
Predicting postoperative pulmonary complications after lung surgery using nmODE
-
摘要: 为了准确预测病人肺部手术后并发症的发生,提出了一种融合神经记忆常微分方程(neural memory ordinary differential equation, nmODE)的并发症预测模型。首先,利用极限梯度提升(extreme gradient boosting, XGBoost)树结构对数据进行编码,并提取其特征重要性。然后,使用长短时记忆神经网络对数据的相关特征依赖性进行分析,并提取处理后的特征。最后,利用nmODE的记忆和学习能力,对提取的特征进行深入分析,并得出最终的预测结果。通过实验评估,在肺部术后并发症数据集中,证明了提出模型的效果优于现有模型,同时可以为预测肺部手术后并发症的发生提供更准确的结果。Abstract: In order to accurately predict the occurrence of postoperative complications in patients' lungs, a complication prediction model combining neural memory ordinary differential equation (nmODE) is proposed. The method of this model is as follows: firstly, an extreme gradient boosting (XGBoost) tree structure is used to encode the data and extract its feature importance. Then, a long short-term memory neural network is employed to analyze the dependency of the data's relevant features and extract the processed features. Finally, by utilizing the memory and learning capabilities of nmODE, the extracted features are deeply analyzed to obtain the final prediction results. Experimental evaluation has demonstrated the effectiveness of the proposed model in the dataset of postoperative complications in the lungs, showing superior performance compared with existing models. Furthermore, it can provide more accurate results for predicting the occurrence of postoperative complications in lung surgery.
-
术后肺部并发症(postoperative pulmonary complications, PPCs)是指手术后出现肺部异常和功能障碍的情况,对患者的健康和康复产生负面影响,可能导致心血管和免疫系统问题,延长住院时间并增加医疗费用。近年来发现随着人口的发展和围手术期医学的进步,胸外科患者的数量不断增加。然而,术后肺部并发症发生率仍高达30.0%~50.0%[1],对患者预后有显著影响。为了能够在早期发现术后肺部并发症的危险因素,识别高危人群,并采取相应的干预措施以减少和预防术后肺部并发症的发生,术后肺部并发症风险预测模型应运而生。通过预测模型的使用,可以实现患者的精准、分层管理,有效减少和预防术后肺部并发症的发生,提高手术病人的治疗效果和康复质量。现有的术后肺部并发症预测方法主要采用统计学方法建立风险预测模型,使用如Logistic回归[2]和Cox回归[3]来分析独立的影响因素,并根据回归系数建立模型。然而,这些方法需要人工进行复杂的分析,无法准确建模。同时通过神经网络建立术后肺部并发症预测模型的相关研究较少,预测效果不理想。针对术后肺部并发症预测模型的构建存在两个问题,1)难以有效建模术后肺部并发症数据:数据为异构表格形式,包含了离散和连续变量的混合,神经网络对于异构表格数据的建模能力欠缺。2)特征之间存在较强的依赖关系:数据集中的部分特征之间存在较强的依赖性问题,这可能影响模型的性能。
为了解决这两个问题,本文提出了一种基于神经记忆常微分方程(neural memory ordinary differential equation,nmODE)的肺部术后并发症预测模型(nmPPCNet)。对于异构表格数据难以建模的问题,使用极限梯度提升(extreme gradient boosting,XGBoost)[4]树结构对数据进行编码,并提取其特征重要性。其次使用长短时记忆神经网络(long short-term memory, LSTM)[5]对数据的相关特征依赖性进行分析并提取处理后的特征。最后利用nmODE[6]记忆与学习能力,分析提取的特征并给出最终的预测结果。本文提出的模型结合了树模型和神经网络的优点,提高模型在表格数据预测中的性能,同时增加模型的可解释性。综上所述,本文的主要贡献如下:
1)提出一个新的术后肺部并发症数据集。
2)提出一种全新的神经网络模型,用于预测术后肺部并发症,并通过实验评估,证明所提出模型比现有模型效果更好。
1. 相关工作
1.1 研究临床意义
