig. 6 Sensitivity of STWD-DA to profiles length
下载:
全尺寸图片
图 7 针对不同科室的STWD-DA灵敏度
Fig. 7 Sensitivity of STWD-DA to medical departments
下载:
全尺寸图片
表 1 数据集描述
Table 1 Data statistics
统计信息 数值 医生数 237 患者数 22 429 科室数 24 每个科室下平均患者数 935 每个科室下平均医生数 10 每位医生平均治疗的患者数 95 患者咨询文本的平均长度 188 医生个人简历的平均长度 106 表 2 不同模型在4个评价指标上的实验结果
Table 2 Experimental results of different methods on four evaluation metrics
方法 Accuracy@1 MRR@10 MAP@100 NDCG@10 Random 0.0042 0.0102 0.0203 0.0166 Frequency 0.0011 0.0050 0.0118 0.0093 BERT-SIM 0.0832 0.0913 0.1072 0.1460 KNN 0.1230 0.2387 0.2037 0.3219 BERT-MLP 0.3053 0.3194 0.3516 0.4050 DSSM 0.3860 0.4276 0.4664 0.4319 SBERT 0.4108 0.5598 0.5671 0.6335 STWD-DA 0.5154 0.6617 0.6667 0.7219 表 3 消融实验结果
Table 3 Experimental results of ablation experiments
方法 Accuracy@1 MRR@10 MAP@100 NDCG@10 SBERT 0.4108 0.5598 0.5671 0.6335 SBERT-random 0.4411 0.5895 0.5960 0.6587 SBERT-DNS 0.4879 0.6306 0.6367 0.6900 STWD-DA 0.5154 0.6617 0.6667 0.7219 表 4 针对不同α值的模型性能比较分析
Table 4 Comparison analysis of model performance for different α values
α Accuracy@1 MRR@10 MAP@100 NDCG@10 0.1 0.5092 0.6575 0.6628 0.7179 0.3 0.5143 0.6605 0.6657 0.7205 0.5 0.5137 0.6601 0.6653 0.7200 0.7 0.5154 0.6617 0.6667 0.7219 0.9 0.5126 0.6594 0.6647 0.7194 -
[1] CHEN Min, YANG Jun, ZHOU Jiehan, et al. 5G-smart diabetes: toward personalized diabetes diagnosis with healthcare big data clouds[J]. IEEE communications magazine, 2018, 56(4): 16−23. doi: 10.1109/MCOM.2018.1700788 [2] 孟秋晴, 熊回香. 基于在线问诊文本信息的医生推荐研究[J]. 情报科学, 2021, 39(6): 152−160. MENG Qiuqing, XIONG Huixiang. Doctor recommendation based on online consultation text information[J]. Information science, 2021, 39(6): 152−160. [3] HUANG Chao, CHEN Jiahui, XIA Lianghao, et al. Graph-enhanced multi-task learning of multi-level transition dynamics for session-based recommendation[C]//Proceedings of the AAAI conference on artificial intelligence. Menlo Park: AAAI, 2021, 35(5): 4123−4130. [4] 叶佳鑫, 熊回香, 蒋武轩. 一种融合患者咨询文本与决策机理的医生推荐算法[J]. 数据分析与知识发现, 2020, 4(S1): 153−164. YE Jiaxin, XIONG Huixiang, JIANG Wuxuan. A physician recommendation algorithm integrating inquiries and decisions of patients[J]. Data analysis and knowledge discovery, 2020, 4(S1): 153−164. [5] 翟姗姗, 胡畔, 潘英增, 等. 融合知识图谱与用户病情画像的在线医疗社区场景化信息推荐研究[J]. 情报科学, 2021, 39(5): 97−105. ZHAI Shanshan, HU Pan, PAN Yingzeng, et al. Scenario-based information recommendation of online medical community based on knowledge graph and disease portrait[J]. Information science, 2021, 39(5): 97−105. [6] GU Zhiqiang, ZHANG Yuejin. Research on online medical community doctor recommendation based on information fusion[C]//IEEE/WIC/ACM International Conference on Web Intelligence. New York: ACM, 2021: 514−519. [7] ZHENG Zhi, QIU Zhaopeng, XIONG Hui, et al. DDR: dialogue based doctor recommendation for online medical service[C]//Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Washington: ACM, 2022: 4592−4600. [8] LU Xiaoxin, ZHANG Yubo, LI Jing, et al. Doctor recommendation in online health forums via expertise learning[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Dublin: USAACL, 2022: 1111−1123. [9] YUAN Hui, DENG Weiwei. Doctor recommendation on healthcare consultation platforms: an integrated framework of knowledge graph and deep learning[J]. Internet research, 2022, 32(2): 454−476. doi: 10.1108/INTR-07-2020-0379 [10] LI Quan, CHEN Lingwei, CAI Yong, et al. Hierarchical graph neural network for patient treatment preference prediction with external knowledge[M]//Advances in Knowledge Discovery and Data Mining. Cham: Springer Nature Switzerland, 2023: 204−215. [11] YAO Yiyu. Three-way decisions with probabilistic rough sets[J]. Information sciences, 2010, 180(3): 341−353. doi: 10.1016/j.ins.2009.09.021 [12] YAO Yiyu, DENG Xiaofei. Sequential three-way decisions with probabilistic rough sets[C]//IEEE 10th International Conference on Cognitive Informatics and Cognitive Computing. Banff: IEEE, 2011: 120−125. [13] CHE Mingxuan, ZHAO Lasheng, JIN Bo, et al. A doctor recommendation framework for online medical platforms using multi-source heterogeneous data[C]//Proceedings of the 2021 7th International Conference on Computing and Artificial Intelligence. Tianjin: ACM, 2021: 326−331. [14] 梁建树, 叶晓庆, 刘盾. 面向在线问诊平台的三支推荐方法[J]. 