
Research on continual detection and localization method for printed circuit board defect
-
摘要: 针对目前缺陷检测与定位方法只能对特定类型的缺陷进行检测,而不能连续地学习检测不同类型缺陷的问题,提出了一种基于反向蒸馏模型的缺陷检测与定位方法。该方法以反向蒸馏模型为基础模型,对模型中间层输出的特征图以及一分类嵌入表示进行池化蒸馏,使得模型能够在连续的任务序列上不断地学习新的检测任务,从而达到持续学习的能力。在4个连续的印刷电路板(printed circuit board, PCB)缺陷检测与定位任务上进行实验,实验结果表明该方法的性能优于对比方法,能够满足工业生产场景的应用需求,在抑制对旧任务样本的检测能力的遗忘的同时,能够保持学习检测新任务的能力。Abstract: Existing defect detection and localization methods can only detect fixed types of defects and cannot meet the continual defect detection requirements in real application scenarios. To address this issue, this paper proposes a defect detection and localization method based on the reverse distillation model. This method uses the reverse distillation model as the basis model and performs pooling distillation on the feature maps from the middle layers of the model and the one-class classification embedding representation. So that the model can continually train new detection tasks without forgetting previous tasks. Experimental results on four printed circuit board defect detection and localization tasks show that this method can meet the requirements of industrial applications, and it outperforms other methods. It maintains the ability to learn and detect new tasks while suppressing the trend of forgetting the ability to detect samples of previous tasks.
-
印刷电路板(printed circuit board, PCB)是电子工业的重要部件之一,生活、生产过程中所用到的电子设备中存在着各式各样的印刷电路板,这些印刷电路板的质量决定了电子设备的运行状态以及耐用程度。因此,对印刷电路板的缺陷检测工作是一项庞大且重要的工作。由于成本高以及效率低下等问题,人工检测的方法正在被淘汰,而高效的自动化缺陷检测算法不仅能提高制造生产的效率,同时也能减少相关的人力成本,让更多的人能够致力于更具有创造性的工作,从而为社会创造更多的效益。
在深度学习技术还未得到广泛应用时,PCB缺陷检测方法主要以传统的图像处理方法和机器学习方法为主。然而,这些方法存在对数据分布敏感、泛化性能差以及检测速度较慢等问题。随着深度学习技术的发展,利用深度学习技术解决PCB缺陷检测问题逐渐成为主流的研究方法。Ding等[1]提出了一种基于Faster R-CNN(faster region-based convolutional neural network)的PCB缺陷检测网络TDD-net(tiny defect detection network),该网络根据PCB缺陷的特点,改进了Faster R-CNN网络,引入了多尺度金字塔结构,同时使用了K-means方法来设计锚框大小,使得网络对于微小缺陷的检测能力得到提升;Adibhatla等[2]将轻量版一阶段检测网络YOLO(you only look once)v2-tiny网络应用于PCB缺陷检测领域,实现了快速且准确的检测;Lin等[3]提出了一种边缘多尺度反向注意力网络,通过对特征融合以及特征提取过程中多个模块的改进,提升了网络对微小缺陷的检测能力;钱万明等[4]提出了一种基于YOLOv4网络的PCB裸板缺陷检测算法,通过提升YOLOv4网络在多尺度特征融合方面的性能,提高了网络的检测精度。
上述PCB缺陷检测方法虽然提高了检测精度,但是这些方法都需要带有标签的数据用于训练,然而,在实际检测场景中,缺陷样本的数量是少量的,这不利于训练数据集的构建,同时也限制了算法的检测精度。同时,现有的PCB缺陷检测研究工作无法进行持续学习,当现有方法在多个检测任务上持续学习时,这些方法将发生灾难性遗忘——直接利用新任务的训练数据进行训练的模型将会遗忘检测先前任务样本的能力,这将导致最终训练出来的模型只能有效地检测最后一个任务的样本,对于过去任务的样本的检测能力则会下降甚至是完全丢失。这两个因素限制了现有PCB缺陷检测方法的实际应用。
针对第1个因素,无监督方法可以有效规避该因素对检测算法的影响。无监督缺陷检测要求在训练过程中仅能使用正常样本来进行训练,由于不需要缺陷样本,该类方法可以有效避免训练数据集不平衡等问题对方法精度的影响。由于这类方法只能学习到无缺陷特征,当检测过程中发现未见过的特征时,即认为检测出缺陷,此时“缺陷”意味着异常,因此该类方法也常被称为异常检测(anomaly detection)[5],通过对正常样本的特征进行分布拟合或分布估计,来判断后续的测试样本中是否包含缺陷特征。现存的基于深度学习的异常检测方法主要可以分为两类:基于特征表示的异常检测方法[6-11]与基于重建的异常检测方法[12-16]。前者的核心思想是利用深度学习方法训练出来的神经网络作为特征提取器,对正常图像的特征进行提取并处理后,在测试阶段主要根据样本特征与正常特征之间的距离来判断样本中是否包含异常特征,并对异常区域进行定位;后者的思想则主要是训练网络以学习重建原始输入图像或原始网络输出的特征图的能力,通过比对重建结果与原始目标之间的差异,来判断样本是否包含异常特征。
关于第2个因素,当存在多个任务时,现有的PCB缺陷检测方法均需要针对不同任务训练不同的网络模型,在实际应用中,这种训练方式不仅会浪费大量的内存空间,而且还无法在任务序列上进行持续学习。现有的研究工作中也存在诸多针对持续学习问题进行研究的方法,这些方法大致可分为3类:基于正则化的方法、基于回放的方法以及基于网络扩增的方法。基于正则化的方法[17-20]通常根据参数梯度以及先验知识构建正则项,并将之作为惩罚项施加于损失中,用于修正网络参数的更新方向;基于回放的方法[21-23]根据特定准则保留先前任务的部分训练样本或用生成模型生成先前任务的训练样本,用于与新任务的训练样本一起训练模型;基于网络扩增的方法[24-26]则通过扩增网络模型或改变网络结构的方式,为不同的任务分配不同的网络参数。
虽然上述方法能帮助模型抵抗遗忘,但是上述方法都是针对分类任务设计的,在检测领域,亟需相关的持续学习算法来匹配日益增长的需求。也有一些学者提出了相应的检测方法:文献[27]提出了一种可进行持续学习的基于图像级重建的异常检测方法,该方法以回放的持续学习方法为主体,在每次学习新的检测任务时,会选取当前任务中合适的训练图像进行压缩保存,以用于在后续任务中进行回放,而为了保留在旧任务上的检测性能,网络会将在旧任务中保存的压缩图像进行超分重建,并将重建后的图像与新任务中的训练图像一起送入重建网络中,从而使网络也能对旧任务的输入图像进行重建,以此保留对旧任务样本的检测能力。该方法虽然可以完成持续学习任务设置下的异常检测任务,但是该方法在完成持续学习任务时需要保存旧任务中的原始训练数据,这增加了数据泄露的风险,不利于对数据的保护。
