 2022,
Vol. 31
2022,
Vol. 31



2. 农业农村部大洋渔业开发重点实验室, 上海 201306;
3. 佛罗里达国际大学 生物科学学院, 美国迈阿密 33199
印度洋长鳍金枪鱼(Thunnus alalunga)分布于印度洋的温带水域,是印度洋金枪鱼渔业的重要经济鱼种之一[1-4]。印度洋金枪鱼委员会(Indian Ocean Tuna Commission,IOTC)的温带金枪鱼工作组(working party on temperate tunas,WPTmT)于2019年对印度洋长鳍金枪鱼进行了完整的资源评估,认为该鱼种生物量尚未被过度捕捞,但捕捞死亡率正在导致其过度捕捞[5]。然而,目前印度洋长鳍金枪鱼的资源评估中,仍存在若干影响资源评估结果的问题需要研究,数据权重就是其中之一。
尽管目前针对数据权重问题的最佳解决方法仍未有定论,但其在资源评估中的重要性已经成为相关研究领域的共识[6-8]。受到数据权重影响的任何统计推断,都可能导致对资源状况的判断产生偏差或错误[9-10]。FRANCIS[11]建议在资源评估中应优先考虑丰度指数的数据权重,因为该类数据能够代表种群动态的直接信息,需要优先考虑以防止其中蕴含的资源信息被忽视。WANG等[12]发现丰度指数的拟合只能通过在特定时间序列中增加其权重才能得到一定的改善。LEE等[13]则认为,过度强调不具有信息代表性的丰度指数可能是不恰当的。无论如何,丰度指数作为数据加权的关键性因素,都是资源评估过程中需要认真考虑的重要问题。
目前,WPTmT已通过使用各成员国收集的渔获量和捕捞努力量数据,进一步开发了以不同区域划分的长鳍金枪鱼单位捕捞努力量渔获量(catch per unit effort,CPUE)数据。在WPTmT的最新研究中[5],采用多种资源评估模型对长鳍金枪鱼进行了资源评估,包括贝叶斯状态空间剩余产量模型(bayesian state-space surplus production model,BSSPM)[14]、资源综合模型(stock synthesis,SS)[15]、年龄结构渔获量统计模型(statistical-catch-at-age,SCAA)[16]。然而,BSSPM和SS仅使用了基于印度洋东南和西南区域的CPUE时间序列数据,而SCAA虽然考虑了所有4个区域的CPUE时间序列数据,但却没有针对不同CPUE权重进行敏感性分析。
资源评估是渔业科学管理的基础,探讨不同CPUE权重的分配是否会对资源评估结果产生影响,对于后续资源评估改进具有借鉴意义[3-4]。本研究以印度洋长鳍金枪鱼为对象,通过考虑不同的CPUE权重,并结合生物学参数的错误设置,进行敏感性分析,来评价CPUE权重的错误设置对评估结果的影响,以期为今后相关领域的研究工作提供一定的参考。
1 材料与方法 1.1 评估模型的构建 1.1.1 模型简介本研究使用年龄结构资源评估模型(age-structured assessment program,ASAP),通过给定的渔获量、渔获年龄组成以及丰度指数数据作为观测量,并将捕捞死亡系数分为年间和年龄两部分,采用顺推方式模拟种群动态的变化过程[17-18]。
1.1.2 生物学参数和数据本研究遵循WPTmT最新资源评估研究的有关基础假设[5],假定印度洋长鳍金枪鱼为单一的资源种群[15]。使用传统的Von Bertalanffy生长方程[19],体长(L)和体质量(W)的关系为W=(1.371 8×10-5)L3.097 3,忽略可能存在的生长误差[20]。假设繁殖力与各年龄的雌性鱼体质量成比例[21],补充阶段时的性别比例是相等的(即1:1)[15]。种群的年龄组由0~15龄构成(大于15龄则被视为附加年龄组)[5]。自然死亡系数M设置为0.3[22],Beverton-Holt亲体补充量关系的陡度参数h设置为0.7[15](表 1)。