影响外科手术并发症发生率、围术期死亡率的原因多种多样。既往的相关研究主要关注外科手术技术选择、手术策略设计、患者术前基础状况等与临床治疗直接相关的因素。而近年来,手术时刻、季节、气候、环境等宏观时空环境对术后恢复的影响正逐渐受到关注。有研究表明,环境及生物节律可能影响手术患者的基础生理活动,进而影响患者手术效果[7-8]。当地气候季节和舒适度等级变化对居民心脑血管疾病发病人数占比有影响[9]。季节与气温对疾病发病率和死亡率也会产生影响[10]。由此说明,宏观环境因素对于外科手术术后康复可能存在影响,而且这种影响可能与其他临床因素对患者术后的影响同等重要。
有研究表明,寒冷季节为多种呼吸系统疾病的高发季节。呼吸系统感染性疾病发病率也在寒冷季节有明显上升[11-12]。对于呼吸系统生理学功能而言,寒冷气温可以导致呼吸道免疫功能下降。而手术患者若合并呼吸系统基础疾病,则可能使季节因素更加明显地影响手术患者的术后康复[13]。在不同季节环境进行肺切除手术的患者,其术后康复情况很可能由于季节环境的不同而存在差异。
术后肺部并发症是患者和临床医生关注的重点问题,也是胸外科发展中的难题。近年来,外科和麻醉技术的进步推动了术后肺部并发症的预防和治疗。然而大多数预测模型仅纳入局部手术数据,未对当天季节因素的影响进行全面考虑。这可能导致预测模型的数据来源不全面,无法充分反映术后肺部并发症的发生风险。因此在预测模型的构建中应考虑更加全面的数据来源,包括术中和术后环境因素的影响。这将有助于指导临床医生采取相应的预防和治疗措施,提高患者的手术安全性和康复效果。
1.2 异构表格数据的挑战
日益增长的计算机算力和大型标记数据集的可获得性加快了深度神经网络的成功。尽管深度学习方法在处理同质数据(例如图像、音频和文本数据)的分类或数据生成任务方面表现出色,但表格数据仍然对深度学习模型构成挑战[14]。异构表格数据不像图像数据可以通过空间关系引入特征之间的相关性,它需要在不依赖空间信息的前提下发现相关性。因此,Kadra等[15]将表格数据集称为深度神经网络模型的最后一个“未被征服的城堡”。近年来随着神经网络的发展,在表格数据中新的模型被提出,这些模型在具有许多分类变量的异构数据集上进行快速准确的预测。如在神经网络内部模拟树模型,Net-dnf (effective deep modeling of tabular data) [16]、NODE (neural ordinary differential equations)[17] 和SDTR (smooth decision tree regression)[18] ;基于Transformer的神经网络模型,如TabNet (attentive interpretable tabular learning network) [19];将神经网络与树模型相结合,如XBNet (an extremely boosted neural network) [20] 、DeepGBM (a deep learning framework for gradient boosting machines)[21] 和NBDT (neural-backed decision trees)[22] 。但是,神经网络模型的性能尚未达到预期,并且使用神经网络进行准确的表格数据建模仍然是一个值得研究的问题,需要进一步的研究来解决。同时,树模型也被广泛用于处理表格数据,如文献[23]提出的greedy function approximation、文献[24]提出的a decision-theoretic generalization of on-line learning and an application to boosting、Random Forests [25]、XGBoost、LightGBM (a highly efficient gradient boosting decision tree)[26]、DecisionTree[27]等,被学者和从业者广泛应用于表格数据的分类和回归问题中。这些模型反复地分割输入向量空间,最终得到结果。虽然这些模型在细节上有所不同,但在大多数任务上,它们的表现差不多。树模型在分类和回归问题上通常比神经网络表现得更好。但是容易出现过拟合现象,使得模型的泛化能力不好。
因此本文提出了一个新的神经网络模型(nmPPCNet)旨在解决表格数据建模中的困难,并同时捕捉不同特征之间的依赖关系,以提高预测的准确性和模型的泛化性。
1.3 NeuralODE
在数学上,常微分方程(ordinary differential equation, ODE)可以用来描述动力学系统。同时,神经网络也可以被ODE建模。Chen等[28]提出了NeralODE的概念,利用ODE描述ResNet的连续版本,表明NeralODE具有记忆效率高、能自适应计算、参数效率高等优点。NeuralODE认为t是连续的,隐藏状态h(t)由一个ODE系统表示:
$$ \frac{{{\text{d}}h(t)}}{{{\text{d}}t}} = f(h(t),t;\theta ) $$ (1) 式中f为由参数θ定义的神经网络。以微分方程的概念来解释神经网络是近年来兴起的一个新的研究方向,研究者们首先假设特定类型的神经网络可以看作是离散的微分方程,所以可以使用现成的微分方程求解器来进行计算,希望可以得到效果更好且具有强解释性的结果。神经常微分方程的核心操作是对网络隐藏层状态的导数进行参数化,进而建立起与隐藏层强相关的微分方程,如果可以使用某种手段直接将中间层的结果求解出来,NeuralODE有望避免复杂且大量重复的反向传播过程,从而提高存储效率。但是随着研究也发现ODE建模的问题,Dupont等[29]证明一般神经元ODE存在学习特征与输入数据空间同构的问题。