本文提出了一种无监督缺陷检测持续学习方法,该方法采用反向蒸馏(reverse distillation)模型[28]作为骨干网络来对样本进行缺陷检测,通过改进其损失函数,在中间层特征以及嵌入特征的维度上进行池化蒸馏(pooling distillation)[29],使得网络模型能够学习并保留储存在旧模型中的知识。
1. 任务描述
本文的任务场景与目标是在PCB缺陷检测任务序列上进行持续学习。在工业生产场景中,通常能够获得大量的无缺陷样本图片,而带有缺陷的样本图片则是少量的,并且在制造过程中也无法获知所有可能出现的缺陷类型,所以,如何仅依靠在无缺陷样本图片上进行训练就能够正确地识别与定位缺陷区域是一项非常有实际意义的研究,这样的训练方式通常被称为一分类(one-class classification, OCC)任务,本文所构建的PCB缺陷检测任务序列也是由多个训练集中仅包含正常样本的检测任务组成,任务划分的依据主要为样本在PCB板上所处的位置,当模型能够持续地学习完PCB板上所有不同位置处的检测任务时,该模型也就拥有了能够检测整个PCB板上缺陷的能力,同理,对于其他表面缺陷检测任务也有同样的效果。
假设根据上述划分依据可以得到
$ M $ 个PCB缺陷检测任务$ \left\{ {{T_m}|m \in (1,2, \cdot \cdot \cdot ,M)} \right\} $ ,那么,在训练过程中,$ M $ 个缺陷检测任务的训练样本集将被依次送入训练模型,每个缺陷检测任务$ {T_m} $ 的训练集中都只包含一种相似位置处的无缺陷样本$ {X_m} $ ,各任务之间的训练数据之间没有交集,即$ {X_1} \cap {X_2} \cap \cdot \cdot \cdot \cap {X_m} = \varnothing $ ;在测试过程中,待检测的输入图像则既包括无缺陷样本,也包括缺陷样本,在第$ m $ 个任务的测试阶段,测试样本将不仅包含任务$ {T_m} $ 的测试样本,同时也包含任务$ \left\{ {{T_n}|n \in (1,2, \cdot \cdot \cdot ,m - 1)} \right\} $ 的测试样本,以评估算法的抗遗忘能力,模型最终将输出像素级缺陷热度图,以用于检测与定位缺陷。2. 反向蒸馏检测模型
反向蒸馏异常检测算法是一种基于师生蒸馏模型的改进算法,该算法的网络模型结构如图1所示,
$ {L_{\rm{rec}}} $ 为重建损失。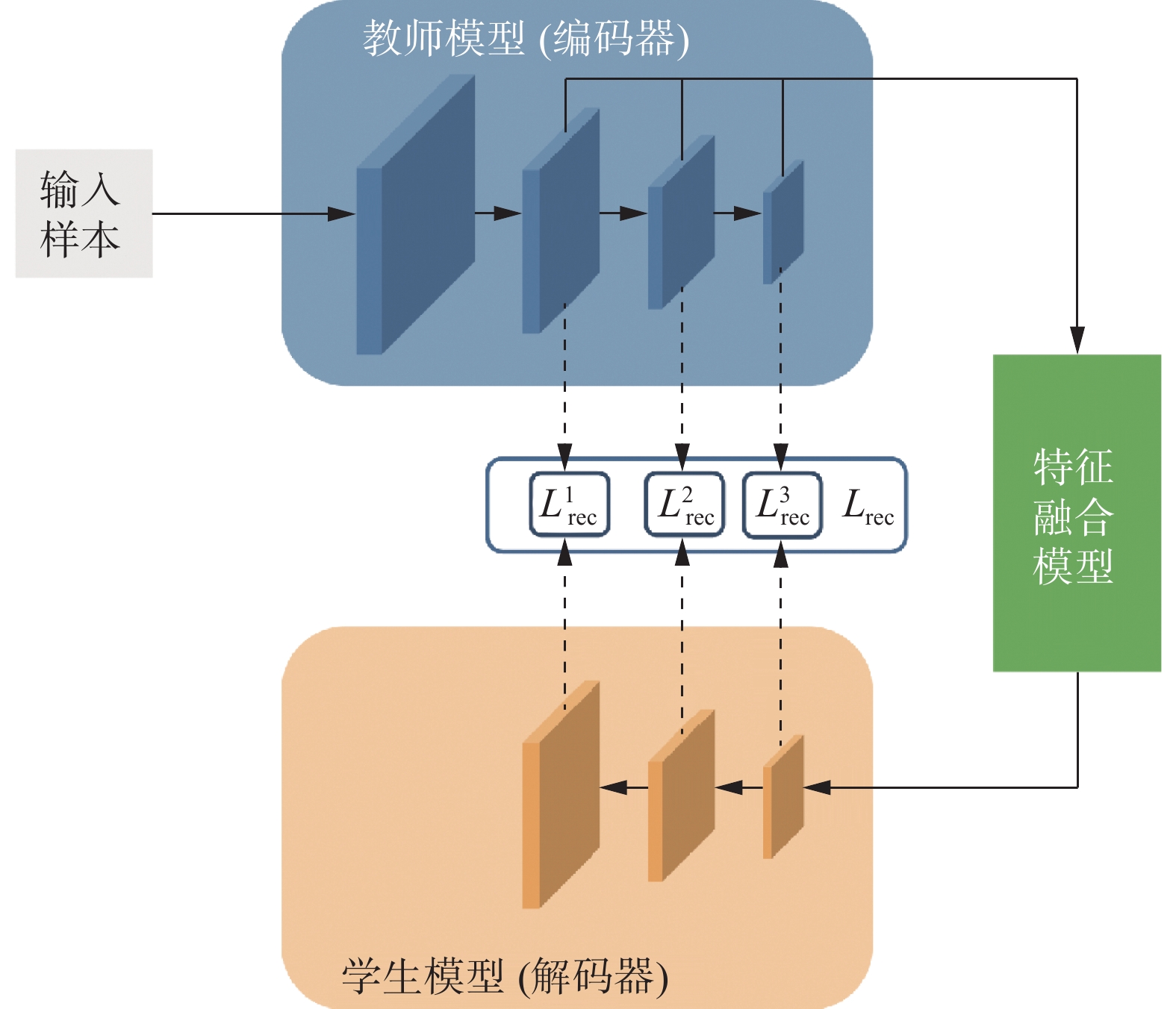 图 1 反向蒸馏模型网络结构Fig. 1 Network structure of reverse distillation model
图 1 反向蒸馏模型网络结构Fig. 1 Network structure of reverse distillation model 下载:
全尺寸图片
下载:
全尺寸图片
区别于师生蒸馏检测模型,在反向蒸馏异常检测模型中,学生模型采用解码器结构,其输入不再以原始图片或经原始图片处理后的激活层响应作为网络输入,而是以特征融合模块根据教师模型提取出来的多级特征图学习得到的一分类嵌入特征为输入,利用该嵌入特征来重建多尺度特征图。这样的网络结构设计,可以更好地避免学生模型在学习重建的过程中完全复刻教师模型的参数,从而避免学生模型对样本的缺陷区域也能进行良好的重建,进而提升学生模型对正常样本与缺陷样本的区分程度,提升模型对样本缺陷区域的定位能力。
在反向蒸馏模型中,教师模型依然采用在大型数据集上预训练好的模型作为教师编码器提取多尺度特征图,提取出多尺度特征图后,这些特征图首先会被送入特征融合模块,该模块会对多尺度特征图进行融合处理,并对融合后的特征进行卷积操作,从而学习得到一个一分类嵌入特征。学生模型作为解码器,将会根据该嵌入特征,重建教师模型输出的各尺度特征图。为了使学生模型能够学习到重建特征图的能力,计算教师模型与学生模型输出的对应尺度下的特征图中对应位置处的特征间的向量级余弦相似度损失,将某尺度下的所有损失加权平均后得到该尺度下的总损失,再将各尺度下的总损失加和得到的结果作为最终损失来进行梯度计算与反向传播。
让
$ {\boldsymbol{f}}_{\mathrm{E}}^l(h,w) $ 和$ {\boldsymbol{f}}_{\mathrm{D}}^l(h,w) $ 分别代表由教师编码器和学生编码器输出的第$ l $ 层特征图中$ (h,w) $ 处的特征,则第$ l $ 层特征图中$ (h,w) $ 处特征间的向量级余弦相似度损失的计算公式为$$ {M^l}(h,w) = 1 - \frac{{{{({\boldsymbol{f}}_{\text{E}}^l(h,w))}^{\text{T}}} · ({\boldsymbol{f}}_{\text{D}}^l(h,w))}}{{||{\boldsymbol{f}}_{\text{E}}^l(h,w)|| ||{\boldsymbol{f}}_{\text{D}}^l(h,w)||}} $$ 当该数值较大时,表明学生模型对该处特征的重建质量较差,因此也可以称之为该位置处的重建损失。第
$ l $ 层特征图上各个位置的重建损失可以组成$ l $ 级重建误差热度图$ {M^l} $ ,该热度图是后续用于判定样本是否包含缺陷以及对缺陷进行定位的关键。加权第
$ l $ 层特征图中各位置处的余弦相似度损失后可以得到该尺度下的重建损失$ L_{\rm{rec}}^l $ ,考虑到多尺度蒸馏能够提升算法的检测性能,则最终用于优化学生解码器的损失的计算公式为$$ {L_{\rm{rec}}} = \sum\limits_{l = 1}^L {\left\{ {\frac{1}{{{H_l}{W_l}}}\sum\limits_{h = 1}^{{H_l}} {\sum\limits_{w = 1}^{{W_l}} {{M^l}(h,w)} } } \right\}} $$ 式中:
$ L $ 为所用到的不同尺度下的特征图的总数,$ {H_l} $ 、$ {W_l} $ 为第$ l $ 层特征图的最大横、纵坐标。在测试阶段,首先计算获得各尺度下的重建误差热度图,然后将不同尺度下的热度图上采样到与输入图片一致,叠加各尺度下的热度图,最终得到用于判断样本是否异常以及确定异常区域所在位置的异常热度图。对于正常样本,由于学生模型在训练阶段中学习了对正常特征的重建能力,学生模型输出的重建特征图与教师模型输出的特征图将高度相似,此时,对应位置处特征间的余弦相似度也较高,最终得到的异常热度图上各点位处的数值则较低;而对于缺陷样本,由于学生模型没有学习过对缺陷特征的重建能力,学生模型对缺陷特征的重建将与教师模型输出的特征差异巨大,在异常热度图上即体现为正常区域处的数值较低而缺陷处的数值则较高。通过这样的方式即可完成对缺陷的检测与定位。
3. 持续缺陷检测与定位模型
针对单一任务时,反向蒸馏检测模型能够有效地检测并定位样本的缺陷区域。然而,当需要对多个缺陷检测任务进行连续的学习与检测时,该模型将在持续学习的过程中发生灾难性遗忘。因此,本文根据检测任务的特性,将改进后的持续学习方法引入反向蒸馏检测模型当中,通过两者的有效结合,新的检测模型能够更好地适应实际检测场景并完成持续检测任务。
3.1 损失函数
本文采用知识蒸馏来帮助模型保留在旧任务中所学习到的知识。由于反向蒸馏算法的本质也是通过让学生模型学习教师模型所储存的知识,使得学生模型仅能够完成正常特征的重建,而不能有效地完成对异常特征的重建,从而能够区分正常特征与异常特征,完成对缺陷部位的定位;因此,通过结合知识蒸馏方法能够有效帮助该算法抵抗遗忘,在学习新的训练任务时,模型在通过原损失学习新任务的同时,可以通过知识蒸馏方法来继续学习旧模型中所储存的知识,从而达到抵抗遗忘的效果。本文拟在模型学习新任务时,在多尺度特征图以及一分类嵌入特征两个层面上来进行蒸馏,从而使得算法能够完成持续学习任务。
本文采用池化蒸馏持续学习方法,通过池化某一维度,网络能够在被池化的维度上重新组织输出,而惩罚在其他维度上的输出变化。首先,针对多级特征图,本文采用空间维度上的池化蒸馏,即同时包含了在特征图的宽度维度上的池化蒸馏与高度维度上的池化蒸馏,这两种池化方式都会严重惩罚输出在通道维度上的变化,通过这样的方式可以增强网络模型在学习新任务时的重建输出在通道维度上的稳定性,从而能够在后续检测时保留对旧任务样本的检测能力。但是,由于原池化蒸馏损失是针对分类任务设计的,该损失函数对于网络参数的约束性较强,将其直接与反向蒸馏检测方法结合并不能有效提升算法的持续学习性能。因此,为了更好地适配检测任务,本文对池化蒸馏损失函数进行了改进,相比于原损失函数,改进后的损失函数能够提高模型的可塑性,使得模型能够在持续学习任务序列上更好地学习新的训练任务。后续若无特别说明,则文中所提到的池化蒸馏损失均为改进后的池化蒸馏损失。那么,第