|
表 1 印度洋长鳍金枪鱼资源评估参数值 Tab.1 Parameter values for stock assessment of Indian Ocean albacore |
印度洋长鳍金枪鱼的渔业独立或非独立数据由IOTC秘书处统计,主要包括渔获量、渔获年龄组成以及CPUE[5]。将印度洋长鳍金枪鱼渔业共划分为5种渔业,其中分别包括:西北部海域的延绳钓渔业(渔业1,LLNW)、东北部海域的延绳钓渔业(渔业2,LLNE)、西南部海域的延绳钓渔业(渔业3,LLSW)、东南部海域的延绳钓渔业(渔业4,LLSE)、印度洋海域的其他渔业(渔业5,Other)。研究中所使用的CPUE数据是通过标准化而得到的联合标准化CPUE(joint CPUE,尾/千钩)[5],时间跨度为1980—2017年,具体按区域划分为西北部海域(northwest),东北部海域(northeast),西南部海域(southwest),东南部海域(southeast),共4个区域的时间序列数据。
1.2 操作模型通过评估模型估计得出的相关参数(包括捕捞死亡系数、渔具选择性等),使用年龄结构种群模拟器(age based population simulator,PopSim)构建操作模型,用以模拟“真实”的资源种群动态以及相应的捕捞动态(图 1)。假设可捕系数不随时间变化,渔具选择性为逻辑斯蒂曲线(single-logistic),CPUE数据和渔获量数据的样本量设置为200尾。在此基础上模拟了4个CPUE时间序列数据集(图 2)。4组渔业的假设如下:(1)西北部区域的CPUE表示该区域对应的渔获量数据不可靠(称为“渔获量的高度不确定性”);(2)东北部区域的CPUE表示该区域对应的渔业渔获量比例最小(称为“渔获量比例低”);(3)西南部区域的CPUE表示该区域的CPUE不可靠(称为“CPUE的高度不确定性”);(4)东南部区域的CPUE表示该区域的CPUE时间序列不完整(称为“短时间的CPUE序列”)。考虑了CPUE和渔获量不同水平的变异系数(coefficient of variation,CV),以探讨CPUE权重对资源评估结果的影响。同时,还考虑了按区域划分的渔获量比例(表 2),其计算公式为

|
图 1 操作模型中的捕捞死亡系数和渔具选择性(1980—2017) Fig. 1 Fishing mortality and selectivity from the operating model (1980-2017) |

|
图 2 操作模型中的CPUE(1980—2017) Fig. 2 CPUE time series from the operating model (1980-2017) |

|
表 2 不同区域的渔业数据组成 Tab.2 Structure of fishery-dependant data in different regions |
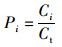 (1)
(1)
式中:Pi分别为西北、东北、西南和东南区域渔获量的相对比例;Ci为各区域在1980—2017年的总产量;Ct为这4个区域1980—2017年的总产量。
1.3 估算模型操作模型生成的渔获量、渔获年龄组成以及CPUE数据用作估算模型的输入数据,估算模型使用的仍旧是ASAP。除了CPUE权重以外,大多数生物学参数以及模型设置都与1.1节中评估模型的设置一致,以去除其他因素对研究结果的影响。
ASAP中参数估算的目标函数由拟合数据的似然函数构成,其中似然函数的误差分布共有两种:对数正态分布以及多项式分布。前者包括了丰度指数、渔获量数据的误差分布,后者则是渔获年龄组成数据的误差分布。多项式分布的似然函数公式如下:
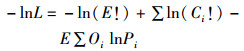 (2)
(2)
式中:lnL为似然函数取对数;Ci为i龄鱼的渔获量;Oi为观测的i龄鱼的渔获量比例;Pi为模型估计的渔获量的比例;“!”为阶乘;E为有效样本量。对数正态分布的似然函数公式如下:
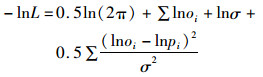 (3)
(3)
式中:lnL为似然函数取对数;oi为第i个数据的观测值;pi为第i个数据的模型估计值;σ为误差分布的标准差。ASAP的最终目标函数是渔获年龄组成,渔获量以及CPUE数据的似然函数之和:
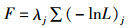 (4)
(4)
式中:F为目标函数;lnL为似然函数取对数;λj为第j个似然函数的加权因子。因此,针对4个区域特定CPUE的权重因子配置将会影响到资源状态的评估结果。
1.4 情景设立除了4组CPUE数据统一分配相同的权重因子以外,在估算模型中还考虑了另外4种CPUE权重的分配方案,即分别为每个区域的CPUE值分配相较于其余区域5倍的加权因子。综上所述,本研究总共考虑了5种CPUE权重方案对于估算模型评估资源状态的影响(表 3)。