一个新的神经记忆ODE(nmODE)的提出也解决了上述同构问题。nmODE设计了一个特殊结构,它将学习神经元与记忆神经元分开并加上一种使用网络中吸引子的记忆机制,建立起外部输入和记忆之间的关系,具有相当清晰的动态,也不存在同构问题。nmODE的提出为研究神经网络问题提供了一种新的思路,本文在表格数据处理中,利用nmODE记忆与学习能力,分析提取的特征并给出最终的预测结果,提升神经网络在表格数据上的表现。
2. 模型构建
2.1 问题阐述
在本文中,定义了以下参数和变量:
输入特征集合K = {
$\mathop k\nolimits_1 $ ,$\mathop k\nolimits_2 $ , ···,$\mathop k\nolimits_m $ },其中k表示样本的特征,m表示特征的数量;数据集X ={
$\mathop x\nolimits_1 $ ,$\mathop x\nolimits_2 $ , ···,$\mathop x\nolimits_n $ },其中n表示样本的数量,每个样本包含特征集合中的所有特征;标签集合Y= {
$ \mathop y\nolimits_1 $ ,$\mathop y\nolimits_2 $ , ···,$\mathop y\nolimits_n $ },数据集X中的第i个样本$ \mathop x\nolimits_i $ 对应的标签$ \mathop y\nolimits_i $ ;XGBoost模块函数
$G( \cdot )$ ,该函数生成基于树结构的模型T。信息增益E用于衡量在树分裂中特征带来的提升。目标函数使用$\mathop E\nolimits_{\text{a}} $ 表示树分裂前的目标函数,$\mathop E\nolimits_{\text{b}} $ 表示树分裂后的目标函数,用于评估树的拟合效果;LSTM模块函数
$L( \cdot )$ ;nmODE模块函数
$O( \cdot )$ 。任务目标是构建一个神经网络模型,以有效地预测特征集合X与标签集合Y之间的映射关系,模型结构如图1所示。
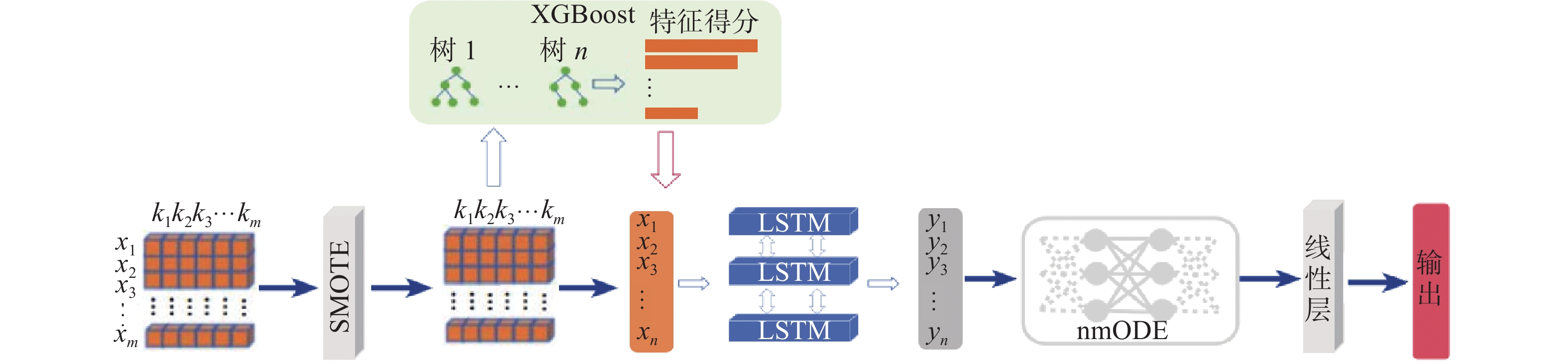 图 1 nmPPCNet模型Fig. 1 nmPPCNet model
图 1 nmPPCNet模型Fig. 1 nmPPCNet model 下载:
全尺寸图片
下载:
全尺寸图片
2.2 结合XGBoost与LSTM
为了有效解决术后肺部并发症数据的建模问题,本文首先,引入XGBoost来处理数据集,并对每个特征进行打分以确定其重要性。通过对特征得分进行归一化,并将其用于权重初始化,能够促进神经网络的快速收敛。其次,考虑到特征之间存在较强依赖关系,采用了LSTM来学习不同特征之间的关联。通过神经网络模型,提高了模型的泛化能力,使其能够更好地适应术后并发症数据的特点。采用这些方法能够更有效地处理术后肺部并发症数据,提升建模的准确性和性能。
本文设计一个将XGBoost与LSTM结合的模块。在该模块的构建过程中,利用XGBoost来评估数据集中的特征重要性。这种方式可以快速筛选出对模型性能有较大影响的特征,从而减少计算成本。使用XGBoost构建了n棵树来实现预测:
$$ y = \sum\limits_{i = 1}^n {\mathop G\nolimits_i (x)} $$ (2) 式中:x表示数据集的输入特征,y表示XGBoost的输出,
$ {G}_{i} $ (x)表示第i棵树的叶子节点得分。树是通过计算信息增益来进行分裂的。假设生成的一棵树为T,对每个特征进行分裂收益计算,分裂前的目标函数表示为$$ \mathop E\nolimits_{\text{a}} = - \frac{1}{2}\left(\frac{{{{(\mathop T\nolimits_{{\text{GL}}} + \mathop T\nolimits_{{\text{GR}}} )}^2}}}{{\mathop T\nolimits_{{\text{HL}}} + \mathop T\nolimits_{{\text{HR}}} + \lambda }}\right) + \gamma $$ (3) 式中:
$ {T}_{\mathrm{G}\mathrm{L}} $ 为左子树所包含样本的一阶偏导数累加之和,$ {T}_{\mathrm{H}\mathrm{L}} $ 为左子树所包含样本的二阶偏导数累加之和,$ {T}_{\mathrm{G}\mathrm{R}} $ 为右子树所包含样本的一阶偏导数累加之和,$ T_{\mathrm{H}\mathrm{R}} $ 为右子树所包含样本的二阶偏导数累加之和,$ \lambda $ 和$ \mathrm{\gamma } $ 为惩罚系数。分裂后的目标函数为$$ {{\displaystyle E}}_{\text{b}}=-\frac{1}{2}\left(\frac{{{\displaystyle T}}_{\text{GL}}^{2}}{{{\displaystyle T}}_{\text{HL}}+\lambda }+\frac{{{\displaystyle T}}_{\text{GR}}^{2}}{{{\displaystyle T}}_{\text{HR}}+\lambda }\right)+2\gamma $$ (4) 信息增益衡量的是节点在分裂前后目标函数的差异,计算公式为
$$ E = \mathop E\nolimits_{\text{a}} - \mathop E\nolimits_{\text{b}} $$ (5) 这个模块首先使用XGBoost模型对训练数据集进行拟合,并计算每个特征在每棵决策树中的分裂增益,从而评估特征的重要性。通过分析这些分裂增益,可以得到特征的分数,进而更深入地了解它们在模型中的重要性和在决策过程中的作用。然后,对于特征集合K ={k1, k2, ···, km} 中的每个特征ki相应的分数进行遍历,并记录最大值max(k) 和最小值min(k)。对于i ≤ m重新计算ki:
$$ \mathop k\nolimits_i = \frac{{\mathop k\nolimits_i - \min (k)}}{{\max (k) - \min (k)}} $$ 经过处理得到特征得分,如手术分钟数、住院时间、季节的特征得分很高,将这些特征得分作为LSTM模型的初始权重。这种做法有助于模型更快地收敛,通过给予重要特征更高的初始权重,可以提前引导模型学习到重要特征的信息。在LSTM模型中,使用输入门、输出门和遗忘门机制来传递和选择信息。输入门用来更新当前状态的信息,输出门用来选择当前时刻输出的信息,遗忘门用来选择上一时刻需要丢弃的信息。这种门控机制与本文希望从数据中提取相关性和选择有用信息的目标非常一致。
综合使用XGBoost和LSTM模型,能够充分发挥它们各自的优势,提高模型性能。XGBoost擅长处理稀疏特征和非线性关系,筛选出影响结果的重要特征,而LSTM可以捕捉特征之间的依赖关系。通过综合运用它们,能够更好地应对复杂的数据分析和预测任务,以提高模型的表现能力。
2.3 nmODE模块
nmODE是一种特殊的神经常微分方程,它是一个针对记忆神经元的解耦系统,可以看作是由神经元ODE块构建的。与许多传统的神经元数学模型不同,神经元ODE由一个ODE动态系统描述,这方便进行动态分析。特别地,nmODE中每个学习连接只从一个输入神经元连接到记忆神经元,而任何两个记忆神经元之间都没有学习连接。这样的设计使得学习与记忆彼此分离,使得模型更易于进行学习。这也体现出nmODE的特有体系结构,如图2所示。
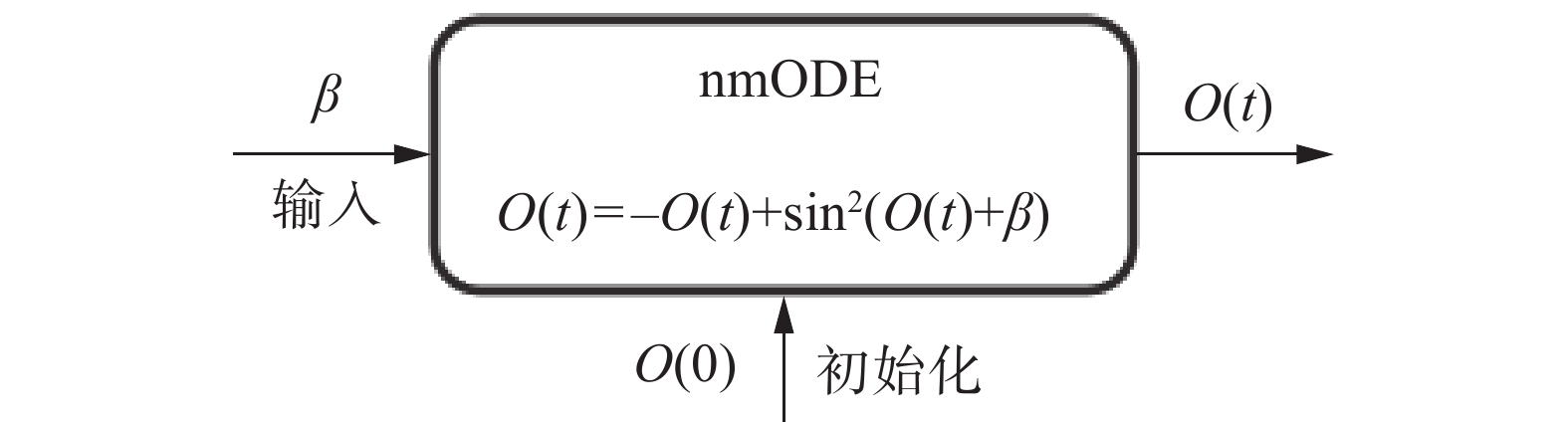 图 2 nmODE结构Fig. 2 Structure of nmODE下载:
全尺寸图片
图 2 nmODE结构Fig. 2 Structure of nmODE下载:
全尺寸图片
nmODE框架为实现非线性映射提供了一个通用的体系结构。在实践过程中,引入了一种新的等式,实现公式为
$$ O(t)= - O(t) + \mathop {\sin }\nolimits^2 (O(t) + \beta ) $$ 式中:β代表外部输入;O(0)为初始内部输入,可以任意设置。给定初始内部输入O(0)和外部输入β,nmODE将输出O(t)。该方程的一个重要优势是它只有一个全局吸引子,它代表了系统的长期行为和稳定性。无论起点或初始条件如何,系统都会趋向于同一个全局吸引子。这一概念被广泛应用于研究物理、生物学和经济学等各领域中复杂和动态系统的行为。人们普遍认为动态系统中的吸引子与记忆有关。因此,将nmODE纳入模型可能会提高训练数据集的准确性,并改善噪声鲁棒性。
针对特征之间存在强烈的相互依赖关系的问题,采用nmODE的独特网络结构,通过将学习和记忆过程分离,更好地捕捉特征之间的依赖关系。为了提升肺部并发症预测模型的性能,引入nmODE模块作为模型的一部分。在本文的体系结构中,nmODE被放置在第3层,旨在处理经过LSTM的特征。nmODE模块的输出将被传递给后续的线性层,用于进行并发症预测。数据首先经过XGBoost树模型进行编码,并提取特征重要性。然后,经过LSTM对数据的特征进行分析和提取。最后,将处理后的数据传入nmODE模块。对于本任务进行了一些修改,使nmODE的实现公式变为
$$ \left\{\begin{array}{l} {O(t) = - O(t) + {\cos }^2 (O(t) + \beta )} \\ {\beta = L(x)} \end{array} \right.$$ 式中:L(x)代表LSTM模块的输出,x代表数据集数据,O(t)代表网络在t时刻的状态,t ≥0。在模型训练过程中,引入了适应性和动态参数更新的方法来改进模型的性能。这意味着允许模型的参数根据输入数据的波动性进行变化。通过这种方式,本文的模型可以更好地适应不同特征的依赖关系,并及时调整nmODE模块的参数以更准确地预测肺部并发症的发生。本文通过迭代的方式交替训练nmODE模块,并利用了其深度分析和处理特征依赖关系的能力。最后,使用线性层将这些经过处理的特征转化为最终的预测输出。这样的训练方法可以充分利用nmODE模块的特点,从而提高模型的准确性。
通过nmODE模块,能够获得更精确的预测结果并更好地捕捉不同特征对结果的综合影响,从而提高模型的稳定性。nmODE模块通过深入分析和处理特征之间的依赖关系,更好地理解数据间的复杂关系,并根据输入数据的波动性进行动态参数更新。这使得本文模型能够更好地适应不同特征的变化和相互作用,提供更准确、可靠的预测效果。同时,这种学习行为增强了模型的稳定性,使其在面对不同的输入数据和场景时能够保持一致的表现。
3. 实验仿真及结果分析
3.1 实验设置
3.1.1 数据集
本研究使用了华西医学院胸外科收集的数据,包含了31个可能导致并发症的原因,如手术时间、患者吸烟史和季节等。要对数据进行预处理,首先要对数据集中的患者数据进行获取,对于患者数据存在空白和不详的情况,选择删除这类病人数据。接着将获取到特征没有缺失的患者数据进行存储。存储的数据集中特征类别不一致,如有int类型数据(留置根数、身体质量指数分类、手术时长等),char类型数据(吸烟史、性别、季节等),string类型数据(肺功能情况、开胸还是微创等)。需要将不同类型的数据转化为数值类型,方便模型进行训练。最后,对数据进行独热编码。然而,实验数据存在严重的样本不平衡问题,负样本数量占据绝大部分,未经处理可能导致过拟合。为了解决这个问题,本研究采用了合成少数过采样技术(synthetic minority oversampling technique,SMOTE)[30]来处理数据样本不平衡。该算法基于每个样本点的K个最近邻样本,随机选择N个邻近点,并通过插值生成取值在[0, 1]的阈值来合成数据。输入为数据集X,输出为采样后的数据集,规模为(N/100)×T。算法有3个参数:T表示待处理的样本数量,N表示采样比例,K表示最近邻样本数。本实验中,K设为5。