$ l $ 层特征图上的宽度维度上的池化蒸馏损失计算公式为$$ {L_{\text{pod-width}}}\left({\boldsymbol{h}}_{l,\widehat w}^{t - 1},{\boldsymbol{h}}_{l,\widehat w}^t\right) = 1 - \frac{1}{{{H_l}}}\sum\limits_{h = 1}^{{H_l}} {\frac{{{{\left({\boldsymbol{h}}_{l,\widehat w,h}^{t - 1}\right)}^{\mathrm{T}}} · \left({\boldsymbol{h}}_{l,\widehat w,h}^t\right)}}{{\left\|{\boldsymbol{h}}_{l,\widehat w,h}^{t - 1}\right\| \left\|{\boldsymbol{h}}_{l,\widehat w,h}^t\right\|}}} $$ 式中:
$ t $ 表示当前任务序号,$ {\boldsymbol{h}}_{l,\widehat w,h}^t $ 表示在第$ l $ 层特征图上对宽度维度进行池化后在高度维度为$ h $ 处的特征表示。同理可得高度维度上的池化蒸馏损失计算公式,那么空间维度上的池化蒸馏损失计算公式则为$$ \begin{gathered} {L_{\text{pod-spatial}}}\left({\boldsymbol{h}}_l^{t - 1},{\boldsymbol{h}}_l^t\right) = {L_{\text{pod-width}}}\left({\boldsymbol{h}}_{l,\widehat w}^{t - 1},{\boldsymbol{h}}_{l,\widehat w}^t\right) + \\ {L_{\text{pod-height}}}\left({\boldsymbol{h}}_{l,\widehat h}^{t - 1},{\boldsymbol{h}}_{l,\widehat h}^t\right) \\ \end{gathered} $$ 针对一分类嵌入特征,本文则采用针对最终嵌入特征所设计的池化蒸馏方法,该蒸馏损失计算公式为
$$ \begin{gathered} {L_{\text{pod-emb}}}\left({{\boldsymbol{h}}^{t - 1}},{{\boldsymbol{h}}^t}\right) = 2 - \frac{1}{H}\sum\limits_{h = 1}^H {\frac{{{{\left({\boldsymbol{h}}_{\widehat w,h}^{t - 1}\right)}^{\mathrm{T}}} · \left({\boldsymbol{h}}_{\widehat w,h}^t\right)}}{{\left\|{\boldsymbol{h}}_{\widehat w,h}^{t - 1}\right\| \left\|{\boldsymbol{h}}_{\widehat w,h}^t\right\|}} - } \\ \frac{1}{W}\sum\limits_{w = 1}^W {\frac{{{{\left({\boldsymbol{h}}_{w,\widehat h}^{t - 1}\right)}^{\mathrm{T}}} · \left({\boldsymbol{h}}_{w,\widehat h}^t\right)}}{{\left\|{\boldsymbol{h}}_{w,\widehat h}^{t - 1}\right\| \left\|{\boldsymbol{h}}_{w,\widehat h}^t\right\|}}} \\ \end{gathered} $$ 结合以上两个维度的池化蒸馏损失,本文所采用的最终的池化蒸馏损失为
$$ \begin{gathered} {L_{\text{pod-final}}} = \frac{{{\lambda _{\mathrm{s}}}}}{{L - 1}}\sum\limits_{l = 1}^L {{L_{\text{pod-spatial}}}\left({\boldsymbol{h}}_l^{t - 1},{\boldsymbol{h}}_l^t\right)} + \\ {\lambda _{\mathrm{f}}}· {L_{\text{pod-emb}}}\left({{\boldsymbol{h}}^{t - 1}},{{\boldsymbol{h}}^t}\right) \\ \end{gathered} $$ (1) 式(1)的
$ {L_{\text{pod-final}}} $ 能够在持续学习的过程中帮助模型抵抗遗忘,其中$ \lambda{_{\mathrm{s}}} $ 与$ \lambda{_{\mathrm{f}}} $ 用于调节两种损失在池化蒸馏损失中的占比。结合原反向蒸馏检测方法中的损失函数$ {L_{\rm{rec}}} $ ,可以得到最终用于持续学习任务设置下的总损失函数为$$ {L_{{\mathrm{total}}}} = {L_{\rm{rec}}} + \lambda · {L_{\text{pod-final}}} $$ 实际上,为了增强算法抗遗忘的能力,本文还引入了回放的方法。在池化蒸馏的过程中回放旧样本,让学生模型学习重建教师模型对回放样本的输出,从而更好地学习并保留储存在旧模型中的知识。由于所提出的方法是基于特征级重建的方法,因此不需要存储原始输入,只需要存储中间响应层的输出即可,大大降低了数据泄露的风险。
3.2 检测模型
PCB样本中包含丰富的色彩、纹理以及语义等信息,为了充分提取出样本中包含的信息并用于重建,本文采用在ImageNet-1k数据集上预训练好的WideResNet-50模型作为检测模型中的教师模型,采用与WideResNet-50模型相比结构翻转的解码器网络作为学生模型,根据算法需要,最终只保留了其中的3个残差网络块,每个网络块由若干个残差块组成,其他冗余部分则均被裁剪掉,并且由于是解码器结构,每个网络块中的第一个残差块中均包含了一层逆卷积网络,该残差块的具体结构如图2所示。学生模型的网络结构组成则如表1所示。
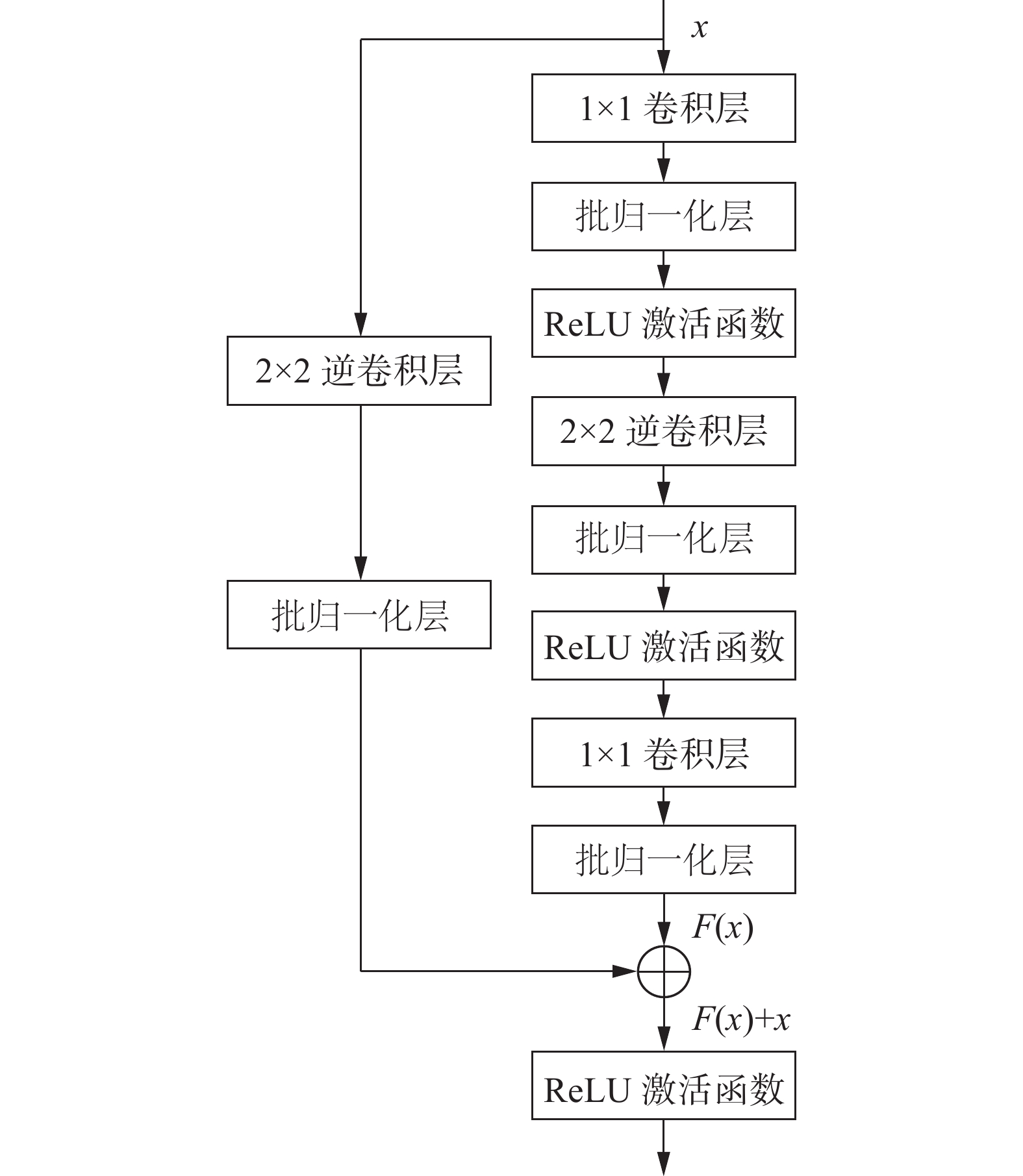 图 2 包含逆卷积层的残差块结构Fig. 2 Structure of residual block with transposed convolutional layer下载:
全尺寸图片
表 1 学生模型网络结构Table 1 Network architecture of student model
图 2 包含逆卷积层的残差块结构Fig. 2 Structure of residual block with transposed convolutional layer下载:
全尺寸图片
表 1 学生模型网络结构Table 1 Network architecture of student model网络块 输出尺寸 残差块组成 网络块1 14×14 $ \left[\begin{array}{c}1\times 1\\ 2\times 2\\ 1\times 1\end{array}\right]\times 1 $ $ \left[\begin{array}{c}1\times 1\\ 3\times 3\\ 1\times 1\end{array}\right]\times 2 $ 网络块2 28×28 $ \left[\begin{array}{c}1\times 1\\ 2\times 2\\ 1\times 1\end{array}\right]\times 1 $ $ \left[\begin{array}{c}1\times 1\\ 3\times 3\\ 1\times 1\end{array}\right]\times 3 $ 网络块3 56×56 $ \left[\begin{array}{c}1\times 1\\ 2\times 2\\ 1\times 1\end{array}\right]\times 1 $ $ \left[\begin{array}{c}1\times 1\\ 3\times 3\\ 1\times 1\end{array}\right]\times 5 $ 所有样本在送入网络模型前都会被缩放至固定尺寸。当样本流经网络后,能够从教师模型与学生模型中分别提取出若干张尺度对应的特征图,利用向量级余弦相似度函数计算每张特征图上特征向量间的余弦相似度后,可以得到若干张不同尺度下的重建误差热度图,将不同尺度下的热度图上采样到与输入图片一致,叠加各尺度下的热度图,最终得到用于判断样本是否包含异常以及确定异常区域所在位置的异常热度图,具体过程如图3所示,图中的M表示特征图。