|
表 3 4个区域CPUE权重因子的5种分配方案 Tab.3 Five weighting scenarios of CPUE factors for four areas |
此前的研究表明,作为年龄结构模型主要的不确定性来源,M和h可能会较大地影响评估结果[23-24]。因此,设置3种自然死亡系数M(0.15, 0.30, 0.45)以及3种Beverton-Holt亲体补充量关系的陡度参数h的水平(0.5, 0.7, 0.9),进行敏感性分析,目的是为了分析以上生物学参数的错误假设是否会对CPUE权重产生进一步的影响。因此,在估算模型中总共考虑了45种模型的全因子实验设计方案(3种M×3种h×5种CPUE权重),对于每种方案,都在实验过程中进行了100次的数据模拟及模型拟合。
1.5 评估指标捕捞死亡系数(fishing mortality,F)和产卵亲体生物量(spawning stock biomass,B)的均方根误差(relative root mean square error,RMSE)被用于衡量估算模型的性能,更小的RMSE代表模型更好的拟合度[6]。相对RMSE的计算公式如下:
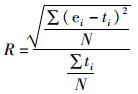 (5)
(5)
式中:R为相对RMSE;ei和ti分别为第i个数据的估计值和真实值;N为模拟次数。
估算模型的估计值和操作模型的模拟值之间F和B的相对误差(relative error,RE),同样被作为参考指标来进行比较,以此来探讨不同CPUE权重对资源评估的影响[23],RE的计算公式如下:
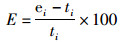 (6)
(6)
式中:E为相对误差RE;ei和ti分为表第i个数据的估计值和真实值。
此外,通过比较估算模型中最后一年的B/F与评估中第一年的B/F的比值(Blast/Bstart和Flast/Fstart),来评价不同CPUE权重对资源评估结果的影响[25]。鉴于PopSim模型本身的局限性,只能够输出F和B作为评判资源状况的指标,因此使用Blast/Bstart和Flast/Fstart作为资源状态变化的参考指标。参考指标的中位数相对误差(median relative error,MRE)和中位数绝对值相对误差(median absolute relative error,MARE)的计算公式如下[26]:
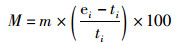 (7)
(7)
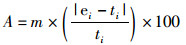 (8)
(8)
式中:M为相对MRE;A为相对MARE;m为中位数;ei和ti分别为第i个数据的估计值和真实值。
2 结果 2.1 F和B的结果根据PopSim模拟的印度洋长鳍金枪鱼“真实”的种群动态及渔业状况,对不同生物学假设进行了资源评估,并对结果进行了比较。结果显示,当在估算模型中正确指定了自然死亡系数M和陡度h时,将更多的权重分配给具有高度不确定性的CPUE序列数据的S3,其捕捞死亡系数F的中位数相对误差MRE均大于零,即S3在估计F时具有明显的过度估计趋势(图 3)。相对应的,S3在估计产卵亲体生物量B时则具有明显的低估趋势,即B的MRE均小于零(图 3)。而其余所有方案(S1,S2,S4和S5)对F和B的估计仅存在较小的不确定性,相应的MRE值都接近于零。表 4和表 5中列出了所有CPUE权重方案的相对RMSE值。同样的,无论是在估计F还是B时,S3的相对RMSE值都大于其余方案。

|
图 3 F和B的相对误差(M=0.3,h=0.7) Fig. 3 REs of F and B(M=0.3, h=0.7) |

|
表 4 F的相对均方根误差(RMSE) Tab.4 Relative root mean square error (RMSE) of F |

|
表 5 B的相对均方根误差(RMSE) Tab.5 Relative root mean square error (RMSE) of B |
当真实M与估算模型中的假设M相同时,无论h增加或减少,所有CPUE权重方案的RE年间变动趋势都是类似的(因此只展示了h等于0.7时的结果)。然而,错误设置的M会导致估计F和B的相对RMSE以及RE发生明显变化。RE的结果表明,所有CPUE权重方案的估算模型的评估结果都对M的错误设置敏感。当h不变时,过高估计的M(即真实M为0.3,但估算模型中假设M为0.45,图 4)将对F的估计产生负偏差,而对B的估计产生正偏差;当M被低估时(即真实M为0.3,但估算模型中假设M为0.15,图 5),对于F和B的估计则产生相反的影响。