采用过采样和欠采样的结合方法,可以在ROC(receiver operating characteristic)空间中获得比单纯过采样效果更好的分类性能,因此本实验采用过采样和欠采样相结合的方法。初始数据中正、负样本比例为766∶5 515。经过采样和欠采样处理,正、负样本比例调整为2∶1。同时,按照0.8∶0.2的比例将数据集划分为训练集和测试集。
3.1.2 基准方法
为了验证本文方法,选择了XGBoost作为基线模型,并采用Adam优化器和BCELoss作为损失函数,学习率设置为0.000 1。进行了200轮的训练,同时在训练时采用五折交叉验证。通过这样的设置,可以使用华西制作的数据集进行对比实验,并评估本文方法的性能。训练过程中的参数选择可以根据实际情况进行调整,以获得更好的模型性能。
3.1.3 评估指标
使用准确率(Acc)、精确性(Precision)、ROC曲线下的面积(Auc)、召回率(Recall)和F1分数(F1-score)等指标来评估模型的性能。其中,Acc是常用的评估指标,但在存在类别不平衡的数据集中,其评估效果不佳,因为它受样本数量的影响。除了准确率外,还应综合考虑其他评估指标,以全面评估模型的性能。对于所有这些指标,数值越高表示模型性能越好。
3.2 消融实验与统计学检验
为评估不同模块对模型预测性能的影响进行消融实验,通过有目的地删除LSTM模块或nmODE模块,观察模型在改变这些模块时性能指标的变化,可以评估这些模块对模型的影响。选择相同的参数设置进行200轮的训练,实验结果如表1所示。
表 1 消融实验结果Table 1 Results of ablation experimentsnmODE LSTM Acc Precision Auc Recall F1-score 0.78 0.48 0.85 0.78 0.77 √ 0.79 0.42 0.86 0.75 0.76 √ 0.80 0.47 0.83 0.78 0.78 √ √ 0.82 0.42 0.87 0.78 0.80 从表1可以看到,将nmODE和LSTM模块加入模型确实对模型的性能起到了积极作用,并提升了模型效果。针对强依赖性的数据集,采用具备长期依赖性和记忆能力的模型能更好地提取有效特征,进而提高模型的准确率。
同时,考虑到本文的模型2与只加入nmODE模块的模型1相比评价指标Recall差距不是非常显著,对这两个模型进行统计学检验,将两个模型各运行10次并记录评价指标。首先假设两个模型在预测的均值上没有差异,对模型进行t检验结果的p值为2.372×10−2,可以看到t检验的p值小于0.05,说明拒绝原假设,即两个模型在该指标上的均值有差异。然后假设两个模型在预测的均值方差没有差异,进行F检验结果的p值为0.865 2,p值大于0.5,表明接受原假设,即这两个模型10组结果的稳定程度一致。最后比较均值,模型2大于模型1,说明模型2在统计学上的表现优于模型1。
3.3 对比实验
为证明本文模型的有效性,与XGBoost、XBNet、Random Forest、DecisionTree进行对比实验,使用Acc、Precision、Auc等性能指标评估模型性能,经过200轮的训练后,对比实验结果见表2。
表 2 对比实验结果Table 2 Results of comparative experiment模型 Acc Precision Auc Recall F1-score XGBoost 0.80 0.79 0.86 0.72 0.75 XBNet 0.80 0.77 0.86 0.78 0.77 Random Forest 0.81 0.74 0.78 0.68 0.71 DecisionTree 0.79 0.66 0.76 0.70 0.68 nmPPCNet 0.82 0.80 0.87 0.78 0.80 从表2可以看出,本文模型在所有指标中表现最好,这表明本文模型比其他模型在预测性能上更具竞争力。本文模型在与经典的树模型和神经网络模型进行比较时表现最佳,表明本文模型在私有数据集上展现出较高的性能,并进一步验证了本文模型设计和参数调整的有效性。同时,在公开数据集上进行对比,采用的公开数据集是威斯康星州乳腺癌数据集和Pima Indians糖尿病发病情况数据集。威斯康星州乳腺癌数据集包含了从乳腺癌患者收集的肿瘤特征的测量值以及相应的良性或恶性标签。Pima Indians糖尿病数据集中包含一些预测患者是否患有糖尿病的诊断性测量。2个数据集包含多个临床数据和一个标签,临床数据包括患者的怀孕次数、BMI指数、胰岛素水平、年龄等。对数据集进行拆分,测试集占总数据的30%,模型参数保持默认设置不做任何改动。结果如表3和表4所示。
表 3 乳腺癌数据集实验结果Table 3 Experiment results of breast cancer模型 Acc Precision Auc Recall F1-score XGBoost 0.95 0.95 0.96 0.94 0.95 XBNet 0.95 0.94 0.99 0.94 0.95 Random Forest 0.95 0.95 0.96 0.95 0.95 DecisionTree 0.94 0.90 0.94 0.93 0.92 nmPPCNet 0.95 0.95 0.99 0.95 0.95 表 4 糖尿病数据集实验结果Table 4 Experiment results of diabetes cancer模型 Acc Precision Auc Recall F1-score XGBoost 0.73 0.62 0.68 0.51 0.56 XBNet 0.75 0.68 0.69 0.66 0.58 Random Forest 0.74 0.67 0.68 0.51 0.55 DecisionTree 0.72 0.62 0.65 0.52 0.53 nmPPCNet 0.78 0.68 0.71 0.70 0.62 4. 结束语