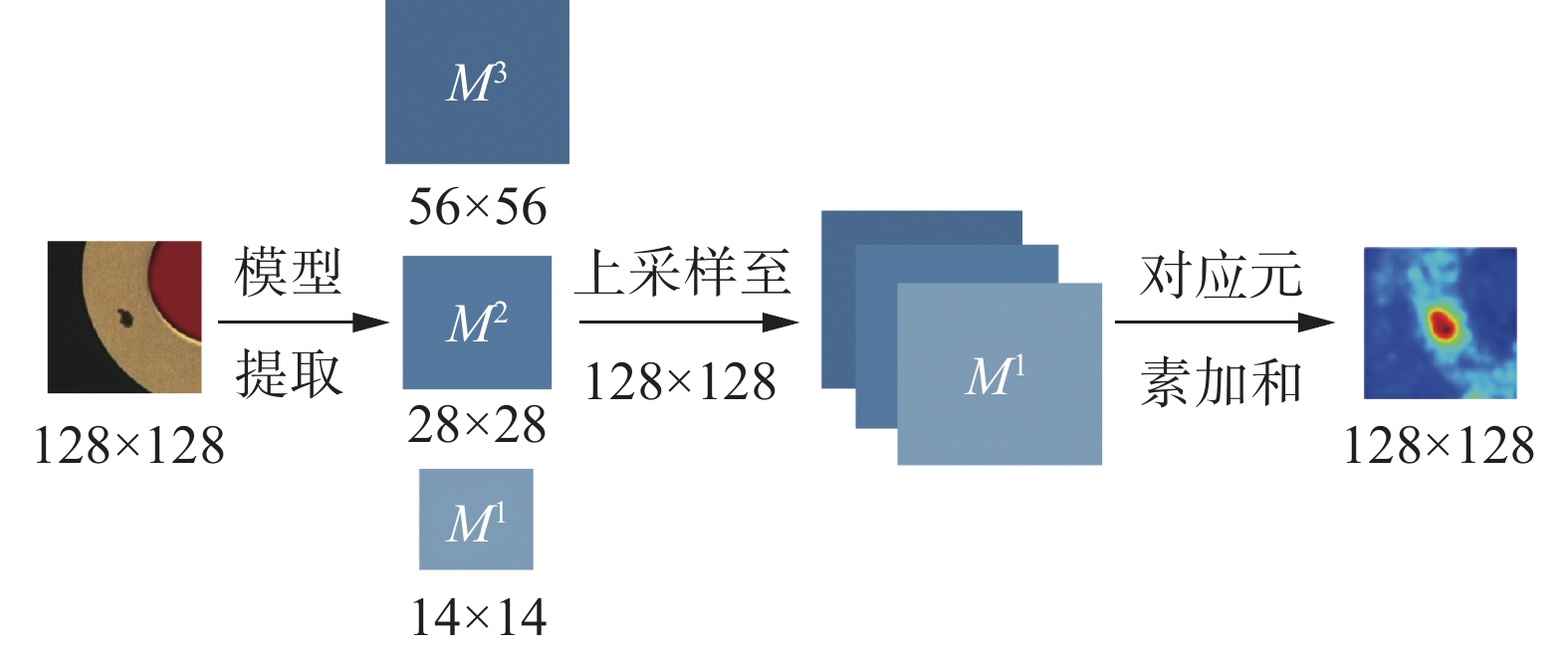 图 3 检测过程Fig. 3 Inference stage下载:
全尺寸图片
图 3 检测过程Fig. 3 Inference stage下载:
全尺寸图片
4. 实验结果及分析
4.1 数据集与实验设置
4.1.1 数据集
在构建用于验证算法检测性能的PCB数据集时,本文根据采样时拍摄位置的不同将PCB样本划分到多个独立的任务当中,每份样本的尺寸为128×128,每个独立的任务都按照无监督训练任务的模式来构建训练集与测试集,即训练集中仅包含当前任务的正常样本,而测试集中同时包含了正常样本与带有缺陷的样本。同时,为了能够对方法进行缺陷定位性能的定量分析,本团队也为每一份包含缺陷的测试样本制作了缺陷真值图。
4.1.2 实验设置
实验于GTX 3090下的Ubuntu 20.04版本系统下进行,算法基于Pytorch深度学习框架编写。在训练网络时,本文采用Adam优化器[30],并将β参数设置为(0.5, 0.999),学习率设置为
0.0005 ,用于平衡重建损失与池化蒸馏损失的参数λ则设置为1,按照这样的设置循环训练200轮后完成训练步骤。本文制作了8个独立的PCB缺陷检测任务来构建PCB检测的持续学习任务序列,具体任务如图4所示。
 图 4 PCB持续学习任务序列Fig. 4 PCB continual learning task sequence下载:
全尺寸图片
图 4 PCB持续学习任务序列Fig. 4 PCB continual learning task sequence下载:
全尺寸图片
因为不同任务下能采到的样本数量是不同的,所以各任务间训练样本的数量是不均衡的,为了避免训练样本不均衡影响到对算法抗遗忘能力的评估,本文也采取了数据增强来平衡各任务间训练样本的数量,各任务训练样本与测试样本的最终数量如表2所示,其中,测试样本数量的统计格式为“正常样本数量/缺陷样本数量”。
表 2 PCB持续学习任务序列各任务训练样本与测试样本数量Table 2 Number of training samples and test samples for each task of the PCB continual learning task sequence任务序号 训练样本
数量训练样本
数量(增广后)测试样本
数量任务1 80 200 16/60 任务2 53 212 10/30 任务3 40 200 9/54 任务4 40 200 16/23 任务5 64 192 14/27 任务6 40 200 20/54 任务7 102 204 14/41 任务8 45 180 18/20 本文将微调方法(Fine-turning)、师生特征金字塔匹配(student-teacher feature pyramid matching, STFPM)异常检测方法[14]、师生异常检测(student-teacher anomaly detection, STAD)方法[15]、重新审视反向蒸馏(revisiting reverse distillation, RD++)异常检测方法[31]、判别关节重建异常嵌入方法(discriminative joint reconstruction anomaly embedding method, DRAEM) [32]与本文方法做了对比实验。其中,STFPM方法与STAD方法都是基于特征级重建的师生蒸馏类的方法,前者教师模型与学生模型结构相同且采用了多级特征,后者也为同构的师生模型,但是其模型结构中包含了多个独立学习的学生模型;RD++方法是在反向蒸馏检测模型的基础上,对中间映射层进行了改进,并且引入了伪异常机制来使得模型能够更有效地区分正常特征与异常特征;DRAEM方法是基于图像级重建的方法。微调方法则是让反向蒸馏模型连续地在持续学习任务序列上训练而不做任何调整。
4.1.3 评价指标
本文的任务主体为缺陷检测与定位,因此,首先需要评价算法的检测与定位能力。涉及检测任务相关的评价指标有图像级受试者工作特征曲线下面积(image-level area under the receiver operating characteristic curve, I-AUROC)指标,涉及定位任务相关的评价指标则有像素级受试者工作特征曲线下面积(pixel-level area under the receiver operating characteristic curve, P-AUROC)指标。
而针对持续学习任务设置,本文也需要设计指标来检验方法在持续学习任务设置下的抗遗忘能力。将分类任务下的相关度量指标迁移到检测领域,可以定义检测领域下的后向传播率(backward transfer, BWT)指标,该指标用于度量后续任务的训练所导致的对之前任务的遗忘程度:
$$ {M_{{\mathrm{BWT}}}} = \sum\limits_{i = 2}^T {\sum\limits_{j = 1}^{i - 1} {\frac{{{A_{i,j}} - {A_{j,j}}}}{{{{T(T - 1)} \mathord{\left/ {\vphantom {{T(T - 1)} 2}} \right. } 2}}}} } $$ 式中:
$ {M_{{\mathrm{BWT}}}} $ 为后向传播率指标,$ {A_{i,j}} $ 为任务$ i $ 结束时对任务$ j $ 进行测试的$ {\text{AUROC}} $ 指标。4.2 实验结果与分析
表3给出了不同方法在设定的长任务序列上对各任务的平均像素级AUROC指标结果及其对应的BWT指标结果,表4则给出了不同方法在设定的长任务序列上对各任务的平均图像级AUROC指标结果及其对应的BWT指标结果。
表 3 不同方法在长PCB持续学习任务序列上的平均像素级AUROC指标以及BWT指标Table 3 Average P-AUROC metrics and BWT metrics on the long PCB continual task sequence of different methods方法 P-AUROC/% BWT 任务1 任务2 任务3 任务4 任务5 任务6 任务7 任务8 Fine-tuning 90.0 89.4 89.7 79.0 95.9 98.1 90.1 95.6 −0.073 STFPM[14] 82.6 81.2 76.0 65.0 92.7 97.2 94.9 93.5 −0.188 STAD[15] 71.5 80.0 35.3 54.3 75.5 74.0 79.5 74.6 −0.100 RD++[31] 87.7 86.4 88.0 85.7 95.9 94.9 82.4 96.3 −0.073 DRAEM[32] 70.1 87.9 66.8 57.1 78.8 87.4 95.5 76.6 −0.157 本文方法 95.3 95.9 97.0 92.5 98.4 98.5 90.4 94.6 −0.015 注:加粗表示结果最优。 