|
图 4 F和B的相对误差(M=0.45,h=0.7) Fig. 4 REs of F and B(M=0.45, h=0.7) |

|
图 5 F和B的相对误差(M=0.15,h=0.7) Fig. 5 REs of F and B(M=0.15, h=0.7) |
当M被正确指定或被低估时,对于F而言,S2的相对RMSE是最低的,而对于B而言,S1的相对RMSE则是最低的;对于F和B而言,S3的相对RMSE都是最高的,这表示其对结果的拟合程度最差。然而,当M被高估时,无论是对于F还是B而言,S3的相对RMSE都是最低的。以上结果都显示了不同CPUE的权重,都将对F和B的估计结果产生影响。
2.2 资源状态指标的结果表 6和表 7列出了所有CPUE权重方案的MARE值(MRE值可从图 6和图 7中看出,因此未列表)。结果表明,当在估算模型中正确指定了M和h时,S1和S2都能够较为准确地估计Flast/Fstart和Blast/Bstart。而与其余方案相比,S3在估计Flast/Fstart时具有明显的过度估计趋势,在估计Blast/Bstart时也准确性较低(图 6,图 7)。

|
表 6 Flast/Fstart中位数绝对值相对误差(MARE) Tab.6 Median absolute relative error (MARE) of Flast/Fstart |

|
表 7 Blast/Bstart的中位数绝对值相对误差(MARE) Tab.7 Median absolute relative error (MARE) of Blast/Bstart |