肺癌患者常采用手术切除作为治疗方法,但术后并发症可能对患者康复产生重大影响,给其带来心理压力。通过提前预测患者手术适宜性及术后不良反应,并采取有效治疗手段,为患者量身定制护理方案,可以降低并发症发生率,减轻患者负担。因此,术前预测起着关键作用。
本文提出了一种创新的神经网络模型,融合了树模型和神经网络模型,并引入了nmODE模块用于术后并发症预测。通过与其他模型在数据集上的比较,验证了该模型卓越的性能,可作为术前评估工具,指导患者围手术期的治疗,更有效地预防术后肺部并发症的发生,为医生提供帮助。
-
图 1 nmPPCNet模型
Fig. 1 nmPPCNet model
下载:
全尺寸图片
图 2 nmODE结构
Fig. 2 Structure of nmODE
下载:
全尺寸图片
表 1 消融实验结果
Table 1 Results of ablation experiments
nmODE LSTM Acc Precision Auc Recall F1-score 0.78 0.48 0.85 0.78 0.77 √ 0.79 0.42 0.86 0.75 0.76 √ 0.80 0.47 0.83 0.78 0.78 √ √ 0.82 0.42 0.87 0.78 0.80 表 2 对比实验结果
Table 2 Results of comparative experiment
模型 Acc Precision Auc Recall F1-score XGBoost 0.80 0.79 0.86 0.72 0.75 XBNet 0.80 0.77 0.86 0.78 0.77 Random Forest 0.81 0.74 0.78 0.68 0.71 DecisionTree 0.79 0.66 0.76 0.70 0.68 nmPPCNet 0.82 0.80 0.87 0.78 0.80 表 3 乳腺癌数据集实验结果
Table 3 Experiment results of breast cancer
模型 Acc Precision Auc Recall F1-score XGBoost 0.95 0.95 0.96 0.94 0.95 XBNet 0.95 0.94 0.99 0.94 0.95 Random Forest 0.95 0.95 0.96 0.95 0.95 DecisionTree 0.94 0.90 0.94 0.93 0.92 nmPPCNet 0.95 0.95 0.99 0.95 0.95 表 4 糖尿病数据集实验结果
Table 4 Experiment results of diabetes cancer
模型 Acc Precision Auc Recall F1-score XGBoost 0.73 0.62 0.68 0.51 0.56 XBNet 0.75 0.68 0.69 0.66 0.58 Random Forest 0.74 0.67 0.68 0.51 0.55 DecisionTree 0.72 0.62 0.65 0.52 0.53 nmPPCNet 0.78 0.68 0.71 0.70 0.62 -
[1] SHELLEY B, MARCZIN N. Do we have the ‘power’ to ‘drive’ down the incidence of pulmonary complications after thoracic surgery[J]. British journal of anaesthesia, 2023, 130(1): e37−e40. doi: 10.1016/j.bja.2022.07.017 [2] 周菲, 焦桂梅, 赵凤兰, 等. Logistic回归的主成分改进方法探讨及其医学应用[J]. 数理医药学杂志, 2014, 27(1): 25−28. ZHOU Fei, JIAO Guimei, ZHAO Fenglan, et al. The study on the enhancing methods of principal component of logistic regression and their application to medicine[J]. Journal of mathematical medicine, 2014, 27(1): 25−28. [3] 李河, 郭兰, 孙家珍. COX回归模型在临床医学科研中的价值[J]. 循证医学, 2011, 11(1): 51−53, 59. LI He, GUO Lan, SUN Jiazhen. The values of COX regression model in the clinical medicine research[J]. The journal of evidence-based medicine, 2011, 11(1): 51−53, 59. [4] CHEN Tianqi, GUESTRIN C. XGBoost: a scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco: ACM, 2016: 785−794. [5] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural computation, 1997, 9: 1735−1780. doi: 10.1162/neco.1997.9.8.1735 [6] YI Zhang. nmODE: neural memory ordinary differential