表 4 不同方法在长PCB持续学习任务序列上的平均图像级AUROC指标以及BWT指标Table 4 Average I-AUROC metrics and BWT metrics on the long PCB continual task sequence of different methods方法 I-AUROC/% BWT 任务1 任务2 任务3 任务4 任务5 任务6 任务7 任务8 Fine-tuning 89.2 81.5 82.5 74.6 93.8 83.2 80.0 82.2 −0.107 STFPM[14] 88.6 67.7 73.0 61.7 71.4 93.1 94.2 100.0 −0.188 STAD[15] 81.1 63.7 63.6 65.6 36.0 75.4 78.7 71.1 −0.052 RD++[31] 81.7 86.7 78.1 77.6 92.8 89.6 87.7 98.8 −0.147 DRAEM[32] 80.1 80.8 49.5 59.1 48.1 99.1 87.4 100.0 −0.166 本文方法 99.6 98.2 98.1 78.1 97.6 95.2 96.0 93.3 −0.019 注:加粗表示结果最优。 从表3和表4中可以看出,在长任务序列上进行持续学习时,本文方法在前5个任务中的平均AUROC指标均高于其他方法,同时,本文方法的像素级BWT指标与图像级BWT指标分别为−0.015与−0.019,优于微调方法(−0.073与−0.107)、STFPM(−0.188与−0.188)、STAD(−0.100与−0.052)、RD++(−0.073与−0.147)以及DRAEM方法(−0.157与−0.166),这表明本文方法在持续学习的过程中展现出了更强的稳定性,模型抵抗遗忘的能力显著优于其他对比方法。而在后3个任务中,本文方法的平均AUROC指标没能全部达到最优,在任务6上的平均图像级AUROC指标低于DRAEM方法,在任务7上的平均像素级AUROC指标低于DRAEM方法与STFPM方法,在最新的任务8上的两项平均AUROC指标则分列所有对比方法中的第3位和第4位。出现这种实验结果是因为本文方法在模型学习新任务时会对模型加以限制,但是通过观察表中数据可以发现,本文方法在所有任务上的平均AUROC指标均未低于90%,这表明本文方法在提升抵抗遗忘的能力的同时,也保留了模型的可塑性,使得模型能够在有限的约束下正常学习新的检测任务,从这一方面也可以看出算法具备良好的持续学习能力。
由于检测任务的特性,在长任务序列上,方法存在因任务间相似性高而获益的可能,同时,也为了更好地对算法的持续学习能力进行分析、比较与展示,本文从上述8个独立的PCB缺陷检测任务中选择了任务间差异性较大的4个任务(任务1、任务2、任务3、任务7)来构建了3个不同顺序的任务序列,在所有任务序列上均进行了实验,并最终对实验结果进行了统计计量与展示。任务序列具体如表5所示。
表 5 所有短任务序列的具体展示Table 5 Specific demonstration of all short task sequences任务序列 任务1 任务2 任务3 任务4 序列1 任务3 任务7 任务2 任务1 序列2 任务1 任务2 任务3 任务7 序列3 任务2 任务3 任务7 任务1 图5给出了不同方法对所有持续学习任务序列上的实验结果计算均值后得到的遗忘曲线,表6给出了不同方法在设定的持续学习任务序列上对各任务的平均像素级AUROC指标结果及其对应的BWT指标结果,表7则给出了不同方法在设定的持续学习任务序列上对各任务的平均图像级AUROC指标及对应的BWT指标,是对图5中数据进行进一步处理后得到的统计结果。从表6和表7中可以看出,在短任务序列上,本文方法的综合检测能力同样优于其他算法,本文方法的像素级BWT指标与图像级BWT指标分别为−0.028与−0.048,在所有对比方法中均是绝对值最小的,优于微调方法(−0.128与−0.174)与同类方法中当前最先进的方法(−0.111与−0.131),这表明本文方法具备最强的稳定性,具有最好的抗遗忘能力;同时,本文方法在前3个任务上的平均AUROC指标也都是最高的,仅在最新的任务上的平均AUROC指标未能达到最佳,但是也达到了94.6%和99.1%,这表明算法能够正常完成对新检测任务的学习,并对样本进行有效的检测与定位。
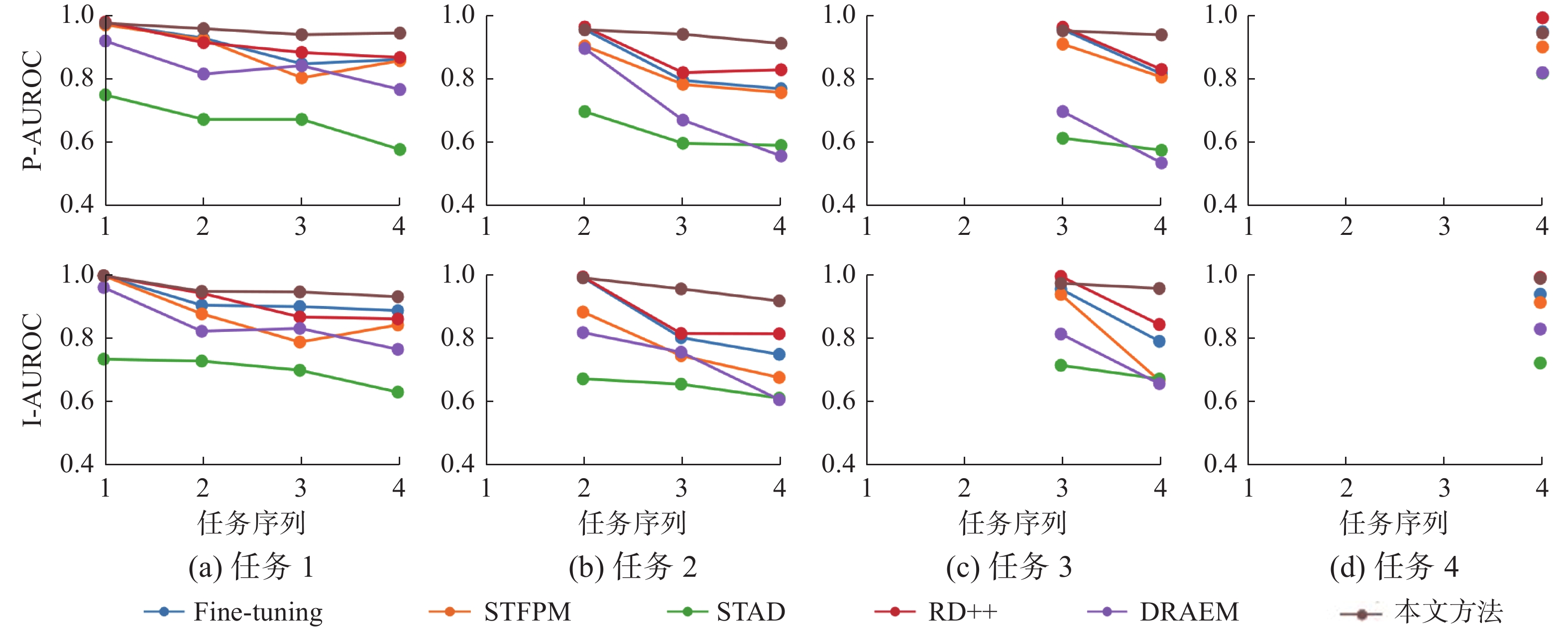 图 5 不同方法在任务序列上的遗忘曲线Fig. 5 Forgetting curves of different methods on the task sequence下载:
全尺寸图片
表 6 不同方法在任务序列上的平均像素级AUROC指标以及BWT指标Table 6 Average P-AUROC metrics and BWT metrics on the task sequence of different methods
图 5 不同方法在任务序列上的遗忘曲线Fig. 5 Forgetting curves of different methods on the task sequence下载:
全尺寸图片
表 6 不同方法在任务序列上的平均像素级AUROC指标以及BWT指标Table 6 Average P-AUROC metrics and BWT metrics on the task sequence of different methods从上述统计结果中可以看出,在长任务序列与短任务序列上,本文方法的检测性能均要优于其他对比方法。本文方法不仅在旧任务的平均检测性能上优于其他方法,同时也保留了学习新任务的能力,这表明所提出的方法在拥有较高的稳定性的同时,也保留了模型的可塑性,使得其能够有效完成持续检测与定位任务。
表 7 不同方法在任务序列上的平均图像级AUROC指标以及BWT指标Table 7 Average I-AUROC metrics and BWT metrics on the task sequence of different methods本文还选取了3个短任务序列中的序列1,通过可视化进行了定性结果的比较、分析与展示。图6给出了不同方法在整个任务序列上对第一个任务的样本的检测表现。
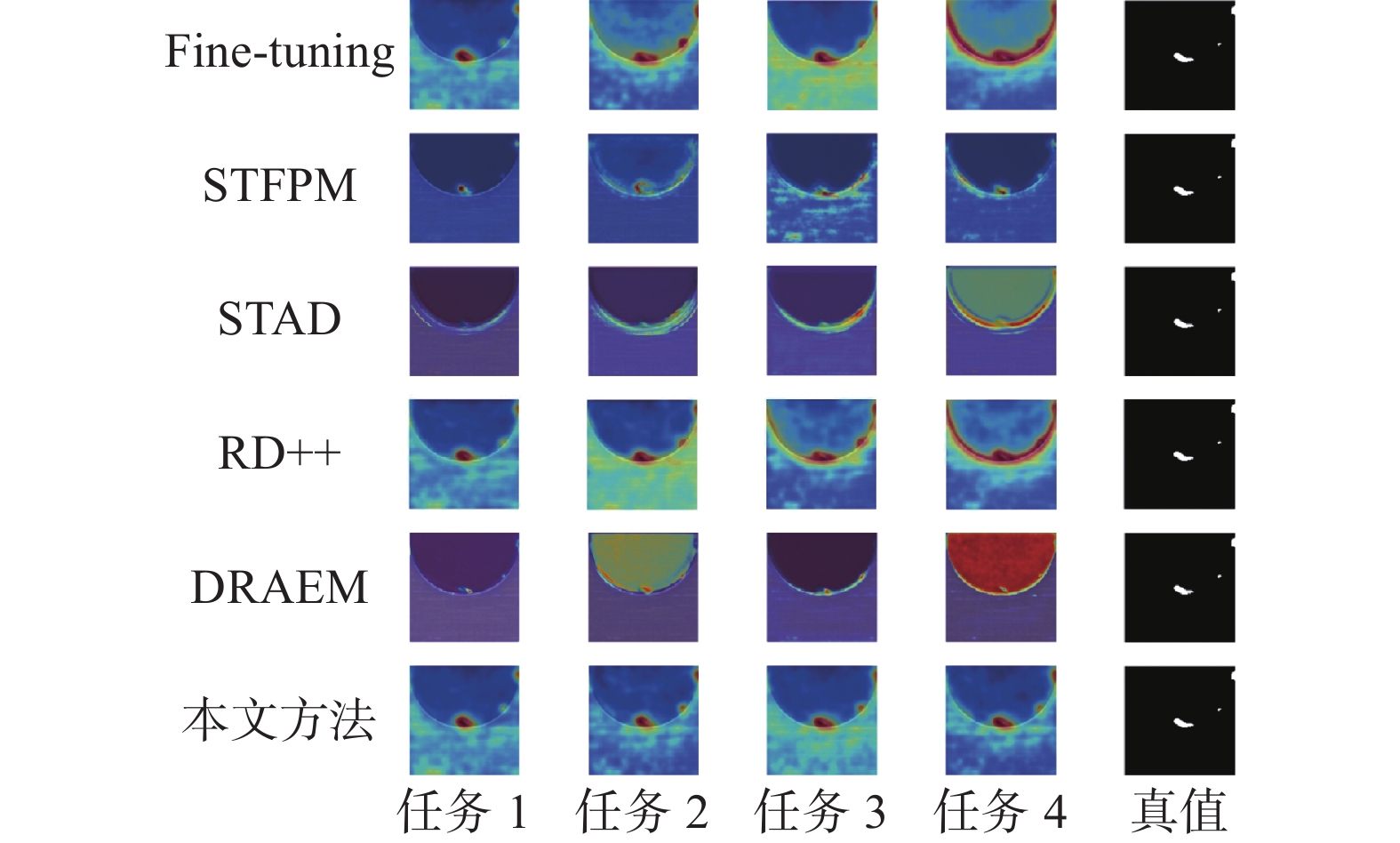 图 6 不同方法对任务1样本的可视化检测结果Fig. 6 Visualization of detection results of different methods for defect samples of Task 1下载:
全尺寸图片
图 6 不同方法对任务1样本的可视化检测结果Fig. 6 Visualization of detection results of different methods for defect samples of Task 1下载:
全尺寸图片
从图6中可以看出,微调方法、STAD、RD++以及DRAEM方法在任务序列上对任务1的样本的检测能力下降严重,STFPM方法则无法对另外两处较小的缺陷完成有效定位。而本文方法在整个持续学习的过程中则一直保留了对样本进行有效检测与定位的能力,进一步验证了算法的持续学习性能。图7给出了完成所有训练任务后,提出的方法对所有任务类别的检测结果。
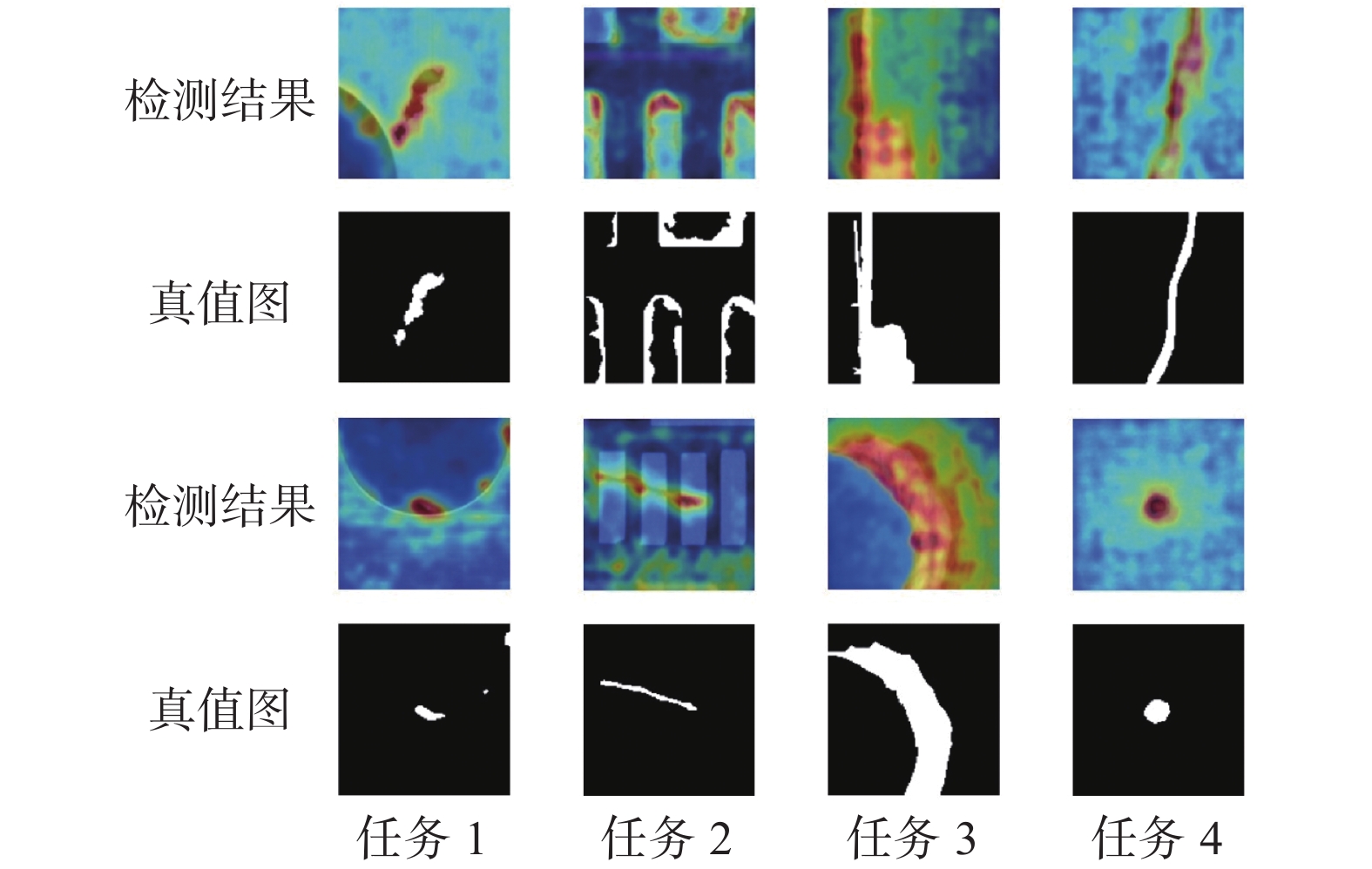 图 7 完成所有训练任务后模型对各任务样本的检测结果Fig. 7 Detection results for samples of each task after finishing all training tasks下载:
全尺寸图片
图 7 完成所有训练任务后模型对各任务样本的检测结果Fig. 7 Detection results for samples of each task after finishing all training tasks下载:
全尺寸图片
为了验证本文对池化蒸馏损失的改进的有效性,本文也对比了方法在采用不同损失函数时的检测表现。表8给出了采用不同损失函数时方法在设定的持续学习任务序列上对各任务的平均像素级AUROC /平均图像级AUROC指标及对应的BWT指标,从表中数据可以看出,采用改进后的损失函数时,方法在各项指标上均优于原本的表现,这得益于改进后的损失函数不仅保留了蒸馏的功能,同时不再以元素为单位进行损失的计算,而是以特征为单位,这放宽了对模型的约束,提升了模型的可塑性,使得方法能够在保存旧知识的同时学习新的知识,从而提升了方法的持续学习能力。