|
图 6 Flast/Fstart的相对误差 Fig. 6 REs of Flast/Fstart |

|
图 7 Blast/Bstart的相对误差 Fig. 7 REs of Blast/Bstart |
类似的,当真实M与估算模型中的假设M相同时,无论h增加或减少,其在估计Flast/Fstart和Blast/Bstart时,对MRE的影响都是类似的。然而,错误设置M会导致估计Flast/Fstart和Blast/Bstart的MRE发生不同变化(图 6,图 7)。MRE的结果表明,所有CPUE权重方案的估算模型都对M的错误设置敏感。除了S3以外,当h不变时,过高估计M将对Flast/Fstart的估计产生正偏差,而对Blast/Bstart的估计产生负偏差;当M被低估时,对于Flast/Fstart和Blast/Bstart的估计则产生相反的影响。此外,无论M在估算模型中被高估抑或是低估,S3都会分别对Flast/Fstart和Blast/Bstart的估计产生正偏差和负偏差。
当M在估算模型中被高估时,S3对Blast/Bstart的估计产生了最低的MRE(图 7)。正相反,在其他情况下,与其余的CPUE权重方案相比,S3对Blast/Bstart的估计产生了最高的MARE(表 7),这体现了结果的不稳定性。此外,除了当M在估算模型中被高估时,MRE的结果表明了S1在能对Flast/Fstart产生更为精确的估计。以上结果都显示了不同CPUE权重,都将对Flast/Fstart和Blast/Bstart的估计结果产生影响。
3 讨论CPUE作为渔业资源丰度指标,是资源评估模型数据权重问题中不可忽视的一部分[27]。本研究探讨了5种不同CPUE权重方案对资源评估结果的影响。鉴于CPUE可以被视为资源状况的代表性数据[28],并且当估算模型中的自然死亡系数M和陡度h被正确指定或被低估时(表 4~7),相对于其他方案而言,“渔获量的高度不确定性”和“渔获量比例低”能够对捕捞死亡系数F和产卵亲体生物量B进行更为准确的估计。因此,与具有其他缺陷的方案(例如“CPUE的高度不确定性”和“短时间的CPUE序列”)相比,具有较高不确定性或不具代表性(即在所有区域中的渔获量比例较低)的渔业或调查数据或许应被分配更高的权重,尤其是当评估中的基础生物学参数能够被信任且富含信息性时。潜在的原因或许是因为,当在这两个区域的CPUE上分配更多的权重时,可以被视为对具有较高准确性和较长时间序列的CPUE分配了更多的权重。而当估算模型中的M被高估时,“CPUE的高度不确定性”出乎意料地对F和B的估计有着最低的相对RMSE值(表 4,表 5)。通常来说,估算模型中偏高指定的M将会导致对B的估计产生正偏差[29],这与本研究中的结果一致。但是,与其他的CPUE权重方案不同,当M在估算模型中被正确指定时,只有“CPUE的高度不确定性”会对B的估计产生负偏差。因此,造成该意外表现的原因可能是由于“CPUE的高度不确定性”对B估计产生的负偏差,部分抵消了估算模型中偏高指定的M所产生的正偏差(图 3)。同时,在CPUE权重的研究中应考虑部分基础生物学参数(例如M和h)的可信度,至少应进行敏感性分析,以涵盖潜在的模型或参数的错误设置对CPUE权重的影响。例如,从某个评估物种最近的生活史信息中研究得到了某一水平的M,但结果却明显地高于之前用于资源评估的值。在这种情况下,对具有较高准确性和较长时间序列的CPUE分配更多的权重,即便该类数据存在“渔获量的高度不确定性”和“渔获量比例低”的缺陷,或许也是一种相对合理的CPUE权重方案。
就Blast/Bstart和Flast/Fstart而言,“渔获量的高度不确定性”和“渔获量比例低”通常会产生最低的MRE和MARE,这代表了结果的准确估计。在2019年的WPTmT会议中,考虑到自2006年以来印度洋东南区域部分船队的作业目标发生了改变,即目标鱼种从南方蓝鳍金枪鱼转变为长鳍金枪鱼。工作组认为与其余部分的CPUE相比,该区域这部分船队的CPUE存在着由渔业选择性变化引起的不确定性。因此,最终的资源评估过程中将该部分的CPUE排除,而不是将存在冲突的相对丰度指数全部纳入联合CPUE中[5]。WANG等[12]在对印度洋剑鱼(Xiphias gladius)的CPUE权重研究中发现,增加日本延绳钓船队的CPUE权重无法提高数据的拟合度,这或许是因为船队的捕捞目标发生了转移而使得CPUE数据的准确性下降。以上研究结果都与本研究中有关“渔获量的高度不确定性”和“渔获量比例低”的结果相一致,即便该区域的渔获量数据并非十分具有代表性,也可对具有较高准确性和较长时间序列的CPUE分配更多的权重,以减少来自冲突数据中潜在的偏差。
然而,对于当前的印度洋长鳍金枪鱼资源评估而言,CPUE数据集的选择同样也是一个值得商榷的问题。如图 2所示,来自4个区域的CPUE时间序列数据集的变动趋势并不总是一致的,只有来自西部区域的两类CPUE具有相似的年间变化趋势,倘若要在模型中同时将其拟合是很困难的[9]。事实上,目前处理资源评估中数据冲突问题更为常见的方法是消除冲突的数据集[30],或“减少”一个或多个冲突的数据集的权重[31-32]。针对印度洋长鳍金枪鱼CPUE数据的选择问题,许多研究人员仅仅是使用了部分区域的CPUE数据集[14-15]。但是,考虑到每一个区域的CPUE数据都有可能反映了该区域资源的丰度状况,这类做法仍旧有待商榷[33]。因此,更重要的是要保证模型假设具有相对正确的生物学参数,考虑使用所有区域的CPUE数据集并赋予其适当的权重[32]。
总而言之,不同的CPUE权重方案确实会对印度洋长鳍金枪鱼资源评估结果产生影响。同时,本研究的结果表明,当使用多组CPUE数据时,对具有较高准确性或较长时间序列的CPUE分配更高的权重,或可提高资源状态指标估算的准确性。然而,考虑到有关数据权重的选择仍未有客观的标准,不同CPUE序列数据集的权重仍不可避免地受到主观判断的影响[11]。
| [1] |
马璐璐, 朱江峰, 耿喆, 等. 运用生物量动态模型评估印度洋长鳍金枪鱼资源[J]. 上海海洋大学学报, 2018, 27(2): 259-264. MA L L, ZHU J F, GENG Z, et al. Stock assessment of albacore (Thunnus alalunga) in the Indian Ocean using biomass dynamics model[J]. Journal of Shanghai Ocean University, 2018, 27(2): 259-264. |
| [2] |
张亚男, 官文江, 李阳东. 印度洋长鳍金枪鱼栖息地指数模型的构建与验证[J]. 上海海洋大学学报, 2020, 29(2): 268-279. ZHANG Y N, GUAN W J, LI Y D. Construction and verification of a habitat suitability index model for the Indian Ocean albacore tuna[J]. Journal of Shanghai Ocean University, 2020, 29(2): 268-279. |
| [3] |
朱江峰, 戴小杰, 官文江. 印度洋长鳍金枪鱼资源评估[J]. 渔业科学进展, 2014, 35(1): 1-8. ZHU J F, DAI X J, GUAN W J. Stock assessment of albacore Thunnus alalunga in the Indian Ocean[J]. Progress in Fishery Sciences, 2014, 35(1): 1-8. DOI:10.3969/j.issn.1000-7075.2014.01.001 |