equation[J]. Artificial intelligence review, 2023, 56(12): 14403−14438. doi: 10.1007/s10462-023-10496-2 [7] CLOYD J M, CHEN J, MA Yifei, et al. Association between weekend discharge and hospital readmission rates following major surgery[J]. JAMA surgery, 2015, 150(9): 849−856. doi: 10.1001/jamasurg.2015.1087 [8] MONTAIGNE D, MARECHAL X, MODINE T, et al. Daytime variation of perioperative myocardial injury in cardiac surgery and its prevention by Rev-Erbα antagonism: a single-centre propensity-matched cohort study and a randomised study[J]. The lancet, 2018, 391(10115): 59−69. doi: 10.1016/S0140-6736(17)32132-3 [9] 瞿冲, 王式功, 李河利, 等. 贵阳地区气候季节变化对心脑血管发病人数占比的影响研究[J]. 沙漠与绿洲气象, 2023, 17(6): 23−31. QU Chong, WANG Shigong, LI Heli, et al. The influence of seasonal changes of climate on the proportion of cardiovascular and cerebrovascular patients in Guiyang City[J]. Desert and oasis meteorology, 2023, 17(6): 23−31. [10] 马亮, 严海琳, 肖雪, 等. 季节及气温对缺血性心脏病患者消化道出血的影响研究[J]. 中国全科医学, 2022, 25(21): 2589−2596. MA Liang, YAN Hailin, XIAO Xue, et al. Effects of season and temperature on gastrointestinal bleeding in patients with ischemic heart disease[J]. Chinese general practice, 2022, 25(21): 2589−2596. [11] 唐圣辉, 王宇清. 儿童呼吸道合胞病毒感染与气候因素的关系研究[J]. 儿科药学杂志, 2013, 19(5): 1−3. doi: 10.3969/j.issn.1672-108X.2013.05.001 TANG Shenghui, WANG Yuqing. The relationship between meteorological conditions and respiratory syncytial virus infection in hospitalized children[J]. Journal of pediatric pharmacy, 2013, 19(5): 1−3. doi: 10.3969/j.issn.1672-108X.2013.05.001 [12] RAMAEKERS K, KEYAERTS E, RECTOR A, et al. Prevalence and seasonality of six respiratory viruses during five consecutive epidemic seasons in Belgium[J]. Journal of clinical virology, 2017, 94: 72−78. doi: 10.1016/j.jcv.2017.07.011 [13] 赖玉田, 苏建华, 杨梅, 等. 术前短期综合肺康复训练对肺癌合并轻中度慢性阻塞性肺病患者的影响: 一项前瞻性随机对照试验[J]. 中国肺癌杂志, 2016, 19(11): 746−753. doi: 10.3779/j.issn.1009-3419.2016.11.05 LAI Yutian, SU Jianhua, YANG Mei, et al. Impact and effect of preoperative short-term pulmonary rehabilitation training on lung cancer patients with mild to moderate chronic obstructive pulmonary disease: a randomized trial[J]. Chinese journal of lung cancer, 2016, 19(11): 746−753. doi: 10.3779/j.issn.1009-3419.2016.11.05 [14] LAN G, YOSHUA B, AARON C. Deep learning[M]. Cambridge: MIT Press, 2016. [15] KADRA A, LINDAUER M, HUTTER F, et al. Well-tuned simple nets excel on tabular datasets[J]. Advances in neural information processing systems, 2021, 34: 23928−23941. [16] KATZIR L, ELIDAN