表 8 采用不同损失函数时各任务的平均像素级AUROC /平均图像级AUROC指标及对应的BWT指标Table 8 Average P-AUROC/I-AUROC metrics and BWT metrics with different loss functions for tasks损失函数 AUROC/% BWT 任务1 任务2 任务3 任务4 原损失函数 96.2/87.4 80.2/76.9 92.5/96.5 95.7/98.9 −0.036/−0.108 改进损失函数 96.3/93.1 89.5/93.1 94.6/98.5 97.1/100.0 −0.027/−0.063 为了验证本文方法是否能够满足在实际工业生产场景中的持续检测需求,本文也统计了各方法的平均检测时间,统计结果如表9所示。实验结果显示,本文方法平均每份样本的检测时间需要 29.48 ms,即每秒可以检测超过30张图片,可以满足实际工业场景的检测需求。
表 9 本文方法及所有对比方法的平均检测时间Table 9 Average detection time of the proposed method and all comparison methodsms 方法 STFPM STAD RD++ DRAEM 本文方法 检测时间 14.84 66.53 38.37 27.88 29.48 5. 结束语
本文提出了一种能够完成持续学习任务的缺陷检测方法,该方法以反向蒸馏模型为基础,通过对模型中间层输出的特征图以及一分类嵌入特征进行池化蒸馏来使得其拥有能够持续地学习新的任务、抵抗灾难性遗忘的能力。由于本文所提出的方法基于特征级重建,因此该方法仅需要保存少量旧任务数据在教师模型中的中间层响应,极大程度上提升了数据保护的安全性。通过进行实验来验证该方法在持续学习任务设置下的检测性能,实验结果验证了本文方法的有效性,表明了本文方法能够在实际工业生产场景中进行持续学习。尽管如此,本文所提出的方法在持续学习过程中存在对物体边缘、背景纹理处重建错误的倾向,这是导致方法在长任务序列上检测性能不佳的主要原因之一,也是本课题中值得进一步深入研究的一个问题。
-
图 1 反向蒸馏模型网络结构
Fig. 1 Network structure of reverse distillation model
下载:
全尺寸图片
图 2 包含逆卷积层的残差块结构
Fig. 2 Structure of residual block with transposed convolutional layer
下载:
全尺寸图片
图 3 检测过程
Fig. 3 Inference stage
下载:
全尺寸图片
图 4 PCB持续学习任务序列
Fig. 4 PCB continual learning task sequence
下载:
全尺寸图片
图 5 不同方法在任务序列上的遗忘曲线
Fig. 5 Forgetting curves of different methods on the task sequence
下载:
全尺寸图片
图 6 不同方法对任务1样本的可视化检测结果
Fig. 6 Visualization of detection results of different methods for defect samples of Task 1
下载:
全尺寸图片
图 7 完成所有训练任务后模型对各任务样本的检测结果
Fig. 7 Detection results for samples of each task after finishing all training tasks
下载:
全尺寸图片
表 1 学生模型网络结构
Table 1 Network architecture of student model
网络块 输出尺寸 残差块组成 网络块1 14×14 $ \left[\begin{array}{c}1\times 1\\ 2\times 2\\ 1\times 1\end{array}\right]\times 1 $ $ \left[\begin{array}{c}1\times 1\\ 3\times 3\\ 1\times 1\end{array}\right]\times 2 $ 网络块2 28×28 $ \left[\begin{array}{c}1\times 1\\ 2\times 2\\ 1\times 1\end{array}\right]\times 1 $ $ \left[\begin{array}{c}1\times 1\\ 3\times 3\\ 1\times 1\end{array}\right]\times 3 $ 网络块3 56×56 $ \left[\begin{array}{c}1\times 1\\ 2\times 2\\ 1\times 1\end{array}\right]\times 1 $ $ \left[\begin{array}{c}1\times 1\\ 3\times 3\\ 1\times 1\end{array}\right]\times 5 $ 表 2 PCB持续学习任务序列各任务训练样本与测试样本数量
Table 2 Number of training samples and test samples for each task of the PCB continual learning task sequence
任务序号 训练样本
数量训练样本
数量(增广后)测试样本
数量任务1 80 200 16/60 任务2 53 212 10/30 任务3 40 200 9/54 任务4 40 200 16/23 任务5 64 192 14/27 任务6 40 200 20/54 任务7 102 204 14/41 任务8 45 180 18/20 表 3 不同方法在长PCB持续学习任务序列上的平均像素级AUROC指标以及BWT指标
Table 3 Average P-AUROC metrics and BWT metrics on the long PCB continual task sequence of different methods
方法 P-AUROC/% BWT 任务1 任务2 任务3 任务4 任务5 任务6 任务7 任务8 Fine-tuning 90.0 89.4 89.7 79.0 95.9 98.1 90.1 95.6 −0.073 STFPM[14] 82.6 81.2 76.0 65.0 92.7 97.2 94.9 93.5 −0.188 STAD[15] 71.5 80.0 35.3 54.3 75.5 74.0 79.5 74.6 −0.100 RD++[31] 87.7 86.4 88.0 85.7 95.9 94.9 82.4 96.3 −0.073 DRAEM[32] 70.1 87.9 66.8 57.1 78.8 87.4 95.5 76.6 −0.157 本文方法 95.3 95.9 97.0 92.5 98.4 98.5 90.4 94.6 −0.015 注:加粗表示结果最优。 表 4 不同方法在长PCB持续学习任务序列上的平均图像级AUROC指标以及BWT指标
Table 4 Average I-AUROC metrics and BWT metrics on the long PCB continual task sequence of different methods
方法 I-AUROC/% BWT 任务1 任务2 任务3 任务4 任务5 任务6 任务7 任务8 Fine-tuning 89.2 81.5 82.5 74.6 93.8 83.2 80.0 82.2 −0.107 STFPM[14] 88.6 67.7 73.0 61.7 71.4 93.1 94.2 100.0 −0.188 STAD[15] 81.1 63.7 63.6 65.6 36.0 75.4 78.7 71.1 −0.052 RD++[31] 81.7 86.7 78.1 77.6 92.8 89.6 87.7 98.8 −0.147 DRAEM[32] 80.1 80.8 49.5 59.1 48.1 99.1 87.4 100.0 −0.166 本文方法 99.6 98.2 98.1 78.1 97.6 95.2 96.0 93.3 −0.019 注:加粗表示结果最优。 表 5 所有短任务序列的具体展示
Table 5 Specific demonstration of all short task sequences