西北大学学报(自然科学版), 2022, 52(5): 784−796. LIANG Jianshu, YE Xiaoqing, LIU Dun. Three-way recommendations for online medical consultation platform[J]. Journal of northwest university (natural science edition), 2022, 52(5): 784−796. [15] SINGH H, SINGH M B, SHARMA R, et al. Optimized doctor recommendation system using supervised machine learning[C]//Proceedings of the 24th International Conference on Distributed Computing and Networking. Kharagpur: ACM, 2023: 360−365. [16] CHEN Yi, LI Chusong, TANG Minglu. Online doctor recommendation method for doctor-patient interaction data and doctor attributes[C]//2023 IEEE 17th International Conference on Application of Information and Communication Technologies. Baku: IEEE, 2023: 1−6. [17] 聂卉, 蔡瑞昇. 引入注意力机制的在线问诊推荐研究[J]. 数据分析与知识发现, 2023, 7(8): 138−148. NIE Hui, CAI Ruisheng. Online doctor recommendation system with attention mechanism[J]. Data analysis and knowledge discovery, 2023, 7(8): 138−148. [18] LIANG Decui, YI Bochun, CAO Wen, et al. Exploring ensemble oversampling method for imbalanced keyword extraction learning in policy text based on three-way decisions and SMOTE[J]. Expert systems with applications, 2022, 188: 116051. doi: 10.1016/j.eswa.2021.116051 [19] SHEN Feng, YANG Zhiyuan, ZHAO Xingchao, et al. Reject inference in credit scoring using a three-way decision and safe semi-supervised support vector machine[J]. Information sciences, 2022, 606: 614−627. doi: 10.1016/j.ins.2022.05.067 [20] ZHOU Jing, LIU Yu, LIANG Decui, et al. Two-stage three-way enhanced multi-criteria classification optimization for risk-averse product design programming[J]. Information sciences, 2023, 632: 757−775. doi: 10.1016/j.ins.2023.03.068 [21] LIU Dun, YE Xiaoqing. A matrix factorization based dynamic granularity recommendation with three-way decisions[J]. Knowledge-based systems, 2020, 191: 105243. doi: 10.1016/j.knosys.2019.105243 [22] YE Xiaoqing, LIU Dun. A cost-sensitive temporal-spatial three-way recommendation with multi-granularity decision[J]. Information sciences, 2022, 589: 670−689. doi: 10.1016/j.ins.2021.12.105 [23] LI Huaxiong, ZHANG Libo, HUANG Bing, et al. Sequential three-way decision and granulation for cost-sensitive face recognition[J]. Knowledge-based systems, 2016, 91: 241−251. doi: 10.1016/j.knosys.2015.07.040 [24] YANG Xin, LOUA M A, WU Meijun, et al. Multi-granularity stock prediction with sequential three-way decisions[J]. Information sciences, 2023, 621: 524−544. doi: 10.1016/j.ins.2022.11.077 [25] LIANG Decui, WU Yiqi, DUAN Weiyi. Multiple granularity user intention fairness recognition of intelligent government Q & A system via three-way decision[J]. Information sciences, 2023, 631: 305−326. doi: 10.1016/j.ins.2023.02.070 [26] ROBINSON J, CHUANG C Y, SRA S, et al. Contrastive learning with hard negative samples[EB/OL]. (2020−10−09)[2024−06−10]. https://arxiv.org/abs/2010.04592v2. [27] LIANG Decui, YI Bochun. Two-stage three-way enhanced technique for ensemble learning in inclusive policy text classification[J]. Information sciences, 2021, 547: 271−288. doi: 10.1016/j.ins.2020.08.051 [28] DEVLIN J, CHANG Mingwei, LEE K, et al, Bert: pre-training of deep bidirectional transformers for language understanding[C]//Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis: NAACL, 2019: 4171–4186. [29] REIMERS N, GUREVYCH I. Sentence-BERT: sentence embeddings using Siamese BERT-networks[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong-Kong: USAACL, 2019. [30] HADSELL R, CHOPRA S, LECUN Y. Dimensionality reduction by learning an invariant mapping[C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2006: 1735−1742. [31] LI Huaxiong, ZHANG Libo, ZHOU Xianzhong, et al. Cost-sensitive sequential three-way decision modeling using a deep neural network[J]. International journal of approximate reasoning, 2017, 85: 68−78. doi: 10.1016/j.ijar.2017.03.008 [32] ZHANG Ningyu, JIA Qianghuai, YIN Kangping, et al. Conceptualized representation learning for Chinese biomedical text mining[EB/OL]. (2020−08−25)[2024−06−10]. https://arxiv.org/abs/2008.10813v1. [33] HUANG Posen, HE Xiaodong, GAO Jianfeng, et al. Learning deep structured semantic models for web search using clickthrough data[C]//Proceedings of the 22nd ACM International Conference on Information & Knowledge Management. San Francisco: ACM, 2013: 2333−2338. [34] MIKOLOV T, CHEN Kai, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013−01−16)[2024−06−10]. https://arxiv.org/abs/1301.3781v3.





