| [4] |
官文江, 朱江峰, 高峰. 印度洋长鳍金枪鱼资源评估的影响因素分析[J]. 中国水产科学, 2018, 25(5): 1102-1114. GUAN W J, ZHU J F, GAO F. Analysis of influencing factors on stock assessment of the Indian Ocean albacore tuna (Thunnus alalunga)[J]. Journal of Fishery Sciences of China, 2018, 25(5): 1102-1114. |
| [5] |
IOTC-WPTmT07(AS)-R. Report of the seventh session of the IOTC working party on temperate tunas: assessment meeting[C]//Working Party on Temperate Tuna (WPTmT).
|
| [6] |
DERISO R B, MAUNDER M N, SKALSKI J R. Variance estimation in integrated assessment models and its importance for hypothesis testing[J]. Canadian Journal of Fisheries and Aquatic Sciences, 2007, 64(2): 187-197. DOI:10.1139/f06-178 |
| [7] |
HULSON P J F, MILLER S E, QUINN T J, et al. Data conflicts in fishery models: incorporating hydroacoustic data into the Prince William Sound Pacific herring assessment model[J]. ICES Journal of Marine Science, 2008, 65(1): 25-43. DOI:10.1093/icesjms/fsm162 |
| [8] |
PUNT A E, DENG R A, SIDDEEK M S M, et al. Data weighting for tagging data in integrated size-structured models[J]. Fisheries Research, 2017, 192: 94-102. DOI:10.1016/j.fishres.2015.12.010 |
| [9] |
FRANCIS R I C C. Revisiting data weighting in fisheries stock assessment models[J]. Fisheries Research, 2017, 192: 5-15. DOI:10.1016/j.fishres.2016.06.006 |
| [10] |
RICHARDS L J. Use of contradictory data sources in stock assessments[J]. Fisheries research, 1991, 11(3/4): 225-238. |
| [11] |
FRANCIS R I C C. Data weighting in statistical fisheries stock assessment models[J]. Canadian Journal of Fisheries and Aquatic Sciences, 2011, 68(6): 1124-1138. DOI:10.1139/f2011-025 |
| [12] |
WANG S P, MAUNDER M N, NISHIDA T, et al. Influence of model misspecification, temporal changes, and data weighting in stock assessment models: Application to swordfish (Xiphias gladius) in the Indian Ocean[J]. Fisheries Research, 2015, 166: 119-128. DOI:10.1016/j.fishres.2014.08.004 |
| [13] |
LEE H H, PINER K R, METHOT R DJR, et al. Use of likelihood profiling over a global scaling parameter to structure the population dynamics model: an example using blue marlin in the Pacific Ocean[J]. Fisheries Research, 2014, 158: 138-146. DOI:10.1016/j.fishres.2013.12.017 |
| [14] |
LEE S I, KITAKADO T, KIM D N. Stock assessment of albacore tuna in the indian ocean using bayesian state-space surplus production model[R]. IOTC-2019-WPTmT07(AS)-14_Rev1. IOTC, 2019.
|
| [15] |
LANGLEY A. Stock assessment of albacore tuna in the Indian Ocean using Stock Synthesis for 2019[C]//Working Party on Temperate Tuna (WPTmT).
|
| [16] |
NISHIDA T, KITAKADO T. Preliminary stock assessments for albacore tuna (Thunnus alalunga) in the Indian Ocean using Statistical-Catch-At-Age (SCAA)[R]. IOTC-2019-WPTmT07(AS)-17_Rev1. IOTC, 2019.
|
| [17] |
LEGAULT C M, RESTREPO V R. A flexible forward age-structured assessment program[R]. ICCAT WORKING DOCUMENTSCRS/98/58. ICCAT, 1998.
|
| [18] |
MOUSTAHFID H, LINK J S, OVERHOLTZ W J, et al. The advantage of explicitly incorporating predation mortality into age-structured stock assessment models: an application for Atlantic mackerel[J]. ICES Journal of Marine Science, 2009, 66(3): 445-454. DOI:10.1093/icesjms/fsn217 |
| [19] |
FARLEY J H, EVESONP J P, BONHOMMEAU S, et al. Growth of albacore tuna (Thunnus alalunga) in the western Indian Ocean using direct age estimates[R]. IOTC-2019-WPTmT07(DP)-21_Rev1. IOTC, 2019.