任务序列 任务1 任务2 任务3 任务4 序列1 任务3 任务7 任务2 任务1 序列2 任务1 任务2 任务3 任务7 序列3 任务2 任务3 任务7 任务1 表 6 不同方法在任务序列上的平均像素级AUROC指标以及BWT指标
Table 6 Average P-AUROC metrics and BWT metrics on the task sequence of different methods
表 7 不同方法在任务序列上的平均图像级AUROC指标以及BWT指标
Table 7 Average I-AUROC metrics and BWT metrics on the task sequence of different methods
表 8 采用不同损失函数时各任务的平均像素级AUROC /平均图像级AUROC指标及对应的BWT指标
Table 8 Average P-AUROC/I-AUROC metrics and BWT metrics with different loss functions for tasks
损失函数 AUROC/% BWT 任务1 任务2 任务3 任务4 原损失函数 96.2/87.4 80.2/76.9 92.5/96.5 95.7/98.9 −0.036/−0.108 改进损失函数 96.3/93.1 89.5/93.1 94.6/98.5 97.1/100.0 −0.027/−0.063 表 9 本文方法及所有对比方法的平均检测时间
Table 9 Average detection time of the proposed method and all comparison methods
ms 方法 STFPM STAD RD++ DRAEM 本文方法 检测时间 14.84 66.53 38.37 27.88 29.48 -
[1] DING Runwei, DAI Linhui, LI Guangpeng, et al. TDD-net: a tiny defect detection network for printed circuit boards[J]. CAAI transactions on intelligence technology, 2019, 4(2): 110−116. doi: 10.1049/trit.2019.0019 [2] ADIBHATLA V A, CHIH H C, HSU C C, et al. Defect detection in printed circuit boards using you-only-look-once convolutional neural networks[J]. Electronics, 2020, 9(9): 1547. doi: 10.3390/electronics9091547 [3] LIN Qiangqiang, ZHOU Jinzhu, MA Qiurui, et al. EMRA-net: a pixel-wise network fusing local and global features for tiny and low-contrast surface defect detection[J]. IEEE transactions on instrumentation measurement, 2022, 71: 3151926. [4] 钱万明, 朱红萍, 朱泓知, 等. 基于自适应加权特征融合的PCB裸板缺陷检测研究[J]. 电子测量与仪器学报, 2022, 36(10): 92−99. doi: 10.13382/j.jemi.B2205520 QIAN Wanming, ZHU Hongping, ZHU Hongzhi, et al. Research on defect detection of PCB bare board based on adaptive weighted feature fusion[J]. Journal of electronic measurement and instrumentation, 2022, 36(10): 92−99 doi: 10.13382/j.jemi.B2205520 [5] 陶显, 侯伟, 徐德. 基于深度学习的表面缺陷检测方法综述[J]. 自动化学报, 2021, 47(5): 1017−1034. TAO Xian, HOU Wei, XU De. A survey of surface defect detection methods based on deep learning[J]. Acta automatica sinica, 2021, 47(5): 1017−1034. [6] RUFF L, VANDERMEULEN R, GOERNITZ N, et al. Deep one-class classification[C]//Proceedingds of the 35th International conference on machine learning. Stockholm: PMLR, 2018: 4393−4402. [7] LIZNERSKI P, RUFF L, VANDERMEULEN R A, et al. Explainable deep one-class classification[EB/OL]. (2020−07−03)[2023−10−19]. http://arxiv.org/abs/2007.01760v3. [8] BERGMAN L, HOSHEN Y. Classification-based anomaly detection for general data[EB/OL]. (2020−05−05) [2023−10−19]. http://arxiv.org/abs/2005.02359v1. [9] COHEN N, HOSHEN Y. Sub-image anomaly detection with deep pyramid correspondences[EB/OL]. (2020−05−05) [2023−10−19]. http://arxiv.org/abs/2005.02357v3. [10] DEFARD T, SETKOV A, LOESCH A, et al. PaDiM: A patch distribution modeling framework for anomaly detection and localization[C]//International Conference on Pattern Recognition. Cham: Springer, 2021: 475−489. [11] ROTH K, PEMULA L, ZEPEDA J, et al. Towards total recall in industrial anomaly detection[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 14298−14308. [12] CRESWELL A, WHITE T, DUMOULIN V, et al. Generative adversarial networks: an overview[J]. IEEE signal processing magazine, 2018, 35(1): 53−65. doi: 10.1109/MSP.2017.2765202 [13] 陈大鹏, 姚剑敏, 严群, 等. 基于自编码器结构改进的无监督图像异常检测[J]. 