G, EL-YANIV R. Net-dnf: effective deep modeling of tabular data[C]//The Eighth International Conference on Learning Representations. Virtual Only: ICLR, 2020. [17] RICKY T Q, CHEN Yulia, RUBANOVA J B, et al. NODE: neural ordinary differential equations for tabular data[J]. Advances in neural information processing systems, 2022, 32: 7537−7547. [18] LUO Haoran, CHENG Fan, YU Heng, et al. SDTR: soft decision tree regressor for tabular data[J]. IEEE access, 2021, 9: 55999−56011. doi: 10.1109/ACCESS.2021.3070575 [19] ARIK S Ö, PFISTER T. TabNet: attentive interpretable tabular learning[C]//Proceedings of the AAAI conference on artificial intelligence. New York: AAAI press, 2021, 35(8): 6679−6687. doi: 10.1609/aaai.v35i8.16826 [20] SARKAR T. XBNet: an extremely boosted neural network[J]. Intelligent systems with applications, 2022, 15: 200097. doi: 10.1016/j.iswa.2022.200097 [21] KE Guolin, XU Zhenhui, ZHANG Jia, et al. DeepGBM: a deep learning framework distilled by GBDT for online prediction tasks[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Anchorage: ACM, 2019: 384−394. [22] WAN A, DUNLAP L, HO D, et al. NBDT: neural-backed decision trees[EB/OL]. (2020−04−01)[2024−01−04]. https://arxiv.org/abs/2004.00221v3. [23] FRIEDMAN J H. Greedy function approximation: a gradient boosting machine[J]. The annals of statistics, 2001, 29(5): 1189−1232. doi: 10.1214/aos/1013203450 [24] FREUND Y, SCHAPIRE R E. A decision-theoretic generalization of on-line learning and an application to boosting[J]. Journal of computer and system sciences, 1997, 55(1): 119−139. doi: 10.1006/jcss.1997.1504 [25] BREIMAN L. Random forests[J]. Machine learning, 2001, 45: 5−32. doi: 10.1023/A:1010933404324 [26] KE Guolin, MENG Qi, FINLEY T, et al. LightGBM: a highly efficient gradient boosting decision tree[J]. Advances in neural information processing systems, 2017, 30: 3815895. [27] MYLES A J, FEUDALE R N, LIU Yang, et al. An introduction to decision tree modeling[J]. Journal of chemometrics, 2004, 18(6): 275−285. doi: 10.1002/cem.873 [28] CHEN R T Q, AMOS B, NICKEL M. Learning neural event functions for ordinary differential equations[EB/OL]. (2020−11−08)[2024−01−04]. https://arxiv.org/abs/2011.03902v4. [29] DUPONT E, DOUCET A, TEH Y. Augmented neural ODEs[EB/OL]. (2019−04−02)[2024−01−04]. https://doi.org/10.48550/arXiv.1904.01681. [30] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of artificial intelligence research, 2002, 16: 321−357. doi: 10.1613/jair.953