|
| [20] |
PENNEY A. Morphometric relationships, annual catch-at-size for South African-caught South Atlantic albacore (Thunnus alalunga)[OL]. ICCAT, 1994, 42(1): 371-382.
|
| [21] |
FARLEY J H, WILLIAMS A J, HOYLE S D, et al. Reproductive dynamics and potential annual fecundity of South Pacific albacore tuna (Thunnus alalunga)[J]. PLoS One, 2013, 8(4): e60577. DOI:10.1371/journal.pone.0060577 |
| [22] |
WATANABE H, KUBODERA T, MASUDA S, et al. Feeding habits of albacore Thunnus alalunga in the transition region of the central North Pacific[J]. Fisheries science, 2004, 70(4): 573-579. DOI:10.1111/j.1444-2906.2004.00843.x |
| [23] |
DEROBA J J, SCHUELLER A M. Performance of stock assessments with misspecified age-and time-varying natural mortality[J]. Fisheries Research, 2013, 146: 27-40. DOI:10.1016/j.fishres.2013.03.015 |
| [24] |
ZHU J F, CHEN Y, DAI X J, et al. Implications of uncertainty in the spawner-recruitment relationship for fisheries management: An illustration using bigeye tuna (Thunnus obesus) in the eastern Pacific Ocean[J]. Fisheries Research, 2012, 119-120: 89-93. DOI:10.1016/j.fishres.2011.12.008 |
| [25] |
CARVALHO F, PUNT A E, CHANG Y J, et al. Can diagnostic tests help identify model misspecification in integrated stock assessments?[J]. Fisheries Research, 2017, 192: 28-40. DOI:10.1016/j.fishres.2016.09.018 |
| [26] |
ONO K, LICANDEO R, MURADIAN M L, et al. The importance of length and age composition data in statistical age-structured models for marine species[J]. ICES Journal of Marine Science, 2015, 72(1): 31-43. DOI:10.1093/icesjms/fsu007 |
| [27] |
PUNT A E. Some insights into data weighting in integrated stock assessments[J]. Fisheries research, 2017, 192: 52-65. DOI:10.1016/j.fishres.2015.12.006 |
| [28] |
MAUNDER M N, PUNT A E. Standardizing catch and effort data: a review of recent approaches[J]. Fisheries research, 2004, 70(2-3): 141-159. DOI:10.1016/j.fishres.2004.08.002 |
| [29] |
PUNT A E, CASTILLO-JORDÁN C, HAMEL O S, et al. Consequences of error in natural mortality and its estimation in stock assessment models[J]. Fisheries Research, 2021, 233: 105759. DOI:10.1016/j.fishres.2020.105759 |
| [30] |
SIDDEEK M S M, ZHENG J, PUNT A E, et al. Effect of data weighting on the mature male biomass estimate for Alaskan golden king crab[J]. Fisheries Research, 2017, 192: 103-113. DOI:10.1016/j.fishres.2017.02.001 |
| [31] |
TRUESDELL S B, BENCE J R, SYSLO J M, et al. Estimating multinomial effective sample size in catch-at-age and catch-at-size models[J]. Fisheries Research, 2017, 192: 66-83. DOI:10.1016/j.fishres.2016.11.003 |
| [32] |
MINTE-VERA C V, MAUNDER M N, AIRES-DA-SILVA A M, et al. Get the biology right, or use size-composition data at your own risk[J]. Fisheries research, 2017, 192: 114-125. DOI:10.1016/j.fishres.2017.01.014 |
| [33] |
MAUNDER M N, PINER K R. Dealing with data conflicts in statistical inference of population assessment models that integrate information from multiple diverse data sets[J]. Fisheries Research, 2017, 192: 16-27. DOI:10.1016/j.fishres.2016.04.022 |
2. Key Laboratory of Oceanic Fisheries Exploration, Ministry of Agriculture and Rural Affairs, Shanghai 201306, China;
3. Department of Biological Sciences, Florida International University, Miami 33199, United States