信息技术与信息化, 2023(8): 4−7. doi: 10.3969/j.issn.1672-9528.2023.08.001 CHEN Dapeng, YAO Jianmin, YAN Qun, et al. Unsupervised image anomaly detection based on improved autoencoder structure[J]. Information technology and informatization, 2023(8): 4−7. doi: 10.3969/j.issn.1672-9528.2023.08.001 [14] WANG Guodong, HAN Shumin, DING Errui, et al. Student-teacher feature pyramid matching for anomaly detection[EB/OL]. (2021−03−07)[2023−10−19]. http://arxiv.org/abs/2103.04257v3. [15] BERGMANN P, FAUSER M, SATTLEGGER D, et al. Uninformed students: student-teacher anomaly detection with discriminative latent embeddings[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 4182−4191. [16] 秦荣荣, 高晓蓉, 罗林, 等. 基于注意力反向知识蒸馏的车轮踏面异常检测[J]. 激光与光电子学进展, 2023, 60(24): 230−239. QIN Rongrong, GAO Xiaorong, LUO Lin, et al. Wheel tread anomaly detection based on attentional reverse knowledge distillation[J]. Laser & optoelectronics progress, 2023, 60(24): 230−239. [17] KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the national academy of science, 2017, 114(13): 3521−3526. doi: 10.1073/pnas.1611835114 [18] LI Zhizhong, HOIEM D. Learning without forgetting[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 40(12): 2935−2947. doi: 10.1109/TPAMI.2017.2773081 [19] 张静宇, 续欣莹, 谢刚, 等. 基于弹性权重巩固与知识蒸馏的垃圾持续分类[J]. 智能系统学报, 2023, 18(4): 878−885. ZHANG Jingyu, XU Xinying, XIE Gang, et al. Continuous classification of garbage based on the elastic weight consolidation and knowledge distillation[J]. CAAI transactions on intelligent systems, 2023, 18(4): 878−885. [20] LIU Hao, LIU Huaping. Continual learning with recursive gradient optimization[EB/OL]. (2022−01−29)[2023−10−19]. http://arxiv.org/abs/2201.12522v1. [21] REBUFFI S A, KOLESNIKOV A, SPERL G, et al. iCaRL: incremental classifier and representation learning[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 5533−5542. [22] BUZZEGA P, BOSCHINI M, PORRELLO A, et al. Dark experience for general continual learning: a strong, simple baseline[EB/OL]. (2020−04−15)[2023−10−19]. http://arxiv.org/abs/2004.07211v2. [23] HU Zhiyuan, LI Yunsheng, LYU Jiancheng, et al. Dense network expansion for class incremental learning[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 11858−11867. [24] MALLYA A, LAZEBNIK S. PackNet: adding multiple tasks to a single network by iterative pruning[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7765−7773. [25] FERNANDO C, BANARSE D, BLUNDELL C, et al. PathNet: evolution channels gradient descent in super neural networks[EB/OL]. (2017−01−30)[2023−10−19]. http://arxiv.org/abs/1701.08734v1. [26] 陈焕文. 网络分割与自适应突触可塑性融合的连续学习[J]. 华中科技大学学报(自然科学版), 2024, 52(3): 156−160. CHEN Huanwen. Continual learning using split network and adaptive synaptic plasticity[J]. Journal of huazhong university of science and technology(natural science edition), 2024, 52(3): 156−160. [27] PEZZE D D, ANELLO E, MASIERO C, et al. Continual learning approaches for anomaly detection[EB/OL]. (2022−11−21)[2023−10−19]. http://arxiv.org/abs/2212.11192v1. [28] DENG Hanqiu, LI Xingyu. Anomaly detection via reverse distillation from one-class embedding[C]//2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 9727−9736. [29] DOUILLARD A, CORD M, OLLION C, et al. PODNet: pooled outputs distillation for small-tasks incremental learning[C]//European Conference on Computer Vision. Cham: Springer, 2020: 86−102. [30] KINGMA D P, BA J, HAMMAD M M. Adam: a method for stochastic optimization[EB/OL]. (2014−12−22)[2023−10−19]. http://arxiv.org/abs/1412.6980v9. [31] TIEN T D, NGUYEN A T, TRAN N H, et al. Revisiting reverse distillation for anomaly detection[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 24511−24520. [32] ZAVRTANIK V, KRISTAN M, SKOČAJ D. DRAEM-A discriminatively trained reconstruction embedding for surface anomaly detection[C]//2021 IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 8310−8319.















































